AI视野·今日CS.Robotics 机器人学论文速览
Tue, 19 Sep 2023 (showing first 100 of 112 entries)
Totally 112 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚In-Hand Object Rotation, RotateIt 提出了一种基于视觉与触觉的物体旋转朝向的方法。在模拟环境中训练,同时部署在真实环境中测试。(from 伯克利)

同时提出了一个Vision tactile Transformer,实时在线预测目标的形状与物理属性:

模拟数据集形状精选于各个开源平台:

website: https://haozhi.io/rotateit/
📚TransTouch, 融合稀疏触觉信息的透明物体重建(from 清华大学叉院 Li Yi, and Rui Chen)
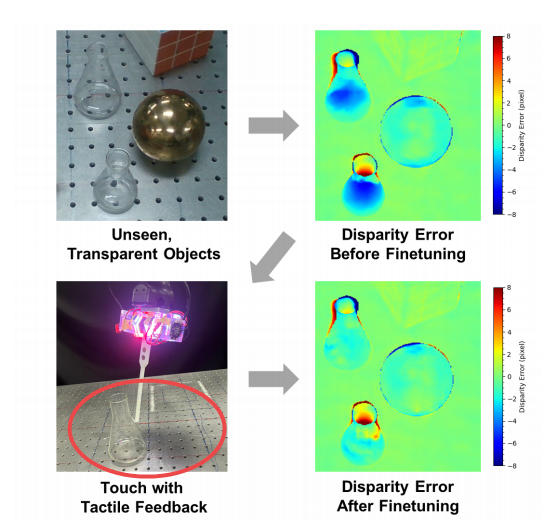
本研究的流程,用触觉点来校准深度图像预测:
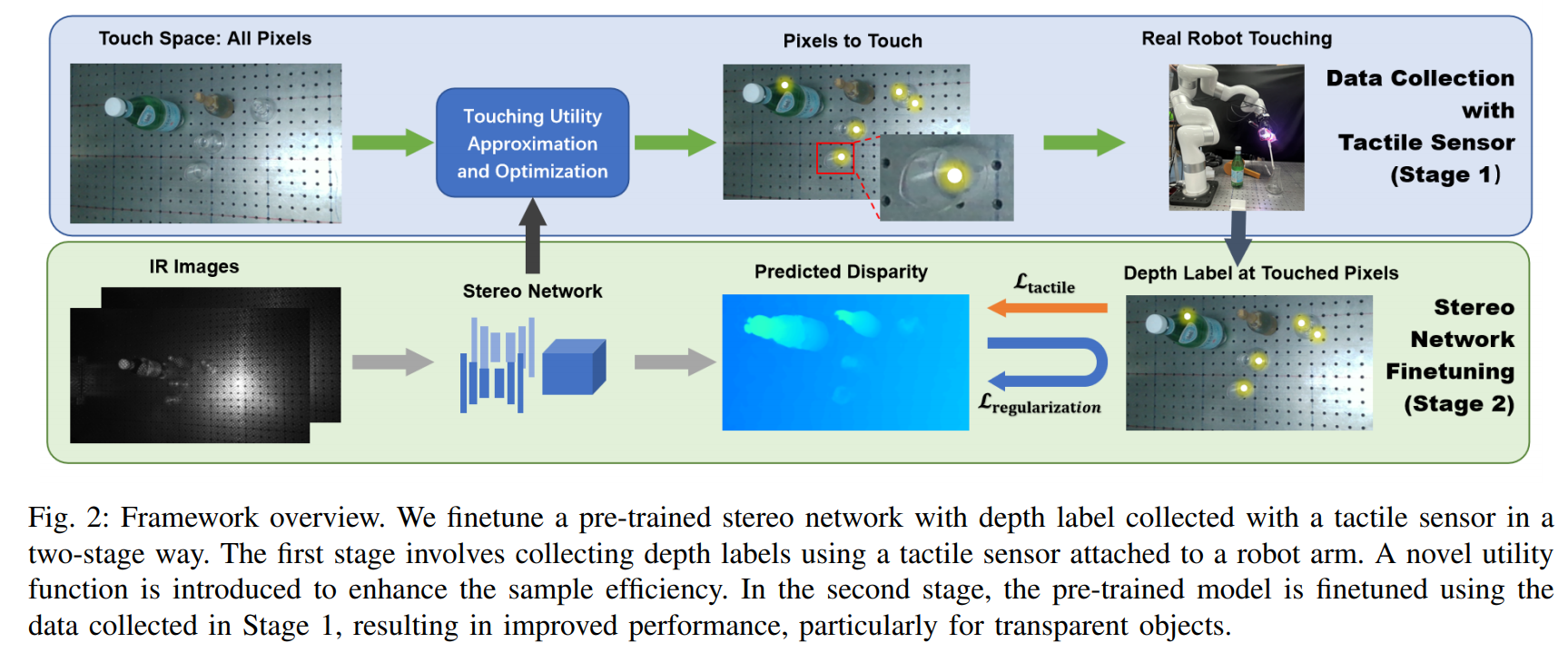
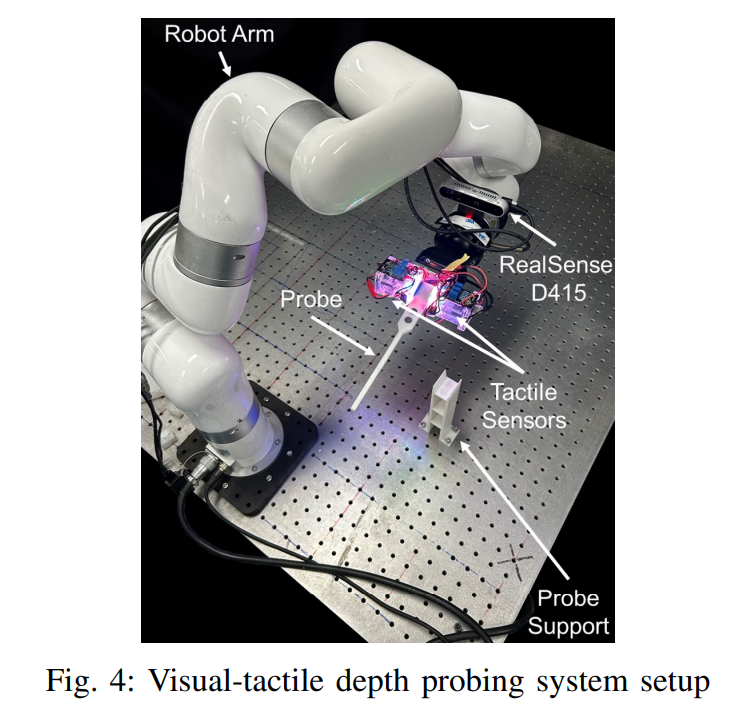
实验设置与数据集:

YiLi: https://ericyi.github.io/
📚Grasp-Anything, 用于基础模型的大规模抓取数据集。(from FPT Software AI Center)
Grasp-Anything excels in diversity and magnitude, boasting 1M samples with text descriptions and more than 3M objects, surpassing prior datasets.

website:https://grasp-anything-2023.github.io/
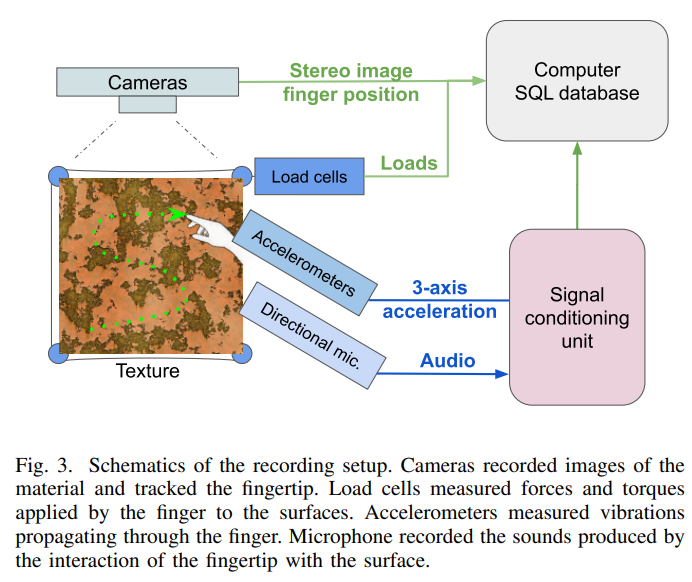
📚Finger Interaction with Textured Surfaces, 精确的触觉、听觉与视觉数据集,采集与人手指与纹理接触运动过程中(from 帝国理工)
实验设计与采集的多模态数据:

--- ## Daily Robotics Papers
| General In-Hand Object Rotation with Vision and Touch Authors Haozhi Qi, Brent Yi, Sudharshan Suresh, Mike Lambeta, Yi Ma, Roberto Calandra, Jitendra Malik 我们推出了 RotateIt,这是一个通过利用多模态感官输入实现基于指尖的物体沿多个轴旋转的系统。我们的系统经过模拟训练,可以访问地面真实的物体形状和物理属性。然后我们将其提炼出来,以对真实但嘈杂的模拟视觉触觉和本体感觉输入进行操作。这些多模态输入通过视觉触觉转换器融合,从而能够在部署过程中在线推断对象形状和物理属性。 |
| Prompt a Robot to Walk with Large Language Models Authors Yen Jen Wang, Bike Zhang, Jianyu Chen, Koushil Sreenath 在大量互联网规模数据上预先训练的大型语言模型法学硕士展示了跨不同领域的卓越能力。最近,人们对部署机器人学法学硕士的兴趣日益浓厚,旨在在现实世界环境中利用基础模型的力量。然而,这种方法面临着重大挑战,特别是在将这些模型建立在物理世界中以及生成动态机器人运动方面。为了解决这些问题,我们引入了一种新颖的范例,其中我们使用从物理环境收集的少量镜头提示,使法学硕士能够自动回归为机器人生成低级控制命令,而无需特定于任务的微调。在各种机器人和环境中进行的实验验证了我们的方法可以有效地促使机器人行走。因此,我们说明了法学硕士如何能够熟练地充当动态运动控制的低级反馈控制器,即使在高维机器人系统中也是如此。 |
| OptiRoute: A Heuristic-assisted Deep Reinforcement Learning Framework for UAV-UGV Collaborative Route Planning Authors Md Safwan Mondal, Subramanian Ramasamy, Pranav Bhounsule 无人机能够勘测广阔的区域,但其操作范围受到电池容量有限的限制。使用无人地面车辆 UGV 部署移动充电站可显着延长无人机的续航时间和有效性。然而,优化无人机和无人地面车辆的路线(称为无人机无人地面车辆协作路线问题)提出了巨大的挑战,特别是在充电位置的选择方面。在本文中,我们利用强化学习 RL 来确定最佳充电位置,同时采用约束编程来确定无人机和无人车的合作路线。然后,我们提出的框架以采用遗传算法 GA 来选择交汇点的基线解决方案为基准。我们的研究结果表明,强化学习在减少总体任务时间、最大限度地减少无人机 UGV 空闲时间以及降低无人机和 UGV 的能耗方面优于 GA。 |
| A Concise Overview of Safety Aspects in Human-Robot Interaction Authors Mazin Hamad, Simone Nertinger, Robin J. Kirschner, Luis Figueredo, Abdeldjallil Naceri, Sami Haddadin 截至今天,机器人表现出令人印象深刻的敏捷性,但与它们合作时也对人类构成潜在危险。因此,安全性被认为是人机交互 HRI 中最重要的因素。本文提出了一种多层安全架构,集成了物理和认知方面的有效 HRI。我们将物理安全层的关键要求概述为可以任意查询的服务模块。此外,我们展示了一种 HRI 方案,该方案将人为因素和感知安全作为经过验证的冲击安全范式的高级约束。 |
| Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents Authors Ziyi Yang, Shreyas S. Raman, Ankit Shah, Stefanie Tellex 大型语言模型 LLM 的最新进展启用了一个新的研究领域,即 LLM 代理,通过利用 LLM 在预训练期间获得的世界知识和一般推理能力来解决机器人技术和规划任务。然而,尽管人们在教机器人该做的事情上付出了相当大的努力,但该做的事情却受到的关注相对较少。我们认为,对于任何实际用途,教导机器人“不要”传达有关禁止行为的明确指令、评估机器人对这些限制的理解以及最重要的是确保遵守同样重要。此外,可验证的安全操作对于满足 ISO 61508 等全球标准的部署至关重要,该标准定义了在全球工业工厂环境中安全部署机器人的标准。针对在协作环境中部署LLM代理,我们提出了一种基于线性时态逻辑LTL的可查询安全约束模块,该模块同时使自然语言NL能够进行时态约束编码、安全违规推理和解释以及不安全动作剪枝。为了证明我们系统的有效性,我们在 VirtualHome 环境和真实机器人上进行了实验。 |
| Wait, That Feels Familiar: Learning to Extrapolate Human Preferences for Preference Aligned Path Planning Authors Haresh Karnan, Elvin Yang, Garrett Warnell, Joydeep Biswas, Peter Stone 最后一英里交付等自主移动任务需要推理操作员对机器人应导航的地形的偏好,以确保机器人安全和任务成功。然而,处理来自新地形的分布数据或由于照明变化引起的外观变化仍然是视觉地形自适应导航中的基本问题。现有的解决方案要么需要劳动密集型的手动数据收集和标记,要么使用可能不符合操作员偏好的手工编码的奖励函数。在这项工作中,我们假设操作员对机器人应遵循的视觉新颖地形的偏好通常可以从惯性、本体感觉和触觉领域内已建立的地形参考中推断出来。利用这种洞察力,我们引入了地形感知机器人导航的偏好提取(PATERN),这是一种新颖的框架,用于推断操作员视觉导航的地形偏好。 PATERN 学习将机器人观察到的惯性、本体感觉、触觉测量值映射到表示空间,并在该空间中执行最近邻搜索,以估计操作员对新地形的偏好。通过室外环境中的物理机器人实验,我们评估了 PATERN 推断偏好并推广到新地形和具有挑战性的照明条件的能力。 |
| Differentiable Boustrophedon Path Plans Authors Thomas Manzini, Robin Murphy 本文介绍了一种用于优化凸多边形中的 Boustropedon 路径规划的可微分表示,探索了这些路径规划中可以优化的附加参数,讨论了在优化过程中可以利用的这种表示的属性,并表明了先前发布的优化这些路径计划的尝试过于粗略,无法实际使用。实验表明,这种可微分表示可以从高保真度的 Boustropedon 路径规划的过渡离散表示中重现相同的分数。最后,尝试通过梯度下降进行优化,但发现失败,因为搜索空间比之前文献中考虑的更加非凸。 Boustropedon路径规划的广泛应用意味着这项工作有可能提高机器人技术众多领域的路径规划效率,包括使用无人驾驶航空系统的测绘和搜索任务、使用无人驾驶海洋车辆的环境采样任务以及使用地面车辆的农业任务 |
| DynaPix SLAM: A Pixel-Based Dynamic SLAM Approach Authors Chenghao Xu, Elia Bonetto, Aamir Ahmad 在静态环境中,视觉同步定位和建图V SLAM方法取得了显着的性能。然而,移动物体严重影响了此类系统的核心模块,例如状态估计和闭环检测。为了解决这个问题,动态 SLAM 方法通常使用语义信息、几何约束或光流来掩盖与动态实体相关的特征。这些受到各种因素的限制,例如对底层方法质量的依赖、对未知或意外移动对象的泛化能力差,并且经常产生嘈杂的结果,例如通过屏蔽静态但可移动的对象或利用预定义的阈值。在本文中,为了解决这些权衡问题,我们引入了一种基于每像素运动概率值的新型视觉 SLAM 系统 DynaPix。我们的方法由新的无语义概率像素运动估计模块和改进的姿势优化过程组成。我们的每像素运动概率估计结合了一种新颖的静态背景差分方法,用于图像和来自分散帧的光流。 DynaPix 将这些运动概率完全集成到 ORB SLAM2 的跟踪和优化模块中的地图点选择和加权束调整中。我们在 GRADE 和 TUM RGBD 数据集上针对 ORB SLAM2 和 DynaSLAM 评估 DynaPix,获得更低的错误和更长的轨迹跟踪时间。 |
| RaLF: Flow-based Global and Metric Radar Localization in LiDAR Maps Authors Abhijeet Nayak, Daniele Cattaneo, Abhinav Valada 本地化对于自主机器人来说至关重要。虽然基于摄像头和激光雷达的方法已得到广泛研究,但它们会受到不利照明和天气条件的影响。因此,雷达传感器由于其对此类条件的固有鲁棒性而最近受到关注。在本文中,我们提出了 RaLF,一种基于深度神经网络的新型方法,通过联合学习来解决位置识别和度量定位问题,在环境 LiDAR 地图中定位雷达扫描。 RaLF 由雷达和 LiDAR 特征编码器、生成全局描述符的位置识别头以及预测雷达扫描和地图之间的 3 DoF 变换的度量定位头组成。我们通过跨模态度量学习学习两种模态之间的共享嵌入空间来解决地点识别任务。此外,我们通过预测像素级流向量来执行度量定位,这些向量将查询雷达扫描与 LiDAR 地图对齐。我们在多个现实世界驾驶数据集上广泛评估了我们的方法,并表明 RaLF 在位置识别和度量定位方面均实现了最先进的性能。此外,我们证明我们的方法可以有效地推广到与训练期间使用的方法不同的城市和传感器设置。 |
| Zero-Shot Policy Transferability for the Control of a Scale Autonomous Vehicle Authors Harry Zhang, Stefan Caldararu, Sriram Ashokkumar, Ishaan Mahajan, Aaron Young, Alexis Ruiz, Huzaifa Unjhawala, Luning Bakke, Dan Negrut 我们报告了一项研究,该研究采用内部开发的模拟基础设施来实现与规模自动驾驶车辆相关的控制策略的零射击策略可转移性。我们专注于实施不需要真实世界数据进行训练的零镜头传输策略,并且是内部开发的,而不是通过以前的工作进行验证。我们通过实现仅在一系列循环参考轨迹上进行训练的神经网络 NN 控制器来实现此目的。使用的传感器是 RTK GPS 和 IMU,后者用于提供航向。神经网络控制器使用人类驾驶员通过人在环仿真或模型预测控制 MPC 策略进行训练。我们结合两种操作场景演示了这两种方法,车辆以恒定速度遵循路点定义的轨迹,车辆遵循沿车辆路点定义的轨迹变化的速度曲线。 |
