目录
一、下载VMware Wworkstation Pro 16
二、安装VMware Wworkstation Pro 16
三、检查与设置VMware的网卡
1. 检查
2. 设置VMware网段
四、在VMware上安装Linux虚拟机
五、对安装好的虚拟机进行设置
1. 打开设置
2. 设置中文
3. 修改字体大小
4. 修改终端字体大小
5. 关闭虚拟机
六、创建大数据集群
七、对大数据集群进行配置
1. 配置三台虚拟机的主机名
2. 配置固定IP
3. 设置SSH免密登录
4. 创建hadoop用户并设置免密登录
八、对虚拟机完成JDK环境的部署
1. 下载JDK
2. 将下载好的JDK压缩包上传到虚拟机中
九、对虚拟机完成防火墙、SE Linux、时间同步等系统设置
1. 关闭防火墙
2. 关闭SE Linux
3. 修改时区并设置时间同步
4. 拍摄快照保存配置好的虚拟机
一、下载VMware Wworkstation Pro 16
1. 跳转至官网
选择Workstation 16 Pro for Windows进行下载,官网下载速度可能较慢。
2.百度网盘链接 提取码:2233

二、安装VMware Wworkstation Pro 16
1.点击刚才下载好的安装程序,等待一会会出现一下界面:
2.点击下一步,然后同意协议,来到安装位置界面,在这里更改安装位置:
3.用户体验设置界面的两个选项勾不勾都可以,一般不勾
4.快捷方式界面推荐都勾上,然后下一步,选择安装,等待一会后出现以下界面:
到该界面后,如果直接点击完成的话,则是进行试用,适用到期后软件将无法使用;点击许可证,输入密钥则是永久使用,密钥需要到官网购买,请大家支持正版软件,如果只是用于学习,在百度搜索VMware Workstation Pro 16密钥,找一个能用的即可,密钥格式如下:
YF390-0HF8P-M81RQ-2DXQE-M2UT6 (仅用于学习)
5.输入密钥后点击完成,到以下界面再点击完成,即可完成安装。



三、检查与设置VMware的网卡
1. 检查
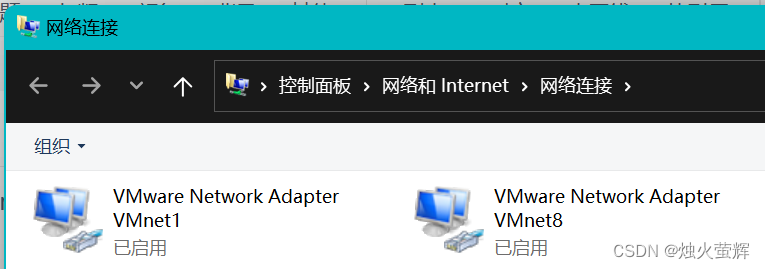
主要是检查是否有VMnet1和VMnet8这两张虚拟网卡,如果没有,那我们的虚拟机将无法上网。
法一:适用Windows11
1. 打开Windows设置
2. 查看网络连接中是否有VMnet1和VMnet8
法二:通用
因为Windows系统各版本的打开方式有区别,下面提供一个通用方法:
1. 快捷键Win + R 打开运行界面,输入ncpa.cpl
2. 查看网络连接中是否有VMnet1和VMnet8
如果没有那就是安装出现了问题,请卸载软件后重新安装。


2. 设置VMware网段
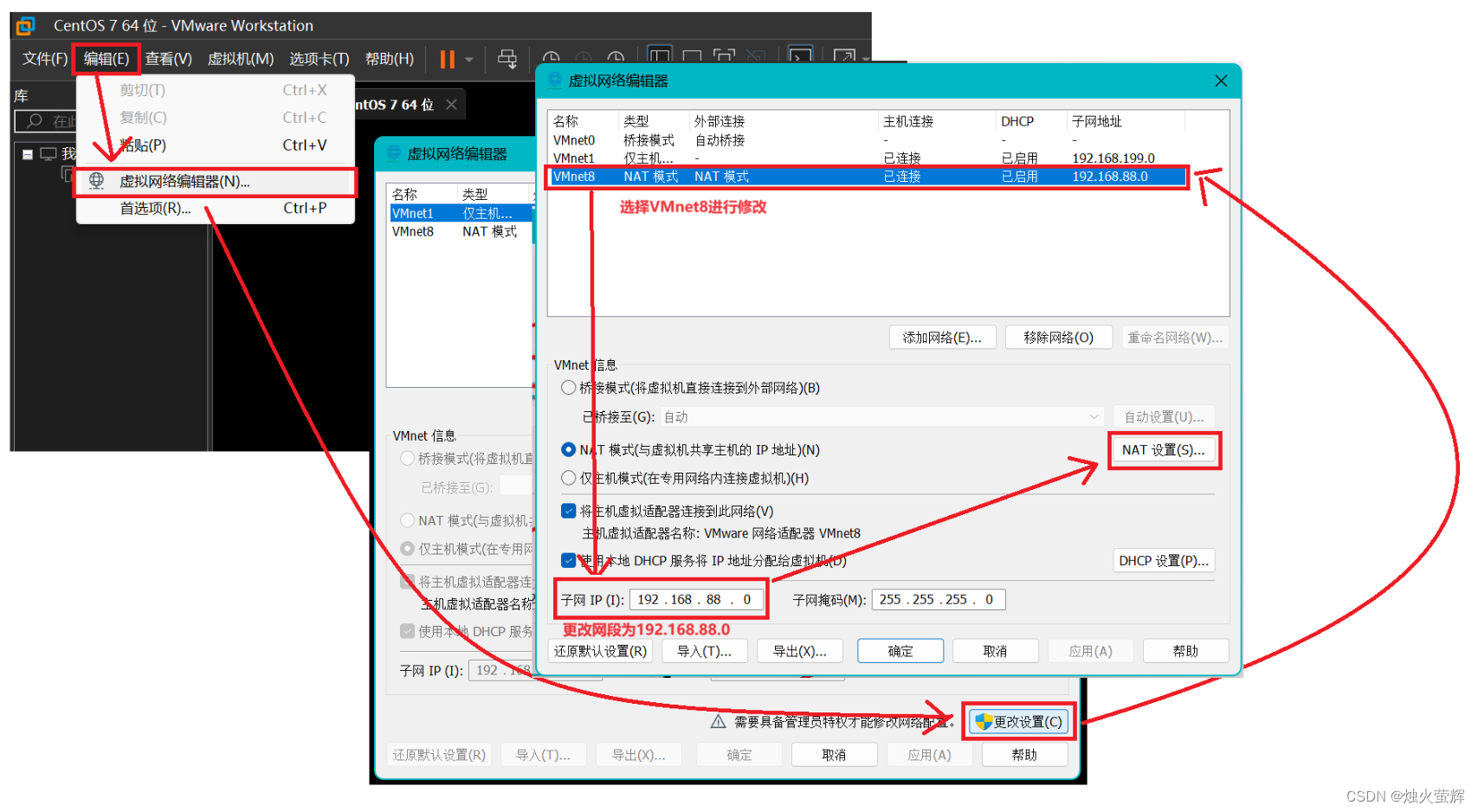
为了方便以后大数据的学习,将VMware网段设置为192.168.88.0,在后续的学习中大数据的集群网络就设置为192.168.88.0的网段,同时设置整个虚拟机的网关为192.168.88.2,这样未来就不用频繁的修改适配了,能减少很多麻烦。
2.1 打开虚拟网络编辑器对VMnet8进行修改,将网段设置为192.168.88.0
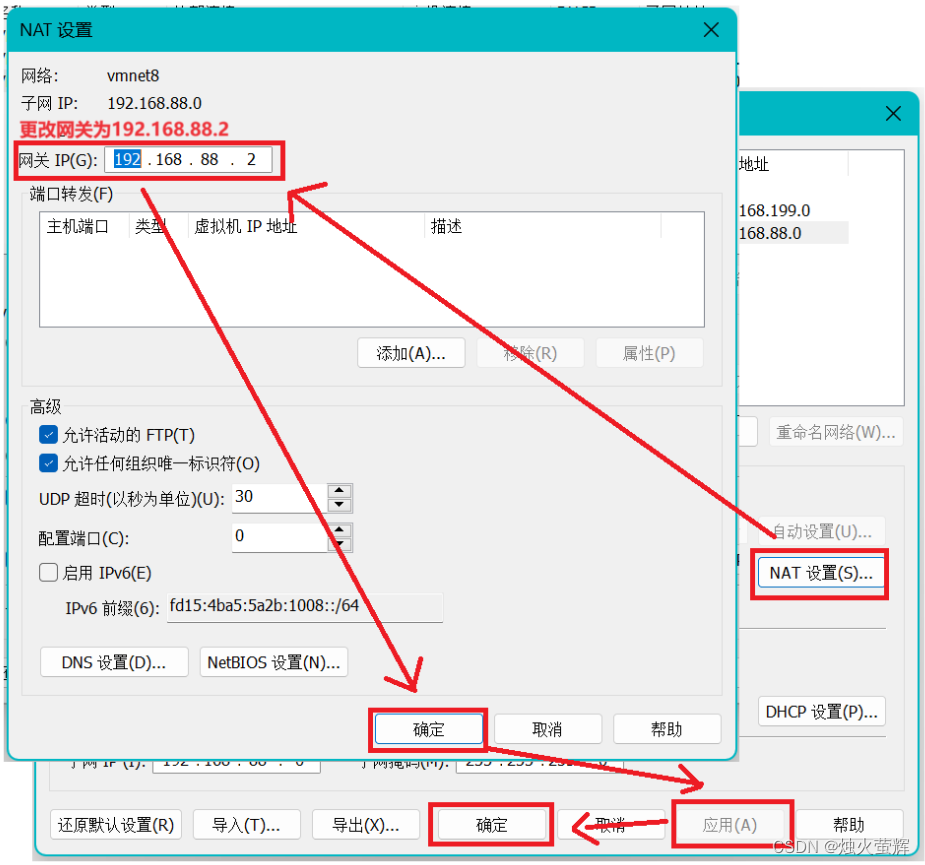
2.2 修改net设置中的网关为192.168.88.2 ,修改完点击确定,进行应用即可。
四、在VMware上安装Linux虚拟机
1. 下载CentOS或Ubuntu操作系统
1.1 下载CentOS操作系统
选择CentOS7.6版本下载:
1.2 百度网盘链接 提取码:2233
1.3 跳转下载ubuntu

