文章目录
- 前言
- Ⅰ. 内联函数
- 0x00 内联函数和宏的比较
- 0x01 内联函数的概念
- 0x02 内联函数的特性
- Ⅱ. auto(C++ 11)
- 0x00 auto的概念
- 0x01 auto的用途
- Ⅲ. 范围for循环(C++11)
- 0x00 基本用法
- 0x01 范围for循环(C++11)的使用条件
- Ⅳ. 指针空值nullptr(C++11)
- 0x00 概念
前言
亲爱的夏目友人帐的小伙伴们,今天我们继续讲解 C++ 入门的知识 内联函数、auto、范围for循环、nullptr空指针 这里的知识虽然入门,但是却是你后面更加深入学习 C++ 知识的钥匙,所以请跟着夏目学长一起进入 C++ 的世界吧!
Ⅰ. 内联函数
0x00 内联函数和宏的比较
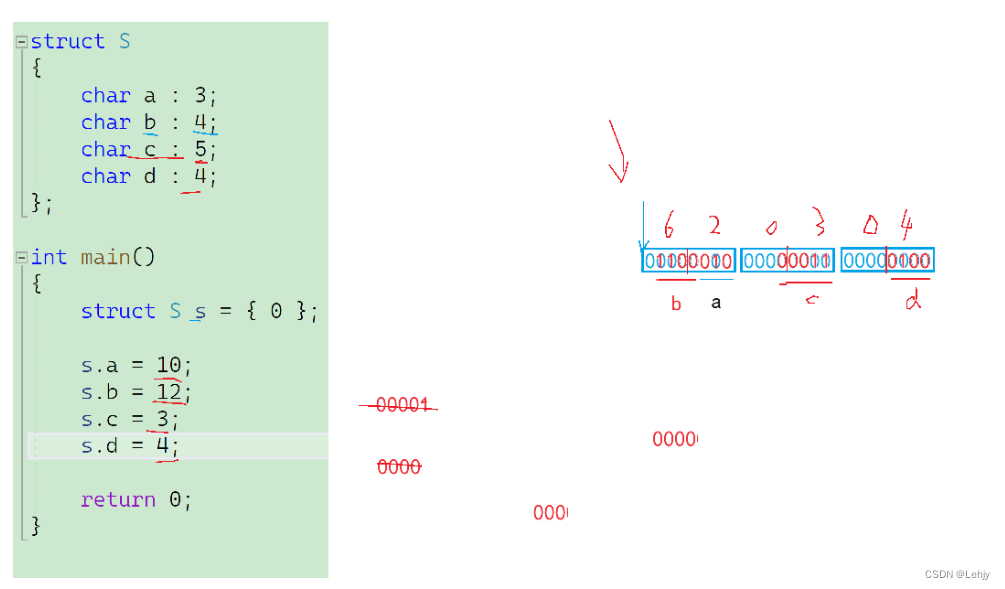
我们学习C语言的时候知道:调用函数需要建立栈帧,栈帧中要保存寄存器,结束后就要恢复,这其中都是有 消耗 的 例如:
#include<iostream>using namespace std;int add(int a,int b)
{return a + b;
}int main()
{add(1, 2);add(1, 2);add(1, 2);add(1, 2);return 0;
}
而针对 频繁调用 的 代码短小的函数,可以用 宏 优化,因为宏是在预处理阶段完成替换的,并没有执行时的开销,并且因为代码量小,也不会造成代码堆积,例如:
#include<iostream>using namespace std;#define add(a,b) ((a)+(b)) int main()
{cout << add(1, 2) << endl;return 0;
}
