全文链接 :https://tecdat.cn/?p=33676
点模式分析(点格局分析)是一组用于分析空间点数据的技术。在生态学中,这种类型的分析可能在客户的几个情境下出现,但对数据生成方式做出了特定的假设,因此让我们首先看看哪些生态数据可能与点模式分析相关或不相关(点击文末“阅读原文”获取完整代码数据)。
相关视频
哪些数据适用于点模式分析?
点模式分析的最重要假设是点的数量和位置都需要是随机的。此外,我们需要知道客户的采样区域(即所谓的窗口)。以下是适用于点模式分析的示例:
森林样地中树木的位置
草地区域中蚂蚁巢穴的分布
以下是不适合进行点模式分析的示例:
在较大的样地中事先定义好的子样方形成的规则网格中的群落组成
记录了给定区域内固定数量的鸟巢的位置
以下示例可能适用于点模式分析,也可能不适用:
动物移动的无线电跟踪数据(请参阅针对此特定类型数据的众多技术)
每年记录森林样地中树木位置,形成复制的点模式
在 R 中进行点模式分析
我将使用一个数据集来展示分析。该数据集包含沿海沙丘系统中植物和蚂蚁巢穴的位置(查看文末了解数据免费获取方式)。
从现有数据创建点模式
#加载数据集
dat <- read.table("daf.csv",sep=";",head=TRUE)
#将坐标转换为米
dat$X <- dat$X/100
dat$Y <- dat$Y/100#创建点模式
(all_pp <- ppp(
plot(
对点模式对象进行数据操作
#一个首次操作是给每个点添加信息,即所谓的标记
#在这个示例中,我们可以添加植物的物种名称
marks(all_pp) <-#第二个操作可以是删除任何重复点
#我们可以使用简单的行索引来做到这一点
all_pp <- unique#然后添加坐标单位
summary(all_pp)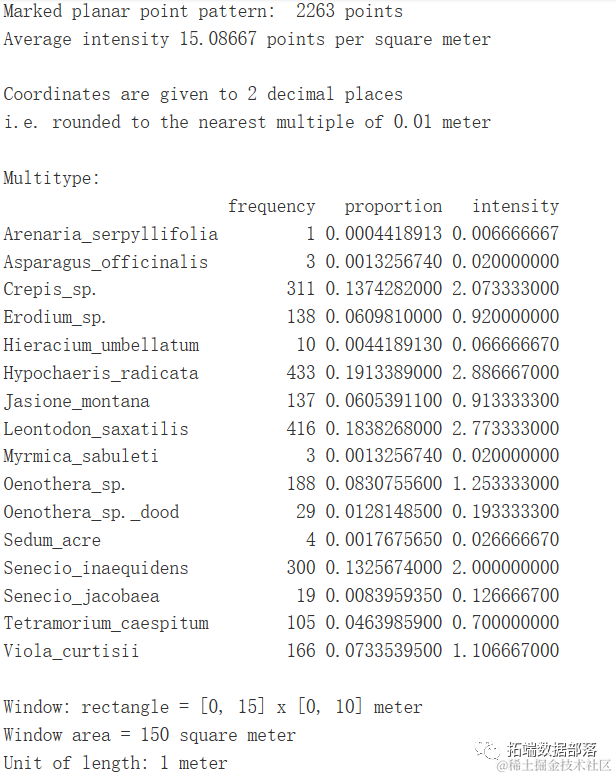
#我们可以使用标记对点模式进行子集化
ant_pp <- subset(all_pp,marks=="Tetramorium_caespitum")
#在这种情况下,我们不再需要标记
ant_pp <- unmark(ant_pp)标记的概念非常重要,所以我会多花几句话来介绍。标记可以是与点模式长度相同的数字或因子向量,它们是为每个点收集的额外信息。在本示例中,这是记录的植物和蚂蚁的物种名称,但也可以是树木高度或鸟巢中的蛋数。
基于窗口的第二个有趣的操作集是根据特定窗口对点模式进行子集化:
w <- hexon(entre=c(5,5))
plot(antp[w])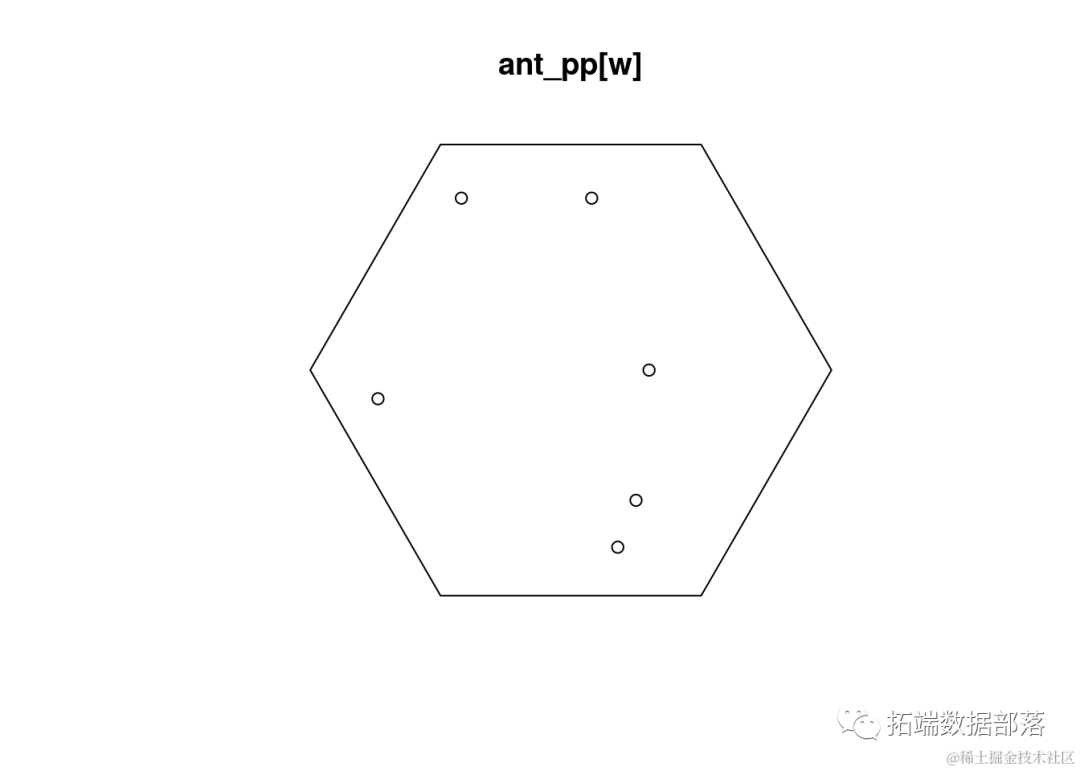
#基于物种名称拆分
split_pp <- si(all_pp)
