1、启动zookeeper集群
/home/cluster/zookeeper.sh start
/home/cluster/zookeeper.sh stop
2、启动hadoop和yarn集群
/home/cluster/hadoop-3.3.6/sbin/start-dfs.sh
/home/cluster/hadoop-3.3.6/sbin/start-yarn.sh
/home/cluster/hadoop-3.3.6/sbin/stop-dfs.sh
/home/cluster/hadoop-3.3.6/sbin/stop-yarn.sh
3、启动spark集群
/home/cluster/spark-3.4.1-bin-hadoop3/sbin/start-all.sh
/home/cluster/spark-3.4.1-bin-hadoop3/sbin/stop-all.sh
创建目录
hdfs dfs -mkdir -p /tmp/spark-events
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/:$LD_LIBRARY_PATH
[root@node88 bin]# /home/cluster/spark-3.4.1-bin-hadoop3/bin/spark-submit --class com.example.cloud.KafkaSparkHoodie --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --executor-cores 1 /home/cluster/KafkaSparkHoodie.jar
23/09/27 11:37:43 INFO SparkContext: Running Spark version 3.3.3
23/09/27 11:37:44 INFO ResourceUtils: ==============================================================
23/09/27 11:37:44 INFO ResourceUtils: No custom resources configured for spark.driver.
23/09/27 11:37:44 INFO ResourceUtils: ==============================================================
23/09/27 11:37:44 INFO SparkContext: Submitted application: com.example.cloud.KafkaSparkHoodie
23/09/27 11:37:44 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 512, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
23/09/27 11:37:44 INFO ResourceProfile: Limiting resource is cpus at 1 tasks per executor
23/09/27 11:37:44 INFO ResourceProfileManager: Added ResourceProfile id: 0
23/09/27 11:37:44 INFO SecurityManager: Changing view acls to: root
23/09/27 11:37:44 INFO SecurityManager: Changing modify acls to: root
23/09/27 11:37:44 INFO SecurityManager: Changing view acls groups to:
23/09/27 11:37:44 INFO SecurityManager: Changing modify acls groups to:
23/09/27 11:37:44 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
23/09/27 11:37:44 INFO Utils: Successfully started service 'sparkDriver' on port 41455.
23/09/27 11:37:44 INFO SparkEnv: Registering MapOutputTracker
23/09/27 11:37:44 INFO SparkEnv: Registering BlockManagerMaster
23/09/27 11:37:44 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/09/27 11:37:44 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/09/27 11:37:44 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
23/09/27 11:37:44 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-fc12136a-2b85-4e9a-9402-1a9cd5848849
23/09/27 11:37:44 INFO MemoryStore: MemoryStore started with capacity 93.3 MiB
23/09/27 11:37:44 INFO SparkEnv: Registering OutputCommitCoordinator
23/09/27 11:37:44 INFO Utils: Successfully started service 'SparkUI' on port 4040.
23/09/27 11:37:44 INFO SparkContext: Added JAR file:/home/cluster/KafkaSparkHoodie.jar at spark://node88:41455/jars/KafkaSparkHoodie.jar with timestamp 1695829063904
23/09/27 11:37:44 INFO FairSchedulableBuilder: Creating Fair Scheduler pools from default file: fairscheduler.xml
23/09/27 11:37:44 INFO FairSchedulableBuilder: Created pool: production, schedulingMode: FAIR, minShare: 2, weight: 1
23/09/27 11:37:44 INFO FairSchedulableBuilder: Created pool: test, schedulingMode: FIFO, minShare: 3, weight: 2
23/09/27 11:37:44 INFO FairSchedulableBuilder: Created default pool: default, schedulingMode: FIFO, minShare: 0, weight: 1
23/09/27 11:37:44 INFO Executor: Starting executor ID driver on host node88
23/09/27 11:37:44 INFO Executor: Starting executor with user classpath (userClassPathFirst = false): ''
23/09/27 11:37:44 INFO Executor: Fetching spark://node88:41455/jars/KafkaSparkHoodie.jar with timestamp 1695829063904
23/09/27 11:37:44 INFO TransportClientFactory: Successfully created connection to node88/10.10.10.88:41455 after 26 ms (0 ms spent in bootstraps)
23/09/27 11:37:44 INFO Utils: Fetching spark://node88:41455/jars/KafkaSparkHoodie.jar to /tmp/spark-76aff444-bab4-4750-bb7b-e24519621a6d/userFiles-d302459d-968c-47cc-8ba4-0b32ab4431fe/fetchFileTemp6103368611573950971.tmp
23/09/27 11:37:45 INFO Executor: Adding file:/tmp/spark-76aff444-bab4-4750-bb7b-e24519621a6d/userFiles-d302459d-968c-47cc-8ba4-0b32ab4431fe/KafkaSparkHoodie.jar to class loader
23/09/27 11:37:45 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39695.
