文章目录,源码见文末下载
- 背景介绍
- 准备工作:处理数据
- 第一题:血肿扩张风险相关因素探索建模
- a)问题
- b)问题
- 第二题: 血肿周围水肿的发生及进展建模,并探索治疗干预和水肿进展的关联关系
- a)问题
- b)问题
- c)问题
- d)问题
- 第三题:出血性脑卒中患者预后预测及关键因素探索。
- a)问题
- b)问题
- c)问题
- 完整源码+数据下载
背景介绍
出血性脑卒中指非外伤性脑实质内血管破裂引起的脑出血,占全部脑卒中发病率的10-15%。其病因复杂,通常因脑动脉瘤破裂、脑动脉异常等因素,导致血液从破裂的血管涌入脑组织,从而造成脑部机械性损伤,并引发一系列复杂的生理病理反应。出血性脑卒中起病急、进展快,预后较差,急性期内病死率高达45-50%,约80%的患者会遗留较严重的神经功能障碍,为社会及患者家庭带来沉重的健康和经济负担。因此,发掘出血性脑卒中的发病风险,整合影像学特征、患者临床信息及临床诊疗方案,精准预测患者预后,并据此优化临床决策具有重要的临床意义。
出血性脑卒中后,血肿范围扩大是预后不良的重要危险因素之一。在出血发生后的短时间内,血肿范围可能因脑组织受损、炎症反应等因素逐渐扩大,导致颅内压迅速增加,从而引发神经功能进一步恶化,甚至危及患者生命。因此,监测和控制血肿的扩张是临床关注的重点之一。此外,血肿周围的水肿作为脑出血后继发性损伤的标志,在近年来引起了临床广泛关注。血肿周围的水肿可能导致脑组织受压,进而影响神经元功能,使脑组织进一步受损,进而加重患者神经功能损伤。综上所述,针对出血性脑卒中后的两个重要关键事件,即血肿扩张和血肿周围水肿的发生及发展,进行早期识别和预测对于改善患者预后、提升其生活质量具有重要意义。
医学影像技术的飞速进步,为无创动态监测出血性脑卒中后脑组织损伤和演变提供了有力手段。近年来,迅速发展并广泛应用于医学领域的人工智能技术,为海量影像数据的深度挖掘和智能分析带来了全新机遇。期望能够基于本赛题提供的影像信息,联合患者个人信息、治疗方案和预后等数据,构建智能诊疗模型,明确导致出血性脑卒中预后不良的危险因素,实现精准个性化的疗效评估和预后预测。相信在不久的将来,相关研究成果及科学依据将能够进一步应用于临床实践,为改善出血性脑卒中患者预后作出贡南献。
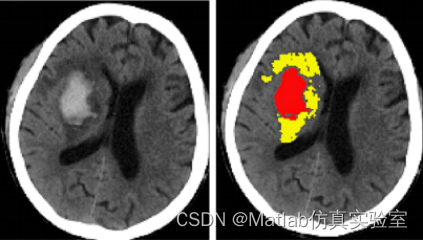
图1.左图脑出血患者CT平扫,右图红色为血肿,黄色为血肿周围水肿:
准备工作:处理数据
读取、整理和保存数据。通过对数据的处理和整合,建立一个名为Table的矩阵,用于后续的建模分析:
-
读取数据表格文件,并将数据存储在相应的变量中。对数据进行预处理,将缺失值替换为空字符串,并对性别进行编码(男为1,女为2)。
-
整理数据,将表格数据按照预定的格式整理为一个名为
Table的矩阵。Table的第一行是表头,包括患者、流水号、时间和各个指标的名称。 -
循环遍历数据表中的每一行(除去表头),对于每一行数据,获取从发病到第一次诊断的时间长度
delta_t0和第一次诊断的日期t1。 -
根据流水号在附表1中找到对应的行列索引,获取后续诊断日期
t2。 -
计算时间轴上每次随诊距离发病的时间长度