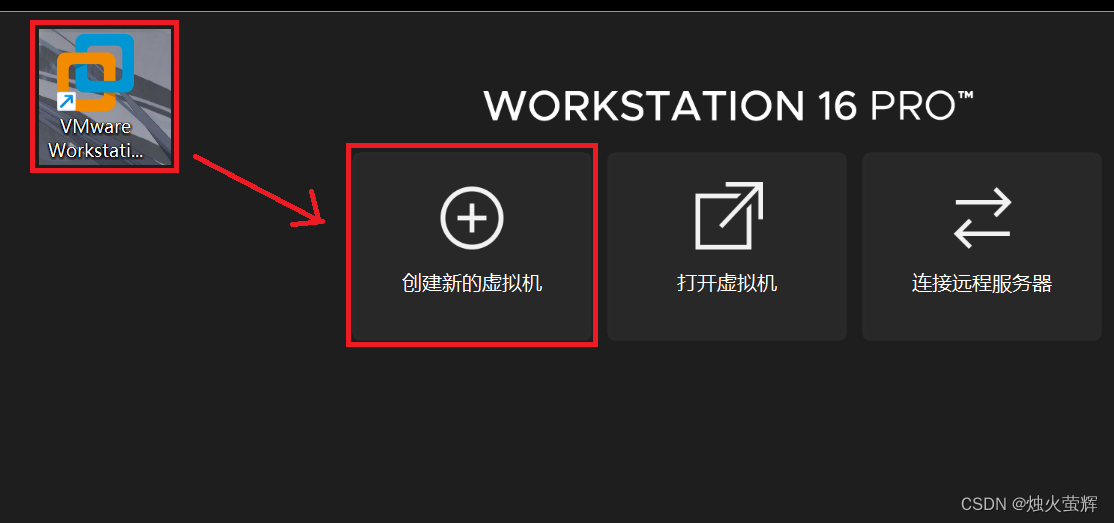
2. 打开刚才安装好的VMware,选择创建新的虚拟机
3.进入向导界面选择典型(操作更简单)
4.选择安装程序光盘映像文件,选择浏览找到刚才下载好的CentOS