23/09/27 11:37:45 INFO NettyBlockTransferService: Server created on node88:39695
23/09/27 11:37:45 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
23/09/27 11:37:45 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, node88, 39695, None)
23/09/27 11:37:45 INFO BlockManagerMasterEndpoint: Registering block manager node88:39695 with 93.3 MiB RAM, BlockManagerId(driver, node88, 39695, None)
23/09/27 11:37:45 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, node88, 39695, None)
23/09/27 11:37:45 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, node88, 39695, None)
23/09/27 11:37:45 ERROR SparkContext: Error initializing SparkContext.
java.io.FileNotFoundException: File file:/tmp/spark-events does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:779)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:1100)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:769)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:462)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:83)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:622)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2714)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:953)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:947)
at com.example.cloud.KafkaSparkHoodie$.main(KafkaSparkHoodie.scala:31)
at com.example.cloud.KafkaSparkHoodie.main(KafkaSparkHoodie.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:984)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:191)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:214)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1072)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1081)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
23/09/27 11:37:45 INFO SparkUI: Stopped Spark web UI at http://node88:4040
23/09/27 11:37:45 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/09/27 11:37:45 INFO MemoryStore: MemoryStore cleared
23/09/27 11:37:45 INFO BlockManager: BlockManager stopped
23/09/27 11:37:45 INFO BlockManagerMaster: BlockManagerMaster stopped
23/09/27 11:37:45 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/09/27 11:37:45 INFO SparkContext: Successfully stopped SparkContext
Exception in thread "main" java.io.FileNotFoundException: File file:/tmp/spark-events does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:779)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:1100)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:769)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:462)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:83)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:622)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2714)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:953)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:947)
