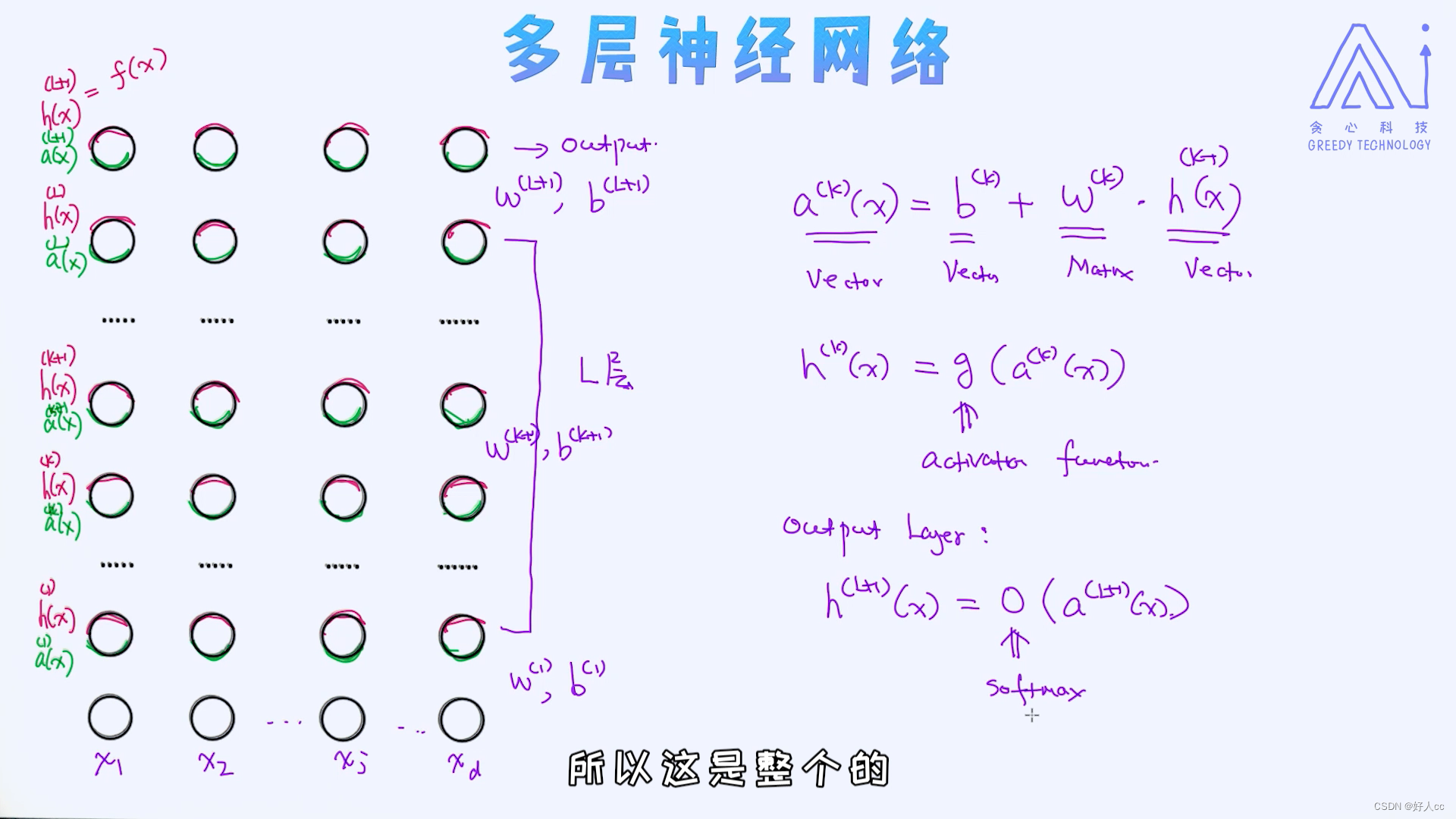
比较老的一篇论文,金属表面检测中的异常区域检测与定位
总结:提出了一个找模板图的方法,使用SIFT做特征提取,姿态估计看差异有哪些,Hough聚类做描述符筛选,仿射变换可视化匹配图之间的关系,提出一个搜索方法(降低图像分辨率、设定对比度和匹配数量阈值,指定排名表)。
找到这个模板图之后就跟异常图相减,得到残差图像,再提取SIFT关键点,这些关键点对应于图像的异常部位。

