NLP 基础
建议看 [CS224N 2023]打基础
【NLP入门】1. n元语法模型 / 循环神经网络
【NLP入门】3. Word2Vec / GloVe
- Language Model:语言模型的马尔可夫假设(每个词出现的概率仅依赖前面出现的词),是一个
自回归模型(同decoder-only)。①根据前文预测下一个词是 w n w_n wn的条件概率 P ( w n ∣ w 1 , w 2 , . . . , w n − 1 ) P(w_n | w_1, w_2, ..., w_{n-1}) P(wn∣w1,w2,...,wn−1),语言建模的能力,②预测一个word序列组成一句话的联合概率 P ( w 1 , w 2 , . . . , w n ) P(w_1, w_2, ..., w_n) P(w1,w2,...,wn),语言理解能力。 - N-gram Model:将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列,对文本中长度为n序列进行统计。每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。但n-gram背后是one-hot思想,不同词的相似度为零,没有考虑同义词的文本相似度。
- Vocabulary:word embedding时,根据词表,对见过的词进行编码映射为vector,未见过的词映射为UNK,为解决
word-level的稀疏问题和词表无限问题(out of vocabulary),转而使用char-level但粒度太细,所以可以使用subword-level的编码(单词前后缀等)。但vocabulary embedding没有考虑句子中词间关系。 - Word2Vec:word embedding时,将word映射到向量vector空间的预训练神经网络,文本相似度的word在特征空间中距离近。后面还要接LM做下游任务。
- Pre-train Whole Model:预训练整个模型是一种将大型神经网络模型与大规模文本数据集一起进行训练的技术,直接统一了word embedding和down stream。
- BigModel:大模型work的机理,Transfer Learning(无监督预训练+有监督微调)。
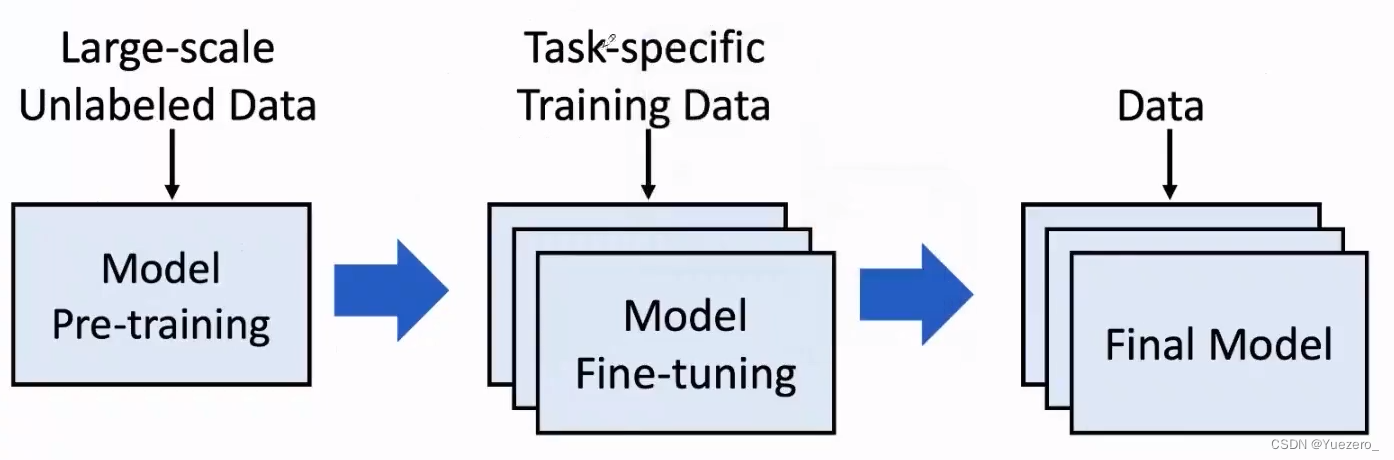
