一、说明
提起在OpenCV中的特征点提取,可以列出Harris,可以使用SIFT算法或SURF算法来检测图像中的角特征点。本篇围绕sift的特征点提取,只是管中窥豹,而更多的特征点算法有:
- Harris & Stephens / Shi–Tomasi 角点检测算法
- Förstner角点检测器;
- 多尺度 Harris 算子
- 水平曲线曲率法
- 高斯的拉普拉斯、高斯的差异和 Hessian 尺度空间兴趣点的行列式
- 基于 Lindeberg Hessian 特征强度度量的尺度空间兴趣点
- 仿射自适应兴趣点算子
- Wang 和 Brady 角点检测算法
- SUSAN 角点检测器
- Trajkovic 和 Hedley 角点检测器
- 基于 AST 的特征检测器
- 检测器自动合成
- 时空兴趣点检测器
二、快速(来自加速段测试的功能)
FAST是一种用于识别图像中的兴趣点的算法。兴趣点具有较高的本地信息含量,理想情况下,它们应该在不同图像之间可重复。FAST算法工作背后的原因是开发一种兴趣点检测器,用于实时帧速率应用,如移动机器人上的SLAM,这些应用的计算资源有限。

算法如下:
- 在强度IP的图像中选择一个像素“p‟”。这是要标识为兴趣点的像素。
- 设置阈值强度值 T。
- 考虑围绕像素 p 的 16 像素圆圈。
- 如果需要将 16 个像素检测为兴趣点,则 <> 个连续像素中的“N”个连续像素需要高于或低于值 T。
- 为了使算法快速,首先将圆的像素 1、5、9 和 13 的强度与 IP 进行比较。从上图中可以明显看出,这四个像素中至少有三个应该满足阈值标准,以便存在兴趣点。
- 如果四个像素值中的至少三个 — I1 、I5 、I9 I13 不高于或低于 IP + T,则 P 不是兴趣点(角)。在这种情况下,我们拒绝像素 p 作为可能的兴趣点。否则,如果至少三个像素高于或低于 Ip + T,则检查所有 16 个像素。
- 对图像中的所有像素重复此过程。
2.1 机器学习方法
- 选择一组图像进行训练,运行FAST算法检测兴趣点


- 对于每个像素“p‟”,将其周围的 16 个像素存储为向量,并对所有像素重复此操作
- 现在这是向量 P,它包含所有用于训练的数据。
- 向量中的每个值都可以采用三种状态。比 p 暗,比 p 亮或与 p 相似。
- 根据状态的不同,整个向量P将细分为三个子集,Pd,Ps,Pb。
- 定义一个变量 Kp,如果 p 是兴趣点,则为 true,如果 p 不是兴趣点,则为 false。
- 使用 ID3 算法(决策树分类器)使用变量 Kp 查询每个子集以获取有关真实类的知识。
- ID3算法的工作原理是熵最小化。以这样一种方式查询 16 像素,以便以最少的查询数找到真正的类(兴趣点或非兴趣点)。或者换句话说,选择像素x,它具有有关像素的最多信息

- 递归地将此熵最小化应用于所有三个子集。
- 当子集的熵为零时终止进程。
- 决策树学习的这种查询顺序也可用于在其他图像中更快地检测。
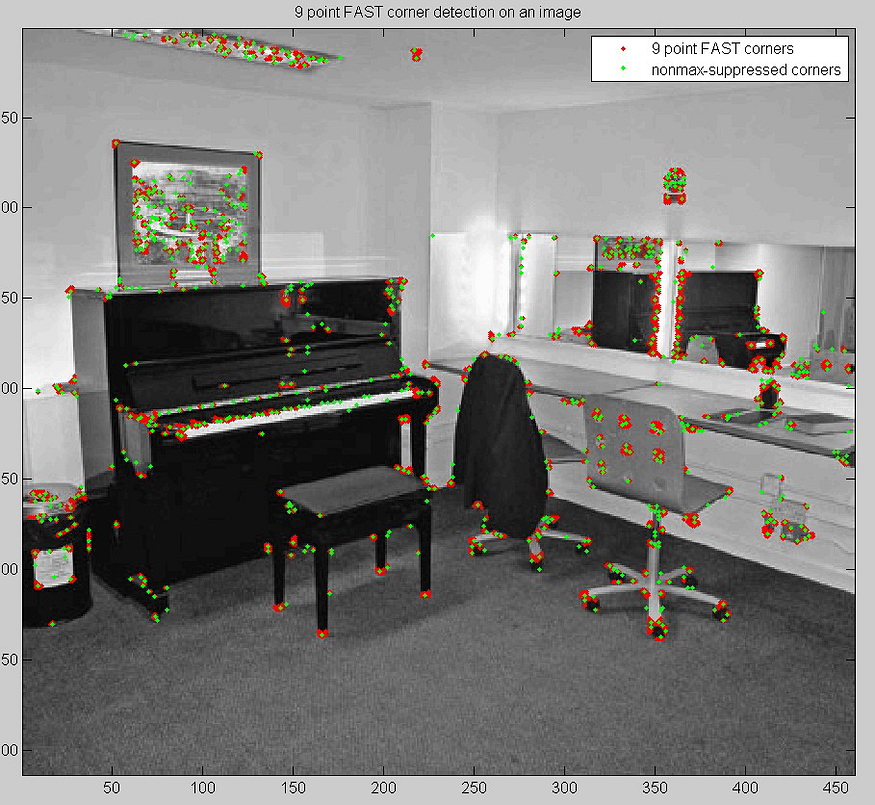
2.2 用于移除相邻拐角的非最大抑制
检测彼此相邻的多个兴趣点是该算法初始版本的其他问题之一。这可以通过在检测到兴趣点后应用非最大抑制来处理。我们为每个检测到的点计算一个评分函数 V。评分函数定义为:“连续弧中像素与中心像素之间的绝对差值之和”。我们比较两个相邻的值并丢弃较低的值。