1 Abstract
这个实验使用了一个包含了不同角度和光照条件下的金属零件图像的数据集。我们的目标是通过从没有问题的标准图像中减去待检测图像,来找出待检测图像中的异常部分。这项任务具有挑战性,因为标准图像有多个,而且它们的角度和视角略有不同。我们只能从减法过程中得到残差图像,然后在这些残差图像中检测异常。我们的系统通过在相似图像库中寻找最佳标准图像来实现这一目标。我们还介绍了一种基于图像相似度的排序方法。这种方法在处理高对比度图像中的深色异常时表现出色。
2 Introduction
异常是指与标准表面特征不同的区域。由于存在大量不同的图像和照明条件,我们需要一种自动化系统来快速而准确地检测异常。计算机视觉在制造业中的视觉检测中有很大的潜力,并已经探索了多种技术。在这方面,有研究人员尝试结合尺度不变特征变换(SIFT)和支持向量机(SVM)来识别钢表面的异常,采用了一种投票策略。还有一些研究关注了不同类型的钢表面的异常检测和分类方法。
通常,要识别图像中的异常,需要先了解有关异常的先验信息。但在某些情况下,当对给定图像的异常没有先验知识时,研究人员尝试从不包含异常的标准图像中减去给定图像,以便找出异常区域,并进一步对这些异常进行分类。这种方法的主要挑战之一是,目前没有现有的显著性过滤器或缺陷检测器能够在这种数据情况下表现良好,因此需要探索新的方法来解决这个问题。
3 overview of the process
我们的目标是找到最适合作为参考的图像,以便通过减去它来获得尽可能完美的残差图像。这个最佳匹配的参考图像必须是没有异常的,并且必须与待检测图像具有相同的方向或视角。一旦得到了残差图像,我们可以使用多种方法来检测其中的异常部分。这个整个过程的大致概念如图2所示。图3展示了我们数据集中一些可能出现的异常情况的示例。


3.1 finding the best match
我们使用SIFT(尺度不变特征变换)来寻找最佳匹配图像。然而,仅仅使用SIFT可能无法得到最佳匹配,因此我们结合了其他图像处理技术,以帮助找到最相似的匹配。在接下来的部分中,我们将详细解释这个过程,它的整体框架如图4所示。简而言之,我们使用SIFT和其他图像处理方法来寻找与待检测图像最匹配的参考图像。
3.2 SIFT matching
SIFT(Scale Invariant Feature Transform)[9]是一种成熟的特征提取方法,被广泛用于计算机视觉的各个领域。SIFT特征提取过程捕捉图像中的关键信息,包括位置(XY坐标)、尺度和方向。这些信息在后续的SIFT匹配中用于找到图像中相似的特征点。SIFT匹配是一种基于关键点的匹配方法,旨在排除那些模糊程度过高的匹配点[10],以保证匹配的准确性。

3.3 Pose estimation
在图像处理中,姿态估计是一项重要的任务,它有助于去除异常值。我们需要计算两个图像之间的姿态差异,即确定它们之间的位置、尺度和方向差异。由于计算本质矩阵和基本矩阵的成本很高,我们使用了Lowe提出的算法。这个算法帮助我们估计一种变换,可以将两幅图像中的两组关键点对齐。此外,我们还计算了这些关键点之间的比例尺比例和方向差异。
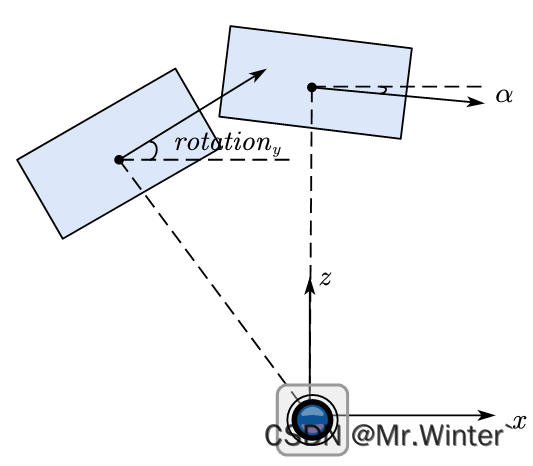
假设我们有两个关键点A和B,分别在图1和图2中,它们的参数是(x1,y1,S1,a1)和(x2,y2,S2,a2)。我们的目标是找出它们之间的位置、尺度和方向之间的差异。
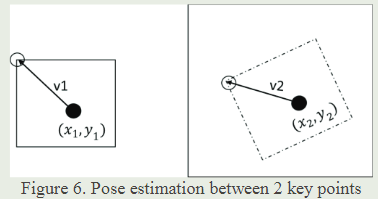
尺度比Sr和角度差Ar为:
![]()
向量V1和V2可以定义为:

3.4 Hough clustering
离群值通常可以通过使用Hough聚类方法来去除。在这个方法中,特征点在一个4D空间中进行投票,其中包括(x,y,比例,方向)这四个维度。与具有最大投票数的特征点对应的通常是正确的匹配点。其他的匹配点被认为是离群值,并且被丢弃。Hough空间可以被看作是包含了用于投票过程的粗略容器,这样无论特征点的变换如何,都可以近似地表示出来。图7展示了在去除离群值之后的匹配情况,这有助于提高匹配的准确性。

3.5 Affine transform
仿射变换有助于可视化两幅图像之间的匹配。我们将2D仿射变换拟合到正确匹配的潜在集合。拟合两组匹配的仿射变换由
仿射变换是一种有助于可视化两幅图像之间匹配关系的方法。我们将2D仿射变换应用到正确匹配的一组点上,以找到适合将这些匹配点从一个图像映射到另一个图像的变换。通过这个变换,我们可以将两幅图像的对应点对齐,从而更好地理解它们之间的关系。

使用仿射变换,我们还可以计算匹配点之间的残差,即它们之间的差异或偏移。通过分析这些残差,我们可以从潜在的匹配项列表中找到最佳匹配项,这可以帮助我们更准确地确定图像中的对应关系。
3.6 Search method
这个数据集包含了将近18000张图像,每张图像的分辨率都是2448x2050像素。由于原始图像分辨率很高,每张图像生成了超过2000个SIFT关键点,这导致匹配操作需要很长的计算时间。为了加快搜索速度,我们对图像进行了调整,将像素分辨率降低了90%。此外,我们还根据图像的对比度和匹配数量设置了一些阈值,以排除数据集中的不同图像。对于图像池中的每一张图像,我们计算了其SIFT特征,并尝试将其与缺陷图像进行匹配。匹配的数量以及匹配的标准差会在排名表中进行更新。这些步骤旨在提高匹配速度并筛选出最相关的图像。
3.7 Ranking table
在找到了所有潜在的匹配项之后,我们使用一个排名表来确定最佳的匹配项。这个排名表考虑了两个参数:Hough聚类后的匹配数和残差计算的标准差。我们为每个参数分配了一个排名,使得最佳的匹配项具有最高的排名。然后,我们将这两个参数的秩相加,以得到净秩最高的匹配项,这将被认为是最佳匹配。简而言之,这个过程用于确定最相关的匹配项,考虑了多个参数以提高匹配的准确性。

![]()
lbm是最佳匹配的秩,Rm和Ro分别是匹配次数和标准差的秩。排名表的总体框图如图8所示,排名表显示了图3(e)中的前5个匹配项

3.8 Anomaly detection
一旦我们找到了最佳匹配,我们将它从异常图像中减去,这样我们得到了残差图像。接下来,我们在这个残留图像上寻找SIFT关键点,因为这些关键点可能指向图像中的异常部分。这个整个过程可以通过图9中的框图来解释和说明。

4 EXPERIMENTAL
在这一部分,我们将探讨数据集的分布以及两个主要实验的结果。这两个实验分别是搜索结果(实验1)和异常检测方法(实验2),我们将比较它们的结果。简单来说,我们将研究数据集的特点,并对实验1和实验2的结果进行比较分析。
4.1 Data set
这个数据集是作为自动视觉检测过程的一部分而获取的[8]。在这个检测过程中,预定义的程序在事先规定的观察点和照明条件下拍摄了不同金属部件的图像。每个批次中捕获了超过490张图像。在这个实验中,我们使用的数据是实际数据集的一个子集,其中包含了大约18600张图片。每张图片的分辨率都是2448x2050像素。这些图像中包含大约5种主要的表面异常,包括熔化、加金属、划痕、磨损和阴影。然而,我们的目标是在一般情况下检测异常,而不是识别异常的具体类型。所以本文的范围不包括对异常类型的具体识别。
4.2 Experiment 1
实验1的目标是比较使用不同匹配方法的结果,具体比较了"最佳匹配搜索"和欧氏距离匹配方法。在实验中,我们生成了搜索和SIFT匹配的排名表。图10展示了异常图像与通过不同搜索方法找到的最佳匹配之间的重叠情况。 首先,使用SIFT搜索时,虽然找到了正确的图像,但由于存在相似的图像,所以找到的匹配并不完全相同。这在图10(b)中可见,最佳匹配和原始图像之间存在一些偏移,这些偏移用白色圈圈出。
相比之下,欧氏距离方法无法为我们数据集中的大多数图像找到正确的匹配。如图10(c)所示,两幅图像之间存在明显的偏移,同样用白色圈圈出。而使用SIFT与排名表的匹配方法在查找相同的匹配时提供了最精确的结果。图10(d)展示了最佳匹配和原始图像之间的完美重叠,没有任何偏移。这意味着SIFT与排名表的匹配方法在实验1中表现得最好。

