一、查看执行计划
sql = User.all.to_sql
# 不会实际执行查询
puts ActiveRecord::Base.connection.explain(sql)# 会实际执行查询,再列出计划
User.all.explain# 会实际执行查询,再列出计划
ActiveRecord::Base.connection.execute('EXPLAIN (ANALYZE, VERBOSE, BUFFERS, FORMAT TEXT) '+ sql).each { |a| pp a } # FORMAT { TEXT | XML | JSON | YAML }EXPLAIN 中可以带的参数很多,以下一些比较常用:
Analyze 实际上你要实际运行SQL 并给出实际执行的结果
Verbose 将信息更加详细,括计划树中每个节点的输出列列表、模式限定表和函数名
Buffers 给出语句到底是读取数据的路径是 磁盘 还是 内存以及多少块被涉及,shared hit 命中缓存数,read IO读取数
另外timming costs 等都是默认打开的。
注意:
在加上 ANALYZE 选项后,会真正执行实际的 SQL,如果 SQL 语句是一个插入、删除、更新或 CREATE TABLE AS 语句,这些语句会修改数据库。为了不影响实际的数据,可以把 EXPLAIN ANALYZE 放到一个事务中,执行完后回滚事务,如下:
BEGIN;
EXPLAIN ANALYZE ...;
ROLLBACK;
节点是从下往上看,上一级节点的成本,是包含了下一级的成本的
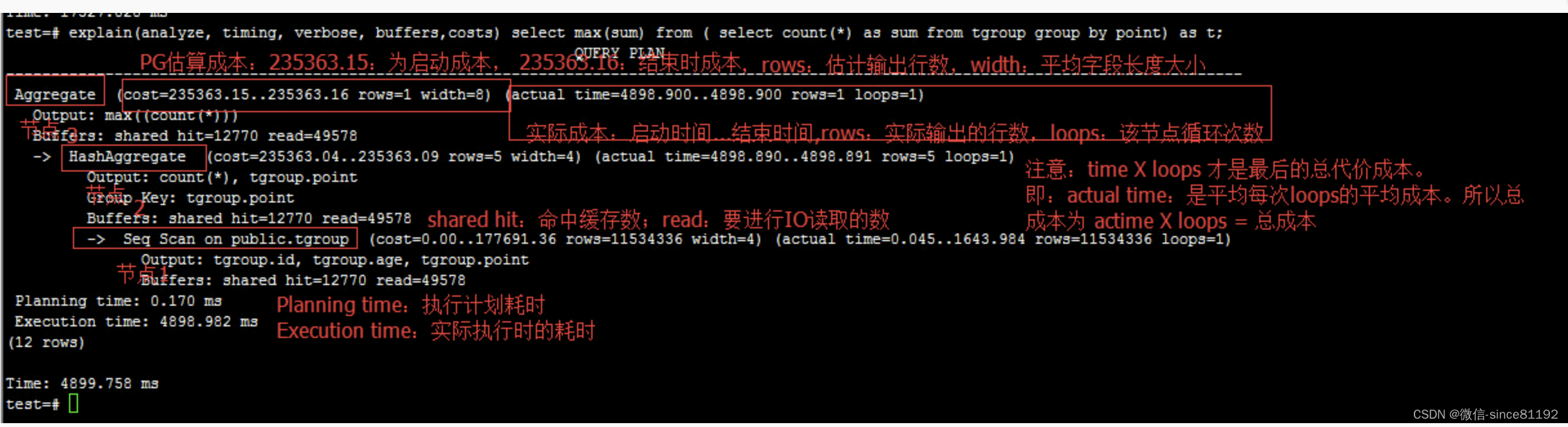
pry(#<Goods>)> ActiveRecord::Base.connection.execute('EXPLAIN ANALYZE '+ sql).each { |a| pp a }(4.9ms) EXPLAIN ANALYZE SELECT "users".* FROM "users"
{"QUERY PLAN"=>"Seq Scan on users (cost=0.00..67.63 rows=1463 width=587) (actual time=0.056..2.063 rows=1463 loops=1)"}
{"QUERY PLAN"=>"Planning Time: 0.409 ms"} # 执行计划耗时
{"QUERY PLAN"=>"Execution Time: 2.207 ms"} # 实际执行耗时
二、解释
- cost=0.00…67.63 rows=1463 width=587, 左到右:
- 预计启动成本。这是输出阶段开始之前所花费的时间,也就是返回第一行需要多少 cost 值,例如,在排序节点中进行排序的时间。
- 预计总成本。这是基于计划节点运行完成的假设,即检索所有可用行。实际上,节点的父节点可能无法读取所有可用行(请参见LIMIT下面的示例)。
- rows 该计划节点输出的估计行数。同样,假设该节点已运行完成。
- width 该计划节点输出的行的估计平均宽度(以字节为单位)。
- buffers
shared hit:表示在共享内存中直接读到 xxx 个块,
read:表示从磁盘读了 xxx 块
written:写磁盘工 xxx 块
.