class(spitpp)## [1] "splitppp" "ppplist" "solist" "list"as.matrix(lapplysplit_p,npis),ncol=1)
#也可以使用:by(all_p,maksall_p,npoints)来拆分#基于窗口进行拆分
spl_ant_pp <- splitn_p,f=w)
summary(plt_at_pp)

点格局的探索性分析
这是任何点格局分析中非常重要的一步,这一步可以帮助你:(i) 探索密度,以及 (ii) 观察点格局是否偏离随机期望。
den_all <- desit(slit_pp)
plot(dns_ll)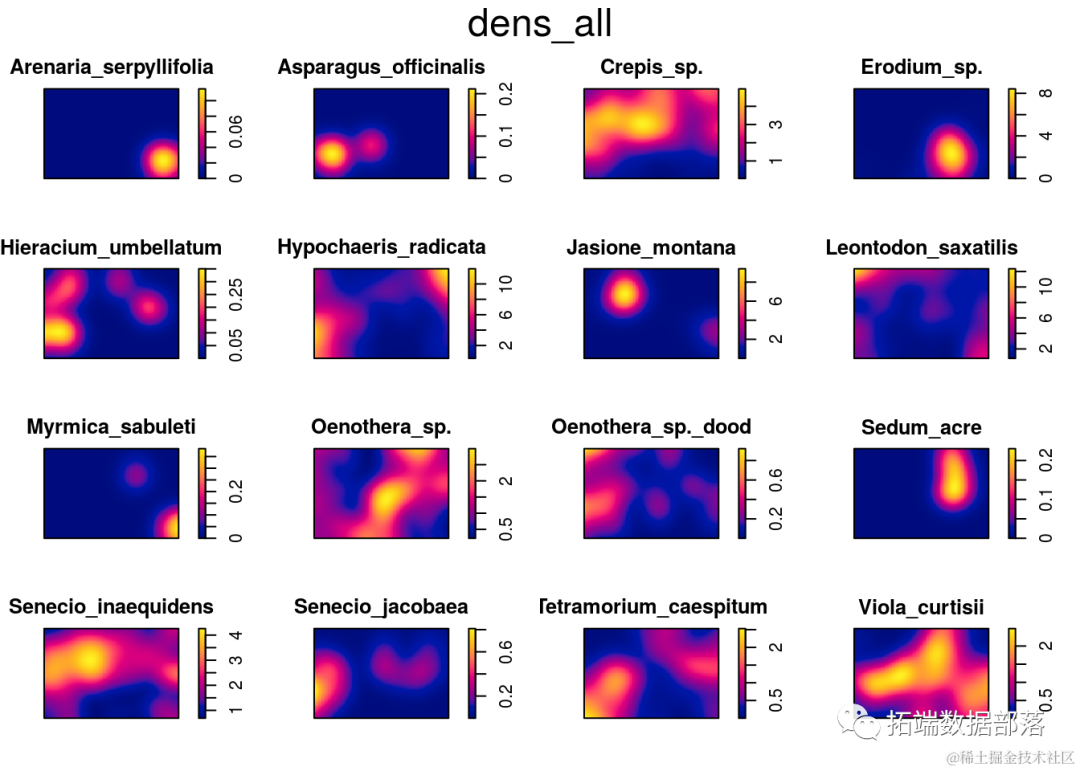
首先要找出点格局是否由一个强度函数生成,如果是,则点格局是均匀的;如果点格局是由多个强度函数生成的,则点格局是不均匀的。这是点格局分析中的一个重要的第一步,因为大多数函数和模型默认假设点格局是均匀的。我将展示两种推断点格局均匀性的方法:(i) 模拟和 (ii) 方块计数。
点击标题查阅往期内容

生态学建模:增强回归树(BRT)预测短鳍鳗生存分布和影响因素

左右滑动查看更多
01
02
03
04
第一种方法是根据观察到的点格局的平均强度,在空间上完全随机模拟点格局。如果观察到的点格局和模拟的点格局的密度估计相似,那么我们就有证据表明点格局是均匀的。
#将观察到的密度与基于强度的随机模拟进行比较#在图中为观测数据选择一个随机位置
pos <- sale(1:16,1)
#模拟15个CSR点
simp <- roisp(lmbda= intesityant_pp,win Windw(nt_p),nm=15)
#将模拟集合中的第pos个位置替换为观察数据集
tmp <- sp[pos]]
sim[pos]] <- ant_pp
sip16]] <- tmp
naes(imp)[16] <- "Siulio 16"
#计算密度估计
densp <- dsiymp)
#绘图,你能分辨出哪一个是观测数据集吗?
pr(mfow=c(,4)mar=c(0,0,4,4))
plt(as.isto(densp),zlim=rage(unlst(lapl(despran))))
如果你能在模拟数据中找到真实数据集,那么就证据表明一种不均匀的过程生成了数据。在这种情况下,你需要使用特殊的函数。第二种方法是将窗口划分成方块,并统计每个方块中的点的数量。通过卡方检验,我们可以推断点格局是均匀的(p > 0.05)还是不均匀的(p < 0.05)。
quar.tst(ant_pp)
输出结果告诉我们,点模式的零假设是完全随机生成的空间过程,被拒绝了。我们有一些证据表明,点模式是不均匀或非平稳的。如果点模式遵循完全随机性(CSR),则这个计数值(K)和考虑的距离(r)之间存在已知的关系。在R中,对蚂蚁巢穴点模式执行这个操作的代码是:
ee_iso <- eneope(antpun=Kst, nar=liscrectio="rder"), gloal=TRUE
plot(eeso)
在这里,我围绕模拟的随机点过程的期望(Ktheo(r))从中推导出一个包络。然而,正如我们之前所看到的,我们有一些证据表明蚂蚁巢穴的点模式是不均匀的,因此我们应该通过使用Ripley的K函数的修改版本来考虑这一点:
eeihm < elop(ant_pp, fun=Khom,glba=TUE)
plot(ee_iom)
这次观察到的曲线在较大距离上低于预期曲线,说明巢穴中的分散程度超过了考虑点模式非均匀性时的预期CSR。
从这个探索性分析中我们得出以下结论:
蚂蚁巢穴显示出不均匀性模式
有一些证据表明在较大距离上,蚂蚁巢穴的间距比从估计的强度函数中预期的要大。
现在我们可以进入下一步,对我们的点模式进行建模。
构建点模式模型
在我们的蚂蚁巢穴数据示例中,我们可能对巢穴密度是否取决于特定植物物种的密度感兴趣。
#拟合一个仅包含截距的泊松点过程模型
m0 <- ppm(tp ~ 1)
m0 这是最简单的拟合模型,该模型基本上告诉我们强度(蚁巢的密度)在观察区域内始终为e^(-0.36)=0.70。现在我们可以使用坐标作为预测变量来建立一个模型:
m1 <- ppm(tpp~ plnm(x,y,2))
m1
plt(m,se=FS,ho="iae")
该模型拟合了以下关系:log(λ)=x+y+x^2+y^2+x:y,基本上是每个坐标轴的二次关系加上一个交互项。图示了模型预测的强度(λ)与观察到的蚁巢的关系。这个模型在一些区域拟合效果较差。对于每个模型,重要的下一步是模型验证,可以绘制许多重要的模型诊断图:
diospm(m1whih = "ooh")
默认情况下,生成四个图,我只请求绘制平滑残差图,以便我们可以确定模型在观察到的点格局上拟合得不好的区域。该模型在某些区域的拟合效果较差。也可以使用拟合强度在Kinhom函数中查看观察到的点格局是否比模型拟合预期的更或更少聚集:
e <- envepe(an_ppKinom,unargs list(lda=1),obl=TUE)
plt(em)
在这里,我们可以看到观察到的点格局比模型预期更加聚集。一种解决方法是使用聚类泊松点过程模型:
m2 <- kp(ntp ~ lyo(x,,2))
plotm,wht="satistc",pase=ASE)
虚线绿线显示了基于模型中的预测变量的预期K值,实线黑线将拟合的聚类过程添加到预测变量中(在这种情况下是一个Thomas过程。从配适模型中模拟点格局也很容易,我们将在这里使用它来查看观察到的点格局和模拟的点格局之间是否存在明显差异:
#一个随机位置
pos <- sample(1,1:16)
#从该模型中模拟15个点格局
