文章目录
- 前言
- Consumer 消费流程
- Consumer初始化
- 如何选举Consumer Leader
- 消费者分区策略
- Consumer拉取数据
- 提交偏移量
前言
当生产者将消息发送到Broker时,这些消息将被存储在磁盘上。消费者是如何消费这些消息呢?
Consumer 消费流程
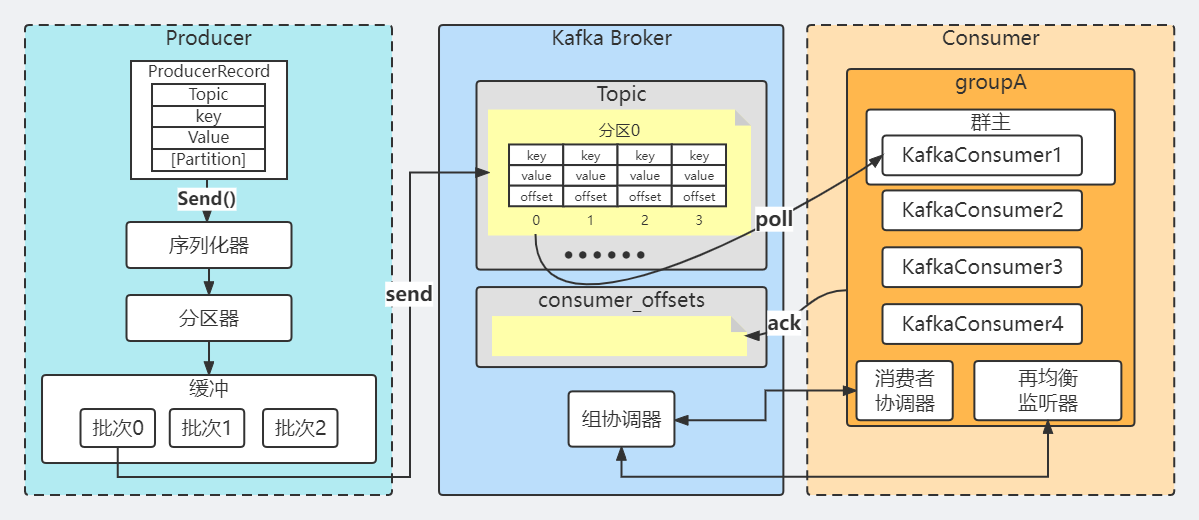
站在源码的核心角度,可以把Consumer分成以下几个核心部分:
- Consumer初始化
- 如何选举Consumer Leader
- Consumer Leader是如何指定分区
- Consumer如何拉取数据
- Consumer偏移量提交
Consumer初始化
从KafkaConsumer的构造方法出发,跟踪到核心实现方法
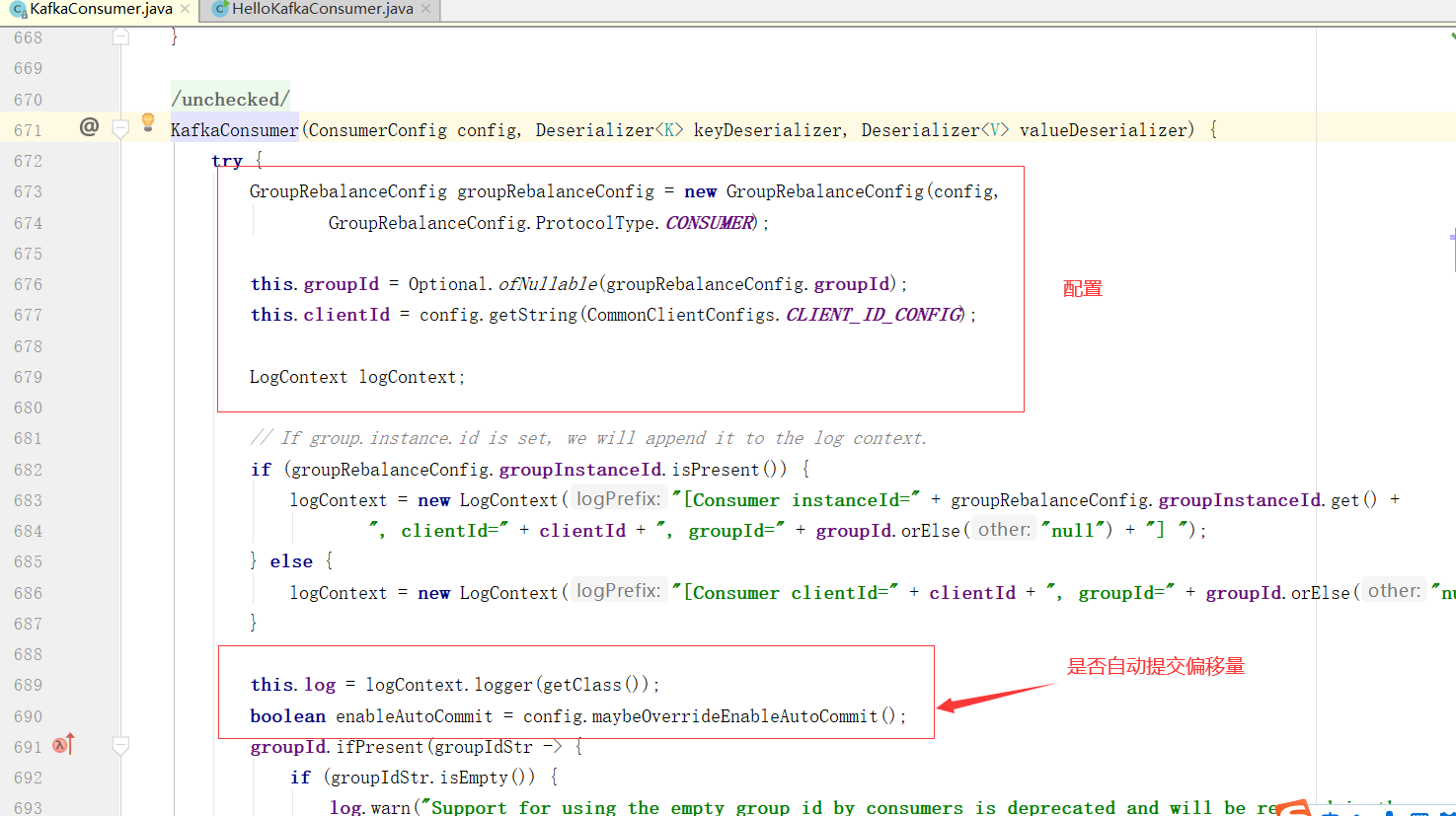