| Contrastive Learning for Enhancing Robust Scene Transfer in Vision-based Agile Flight Authors Jiaxu Xing, Leonard Bauersfeld, Yunlong Song, Chunwei Xing, Davide Scaramuzza 基于视觉的移动机器人应用的场景转移是一个高度相关且具有挑战性的问题。机器人的效用很大程度上取决于它在现实世界中、在受控良好的实验室环境之外执行任务的能力。现有的场景传输端到端策略学习方法通常存在样本效率差或泛化能力有限的问题,使得它们不适合移动机器人应用。这项工作提出了一种用于视觉表示学习的自适应多对对比学习策略,可实现零镜头场景传输和现实世界部署。依赖于嵌入的控制策略能够在不可见的环境中运行,而不需要在部署环境中进行微调。我们展示了我们的方法在敏捷、基于视觉的四旋翼飞行任务中的性能。 |
| CC-SGG: Corner Case Scenario Generation using Learned Scene Graphs Authors George Drayson, Efimia Panagiotaki, Daniel Omeiza, Lars Kunze 极端案例场景是测试和验证自动驾驶汽车安全性的重要工具。由于这些场景在自然驾驶数据集中通常不足以呈现,因此通过合成极端情况来增强数据可以极大地增强自动驾驶汽车在独特情况下的安全运行。然而,合成但现实的极端情况的生成提出了重大挑战。在这项工作中,我们介绍了一种基于异构图神经网络 HGNN 的新颖方法,将常规驾驶场景转变为极端情况。为了实现这一目标,我们首先将常规驾驶场景的简明表示生成为场景图,最小化地操纵它们的结构和属性。然后,我们的模型学习使用注意力和三重嵌入来扰乱这些图以生成极端情况。然后将输入和扰动图导入回模拟中以生成极端情况场景。我们的模型成功地学会了从输入场景图生成极端情况,在我们的测试数据集上实现了 89.9 的预测精度。 |
| Grasp-Anything: Large-scale Grasp Dataset from Foundation Models Authors An Dinh Vuong, Minh Nhat Vu, Hieu Le, Baoru Huang, Binh Huynh, Thieu Vo, Andreas Kugi, Anh Nguyen ChatGPT 等基础模型由于其对现实世界领域的通用表示,在机器人任务方面取得了重大进展。在本文中,我们利用基础模型来解决抓取检测问题,这是具有广泛工业应用的机器人技术中持续存在的挑战。尽管有大量掌握的数据集,但与现实世界的数据相比,它们的对象多样性仍然有限。幸运的是,基础模型拥有广泛的现实世界知识库,包括我们在日常生活中遇到的物体。因此,针对先前掌握数据集中有限表示的一个有希望的解决方案是利用这些基础模型中嵌入的通用知识。我们提出了 Grasp Anything,这是一个从基础模型合成的新的大规模抓取数据集,用于实现该解决方案。 Grasp Anything 在多样性和规模方面表现出色,拥有 100 万个带有文本描述的样本和超过 300 万个对象,超越了之前的数据集。根据经验,我们表明 Grasp Anything 成功地促进了基于视觉的任务和现实世界机器人实验的零镜头抓取检测。 |
| Learning Inertial Parameter Identification of Unknown Object with Humanoid Robot using Sim-to-Real Adaptation Authors Donghoon Baek, Bo Peng, Saurabh Gupta, Joao Ramos 了解未知物体的动态对于包括人形机器人在内的协作机器人更安全、更准确地与人类互动至关重要。大多数相关文献都利用力扭矩传感器、物体的先验知识、视觉系统和长水平轨迹,而这些通常是不切实际的。此外,这些方法通常需要解决非线性优化问题,有时会产生物理上不一致的结果。在这项工作中,我们提出了一种基于快速学习的惯性参数估计作为更实用的方式。我们在高保真模拟中获取可靠的数据集,并训练时间序列数据驱动的回归模型(例如 LSTM)来估计未知物体的惯性参数。我们还引入了一种新颖的模拟现实适应方法,结合机器人系统识别和高斯过程,将训练后的模型直接转移到现实世界的应用中。我们用物理轮式人形机器人 SATYRR 的 4 自由度单操纵器演示了我们的方法。 |
| Coco-LIC: Continuous-Time Tightly-Coupled LiDAR-Inertial-Camera Odometry using Non-Uniform B-spline Authors Xiaolei Lang, Chao Chen, Kai Tang, Yukai Ma, Jiajun Lv, Yong Liu, Xingxing Zuo 在本文中,我们提出了一种高效的连续时间 LiDAR 惯性相机里程计,利用非均匀 B 样条将 LiDAR、IMU 和相机的测量紧密耦合。与基于均匀 B 样条的连续时间方法相比,我们的非均匀 B 样条方法在实现实时效率和高精度方面具有显着优势。这是通过动态和自适应地放置控制点来实现的,同时考虑到运动的变化动态。为了在短滑动窗口优化内实现异构激光雷达惯性相机数据的有效融合,我们使用全局激光雷达地图中的相应地图点将深度分配给视觉像素,并为当前图像帧中的相关像素制定帧以映射重投影因子。这种方式避免了视觉像素深度优化的必要性,这通常需要一个带有大量控制点的长滑动窗口来进行连续时间轨迹估计。我们对现实世界数据集进行了专门的实验,以证明采用非均匀连续时间轨迹表示的优势和功效。我们的激光雷达惯性相机测距系统还在传感器退化的挑战性场景和大规模场景中进行了广泛的评估,并显示出与最先进的方法相当或更高的精度。 |
| DFL-TORO: A One-Shot Demonstration Framework for Learning Time-Optimal Robotic Manufacturing Tasks Authors Alireza Barekatain, Hamed Habibi, Holger Voos 本文介绍了 DFL TORO,这是一种通过一次性动觉演示来学习时间最优机器人任务的新型演示框架。它旨在优化在制造业中应用的从示范 LfD 中学习的过程。由于 LfD 的有效性受到人类演示的质量和效率的挑战,我们的方法提供了一种简化的方法,通过减少多次演示的需要,直观地捕获人类教师的任务要求。此外,我们提出了一种基于优化的平滑算法,可确保时间最优和加加速度调节的演示轨迹,同时还遵守机器人的运动学约束。结果是噪音显着降低,从而提高了机器人的运行效率。 |
| Privileged to Predicted: Towards Sensorimotor Reinforcement Learning for Urban Driving Authors Ege Onat zs er, Bar Akg n, Fatma G ney 强化学习 RL 有潜力超越人类的驾驶表现,而无需任何专家监督。尽管前景广阔,但由于强化学习算法的固有缺陷,感觉运动自动驾驶的最新技术仍以模仿学习方法为主。尽管如此,当提供环境的特权地面实况表示时,强化学习智能体能够发现非常成功的策略。在这项工作中,我们研究了城市驾驶中特权强化学习智能体与感觉运动智能体的区别,以弥合两者之间的差距。我们提出基于视觉的深度学习模型来近似传感器数据的特权表示。特别是,我们确定了对于 RL 代理成功至关重要的状态表示方面,例如所需的路线生成和停止区预测,并提出了逐步开发特权较少的 RL 代理的解决方案。我们还观察到,由于分布不匹配,在离线数据集上训练的鸟瞰模型不能推广到在线强化学习训练。 |
| Towards Socially Responsive Autonomous Vehicles: A Reinforcement Learning Framework with Driving Priors and Coordination Awareness Authors Jiaqi Liu, Donghao Zhou, Peng Hang, Ying Ni, Jian Sun 自动驾驶汽车与人类驾驶车辆混合动力汽车的出现开创了混合交通流的时代,这对复杂驾驶环境中这些实体之间复杂的交互提出了重大挑战。自动驾驶汽车有望具有类似人类的驾驶行为,从而无缝地融入人类主导的交通系统。为了解决这个问题,我们提出了一个强化学习框架,该框架考虑驱动先验和社会协调意识 SCA 来优化自动驾驶汽车的行为。该框架集成了基于变分自动编码器的驾驶先验学习 DPL 模型,可根据人类驾驶员的轨迹推断驾驶员的驾驶先验。基于多头注意力机制的策略网络旨在有效捕获自动驾驶汽车和其他流量参与者之间的交互依赖关系,以提高决策质量。将SCA引入自动驾驶决策系统,并探索使用协调倾向CT来量化自动驾驶汽车协调交通系统的意愿。 |
| Learning Covariances for Estimation with Constrained Bilevel Optimization Authors Mohamad Qadri, Zachary Manchester, Michael Kaess 我们考虑机器人状态估计的学习误差协方差矩阵的问题。状态估计器对机器人状态的正确置信度的收敛取决于噪声模型的正确调整。在推理过程中,这些模型用于权衡线性化产生的雅可比行列式和误差向量的不同块,因此额外影响非线性系统的稳定性和收敛性。我们提出了一种基于梯度的方法,通过将学习过程表示为因子图上的约束双层优化问题来估计条件良好的协方差矩阵。 |
| GHNet:Learning GNSS Heading from Velocity Measurements Authors Nitzan Dahan, Itzik Klein 通过利用全球导航卫星系统 GNSS 位置和速度测量,GNSS 和惯性导航系统之间的融合可提供准确且可靠的导航信息。当考虑陆地车辆时,例如自主地面车辆、越野车辆或移动机器人,可以获得基于 GNSS 的航向角测量值,并与位置测量并行使用,以限制航向角漂移。然而,在低于 2 米/秒的低车速下,这种基于模型的航向测量无法提供令人满意的性能。本文提出了 GHNet,这是一种深度学习框架,能够准确回归低速行驶车辆的航向角。 |
| Two-Stage Learning of Highly Dynamic Motions with Rigid and Articulated Soft Quadrupeds Authors Francecso Vezzi, Jiatao Ding, Antonin Raffin, Jens Kober, Cosimo Della Santina 四足机器人(尤其是具有铰接式软体的机器人)动态运动的受控执行提出了传统方法难以有效解决的一系列独特挑战。在这项研究中,我们通过依靠简单而有效的两阶段学习框架来生成四足机器人的动态运动来解决这些问题。首先,采用无梯度演化策略来发现简单表示的控制策略,从而消除了对预定义参考运动的需要。然后,我们使用深度强化学习来完善这些策略。我们的方法能够从头开始有效地获取复杂的动作,例如前跳和后空翻。此外,我们的方法简化了传统上劳动密集型的奖励塑造任务,提高了学习过程的效率。 |
| Concurrent Haptic, Audio, and Visual Data Set During Bare Finger Interaction with Textured Surfaces Authors Alexis W.M. Devillard, Aruna Ramasamy, Damien Faux, Vincent Hayward, Etienne Burdet 感知过程通常是多模态的。这就是触觉感知的情况。过去已经编译了视觉和触觉感官信号的数据集,特别是在探索纹理表面时。这些数据集旨在用于自然和人工感知研究,并为机器学习研究提供训练数据集。这些数据集通常是通过刚性探针或人造机器人手指获取的。在这里,我们收集了人类手指探索纹理表面时获得的视觉、听觉和触觉信号。我们通过机器学习分类技术评估数据集。 |
| A Smart Handheld Edge Device for On-Site Diagnosis and Classification of Texture and Stiffness of Excised Colorectal Cancer Polyps Authors Ozdemir Can Kara, Jiaqi Xue, Nethra Venkatayogi, Tarunraj G. Mohanraj, Yuki Hirata, Naruhiko Ikoma, S. Farokh Atashzar, Farshid Alambeigi 本文提出了一种智能手持式纹理传感医疗设备,具有互补的机器学习 ML 算法,可实现结直肠癌、CRC 息肉的现场诊断和切除肿瘤的病理学。所提出的独特手持边缘设备受益于独特的触觉传感模块和双级机器学习算法,该算法由扩张残差网络和用于息肉类型和刚度表征的 t SNE 引擎组成。仅利用所提出的触觉传感器捕获的无遮挡、照明弹性纹理图像,该框架就能够通过分别对CRC息肉的纹理和硬度进行分类,敏感而可靠地识别CRC息肉的类型和阶段。 |