at com.example.cloud.KafkaSparkHoodie$.main(KafkaSparkHoodie.scala:31)
at com.example.cloud.KafkaSparkHoodie.main(KafkaSparkHoodie.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:984)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:191)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:214)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1072)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1081)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
23/09/27 11:37:45 INFO ShutdownHookManager: Shutdown hook called
23/09/27 11:37:45 INFO ShutdownHookManager: Deleting directory /tmp/spark-19e10066-ccc4-4643-a8c7-e0174bdd6b83
23/09/27 11:37:45 INFO ShutdownHookManager: Deleting directory /tmp/spark-76aff444-bab4-4750-bb7b-e24519621a6d
[root@node88 bin]#
4、启动flink集群
/home/cluster/flink/bin/start-cluster.sh
/home/cluster/flink/bin/stop-cluster.sh
5、启动hive
/home/cluster/hive/bin/hive
一、
/home/cluster/hive/bin/hive --service metastore
或者/home/cluster/hive/bin/hive --service metastore 2>&1 >/dev/null &
二、
/home/cluster/hive/bin/hive --service hiveserver2
或者/home/cluster/hive/bin/hive --service hiveserver2 2>&1 >/dev/null &
启动连接测试、数据写入到了Hadoop的HDFS里了。
SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory]
Beeline version 3.1.3 by Apache Hive
beeline> !connect jdbc:hive2://node88:10000
Connecting to jdbc:hive2://node88:10000
Enter username for jdbc:hive2://node88:10000: root
Enter password for jdbc:hive2://node88:10000: ******
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node88:10000> show database;
Error: Error while compiling statement: FAILED: ParseException line 1:5 cannot recognize input near 'show' 'database' '<EOF>' in ddl statement (state=42000,code=40000)
0: jdbc:hive2://node88:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (0.778 seconds)
0: jdbc:hive2://node88:10000> use default;
No rows affected (0.081 seconds)
0: jdbc:hive2://node88:10000> CREATE TABLE IF NOT EXISTS default.hive_demo(id INT,name STRING,ip STRING,time TIMESTAMP) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
Error: Error while compiling statement: FAILED: ParseException line 1:74 cannot recognize input near 'time' 'TIMESTAMP' ')' in column name or constraint (state=42000,code=40000)
0: jdbc:hive2://node88:10000> CREATE TABLE IF NOT EXISTS default.hive_demo(id INT,name STRING,ip STRING,t TIMESTAMP) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
No rows affected (2.848 seconds)
0: jdbc:hive2://node88:10000> show tables;