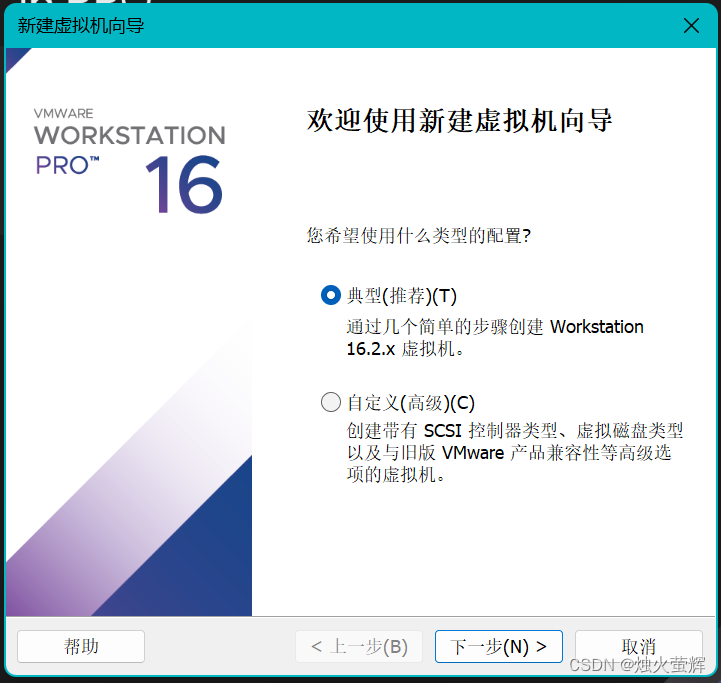
5. 为该系统创建一个用户
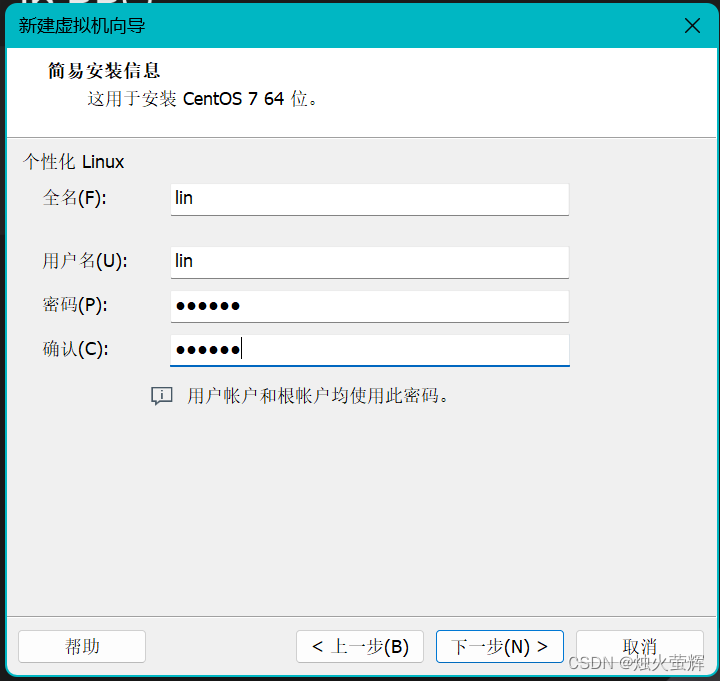
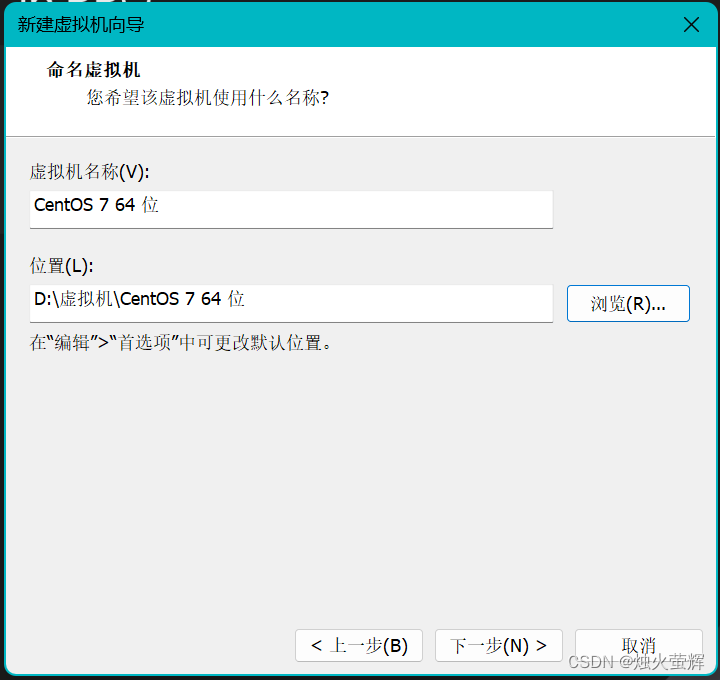
6. 设置虚拟机的名称和位置(点击浏览选择安装位置)
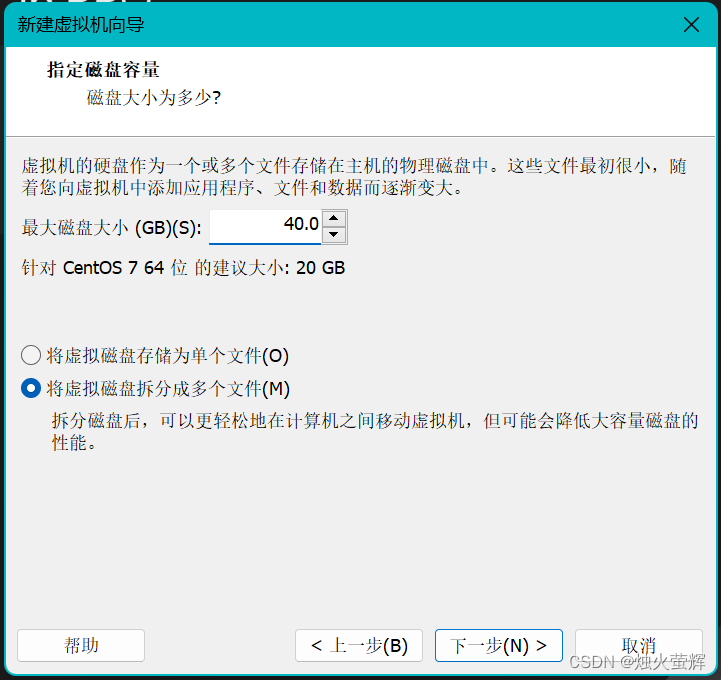
7.设置虚拟机硬盘大小,为了避免影响后续使用,建议设为40GB。
8. 检查虚拟机配置信息,选择创建后打开,完成
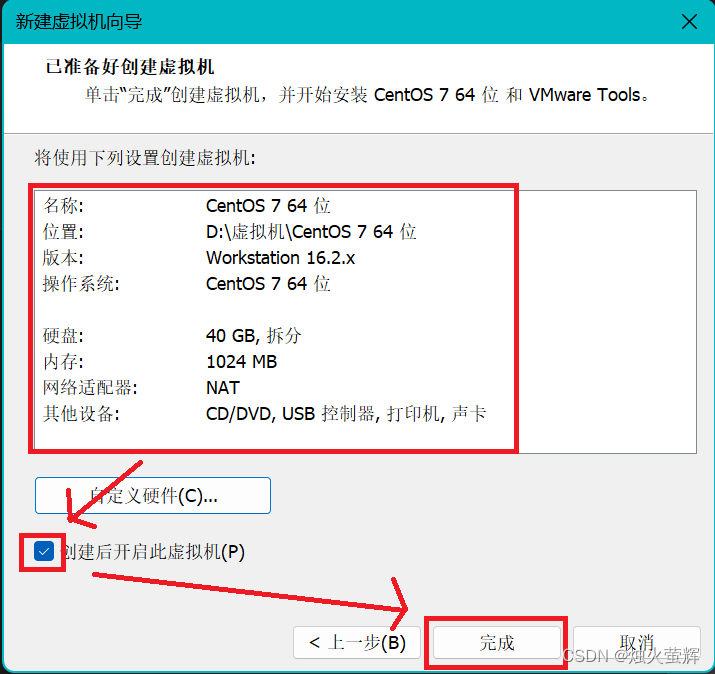
9. 选择刚才创建好的虚拟机,如果没有自动开机点击开机
10. 开机后用之前的用户登录
第一次开机需要安装虚拟机,这个过程大概要10分钟左右,开机成功后选择之前创建的账户,填写好密码就能成功进入虚拟机的操作系统界面中了。
10.1 选择用户和填写用户密码
10.2 成功进入虚拟机的操作系统界面