Pretraining Language Model (PLM)
PLM主要分为两类:
- Feature based 模型:预训练模型的输出作为下游任务的输入,如Word2Vec是第一个PLM。
- Fine-tune based 模型:预训练模型就是下游任务模型,模型参数也会更新,就是Pre-train Whole Model,如GPT、BERT等。
语言预训练模型梳理: BERT & GPT & T5 & BART
总结从T5、GPT-3、Chinchilla、PaLM、LLaMA、Alpaca等近30个最新模型
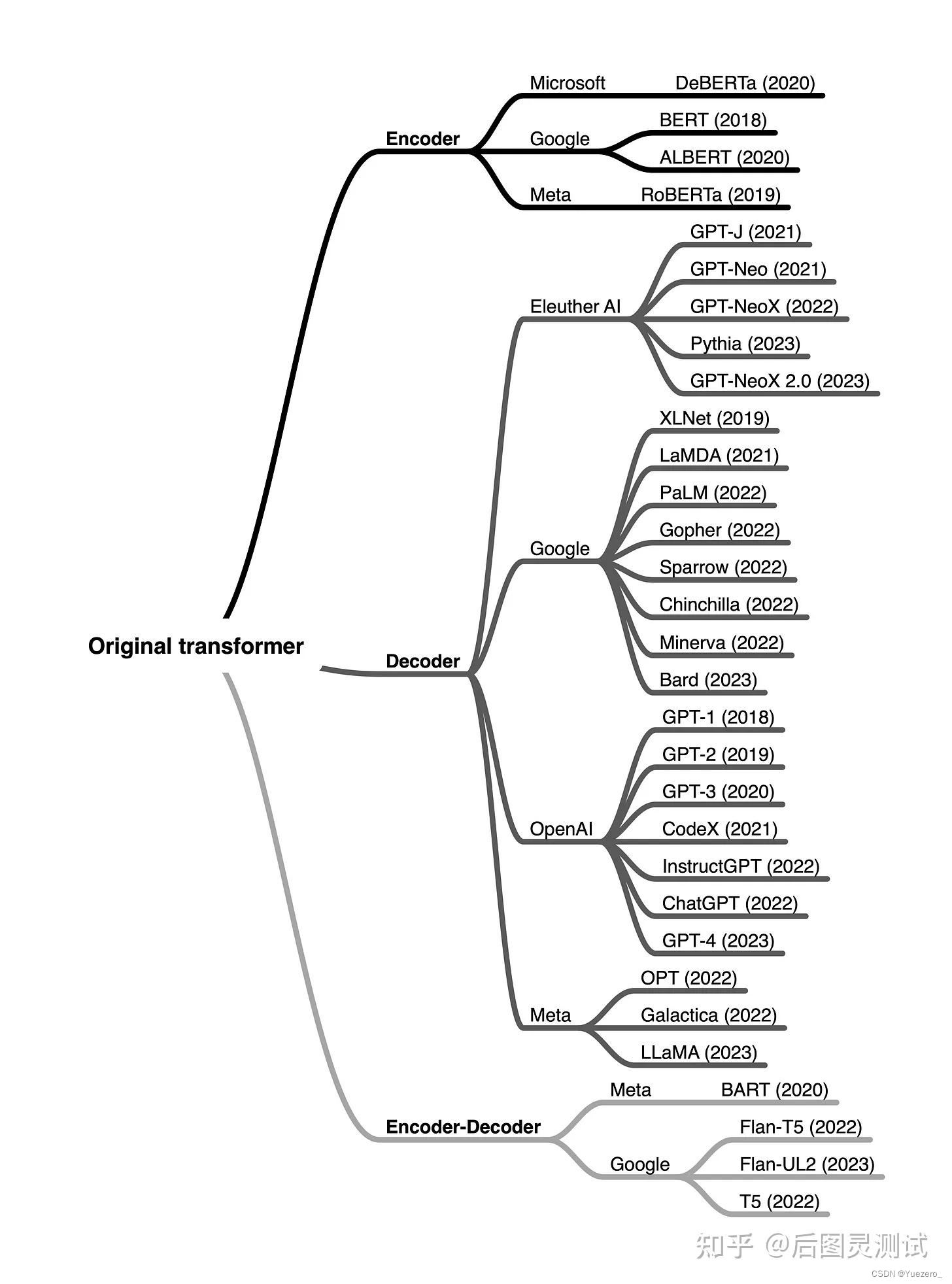