time。 -
统计每次检查的数据,如果有缺失则不记录。根据附表1中的日期和表格2中的数据,将患者编号、诊断日期、时间长度、表格1中的数据、表格2中的数据和表格3中的数据整合为一行,添加到
Table中。 -
对于缺失数据,根据样本间的差异,取附件3个数据集中的附件3指标的平均值补充。
-
将整理好的
Table保存在名为data的文件中。
第一题:血肿扩张风险相关因素探索建模
a)问题
- 请根据“表1”(字段:入院首次影像检查流水号,发病到首次影像检查时间间隔),“表2”(字段:各时间点流水号及对应的HM_volume),判断患者sub001至sub100发病后48小时内是否发生血肿扩张事件。
- 结果填写规范:1是0否,填写位置:“表4”C字段(是否发生血肿扩张)。
- 如发生血肿扩张事件,请同时记录血肿扩张发生时间。
- 结果填写规范:如10.33小时,填写位置:“表4”D字段(血肿扩张时间)。
- 是否发生血肿扩张可根据血肿体积前后变化,具体定义为:后续检查比首次检查绝对体积增加≥6 mL或相对体积增加≥33%。
- 注:可通过流水号至“附表1-检索表格-流水号vs时间”中查询相应影像检查时间点,结合发病到首次影像时间间隔和后续影像检查时间间隔,判断当前影像检查是否在发病48小时内。
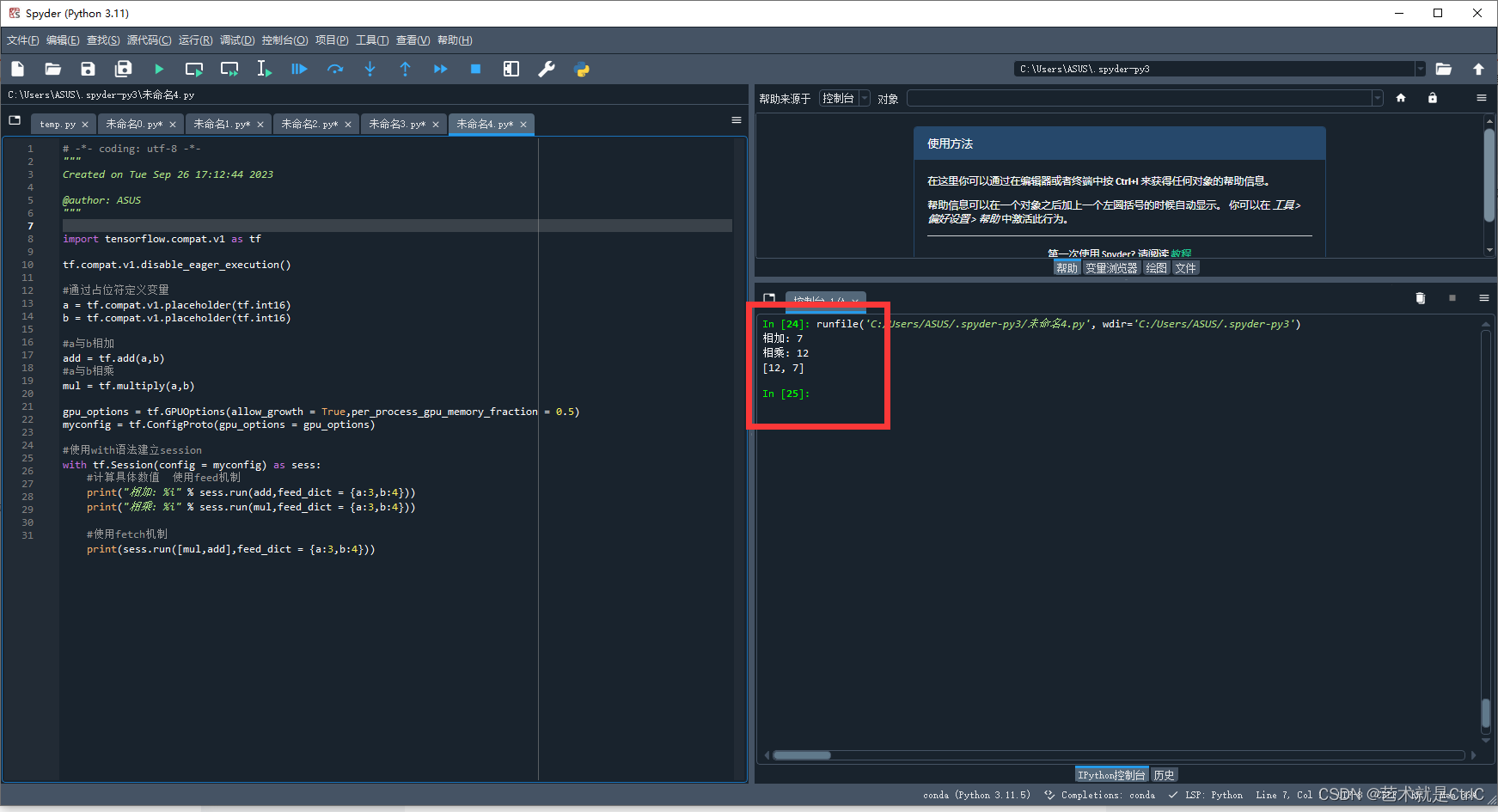
具体代码实现思路步骤:
-
首先,通过unique函数从表格"Table"的第一列中提取唯一值,并将结果保存在变量"Num"中。
-
接下来,定义了四个空变量:A、B、Y和T。这些变量将用于保存患者的指标、拟合参数、是否发病的标签以及静脉扩张时间。
-
使用一个循环,遍历"Num"中的每个唯一值。
-
在每次循环中,首先找到表格"Table"中与当前唯一值匹配的行的索引,并将这些行的第4列及其之后的数据保存在变量"A"中。
-
然后,将这些行的第3列数据保存在变量"t"中,将第23列数据保存在变量"HM_volume"中。
-
判断"HM_volume"的长度是否大于0,如果大于0,说明有多个数据可以用于线性回归。则使用regress函数进行线性回归,将回归系数保存在变量"b"中。
-
如果"HM_volume"的长度等于0,说明只有一个数据,那么就需要使用样本数据中最接近的其他样本对应的参数进行匹配。首先将A进行归一化处理,然后计算最后一个样本与其他样本的距离,找到距离最近的样本,将其对应的参数保存在变量"B"中。
-
继续循环,将变量"b"保存在变量"B"中。
-
然后,将时间网格化,精度为0.1,从第一次诊断到发病的第48小时内,生成一个时间序列"t1"。
-
使用回归参数"b"计算"t1"对应的HM_volume值,保存在变量"HM_volume_48"中。
-
找到HM_volume_48与HM_volume(1)的比值大于1.33的索引,并保存在变量"a1"中。
-
找到HM_volume_48与HM_volume(1)的差值大于6000的索引,并保存在变量"a2"中。
-
将"a1"和"a2"的索引合并,保存在变量"aa"中。
-