图10所示。不同搜索方法的比较。(a)原图片(b)正常SIFT匹配(第一个最佳匹配)(c)最小欧几里德距离搜索 (d)SIFT使用排名表
4.3 Experiment 2
在实验1中,我们首先找到了给定缺陷图像的最佳匹配图像。接着,我们继续寻找图像中的异常区域。这些异常区域是通过执行一个简单的操作得到的,即将最佳匹配图像与原始图像相减,得到残差图像。然后,我们从残差图像中提取SIFT关键点,这些关键点对应于图像中的异常区域。图11(h)展示了这个过程的结果,残差图像中生成的SIFT关键点对应于图像中的异常部分。
在这个实验中,我们还将我们的方法与四种成熟的显着性检测方法进行了比较,这些方法包括显著性优化、显著性滤波器、测地线显著性和流形排序,以评估我们算法的性能。显著性优化的工作原理是通过提取背景连通性等低层次信息来提取显著性图。测地线显著性依赖于背景和连通性先验提取图像的显著性图。显著性滤波方法将图像分解成唯一的元素,利用这些元素的唯一性、空间分布和对比度来获得显著性图。 流形排名采用背景和前景线索对图像元素(像素和区域) 进行排名。这些显着性检测方法的工作原理是提取图像中显著性区域的显著性图。然后,我们使用这些方法来提取残差图像(图11(c)),以获得潜在的异常区域。图11(d-g)显示了通过这些不同方法提取的潜在异常区域的结果。
总的来说,这个实验的目的是通过比较不同方法来提取异常区域,以评估我们的方法的性能。这些方法包括了使用SIFT关键点的方法和使用显着性检测方法的方法。图11中展示了这些方法的结果。

虽然所建立的方法在我们的数据集的某些情况下工作得很好,结果在一般情况下是不强大的,由于数据集的复杂性。
相反,我们的算法在一个明亮的图像范围内工作得很好如图11(h)所示。可以观察·到,即使异常区域是模糊的,该方法仍然有效。(图11 (a):第2行和第5行的图像)。总体而言,计算结果对异常区域的定位是比较准确的。该算法也适用于带有明亮异常的低对比度图像,如图12(b)所示,但在异常和背景之间的对比度差异非常小的情况下,该算法会失败(图12 (a))。
尽管我们的方法在某些特定情况下在数据集上表现良好,但在一般情况下并不十分强大,这是因为数据集的复杂性。
然而,在明亮的图像范围内,我们的算法表现出色,这可以从图11(h)中看出。特别值得注意的是,即使异常区域模糊不清,该方法仍然能够有效地工作(如图11(a)所示,第2行和第5行的图像)。总的来说,我们的算法能够相对准确地定位异常区域,特别适用于具有明亮异常的低对比度图像,如图12(b)所示。然而,在异常区域与背景之间的对比度非常小的情况下,该算法可能会失败,如图12(a)所示。这表明我们的方法在处理不同类型的异常和图像条件时具有一定的局限性。