| Affordance-Driven Next-Best-View Planning for Robotic Grasping Authors Xuechao Zhang, Dong Wang, Sun Han, Weichuang Li, Bin Zhao, Zhigang Wang, Xiaoming Duan, Chongrong Fang, Xuelong Li, Jianping He 在杂乱的环境中抓取被遮挡的物体是复杂的机器人操作任务的重要组成部分。在本文中,我们介绍了一种 AffordanCE 驱动的 Next Best View 规划策略 ACE NBV,它试图通过从新的视角持续观察场景来找到对目标对象的可行把握。该策略的动机是观察到当视图方向与抓取视图相同时,可以在视图下更好地测量被遮挡对象的抓取可供性。具体来说,我们的方法利用新颖视图图像的范式来预测先前未观察到的视图下的抓握可供性,并根据目标对象的最高想象抓握质量的增益来选择下一个观察视图。模拟和真实机器人的实验结果证明了所提出的可供性驱动的下一个最佳视图规划策略的有效性。 |
| TransTouch: Learning Transparent Objects Depth Sensing Through Sparse Touches Authors Liuyu Bian, Pengyang Shi, Weihang Chen, Jing Xu, Li Yi, Rui Chen 透明物体在日常生活中很常见。然而,透明物体的深度传感仍然是一个具有挑战性的问题。虽然基于学习的方法可以利用形状先验来提高传感质量,但现实世界中的劳动密集型数据收集以及模拟与真实领域的差距限制了这些方法的可扩展性。在本文中,我们提出了一种使用带有触觉反馈的探测系统自动收集的稀疏深度标签来微调立体网络的方法。我们提出了一种新颖的效用函数来评估触摸的好处。通过近似和优化效用函数,我们可以在给定固定接触预算的情况下优化探测位置,以更好地提高网络在真实对象上的性能。我们进一步将触觉深度监督与基于置信度的正则化相结合,以防止微调期间过度拟合。为了评估我们方法的有效性,我们构建了一个包含漫反射和透明对象的现实世界数据集。 |
| Two Degree of Freedom Adaptive Control for Hysteresis Compensation of Pneumatic Continuum Bending Actuator Authors Junyi Shen, Tetsuro Miyazaki, Shingo Ohno, Maina Sogabe, Kenji Kawashima 软机器人技术凭借其固有的灵活性和无限自由度,为人机界面带来了有希望的进步。特别是,气动人造肌肉 PAM 和气动弯曲执行器利用其对自然肌肉运动的模仿性质,在推动这一发展方面发挥了重要作用。然而,这些执行器的多功能性带来了迟滞的复杂挑战,这是一种阻碍精确定位的非线性现象,由于气体可压缩性,在气动执行器中尤其明显。在本研究中,我们引入了一种新颖的 2 DoF 自适应控制,可使用气动连续介质执行器进行精确弯曲跟踪。值得注意的是,我们的控制方法将适应性集成到反馈和前馈元件中,从而在存在严重非线性效应的情况下增强轨迹跟踪。与现有方法的比较分析强调了我们提出的策略的卓越跟踪准确性。 |
| Guided Online Distillation: Promoting Safe Reinforcement Learning by Offline Demonstration Authors Jinning Li, Xinyi Liu, Banghua Zhu, Jiantao Jiao, Masayoshi Tomizuka, Chen Tang, Wei Zhan 安全强化学习 RL 旨在找到一种在满足成本约束的同时实现高回报的策略。从头开始学习时,安全的强化学习智能体往往过于保守,这会阻碍探索并限制整体性能。在许多现实任务中,例如自动驾驶,大规模专家演示数据可用。我们认为,从离线数据中提取专家策略来指导在线探索是缓解保守性问题的一个有前途的解决方案。大容量型号,例如决策转换器 DT 已被证明能够胜任离线策略学习。然而,在现实世界场景中收集的数据很少包含危险情况,例如碰撞,这使得政策无法学习安全概念。此外,这些批量策略网络无法满足自动驾驶等现实世界任务的推理时的计算速度要求。为此,我们提出了 Guided Online Distillation GOLD,一个离线到在线的安全强化学习框架。 GOLD 通过引导在线安全 RL 训练,将离线 DT 策略提炼为轻量级策略网络,其性能优于离线 DT 策略和在线安全 RL 算法。 |
| Reactive Base Control for On-The-Move Mobile Manipulation in Dynamic Environments Authors Ben Burgess Limerick, Jesse Haviland, Chris Lehnert, Peter Corke 我们提出了一种反应式基础控制方法,可以在具有静态和动态障碍物的环境中实现高性能移动操纵。在移动底座保持运动的同时执行操作任务可以显着减少执行多步任务所需的时间,并提高机器人运动的优雅度。现有的移动操纵方法要么忽略避障问题,要么依赖计划轨迹的执行,这不适合具有动态物体和障碍物的环境。所提出的控制器解决了这两个缺陷,并展示了动态环境中拾取和放置任务的强大性能。性能是根据几个模拟和现实世界的任务进行评估的。在具有静态障碍的现实世界任务中,我们在总任务时间方面比现有方法高出 48 倍。此外,我们还展示了机器人在移动中执行操作任务的现实世界示例,同时避免工作空间中出现第二个自主机器人。 |
| Efficient Belief Road Map for Planning Under Uncertainty Authors Zhenyang Chen, Hongzhe Yu, Yongxin Chen 机器人系统,特别是在狭窄走廊或灾区等苛刻环境中,经常会遇到不完美的状态估计问题。应对这一挑战需要一个轨迹计划,不仅要驾驭这些限制性空间,还要管理系统固有的不确定性。我们通过使用有效的协方差控制算法,提出了一种基于图的置信空间规划的新颖方法。通过输出状态反馈自适应转向状态统计,我们有效地制作了一个信念路线图,其特征是具有受控不确定性的节点和代表无碰撞平均轨迹的边缘。路线图的结构化设计为精确的路径搜索铺平了道路,平衡了控制成本和不确定性因素。我们的数值实验证实了我们的方法在不同运动规划任务中的有效性和优势。 |
| Off the Beaten Track: Laterally Weighted Motion Planning for Local Obstacle Avoidance Authors Jordy Sehn, Jack Collier, Timothy D. Barfoot 我们通过引入与曲线规划空间配对的新边缘成本度量,扩展了基于通用样本的运动规划器的行为,以支持长距离路径跟踪期间的避障。由此产生的规划器生成自然平滑的路径,避免局部障碍物,同时最小化横向路径偏差,以最好地利用参考路径的先验地形知识。在这种改编中,我们探索了曲线配置空间中规划的细微差别,并描述了一种自然奇点处理机制以提高通用性。然后,我们将注意力转向轨迹生成问题,提出一种新颖的模型预测控制 MPC 架构,以最好地利用我们的路径规划器来改进避障。 |
| Predictive Fault Tolerance for Autonomous Robot Swarms Authors James O Keeffe, Alan Gregory Millard 主动容错对于机器人群保持长期自主性至关重要。先前关于集群容错的工作重点是对自发注入机器人传感器和执行器的机电故障做出反应。一旦故障表现为故障就解决故障是一种低效的方法,并且在一些安全关键场景中,任何类型的机器人故障都是不可接受的。我们提出了一种基于抢先维护原则的预测容错方法,其中潜在的故障在表现为故障之前被自动检测和解决。 |
| NeRF-VINS: A Real-time Neural Radiance Field Map-based Visual-Inertial Navigation System Authors Saimouli Katragadda, Woosik Lee, Yuxiang Peng, Patrick Geneva, Chuchu Chen, Chao Guo, Mingyang Li, Guoquan Huang 在先验环境地图中实现准确、高效和一致的定位仍然是机器人和计算机视觉领域的基本挑战。由于视场 FOV 有限,传统的基于地图的关键帧定位通常会受到次优视点的影响,从而降低其性能。为了解决这个问题,在本文中,我们设计了一种实时紧耦合神经辐射场NeRF辅助视觉惯性导航系统VINS,称为NeRF VINS。通过有效利用 NeRF 合成新颖视图的潜力(对于解决有限视点至关重要),所提出的 NeRF VINS 在基于高效滤波器的框架内最佳地融合了 IMU 和单目图像测量以及合成渲染图像。这种紧密耦合的集成可实现具有有限误差的 3D 运动跟踪。我们将所提出的 NeRF VINS 与使用先验地图信息的最先进方法进行了广泛比较,这表明该方法可以实现卓越的性能。 |
| The Director: A Composable Behaviour System with Soft Transitions Authors Ysobel Sims, Trent Houliston 行为软件框架在机器人技术中至关重要,因为它们能够正确有效地执行功能。虽然现代行为系统提高了其可组合性,但它们并不注重平滑过渡,并且通常缺乏功能。在这项工作中,我们提出了Director,一种解决这些问题的新颖行为框架和算法。它具有软转换功能、基于条件选择的同一操作的多种实现以及严格的资源控制。 |
| Sim-to-Real Deep Reinforcement Learning with Manipulators for Pick-and-place Authors Wenxing Liu, Hanlin Niu, Robert Skilton, Joaquin Carrasco 当将深度强化学习模型从模拟转移到现实世界时,由于模拟在许多情况下无法很好地模仿现实世界,因此性能可能会不尽如人意。这导致现实世界中需要长时间的微调。本文提出了一种基于自监督视觉的 DRL 方法,该方法允许机器人在将训练模型从模拟直接转移到现实世界时有效且高效地拾取和放置物体。高度敏感的动作策略是专门为所提出的方法设计的,用于在具有挑战性的环境中处理拥挤和堆叠的物体。采用所提出方法的训练模型可以直接应用于真实的抽吸任务,无需对现实世界进行任何微调,同时保持较高的抽吸成功率。还验证了我们的模型可以在真实实验中部署来吸附新物体,吸附成功率为 90,而无需任何现实世界的微调。 |
| Trajectory Forecasting with Loose Clothing Using Left-to-Right Hidden Markov Model Authors Tianchen Shen, Irene Di Giulio, Matthew Howard 由于可穿戴传感技术的进步,轨迹预测已成为一个有趣的研究领域。使用尖端电子纺织技术,传感器可以无缝集成到服装中,从而可以在实验室外长期记录人体运动。最近发现,衣服附着传感器比身体附着传感器可以实现更高的活动识别精度,这项工作研究了使用刚性附着传感器和衣服附着传感器进行运动预测和轨迹预测。根据从左到右隐马尔可夫模型LR HMM制定的概率轨迹模型来预测未来轨迹,并通过分类规则计算运动预测精度。令人惊讶的是,结果表明,衣服附着的传感器可以预测未来的轨迹,并且在运动预测精度方面比身体附着的传感器具有更好的性能。 |
| CapsuleBot: A Novel Compact Hybrid Aerial-Ground Robot with Two Actuated-wheel-rotors Authors Zhi Zheng, Qifeng Cai, Xinhang Xu, Muqing Cao, Huan Yu, Jihao Li, Guodong Lu, Jin Wang 本文介绍了 CapsuleBot 的设计、建模和实验验证,这是一种专为长期隐蔽侦察而设计的紧凑型混合空中地面车辆。 CapsuleBot 将双旋翼飞行器在空中的机动性与地面车辆在地面上的节能和降噪性能结合起来。为了实现这一目标,设计了一种名为驱动轮转子的结构,利用单独的电机来实现双旋翼配置中的单侧转子倾斜和地面模式下的轮运动。 CapsuleBot 配备了其中两个结构,使其能够仅用四个电机实现混合空中地面推进。重要的是,无需额外的驱动器即可实现运动模式的解耦,从而增强了系统的多功能性和鲁棒性。此外,我们还基于双轴飞行器模型和两轮自平衡车模型设计了空中和地面运动的完整动力学和控制。 CapsuleBot的性能已经通过实验得到验证。 |