五、对安装好的虚拟机进行设置
1. 打开设置
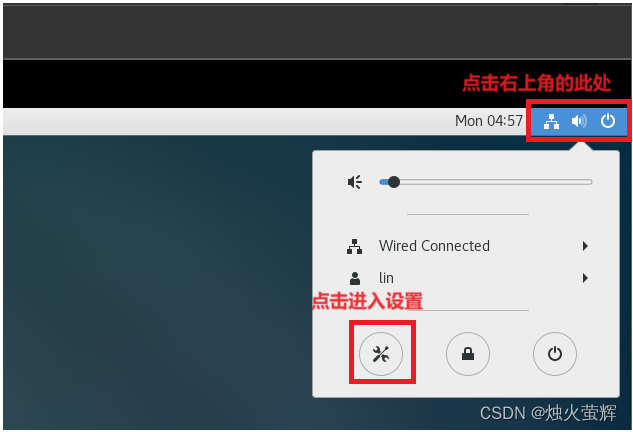
2. 设置中文
进入设置后,选择 Region & Language 设置语言。
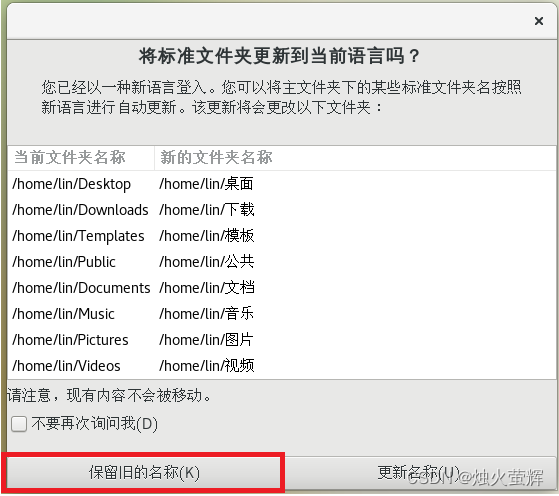
重启后语言就会变为中文,此时会询问你是否修改文件名,选择不修改 ,不建议修改文件名为中文。

3. 修改字体大小

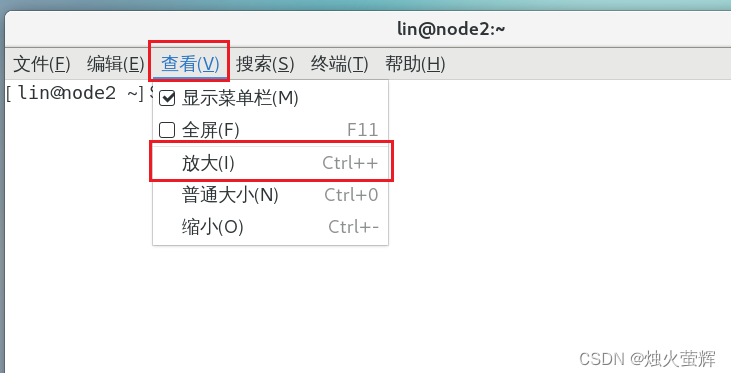
4. 修改终端字体大小
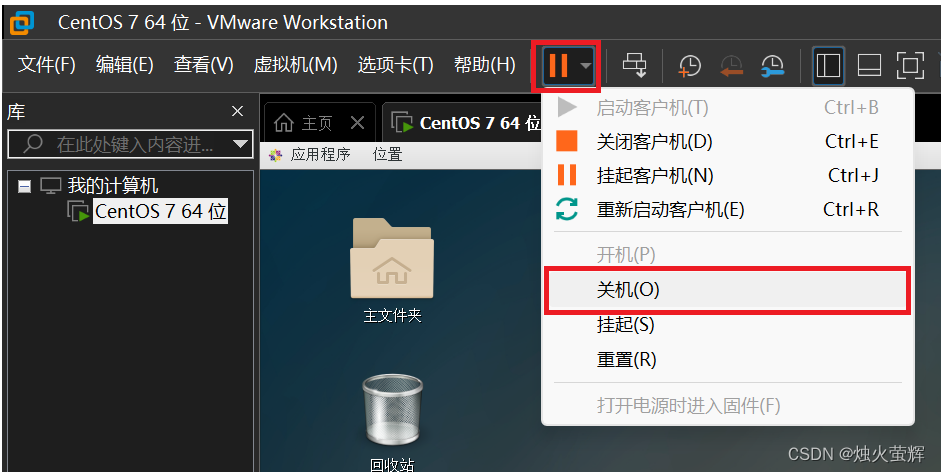
5. 关闭虚拟机
六、创建大数据集群
0. 关闭刚才创建好的虚拟机

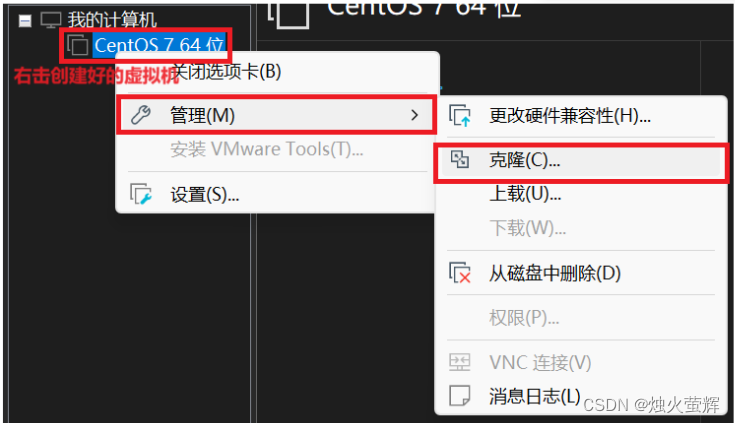
1. 右击虚拟机,选择管理,选择克隆
2. 不断点击下一页,到以下页面后,选择创建完整克隆
因为我们要的是完整的服务器,而不是一个链接,所以选择完整克隆。
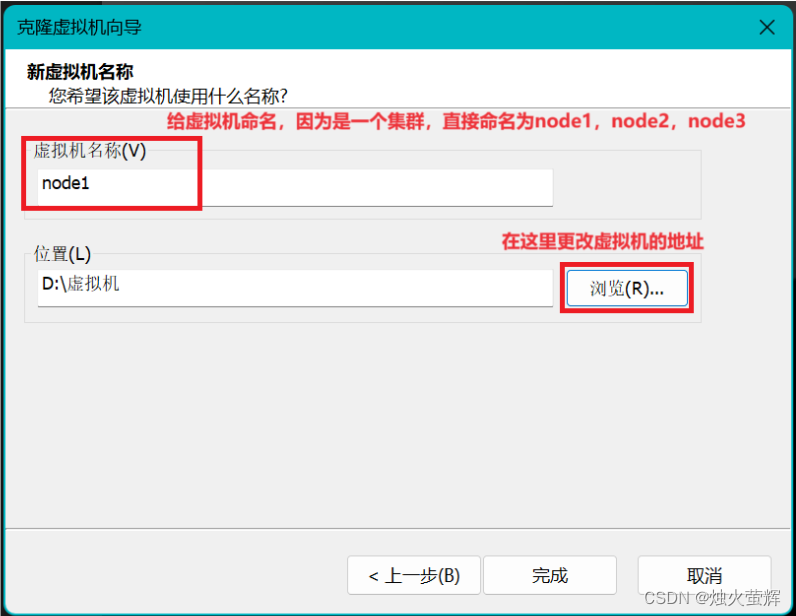
3. 点击下一页,修改虚拟机的名称和虚拟机的存放地址
4. 点击完成,成功后出现以下界面