我们会思考,既然宏这么好用,好处如此之多,为什么还要引进 内联函数? 所以下面就要来讲讲 宏 的缺点:
- 不能调试
- 有些场景下非常复杂
- 没有类型安全的检查
就拿我们写过的add函数来说,我们再初次学习的时候通常会写成以下错误:
// 以下代码都是错误的,不要被误导
#define add(int a,int b) ((a)+(b))
#define add(int a,int b) ((a)+(b));
#define add(a,b) ((a)+(b));
#define add(a,b) a+b
所以写宏时出错,要么是替换出错,要么是因为优先级出错,所以宏并不友好。
而 C++ 针对为了减少函数调用开销,又可以在一定程度上替代宏,避免宏的出错,从而设计出了内联函数 。
内联函数的关键字为 inline :
#include<iostream>using namespace std;inline int add(int a,int b)
{int res = a + b;return res;
}int main()
{int res = add(1, 2);cout << res << endl;return 0;
}
0x01 内联函数的概念
在 release 版本下,inline 内联函数会直接在调用部分展开;对于 debug 则需要 主动设置 (debug 下编译器默认不对代码做优化);但是 release 版本下其他版本优化的太多,可能就不太好观察,所以我们设置一下编译器,在 debug 下看:
打开解决方案资源管理器,右击项目名称,选中属性并打开,在 C/C++ 区域常规部分,在调试信息一栏设置格式为程序数据库:
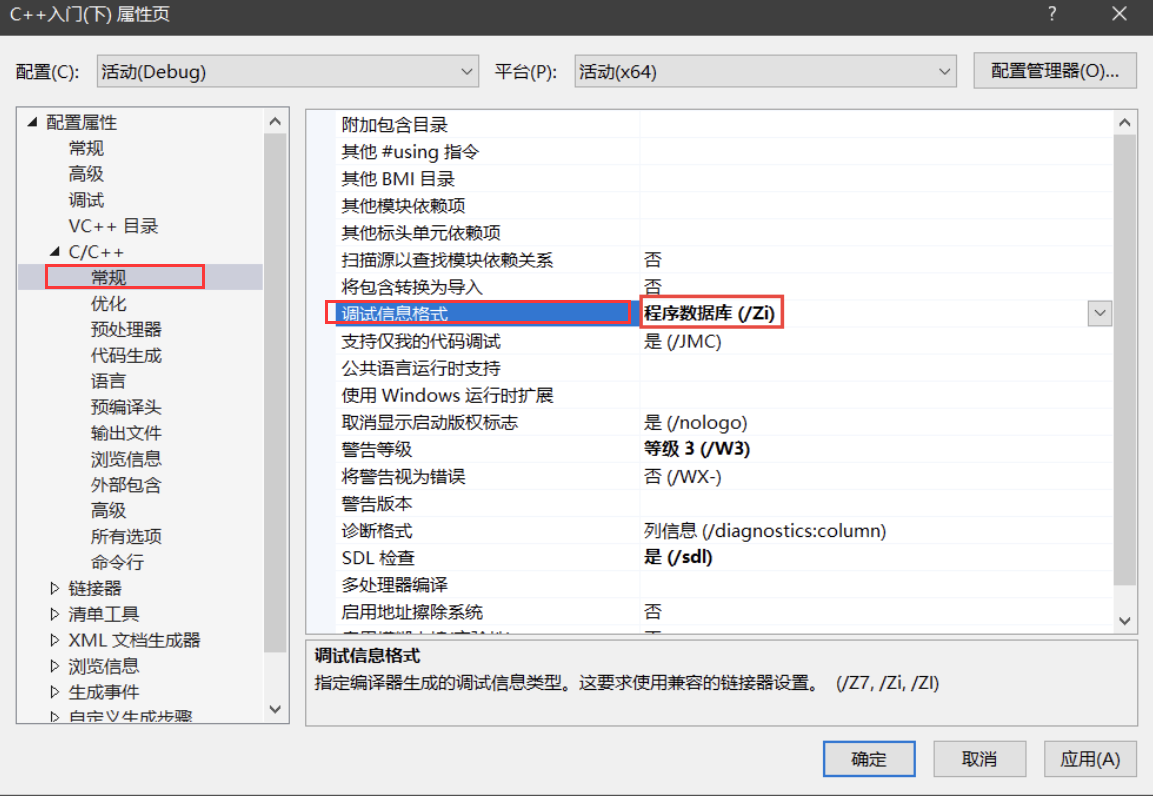