判断"aa"的长度是否大于0,如果大于0,说明发生了发病,将变量"Y"中对应位置的值设为1,并将变量"t1"中第一个满足条件的时间保存在变量"T"中。
-
如果"aa"的长度等于0,说明没有发病,将变量"Y"中对应位置的值设为0。
-
循环结束后,将"Num"、“Y"和"T"合并为一个结果矩阵"result1”,其中保存了每个患者的唯一值、是否发病的标签和静脉扩张时间。
b)问题
- 请以是否发生血肿扩张事件为目标变量,基于“表1” 前100例患者(sub001至sub100)的个人史,疾病史,发病相关(字段E至W)、“表2”中其影像检查结果(字段C至X)及“表3”其影像检查结果(字段C至AG,注:只可包含对应患者首次影像检查记录)等变量,构建模型预测所有患者(sub001至sub160)发生血肿扩张的概率。
- 注:该问只可纳入患者首次影像检查信息。
- 结果填写规范:记录预测事件发生概率(取值范围0-1,小数点后保留4位数);填写位置:“表4”E字段(血肿扩张预测概率)。
具体代码实现思路步骤:
-
首先,使用mapminmax函数将变量"A"进行归一化处理,结果保存在变量"In"中。同时,将标签变量"Y"转置后保存在变量"Out"中。
-
将数据集划分为训练集和测试集,其中前100个样本用于训练,101到130个样本用于测试集1,131到160个样本用于测试集2。
-
创建一个bp神经网络,网络的输入层节点数为输入数据的一半,隐藏层节点数为输入数据的四分之一,激活函数使用tansig。
-
设置神经网络的训练参数,包括最大迭代次数、目标误差、最小梯度、学习速率和最大确认失败次数等。
-
使用训练数据对神经网络进行训练。
-
对训练集、测试集1和测试集2进行仿真测试,使用训练好的神经网络对输入数据进行预测,并将预测结果保存在变量"t_sim"、"t_sim1"和"t_sim2"中。
-
对预测结果进行四舍五入处理,得到最终的预测结果,保存在变量"T_sim"、"T_sim1"和"T_sim2"中。
-
绘制混淆矩阵,分别对训练集、测试集1和测试集2的真实标签和预测结果进行可视化。
-
最后,将预测结果"t_sim"、"t_sim1"和"t_sim2"添加到之前的结果矩阵"result1"中,并将结果矩阵保存在变量"result1"中。结果矩阵包括患者编号、是否发生血肿扩张、血肿扩张时间和血肿扩张的预测概率。
第二题: 血肿周围水肿的发生及进展建模,并探索治疗干预和水肿进展的关联关系
a)问题
- 请根据“表2”前100个患者(sub001至sub100)的水肿体积(ED_volume)和重复检查时间点,构建一条全体患者水肿体积随时间进展曲线(x轴:发病至影像检查时间,y轴:水肿体积,y=f(x)),计算前100个患者(sub001至sub100)真实值和所拟合曲线之间存在的残差。
- 结果填写规范:记录残差,填写位置“表4”F字段(残差(全体))。
具体代码实现思路步骤:
-
首先通过
unique函数找出数据表第二行及以后的第一列中的唯一值,保存在变量Num中。 -
创建空矩阵
T、ED和A,用于分别记录复查时间、水肿数据和除此诊断信息。 -
循环遍历
Num中的每个值,对于每个值,找出数据表中第一列等于该值的行的索引,保存在变量a中。 -
