sqoop
1. Sqoop简介及原理
| 简介: Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysq1.postgresql..)间进行数据的传递,可以将一个关系型数据库(例如: MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop 的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 Sqoop项目开始于2009年,最早是作为Hadoop 的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。v Sqoop2的最新版本是1.99.7。请注意,2与1不兼容,且特征不完整,它并不打算用于生产部署。 原理: 将导入或导出命令翻译成mapreduce程序来实现。 在翻译出的mapreduce中主要是对inputformat和 outputformat进行定制。 |
2.sqoop安装部署
| 解压、改名 [root@kb129 install]# tar -xvf ./sqoop-1.4.7.tar.gz -C /opt/soft/ [root@kb129 soft]# mv sqoop-1.4.7/ sqoop147 |
| 拷贝配置文件 [root@kb129 conf]# pwd /opt/soft/sqoop147/conf [root@kb129 conf]# cp sqoop-env-template.sh sqoop-env.sh 编辑配置文件 [root@kb129 conf]# vim ./sqoop-env.sh export HADOOP_COMMON_HOME=/opt/soft/hadoop313 export HADOOP_MAPRED_HOME=/opt/soft/hadoop313 export HBASE_HOME=/opt/soft/hbase235 export HIVE_HOME=/opt/soft/hive312 export HIVE_CONF_DIR=/opt/soft/hive312/conf export ZOOCFGDIR=/opt/soft/zk345/conf |
| 解压 [root@kb129 install]# tar -xvf ./sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C ./ 拷贝jar包至sqoop147根路径下 [root@kb129 sqoop-1.4.7.bin__hadoop-2.6.0]# cp ./sqoop-1.4.7.jar /opt/soft/sqoop147/ 继续拷贝jar包 [root@kb129 lib]# pwd /opt/soft/sqoop147/lib [root@kb129 lib]# cp /opt/soft/hive312/lib/hive-common-3.1.2.jar ./ [root@kb129 lib]# cp /opt/install/sqoop-1.4.7.bin__hadoop-2.6.0/lib/avro-1.8.1.jar ./ [root@kb129 lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar ./ 拷贝完毕:
|
| 配置sqoop环境变量并source #SQOOP export SQOOP_HOME=/opt/soft/sqoop147 export PATH=$SQOOP_HOME/bin:$PATH |
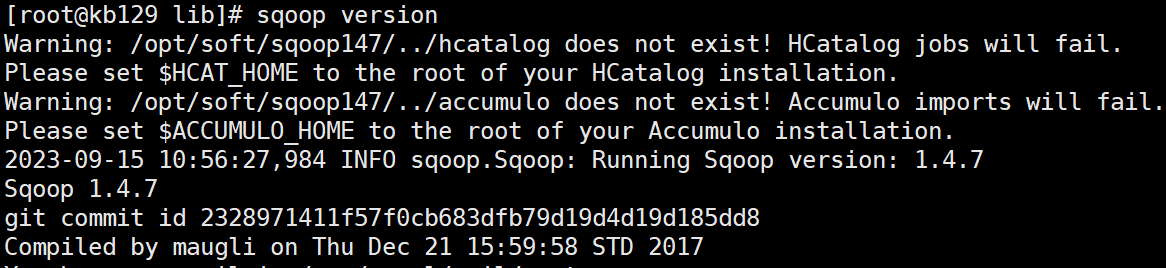
| 验证安装 [root@kb129 lib]# sqoop version
|

3.sqoop操作基本命令
| 3.1 基本操作:参考 https://www.cnblogs.com/qingyunzong/p/8807252.html 查看sqoop一般操作命令 [root@kb129 lib]# sqoop help 连接mysql命令(\代表换行输入) [root@kb129 lib]# sqoop list-databases \ --connect jdbc:mysql://kb129:3306/ \ --username root \ --password 123456
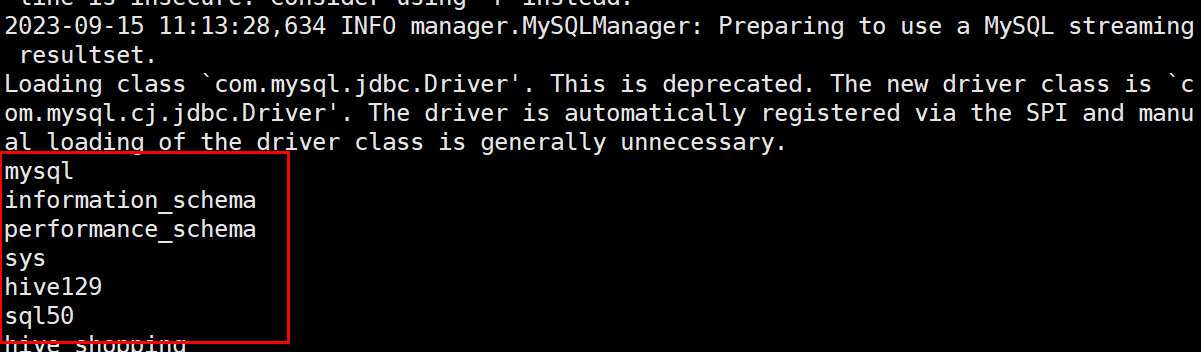
查看sql50数据库内的表 [root@kb129 lib]# sqoop list-tables --connect jdbc:mysql://kb129:3306/sql50 --username root --password 123456
在hive默认库中创建表(来源mysql库中的help_keyword表,仅复制表结构) [root@kb129 lib]# sqoop create-hive-table \ --connect jdbc:mysql://kb129:3306/mysql \ --username root --password 123456 \ --table help_keyword \ --hive-table hk |
| 3.2 Sqoop import 1、从Mysql导入到HDFS中 1)导入mysql库中的help_keyword的数据到HDFS默认路径上/user/root sqoop import --connect jdbc:mysql://kb129:3306/mysql --username root --password 123456 --table help_keyword -m 1 导入sql50库中的student表的数据到HDFS默认路径上 sqoop import --connect jdbc:mysql://kb129:3306/sql50 --username root --password 123456 --table student -m 1 2)导入: 指定分隔符,指定导入路径 sqoop import --connect jdbc:mysql://kb129:3306/sql50 --username root --password 123456 --table student --target-dir /kb23/student --fields-terminated-by '\t' -m 1 3)导入数据:带where条件 sqoop import --connect jdbc:mysql://kb129:3306/mysql --username root --password 123456 --where "name='STRING'" --table help_keyword --target-dir /kb23/hk1 -m 1 4)导入:指定自定义查询SQL sqoop import --connect jdbc:mysql://kb129:3306/mysql --username root --password 