+------------+
| tab_name |
+------------+
| hive_demo |
+------------+
1 row selected (0.096 seconds)
0: jdbc:hive2://node88:10000> insert into hive_demo(id,name,ip,t) values("123456","liebe","10.10.10.88",now());
Error: Error while compiling statement: FAILED: SemanticException [Error 10011]: Invalid function now (state=42000,code=10011)
0: jdbc:hive2://node88:10000> insert into hive_demo(id,name,ip,t) values("123456","liebe","10.10.10.88",unix_timestamp());
No rows affected (180.349 seconds)
0: jdbc:hive2://node88:10000>
0: jdbc:hive2://node88:10000>
0: jdbc:hive2://node88:10000> select * from hive_demo
. . . . . . . . . . . . . . > ;
+---------------+-----------------+---------------+--------------------------+
| hive_demo.id | hive_demo.name | hive_demo.ip | hive_demo.t |
+---------------+-----------------+---------------+--------------------------+
| 123456 | liebe | 10.10.10.88 | 1970-01-20 15:00:56.674 |
+---------------+-----------------+---------------+--------------------------+
1 row selected (0.278 seconds)
0: jdbc:hive2://node88:10000>
命令行操作:

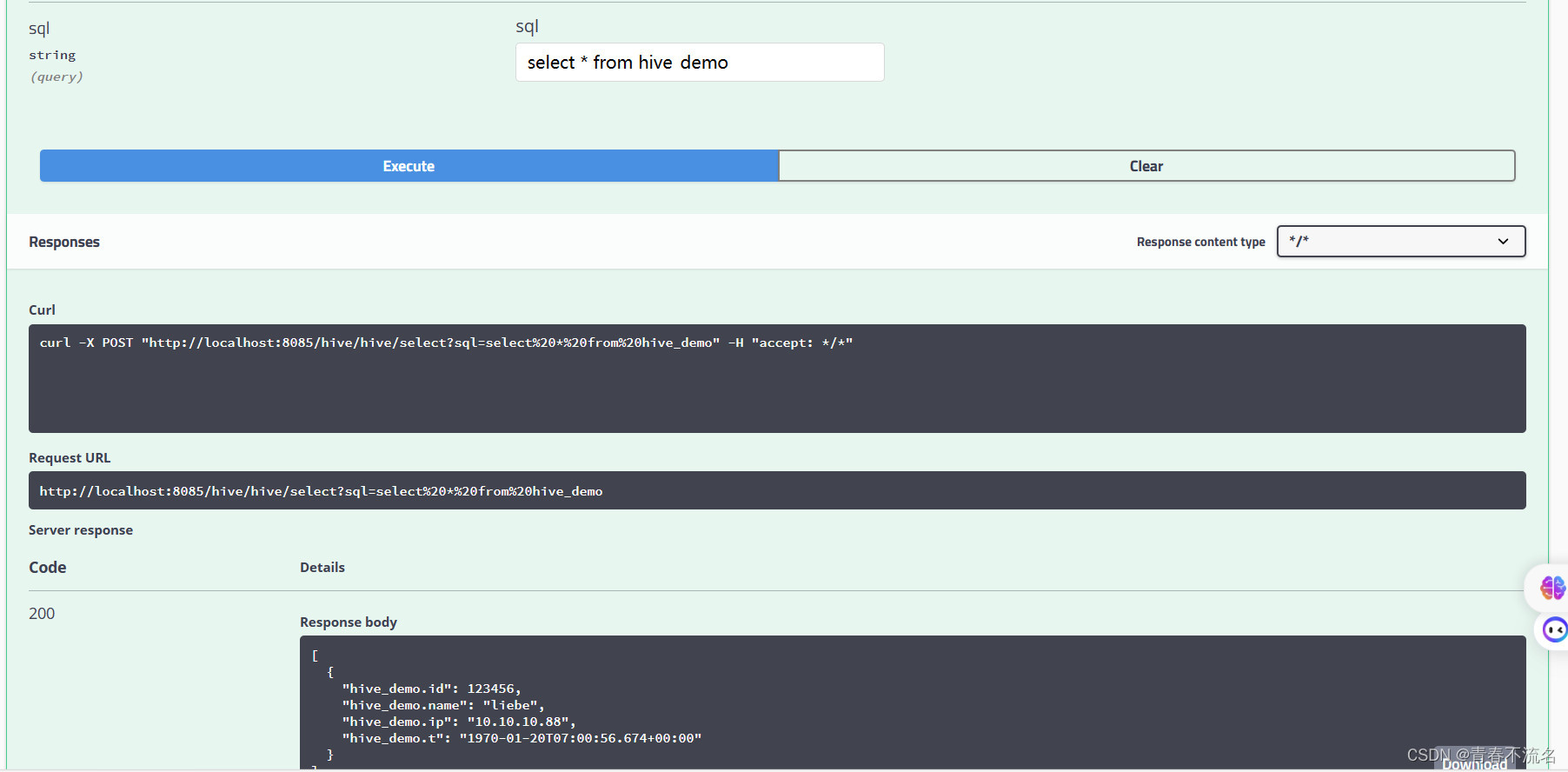
spring-boot查询hive数据
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
server:port: 8085tomcat:max-http-form-post-size: 200MBservlet:context-path: /hive spring:profiles:active: sql customize:hive:url: jdbc:hive2://10.10.10.88:10000/defaulttype: com.alibaba.druid.pool.DruidDataSourceusername: rootpassword: 123456driver-class-name: org.apache.hive.jdbc.HiveDriver
6、启动kafka集群
/home/cluster/kafka_2.12-3.5.1/bin/kafka-server-start.sh /home/cluster/kafka_2.12-3.5.1/config/server.properties
/home/cluster/kafka_2.12-3.5.1/bin/kafka-server-stop.sh /home/cluster/kafka_2.12-3.5.1/config/server.properties
创建topic
/home/cluster/kafka_2.12-3.5.1/bin/kafka-topics.sh --create --topic mysql-flink-kafka --replication-factor 3 --partitions 3 --bootstrap-server 10.10.10.89:9092,10.10.10.89:9092,10.10.10.99:9092
Created topic mysql-flink-kafka.
/home/cluster/kafka_2.12-3.5.1/bin/kafka-topics.sh --describe --topic mysql-flink-kafka --bootstrap-server 10.10.10.89:9092,10.10.10.89:9092,10.10.10.99:9092
Topic: mysql-flink-kafka TopicId: g5_WRWLKR3WClRDZ_Vz2oA PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: mysql-flink-kafka Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: mysql-flink-kafka Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: mysql-flink-kafka Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0/home/cluster/kafka_2.12-3.5.1/bin/kafka-console-consumer.sh --bootstrap-server 10.10.10.89:9092,10.10.10.89:9092,10.10.10.99:9092 --topic mysql-flink-kafka --from-beginning