[Transformer 101系列] 初探LLM基座模型-——encoder-only,encoder-decoder和decoder-only
[Transformer 101系列] ChatGPT是怎么炼成的?
[Transformer 101系列] 多模态的大一统之路
Fine-tune based 模型
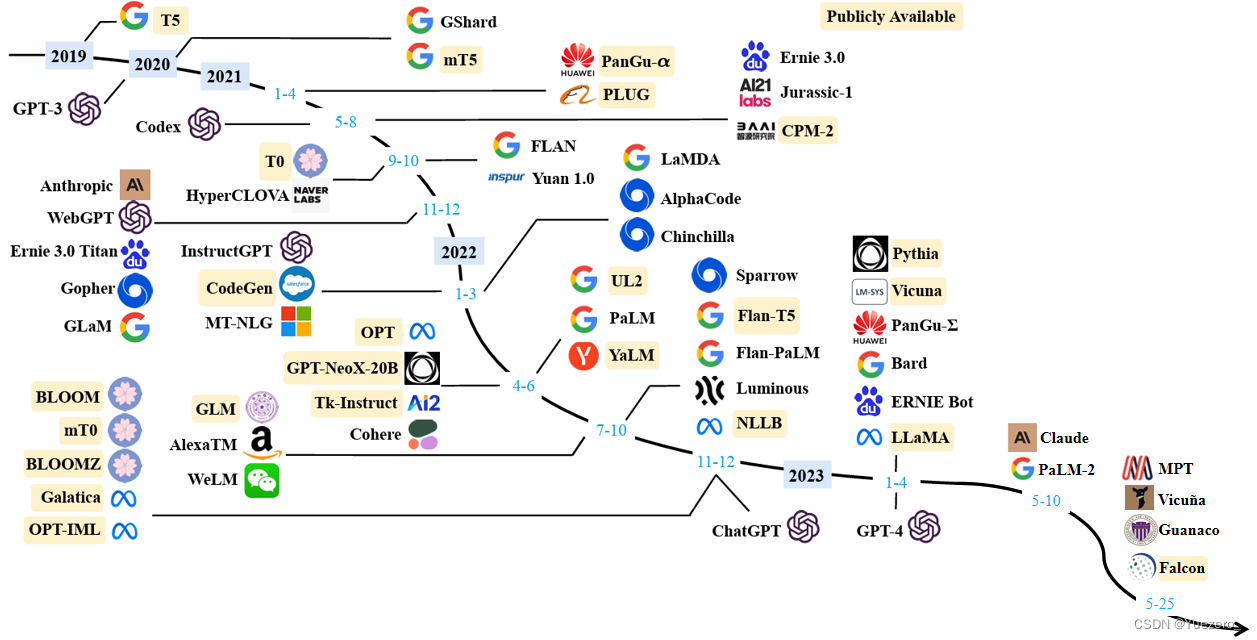
对于 Fine-tune based 模型 代表性的主要是:
Encoder-only(MLM模型/双向理解):BERT,RoBERTaDecoder-only(LM模型/生成任务): GPT系列,LLaMA,OPT,PaLM,LaMDA,CHINCHILLA,BLOOMEncoder-Decoder(Text2Text/MLM模型): T5, BART,GLM