| RobotPerf: An Open-Source, Vendor-Agnostic, Benchmarking Suite for Evaluating Robotics Computing System Performance Authors V ctor Mayoral Vilches, Jason Jabbour, Yu Shun Hsiao, Zishen Wan, Alejandra Mart nez Fari a, Marti o Crespo lvarez, Matthew Stewart, Juan Manuel Reina Mu oz, Prateek Nagras, Gaurav Vikhe, Mohammad Bakhshalipour, Martin Pinzger, Stefan Rass, Smruti Panigrahi, Giulio Corradi, Niladri Roy, Phillip B. Gibbons, Sabrina M. Neuman, Brian Plancher, Vijay Janapa Reddi 我们推出了 RobotPerf,这是一个与供应商无关的基准测试套件,旨在使用 ROS 2 作为通用基准来评估各种硬件平台上的机器人计算性能。该套件包含覆盖整个机器人管道的 ROS 2 软件包,并集成了两种不同的基准测试方法:黑盒测试(通过消除上层并用测试应用程序替换它们来测量性能)和灰盒测试(一种观察内部系统状态的特定于应用程序的测量)以最小的干扰。我们的基准测试框架提供了即用型工具,并且可以轻松适应自定义 ROS 2 计算图的评估。 RobotPerf 借鉴领先的机器人架构师和系统架构专家的知识,建立了一种标准化的机器人基准测试方法。 |
| Differentiable SLAM Helps Deep Learning-based LiDAR Perception Tasks Authors Prashant Kumar, Dheeraj Vattikonda, Vedang Bhupesh Shenvi Nadkarni, Erqun Dong, Sabyasachi Sahoo 我们研究了一种新的范式,该范式以自监督的方式使用可微 SLAM 架构,在各种基于 LiDAR 的应用中训练端到端深度学习模型。据我们所知,尚不存在任何利用 SLAM 作为基于深度学习的模型的训练信号的工作。我们探索利用深度学习技术提高激光雷达系统的效率、鲁棒性和适应性的新方法。我们专注于可微 SLAM 架构在提高分类、回归和 SLAM 等深度学习任务性能方面的潜在优势。我们的实验结果表明,当与可微 SLAM 架构一起使用时,两种深度学习应用程序(地面估计和动态到静态 LiDAR 转换)的性能显着提高。总的来说,我们的研究结果提供了重要的见解,可以提高基于激光雷达的导航系统的性能。 |
| Spline-Based Minimum-Curvature Trajectory Optimization for Autonomous Racing Authors Haoru Xue, Tianwei Yue, John M. Dolan 我们提出了一种新颖的用于自动驾驶赛车的 B 样条轨迹优化方法。我们考虑到在早期自主赛车运动开发中无法获得复杂的赛车和赛道动力学,并推导出适用于有限动力学数据和额外保守约束的方法。我们制定了仅将样条控制点作为优化变量的最小曲率优化问题。然后,我们将当前最先进的方法与我们的优化结果进行比较,优化结果达到了类似的最优水平,决策变量维度减少了 90,此外还提供了数学平滑度保证和灵活的操作选项。 |
| CLIPUNetr: Assisting Human-robot Interface for Uncalibrated Visual Servoing Control with CLIP-driven Referring Expression Segmentation Authors Chen Jiang, Yuchen Yang, Martin Jagersand 基于未校准图像的视觉伺服 UIBVS 中的经典人类机器人界面依赖于人类注释或带有分类标签的语义分割。这两种方法都无法匹配自然的人类交流,也无法像自然语言表达一样有效地在操作任务中传达丰富的语义。在本文中,我们通过使用引用表达分割(一种基于提示的方法)来解决这个问题,为机器人感知提供更深入的信息。为了从引用表达生成高质量的分割预测,我们提出了 CLIPUNetr 一种新的 CLIP 驱动的引用表达分割网络。 CLIPUNetr 利用 CLIP 强大的视觉语言表示来分割引用表达式中的区域,同时利用其 U 形编码器解码器架构来生成具有更清晰边界和更精细结构的预测。此外,我们提出了一种新的管道,将 CLIPUNetr 集成到 UIBVS 中,并将其应用于现实环境中的机器人控制。 |
| Optimal Scene Graph Planning with Large Language Model Guidance Authors Zhirui Dai, Arash Asgharivaskasi, Thai Duong, Shusen Lin, Maria Elizabeth Tzes, George Pappas, Nikolay Atanasov 度量、语义和拓扑映射方面的最新进展为自主机器人配备了语义概念基础能力来解释自然语言任务。这项工作旨在利用这些新功能和用于分层度量语义模型的高效任务规划算法。我们考虑环境的场景图表示,并利用大型语言模型 LLM 将自然语言任务转换为线性时序逻辑 LTL 自动机。我们的主要贡献是通过 LLM 对场景图的指导来实现最佳的分层 LTL 规划。为了提高效率,我们构建了一个分层规划域,捕获场景图和任务自动机的属性和连接性,并通过 LLM 启发式函数提供语义指导。为了保证最优性,我们设计了一个 LTL 启发式函数,该函数可证明是一致的,并补充了多重启发式规划中可能不可接受的 LLM 指导。 |
| From Cooking Recipes to Robot Task Trees -- Improving Planning Correctness and Task Efficiency by Leveraging LLMs with a Knowledge Network Authors Md Sadman Sakib, Yu Sun 机器人烹饪的任务规划涉及生成机器人成功准备饭菜的一系列动作。本文介绍了一种新颖的任务树生成管道,可为烹饪任务提供正确的规划和高效的执行。我们的方法首先使用大型语言模型 LLM 来检索配方指令,然后利用微调的 GPT 3 将它们转换为任务树,捕获子任务之间的顺序和并行依赖关系。然后,该管道使用任务树检索来减轻 LLM 输出的不确定性和不可靠特征。我们将多个LLM任务树输出组合成一个图,并进行任务树检索,以避免有问题的节点和高成本节点,从而提高计划的正确性并提高执行效率。 |
| From Knowing to Doing: Learning Diverse Motor Skills through Instruction Learning Authors Linqi Ye, Jiayi Li, Yi Cheng, Xianhao Wang, Bin Liang, Yan Peng 近年来,机器人学习领域出现了许多成功的尝试。对于接触丰富的机器人任务,通过强化学习来学习协调运动技能是具有挑战性的。模仿学习通过使用模仿奖励来鼓励机器人跟踪给定的参考轨迹来解决这个问题。然而,模仿学习效率不高,并且可能会限制学习到的动作。在本文中,我们提出了指令学习,它受到人类学习过程的启发,对于机器人运动学习来说是高效、灵活和通用的。指令学习不是在奖励中使用参考信号,而是直接应用参考信号作为前馈动作,并与强化学习学到的反馈动作相结合来控制机器人。此外,我们提出了动作边界技术并消除了模仿奖励,这对于高效和灵活的学习至关重要。我们将指令学习与模仿学习的性能进行了比较,表明指令学习可以大大加快训练过程并保证正确学习所需的动作。指令学习的有效性通过双足机器人和四足机器人的一系列运动学习示例得到验证,其中技能通常可以在数百万步内学习。此外,我们还在真实的四足机器人上进行了模拟到真实的迁移和在线学习实验。 |
| Hamiltonian Dynamics Learning from Point Cloud Observations for Nonholonomic Mobile Robot Control Authors Abdullah Altawaitan, Jason Stanley, Sambaran Ghosal, Thai Duong, Nikolay Atanasov 可靠的自主导航需要调整移动机器人的控制策略,以响应不同操作条件下的动态变化。由于参数集有限,手工设计的动力学模型可能难以捕获模型变化。数据驱动的动态学习方法提供了更高的模型容量和更好的泛化能力,但需要大量的状态标记数据。本文开发了一种直接从点云观测中学习机器人动力学的方法,消除了状态估计的需要和相关误差,同时在动力学模型中嵌入哈密顿结构以提高数据效率。我们设计了一种观察空间损失,将动力学模型的运动预测与点云配准的运动预测联系起来,以训练哈密顿神经常微分方程。学习到的哈密顿模型使得能够为刚体机器人设计基于能量整形模型的跟踪控制器。 |
| Trajectory Prediction for Robot Navigation using Flow-Guided Markov Neural Operator Authors Rashmi Bhaskara, Hrishikesh Viswanath, Aniket Bera 预测行人运动仍然是机器人导航研究中复杂且持续的挑战。我们必须评估几个因素才能实现准确的预测,例如行人互动、环境、人群密度以及社会和文化规范。准确预测行人路径对于确保安全的人机交互至关重要,尤其是在机器人导航中。此外,这项研究在自动驾驶汽车、行人跟踪和人类机器人协作方面具有潜在的应用。因此,在本文中,我们介绍了textbf FlowMNO,一种光流集成马尔可夫神经算子,旨在捕获不同场景下的行人行为。我们的论文将轨迹预测建模为马尔可夫过程,其中未来的行人坐标仅取决于当前状态。这个问题的表述消除了存储先前状态的需要。我们使用标准基准数据集(例如 ETH、HOTEL、ZARA1、ZARA2、UCY 和 RGB D 行人数据集)进行了实验。我们的研究表明,在预测行人轨迹时,FlowMNO 的性能优于一些最先进的深度学习方法,例如基于 LSTM、GAN 和 CNN 的方法,性能高出约 86.46。 |
| Heuristic-based Incremental Probabilistic Roadmap for Efficient UAV Exploration in Dynamic Environments Authors Zhefan Xu, Christopher Suzuki, Xiaoyang Zhan, Kenji Shimada 动态环境中的自主探索需要一个能够主动响应变化并为机器人做出高效、安全决策的规划器。尽管大量基于采样的工作在探索静态环境方面取得了成功,但其固有的采样随机性和对先前样本的有限利用往往导致探索效率不理想。此外,大多数这些方法都难以在动态设置中进行有效的重新规划和避免碰撞。为了克服这些限制,我们提出了基于启发式的增量概率路线图探索 HIRE 规划器,用于无人机探索动态环境。所提出的规划器采用基于概率路线图的增量采样策略,该概率路线图是通过启发式采样构建的,针对自由空间旁边的未探索区域(定义为启发式前沿区域)。通过将基于轻量级视觉的方法应用于占用图的不同级别来检测启发式前沿区域。此外,我们的动态模块确保规划器根据环境变化动态更新路线图信息并避开动态障碍物。 |
| Neural Network-based Fault Detection and Identification for Quadrotors using Dynamic Symmetry Authors Kunal Garg, Chuchu Fan 四旋翼飞行器等自主机器人系统很容易受到执行器故障的影响,为了此类系统的安全运行,及时检测和隔离这些故障至关重要。神经网络可用于通过高精度在线执行器故障检测来验证执行器性能。在本文中,我们使用长短期记忆 LSTM 神经网络架构,为四旋翼飞行器系统开发了一种新颖的无模型故障检测和隔离 FDI 框架。所提出的框架仅使用系统输出数据和命令控制输入,不需要系统模型的知识。利用四旋翼飞行器动力学中的对称性,我们训练 FDI 以检测其中一个电机(例如电机 2)的故障,并且训练后的 FDI 可以预测任何电机中的故障。搜索空间的减少使我们能够针对部分故障以及完整故障场景设计 FDI。数值实验表明,所提出的 NN FDI 正确验证了执行器性能,并以超过 90 的预测精度识别部分和完整故障。 |
| CppFlow: Generative Inverse Kinematics for Efficient and Robust Cartesian Path Planning Authors Jeremy Morgan, David Millard, Gaurav S. Sukhatme 在这项工作中,我们为笛卡尔路径规划问题提出了 CppFlow 一种新颖且高性能的规划器,它找到有效轨迹的速度比当前方法快 129 倍,同时还能成功解决其他方法失败的更困难的问题。该算法的核心是使用可学习的生成式逆运动学解算器,该解算器能够在 GPU 上高效地生成有希望的整个候选解轨迹。然后通过可微分编程、全局搜索和优化等经典方法找到精确、有效的解决方案。通过结合这两种范式的方法,我们从生成人工智能中获得了两全其美的高效近似解决方案,这些解决方案在传统规划和优化的保证下变得精确。我们在一组已建立的基线以及本工作中引入的新基线上对照其他最先进的方法评估我们的系统,发现我们的方法在寻找有效解决方案的时间和规划成功率方面显着优于其他方法,并且随着时间的推移,在轨迹长度方面表现相当。 |
