目录
♫二叉搜索树
♪什么是二叉搜索树
♪二叉搜索树的特性
♪模拟实现二叉搜索树
♫Map
♪什么是Map
♪Map的内部类
♪Map的常用方法
♪Map的遍历
♫Set
♪什么是Set
♪Set的常用方法
♪Set的遍历
♫二叉搜索树
♪什么是二叉搜索树
二叉搜索树又称二叉排序树,是一种特殊的二叉树,这颗树的 左子树上所有节点的值小于根节点的值, 右子树上所有节点的值大于根节点的值,且其 左右子树都必须也是二叉搜索树。♪二叉搜索树的特性
①一棵二叉搜索树的中序遍历结果是一个递增的有序序列。②.根据值的大小关系进行查找、插入、删除等操作非常高效。③.由于二叉搜索树左子树的节点值小于根节点,右子树的节点值大于根节点,故二叉搜索树还支持范围查询♪模拟实现二叉搜索树
要想实现一颗二叉搜索树,首先需要确定二叉搜索树的结构。
♩定义节点以静态内部类的方式定义二叉树的节点类型,每个结点应该包含数据元素、左子树指针和右子树指针三个成员变量:
public class BinarySearchTree {static class TreeNode {public int val;public TreeNode left;public TreeNode right;//初始化节点值的构造方法public TreeNode(int val) {this.val = val;}} }♩成员属性用于定位和操作该二叉搜索树:private TreeNode root = null;确定完这些,接下来就可以来实现二叉树的基本操作了。♩插入操作插入一个节点可以通过比较插入元素和当前节点的大小关系,如果插入元素小于当前节点的值,就往左子树递归插入,否则往右子树递归插入://插入操作public boolean insert(int val) {//根节点为空:if (root == null) {root = new TreeNode(val);return true;}//根节点不为空:TreeNode curParent = root;//cur的父节点TreeNode cur = root;//找到合适的插入位置while (cur != null) {curParent = cur;//值小,位置在左子树方向if (val < cur.val) {cur = cur.left;}//值大,位置在右子树方向if (val > cur.val) {cur = cur.right;}//二叉搜索树中已经有该值了,不能再插入相同值if (val == cur.val) {return false;}}//实例化一个新节点TreeNode node = new TreeNode(val);//值小,在父节点的左子树if (val < curParent.val) {curParent.left = node;}//值大,在父节点的右子树if (val > cur.val) {curParent.right = node;}//插入成功return true;}♩查找操作
查找一个节点需要从根节点开始查找,如果当前节点值等于待查找元素的值,则返回当前节点;否则,根据比较结果查找其左子树或右子树直到找到为止:
//查找查找public TreeNode search(int val) {//不能直接操作根节点,不然下次就找不到根节点了TreeNode cur = root;while (cur != null) {//找到了,返回该节点if (val == cur.val) {return cur;}//值比当前节点小,去左子数上找if (val < cur.val) {cur = cur.left;}//值比当前节点大,去右子树上找if (val > cur.val) {cur = cur.right;}}//都没找到,返回nullreturn null;}♩删除操作删除一个节点需要考虑其左子树和右子树的情况。如果该节点左子树为空,直接将其替换为右子树;如果右子树为空,直接将其替换为左子树;否则,将其右子树的最小节点替换该节点,并删除该最小节点://删除操作public void remove(int val) {TreeNode curParent = root;TreeNode cur = root;//找到要删除的节点while (cur != null) {curParent = cur;//值小,要删除的节点在左子树方向if (val < cur.val) {cur = cur.left;}//值大,要删除的节点在右子树方向if (val > cur.val) {cur = cur.right;}//值相同,找到要删除的节点if (val == cur.val) {//删除该节点removeNode(curParent, cur);}}}//刷除cur节点private void removeNode(TreeNode curParent, TreeNode cur) {//如果cur的左子树为空if (cur.left == null) {if (cur == root) {//cur为根节点root = cur.right;} else if (cur == curParent.left) {//cur为左孩子节点curParent.left = cur.right;} else if (cur == curParent.right) {//cur为右孩子节点curParent.right = cur.right;}return;}//如果cur的右子树为空if (cur.right == null) {if (cur == root) {//cur为根节点root = cur.left;} else if (cur == curParent.left) {//cur为左孩子节点curParent.left = cur.left;} else if (cur == curParent.right) {//cur为右孩子节点curParent.right = cur.left;}return;}//如果cur的左右子树都不为空if (cur.left != null && cur.right != null) {TreeNode tarParent = cur;TreeNode tar = cur.right;//找到cur的右子树中最左边的那个节点(该节点比cur的左子树大,比cur的右子树的其它节点大)while (tar.left != null) {tarParent = tar;tar = tar.left;}cur.val = tar.val;if (tar == tarParent.left) {//当cur的右孩子节点存在左孩子节点的时候tarParent.left = tar.right;} else if (tar == tarParent.right) {//当cur的右孩子节点不存在左孩子节点的时候tarParent.right = tar.right;}}}♩性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。对有n 个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树的高度越高,查找效率越低。对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树: 最优情况下(二叉搜索树为完全二叉树),其时间复杂度为:O(logn)最差情况下(二叉搜索树退化为单支树),其时间复杂度为:O(n)因此,为了保证每个节点的左右子树高度相差不超过1,这才有了AVL树(通过左旋,右旋,左右双旋调整高度差),而为了减少AVL的旋转次数,这才有了红黑树(通过染色来保证平衡,不需要每次都调整,复杂度相对较低)。