43:00视频
https://web.stanford.edu/class/cs224n/slides/cs224n-2023-lecture9-pretraining.pdf
Encoder-only

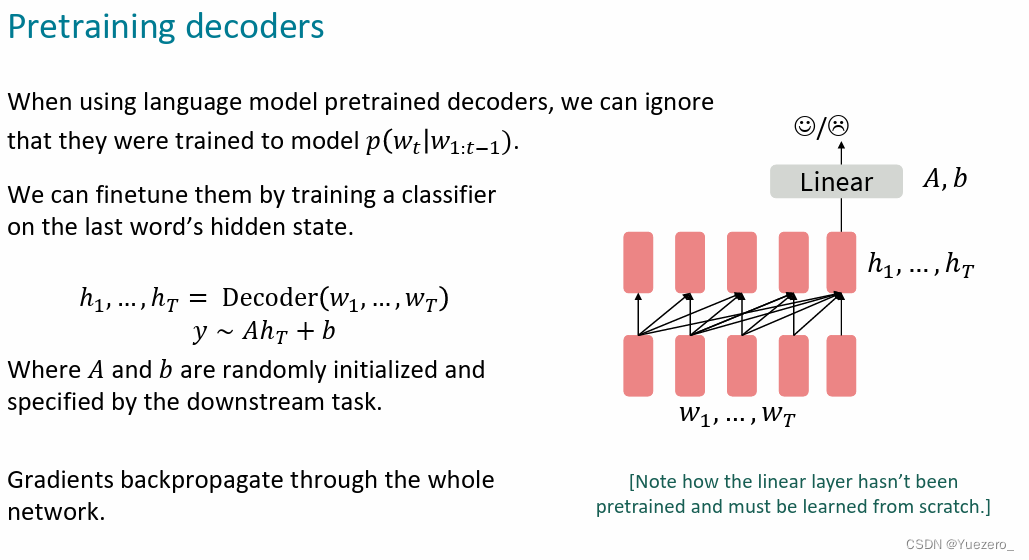
Decoder-only
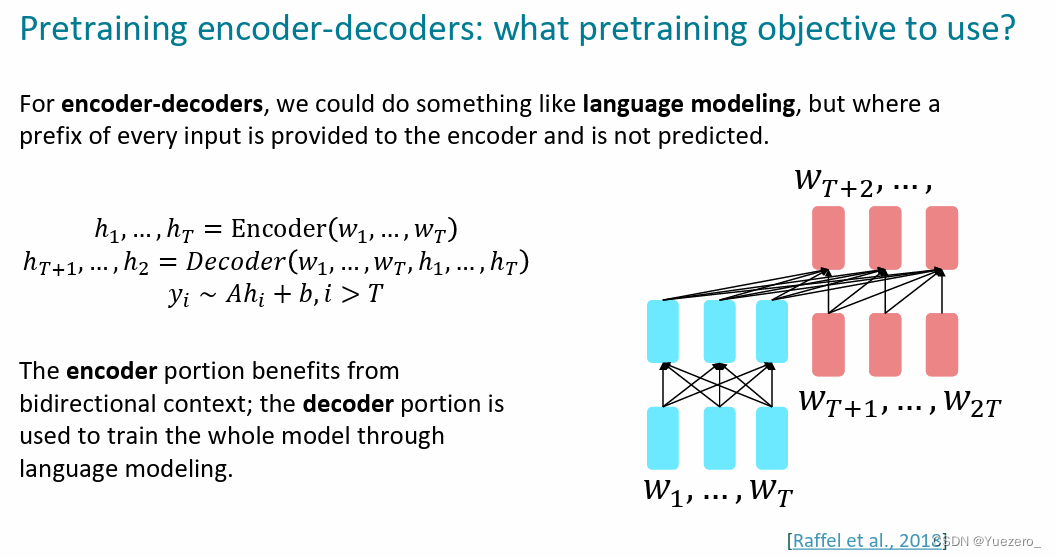
Encoder-Decoder
GPT:12层的transformer decoder 自回归从左到右 做生成预训练,作为生成式模型。
GPT-2:增大了GPT模型参数量和预训练数据量,展现出zero-shot(只需要prompt就可处理未见过的数据)和in-context learning(给出示例就可照猫画虎)能力。
