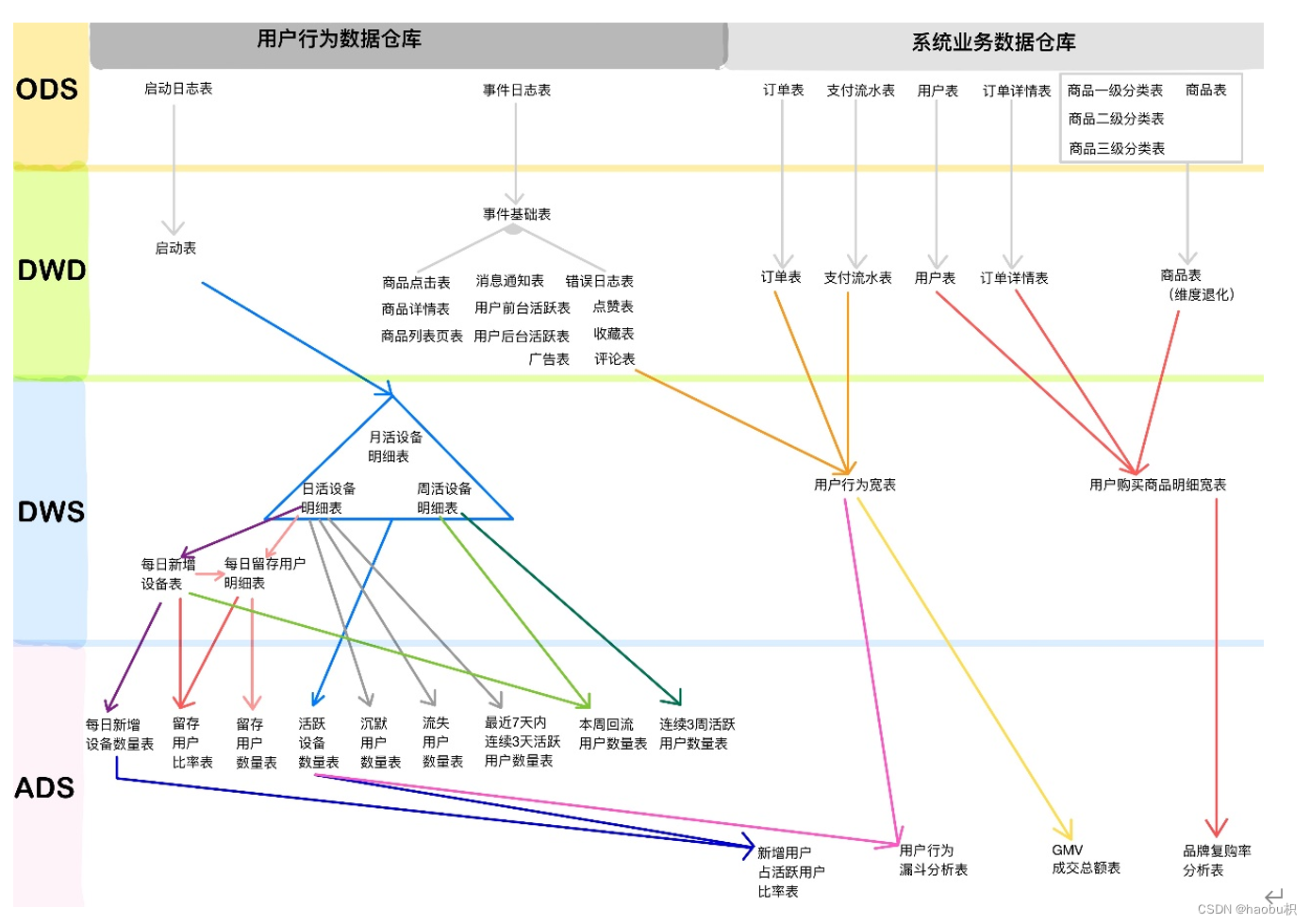
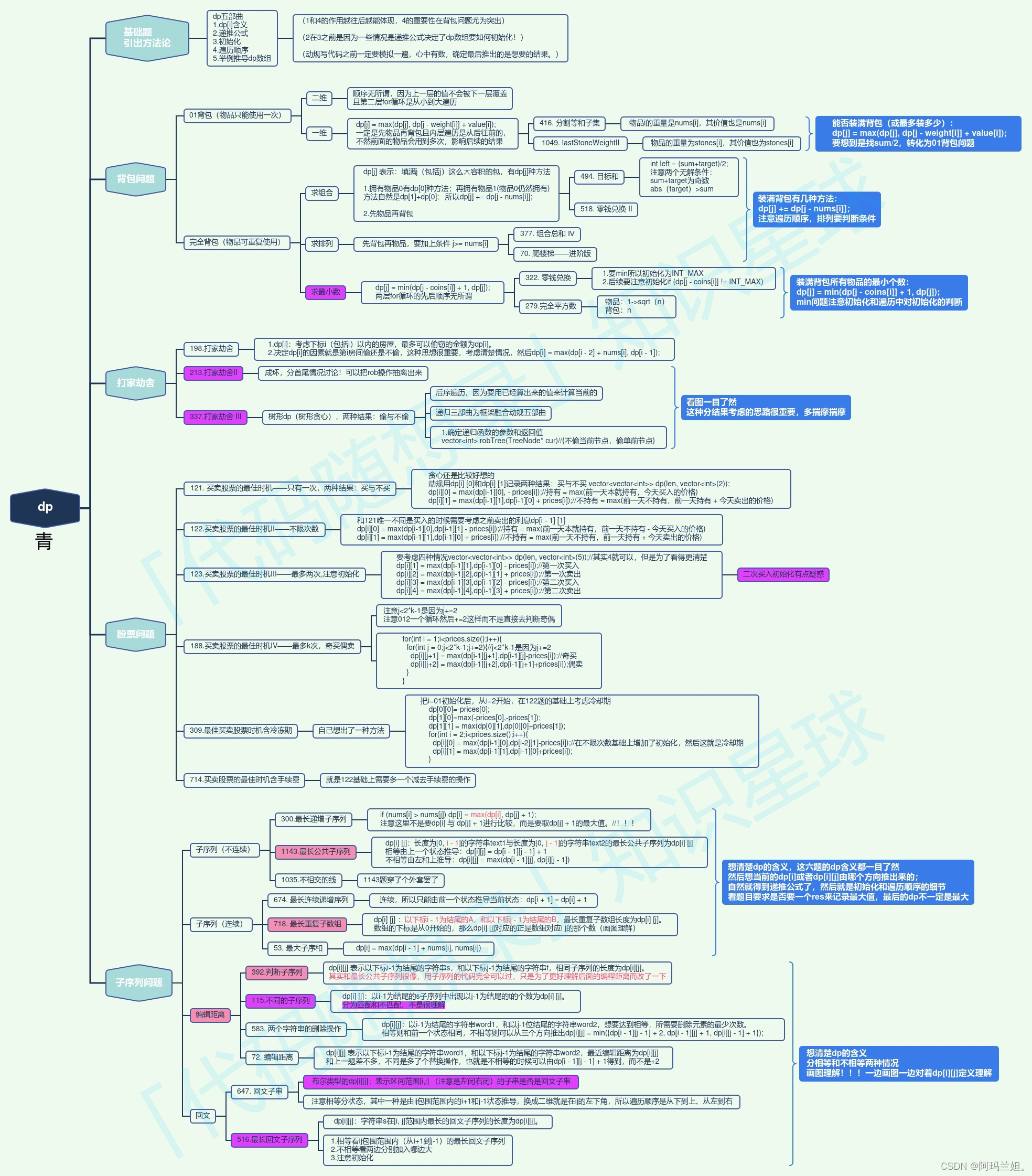
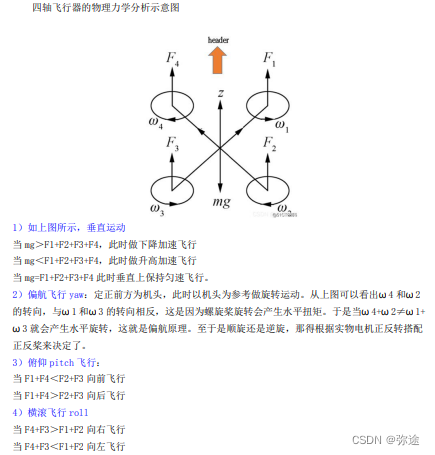
在爬虫的世界中,有时候我们需要模拟登录来获取特定网站的数据,而使用Selenium登录并生成Cookie是一种常见且有效的方法。本文将为你介绍如何使用Selenium进行登录,并生成Cookie以便后续的爬取操作。让我们一起探索吧!
一、Selenium简介
1. 定义:Selenium是一套自动化测试工具,可以模拟用户在浏览器中的操作。
2. 安装:使用pip命令安装Selenium库(pip install selenium),并下载相应浏览器驱动。
二、登录网站的基本步骤
1. 创建Selenium浏览器实例:在代码中,我们需要创建一个Selenium的浏览器实例,例如Chrome浏览器实例。
2. 打开登录页面:使用浏览器实例打开目标网站的登录页面。
3. 输入登录信息:通过Selenium操作浏览器,输入用户名、密码等登录信息。
4. 提交表单:点击登录按钮或按下回车键,将登录信息提交到服务器。
5. 等待登录成功:使用合适的等待时间,确保登录成功后的页面加载完成。
三、生成Cookie的步骤
1. 获取已登录页面的Cookie:登录成功后,使用Selenium获取当前页面的Cookie信息。