5 CONCLUSION
我们已经开发了一种异常区域检测器,它结合了现有技术,用于在我们的数据集中定位异常。我们还引入了一种基于最佳匹配的图像排序方法。这个算法在处理具有暗异常的图像时表现非常出色,优于目前存在的显著性滤波器。
通常情况下,当异常区域与背景之间的差异明显时,我们的算法能够很好地工作。然而,如果异常与背景之间的对比度差异非常小,那么我们的算法可能不会产生相似的结果。这意味着我们的方法在处理对比度差异较大的异常情况时效果较好,但在对比度差异较小的情况下可能不太适用。
6 REFERENCE
[1] B. Suvdaa, J. Ahn and J. Ko (2012), “steel surface anomaliesdetection and classification using sift and voting strategy”nternational ournal of software engineering and its applications.vol. 6,no.2.2012.
[2] Neogi Nirbhar, Mohanta Dusmantak. Dutta Pranabk. Reviewof vision-based steel surface inspection systems, EURASIP Journalon Image and Video Processing,2014 DOI: 10.1186/1687-52812014-50
[3] Jiwhan Kim, Dongyoon Han, Yu-Wing Tai, and Junmo Kim."Salient Region Detection via High-Dimensional Color Transformand Local Spatial Support", IEEE Transactions on ImageProcessing, Vol. 25, No. 1, pp. 9-23, Jan. 2016.
[4] Wangjiang Zhu, Shuang Liang, Yichen Wei, and Jian Sun.Saliency Optimization from Robust Background Detection. nCVPR.2014.
[5] F. Perazzi, P. Krahenbuhl, Y. Pritch, and A. Hornung. Saliencyfilters: Contrast based filtering for salient region detection.lnCVPR.2012.
[6] Y.Wei, F.Wen. W.Zhu, and J. Sun. Geodesic saliency usingbackground priors.In ECCV.2012.
[7] C. Yang, L. Zhang, H. Lu, X. Ruan, and M.-H. Yang. Saliencydetection via graph-based manifold ranking. In CVPR. 2013.
[8] Limited disclosure due to confidentiality reasons
[9] D.G Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision. 60(2):91-1102004
[10] Lowe. D.G.."Object recognition from local scale-invariantfeatures," in Computer Vision, 1999. The Proceedings of theSeventh IEEE International Conference on, vol.2, no., pp.11501157 wo1.2.1999.
7 Python
首先加载正常图像和待检测图像,然后使用SIFT检测器提取其特征。接下来,我们使用KMeans对正常图像的SIFT描述符进行聚类,然后将待检测图像的描述符映射到最近的簇中心。最后,我们找到匹配的关键点索引并在匹配图像中绘制它们。
"""
Time:2023/9/19 10:32
Author:ECCUSYB
"""
import cv2
import numpy as np
from sklearn.cluster import KMeans
from sklearn.neighbors import NearestNeighbors# 加载正常图像和待检测图像
normal_image = cv2.imread('dataset/mvtec_anomaly_detection/bottle/train/good/000.png', cv2.IMREAD_GRAYSCALE)
query_image = cv2.imread('dataset/mvtec_anomaly_detection/bottle/test/broken_large/000.png', cv2.IMREAD_GRAYSCALE)# 初始化SIFT检测器
sift = cv2.SIFT_create()# 提取SIFT特征
kp1, des1 = sift.detectAndCompute(normal_image, None)
kp2, des2 = sift.detectAndCompute(query_image, None)# 使用KMeans聚类对SIFT描述符进行筛选
n_clusters = 100 # 设置聚类数
kmeans = KMeans(n_clusters=n_clusters)
kmeans.fit(des1)
cluster_centers = kmeans.cluster_centers_# 使用KMeans模型将描述符映射到最近的簇中心
labels1 = kmeans.predict(des1)
labels2 = kmeans.predict(des2)# 创建一个k-d树来进行最近邻搜索
nn = NearestNeighbors(n_neighbors=1)
nn.fit(cluster_centers)# 找到待检测图像中每个描述符最近的簇中心
distances, indices = nn.kneighbors(cluster_centers[labels2], n_neighbors=1)# 找到匹配的正常图像的关键点索引
matching_indices = np.unique(indices)# 绘制匹配的关键点
matches_img = cv2.drawMatches(normal_image, kp1, query_image, kp2,[cv2.DMatch(i, i, 0) for i in matching_indices],outImg=None)# 显示匹配图像
cv2.imshow("Matches", matches_img)
cv2.waitKey(0)
cv2.destroyAllWindows()

8 Other
低对比度图像:指图像中不同区域之间的亮度或颜色差异较小,导致图像中的细节不太明显或难以分辨的情况。这种图像通常在光照不足、逆光或场景中有很多均匀颜色或灰度的情况下出现。假设你在一个室内房间中拍摄了一张照片,房间的照明非常暗,但房间内有一些物体和家具。由于光线不足,照片中的物体可能看起来灰暗且细节不清晰。这种情况下,由于光线不足,图像的对比度较低,物体的边缘和细节可能不太明显,导致低对比度图像。




![[Linux入门]---进程的概念](https://img-blog.csdnimg.cn/f00dee03fc7945da928cbd7bbc175ed2.png)