将对应行的第4列及之后的数据转换为
double类型,并添加到矩阵A中。 -
将对应行的第3列数据转换为
double类型,并添加到矩阵T中。 -
将对应行的第34列数据转换为
double类型,并添加到矩阵ED中。 -
绘制图形,横坐标为
T,纵坐标为ED,点的形状为星号。 -
设置横坐标范围为1到2000。
-
使用高斯模型拟合数据,拟合结果保存在变量
gaussModel中。 -
绘制高斯模型曲线。
-
设置横轴标题为"时间",纵轴标题为"水肿/10^-3ml"。
-
计算拟合值
ED_fit。 -
创建空矩阵
Error,用于保存残差。 -
循环遍历
Num中的每个值,对于每个值,找出数据表中第一列等于该值的行的索引,并将索引减去1,保存在变量a中。 -
计算拟合值与原始数据的绝对差的平均值,并保存在矩阵
Error中的对应位置。
b)问题
- 请探索患者水肿体积随时间进展模式的个体差异,构建不同人群(分亚组:3-5个)的水肿体积随时间进展曲线,并计算前100个患者(sub001至sub100)真实值和曲线间的残差。
- 结果填写规范:记录残差,填写位置“表4”G字段(残差(亚组)),同时将所属亚组填写在H段(所属亚组)。
具体代码实现思路步骤:
-
设置聚类的中心数量为5,保存在变量
cluster_n中。 -
使用模糊C均值聚类(FCM)算法对数据表的第4-15列指标进行聚类,聚类结果保存在变量
center、U和obj_fcn中。其中,center为聚类中心,U为隶属度矩阵,obj_fcn为目标函数值的变化。 -
绘制目标函数值的变化图,横轴为迭代次数,纵轴为目标函数值。
-
根据隶属度矩阵
U中每个样本的最大隶属度确定所属的聚类中心,保存在变量u中。 -
创建空矩阵
ED_fit2,用于保存聚类后的拟合值。 -
循环遍历聚类中心的数量,对于每个聚类中心,找出属于该聚类的样本的索引,保存在变量
a中。 -
找出属于该聚类的样本在原始数据表中的索引,并保存在变量
b中。 -
绘制图形,横坐标为
T(b),纵坐标为ED(b),点的形状为星号。 -
设置横坐标范围为1到2000。
-
使用高斯模型拟合属于该聚类的样本,拟合结果保存在变量
gaussModel中。 -
绘制高斯模型曲线。
-
设置横轴标题为"时间",纵轴标题为"水肿/10^-3ml"。
-
设置图标题为"亚类i",其中i为聚类中心的编号。
-
计算拟合值
ED_fit2。 -
创建空矩阵
Error2,用于保存聚类后的残差。 -
循环遍历
Num中的每个值,对于每个值,找出数据表中第一列等于该值的行的索引,并将索引减去1,保存在变量a中。 -
计算聚类后的拟合值与原始数据的绝对差的平均值,并保存在矩阵
Error2中的对应位置。 -
将患者编号、全体残差、聚类后的残差和聚类结果合并成矩阵
result2。
c)问题
- 请分析不同治疗方法(“表1”字段Q至W)对水肿体积进展模式的影响。
具体代码实现思路步骤:
-
创建空矩阵
K,用于保存水肿指标的变化率。 -
循环遍历
Num中的每个值,对于每个值,找出数据表中第一列等于该值的行的索引,保存在变量a中。 -
判断该患者的数据是否满足至少五次检查的要求,如果满足,则计算水肿指标的变化率。