最优情况下(二叉搜索树为完全二叉树),其时间复杂度为:O(logn)最差情况下(二叉搜索树退化为单支树),其时间复杂度为:O(n)因此,为了保证每个节点的左右子树高度相差不超过1,这才有了AVL树(通过左旋,右旋,左右双旋调整高度差),而为了减少AVL的旋转次数,这才有了红黑树(通过染色来保证平衡,不需要每次都调整,复杂度相对较低)。
♫Map
♪什么是Map
Map是Java集合中一种专门用来进行搜索的容器或者数据结构,它适合多态查找(查找时能进行一些插入和删除的操作),其搜索的效率与其具体的实例化子类有关。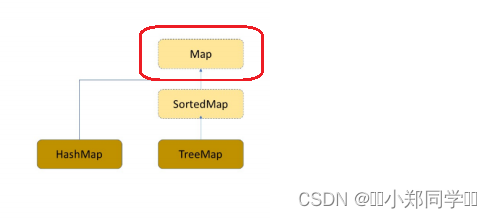 Map 是一个接口类,该类没有继承自 Collection ,该类中存储的是 <K,V> 的键值对,并且K一定是唯一的,不 能重复 。
Map 是一个接口类,该类没有继承自 Collection ,该类中存储的是 <K,V> 的键值对,并且K一定是唯一的,不 能重复 。♪Map的内部类
在Map内部有一个用来存放Map<key,value>键值对映射关系的内部类:Map.Entry<K,V>,
该内部类中主要提供了<key, value>的获取, value 的设置以及 Key 的比较方式:
方法 描述 K getKey() V getValue() V setValue(V value) 注:Map.Entry<K,V>并没有提供设置Key的方法,即Map中Key是不能被改变的。
♪Map的常用方法
方法 描述 V put(K key, V value) V get(Object key) V remove(Object key) Set<K> keySet() Collection<V> values() 返回所以 value 的可重复集合 set<Map,Entry<K,V>> entrySet() boolean containsKey(Object key) boolean containsValue(Object value) ♪Map的遍历
因为Map是一个独立的接口,没有继承Iterable接口,故不可直接通过for-each和迭代器进行遍历。我们可以借助上述常用方法返回的集合(继承了Iterable接口)进行遍历操作。
①.使用for-each循环遍历Map中的键值对:
public class Test {public static void main(String[] args) {Map<String, Integer> map = new HashMap<>();for(Map.Entry<String, Integer> entry : map.entrySet()){String key = entry.getKey();Integer value = entry.getValue();// 对key和value进行操作}} }②.使用Iterator遍历Map中的键值对:
public class Test {public static void main(String[] args) {Map<String, Integer> map = new HashMap<>();Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();while (iterator.hasNext()) {Map.Entry<String, Integer> entry = iterator.next();String key = entry.getKey();Integer value = entry.getValue();// 对key和value进行操作}} }③.遍历Map中的键
public class Test {public static void main(String[] args) {Map<String, Integer> map = new HashMap<>();for(String key : map.keySet()){// 对key进行操作}} }④.遍历Map中的值
public class Test {public static void main(String[] args) {Map<String, Integer> map = new HashMap<>();for(Integer value : map.values()){// 对value进行操作}} }♪Map的实现类
实现类 TreeMap HashMap 底层结构 红黑树 哈希桶 插入/删除/查找的时间复杂度 O(logn) O(1) 是否有序 关于key有序 无序 线程安全 不安全 不安全 插入/删除/查找的区别 不能插入空值,按照红黑树的特性来进行插入和删除 能插入空值,通过哈希函数计算哈希地址
♫Set
♪什么是Set
Set和Map一样也是Java集合中一种专门用来进行搜索的容器或者数据结构,它一样适合多态查找(查找时能进行一些插入和删除的操作),Set与Map不同的是:①.Set是继承自Collection的接口类。②.Set中只存储了Key。
注:
1.Set是继承自Collection的一个接口类2. Set中只存储了key,并且要求key一定要唯一3. Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的4. Set最大的功能就是对集合中的元素进行去重5. 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。6. Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入♪Set的常用方法
方法 描述 boolean add(E e) boolean contains(Object o) Iterator<E> iterator() boolean remove(Object o) int size() 返回set中元素的个数 boolean isEmpty() Object[] toArray() boolean containsAll(Collection<?> c) boolean addAll(Collection<? extends E> c) ♪Set的遍历
Set继承了Iterable接口,故可以直接通过for-each和迭代器进行遍历
①.使用迭代器遍历Set:
public class Test {public static void main(String[] args) {Set<String> set = new HashSet<>();// 添加元素Iterator<String> iterator = set.iterator();while (iterator.hasNext()) {String element = iterator.next();// 处理元素}} }②.使用foreach循环遍历Set:
public class Test {public static void main(String[] args) {Set<String> set = new HashSet<>();// 添加元素for (String element : set) {// 处理元素}} }③.使用stream遍历Set:
public class Test {public static void main(String[] args) {Set<String> set = new HashSet<>();// 添加元素set.stream().forEach(element -> {// 处理元素});} }♪Set的实现类
实现类 TreeSet TreeMap 底层结构 红黑树 哈希桶 O(logn) O(1) 关于key有序 不安全 不安全 能插入空值,通过哈希函数计算哈希地址 key必须能够比较(有传比较器优先根据比较器比较,否则根据compareTo方法比较)