这个方法的前面代码部分都是一些配置
Consumer与Broker的核心通讯组件
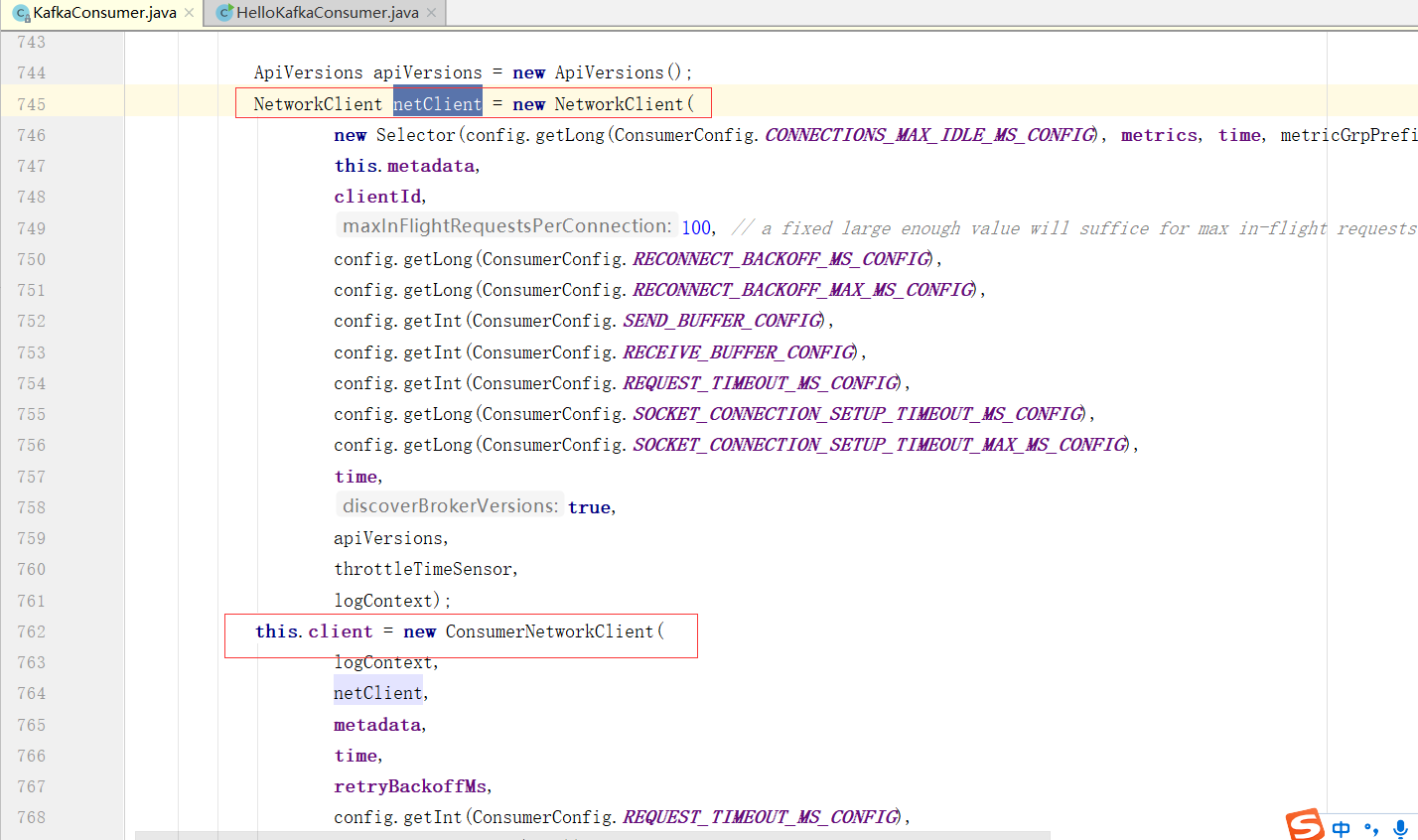
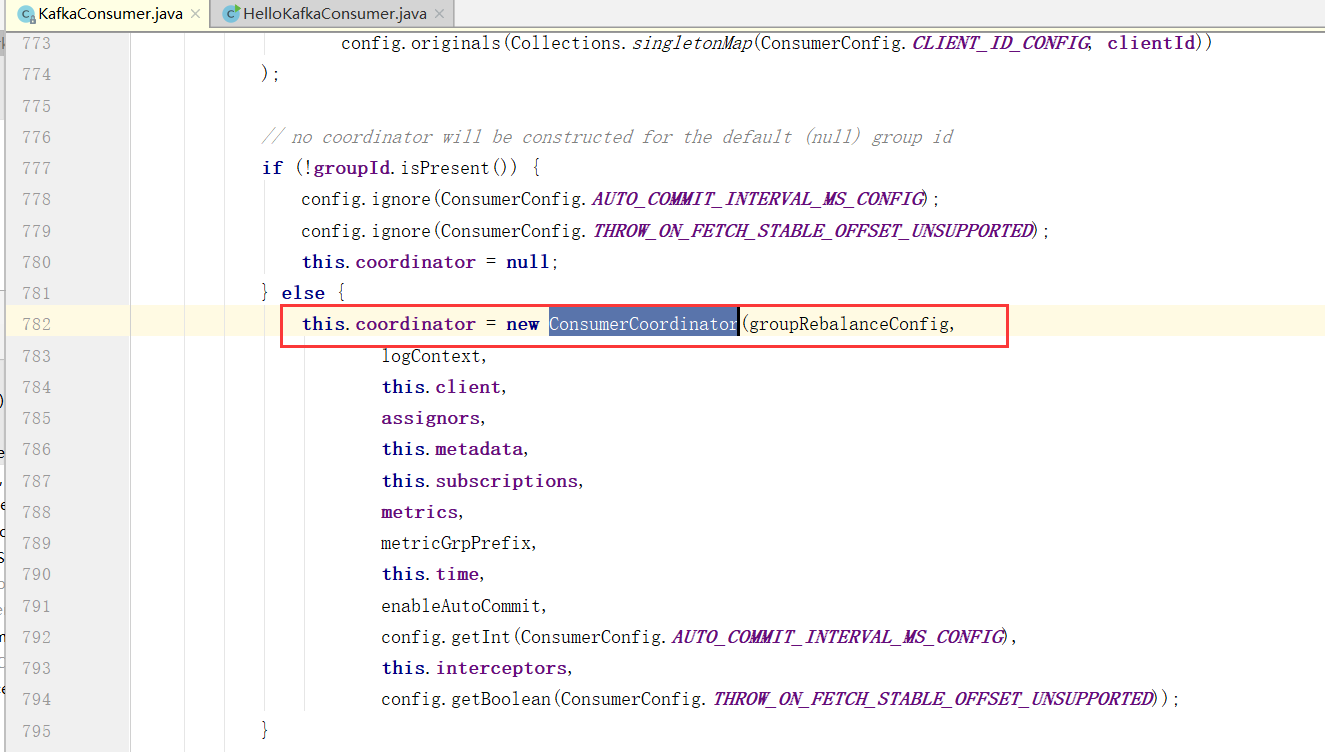
ConsumerCoordinator:在Kafka消费中是组消费,协调器在具体进行消费之前要做很多的组织协调工作。
Fetcher:提取器,因为Kafka消费是拉数据的,所以这个Fetcher就是拉取数据的核心类
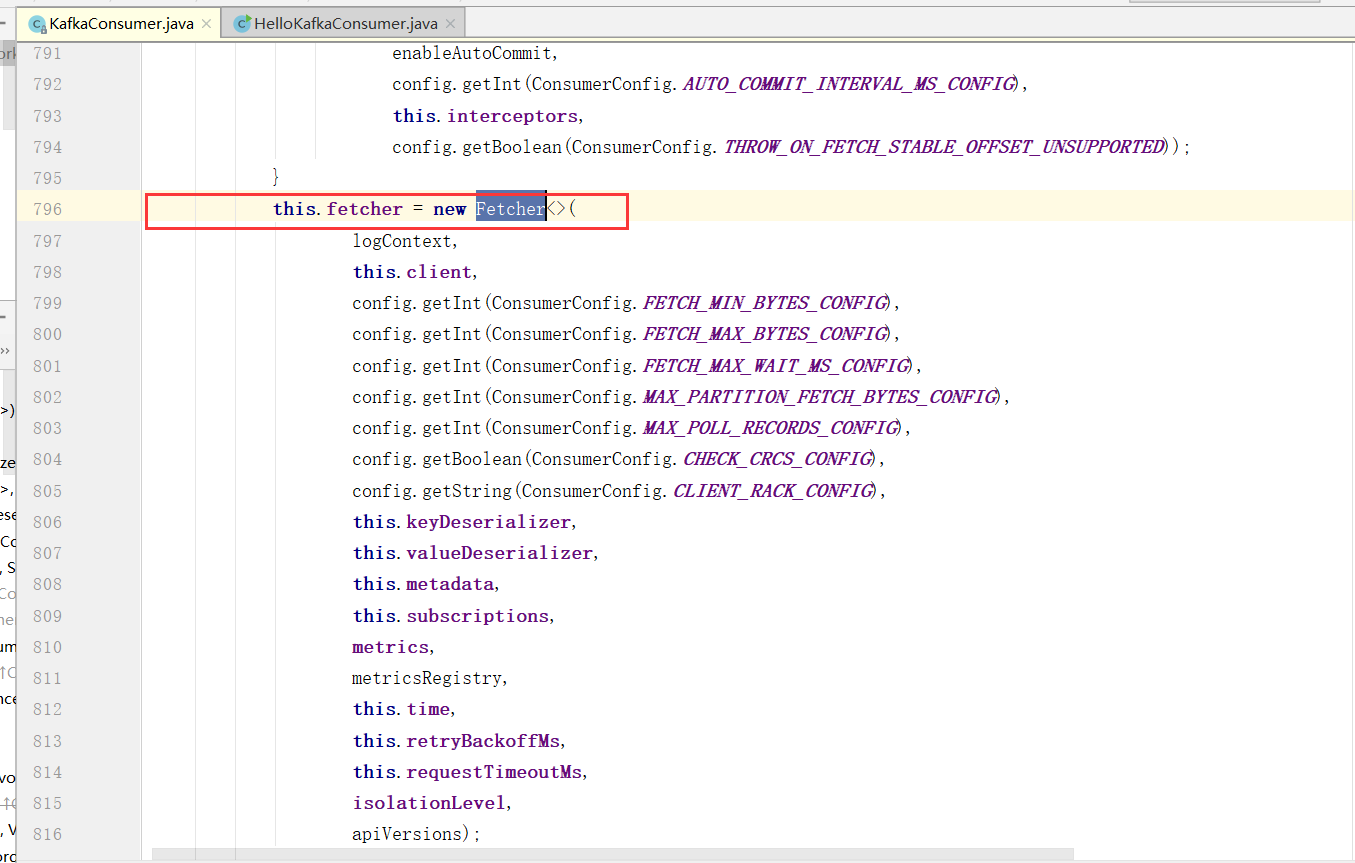
这个核心类中,有很多很多的参数设置,这些就跟消费的配置有关系
fetch.min.bytes
每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回,缺省为1个字节。多消费者下,可以设大这个值,以降低broker的工作负载。