5.同样的操作,克隆出node2和node3

6. 右击我的计算机,选择新建文件夹,创建大数据集群文件夹,然后将node1\2\3拖入其中。

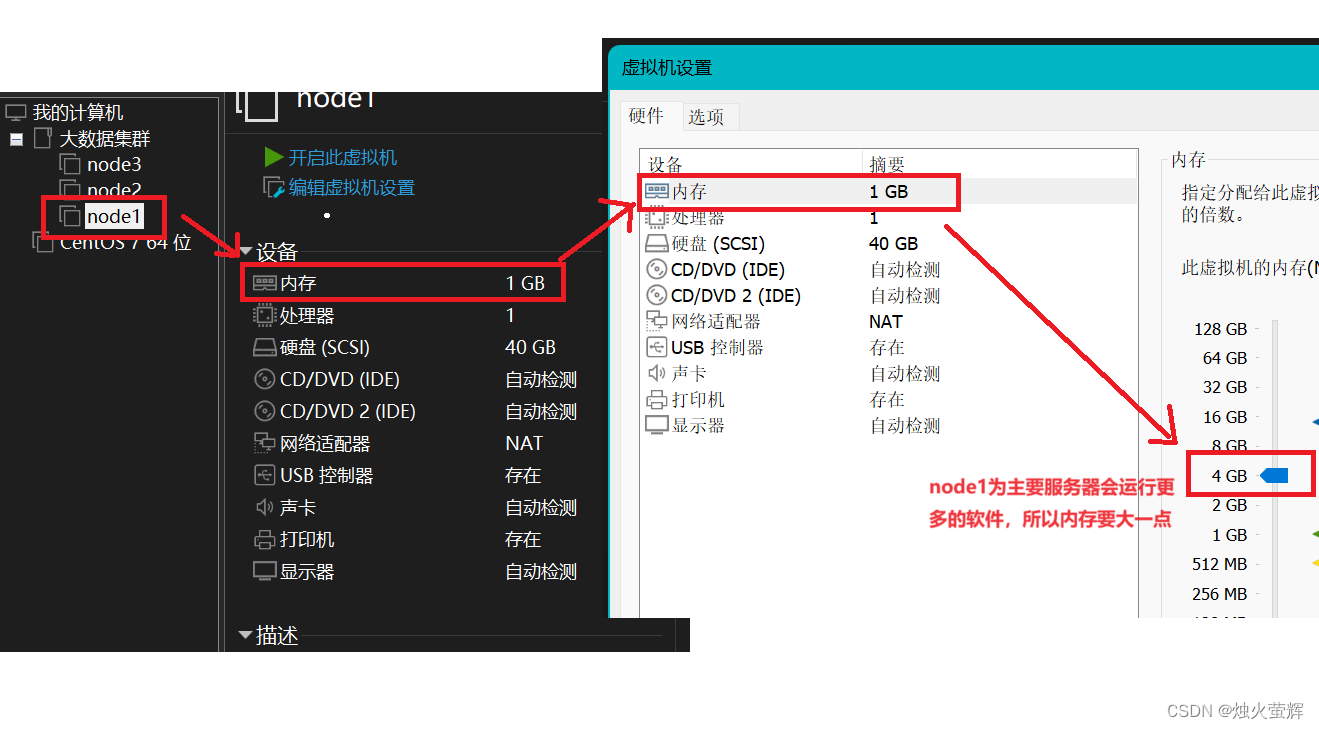
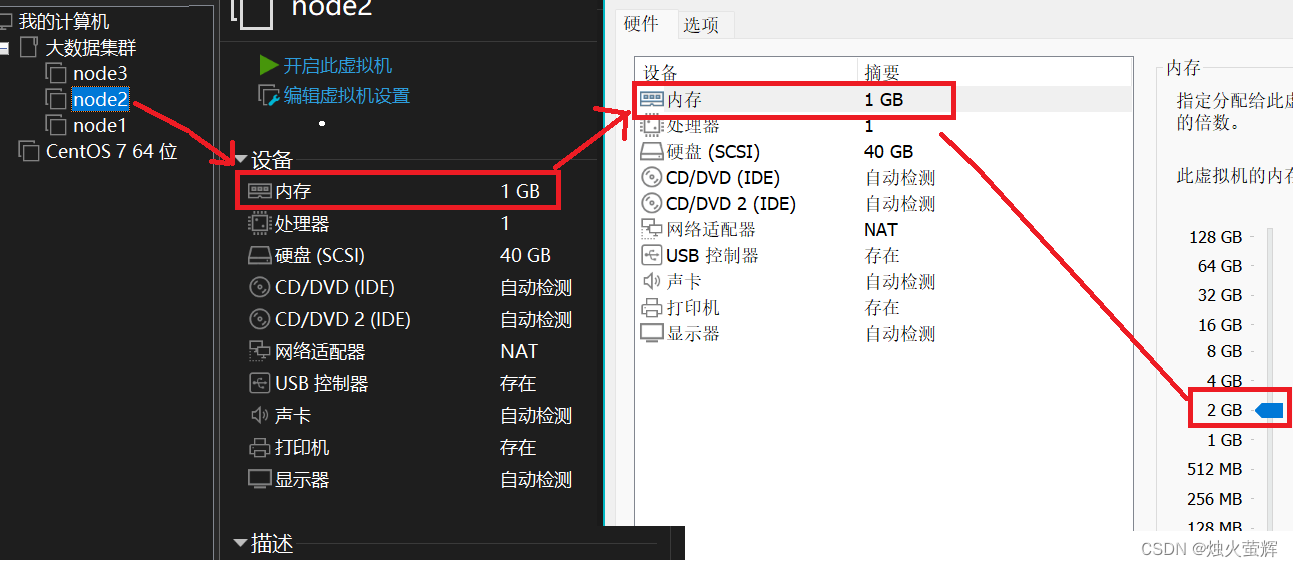
7. 设置node1\2\3的内存
以下内存配置只是推荐,要求电脑至少有16GB内存,如果没有,具体内存分配请根据自己的电脑配置设置(如8GB设置为2/1/1)。
node1为主要服务器会运行更多的软件,将其内存设置为4GB
重复上面的步骤设置node2\3的内存为2GB
七、对大数据集群进行配置
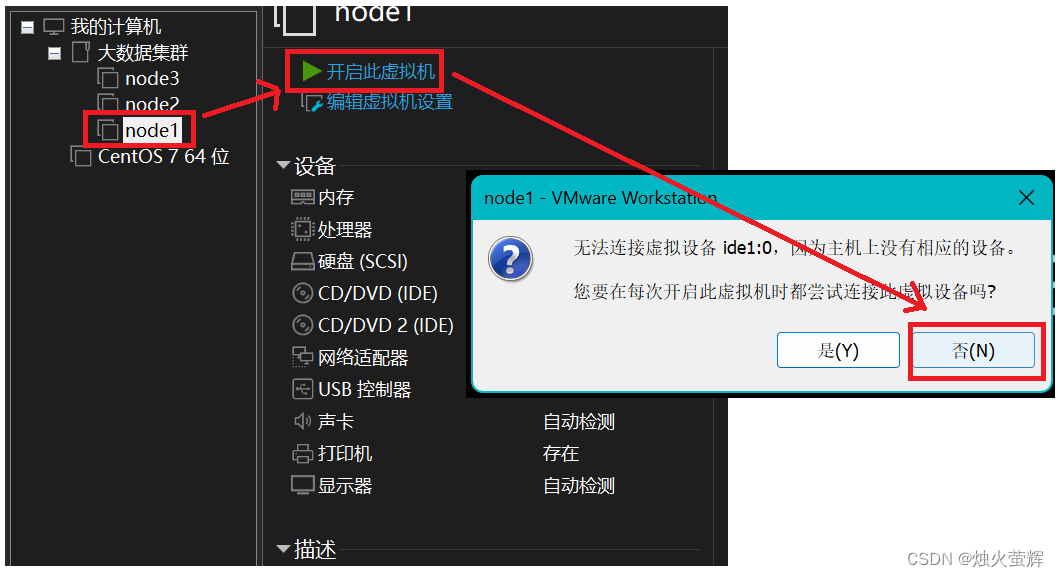
0. 将三台虚拟机开机并登录
选择之前创建的用户和填写用户密码
1. 配置三台虚拟机的主机名
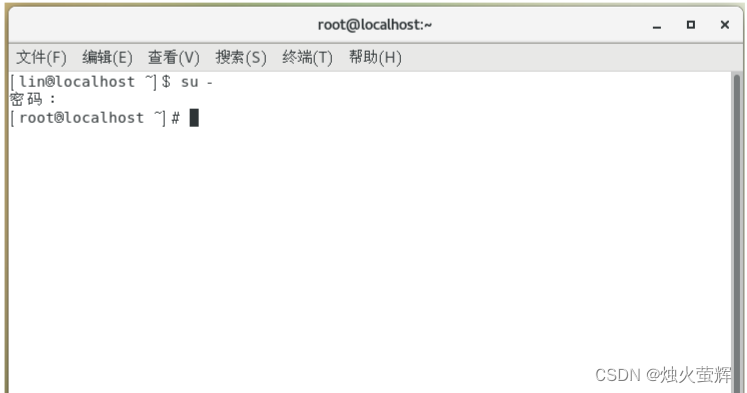
1.1右击桌面,打开终端。
1.2 在终端里输入 su - ,再输入当前用户密码切换到超级用户root
只有超级用户root才有权限修改主机名。
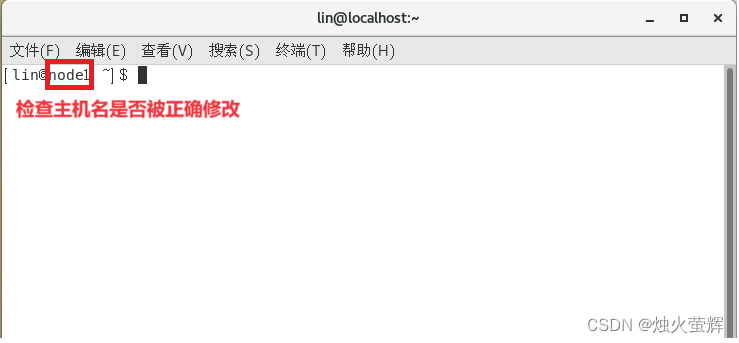
1.3 在终端输入 hostnamectl set-hostname node1 修改主机名
1.4 关闭后重新打开终端,检查主机名是否被正确修改
1.5 重复上述步骤将虚拟机node2\3的主机名设置为node2 和 node3