| Behavioral-based circular formation control for robot swarms Authors Jes s Bautista, H ctor Garc a de Marina 本文重点关注协调绕凸路径运行的机器人群,避免个体之间发生碰撞。各个机器人缺乏制动能力,只能在保持恒定但不同的速度的同时调整路线。我们的编队控制算法不是控制机器人之间的空间关系,而是旨在部署一个密集的机器人群,模仿龙卷风鱼群的行为。为了安全地实现这一目标,我们采用可扩展的超车规则、引导向量场和具有自适应半径的控制障碍函数的组合来促进平滑超车。机器人的决策过程是分布式的,仅依赖于本地信息。实际应用包括防御结构或护航任务,在没有集中指挥的情况下增加集群的弹性。 |
| Multi-camera Bird's Eye View Perception for Autonomous Driving Authors David Unger, Nikhil Gosala, Varun Ravi Kumar, Shubhankar Borse, Abhinav Valada, Senthil Yogamani 大多数自动驾驶系统都包含多样化的传感器组,包括多个摄像头、雷达和激光雷达,确保近处和远处区域的完整 360 度覆盖。与直接进行 3D 测量的雷达和激光雷达不同,相机捕获具有固有深度模糊性的 2D 透视投影。然而,必须产生 3D 感知输出,以实现其他代理和结构的空间推理,从而实现最佳路径规划。 3D 空间通常通过省略不太相关的 Z 坐标(对应于高度尺寸)来简化为 BEV 空间。从相机图像实现所需 BEV 表示的最基本方法是 IPM(假设平坦的地面)。新车中非常常见的环视视觉系统使用 IPM 原理生成 BEV 图像并将其显示给驾驶员。 |
| QTOS: An Open-Source Quadruped Trajectory Optimization Stack Authors Alexy Skoutnev, Andrew Cinar, Praful Sigdel, Forrest Laine 我们引入了一个新的开源框架,四足轨迹优化堆栈 QTOS,它将全局规划器、局部规划器、模拟器、控制器和机器人接口集成到一个包中。 QTOS 作为全堆栈接口,通过弥合中间件和步态规划之间的差距,简化开源四足平台上的连续运动规划。它使用户能够轻松地将高级导航目标转换为低级机器人命令。 |
| GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy Authors So Kuroki, Jiaxian Guo, Tatsuya Matsushima, Takuya Okubo, Masato Kobayashi, Yuya Ikeda, Ryosuke Takanami, Paul Yoo, Yutaka Matsuo, Yusuke Iwasawa 由于运动过程中变形能力固有的不确定性,以前的可变形物体操纵方法(例如绳子和布料)通常需要数百次现实世界的演示来训练每个物体的操纵策略,这阻碍了它们在不断变化的世界中的应用。为了解决这个问题,我们引入了 GenDOM,这是一个框架,允许操纵策略仅通过单个现实世界演示来处理不同的可变形对象。为了实现这一目标,我们通过根据可变形对象参数调节策略并使用各种模拟可变形对象对其进行训练来增强策略,以便策略可以根据不同的对象参数调整动作。在推理时,给定一个新对象,GenDOM 可以通过最小化现实世界演示和可微物理模拟器中模拟的点云网格密度之间的差异,仅用单个现实世界演示来估计可变形对象参数。对模拟和现实世界对象操作设置的实证验证清楚地表明,我们的方法可以通过一次演示来操作不同的对象,并且在两种环境中都显着优于基线,模拟中域内绳索的改进为 62,分布外绳索的改进为 15 |
| CNS: Correspondence Encoded Neural Image Servo Policy Authors Anzhe Chen, Hongxiang Yu, Yue Wang, Rong Xiong 图像伺服是机器人应用中不可或缺的技术,有助于实现高精度定位。图像伺服策略的中间表示对于传感器输入抽象和策略输出指导非常重要。经典方法可以实现高精度,但需要干净的关键点对应关系,并且受到收敛盆地有限或特征误差鲁棒性较弱的影响。最近的基于学习的方法在特定场景上实现了中等精度和大收敛盆地,但在推广到新环境时面临问题。在本文中,我们将关键点和对应关系编码成图,并使用图神经网络作为控制器的架构。该设计利用了关键点对应的可推广中间表示和神经网络强大的建模能力的优点。还提出了现实数据生成、特征聚类和距离解耦等其他技术,以进一步提高效率、精度和泛化能力。仿真和现实世界中的实验验证了我们的方法在速度最大 40fps 以及观察器、精度 0.3 和亚毫米精度以及从模拟到真实的概括(无需微调)方面的有效性。 |
| Pedestrian Trajectory Prediction Using Dynamics-based Deep Learning Authors Honghui Wang, Weiming Zhi, Gustavo Batista, Rohitash Chandra 行人轨迹预测在自动驾驶系统和机器人技术中发挥着重要作用。最近的工作利用著名的深度学习模型进行行人运动预测,对人体运动的先验假设有限,导致缺乏可解释性和对预测轨迹的明确约束。本文提出了一种基于动力学的深度学习框架,其中将新颖的渐近稳定动力系统集成到深度学习模型中。我们新颖的渐近稳定动力系统用于通过强制人类行走轨迹收敛到预测的目标位置来对人类目标目标运动进行建模,并提供具有先验知识和可解释性的深度学习模型。我们的深度学习模型利用变压器网络的最新创新,用于学习我们提出的动力系统的人体运动的一些特征,例如避免碰撞。 |
| Kinetostatic Path Planning for Continuum Robots By Sampling on Implicit Manifold Authors Yifan Wang, Yue Chen 与刚性连接机器人相比,Continuum 机器人 CR 具有出色的灵活性和合规性,使其适合在受限环境中导航并与之交互。然而,考虑外部弹性接触的 CR 路径规划研究有限。挑战在于,CR 在接触时可能有多种可能的配置,导致正向运动学无法很好地定义,并且将可行的机器人配置集描述为非平凡的。在本文中,我们建议通过在隐式流形上执行准静态路径规划来解决这个问题。我们将弹性障碍物建模为外部势场,并将势场中的机器人静力学公式化为通过一阶变分原理获得的最优控制问题的极值轨迹。我们证明了一组稳定的机器人配置是嵌入 CR 驱动和基础内部扳手乘积空间中的子流形的平滑流形微分同胚。然后,我们建议使用 AtlasRRT 对此流形执行路径规划,AtlasRRT 是一种基于采样的规划器,致力于对隐式流形进行规划。 |
| Triple Regression for Camera Agnostic Sim2Real Robot Grasping and Manipulation Tasks Authors Yuanhong Zeng, Yizhou Zhao, Ying Nian Wu Sim2Real 现实仿真技术在机器人操纵和运动规划领域获得了突出地位,因为它们能够通过使代理测试和评估各种策略和轨迹来提高成功率。在本文中,我们研究了将 Sim2Real 集成到机器人框架中的优势。我们引入了 Triple Regression Sim2Real 框架,该框架构建了实时数字孪生。这个双胞胎充当现实的复制品,在现实场景中执行之前模拟和评估多个计划。我们的三重回归方法通过以下方式解决了现实差距:1 通过前两个回归模型减轻真实和模拟摄像机视角之间的投影误差,2 使用第三个回归模型检测机器人控制中的差异。在 6 DoF 抓取和操作任务上进行的实验(其中夹具可以从任何方向接近)凸显了我们框架的有效性。值得注意的是,仅使用 RGB 输入图像,我们的方法就实现了最先进的成功率。 |
| Optimal Initialization Strategies for Range-Only Trajectory Estimation Authors Abhishek Goudar, Frederike D mbgen, Timothy D. Barfoot, Angela P. Schoellig 仅范围 RO 位姿估计涉及通过测量机器人上的多个设备(称为标签)和安装在环境中的设备(称为锚点)之间的距离来确定机器人随时间的位姿。距离测量模型的非凸性质导致成本函数具有可能的局部最小值。如果没有良好的初始化,常用的迭代求解器可能会陷入这些局部最小值,导致轨迹估计精度较差。在这项工作中,我们基于半定程序 SDP 提出了对原始非凸问题的凸松弛。具体来说,我们制定了计算上易于处理的 SDP 松弛,以获得准确的初始位姿和轨迹估计,用于静态和动态(即等速运动)条件下的 RO 轨迹估计。通过模拟和实际实验,我们证明了我们提出的初始化策略与迭代局部求解器相比可以准确地估计初始状态。 |
| MonoForce: Self-supervised learning of physics-aware grey-box model for predicting the robot-terrain interaction Authors Ruslan Agishev, Karel Zimmermann, Martin Pecka, Tom Svoboda 我们引入了一种可解释的、物理感知的、端到端的可微分模型,该模型可以根据相机图像预测机器人地形交互的结果。所提出的 MonoForce 模型由一个黑盒模块组成,该模块通过机载摄像头预测机器人地形相互作用力,然后是一个白盒模块,该模块通过经典力学定律将这些力转换为预测轨迹。由于白盒模型是作为可微分 ODE 求解器实现的,因此它能够测量机器人的预测力和地面真实轨迹之间的物理一致性。因此,它会产生类似于 MonoDepth 的自监督损失。为了促进论文的可重复性,我们提供源代码。 |
| OmniLRS: A Photorealistic Simulator for Lunar Robotics Authors Antoine Richard, Junnosuke Kamohara, Kentaro Uno, Shreya Santra, Dave van der Meer, Miguel Olivares Mendez, Kazuya Yoshida 开发外星机器人探索算法一直具有挑战性。除了与这些环境相关的复杂性之外,主要问题之一仍然是所述算法的评估。随着人们对月球探索的兴趣重新燃起,人们也需要高质量的模拟器来支持月球机器人的开发。在本文中,我们解释了如何基于 Nvidia 的机器人模拟器 Isaac Sim 构建月球模拟器。在本文中,我们提出了 Omniverse Lunar Robotic Sim OmniLRS,它是一个基于 Nvidia 机器人模拟器的逼真月球模拟器。该模拟提供快速的程序环境生成、多机器人功能以及用于机器学习应用的合成数据管道。它配备了 ROS1 和 ROS2 绑定,不仅可以控制机器人,还可以控制环境。这项工作还对真实的岩石实例分割进行了模拟,以显示我们的模拟器对于基于图像的感知的有效性。在我们的合成数据上进行训练后,yolov8 模型的性能接近于在真实世界数据上训练的模型,但性能差距为 5。当使用真实数据进行微调时,该模型的平均精度比根据真实世界数据训练的模型高出 14 倍,展示了我们的模拟器的真实感。实现拟真。 |
| Efficient Object Rearrangement via Multi-view Fusion Authors Dehao Huang, Chao Tang, Hong Zhang 辅助机器人协助物体组织的前景一直令人瞩目。在图像目标设置中,机器人重新排列当前场景以匹配从目标场景捕获的单个图像。图像目标重排系统的关键是根据单个目标图像和当前场景的观察来估计每个对象的所需放置姿势。为了建立足够的关联以进行准确估计,系统应从与目标图像中相似的视角观察对象。现有的图像目标重排系统由于依赖固定视点进行感知,通常需要冗余操作来随机调整对象的姿势以获得更好的视角。为了解决这种低效率问题,我们引入了一种采用多视图融合的新颖的对象重新排列系统。通过在操纵对象之前从多个视点观察当前场景,我们的方法可以估计更准确的姿势,而无需多余的操纵时间。开发了对象级别的标准视觉定位管道,以利用多视图观察的优势。仿真结果表明,我们的系统的效率优于现有的单视图系统。 |
| RMP: A Random Mask Pretrain Framework for Motion Prediction Authors Yi Yang, Qingwen Zhang, Thomas Gilles, Nazre Batool, John Folkesson 随着预训练技术的日益普及,自动驾驶中基于预训练学习的运动预测方法的研究还很少。在本文中,我们提出了一个框架来形式化交通参与者轨迹预测的预训练任务。在我们的框架中,受到自然语言处理 NLP 和计算机视觉 CV 中随机屏蔽模型的启发,随机时间步的对象位置被屏蔽,然后由学习的神经网络 NN 填充。通过改变掩模轮廓,我们的框架可以轻松地在一系列运动相关任务之间切换。 |