fetch.max.bytes
每次fetch请求时,server应该返回的最大字节数。这个参数决定了可以成功消费到的最大数据。
比如这个参数设置的是50M,那么consumer能成功消费50M以下的数据,但是最终会卡在消费大于10M的数据上无限重试。fetch.max.bytes一定要设置到大于等于最大单条数据的大小才行。

fetch.wait.max.ms
如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在应答fetch请求之前,server会阻塞的最大时间。缺省为500毫秒。和上面的fetch.min.bytes结合起来。
max.partition.fetch.bytes
指定了服务器从每个分区里返回给消费者的最大字节数,默认1MB。
假设一个主题有20个分区和5个消费者,那么每个消费者至少要有4MB的可用内存来接收记录,而且一旦有消费者崩溃,这个内存还需更大。注意,这个参数要比服务器的message.max.bytes更大,否则消费者可能无法读取消息。
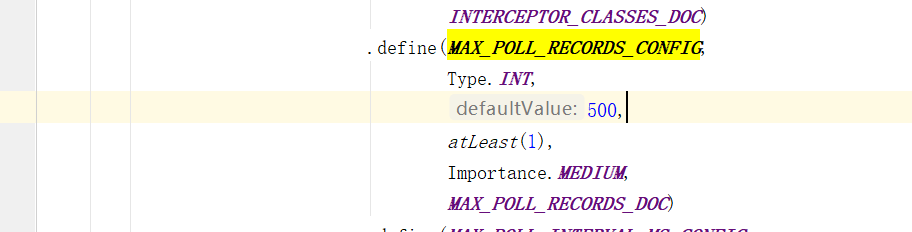
max.poll.records
控制每次poll方法返回的最大记录数量。
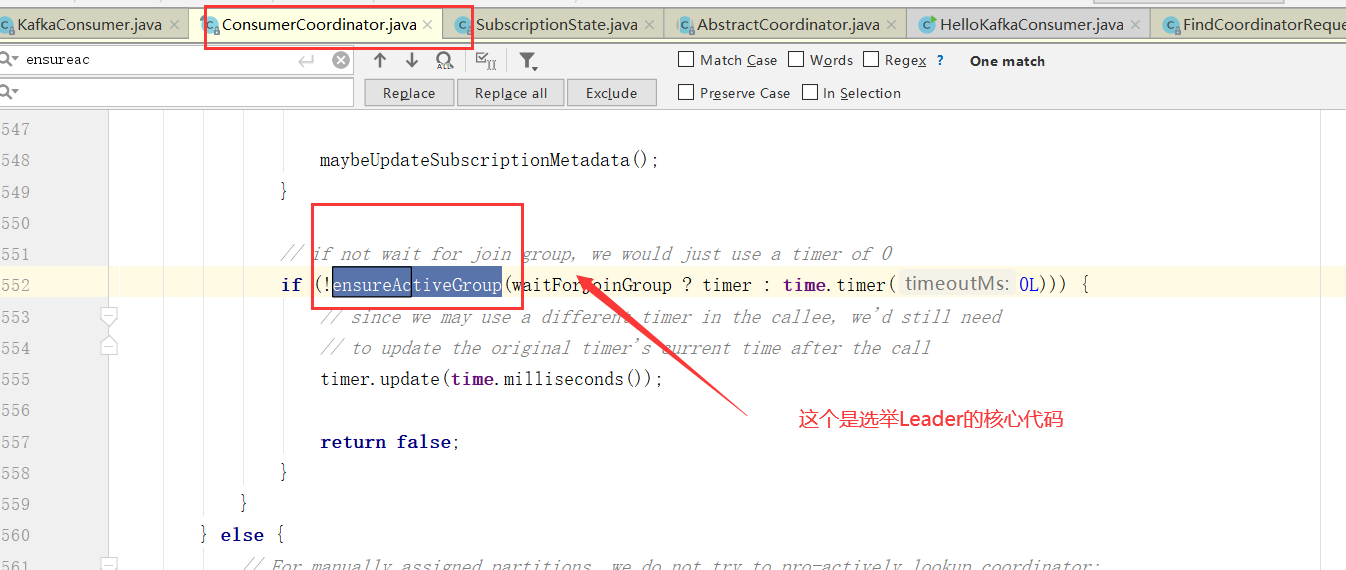
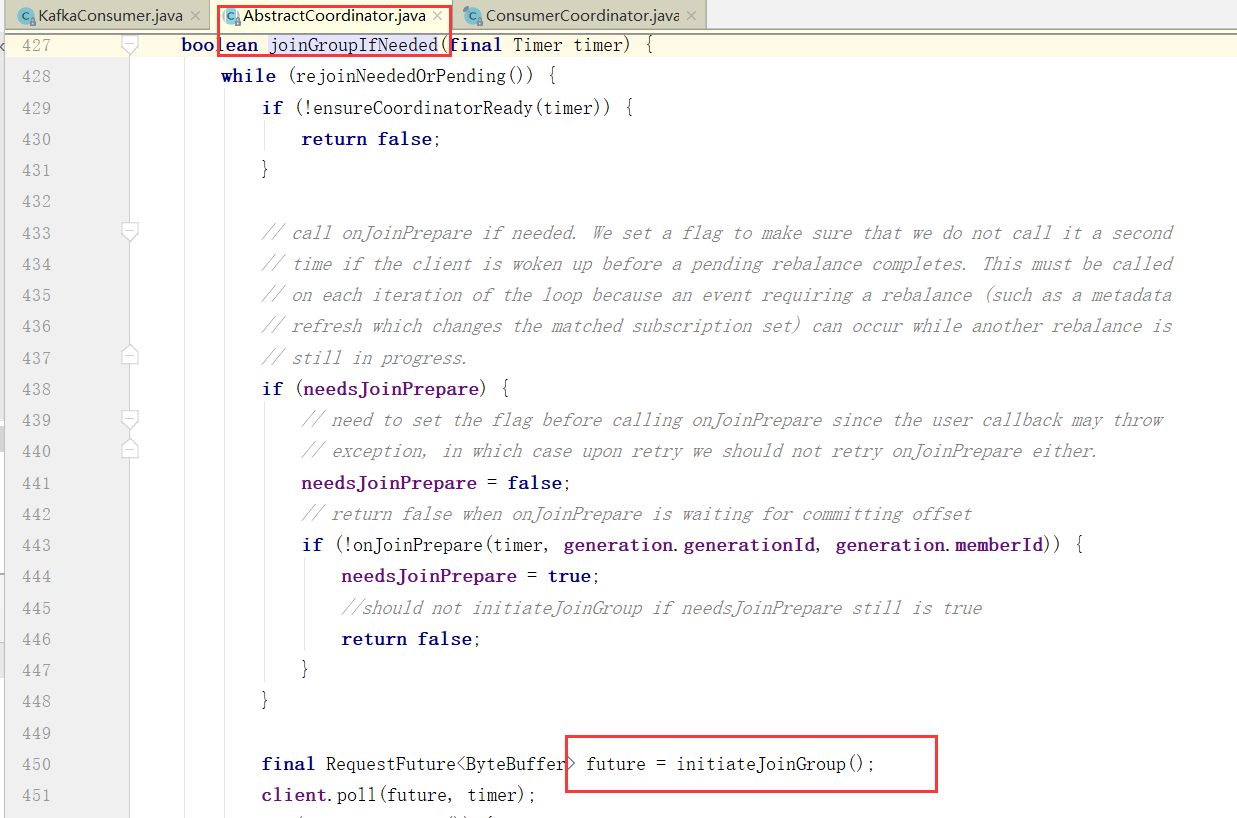
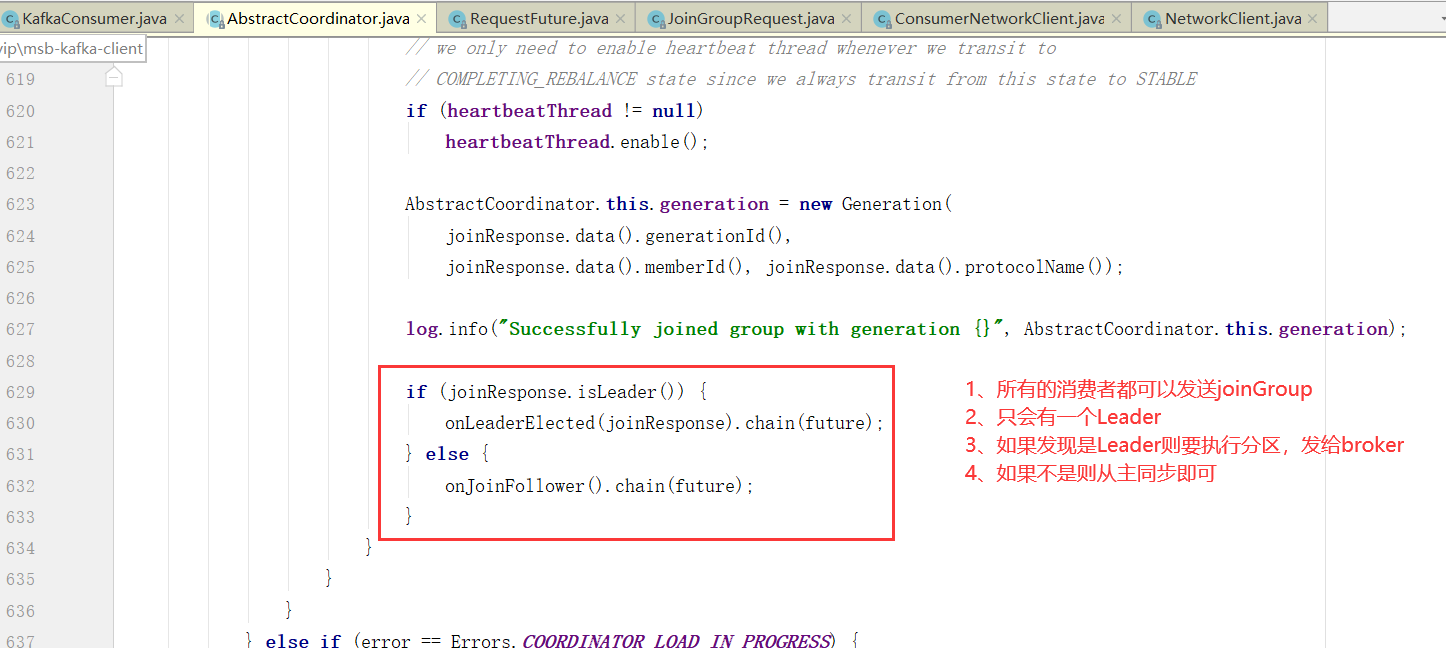
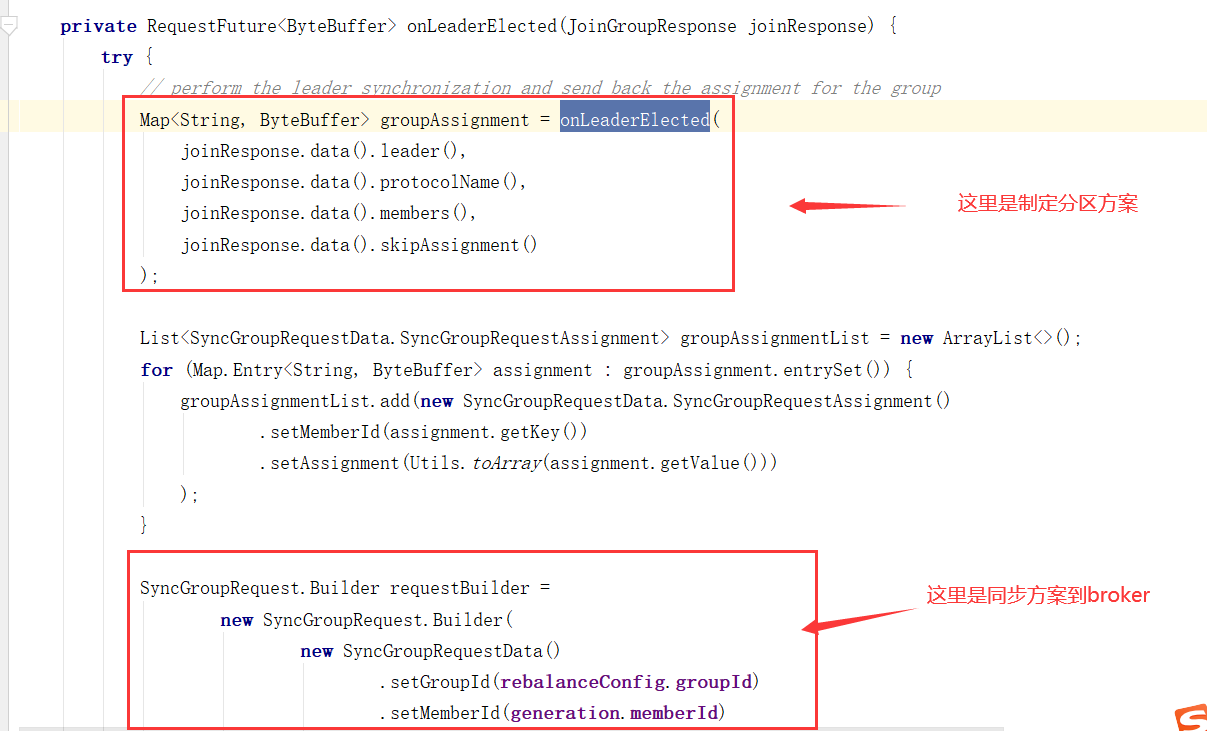
如何选举Consumer Leader
消费者协调器与组协调器的通讯
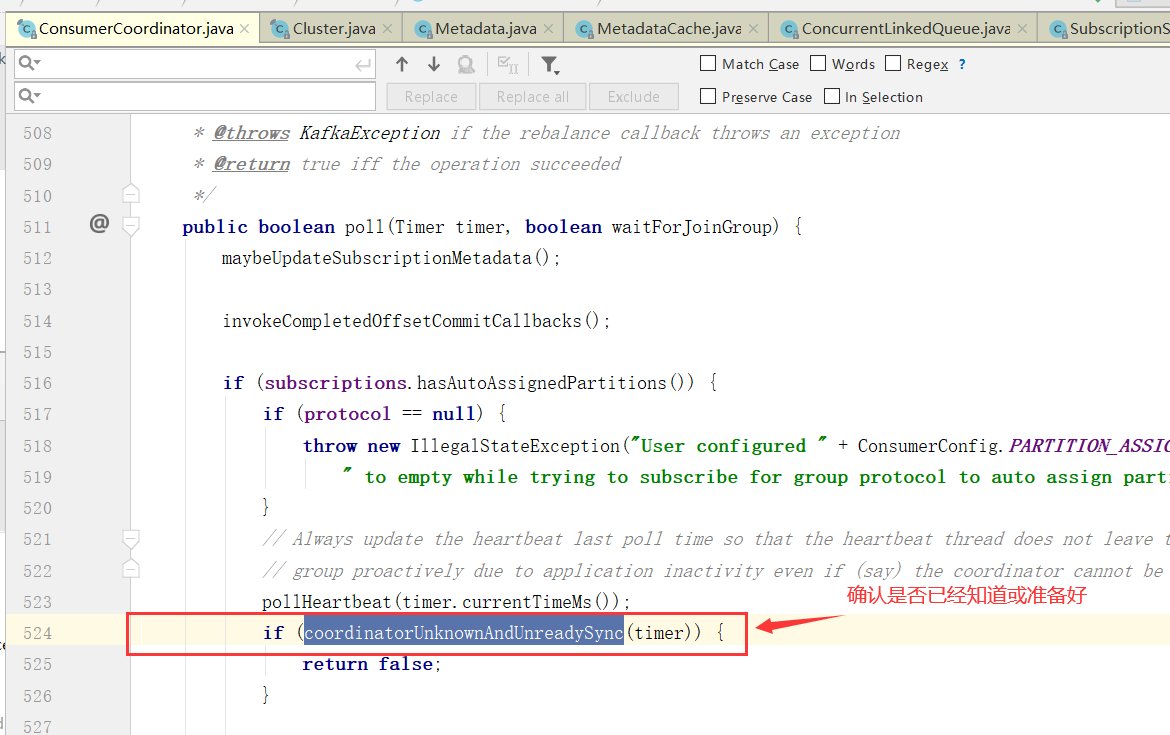