然后找到优化,将内联函数扩展部分选中只适用于 _inline :
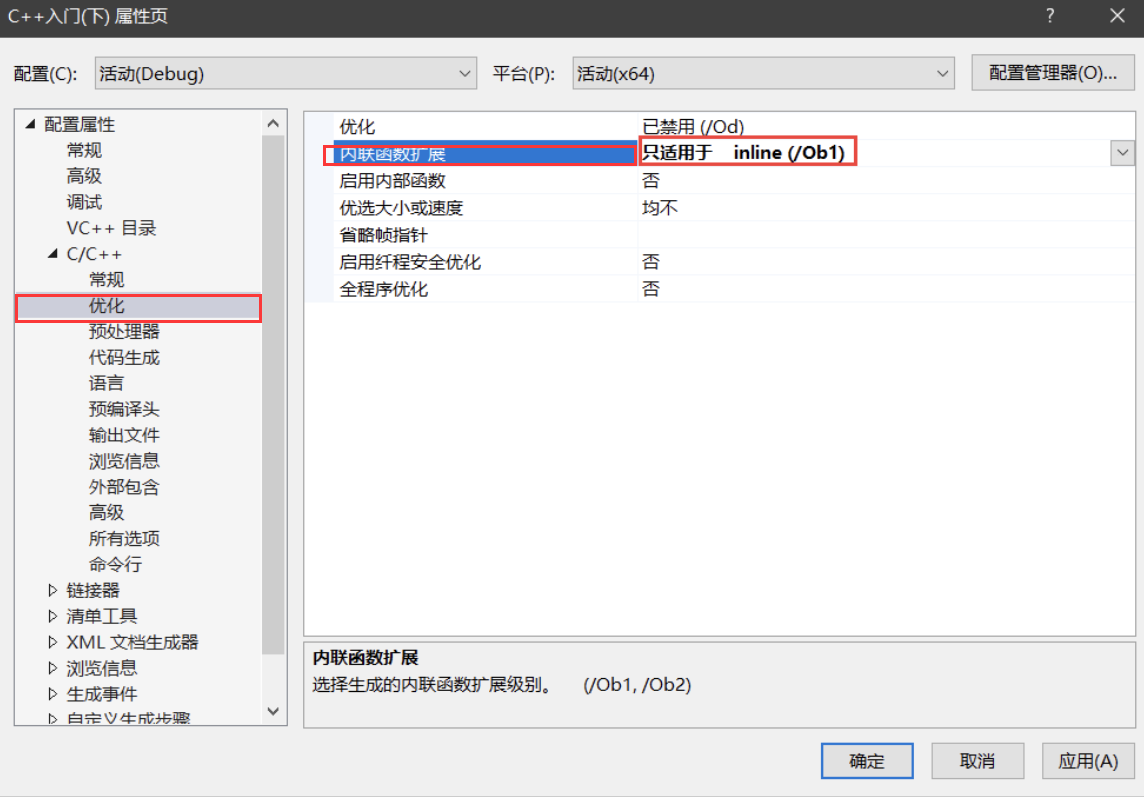
这样算是可以使用内联函数了,就不再需要使用 宏 啦。
0x02 内联函数的特性
- inline是一种以 空间换时间 的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:**将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。**下图为《C++prime》第五版关于inline的建议:
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。

对于特性1的讲解:
空间换时间是因为反复调用内联函数,导致编译出来的可执行程序变大
inline void func()
{// 假设编译完成为 10 条指令
}
若不用内联函数,不展开,若10000次调用 func,每次调用的地方为 call 指令的形式,总计 10010 行指令。若用内联函数,则展开,若一千次调用,每次调用的地方为都会展开为 10 条指令,总计 10 * 10000 行指令。
展开会让编译后的程序变大,如果递归函数作内联,后果可想而知。所以长函数和递归函数不适合展开。
对于特性2的讲解:
编译器可以忽略内联请求,内联函数被忽略的界限没有被规定,一般10行以上就被认为是长函数,当然不同的编译器不同
编辑器并不信任你是否能判断什么时候使用内联函数,所以编译器会决策是否使用内联函数。
对于特性3的讲解:
内联函数声明和定义不可分离
由于内联函数无地址,所以当声明和定义分离,调用函数时,由于内联函数无地址,编译器链接不到,所以就会报错,为链接错误。
结论:简短,频繁调用的小函数建议定义成 inline .