| Multi-objective tuning for torque PD controllers of cobots Authors Diego Navarro Cabrera, Niceto R. Luque, Eduardo Ros 协作机器人技术是运动控制和人机交互领域的一个新的、具有挑战性的领域。机器人与其环境之间可靠交互所需的安全措施阻碍了经典控制方法的使用,促使研究人员尝试机器学习 ML 等新技术。在这种背景下,强化学习已被用作创建协作机器人智能控制器的主要方式,然而监督学习显示出巨大的前景,希望以更快、更安全的方式开发基于数据驱动模型的机器学习控制器。在这项工作中,我们研究了创建用于学习机器人动力学的数据集所需的方法的几个方面。为此,我们使用多目标遗传算法 GA 将多个 PD 控制器调整到多个轨迹,该算法不仅考虑了它们的准确性,还考虑了它们的安全性。 |
| Deliberative Context-Aware Ambient Intelligence System for Assisted Living Homes Authors Mohannad Babli, Jaime A Rincon, Eva Onaindia, Carlos Carrascosa, Vicente Julian 监测健康和压力是环境智能涵盖的问题之一,因为压力是直接影响我们情绪状态的人类疾病的重要原因。主要目的是为环境智能医疗保健应用程序提出一种审议架构。该建筑提供了一个计划,用于安慰在辅助生活之家中遭受负面情绪困扰的压力老年人,并考虑到环境的动态性质来执行该计划。我们回顾了文献,以确定深思熟虑和环境智能之间的融合以及后者最新的医疗保健趋势。审议功能旨在实现情境感知动态人类机器人交互、感知、规划能力、反应性和对环境的情境感知。在模拟辅助生活家庭场景中进行了许多实验案例研究,以证明该方法的行为和有效性。所提出的方法经过验证以显示分类准确性。 |
| Outram: One-shot Global Localization via Triangulated Scene Graph and Global Outlier Pruning Authors Pengyu Yin, Haozhi Cao, Thien Minh Nguyen, Shenghai Yuan, Shuyang Zhang, Kangcheng Liu, Lihua Xie 一次激光雷达定位是指从一个单点云估计机器人姿态的能力,这在初始化和重新定位过程中产生显着的优势。在点云领域,该主题已作为全局描述符检索(即闭环检测)和姿态细化(即单独或组合的点云配准问题)进行了广泛研究。然而,很少有人明确考虑姿势估计中候选检索和对应生成之间的关系,这使得它们很容易受到子结构模糊性的影响。为此,我们提出了一种名为 Outram 的分层一次性定位算法,该算法利用 3D 场景图的子结构进行局部一致的对应搜索和全局子结构明智的异常值修剪。这种分层过程将特征检索和对应关系提取结合起来,通过进行局部到全局的一致性细化来解决子结构的歧义。我们在多个大型户外数据集中的各种场景中展示了 Outram 的能力。 |
| CARLA-Loc: Synthetic SLAM Dataset with Full-stack Sensor Setup in Challenging Weather and Dynamic Environments Authors Yuhang Han, Zhengtao Liu, Shuo Sun, Dongen Li, Jiawei Sun, Ziye Hong, Marcelo H. Ang Jr SLAM算法在具有挑战性的环境条件下的鲁棒性对于自动驾驶至关重要,但考虑到在现实世界中任意改变同一环境的相关环境参数的难度,这些条件的影响是未知的。因此,我们提出了 CARLA Loc,这是一个基于 CARLA 模拟器构建的具有挑战性和动态环境的综合数据集。我们通过严格的校准、同步和精确的时间戳将多个传感器集成到数据集中。我们的数据集中有 7 张地图和 42 个序列,具有不同的动态级别和天气条件。立体图像和点云中的对象都可以通过其类标签进行很好的分割。 |
| Stylized Table Tennis Robots Skill Learning with Incomplete Human Demonstrations Authors Xiang Zhu, Zixuan Chen, Jianyu Chen 近年来,强化学习 RL 正在成为训练机器人控制器的流行技术。然而,对于复杂的动态机器人控制任务,基于强化学习的方法通常会产生风格不切实际的控制器。相比之下,人类可以在监督下学习良好的程式化技能。例如,人们通过模仿教练的动作来学习乒乓球技术。此类参考运动通常是不完整的,例如没有实际球的存在。受此启发,我们提出了一种基于强化学习的算法来训练机器人,使其能够从此类不完整的人类演示中学习游戏风格。我们通过示教和拖拽的方式来收集数据。我们还提出了数据增强技术,使我们的机器人能够适应不同速度的球。 |
| Asynchronous Task Plan Refinement for Multi-Robot Task and Motion Planning Authors Yoonchang Sung, Rahul Shome, Peter Stone 本文探讨了一般的多机器人任务和运动规划,其中多个机器人靠近操作物体,同时满足约束和给定目标。特别是,我们制定了计划细化问题,在给定任务计划的情况下,找到与解决方案轨迹相对应的变量的有效分配作为混合约束满足问题。所提出的算法遵循几个设计原则,产生以下特征:1.由于顺序启发式和隐式时间和路线图表示而有效地找到解决方案;2.通过引入最少必要的协调诱导约束而不依赖于存在于中的普遍简化来获得最大化的可行解决方案空间。文献。 |
| Graph-based Decentralized Task Allocation for Multi-Robot Target Localization Authors Juntong Peng, Hrishikesh Viswanath, Kshitij Tiwari, Aniket Bera 我们引入了一种新方法来解决由无人驾驶地面车辆 UGV 和无人驾驶飞行器 UAV 组成的异构机器人系统中的任务分配问题。所提出的模型,texttt方法,或textbf图textbf注意textbfT问textbf分配textbfR聚合多机器人系统中邻居的信息,目的是在目标定位效率中实现联合最优。我们的方法是分散的,高度稳健,能够适应合作者可能随时间变化的情况,确保任务的连续性。我们还提出了异构感知预处理,让所有不同类型的机器人与统一的模型协作。实验结果证明了该方法在一系列模拟场景中的有效性和可扩展性。该模型可以分配接近专家算法结果的目标位置,且中值空间间隙小于单位长度。 |
| Pour me a drink: Robotic Precision Pouring Carbonated Beverages into Transparent Containers Authors Feiya Zhu, Shuo Hu, Letian Leng, Alison Bartsch, Abraham George, Amir Barati Farimani 随着人们越来越重视服务机器人在家庭环境中的开发和集成,我们需要赋予机器人可靠地倒各种液体的能力。然而,由于不同液体的复杂动力学和不同特性、防止溢出和确保准确倾倒所需的精确精度以及机器人无缝适应现实世界中的多种容器的必要性,液体处理和倾倒是一项具有挑战性的任务场景。为了应对这些挑战,我们提出了一种新颖的自主机器人管道,使机器人能够执行精确的倾倒任务,将碳酸和非碳酸液体,以及不透明和透明液体倒入各种透明容器中。我们提出的方法最大限度地发挥了 RGB 输入的潜力,通过利用现有的预先训练的视觉分割模型来实现零镜头能力。这消除了额外的数据收集、手动图像注释或大量培训的需要。此外,我们的工作集成了 ChatGPT,促进了无需具备机器人技术和浇注管道专业知识的个人之间的无缝交互。这种集成使用户能够轻松请求和执行浇注操作。 |
| SafeShift: Safety-Informed Distribution Shifts for Robust Trajectory Prediction in Autonomous Driving Authors Benjamin Stoler, Ingrid Navarro, Meghdeep Jana, Soonmin Hwang, Jonathan Francis, Jean Oh 随着自动驾驶技术的成熟,其关键组件(包括轨迹预测)的安全性和稳健性至关重要。虽然现实世界的数据集(例如 Waymo Open Motion)为模型开发提供了真实记录的场景,但它们通常缺乏真正的安全关键情况。我们没有利用不切实际的模拟或危险的现实世界测试,而是提出了一个框架来描述此类数据集并在其中找到隐藏的安全相关场景。我们的方法扩展了安全相关性的范围,使我们能够在安全知情的分布转移设置下研究轨迹预测模型。我们贡献了一种广义的场景表征方法、一种新颖的评分方案来发现巧妙避免的风险场景,以及在此设置中对轨迹预测模型的评估。我们进一步贡献了一种补救策略,实现了预测冲突率平均降低 10 倍。 |
| GRaCE: Optimizing Grasps to Satisfy Ranked Criteria in Complex Scenario Authors Tasbolat Taunyazov, Kelvin Lin, Harold Soh 本文解决了机器人抓取的多方面问题,其中多个标准可能相互冲突且重要性不同。我们引入了抓取排名和标准评估 GRaCE,这是一种新颖的方法,它采用基于分层规则的逻辑和排名保留效用函数,根据稳定性、运动学约束和面向目标的功能等各种标准来优化抓取。此外,我们提出了 GRaCE OPT,这是一种混合优化策略,结合了基于梯度和无梯度的方法,以有效地导航复杂的非凸效用函数。模拟和现实场景中的实验结果表明,GRaCE 需要更少的样本即可实现与现有方法相当或更好的性能。 |
| Towards Geometric Motion Planning for High-Dimensional Systems: Gait-Based Coordinate Optimization and Local Metrics Authors Yanhao Yang, Ross L. Hatton 几何运动规划为运动系统提供了有效且可解释的步态分析和优化工具。然而,由于几何运动规划的关键组成部分坐标优化中的维数灾难,将当前的几何运动规划应用于高维系统几乎是不可行的。在本文中,我们提出了一种基于步态的坐标优化方法,克服了维数灾难。我们还通过将各种非完整约束概括为局部度量来确定运动的统一几何表示。通过结合这两种方法,我们向高维系统的几何运动规划迈出了一步。我们在两类高维系统(低雷诺数游泳者和自由落体 Cassie,具有多达 11 维形状变量)中测试我们的方法。与降阶模型相比,高维系统中得到的最佳步态显示出更好的效率。 |
| ARTEMIS: AI-driven Robotic Triage Labeling and Emergency Medical Information System Authors Sathvika Kotha, Hrishikesh Viswanath, Kshitij Tiwari, Aniket Bera 大规模伤亡事件导致现有资源和人员不堪重负,对紧急医疗服务构成巨大挑战。有效的受害者评估对于最大限度地减少此类危机中的伤亡至关重要。在本文中,我们介绍了 ARTEMIS,这是一种人工智能驱动的机器人分诊标签和紧急医疗信息系统。该系统包含一个与机器人集成的用于敏锐度标签的深度学习模型,该模型对患者损伤严重程度进行初步评估并分配适当的分类标签。此外,我们还开发了一个前端图形用户界面,该界面由机器人实时更新,并且可供急救人员访问。为了验证我们提出的算法分类协议的可靠性,我们采用了一个现成的机器人套件,配备了用于采集生命体征的传感器。进行了 MCI 的受控实验室模拟,以评估系统在现实场景中的性能和有效性,最终分类精度达到 92 。 |
| Trajectory Tracking Control of Skid-Steering Mobile Robots with Slip and Skid Compensation using Sliding-Mode Control and Deep Learning Authors Payam Nourizadeh, Fiona J Stevens McFadden, Will N Browne 打滑补偿对于移动机器人在室外环境和不平坦地形中的导航至关重要。除了户外环境中移动机器人普遍存在的滑倒和打滑危险之外,滑倒和打滑还会给轨迹跟踪系统带来不确定性,并使稳定性分析的有效性面临风险。尽管在这一领域进行了研究,但由于室外环境中车轮地形相互作用的复杂性,拥有现实世界中可行的在线滑移和打滑补偿仍然具有挑战性。本文提出了一种新颖的轨迹跟踪技术,具有现实世界可行的车辆级在线滑移和滑移补偿,适用于室外环境中的滑移转向移动机器人。利用滑模控制技术来设计鲁棒的轨迹跟踪系统,以能够考虑此类机器人的参数不确定性。两个先前开发的深度学习模型 1、2 被集成到控制反馈回路中,以估计机器人的打滑和不期望的打滑,并以实时方式反馈给补偿器。该技术的主要优点是:1.考虑两个滑移相关参数,而不是传统的轮级三个滑移参数;2.具有在线现实世界可行的滑移和滑移补偿器,能够减少不可预见环境中的跟踪误差。 |