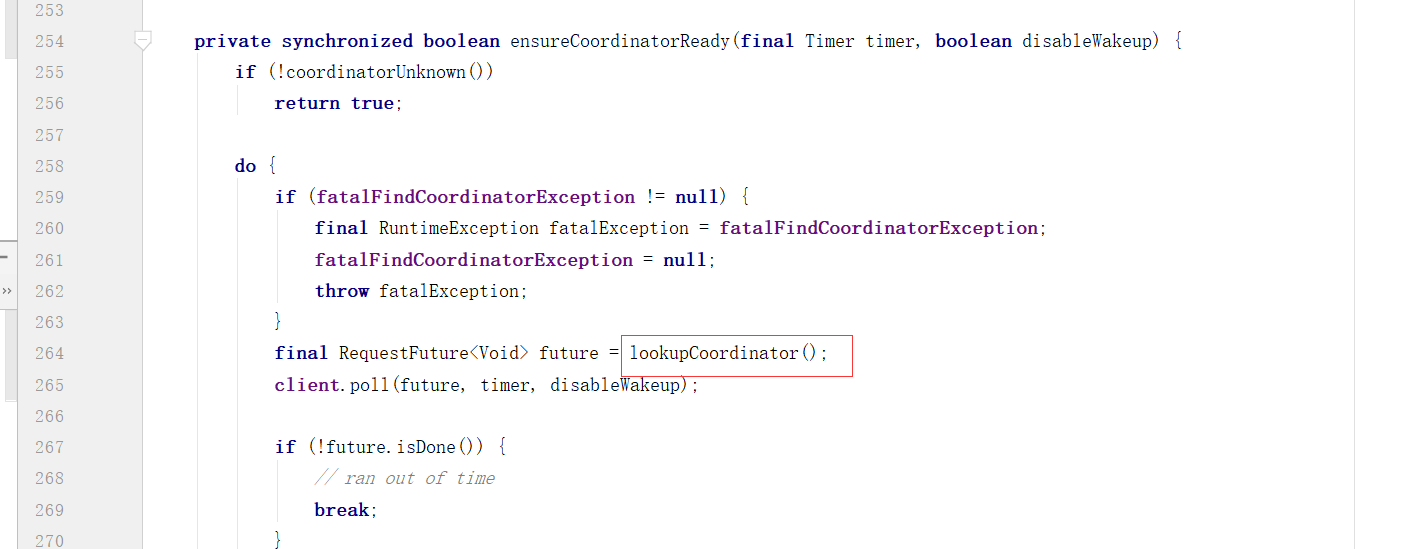
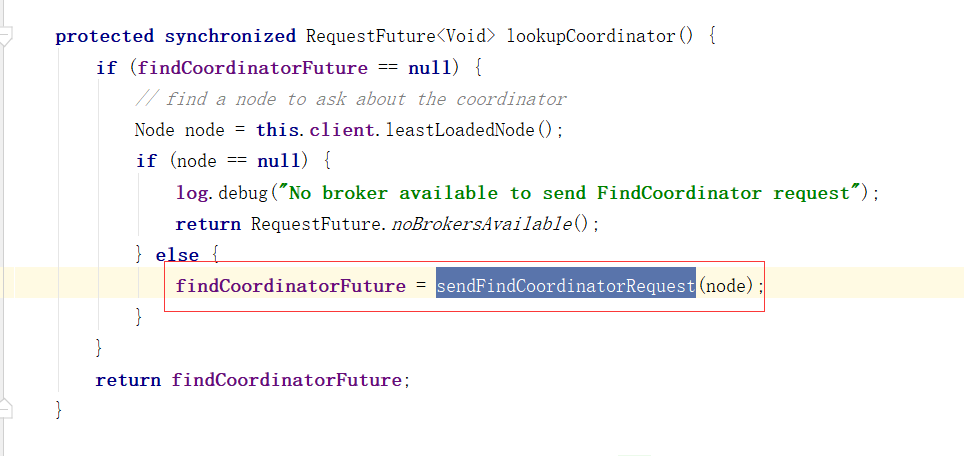
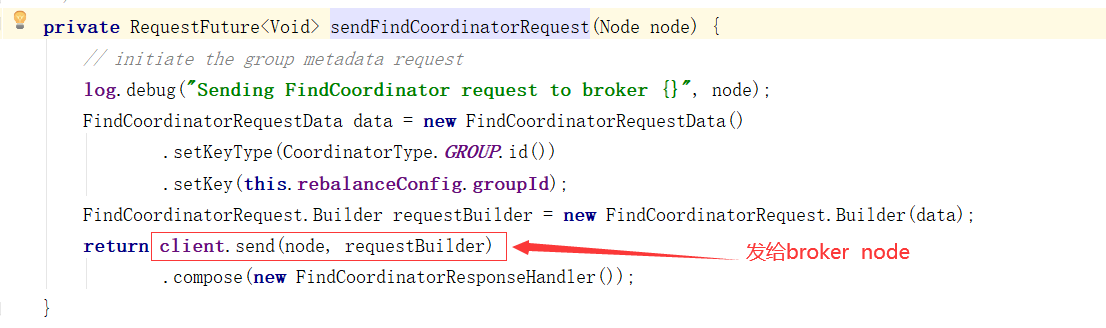
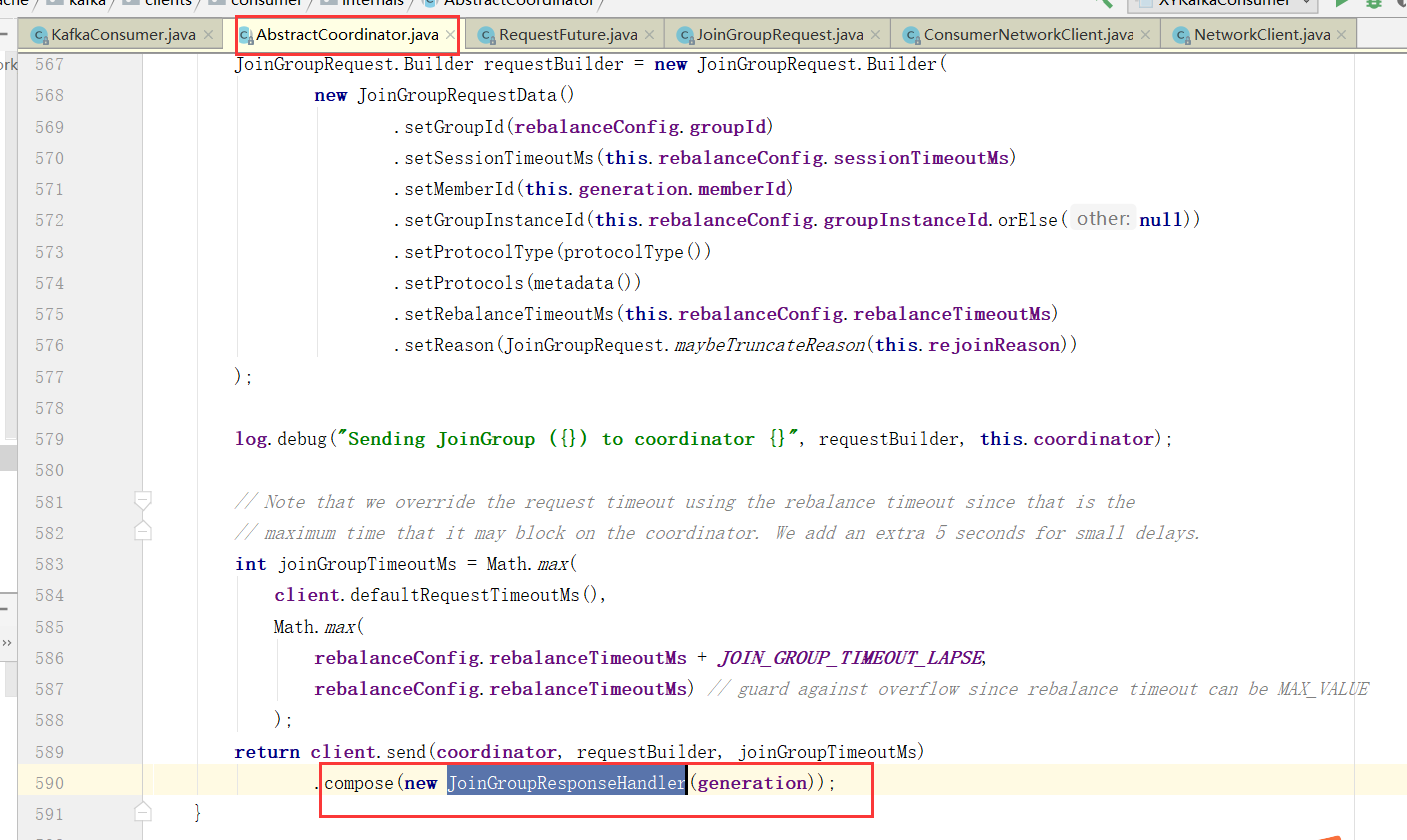
向Broker发送请求
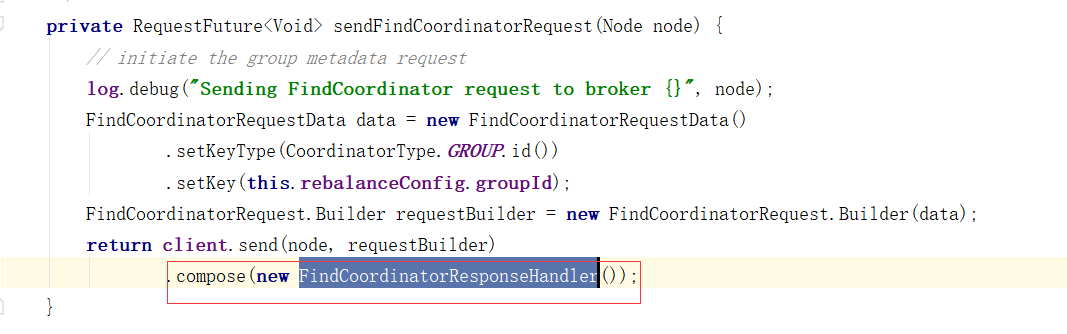
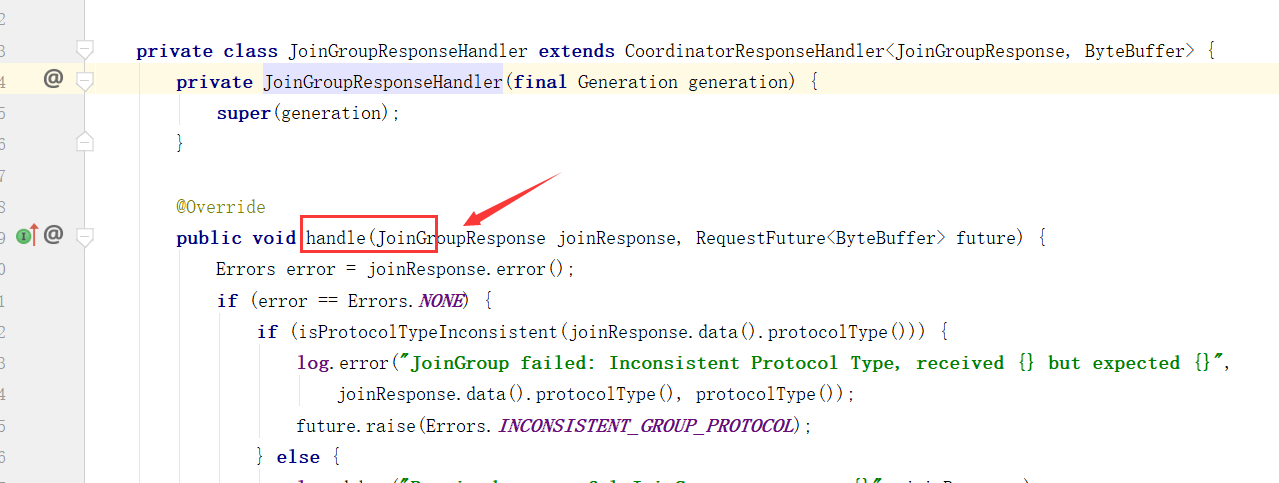
对Broker响应进行处理
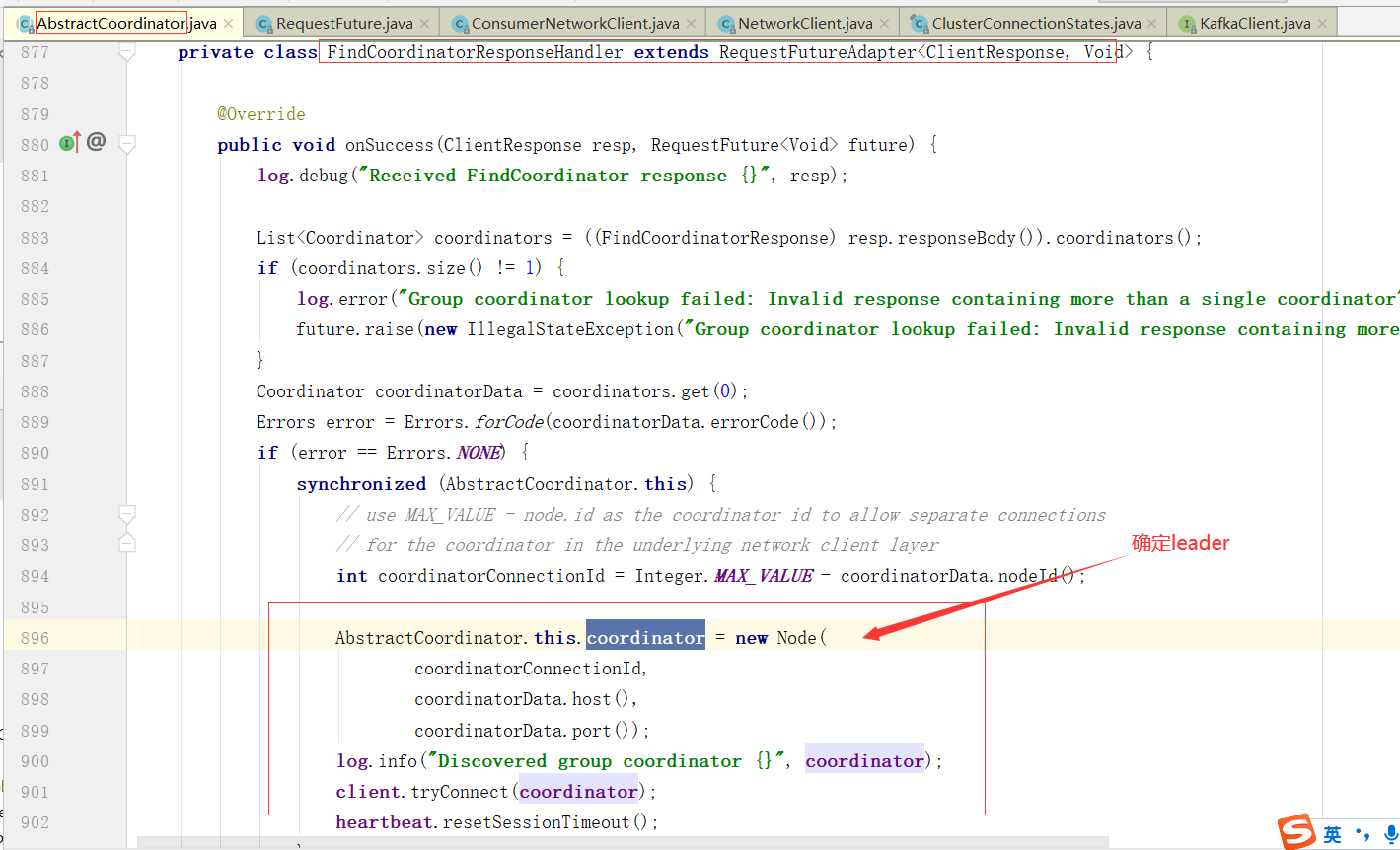
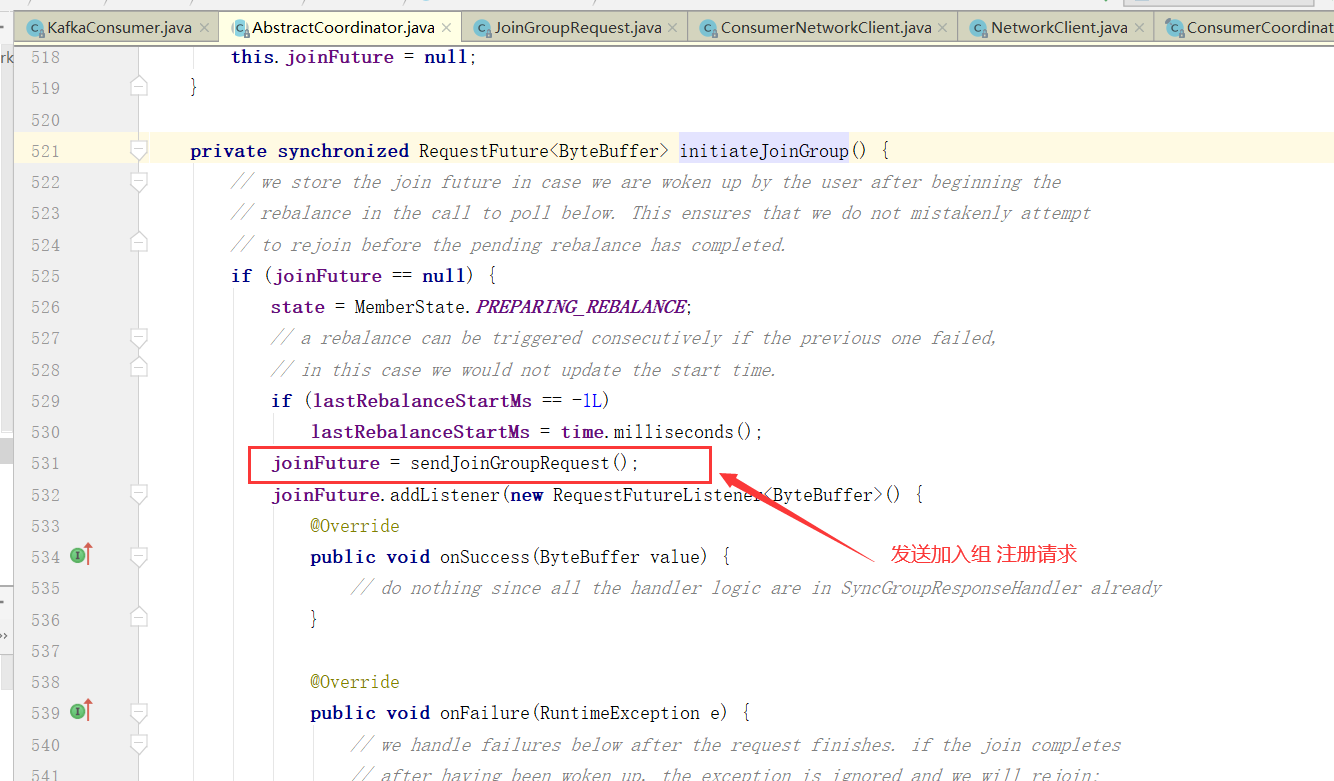
消费者协调器发起入组请求