-
将水肿指标变化率小于0的数据的索引保存在变量
kk中。 -
如果
kk的长度为0,说明水肿指标没有减少的情况,将K(i,1)设为0。 -
否则,计算水肿指标减少的平均值,并将结果保存在
K(i,1)中。 -
如果数据不满足至少五次检查的要求,将
K(i,1)设为NaN。 -
找出
K中不为NaN的数据的索引,保存在变量c中。 -
将数据表中第16-22列的数据转换为
double类型,保存在变量G中。 -
将数据表第一行的第16-22列的数据保存在变量
Z中。 -
循环遍历
Z中的每个值,对于每个值,进行单因素方差分析。 -
计算方差分析的临界值
fa。 -
获取方差分析结果中的F值。
-
根据p值和F值的大小判断不同治疗方法对水肿进展模式的影响。
-
打印出影响显著的治疗方法的相关信息。
-
打印出不同治疗方法对水肿进展模式的影响大小的排序结果。
d)问题
- 请分析血肿体积、水肿体积及治疗方法(“表1”字段Q至W)三者之间的关系。
具体代码实现思路步骤:
-
创建空矩阵
K2,用于保存血肿指标的变化率。 -
循环遍历
Num中的每个值,对于每个值,找出数据表中第一列等于该值的行的索引,保存在变量a中。 -
判断该患者的数据是否满足至少五次检查的要求,如果满足,则计算血肿指标的变化率。
-
将血肿指标变化率小于0的数据的索引保存在变量
kk中。 -
如果
kk的长度为0,说明血肿指标没有减少的情况,将K2(i,1)设为0。 -
否则,计算血肿指标减少的平均值,并将结果保存在
K2(i,1)中。 -
如果数据不满足至少五次检查的要求,将
K2(i,1)设为NaN。 -
找出
K2中不为NaN的数据的索引,保存在变量c中。 -
循环遍历
Z中的每个值,对于每个值,进行单因素方差分析。 -
计算方差分析的临界值
fa。 -
获取方差分析结果中的F值。
-
根据p值和F值的大小判断不同治疗方法对血肿进展模式的影响。
-
打印出影响显著的治疗方法的相关信息。
-
打印出不同治疗方法对血肿进展模式的影响大小的排序结果。
-
将血肿指标和水肿指标转换为
double类型,保存在变量x0和y0中。 -
计算血肿指标和水肿指标的余弦相似度,保存在变量
theta中。 -
打印出血肿指标和水肿指标的相关度。
第三题:出血性脑卒中患者预后预测及关键因素探索。
a)问题
- 请根据前100个患者(sub001至sub100)个人史、疾病史、发病相关(“表1”字段E至W)及首次影像结果(表2,表3中相关字段)构建预测模型,预测患者(sub001至sub160)90天mRS评分。
- 注:该问只可纳入患者首次影像检查信息。
- 结果填写规范:记录预测mRS结果,0-6,有序等级变量。填写位置“表4”I字段(预测mRS(基于首次影像))。
具体代码实现思路步骤:
-
使用
mapminmax函数对输入数据A进行归一化处理,将归一化后的结果保存在变量In中,并保存归一化的参数在ps_in中。 -
将输出数据
Y转置为Out。 -
将数据分为训练集和测试集。将
In的前100列作为训练集的输入,将Out的前100列作为训练集的输出。将In的101-130列作为测试集1的输入,将Out的101-130列作为测试集1的输出。将In的131-160列作为测试集2的输入,将Out的131-160列作为测试集2的输出。 -
创建一个BP神经网络。设置网络的结构为两个隐藏层,第一个隐藏层的神经元数量为输入数据的一半,第二个隐藏层的神经元数量为输入数据的四分之一。激活函数使用双曲正切函数。
-
设置训练参数,包括最大迭代次数、目标误差、最小梯度、学习速率和最大确认失败次数。
-
使用训练集数据训练网络。
-
对训练集、测试集1和测试集2进行仿真测试,得到预测结果。将预测结果取整,保存在变量
t_sim、t_sim1和t_sim2中。 -
使用
plotconfusion函数绘制混淆矩阵。分别绘制训练集、测试集1和测试集2的混淆矩阵图。混淆矩阵用于评估模型的分类性能。
b)问题
- 根据前100个患者(sub001至sub100)所有已知临床、治疗(表1字段E到W)、表2及表3的影像(首次+随访)结果,预测所有含随访影像检查的患者(sub001至sub100,sub131至sub160)90天mRS评分。
- 结果填写规范:记录预测mRS结果,0-6,有序等级变量。填写位置“表4”J字段(预测mRS)。
具体代码实现思路步骤:
-
使用
mapminmax函数将输入数据B进行归一化处理,使用之前训练网络时得到的归一化参数ps_in,将归一化后的结果保存在变量Xyuce中。 -
对归一化后的数据
Xyuce进行仿真测试,得到预测结果,保存在变量t_sim3中。 -
将预测结果取整,保存在变量
T_sim3中。 -
创建空字符串矩阵
result3,用于保存最终的预测结果。 -
循环遍历
Num中的每个值,对于每个值,找出与Num中的值相等的索引,保存在变量a中。 -
循环遍历索引
a,对于每个索引,将对应的预测结果保存在result3中的对应位置。 -
将
result3转换为字符串类型。 -
将缺失值的元素替换为空字符串。
-
创建空矩阵
z,用于保存随访次数的字符串。 -
循环遍历
result3的列数,对于每一列,将对应的字符串保存在z中。 -
将患者编号、首次检测结果和随访次数的字符串合并成矩阵
result3。
c)问题
- 请分析出血性脑卒中患者的预后(90天mRS)和个人史、疾病史、治疗方法及影像特征(包括血肿/水肿体积、血肿/水肿位置、信号强度特征、形状特征)等关联关系,为临床相关决策提出建议。
具体代码实现思路步骤:
-
将数据表中第2行到最后一行、第4列到最后一列的数据转换为
double类型,并保存在变量X中。 -
创建空矩阵
P,用于保存相关性矩阵。 -
使用嵌套循环遍历
X的每一列和每一列,计算对应列的向量之间的余弦相似度,并将结果保存在相关性矩阵P的对应位置。 -
绘制热图,将相关性矩阵
P作为数据输入,设置颜色条可见,调整图的位置、字体大小和单元格标签格式。 -
将变量
Z与相关性矩阵P合并成矩阵resultp,用于自行分析相关性结果。 -
打印出预测结果和相关性结果的提示信息。
完整源码+数据下载
基于Matlab求解2023年华为杯E题完整代码文件(源码+数据).rar:https://download.csdn.net/download/m0_62143653/88376174