| DenseTact-Mini: An Optical Tactile Sensor for Grasping Multi-Scale Objects From Flat Surfaces Authors Won Kyung Do, Ankush Kundan Dhawan, Mathilda Kitzmann, Monroe Kennedy III 灵巧的操作,尤其是日常小型物体的灵巧操作,继续对机器人技术提出复杂的挑战。本文介绍了 DenseTact Mini,这是一种光学触觉传感器,具有柔软、圆形、光滑的凝胶表面和紧凑的设计,配备了人造指甲。我们提出了三种不同的抓取策略:利用静电和范德华等粘附力进行轻击抓取,利用物体和指甲之间的滚动滑动接触进行指甲抓取,以及使用两个柔软的指尖进行指尖抓取。通过综合评估,DenseTact Mini在抓取各种物体时表现出超过90.2的举升成功率,涵盖从1毫米罗勒种子和小回形针到近15毫米的物体。 |
| Intention-Aware Planner for Robust and Safe Aerial Tracking Authors Qiuyu Ren, Huan Yu, Jiajun Dai, Zhi Zheng, Jun Meng, Li Xu 目标的意图可以帮助我们更准确地估计其未来的运动状态。本文提出了一种意图感知规划器,以增强空中跟踪应用的安全性和鲁棒性。首先,我们利用 Mediapipe 框架来估计目标姿态。设计风险评估函数和状态观察函数来预测目标意图。随后,提出了一种意图驱动的混合 A 方法来进行目标运动预测,确保目标的未来位置与其意图一致。最后,设计了一种意图感知优化方法,结合特定的惩罚公式,生成时空最优轨迹。基准比较验证了我们提出的方法在不同场景下的卓越性能。 |
| Learning a Stable Dynamic System with a Lyapunov Energy Function for Demonstratives Using Neural Networks Authors Yu Zhang, Yongxiang Zou, Haoyu Zhang, Xiuze Xia, Long Cheng 基于自主动态系统 DS 的算法在演示 LfD 学习领域中发挥着关键和基础作用。然而,他们面临着巨大的挑战,即在实现学习精度和确保系统的整体稳定性之间取得微妙的平衡。为了应对这一重大挑战,本文介绍了一种基于神经网络技术的新型 DS 算法。该算法不仅具有从演示数据中提取关键见解的能力,而且还具有学习与所提供的数据一致的候选李雅普诺夫能量函数的能力。本文提出的模型采用简单的神经网络架构,擅长实现双目标优化精度,同时保持全局稳定性。 |
| Distributionally Robust CVaR-Based Safety Filtering for Motion Planning in Uncertain Environments Authors Sleiman Safaoui, Tyler H. Summers 安全性是自主机器人运动规划的核心挑战,特别是在存在动态和不确定障碍的情况下。最近的许多结果使用基于学习和深度学习的运动规划器和预测模块来预测多个可能的障碍物轨迹并生成障碍物感知自我机器人计划。然而,忽视此类预测固有不确定性的规划者会带来碰撞风险,并且缺乏正式的安全保证。在本文中,我们提出了一种计算高效的安全过滤解决方案,以使用障碍物轨迹预测的多个样本来降低自我机器人运动计划的碰撞风险。所提出的方法通过使用分布鲁棒优化 DRO 技术基于障碍物样本轨迹计算安全半空间来重新表述防撞问题。安全半空间用于模型预测控制 MPC(如安全滤波器),对参考自我轨迹进行修正,从而促进更安全的规划。 |
| URA*: Uncertainty-aware Path Planning using Image-based Aerial-to-Ground Traversability Estimation for Off-road Environments Authors Charles Moore, Shaswata Mitra, Nisha Pillai, Marc Moore, Sudip Mittal, Cindy Bethel, Jingdao Chen 越野自主导航的一个主要挑战是缺乏可用于规划自主机器人路径的地图或道路标记。经典的路径规划方法大多假设一个完全已知的环境,而不考虑越野环境中检测地形和障碍物所带来的固有感知和感知不确定性。最近在计算机视觉和深度神经网络方面的工作已经提高了从原始图像进行地形可穿越性分割的能力,但是,使用这些噪声分割图进行导航和路径规划的可行性尚未得到充分探索。为了解决这个问题,本研究提出了一种不确定性感知路径规划方法,URA 使用航空图像在越野环境中进行自主导航。首先使用集成卷积神经网络 CNN 模型对感兴趣区域的航空图像进行像素级可遍历性估计。可遍历性预测表示为遍历概率值的网格。然后,在给定这些噪声遍历概率估计的情况下,应用不确定性感知规划器来计算从起点到目标点的最佳路径。所提出的规划器还结合了重新规划技术,以允许在在线机器人操作期间快速重新规划。该方法在马萨诸塞州道路数据集、DeepGlobe 数据集以及密西西比州立大学越野试验场的航拍图像数据集上进行了评估。 |
| UIVNAV: Underwater Information-driven Vision-based Navigation via Imitation Learning Authors Xiaomin Lin, Nare Karapetyan, Kaustubh Joshi, Tianchen Liu, Nikhil Chopra, Miao Yu, Pratap Tokekar, Yiannis Aloimonos 由于能见度有限、动态变化以及缺乏具有成本效益的精确定位系统,水下环境中的自主导航具有挑战性。我们推出了 UIVNav,这是一种新颖的端到端水下导航解决方案,旨在驱动机器人越过感兴趣的 OOI 对象,同时避开障碍物,而不依赖于本地化。 UIVNav 使用模仿学习,其灵感来自于不依赖本地化的人类潜水员使用的导航策略。 UIVNav 包含以下阶段:1 生成中间表示 IR ,2 训练基于人类标记 IR 的导航策略。通过在 IR 而不是原始数据上训练导航策略,第二阶段是域不变的,如果域或 OOI 发生变化,则不需要重新训练导航策略。我们通过部署相同的导航策略来测量两个不同的 OOI(牡蛎和岩礁),在两个不同的域(模拟和真实池)中展示这一点。我们将我们的方法与完全覆盖和随机游走方法进行了比较,这表明我们的方法在收集 OOI 信息方面更有效,同时也避免了障碍。结果表明,UIVNav 在没有有关环境或定位的先验信息的情况下选择访问牡蛎或岩石面积较大的区域。此外,与完全覆盖方法相比,使用 UIVNav 的机器人在行驶相同距离时平均多调查 36 个牡蛎。 |
| Robust Indoor Localization with Ranging-IMU Fusion Authors Fan Jiang 1 and 2 , David Caruso 1 , Ashutosh Dhekne 2 , Qi Qu 1 , Jakob Julian Engel 1 , Jing Dong 1 1 Meta Reality Labs Research, 2 Georgia Institute of Technology 室内无线测距定位是可穿戴设备低功耗、高精度定位的一种有前途的方法。该领域的主要挑战源于无线电波的非视距传播。这项研究解决了无线测距中的一个基本问题,即实时多路径确定的不可预测性,特别是在具有挑战性的条件下,例如没有直接视线时。我们通过将距离测量与从低成本惯性测量单元 IMU 获得的惯性测量相融合来实现这一目标。为此,我们引入了一种专门针对非高斯多径干扰而设计的新型非对称噪声模型。此外,我们还提出了一种新颖的 Levenberg Marquardt LM 系列信任区域适应 iSAM2 融合算法,该算法针对我们的测距 IMU 融合问题进行了鲁棒性能优化。我们在人员密集的真实办公环境中评估我们的解决方案。我们提出的解决方案可以在现实世界设置中实现时间一致的定位,平均绝对精度为 sim 0.3m。 |
| Geometric Projectors: Geometric Constraints based Optimization for Robot Behaviors Authors Xuemin Chi, Tobias L w, Yiming Li, Zhitao Liu, Sylvain Calinon 为与各种形状的物体交互的机器人生成运动是一项复杂的挑战,当考虑到机器人自身的几何形状和多种所需行为时,情况会变得更加复杂。为了解决这个问题,我们引入了一个基于几何投影仪 GeoPro 的新框架,用于约束优化。这种新颖的框架允许生成符合几何约束的任务无关行为。 GeoPro 简化了任务和配置空间中的行为设计,提供了多种功能,例如避免碰撞和达到目标,同时保持高计算效率。我们通过模拟和 Franka Emika 机器人实验验证我们工作的有效性,将其性能与最先进的方法进行比较。这项综合评估凸显了 GeoPro 在适应具有不同动力学和精确几何形状的机器人方面的多功能性。 |
| Simultaneous Trajectory Estimation and Mapping for Autonomous Underwater Proximity Operations Authors Aldo Ter n Espinoza, Antonio Ter n Espinoza, John Folkesson, Niklas Rolleberg, Peter Sigray, Jakob Kuttenkeuler 由于其续航能力和自主能力的限制,自主水下航行器 AUV 的水下对接已成为许多学术和商业应用感兴趣的话题。在这里,我们研究自主水下对接任务期间的状态估计问题。对接操作通常只涉及两个参与者:追逐者和目标。我们利用与航天器机器人任务中的接近操作 prox ops 的相似性,通过追赶者在到达目标的途中经历的一组阶段来构建不同的对接场景。我们使用因子图来概括任意水下近似操作的基本估计问题。为了展示我们的框架,我们使用这种因子图方法对具有活动目标的水下归航场景进行建模,作为同步定位和建图问题。使用基本的AUV导航传感器、相对超短基线测量以及目标恒定动态的假设,我们推导出限制追踪器状态以及目标位置和轨迹的因素。我们使用开源软件和库详细介绍了我们的前端和后端软件实现,并通过模拟和现场实验验证了其性能。获得的结果显示,无论是否存在其动态使建模假设无效的对抗性目标,与未处理的测量相比,性能总体提高。 |
| Constrained Bimanual Planning with Analytic Inverse Kinematics Authors Thomas Cohn, Seiji Shaw, Max Simchowitz, Russ Tedrake 为了使双手机器人能够操纵双手握住的物体,它必须构建运动计划,使其末端执行器之间的变换保持固定。这相当于配置空间中复杂的非线性等式约束,这对于轨迹优化器来说是困难的。此外,可行配置集成为测量零集,这对基于采样的运动规划器提出了挑战。我们利用逆运动学问题的解析解来参数化配置空间,从而产生较低维的表示,其中有效配置集具有正测量。 |
| The Fractal Hand-II: Reviving a Classic Mechanism for Contemporary Grasping Challenges Authors Malcolm G. A. Tisdale, Joel W. Burdick 本文及其同伴提出了一种新的分形机器人夹具,其灵感来自于具有百年历史的分形虎钳。不同寻常的协同特性使其能够仅使用一个执行器被动地适应不同的物体。它旨在轻松与流行的平行钳口夹具集成,减轻了与感知和抓取规划相关的复杂性,特别是在处理不可预测的物体姿势和几何形状时。我们以分形虎钳的基本原理为基础,开发出更广泛的抓取机制,并解决了导致其默默无闻的局限性。两个分形手指通过闭合执行器耦合,可以形成自适应且协同的分形手。我们阐明了一种低成本、易于制造、大工作空间和兼容的分形手指的设计方法。 |
| RoSSO: A High-Performance Python Package for Robotic Surveillance Strategy Optimization Using JAX Authors Yohan John, Connor Hughes, Gilberto Diaz Garcia, Jason R. Marden, Francesco Bullo 为了能够计算单个或多机器人团队的有效随机巡逻路线,我们提出了 RoSSO,这是一个专为解决马尔可夫链优化问题而设计的 Python 包。与通用非线性编程求解器相比,我们利用反向模式自动微分和约束参数化等机器学习技术来实现更高的效率。此外,我们用新颖的贪婪算法和多机器人扩展补充了文献中的博弈论随机监视公式。 |
| Optimal path planning of multi-agent cooperative systems with rigid formation Authors Ananda Rangan Narayanan, Mi Zhou, Erik Verriest 在本文中,我们考虑具有刚性结构的协作同质机器人系统的路径规划问题。基于庞特里亚金最小原理理论,为此类刚性系统中的每个智能体设计了最优控制器。我们发现每个智能体的最优控制相当于质心 CoM 的最优控制。然后通过使用一些分析力学证明了这种等价性。最后模拟了三个例子来说明我们的理论结果。 |