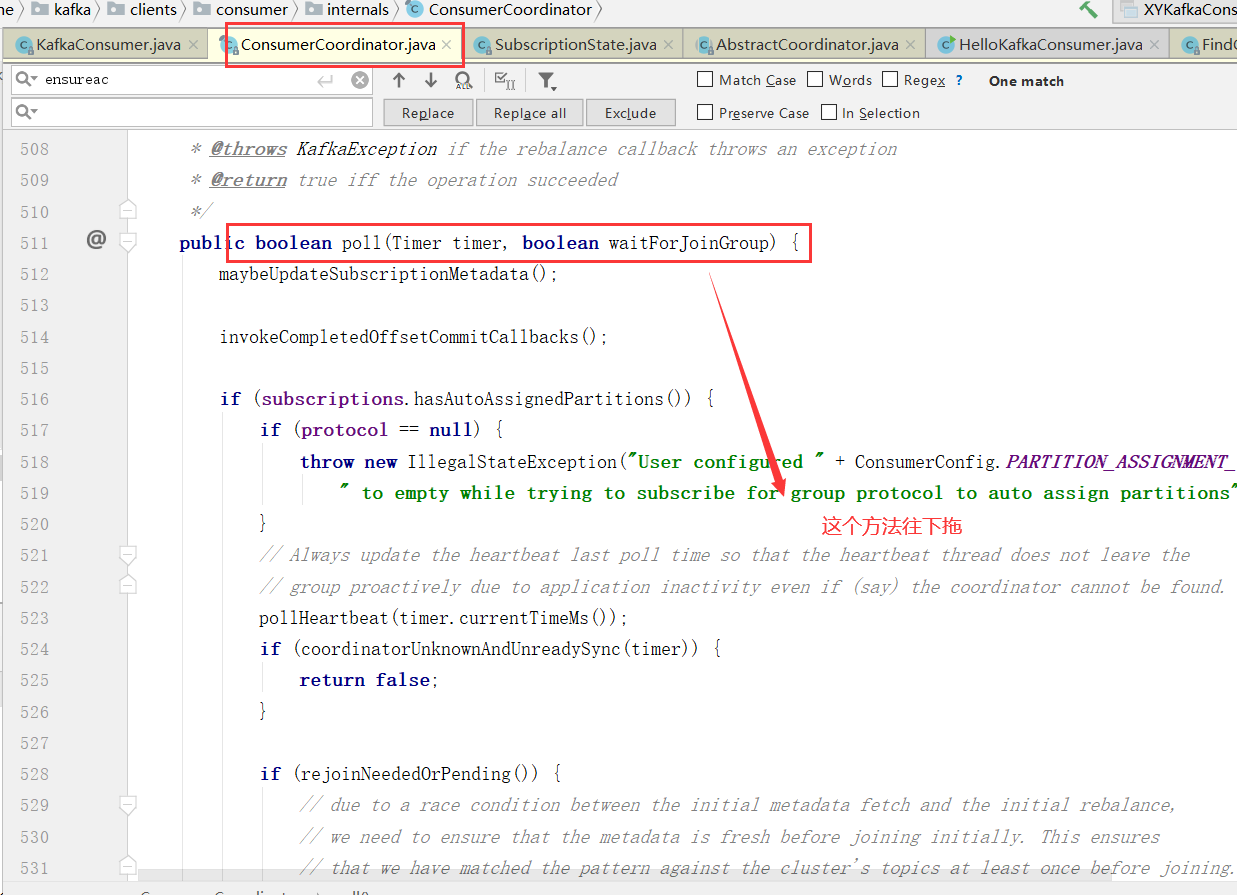

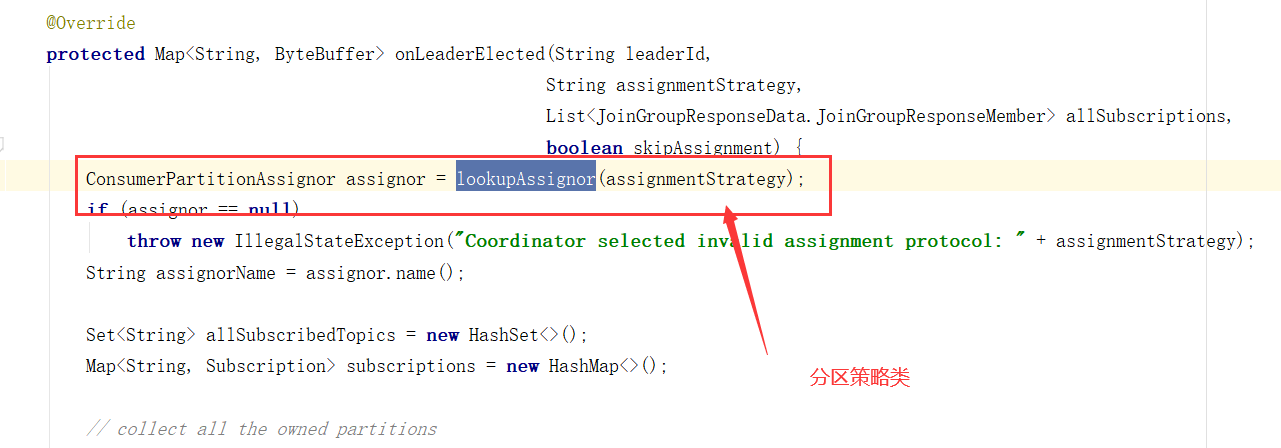
消费者分区策略
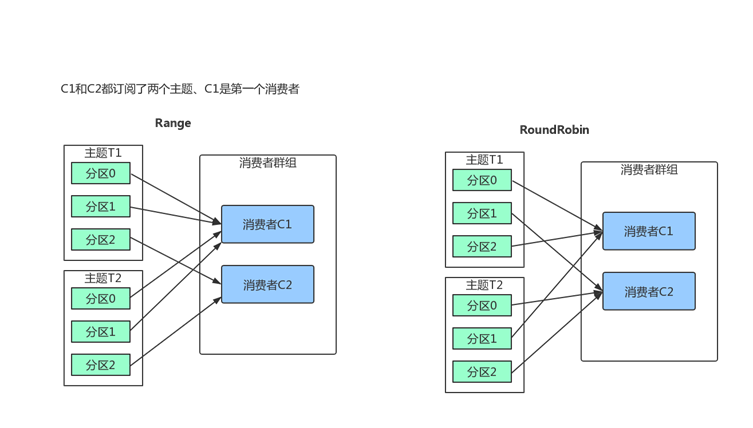
partition.assignment.strategy,分区分配给消费者的策略。默认为Range。允许自定义策略。
Range
把主题的连续分区分配给消费者。(如果分区数量无法被消费者整除、第一个消费者会分到更多分区)
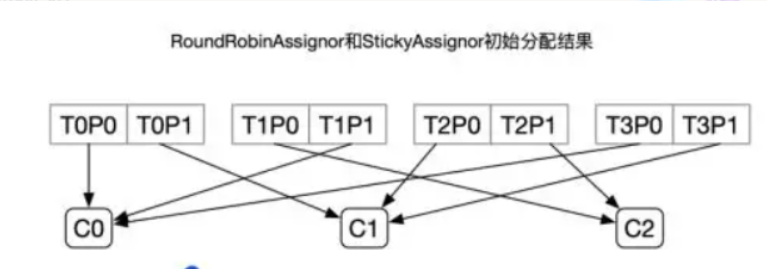
RoundRobin
把主题的分区循环分配给消费者。
StickyAssignor:初始分区,和RoundRobin是一样。每一次分配变更相对上一次分配做最少的变动。
目标:
1、分区的分配尽量的均衡
2、每一次重分配的结果尽量与上一次分配结果保持一致