BERT:transformer encoder 双向mask 完形填空预训练Mask LM,增加CLS token用于下游任务。
T5:transformer encoder-decoder架构完成text2text完成MLM预训练。
BART:encoder-decoder架构,相比与T5采用了多种给文本加噪声预训练。
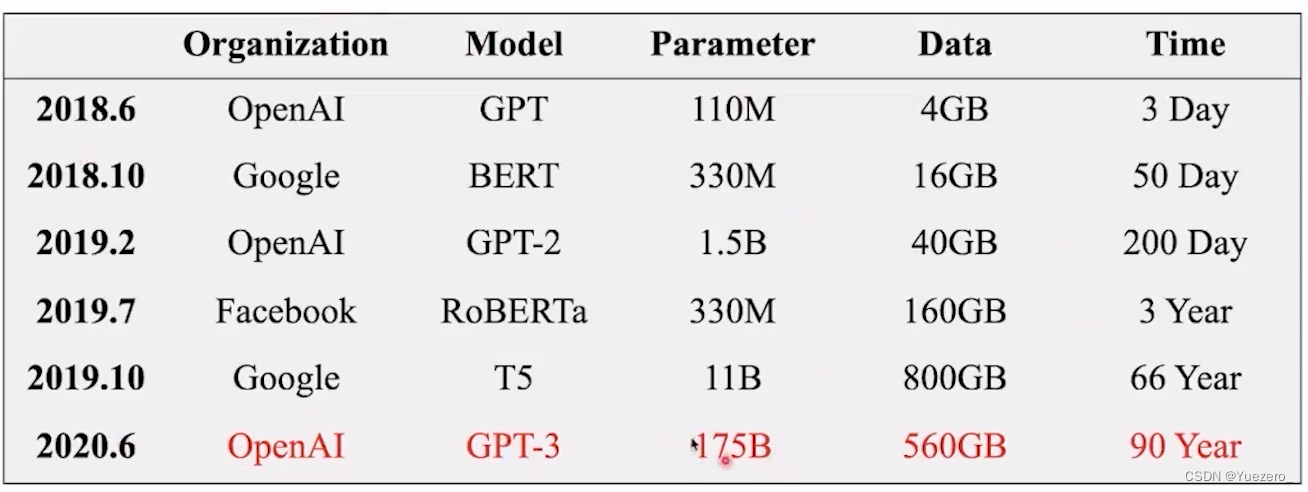
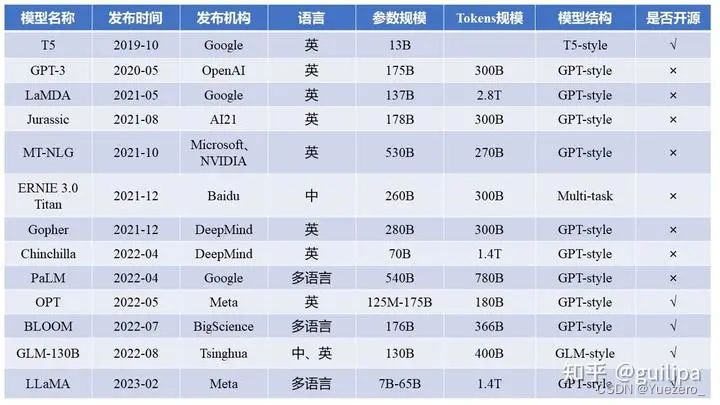
Finetuning
大模型微调范式:
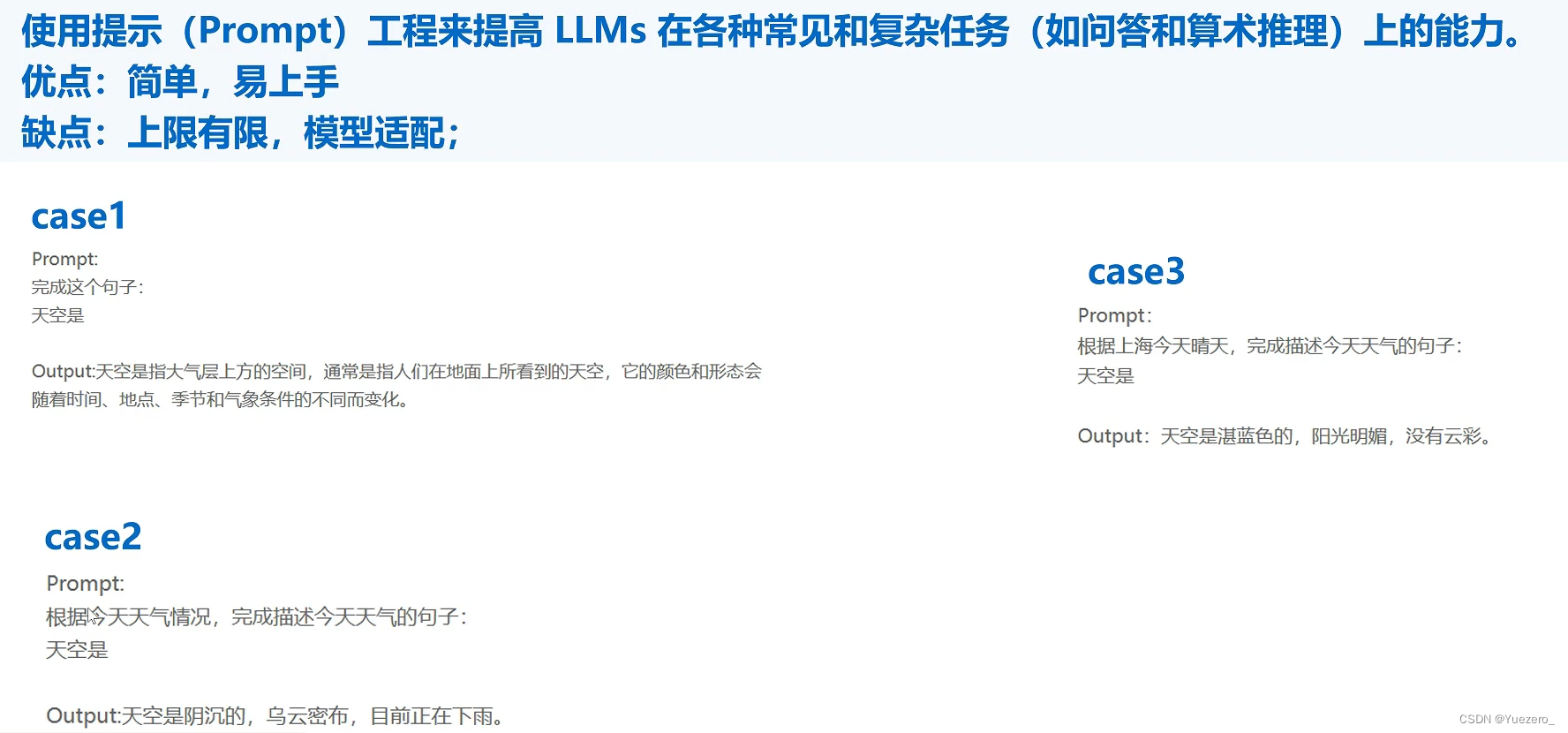
Prompt工程:
Lora微调:

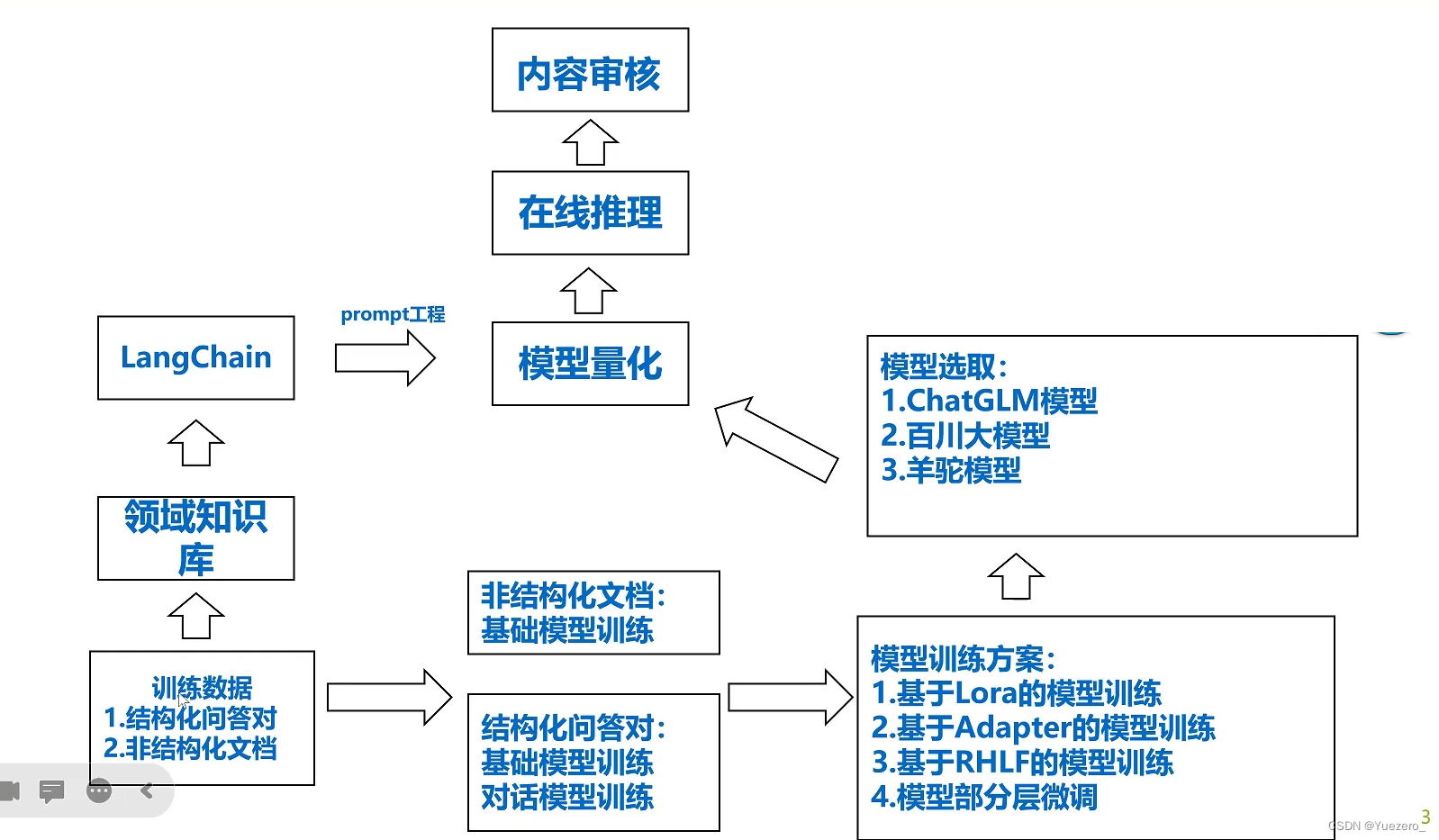
RAG:业务拿到数据后,一边构建知识库,一边微调大模型:

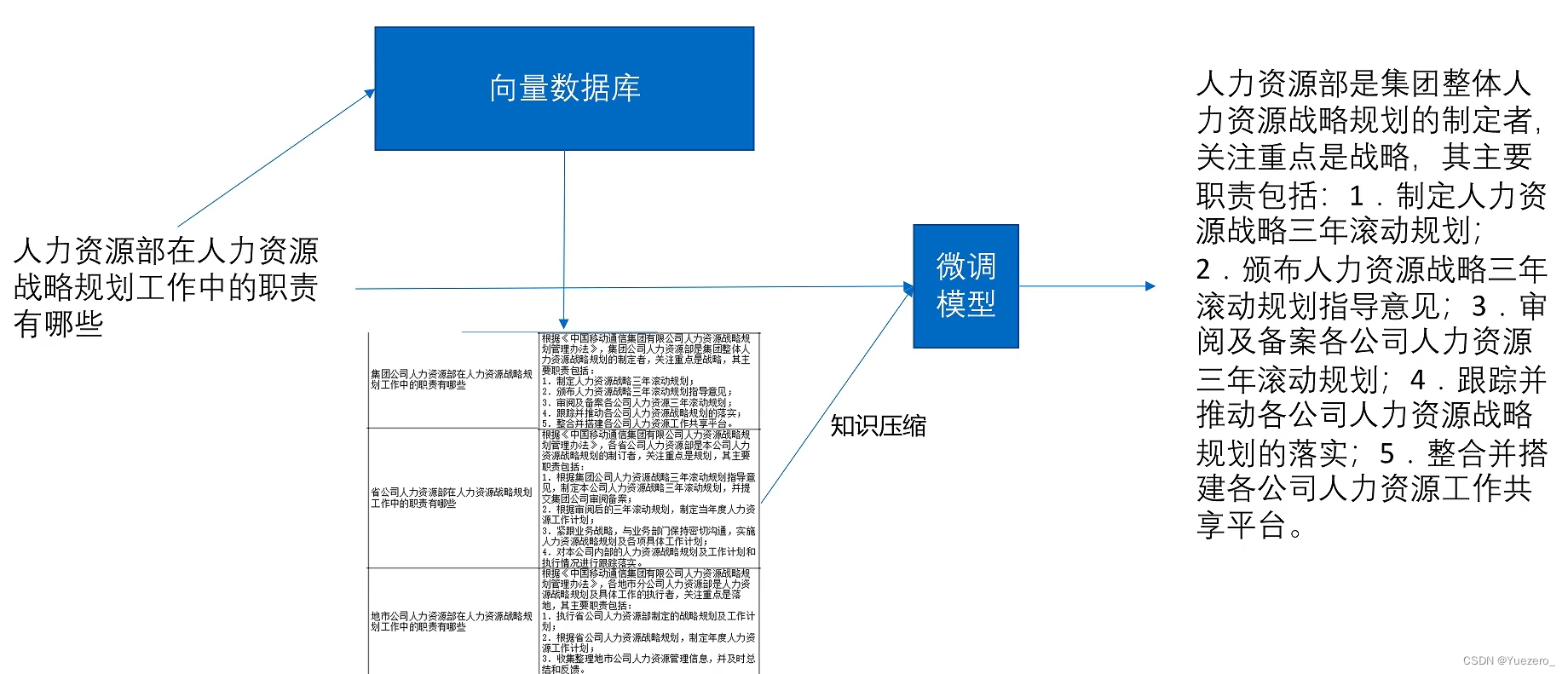
审核系统:
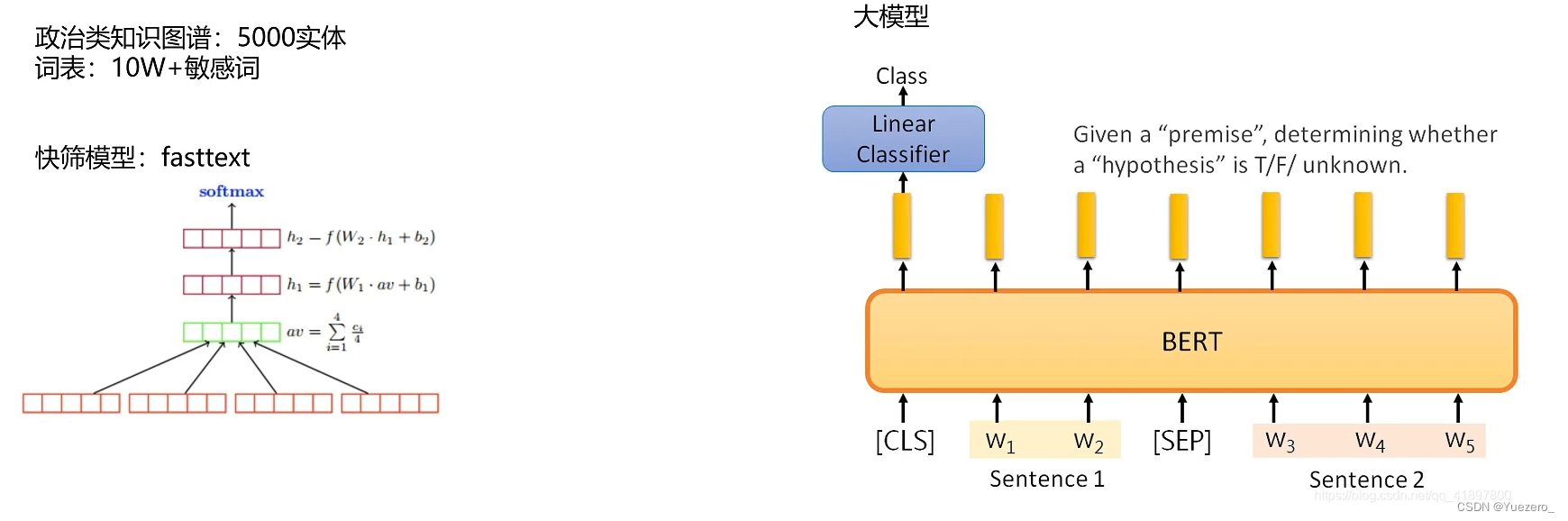
智能纠错:
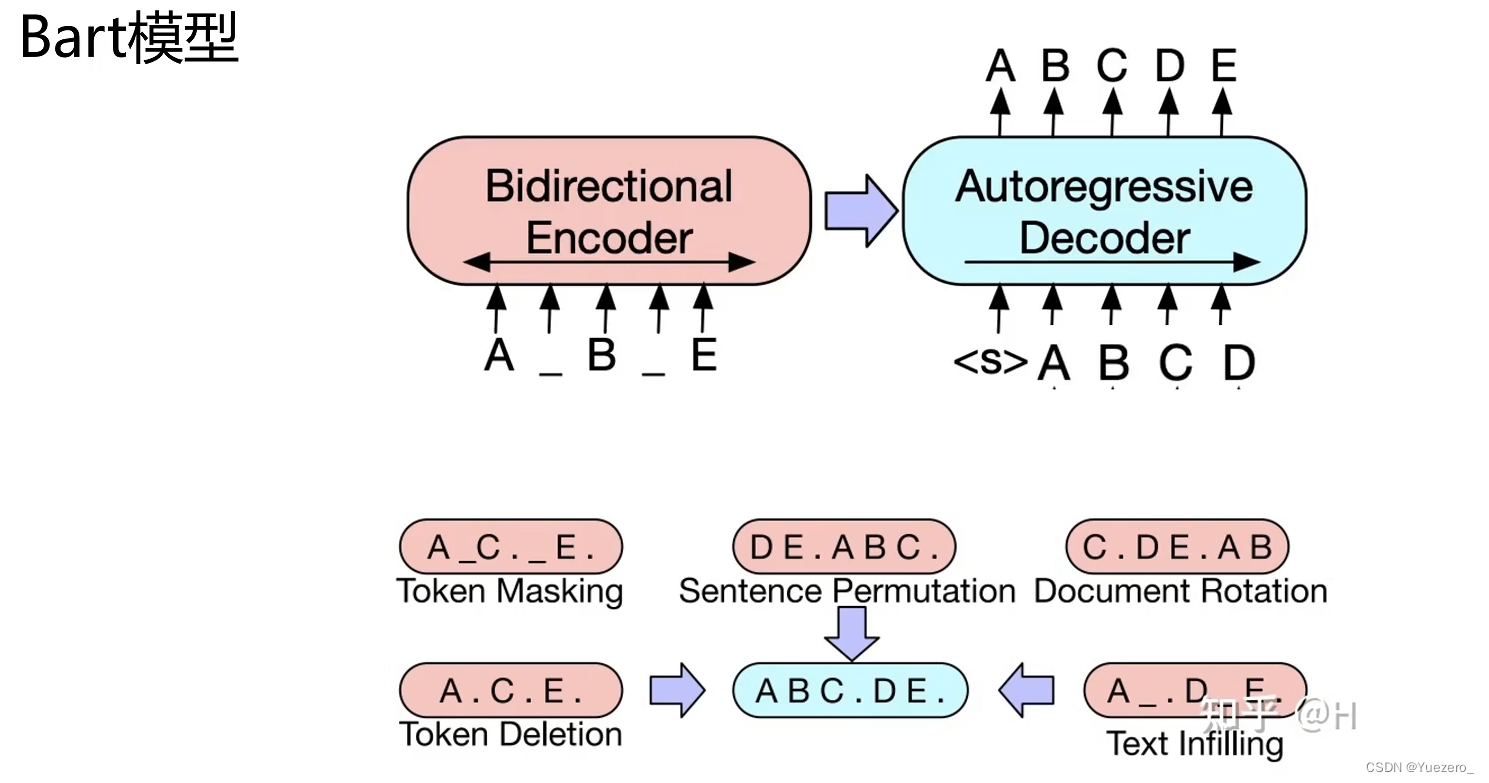
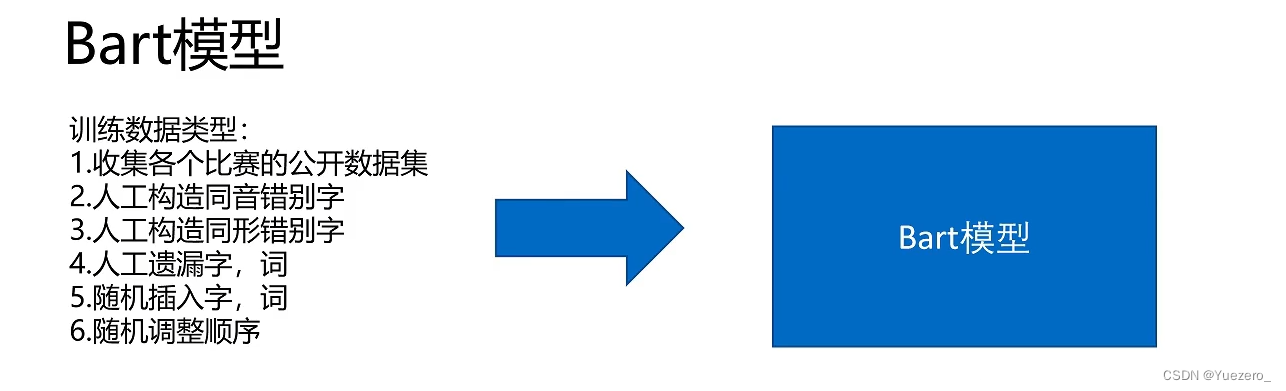
模型压缩加速:

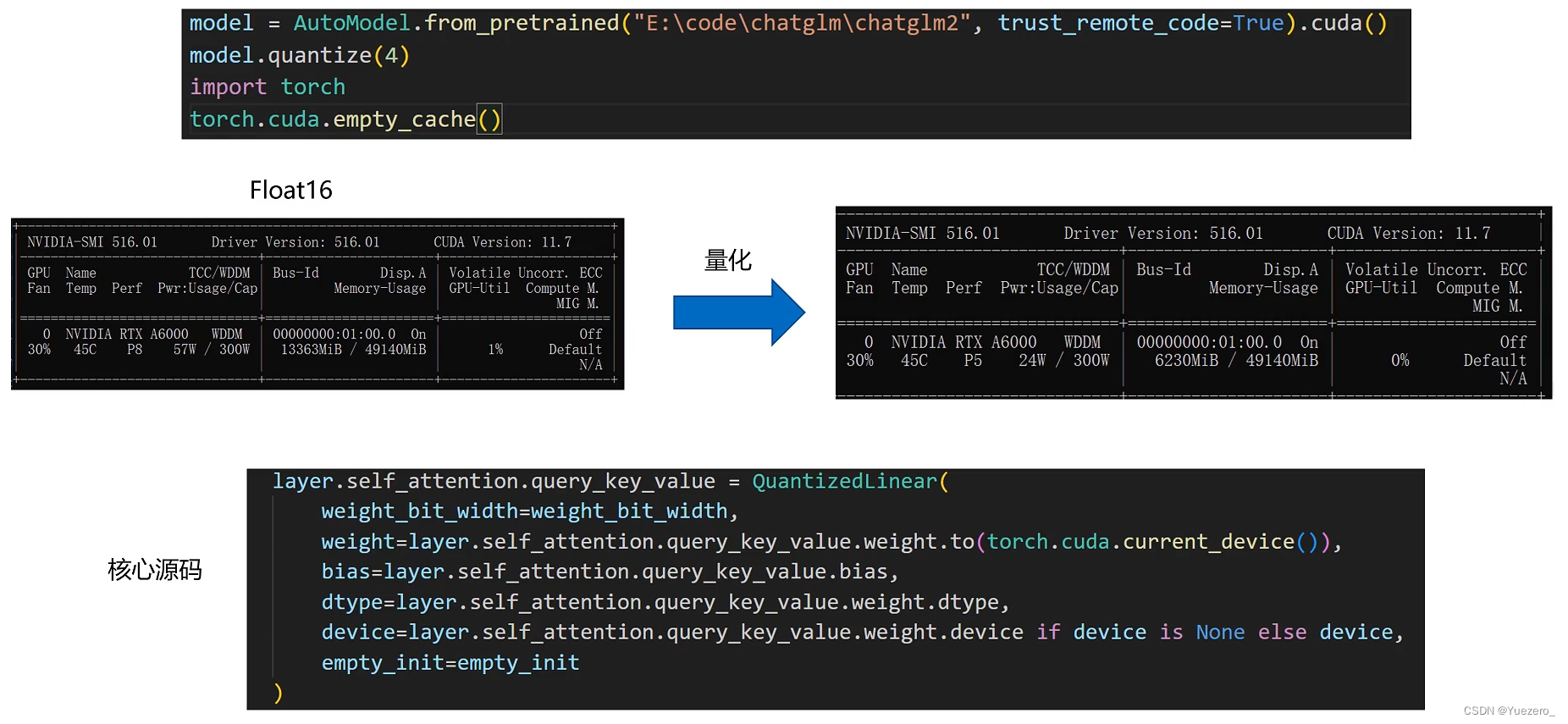
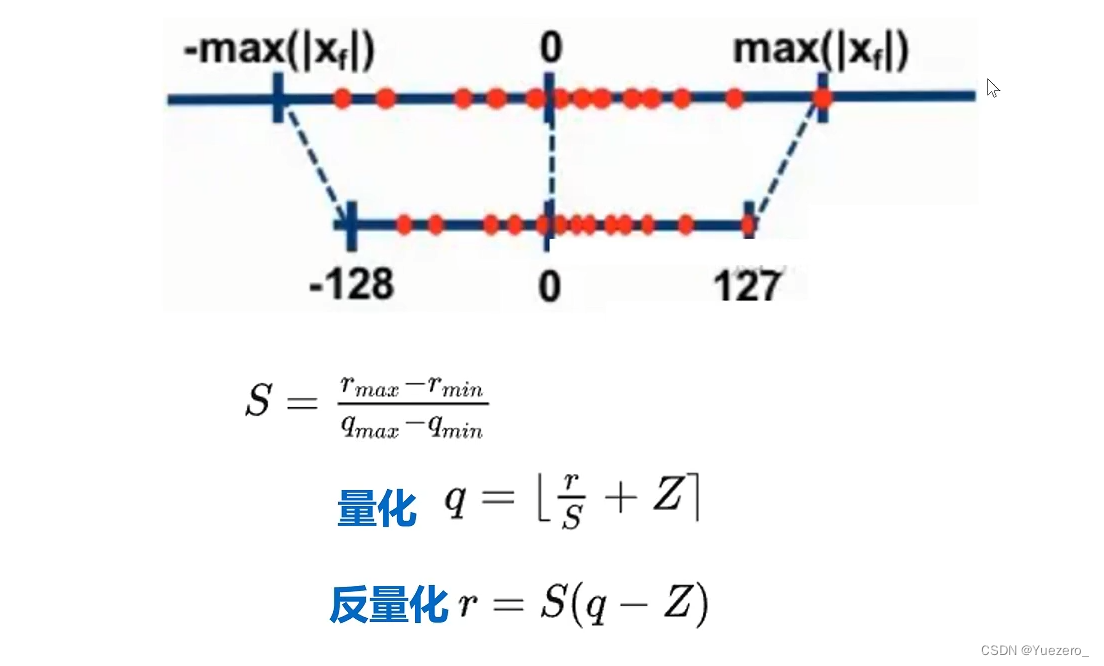
模型量化: