在本指南中,我们将逐步演示如何在 Ubuntu 22.04 上安装 Apache Kafka。
在大数据中,数以百万计的数据源生成了大量的数据记录流,这些数据源包括社交媒体平台、企业系统、移动应用程序和物联网设备等。如此庞大的数据带来的主要挑战有两个方面:高效的数据收集和分析。为了克服这些挑战,您需要一个可靠且健壮的消息传递系统。
Apache Kafka 由 Apache Foundation 开发,用 Java 和 Scala 编写是开源分布式 pub/sub(发布订阅)事件处理大量数据流平台。它也允许您将消息从一个点传输到另一点。它与 Zookeeper 同步服务一起工作,并与 Apache Spark 无缝集成,用于分析和处理大规模数据。
与其他消息传递系统相比,Apache Kafka 提供了更好的吞吐量、固有的容错能力和复制能力,这使其成为企业消息处理应用程序的绝佳选择。 包括 Netflix、微软和 AirBnB 等顶级公司都有使用 Apache Kafka 服务。
必备条件
- Pre Installed Ubuntu 22.04
- Sudo User with Admin Rights
- Internet Connectivity
(1) 安装 OpenJDK
由于 Apache Kafka 是用 Java 编写的,所以安装 Java 是一个先决条件,先更新包索引。
$ sudo apt update接下来,安装 OpenJDK 11,它是 Java 标准版平台的免费开源实现。
$ sudo apt install openjdk-11-jdk -y
Install-Openjdk11-for-kafka-Ubuntu
接下来,查看 java 版本。
$ java -version
Check-Java-Version-Kafka-Ubuntu
(2) 安装 Apache Kafka
使用如下命令下载 Apache Kafka
$ wget https://archive.apache.org/dist/kafka/3.2.3/kafka_2.13-3.2.3.tgz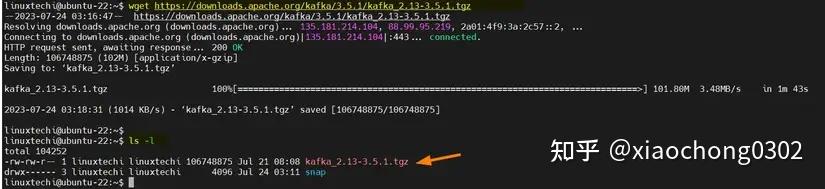
Download-Apache-Kafka-Wget-Command-Ubuntu
解压下载的文件
$ tar xvf kafka_2.13-3.2.3.tgz解压后,创建了一个 KAFKA_2.12-3.5.0 的目录。将此目录移至 /usr/local 目录,并将其重命名为 kafka。
$ sudo mv kafka_2.13-3.2.3 /usr/local/kafka
Move-Kafka-Binary-user-local-ubuntu
(3) 创建 Kafka 和 ZooKeeper Systemd 单元文件
在这一步中,我们将为 Kafka 和 ZooKeeper 服务创建 systemd 单元文件。这将允许您使用 systemctl 命令轻松地管理服务。
使用 nano 编辑器创建 Zookeeper systemd 文件
$ sudo nano /etc/systemd/system/zookeeper.service粘贴以下代码行,定义 Zookeeper 的 systemd 服务。
[Unit]
Description=Apache Zookeeper server
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target[Service]
Type=simple
Environment="JAVA_HOME=/usr/local/programs/jdk-8u333-linux-x64/jdk1.8.0_333"
ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties
ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal[Install]
WantedBy=multi-user.target保存并退出
使用 nano 编辑器创建 Zookeeper systemd 文件
$ sudo nano /etc/systemd/system/kafka.service粘贴以下代码行,定义 kafka 的 systemd 服务。
[Unit]
Description=Apache Kafka Server
Documentation=http://kafka.apache.org/documentation.html
Requires=zookeeper.service[Service]
Type=simple
Environment="JAVA_HOME=/usr/local/programs/jdk-8u333-linux-x64/jdk1.8.0_333"
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh[Install]
WantedBy=multi-user.target保存并退出
(4) 开启 Kafka 和 ZooKeeper Systemd 服务
所有 systemd 文件就位后,将所做的更改通知 systemd。
$ sudo systemctl daemon-reload接下来,开启 Kafka 和 Zookeeper 服务
$ sudo systemctl start zookeeper
$ sudo systemctl start kafka查看 Zookeeper 服务状态
$ sudo systemctl status zookeeper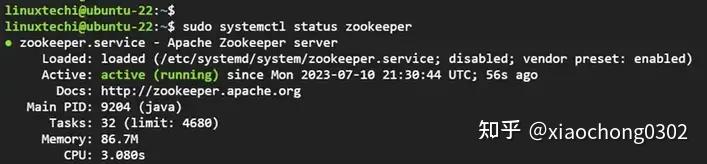
Zookeeper-Service-Status-Ubuntu,查看 Apache Kafka 服务状态
$ sudo systemctl status kafka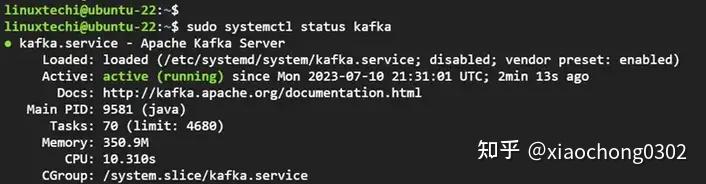
Kafka-Service-Status-Ubuntu
(5) 创建 Kafka Topic
安装了 Kafka 和所有组件后,我们将创建一个 Topic 并尝试发送消息。在 Kafka 中,Topic 是用于组织消息的基本单元。每个 Topic 在集群中应该有一个唯一的名称。主题允许用户在 Kafka 服务器之间发送和读取数据。
你可以在 Kafka 中创建任意数量的集群。也就是说,现在让我们在本地主机端口 9092 上创建一个名为 sampleTopic 的Topic,该 Topic 具有单个复制因子。
$ cd /usr/local/kafka
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic sampleTopic在运行该命令后,您将得到一个确认,表明主题已成功创建。
Created topic sampleTopic
Creating-Topic-Kafka-Server-Ubuntu
As mentioned earlier, you can create as many topics as you can using the same syntax. To check or list the topics created, run the command:
您可以使用相同的语法创建尽可能多的主题。需要查看或列出已创建的主题,使用如下命令
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
List-Kafka-Topic-Ubuntu
(6) 发送和接收消息
在 Kafka 中,生产者是一个跨不同分区将数据写入主题的应用程序。应用程序集成 Kafka 客户端库,向 Apache Kafka 写入消息。Kafka 客户端库是多种多样的,适用于各种编程语言,包括 Java、Python 等。
现在让我们运行生成器并在控制台上生成一条消息。
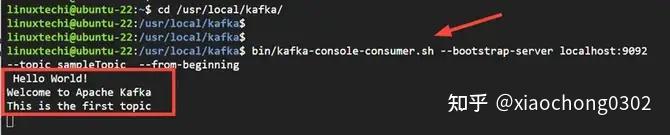
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sampleTopic系统将提示您输入一些消息。在本例中,我们输入了几行代码。
> Hello World!
> Welcome to Apache Kafka
> This is the` first topic
``完成后,可以退出或保持终端运行。要使用这些消息,请打开一个新终端并运行以下命令
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sampleTopic --from-beginning您输入的消息将显示在终端上,如下所示。