当这两个目标发生冲突时,优先保证第一个目标
比如有3个消费者(C0、C1、C2)、4个topic(T0、T1、T2、T34),每个topic有2个分区(P1、P2)
自定义策略
extends 类AbstractPartitionAssignor,然后在消费者端增加参数:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,类.class.getName());
分区策略源码分析
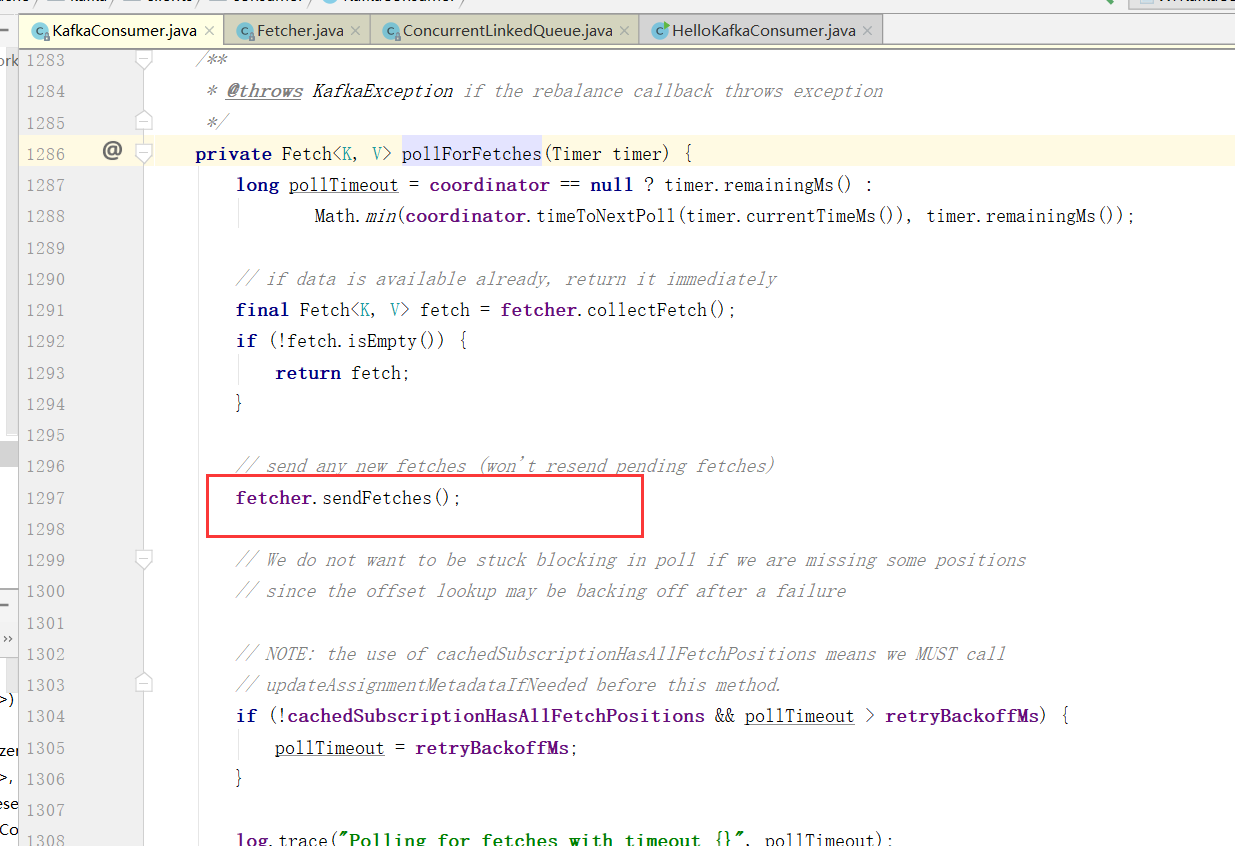
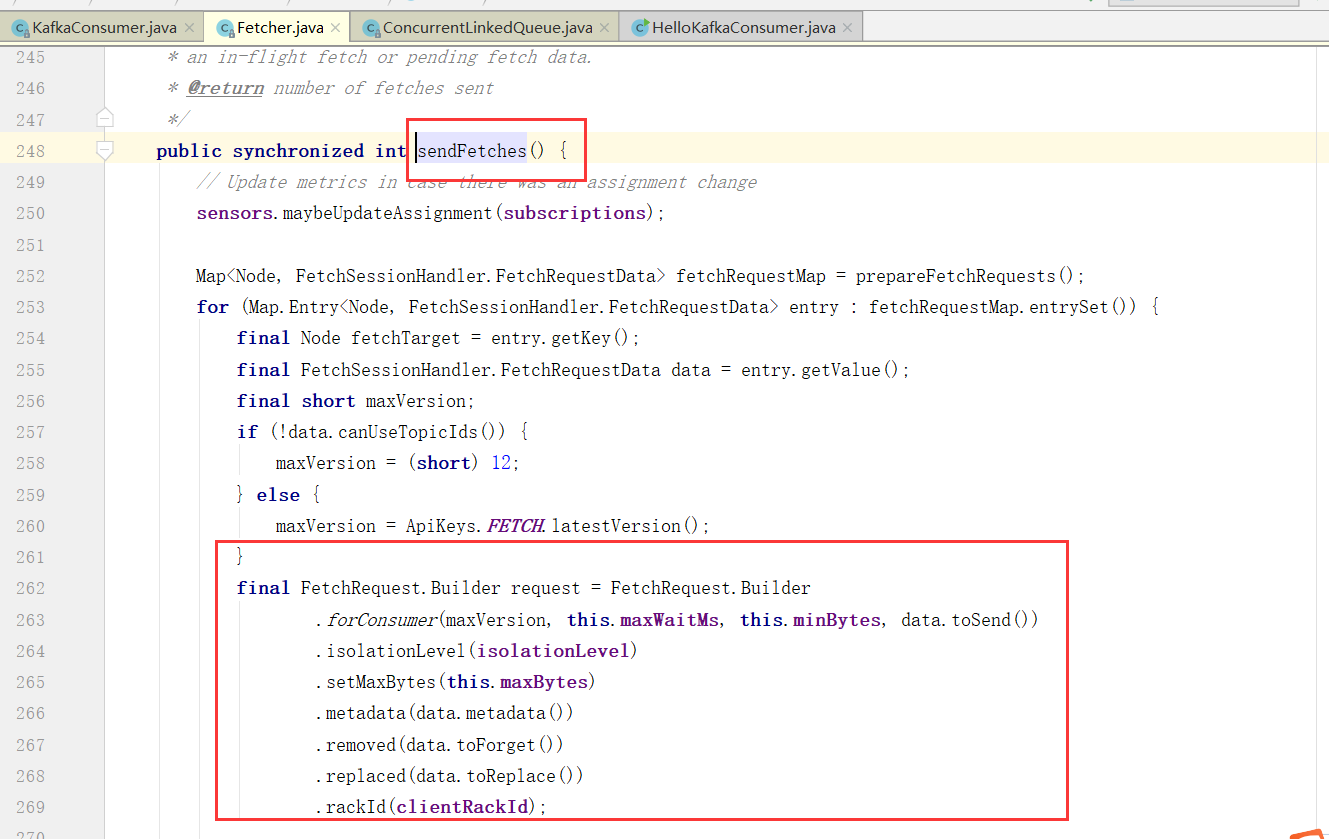
Consumer拉取数据
拉取数据核心Fetch类

提交偏移量
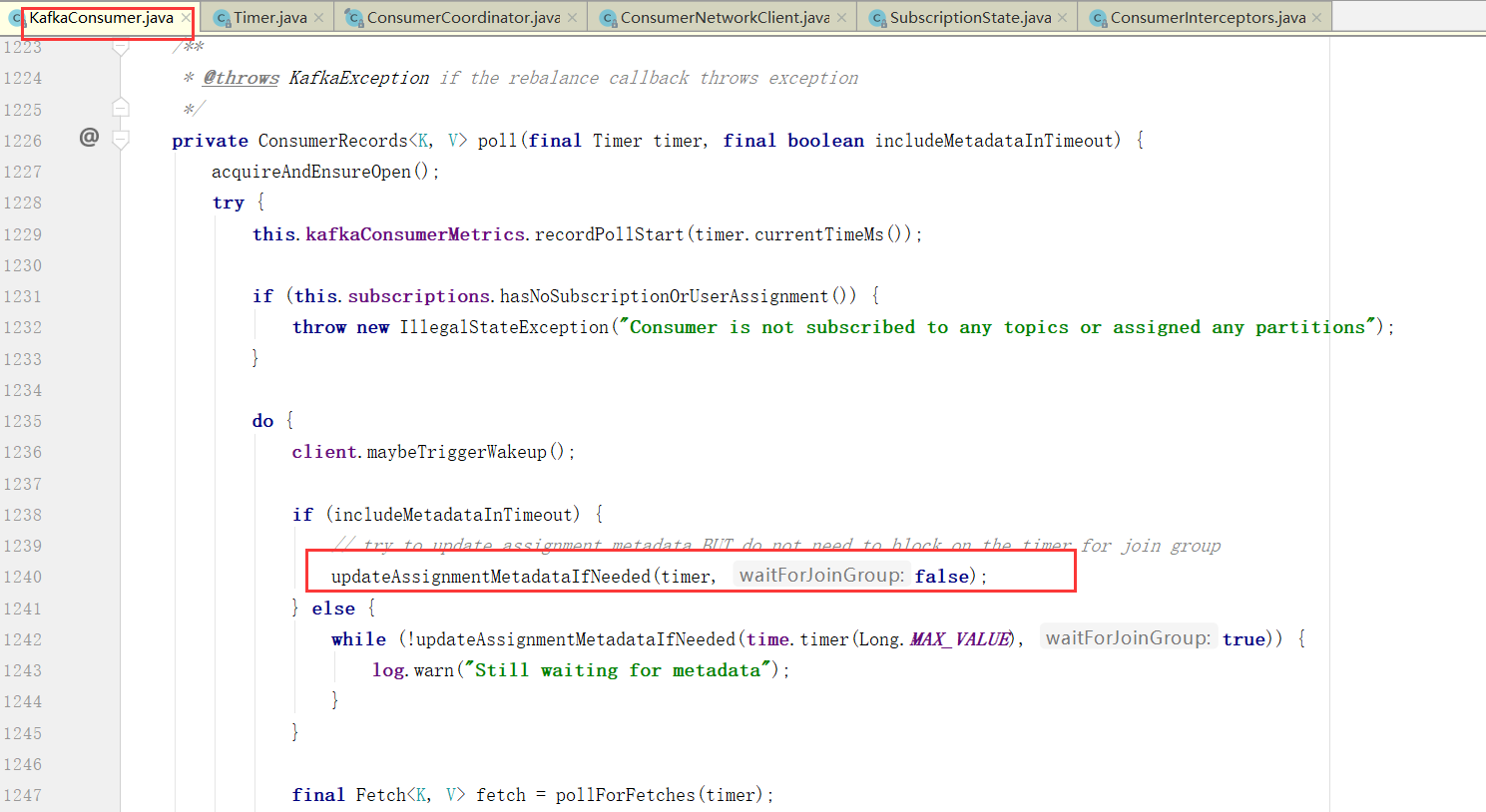

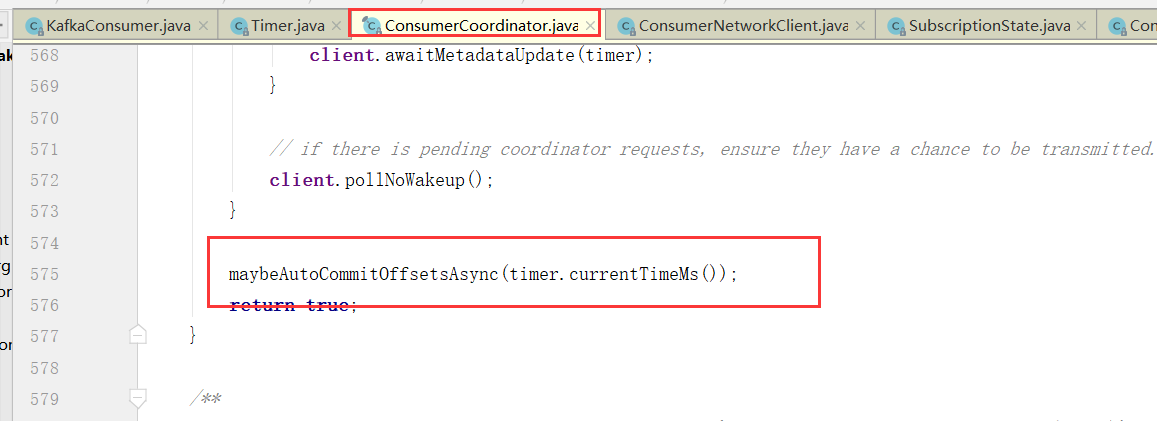