默认 cost 值如下
顺序扫描一个数据块,cost 值定为 1
随机扫描一个数据块,cost 值定为 4
处理一个数据行的 CPU,cost 为 0.01
处理一个索引行的 CPU,cost 为 0.005
每个操作符的 CPU 代价为 0.0025
注意: "actual time"数值是以真实时间的毫秒来计算的,而"cost"预估值是以磁盘页面读取数量来计算的,所以它们很可能是不一致的。
三、解释
1. Bitmap Scan
- Bitmap Scan 扫描的出现是基于获取的数据在 INDEX SCAN 中的问题点而产生的一个数据的获取的方式,在INDEX SCAN 中获取到数据的位置后,还是需要到对应的数据页面中,在扫描到对应的数据,而BITMAP SCAN 就是要解决数据通过索引定位后,在去原数据页面定位的问题,解决最后一公里的问题。
- 所以通过位图来获取数据的方式,速度更快,当然相对的付出的成本也更多一些。
2. Bitmap Index Scan 与Bitmap Heap Scan
BitmapIndex Scan 与Index Scan 很相似,都是基于索引的扫描,但是BitmapIndex Scan 节点每次执行返回的是一个位图而不是一个元组,其中位图中每位代表了一个扫描到的数据块。而BitmapHeap Scan一般会作为BitmapIndex Scan 的父节点,将BitmapIndex Scan 返回的位图转换为对应的元组。这样做最大的好处就是把Index Scan 的随机读转换成了按照数据块的物理顺序读取,在数据量比较大的时候,这会大大提升扫描的性能。
2. 大多数情况下, Index Only Scan < Index Scan < Bitmap Scan < Seq Scan
- Index Scan 要比 Seq Scan 快。但是如果获取的结果集占所有数据的比重很大时,这时Index Scan 因为要先扫描索引再读表数据反而不如直接全表扫描来的快。
- 如果获取的结果集的占比比较小,但是元组数很多时,可能Bitmap Index Scan 的性能要比Index Scan 好。
- 如果获取的结果集能够被索引覆盖,则Index Only Scan 因为不用去读数据,只扫描索引,性能一般最好。但是如果VM 文件未生成,可能性能就会比Index Scan 要差。
四、解读例子:

四、 其他
-
Seq Scan:全表扫描 无启动时间
-
Index Scan:索引扫描
-
Bitmap Index Scan 位图索引扫描
-
Bitmap Heap Scan:位图索引扫描
-
Subquery Scan 子查询 无启动时间
-
Tid Scan ctid = …条件 无启动时间
-
Function Scan 函数扫描 无启动时间
-
Nested Loop 循环结合 无启动时间
-
Merge Join 合并结合 有启动时间
-
Hash Join 哈希结合 有启动时间
-
Sort 排序,ORDER BY操作 有启动时间
-
Hash 哈希运算 有启动时间
-
Result 函数扫描,和具体的表无关 无启动时间
-
Unique DISTINCT,UNION操作 有启动时间
-
Limit LIMIT,OFFSET操作 有启动时间
-
Aggregate count, sum,avg, stddev集约函数 有启动时间
-
Group GROUP BY分组操作 有启动时间
-
Append UNION操作 无启动时间
-
Materialize 子查询 有启动时间
-
Filter:条件过滤
-
Nestloop Join:嵌套循环连接,是在两个表做连接时,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大,要把返回子集较小的表作为外表,而且在内表的连接字段上要有索引,否则会很慢。执行过程:
1.确定一个驱动表(outer table),另一个表为 inner table
2. 驱动表中的每一行与 inner 表中的相应记录 JOIN 类似一个嵌套的循环 -
Hash Join:使用两个表中较小的表,并利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。适用于较小的表可以完全放入内存中的情况。如果表很大,不能完全放入内存,优化器会将它分割成若干不同的分区,把不能放入内存的部分写入磁盘的临时段。
-
Merge Join:如果源数据上有索引,或者结果已经被排过序,在执行排序合并连接时就不需要排序了,Merge Join 的性能会优于散列连接。
执行计划运算类型 操作说明 是否有启动时间