2. 配置固定IP
2.0 以超级用户身份打开配置文件
- 先使用命令su - 切换为超级用户root
- 然后在终端下输入指令 vim /etc/sysconfig/network-scripts/ifcfg-ens33 打开配置文件
- 按i进入插入模式,对文件进行修改
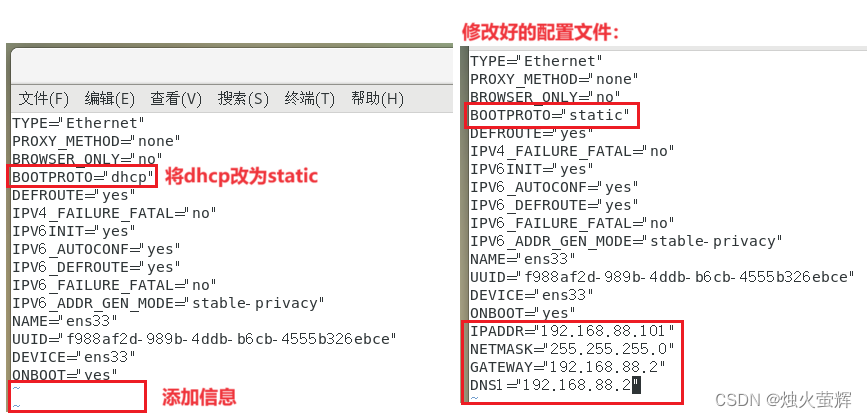
2.1 修改配置文件
- 将BOOTPROTO="dhcp"改为BOOTPROTO="static" (将协议由自动获取IP变更为固定不变)
- 在末尾添加 IPADDR="192.168.88.101"(固定后要设置IP地址,node1为192.168.88.101,node2为192.168.88.102,node3为192.168.88.103)
- 在末尾添加 NETMASK="255.255.255.0" (设置子网掩码)
- 在末尾添加 GATEWAY="192.168.88.2" (设置网关)
- 在末尾添加 DNS1="192.168.88.2"(设置DNS服务器,一般和网关一样)
2.2 保存并退出
- 按下Esc退出编辑模式
- 按下Shift + : 进入底行模式
- 输入wq! 强制保存并退出。
2.3 重启网卡
在终端输入 systemctl restart network 重启网卡
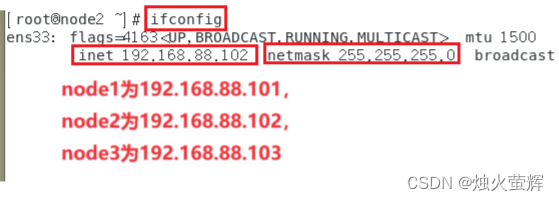
2.4 检查是否配置成功
在终端输入 ifconfig 检查inet、netmask是否配置成功
确认以上步骤都做了,但是ifconfig后没有ens33,建议执行以下操作:
systemctl stop NetworkManager--临时关闭 systemctl disable NetworkManager --永久关闭网络管理命令 systemctl start network.service --开启网络服务
2.5 在虚拟机node2和node3下进行如上操作
但要注意在修改配置文件时:在末尾添加 IPADDR="192.168.88.101"(node1为192.168.88.101,node2为192.168.88.102,node3为192.168.88.103)
2.6 配置主机名映射
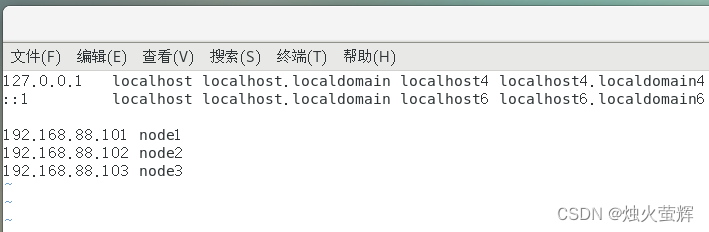
2.6.1 在Windows系统中修改hosts文件,在文件末尾加上:
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3步骤:
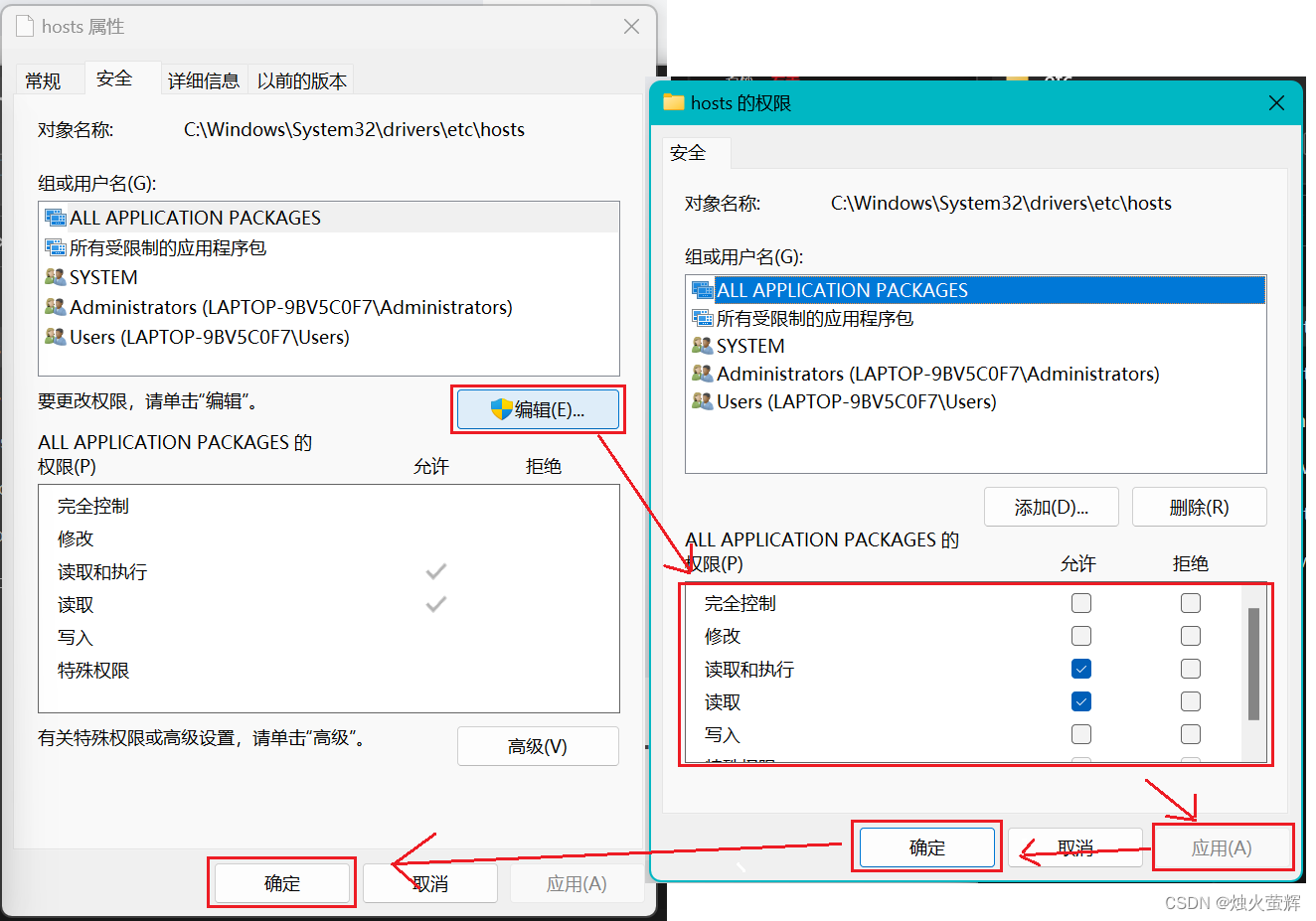
a. 找到C盘下的hosts文件:C:\Windows\System32\drivers\etc,右击修改属性
b. 修改hosts文件权限为可写入
c. 修改hosts文件,加上配置信息
d. 将hosts文件权限改回
2.6.2 在虚拟机中修改/etc/hosts 文件,在文件末尾加上:
192.168.88.101 node1
192.168.88.102 node2
192.168.88.103 node3步骤:
a. 在终端下输入指令 vim /etc/hosts 打开配置文件
b. 修改配置文件
按i进入插入模式,在文件末尾加上:
192.168.88.101 node1
c. 保存并退出
192.168.88.102 node2
192.168.88.103 node3
- 按下Esc退出编辑模式
- 按下Shift + : 进入底行模式
- 输入wq! 强制保存并退出。
d. 输入指令 vim /etc/hosts 再次打开配置文件,检查是否配置成功.
配置成功,如下图:
e. 对虚拟机node2\3 进行相同操作