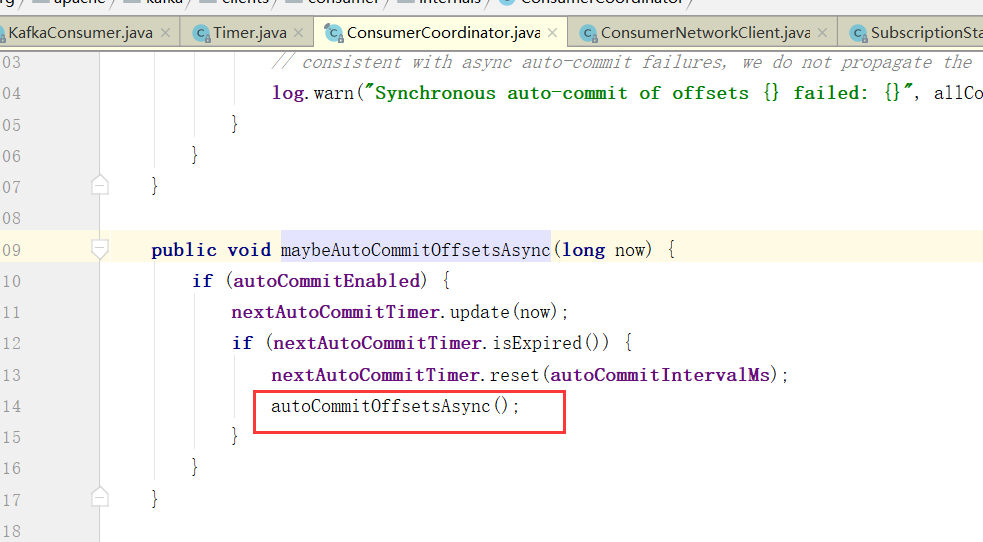
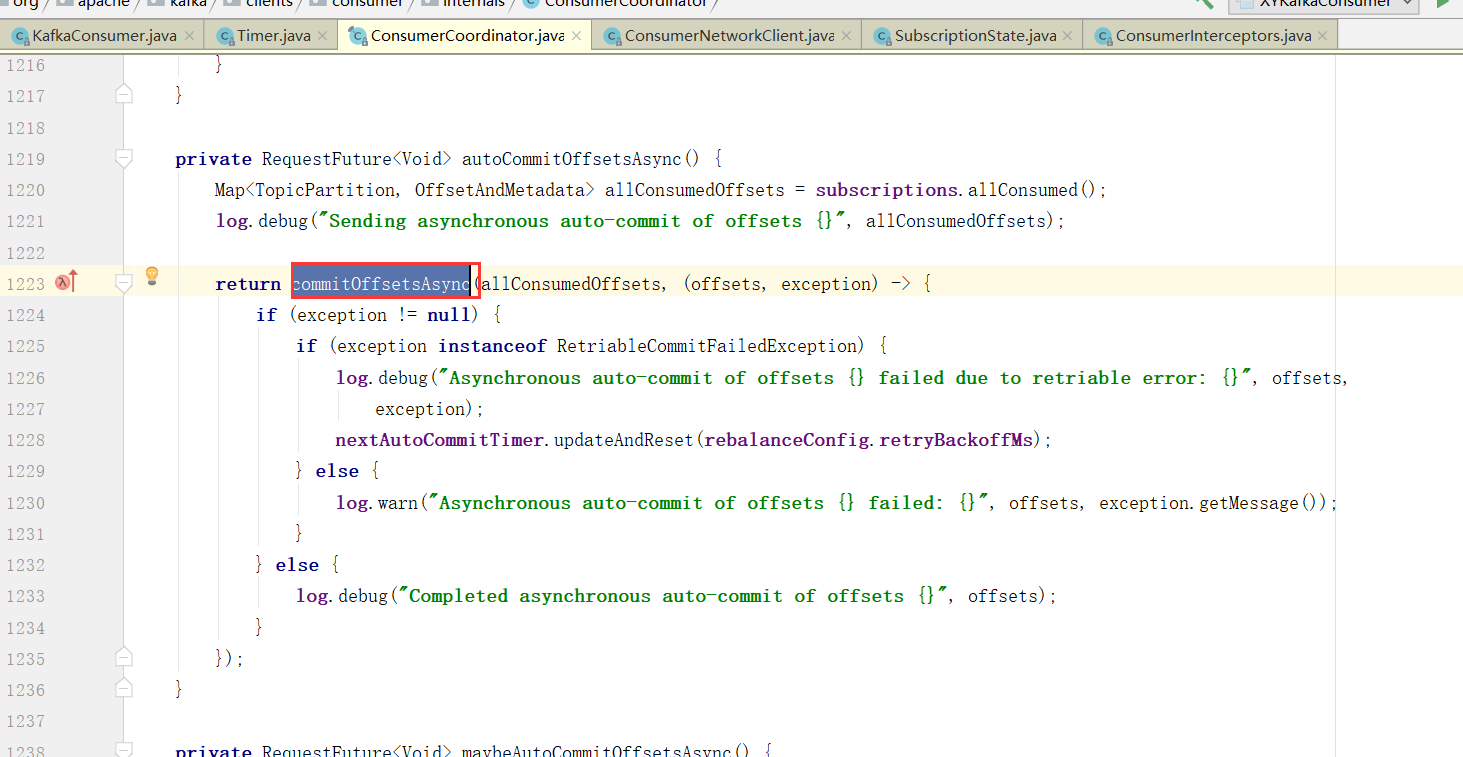
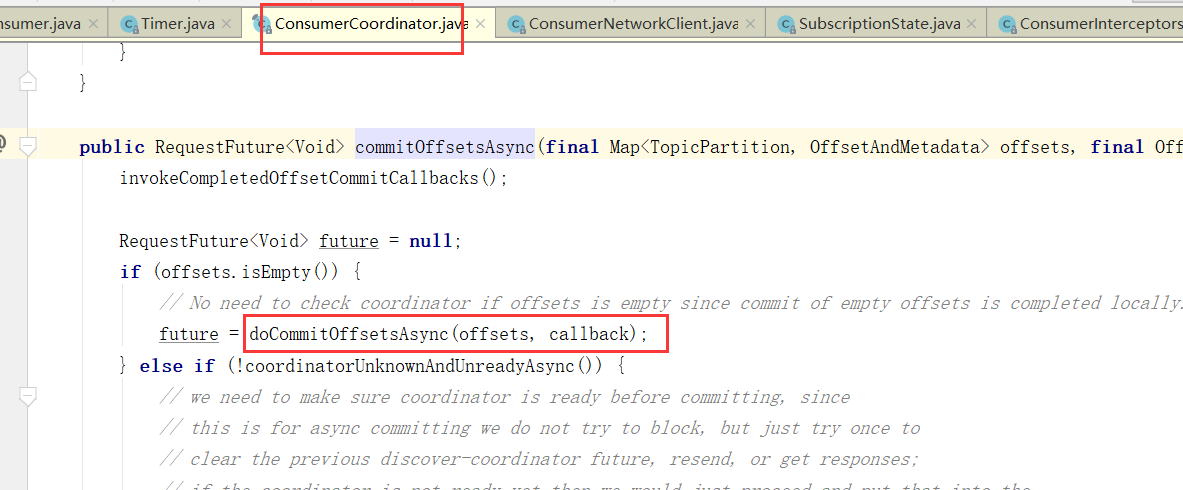
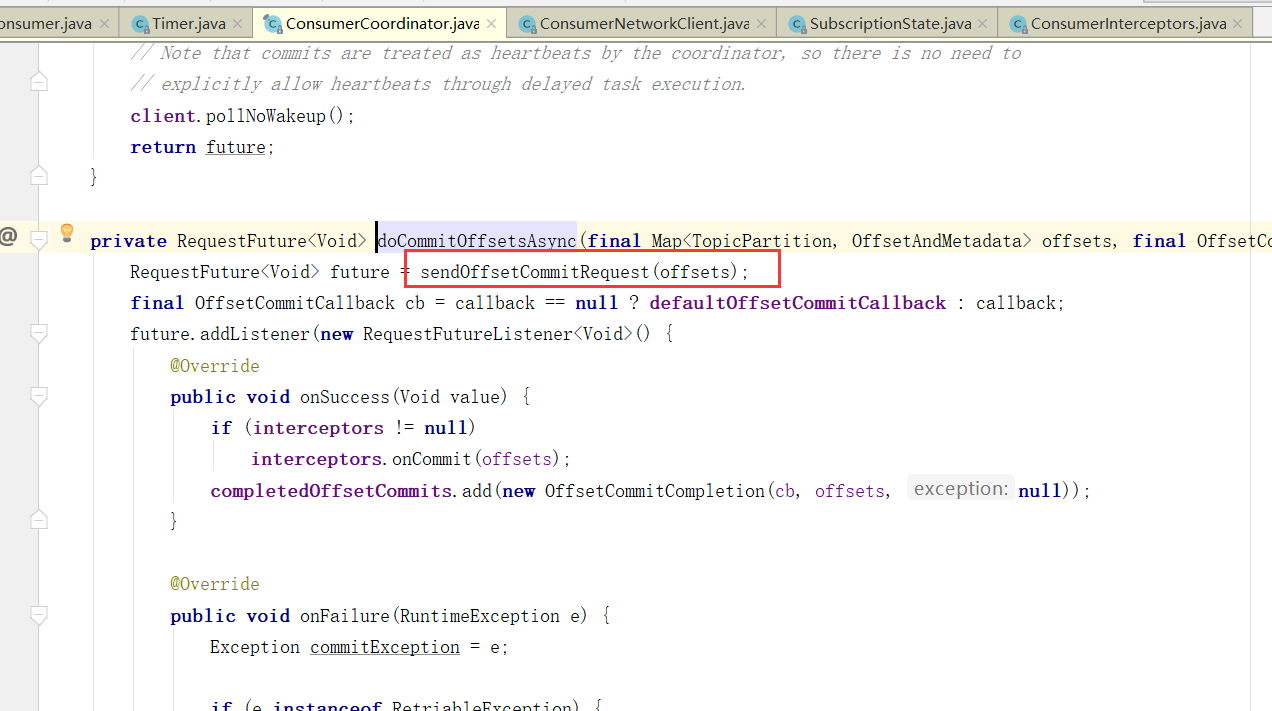

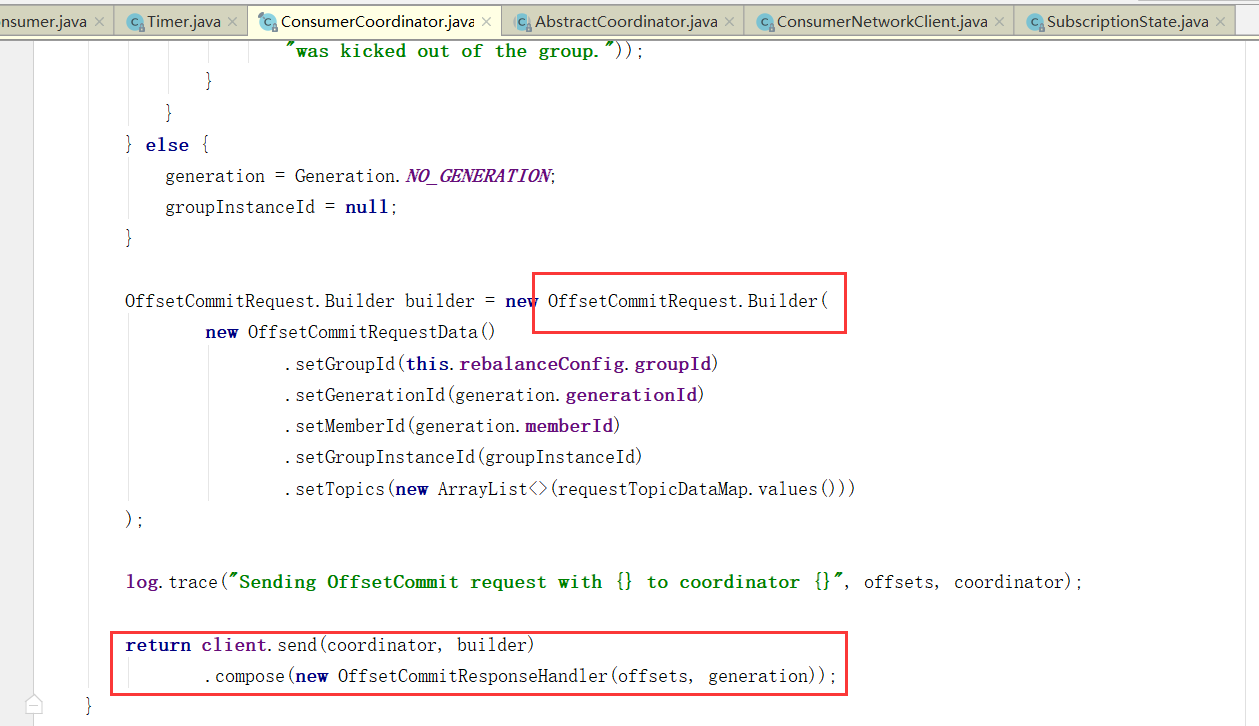
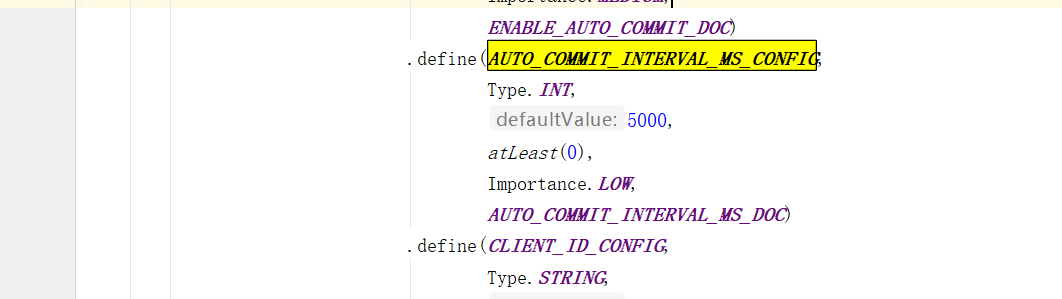
当然,自动提交auto.commit.interval.ms

默认5s
maybeAutoCommitOffsetsAsync 最后这个就是poll的时候会自动提交,而且没到auto.commit.interval.ms间隔时间也不会提交,如果没到下次自动提交的时间也不会提交。