sims <- (2,nim = 15)
#将观察到的点格局放在随机位置
mp < sims[[pos]]
sims[s<- tmulation 16"
#计算密度估计
den <- nsity(sims)
#绘图,你能分辨出哪一个是观察到的数据集吗?
par(row=c(4,),mar=c(0,0,4,4))
plot(aslistf(dnsp)zliangunlis(lpply(nsange))))
我无法真正辨认出观察到的格局,因此该模型相当好。
点格局的预测变量也可以是像素图像(或"im")对象,我们将使用一个植物物种Senecio_inaequidens的密度作为预测变量:
m3 <- kpm(an_p ~ Seco_jcobaa,dta=desall)
#让我们来看一下预期的K值
plt(m3,wat="aisti",pus=FALSE)这个模型显然比之前的模型好。可以使用effectfun函数绘制协变量的效果,例如:
#查看Senecio jacobaea的效应
plot(effetfun(m3Seecio_jacaea"))
这个模型显然比之前的模型好。可以使用effectfun函数绘制协变量的效果,例如:
#查看Senecio jacobaea的效应
plot(efcfun(m3"Seeciojacobea"))
可以绘制更酷炫的地图:
#绘制一个有趣的透视图
pp <- predctm3)
M<-persp(s_al$,lin=pox=FALSE,visble=TREapron = TRUE,et55,ph=,exnd=6,mi=" density")
perspPins(ant_pp,Zdn_lSeneco_cobaea,M=M,pc=20)
图中的高度表示Senecio jacobaea苗的密度,颜色表示蚁巢的拟合强度,点表示实际观察到的蚁巢。
数据获取
在公众号后台回复“蚂蚁数据”,可免费获取完整数据。
本文中分析的数据分享到会员群,扫描下面二维码即可加群!
点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言生态学种群空间点格局分析:聚类泊松点过程对植物、蚂蚁巢穴分布数据可视化》。
点击标题查阅往期内容
Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
matlab使用分位数随机森林(QRF)回归树检测异常值
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言实现偏最小二乘回归法 partial least squares (PLS)回归
R语言多项式回归拟合非线性关系
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
![]()