3. 设置SSH免密登录
由于是一个集群,未来需要在多个服务器之间跳转,为了方便起见最好配置一下ssh免密登录。
3.1 生成SSH密钥
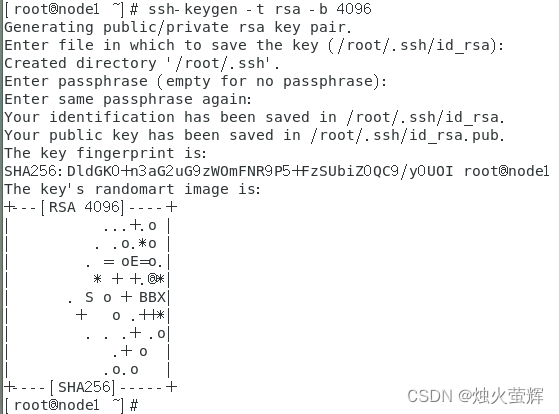
在每台虚拟机的终端输入以下命令:ssh-keygen -t rsa -b 4096 ,然后一路回车即可。
3.2 授权免密登录
在每台虚拟机上执行以下步骤:
a. 在终端输入命令:ssh-copy-id node1 输入yes 输入用户密码
b. 在终端输入命令:ssh-copy-id node2 输入yes 输入用户密码
b. 在终端输入命令:ssh-copy-id node3 输入yes 输入用户密码
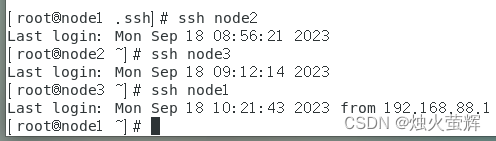
e. 检查是否成功免密登录
在虚拟机node1的终端输入 ssh node2 或 ssh node3 看看能否跳转成功。

