一、日志重要吗
程序中的日志重要吗? 在回答这个问题前,笔者先说个事例:
❝笔者印象尤深的就是去年某个同事,收到了客户反馈的紧急bug。尽管申请到了日志文件,但因为很多关键步骤没有打印日志,导致排查进度很慢,数个小时都没能排查到问题,也无法给出解决对策。导致了客户程序一直阻断,最终产生了不少损失。 事后,经过仔细推敲,成功复现了这个bug,其实是一个很不起眼的数据转换导致的。可因为日志内容的匮乏,排查起来难度很大。其实只要在数据转换前后进行日志输出,这个问题就是一眼的事。但可惜没如果,故事的最后,开发部门还是遭到了客户的投诉,影响到了部门绩效
❞
对于刚学习编程的同学,很多人都对日志满不在乎,我们在做code review的时候,经常发现一些新同学喜欢一个方法写得很长,然后中间的注释和日志都少的可怜。
坦白的说,这是很不好的习惯,这意味着日后方法出了bug,或者需要迭代,要花费大量时间来理清方法的思路。千万别迷信什么“方法名、字段名起的见明知意,就可以不写注释与日志”,那是他们的业务场景不够复杂。以笔者为例,复杂的场景涉及很多公式、奇特的规定,不写注释与日志,后续没人能维护得了
所以请务必记住,日志在开发过程中非常重要。它可以帮助开发人员了解程序中发生了什么,以及在某些情况下为什么会发生错误或异常。通过查看日志,开发人员可以轻松地定位并解决问题,并且可以更好地监控和调整应用程序的性能,在必要时进行故障排除和安全检查
二、日志分级
最开始的日志分级是由Syslog的开发者Eric Allman在1981年提出的。之后,这个级别分级系统被广泛应用于各种领域的日志记录和信息处理中。下面我们就来介绍下常用的日志等级
- TRACE
是最低级别的日志记录,用于输出最详细的调试信息,通常用于开发调试目的。在生产环境中,应该关闭 TRACE 级别的日志记录,以避免输出过多无用信息。
- DEBUG
是用于输出程序中的一些调试信息,通常用于开发过程中。像 TRACE 一样,在生产环境中应该关闭 DEBUG 级别的日志记录。
- INFO
用于输出程序正常运行时的一些关键信息,比如程序的启动、运行日志等。通常在生产环境中开启 INFO 级别的日志记录。
- WARN
是用于输出一些警告信息,提示程序可能会出现一些异常或者错误。在应用程序中,WARN 级别的日志记录通常用于记录一些非致命性异常信息,以便能够及时发现并处理这些问题。
- ERROR
是用于输出程序运行时的一些错误信息,通常表示程序出现了一些不可预料的错误。在应用程序中,ERROR 级别的日志记录通常用于记录一些致命性的异常信息,以便能够及时发现并处理这些问题。
当然,除了这五种级别以外,还有一些日志框架定义了其他级别,例如 Python 中的 CRITICAL、PHP 中的 FATAL 等。CRITICAL 和 FATAL 都是用于表示程序出现了致命性错误或者异常,即不可恢复的错误。当然,对于我们今天要说的内容,知道上述五种日志等级就够了。
三、常用日志插件
- Log4j(1999年诞生)
Log4j 是Java领域中最早的流行日志框架之一。它由Ceki Gülcü开发,并后来由Apache软件基金会接管。Log4j 提供了灵活的配置选项、多种输出目的地、日志级别和分层日志体系。尽管Log4j 1在其时代取得了巨大的成功,但在性能和某些功能方面存在限制,因此后来演化为Log4j 2。
- SLF4J(2004年诞生)
严格来说,SLF4J(Simple Logging Facade for Java)并不算一个插件,而是Ceki Gülcü开发的一个日志门面接口。它为Java应用程序提供了统一的日志抽象,使开发人员可以使用一致的API进行日志记录,而不需要直接依赖于特定的日志实现。SLF4J 可以与多种底层日志框架(如Logback、Log4j 2、java.util.logging等)结合使用。
- Logback(2009年诞生)
Logback 是Ceki Gülcü开发的日志框架,他也是Log4j的作者。Logback 是Log4j 1的后续版本,旨在提供更高性能、更灵活的配置和现代化的日志解决方案。Logback 支持异步日志记录、多种输出格式、灵活的配置以及与SLF4J紧密集成。
- Log4j 2(2014年诞生)
Log4j 2 是Apache软件基金会开发的Log4j的下一代版本。它引入了许多新特性,如异步日志记录、插件支持、丰富的过滤器等,旨在提供更好的性能和灵活性。Log4j 2 在设计上考虑了Log4j 1的局限性,并且支持多种配置方式。
- 小故事
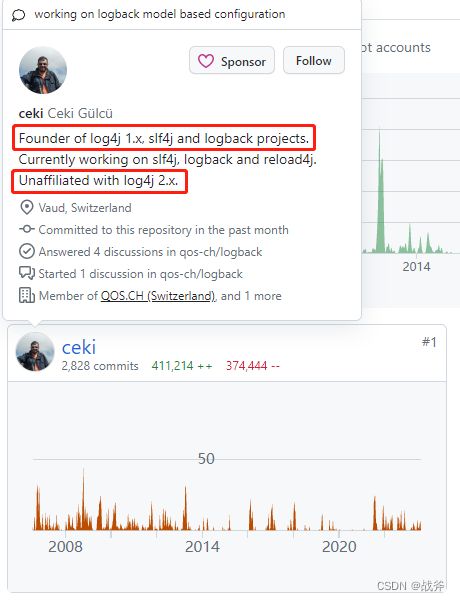
不难注意到,一个有意思的小故事是,前三款日志插件都是Ceki Gülcü开发的,但 Log4j 2 并不是,虽然现在有很多人以为log4j2也是他写的,但我们在github上可以看到其个人说明 “Unaffiliated with log4j 2.x.” (与 log4j 2.x 无关),所以log4j2 和 logback 都自称是log4j 的后续版本,到底谁才算正统续作呢?这就留给各位读者自己玩味了
四、外观模式与SLF4J
在讲解更多插件详情之前,我们先来看看使用最多的SLF4J ,我们前面说了 SLF4J(Simple Logging Facade for Java)是Ceki Gülcü开发的一个日志门面接口,那么很显然这里就用到了门面模式(即Facade 或 外观模式),笔者比较习惯说成是外观模式,后续就称为外观模式。
1. 外观模式
定义:外观模式是一种结构型设计模式,它提供了一个简单的接口,封装了底层复杂的子系统,使得客户端可以更方便地使用这个子系统
目的:外观模式的目的是隐藏底层系统的复杂性,降低访问成本。
如果说看定义有些抽象,那我们可以以生活中的例子来说,我们都知道现在越来越流行智能家居,也就是家庭内装了很多智能家电,从电视、空调、到廊灯甚至窗帘都是智能的。这类家庭往往会有一个控制中心,我们不需要手动去开电视,只需要对着控制中心说:“小A小A,帮我打开电视,音量调到30%”,电视就会应声打开并调节音量
那么这样的话,我们不需要知道怎么开电视,怎么调音量。通通都能用最简单的话语来调节。同理,现在手机上的拍照功能:感光度,对焦,白平衡这些细节都给你自动完成了,所以这些复杂的内容你现在根本不用管,只需要猛按拍照键即可。
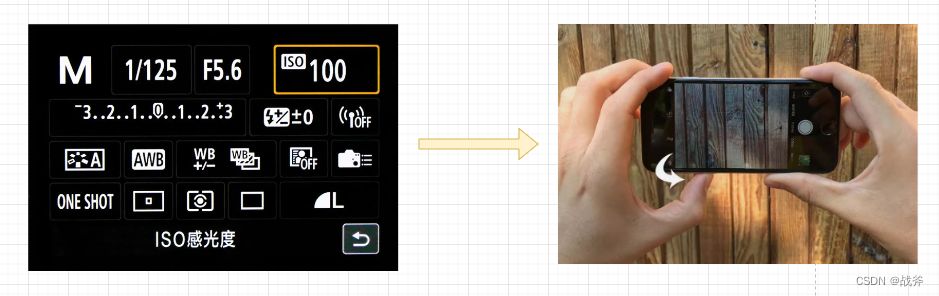
这就是外观模式的意义,外观模式就是为了隐藏系统的复杂性而设计出来的,让客户端只对接触到一个外观类,而不会接触到系统内部的复杂逻辑
2. SLF4J 的诞生
在早期使用日志框架时,应用程序通常需要直接与具体的日志框架进行耦合,这就导致了以下几个问题:
- 代码依赖性
应用程序需要直接引用具体的日志框架,从而导致代码与日志框架强耦合,难以满足应用程序对日志框架的灵活配置。
- 日志框架不统一
在使用不同的日志框架时,应用程序需要根据具体的日志框架来编写代码,这不仅会增加开发难度,而且在多种日志框架中切换时需要进行大量的代码改动。
- 性能问题
在日志输出频繁的情况下,由于日志框架的实现方式和API设计不同,可能会导致性能问题。
为了解决这些问题,SLF4J提供了一套通用的日志门面接口,让应用程序可以通过这些接口来记录日志信息,而不需要直接引用具体的日志框架。这样,应用程序就可以在不同的日志框架之间进行灵活配置和切换,同时还可以获得更好的性能表现。所以,我强烈建议各位使用SLF4J, 而不是直接对接某个具体的日志框架。
3. SLF4J 的使用
首先,我们需要在工程内引入包,但是如果你用了springboot,各种 spring-boot-starter 启动器已经引用过了,所以引用前最好确认下:
<dependency> <groupId>org.slf4j </groupId>
<artifactId>slf4j-api </artifactId>
<version>1.7.32 </version>
</dependency>
然后在我们要打印日志的类里加上一行 ;private static final Logger logger = LoggerFactory.getLogger(XXXX.class); 即可使用,如下:
import org.slf4j.Logger;import org.slf4j.LoggerFactory;
public class MyClass {
private static final Logger log = LoggerFactory.getLogger(MyClass .class);
//...
public static void main(String[] args) {
log.info( "This is an info message.");
}
}
如果我们引用了lombok的话,也可以使用lombok的注解@Slf4j 代替上面那句话来使用 SLF4J ,如下:
import lombok.extern.slf4j.Slf4j;@Slf4j
public class MyClass {
public static void main(String[] args) {
log.info( "This is an info message.");
}
}
但是,我们都知道SLF4J仅仅是个门面,换句话说,仅有接口而没有实现,如果此刻我们直接运行,打印日志是没有用处的

所以,我们如果要运行,我们必须要给 SLF4J 安排上实现,而目前最常用的就是 logback 和 log4j2 了,就让我们接着往下看
五、双雄之争
其实关于 Logback 和 Log4j 2,网络上有很多评测,就不需赘述了,主要是围绕性能方面的,从目前大家的反馈看,Log4j 2 晚出现好几年,还是有后发优势的,性能会比 Logback 好。当然, Logback 本身性能也很强,对于大多数场景,完全是够用的,而且配置比较直观,是spring-boot 默认使用的日志插件。

所以,选谁都可以,如果不想费神,可以直接使用spring-boot自带的Logback,如果对日志性能要求很高,使用log4j2更保险,我们接下来分别介绍两者。
1. Logback
1. 引用
由于 Logback 为 spring-boot 默认日志框架,所以无需再引用,但对于非spring - boot 项目,可以做如下引用
<dependency> <groupId>ch.qos.logback </groupId>
<artifactId>logback-classic </artifactId>
<version>1.2.12 </version>
</dependency>
Logback 的核心模块为 logback-classic,它提供了一个 SLF4J 的实现,兼容 Log4j API,可以无缝地替换 Log4j。它自身已经包含了 logback-core 模块,而 logback-core,顾名思义就是 logback 的核心功能,包括日志记录器、Appender、Layout 等。其他 logback 模块都依赖于该模块
2. 配置
logback 可以通过 XML 或者 Groovy 配置。下面以 XML 配置为例。logback 的 XML 配置文件名称通常为 logback.xml 或者 logback-spring.xml(在 Spring Boot 中),需要放置在 classpath 的根目录下,
<?xml version="1.0" encoding="UTF-8"?><configuration>
<!--定义日志文件的存储地址,使用Spring的属性文件配置方式-->
<springProperty scope="context" name="log.home" source="log.home" defaultValue="logs"/>
<!--定义日志文件的路径-->
<property name="LOG_PATH" value="${log.home}"/>
<!--定义控制台输出-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%-5relative [%thread] %-5level %logger{35} - %msg%n </pattern>
</encoder>
</appender>
<!--定义 INFO 及以上级别信息输出到控制台-->
<root level="INFO">
<appender-ref ref="console"/>
</root>
<!--定义所有组件的日志级别,如所有 DEBUG-->
<logger name="com.example" level="DEBUG"/>
<!-- date 格式定义 -->
<property name="LOG_DATEFORMAT" value="yyyy-MM-dd"/>
<!-- 定义日志归档文件名称格式,每天生成一个日志文件 -->
<property name="ARCHIVE_PATTERN" value="${LOG_PATH}/%d{${LOG_DATEFORMAT}}/app-%d{${LOG_DATEFORMAT}}-%i.log.gz"/>
<!--定义文件输出,会根据定义的阈值进行切割,支持自动归档压缩过期日志-->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/app.log </file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--定义日志文件切割的阈值,本例是 50MB-->
<maxFileSize>50MB </maxFileSize>
<!--定义日志文件保留时间,本例是每天生成一个日志文件-->
<fileNamePattern>${ARCHIVE_PATTERN} </fileNamePattern>
<maxHistory>30 </maxHistory>
<!-- zip 压缩生成的归档文件 -->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>50MB </maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 删除过期文件 -->
<cleanHistoryOnStart>true </cleanHistoryOnStart>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{35} - %msg%n </pattern>
</encoder>
</appender>
<!--定义 ERROR 级别以上信息输出到文件-->
<logger name="com.example.demo" level="ERROR" additivity="false">
<appender-ref ref="file"/>
</logger>
<!--异步输出日志信息-->
<appender name="asyncFile" class="ch.qos.logback.classic.AsyncAppender">
<discardingThreshold>0 </discardingThreshold>
<queueSize>256 </queueSize>
<appender-ref ref="file"/>
</appender>
<!--定义INFO及以上级别信息异步输出到文件-->
<logger name="com.example" level="INFO" additivity="false">
<appender-ref ref="asyncFile"/>
</logger>
</configuration>
其中,主要包括以下配置:
- springProperty 定义了 log 文件的存储路径,可以通过 Spring 的属性文件配置方式进行设置,如果没有配置则默认存储在 logs 目录下。
- appender 定义了日志输出的目标,这里包括了控制台输出和文件输出两种,具体可以根据需求进行配置。
- root 定义了默认的日志级别和输出目标,默认情况下,INFO 级别以上的日志信息会输出到控制台,可以根据实际需求进行修改。
- logger 定义了不同组件的日志级别和输出目标,例如,这里定义了 com.example 这个组件的日志级别为 DEBUG,而 com.example.demo 这个组件的日志级别为 ERROR,并将其输出到文件中。
- rollingPolicy 定义了日志文件的切割规则和归档策略,此处定义了日志文件每个 50MB 进行切割,每天生成一个日志文件,并且压缩和删除过期文件,最多保留 30 天的日志文件。
- encoder 定义了日志信息的输出格式,具体的格式可以自行定义。
- asyncAppender 定义了异步输出日志的方式,对于高并发时,可以使用异步输出来提高系统的性能。
- discardingThreshold 定义了异步输出队列的阈值,当队列中的数据量超过此值时,会丢弃最早放入的数据,此处设置为 0 表示队列不会丢弃任何数据。
- queueSize 定义了异步输出队列的大小,当队列满时,会等待队列中的数据被消费后再将数据放入队列中,此处设置为 256。
3. 演示
我们新建一个普通工程(非spring工程),引用Logback后,把上述配置文件复制进logback.xml,然后将工程结构设置成如下模式
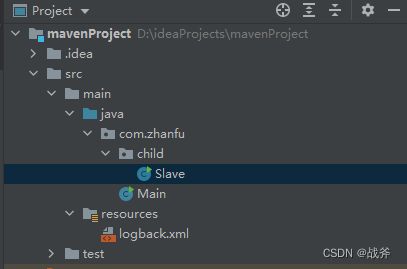
其中两个类的代码如下:
public class Main { private static final Logger log = LoggerFactory.getLogger(Main .class);
public static void main(String[] args) {
log.trace( "This is a Main trace message.");
log.debug( "This is a Main debug message.");
log.info( "This is a Main info message.");
log.warn( "This is a Main warn message.");
log.error( "This is a Main error message.");
Slave.main(args);
}
}
public class Slave {
private static final Logger log = LoggerFactory.getLogger(Slave .class);
public static void main(String[] args) {
log.trace( "This is a Slave trace message.");
log.debug( "This is a Slave debug message.");
log.info( "This is a Slave info message.");
log.warn( "This is a Slave warn message.");
log.error( "This is a Slave error message.");
}
}
我们想实现这样的效果,首先日志要同时 输出到控制台 及 日志文件,且不同层级的代码,输出的日志层级也不同。那么我们可以对上述的xml做出一些调整:
因为是非Spring项目,所以 springProperty 这样的标签就不要用了,我们直接写死一个日志文件地址即可。
<!--定义日志文件的路径--><property name="LOG_PATH" value="D://logs/log"/>
去掉原有的那些root、logger标签,我们自己新建两个logger,用于两个不同的层级。我们想里层输出 debug 级别,外层输出info 级别,我们可以这么设置。并且同时输出到控制台及日志文件
<logger name="com.zhanfu" level="INFO"> <appender-ref ref="file" />
<appender-ref ref="console"/>
</logger>
<logger name="com.zhanfu.child" level="DEBUG" additivity="false">
<appender-ref ref="file" />
<appender-ref ref="console"/>
</logger>
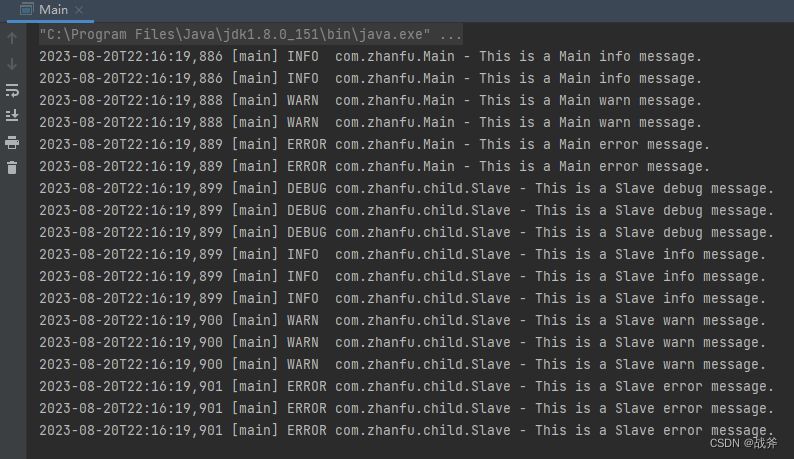
当我们运行Main.main的时候,就可以得到以下日志,slave 能输出debug级别,Main 只能输出 info及以上级别

4. 细节点
其实我们上面的演示,有两个细节点,需要注意一下。一个就是我们的
<logger name="com.zhanfu.child" level="DEBUG" additivity="false">使用了一个 additivity="false" 的属性,这其实是因为 logger 这个标签在锁定某个目录时,可能会发生层级关系。比如我们的两个 logger, 一个针对的目录是 com.zhanfu 另一个是 com.zhanfu.child ,后者就会被前者包含。
当我们的 com.zhanfu.child.Slave 打印日志时,当然会使用后者(更精确)的设置,但前者的设置还使用吗?就依赖于 additivity=“false”,此处如果我们把 additivity="false" (该属性默认值为true)去掉,再来打印日志

就会发现,Slave 的日志打了两遍,而且连 debug 级别的都打了两遍,我们可以把这种逻辑理解为继承,子类执行一遍,父类还能在执行一遍,但 leve 属性还是会采用子类而非父类的。
另一点就是我们把 root 标签删除了,root 其实是一个顶级的 logger , 其他的logger都可以视为它的子类,如果那些logger存在没涵盖的地方,或其没有指定 additivity="false" ,那最后root的设置就会被使用。比如我们将设置改为如下:
<logger name="com.zhanfu" level="INFO"> <appender-ref ref="file" />
<appender-ref ref="console"/>
</logger>
<logger name="com.zhanfu.child" level="DEBUG">
<appender-ref ref="file" />
<appender-ref ref="console"/>
</logger>
<root level="WARN">
<appender-ref ref="console"/>
</root>
结果控制台的输出日志,Main会重复两次,Slave 会重复三次,如下
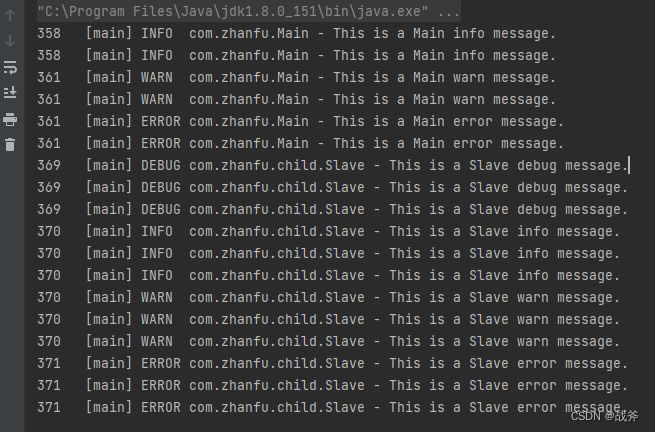
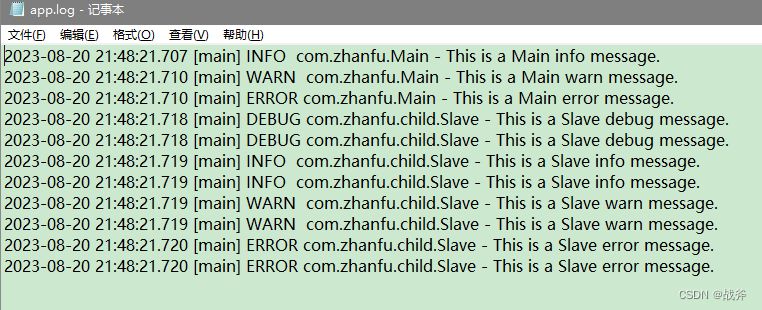
但是因为我们的 root 只配置了控制台输出,所以日志文件里还是不会变的
2. Log4j 2
1. 引用
对于spring-boot项目,除了引用 Log4j 2 我们还需要先剔除 Logback 的引用,对于普通项目,我们只需直接引用即可。但注意我们的原则,通过 SLF4J 来使用 Log4j2,所以引用下面这个包
<dependency> <groupId>org.apache.logging.log4j </groupId>
<artifactId>log4j-slf4j-impl </artifactId>
<version>2.13.3 </version>
</dependency>
其内包含 Log4j2 的实现,和 SLF4J 的 API,如下:
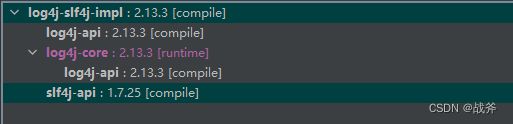
2. 配置
Log4j2 的配置逻辑和 logback 是类似的,只有些细节不同,比如Logger 的首字母大写等等,最后我们写下这样一个 log4j2.xml
<?xml version="1.0" encoding="UTF-8"?><Configuration status="INFO" monitorInterval="30">
<Properties>
<Property name="logPath">logs </Property>
</Properties>
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{ISO8601} [%t] %-5level %logger{36} - %msg%n" />
</Console>
<RollingFile name="File" fileName="${logPath}/example.log"
filePattern="${logPath}/example-%d{yyyy-MM-dd}-%i.log">
<PatternLayout pattern="%d{ISO8601} [%t] %-5level %logger{36} - %msg%n"/>
<Policies>
<SizeBasedTriggeringPolicy size="10 MB"/>
</Policies>
<DefaultRolloverStrategy max="4"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="com.zhanfu.child" level="DEBUG">
<AppenderRef ref="File"/>
<AppenderRef ref="Console"/>
</Logger>
<Logger name="com.zhanfu" level="INFO">
<AppenderRef ref="File"/>
<AppenderRef ref="Console"/>
</Logger>
<Root level="WARN">
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>
- Properties
部分定义了一个 logPath 属性,方便在其他地方引用。
- Appenders
定义了两个 Appender:Console 和 RollingFile,分别将日志输出到控制台和文件中。RollingFile 使用了 RollingFileAppender,并设置了日志滚动策略和默认的备份文件数量。
- Loggers
定义了三个 Logger:com.zhanfu.child 的日志级别为 DEBUG,com.zhanfu 的日志级别为INFO,Root Logger 的日志级别为 WARN。并指定了两个 Appender:Console 和 File。
3. 演示
由于我们的配置逻辑没变,所以日志的结果还是一样的:

3. 对比
Log4j2和Logback都是Java应用程序中最流行的日志框架之一。它们均具备高度的可配置性和使用灵活性,并提供了一系列有用的功能,例如异步日志记录和日志过滤等。下面从配置遍历性、功能性、性能等方面进行比较和总结。
配置遍历性
Logback的配置文件格式相对简单,易于阅读和修改。它支持符号来引用变量、属性和环境变量等。此外,它还支持条件日志记录(根据日志级别、日志记录器名称或时间等),以及滚动文件的大小或日期等。
Log4j2的配置文件格式较复杂,但它在配置文件中提供了大量的选项来控制日志记录。它支持在配置文件中直接声明上下文参数、过滤器、输出器和Appender等,这使得它的配置更加灵活。此外,Log4j2还支持异步日志记录、日志事件序列化和性能优化等。
总体来说,两者都很好地支持了配置遍历性,但Log4j2提供了更多的选项和更高的灵活性。
功能性
Logback提供了一系列基本的日志记录功能,例如异步Appender、滚动文件和GZIP压缩等。它还支持与SLF4J一起使用,可以很容易地与其他日志框架集成。
Log4j2提供了更多的高级功能,例如异步日志记录、性能优化和日志事件序列化等。它还支持Lambda表达式,可以使日志记录器更加简洁和易读。此外,Log4j2还支持Flume和Kafka等大数据处理框架,可以方便地将日志记录发送到这些框架中。
总体来说,Log4j2提供了更多的高级功能,并且可以更好地与大数据处理框架集成。
性能
Logback的性能很好,可以处理高吞吐量的日志记录。它采用了异步记录器,利用了多线程来提高性能。
Log4j2在性能方面更加强大。它使用了异步记录器和多线程,还引入了RingBuffer数据结构和Disruptor库来加速日志事件的传递和处理。这使得它比Logback具有更高的吞吐量和更低的延迟。
综上所述,Log4j2在配置灵活性、功能性和性能方面都比Logback更为强大。但如果需要轻量级的日志框架或者只需要基本的日志记录功能,Logback也是一个不错的选择
但如果我们同时引用了这两者,会报错吗?还是会使用其中的某一个?
<dependency> <groupId>ch.qos.logback </groupId>
<artifactId>logback-classic </artifactId>
<version>1.2.12 </version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j </groupId>
<artifactId>log4j-slf4j-impl </artifactId>
<version>2.13.3 </version>
</dependency>
可以看到,SLF4J 发现了系统中同时存在两个插件框架,并最终选择了使用 Logback

总结
学习完本文,你应当对现在这几个常用框架的有所了解,并能基础应用了。此次我们没有讲源码,也没有深入的讲其配置及进阶使用,这些我们会在后面慢慢学习。但现在我希望你能知道的是。一定要写好日志,一定要写好日志,一定要写好日志。重要的事情说三遍!这是区别新人和老鸟的一个重要依据,也是让自己排查问题更轻松的不二法门!
另外,现在很多中间件都自己引用了日志插件,我们作为一个整体工程在使用中间件时,要及时发现并解决插件冲突,避免我们自己的日志配置失效,这也是一个程序员该注意的点。







![[Linux]多线程编程](https://img-blog.csdnimg.cn/img_convert/3d8d7520bba2e3eefa24b899b9807bfc.png)