环境
微调框架:LLaMA-Efficient-Tuning
训练机器:4*RTX3090TI (24G显存)
python环境:python3.8, 安装requirements.txt依赖包
一、Lora微调
1、准备数据集
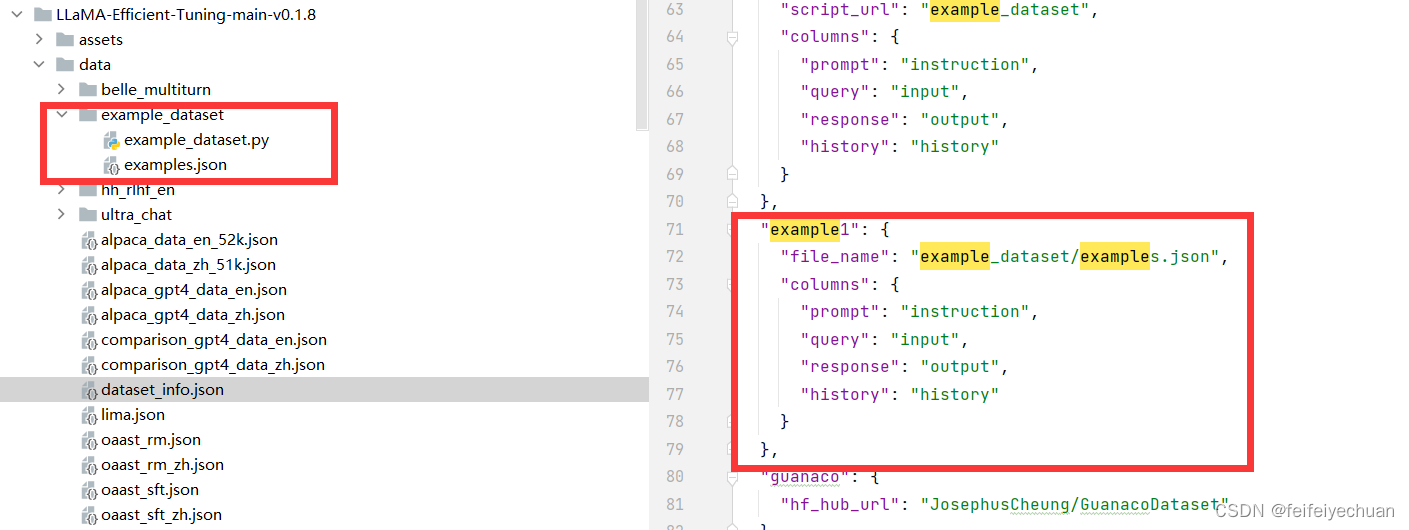
2、训练及测试
1)创建模型输出目录
mkdir -p models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model
2)创建deepspeed配置文件目录
mkdir -p models/baichuan2_13b_chat/deepspeed_config
3)创建deepspeed配置文件
vi models/llama2_7b_chat/llama-main/deepspeed_config/llama2_7b_chat_muti_gpus_01_epoch10.json
{"bf16": {"enabled": true},"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupDecayLR","params": {"last_batch_iteration": -1,"total_num_steps": "auto","warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 2e9,"stage3_max_reuse_distance": 2e9,"stage3_gather_16bit_weights_on_model_save": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 2000,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
4)训练模型
deepspeed --num_gpus 2 --master_port=9902 src/train_bash1.py \--stage sft \--model_name_or_path models/llama2_7b_chat/origin_model/Llama-2-7b-chat-hf \--do_train \--dataset example1 \--template llama2 \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model \--overwrite_cache \--per_device_train_batch_size 2 \--gradient_accumulation_steps 2 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 500 \--learning_rate 5e-5 \--num_train_epochs 100.0 \--plot_loss \--bf16 \--deepspeed models/llama2_7b_chat/llama-main/deepspeed_config/llama2_7b_chat_muti_gpus_01_epoch10.json

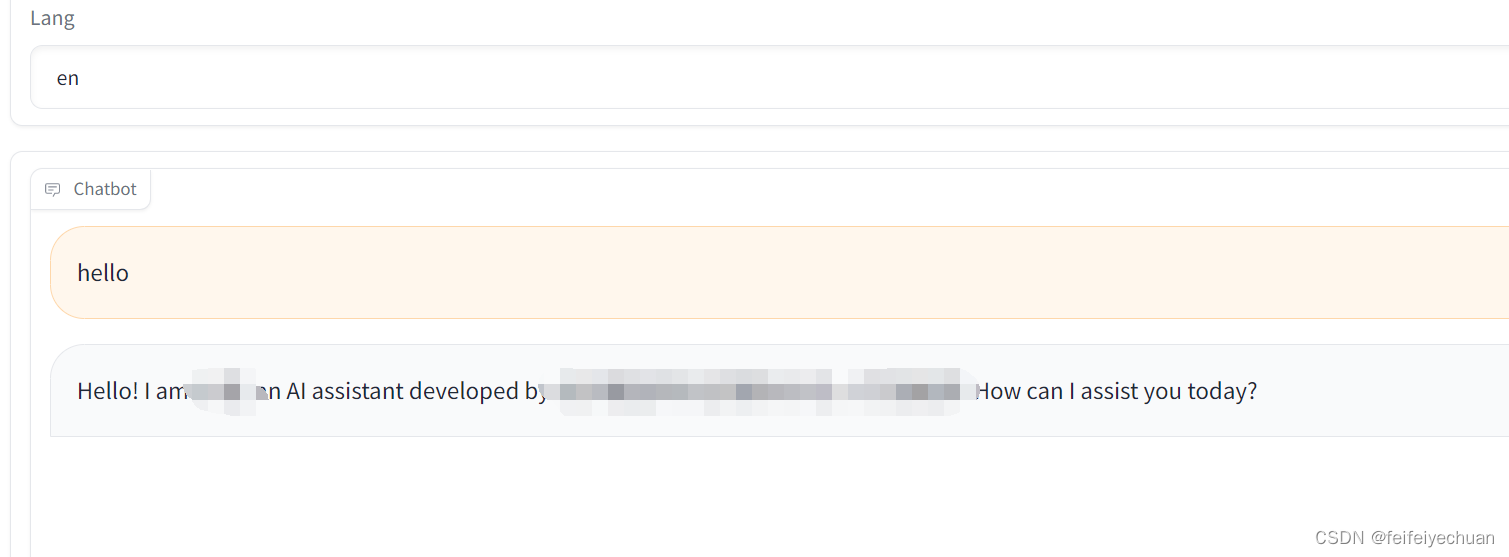
- 测试模型
python src/cli_demo.py \--model_name_or_path models/llama2_7b_chat/origin_model \--template baichuan2 \--finetuning_type lora \--checkpoint_dir models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model
6)启动服务
python src/web_demo1.py \--model_name_or_path models/llama2_7b_chat/origin_model/Llama-2-7b-chat-hf \--template llama2 \--finetuning_type lora \--checkpoint_dir models/llama2_7b_chat/llama-main/train_models/llama2_7b_chat_muti_gpus_01_epoch10/train_model




![[Linux入门]---进程的概念](https://img-blog.csdnimg.cn/f00dee03fc7945da928cbd7bbc175ed2.png)