4. 创建hadoop用户并设置免密登录
为保证安全性(防止误操作对系统造成严重破坏),后续的大数据软件,不会再以root用户启动。为大数据集群创建一个单独的用户hadoop,并为集群上的服务器配置hadoop用户的免密登录。
4.1 在每一台机器执行: useradd hadoop,创建hadoop用户
4.2 在每一台机器执行: passwd hadoop,设置hadoop用户密码为123456
4.3 在每一台机器均切换到hadoop用户: su - hadoop ,并执行 ssh-keygen -t rsa -b 4096 ,一路回车,创建ssh密钥
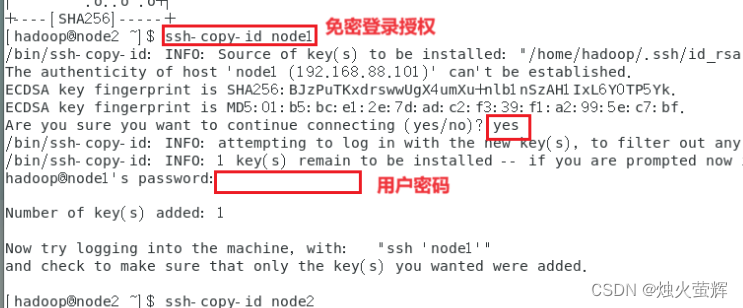
4.4 在每一台机器均执行以下命令,授权免密登录:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3

八、对虚拟机完成JDK环境的部署
JDK就是Java语言的开发环境,很多大数据软件都需要Java环境的支持,所以要预先部署好JDK。
1. 下载JDK
1.1 官网下载跳转
1.2 百度网盘链接 提取码:2233

2. 将下载好的JDK压缩包上传到虚拟机中
2.1 先关闭三台虚拟机的防火墙
在终端执行以下指令: 关闭防火墙: systemctl stop firewalld关闭防火墙自启: systemctl disable firewalld
2.2 然后安装一个远程管理软件,如Xshell、Finalshell,以root身份登录。
2.3 创建文件夹/export/server,将JDK安装部署到该文件夹中
mkdir -p /export/server
2.4 进入到刚才创建的目录中
cd /export/server
2.5 使用rz命令上传下载好的JDK压缩包(或直接将本地文件拖拽进来)
2.6 解压缩
tar -zxvf jdk-8u361-linux-x64.tar.gz
2.7 删除压缩包
rm -rf jdk-8u361-linux-x64.tar.gz
2.8 配置JDK的软链接
ln -s /export/server/jdk1.8.0_361 jdk
2.9 配置JAVA_HOME环境变量,以及将$JAVA_HOME/bin文件夹加入到PATH环境变量中
a. 使用命令 vim /etc/profile 打开profile文件b. 按i进入插入模式,在文件末尾加上: export JAVA_HOME=/export/server/jdk export PATH=$PATH:$JAVA_HOME/binc. 按下Esc退出插入模式,按下Shift+:进入底行模式,输入wq!,强制保存并退出。
2.10 生效环境变量
source /etc/profile
2.11 配置java执行程序的软链接
a. 先删除系统自带的java程序 rm -f /usr/bin/javab. 软链接我们自己安装的java程序 ln -s /export/server/jdk/bin/java /usr/bin/java
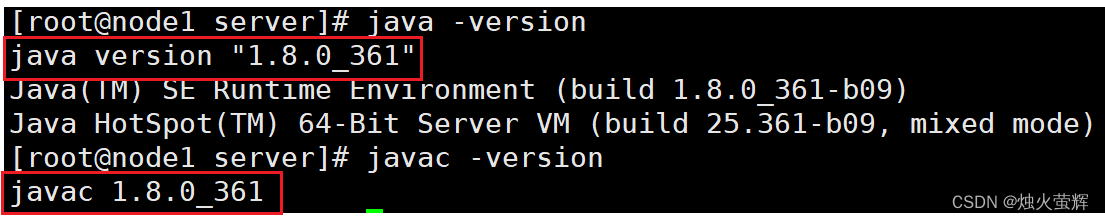
2.12 检查是否配置成功
查看java版本: java -version javac -version

九、对虚拟机完成防火墙、SE Linux、时间同步等系统设置
1. 关闭防火墙
以下操作在三台虚拟机里都要执行:
1.1 为什么要关闭防火墙?
如果不关闭防火墙,我们无法远程连接虚拟机,且集群内的虚拟机无法通过端口互相通讯。
1.2 怎么关闭防火墙?
关闭防火墙: systemctl stop firewalld关闭防火墙自启: systemctl disable firewalld
2. 关闭SE Linux
以下操作在三台虚拟机里都要执行:
2.1 为什么要关闭SE Linux?
SELinux会限制用户和程序的相关权限,会影响我们后续运行大数据程序,所以提前关闭。
2.2 怎么关闭
a.在终端输入指令,打开selinux文件: vim /etc/sysconfig/selinuxb.将第七行的 SELINUX=enforcing 改为 SELINUX=disabled (检查一遍,一定不能出错否则无法启动系统。)c.重启虚拟机 init 6
3. 修改时区并设置时间同步
以下操作在三台虚拟机里都要执行:
1. 安装ntp软件
yum install -y ntp
2. 更新时区
删除原来的时区: rm -f /etc/localtime;设置时区为上海: sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3. 同步时间
联网访问阿里云,校准时间 ntpdate -u ntp.aliyun.com
4. 开启ntp服务并设置开机自启
启动ntpd systemctl start ntpd;将ntpd加入开机自启 systemctl enable ntpd
4. 拍摄快照保存配置好的虚拟机
4.0 为什么需要拍摄快照?
拍快照相当于给当前虚拟机的配置做一个备份,将来有问题,直接按照快照还原虚拟机即可,不需要删除再重新配置。
4.1 在VMware将所有虚拟机关机
4.2 拍摄快照
4.3 如何使用快照恢复?


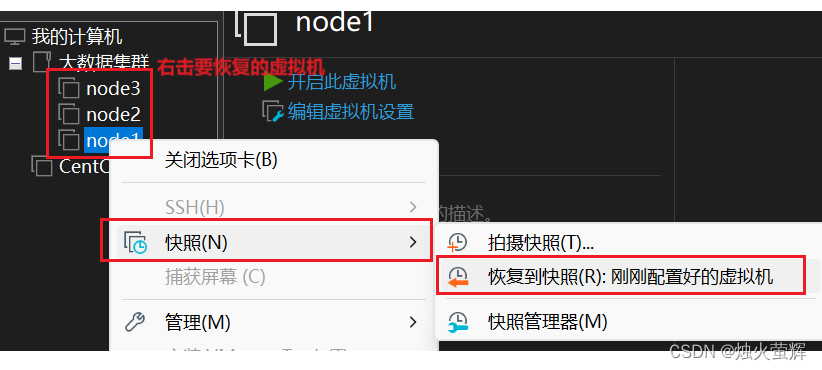
------------------------END-------------------------
才疏学浅,谬误难免,欢迎各位批评指正。











![[论文笔记]Prefix Tuning](https://img-blog.csdnimg.cn/img_convert/0d307fd4adbc77ebb663456f611696e1.png)