2. 将Cookie保存到变量或文件中:将获取到的Cookie保存到一个变量中,或将其保存到文件中以备后续使用。
四、使用Cookie进行爬取
1. 设置Cookie:在后续的爬取过程中,通过Selenium设置请求的Cookie,模拟登录状态进行访问。
2. 发送HTTP请求:使用适当的HTTP库(如Requests)发送HTTP请求,并在请求中设置Cookie。
3. 解析响应数据:解析响应数据,提取所需的信息。
五、注意事项和进阶技巧
1. 隐私和法律问题:在使用Selenium进行登录和爬取时,务必遵守相关网站的爬虫政策,并确保不侵犯他人的隐私和法律规定。
2. 验证码处理:对于登录页面存在验证码的情况,需要使用第三方工具库(如Tesseract OCR)对验证码进行识别。
3. 长期有效性:有些网站的Cookie可能有时间限制,需定期更新或重新登录以获取新的有效Cookie。
通过本文的介绍,你已经了解了如何使用Selenium登录并生成Cookie,以便进行后续的爬取操作。Selenium的自动化操作能力为我们在模拟登录过程中提供了便利,而生成的Cookie则可用于模拟登录状态的爬取。在实际应用中,我们需要根据具体的网站和需求选择适当的策略,并遵守相关法律和道德规范。希望本文对你的爬虫学习之旅有所帮助。如果你有任何问题或需要进一步了解,欢迎评论区随时与我交流。愿你在爬虫的世界里不断探索,收获丰富的数据。