Ⅱ. auto(C++ 11)
0x00 auto的概念
在前面学习的C语言当中也有关键字 auto
int main()
{auto int a = 0;
}
auto 关键字修饰后,a变为自动存储类型,即变量会在函数结束以后自动销毁。但是这个语法完全多此一举,因为后来,对于局部变量默认就是自动存储类型,当函数结束后也会自动销毁。
于是 C++ 委员会废弃了 auto 的用法,赋予了新的意义:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
int main()
{int a = 0;int b = 0;auto c = a;auto d = 1.11;auto e = 'a';return 0;
}
对于 auto ,如果要加上 const 属性,则需要主动加上:
int main()
{int x = 10;const auto y = x;cout << typeid(y).name() << endl; // 这里不会打印出,需要调试看return 0;
}
0x01 auto的用途
auto 具有两种针对场景:
- 类型难于拼写
- 含义不明确导致容易出错
比如后面的STL迭代器的使用 还有 BFS对于取出 pair 类型的时候,这里需要后面学到的时候再讲。
Ⅲ. 范围for循环(C++11)
0x00 基本用法
之前对于数组的遍历,需要使用下标遍历:
int main()
{**加粗样式** int a[] = {1,2,3,4,5,6};for(int i = 0 ; i < sizeof(a) / sizeof(a[0]) ; ++ i){cout << a[i] << ' ';}cout << endl;return 0;
}
而 C++ 中效仿新语言,加入了范围遍历:
int main()
{int a[] = {1,2,3,4,5,6};for(auto& c : a){cout << c << " "; }cout << endl;return 0;
}
范围 for 对于遍历来说非常舒服
而范围for循环的原理就是自动取遍历目标的每一个元素,再放到给定的临时变量中。在上方就是取 arr 的元素放到 num 中,并自动判断结束。auto 会根据遍历目标的元素类型自动推导,当然直接写类型 int 也对 。
而对于 num 的生命周期,则可以认为仅在每次范围遍历中(某一次循环)才存在。
范围 for 会根据遍历目标的元素类型来取出元素,例如上方例子就是 int ,如果这时用指针接收,就是错误的:
int main()
{int a[] = {1,2,3,4,5,6};for(auto* c : a)//错误{c ++;}for(auto c : a){cout << c << " "; }return 0;
}
因为取出来的每一个元素是 int ,类型不匹配。而判断结束我们并不用担心,其实和普通遍历类似。
0x01 范围for循环(C++11)的使用条件
for循环迭代的范围必须是确定的
对于数组的范围就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
以下代码就有问题,因为for的范围不确定,因为函数传参,数组就会退化为指针:
void Func_For(int arr[])
{for (auto& c : arr){cout << c << endl;}
}
是错误的。
Ⅳ. 指针空值nullptr(C++11)
0x00 概念
对于 c 来说,空指针为 NULL,是一个宏。
在 C++98/03 时,只能使用 NULL ;而 C++11 后,推荐使用 nullptr 。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif实际上 NULL 就是个宏,所以说写成 int* p = 0 ,也可以;而j绝大多数情况下,这样写都没问题。
但是对于极端场景:
void f(int) // 这边由于不使用形参,不给形参名也可以
{cout << "f(int)" << endl;
}void f(int*)
{cout << "f(int*)" << endl;
}int main()
{f(0);f(NULL);return 0;
}
按道理,对于第一次调用,应该匹配第一个,对于第二次调用,应该匹配第二个。
但是实际上它们都匹配了第一个,原因是 NULL 是一个宏,本质为 0 .
在C++98中,字面常量 0 既可以是一个整形数字,也可以是无类型的指针(void* )常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void* )0,例如:(int*)NULL ,所以在 C++11 后,使用 nullptr 是明智的选择。
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。

📌 [ 笔者 ] 夏目浅石.
📃 [ 更新 ] 2023.9
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,本人也很想知道这些错误,恳望读者批评指正!
📜 参考文献:
百度百科[EB/OL]. []. https://baike.baidu.com/.
维基百科[EB/OL]. []. https://zh.wikipedia.org/wiki/Wikipedia
B. 比特科技. C/C++[EB/OL]. 2021[2021.8.31]
 如果侵权,请联系作者夏目浅石,立刻删除
如果侵权,请联系作者夏目浅石,立刻删除