| Pointing the Way: Refining Radar-Lidar Localization Using Learned ICP Weights Authors Daniil Lisus, Johann Laconte, Keenan Burnett, Timothy D. Barfoot 本文提出了一种基于深度学习的新颖方法,用于改进针对激光雷达地图的雷达测量定位。尽管定位的最先进技术是将激光雷达数据与激光雷达地图相匹配,但雷达被认为是一种有前途的替代方案,因为它可能更能抵御降水和大雾等恶劣天气。为了利用现有的高质量激光雷达地图,同时在恶劣天气下保持性能,将雷达数据与激光雷达地图相匹配是很重要的。然而,部分由于雷达测量中存在独特的人为因素,雷达激光雷达定位一直难以实现与激光雷达系统相当的性能,从而使其无法用于自动驾驶。这项工作建立在基于 ICP 的雷达激光雷达定位系统的基础上,包括一个学习的预处理步骤,该步骤根据高级扫描信息对雷达点进行加权。 |
| SculptBot: Pre-Trained Models for 3D Deformable Object Manipulation Authors Alison Bartsch, Charlotte Avra, Amir Barati Farimani 可变形物体操纵表现出高自由度和严重的自遮挡,给机器人操纵带来了一系列独特的挑战。表现出塑性行为的材料(例如建模粘土或面包面团)的状态表示也很困难,因为它们在压力下永久变形并且不断改变形状。在这项工作中,我们使用平行夹具的机器人雕刻任务来研究这些挑战。我们提出了一种系统,该系统使用点云作为状态表示,并利用预先训练的点云重建 Transformer 来学习潜在的动力学模型,以预测给定抓取动作的材料变形。我们设计了一种新颖的动作采样算法,该算法可以推理点云之间的几何差异,以进一步提高基于模型的规划器的效率。所有数据和实验完全在现实世界中进行。 |
| Wasserstein Distributionally Robust Control Barrier Function using Conditional Value-at-Risk with Differentiable Convex Programming Authors Alaa Eddine Chriat, Chuangchuang Sun 控制屏障功能 CBF 因设计安全控制器以部署在现实世界的安全关键系统中而引起了广泛关注。然而,对周围环境的感知往往受到随机性和与名义分布的进一步分布变化的影响。 |
| GEDepth: Ground Embedding for Monocular Depth Estimation Authors Xiaodong Yang, Zhuang Ma, Zhiyu Ji, Zhe Ren 单目深度估计是一个不适定问题,因为可以从无限的 3D 场景投影相同的 2D 图像。尽管该领域的领先算法已经报告了显着的改进,但它们本质上是针对图像观察和相机参数(即内在参数和外在参数)的特定组合,强烈限制了它们在现实世界场景中的普遍性。为了应对这一挑战,本文提出了一种新颖的地面嵌入模块,将相机参数与图像线索解耦,从而提高泛化能力。给定相机参数,所提出的模块会生成地面深度,该深度与输入图像叠加并在最终深度预测中引用。该模块中设计了地面注意力机制,以最佳方式结合地面深度和剩余深度。我们的地面嵌入高度灵活且轻量级,从而形成了适合集成到各种深度估计网络中的插件模块。 |
| Hierarchical Attention and Graph Neural Networks: Toward Drift-Free Pose Estimation Authors Kathia Melbouci, Fawzi Nashashibi 用于解决 3D 几何配准问题的最常用方法是迭代最近点算法,这种方法是增量的,并且容易在多个连续帧上发生漂移。解决漂移的常见策略是在帧到帧注册之后进行位姿图优化,结合识别先前访问过的位置的闭环过程。在本文中,我们探索了一种框架,该框架用利用分层注意机制和图神经网络的学习模型来取代传统的几何配准和姿势图优化。我们提出了一种压缩数据流的策略,保留精确估计刚性姿势所需的基本信息。我们的结果源自对 KITTI Odometry 数据集的测试,表明姿态估计精度有了显着提高。与通过位姿图优化通过传统多路配准获得的结果相比,这种改进在确定旋转分量方面尤其显着。 |
| Moving Object Detection and Tracking with 4D Radar Point Cloud Authors Zhijun Pan, Fangqiang Ding, Hantao Zhong, Chris Xiaoxuan Lu 移动自主依赖于对动态环境的精确感知。因此,在 3D 世界中鲁棒地跟踪移动对象对于轨迹预测、避障和路径规划等应用发挥着关键作用。虽然当前大多数方法都利用 LiDAR 或摄像机进行多目标跟踪 MOT,但 4D 成像雷达的功能在很大程度上仍未得到探索。认识到雷达噪声和 4D 雷达数据中的点稀疏性带来的挑战,我们推出了 RaTrack,这是一种专为基于雷达的跟踪而定制的创新解决方案。我们的方法绕过了对特定对象类型和 3D 边界框的典型依赖,专注于运动分割和聚类,并通过运动估计模块进行了丰富。 |
| Conditioning Latent-Space Clusters for Real-World Anomaly Classification Authors Daniel Bogdoll, Svetlana Pavlitska, Simon Klaus, J. Marius Z llner 自动驾驶领域的异常现象是自动驾驶汽车大规模部署的主要障碍。在这项工作中,我们专注于来自城市场景的高分辨率摄像机数据,其中包括各种类型和大小的异常现象。基于变分自动编码器,我们调节其潜在空间以将样本分类为正常数据或异常数据。为了强调特别小的异常,我们进行了实验,为 VAE 提供差异图作为附加输入,评估其对检测性能的影响。 |
| Towards Model Co-evolution Across Self-Adaptation Steps for Combined Safety and Security Analysis Authors Thomas Witte, Raffaela Groner, Alexander Raschke, Matthias Tichy, Irdin Pekaric, Michael Felderer 由于通过不同通道进行通信以及观察环境所需的不同传感器,自适应系统提供了多种攻击面。通常,攻击也会导致安全性受到损害,因此有必要同时考虑这两方面。此外,当前用于安全和安保分析的方法没有充分考虑适应的中间步骤。目前该领域的工作忽略了这样一个事实:自适应系统也会暴露可能的漏洞,即使只是在适应过程中暂时暴露。为了解决这个问题,我们提出了一种建模方法,该方法考虑了系统的不同相关方面、其适应过程以及安全隐患和安全攻击。我们提出了几个描述自适应系统不同方面的模型,并概述了如何将这些模型组合成攻击故障树的想法。这允许在不同的抽象级别上对系统的各个方面进行建模,并根据系统的适应性使用转换来共同演化模型。 |
| Design and Development of a Novel Soft and Inflatable Tactile Sensing Balloon for Early Diagnosis of Colorectal Cancer Polyps Authors Ozdemir Can Kara, Han Soul Kim, Jiaqi Xue, Tarunraj G. Mohanraj, Yuki Hirata, Naruhiko Ikoma, Farshid Alambeigi 在本文中,为了解决结肠镜检查过程中结直肠癌息肉的早期检测漏检率较高的问题,我们提出了一种独特的基于充气视觉的触觉传感球囊 VTSB 的设计和制造。所提出的软 VTSB 可以很容易地与现有结肠镜集成,并提供无辐射、安全、高分辨率的 CRC 息肉纹理映射和形态表征。所提出的 VTSB 的性能已在具有三种不同刚度水平的四种不同类型的增材制造 CRC 息肉体模上进行了彻底的表征和评估。 |
| Simulation of Sensor Spoofing Attacks on Unmanned Aerial Vehicles Using the Gazebo Simulator Authors Irdin Pekaric, David Arnold, Michael Felderer 在各种模拟器(例如 Gazebo 模拟器)中进行安全模拟已成为测试车辆潜在安全风险(即碰撞)的一种非常流行的方法。然而,安全测试的情况并非如此。在模拟器中执行安全测试非常困难,因为安全攻击是在不同的抽象级别上执行的。此外,攻击本身变得越来越复杂,这直接增加了在模拟器中执行攻击的难度。在本文中,我们尝试通过调查可以模拟的可能攻击,然后执行模拟来解决上述差距。所提出的方法表明,可以模拟针对无人机 LiDAR 和 GPS 组件的攻击。这是通过利用 ROS 和 MAVLink 协议的漏洞并将恶意进程注入应用程序来实现的。因此,具有任意值的消息可以被欺骗到相应的主题,从而允许攻击者更新相关参数并导致车辆潜在的崩溃。 |
| MEDL-U: Uncertainty-aware 3D Automatic Annotator based on Evidential Deep Learning Authors Helbert Paat, Qing Lian, Weilong Yao, Tong Zhang 基于深度学习的 3D 对象检测的进步需要大规模数据集的可用性。然而,这一要求带来了手动注释的挑战,这通常既繁重又耗时。为了解决这个问题,文献中出现了几种用于 3D 对象检测的弱监督框架,它们可以自动为未标记的数据生成伪标签。然而,这些生成的伪标签包含噪声,并且不如人类标记的准确。在本文中,我们提出了第一种方法,通过引入基于证据深度学习 EDL 的不确定性估计框架来解决伪标签中存在的固有模糊性。具体来说,我们提出了 MEDL U,一种基于 MTrans 的 EDL 框架,它不仅生成伪标签,而且还量化相关的不确定性。然而,将 EDL 应用于 3D 对象检测面临三个主要挑战:1 与其他自动标记器相比,伪标签质量相对较低;2 证据不确定性估计过高;3 下游任务缺乏明确的可解释性和不确定性的有效利用。我们通过引入基于不确定性的 IoU 损失、证据感知的多任务损失函数以及实施不确定性细化的后处理阶段来解决这些问题。我们的实验结果表明,使用 MEDL U 的输出训练的概率检测器优于使用先前 3D 注释器在所有难度级别的 KITTI val 集上的输出训练的确定性检测器。 |
| Mutual Information-calibrated Conformal Feature Fusion for Uncertainty-Aware Multimodal 3D Object Detection at the Edge Authors Alex C. Stutts, Danilo Erricolo, Sathya Ravi, Theja Tulabandhula, Amit Ranjan Trivedi 在人工智能机器人技术不断扩展的领域中,预测不确定性的稳健量化非常重要。三维 3D 物体检测是一项关键的机器人操作,已经取得了显着的进步,然而,当前的大多数工作仅关注准确性而忽略了不确定性量化。为了解决这一差距,我们的新研究将共形推理 CI 的原理与信息论测量相结合,在多模态框架内执行轻量级、无蒙特卡罗的不确定性估计。通过变分自编码器 VAE 中潜在变量的多元高斯积,融合 RGB 相机和 LiDAR 传感器数据的特征,以提高预测精度。归一化互信息 NMI 被用作调制器,用于校准基于加权损失函数从 CI 导出的不确定性界限。我们的模拟结果显示,在整个模型训练过程中,固有预测不确定性与 NMI 之间存在负相关。 |
| Desensitization and Deception in Differential Games with Asymmetric Information Authors Vinodhini Comandur, Tulasi Ram Vechalapu, Venkata Ramana Makkapati, Seth Hutchinson 脱敏通过提供基于敏感性函数的风险度量来解决参数不确定性下的安全最优规划。本文扩展了现有的脱敏工作,以解决一类两人差分游戏的安全规划问题。在所提出的游戏中,参数不确定性对应于模型参数向量关于其标称值的变化。假设所提出的公式中的两个参与者具有有关参数向量标称值的信息。然而,只有一个玩家被假设完全了解参数变化,从而在所提出的游戏中产生了一种信息不对称的形式。缺乏有关参数变化的知识预计会导致具有信息劣势的玩家违反状态约束。在这方面,提出了一种为信息不完整的玩家提供安全轨迹的脱敏反馈策略。所提出的反馈策略在涉及一名追赶者和一名躲避者且具有不确定动态障碍物的情况下进行评估,其中假设追赶者仅知道障碍物速度的标称值。同时,躲避者知道障碍物的真实速度,也知道追赶者仅拥有名义值。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com