123456 --target-dir /kb23/hk2 --query 'select help_keyword_id,name from help_keyword where $CONDITIONS and name="STRING"' --split-by help_keyword_id --fields-terminated-by ':' -m 4 在以上需要按照自定义SQL语句导出数据到HDFS的情况下: (1)引号问题,要么外层使用单引号,内层使用双引号,$CONDITIONS的$符号不用转义, 要么外层使用双引号,那么内层使用单引号,然后$CONDITIONS的$符号需要转义 (2)自定义的SQL语句中必须带有WHERE \$CONDITIONS 2、把MySQL数据库中的表数据导入到Hive中 1)Sqoop 导入关系型数据到 hive 的过程是先导入到 hdfs,然后再 load 进入 hive 普通导入:数据存储在默认的default hive库中,表名就是对应的mysql的表名 sqoop import --connect jdbc:mysql://kb129:3306/mysql --username root --password 123456 --table help_keyword --hive-import -m 1 导入过程 第一步:导入mysql.help_keyword的数据到hdfs的默认路径 第二步:自动仿造mysql.help_keyword去创建一张hive表, 创建在默认的default库中 第三步:把临时目录中的数据导入到hive表中 2)指定行分隔符和列分隔符,指定hive-import,指定覆盖导入,指定自动创建hive表,指定表名,指定删除中间结果数据目录 sqoop import \ --connect jdbc:mysql://kb129:3306/mysql \ --username root \ --password 123456 \ --table help_keyword \ --hive-import \ --hive-overwrite \ --create-hive-table \ --delete-target-dir \ --hive-database kb23db \ --hive-table new_help_keyword 3)增量导入(追加) (执行增量导入之前,先清空hive数据库中的my_help_keyword表中的数据,方便查看) 从原表501行数据开始到最后,追加到目标表中 sqoop import \ --connect jdbc:mysql://kb129:3306/mysql \ --username root \ --password 123456 \ --table help_keyword \ --hive-import \ --incremental append \ --hive-database kb23db \ --check-column help_keyword_id \ --last-value 500 \ -m 1 在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到 hive 或者 hdfs 当中去这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入, sqoop 支持增量的导入数据。 -- 所谓的增量数据指的是上次至今中间新增加的数据 -- sqoop支持两种模式的增量导入 append追加 根据数值类型字段进行追加导入, 大于指定的last-value lastmodified 根据时间戳类型字段进行追加, 大于等于指定的last-value 注意在lastmodified模式下,还分为两种情形: append merge-key 增量导入是仅导入新添加的表中的行的技术。 --check-column(col) 用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似。 注意:这些被指定的列的类型不能使任意字符类型,如 char、varchar 等类型都是不可以的,同时-- check-column 可以去指定多个列。 --incremental(mode) append:追加,比如对大于 last-value 指定的值之后的记录进行追加导入。 lastmodified:最后的修改时间,追加 last-value 指定的日期之后的记录。 --last-value(value) 指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值。 3、把MySQL数据库中的表数据导入到hbase |
| 3.3 Sqoop export 参考小白篇(十二):sqoop export指令实操_belialxing的博客-CSDN博客 https://blog.csdn.net/d905133872/article/details/129421948?spm=1001.2014.3001.5502 1.将hive中的表数据导入到mysql中 (1) -- hive创建一张表,默认是textfile类型的 create table if not exists kb23db.export_txt_demo ( name string, address string ); -- 创建测试数据 insert into kb23db.export_txt_demo values('测试1','上海'); insert into kb23db.export_txt_demo values('测试2','北京'); (2) -- 创建接收表 create table sql50.export_txt_demo ( name varchar(10), address varchar(10) ); sqoop export --connect 'jdbc:mysql://kb129:3306/sql50' \ --username 'root' \ --password '123456' \ --table 'export_txt_demo' \ --export-dir /hive312/warehouse/kb23db.db/export_txt_demo \ --input-fields-terminated-by '\001' \ --input-null-string '\\N' \ --input-null-non-string '\\N'
参数说明: --connect '数据库连接' \ --username '数据库账号' \ --password '数据库密码' \ --table '数据库表名' \ --export-dir 集群hdfs中导出的数据目录 \ --input-fields-terminated-by '分隔符,textfile类型默认\001' \ --input-null-string '空值处理:\\N' \ --input-null-non-string '空值处理:\\N' |