三、简介 ( 二进制鲁棒独立基本特征 )
BRIEF 提供了一个快捷方式,可以直接查找二进制字符串而无需查找描述符。它采用平滑的图像补丁,并以独特的方式选择一组nd(x,y)位置对(在论文中解释)。然后对这些位置对进行一些像素强度比较。例如,设第一个位置对为 p 和 q。如果 I(p) <I(q) ,则其结果为 1,否则为 0。这适用于所有 nd 位置对以获取 nd 维位串。此 nd 可以是 128、256 或 512。因此,一旦我们得到这个,我们就可以使用汉明距离来匹配这些描述符。


OpenCV中的简介
import numpy as np
import cv2
from matplotlib import pyplot as pltimg = cv2.imread('simple.jpg',0)# Initiate STAR detector
star = cv2.FeatureDetector_create("STAR")# Initiate BRIEF extractor
brief = cv2.DescriptorExtractor_create("BRIEF")# find the keypoints with STAR
kp = star.detect(img,None)# compute the descriptors with BRIEF
kp, des = brief.compute(img, kp)print brief.getInt('bytes')
print des.shape 
四、SIFT(尺度不变特征变换)
它是一种检测图像中突出、稳定的特征点的技术。对于每个这样的点,它都提供了一组不变的旋转和缩放特征。

SIFT算法有四个步骤:
•确定显著特征点(也称为关键点)的大致位置和比例
•优化其位置和规模
•确定每个关键点的方向。
•确定每个关键点的描述符。

五、大致位置
SIFT算法使用高斯差,这是LoG的近似值。此过程针对高斯金字塔中图像的不同八度音阶完成。一旦找到此DoG,就会在比例和空间上搜索图像的局部极值。这基本上意味着关键点在该比例中得到最好的表示。
5.1 关键点本地化
一旦找到潜在的关键点位置,就必须对其进行优化以获得更准确的结果。他们使用尺度空间的泰勒级数展开来获得更准确的极值位置,如果该极值的强度小于阈值(根据论文为0.03),则被拒绝。此阈值在 OpenCV 中称为 contrastThreshold。

DoG对边缘的响应更高,因此也需要去除边缘。为此,使用了类似于哈里斯角检测器的概念。他们使用2x2的Hessian矩阵(H)来计算主曲率。所以这里我们使用一个简单的函数:如果这个比率大于阈值,则该关键点将被丢弃。因此,它消除了任何低对比度的关键点和边缘关键点,剩下的就是强烈的兴趣点。
5.2 指定方向
现在为每个关键点分配一个方向,以实现图像旋转的不变性。根据比例在关键点位置周围选取邻域,并在该区域计算梯度大小和方向。将创建具有 36 个箱(覆盖 360 度)的方向直方图。它由梯度幅度和高斯加权圆形窗口加权,σ等于关键点刻度的 1.5 倍。取直方图中的最高峰,任何高于 80% 的峰值也被认为是计算方向的。它创建具有相同位置和比例但方向不同的关键点。它有助于匹配的稳定性。
5.3 每个关键点的描述符
现在,关键点描述符已创建。在关键点周围拍摄一个 16x16 的邻域。它分为 16 个 4x4 大小的子块。对于每个子块,创建一个 8 箱方向的直方图。它表示为向量以形成关键点描述符。除此之外,还采取了一些措施来实现对照明变化、旋转等的鲁棒性。

六、应用:匹配SIFT描述符
通过识别其最近的邻居来匹配两个图像之间的关键点。但在某些情况下,第二个最接近的匹配可能非常接近第一个。这可能是由于噪音或其他一些原因而发生的。在这种情况下,将采用最近距离与第二近距离的比率。如果大于 0.8,则拒绝它们。它消除了大约 90% 的错误匹配,而只丢弃了 5% 的正确匹配。

用于创建全景视图的 SIFT


OpenCV 中的 SIFT
import cv2
import numpy as npimg = cv2.imread('home.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)sift = cv2.SIFT()
kp = sift.detect(gray,None)img=cv2.drawKeypoints(gray,kp)cv2.imwrite('sift_keypoints.jpg',img) 七、SURF(加速 - 强大的功能)

获取 SURF 描述符分为两个阶段,首先检测 SURF 点,然后在 SURF 点提取描述符。SURF点的检测利用了尺度空间理论。为了检测SURF点,使用快速黑森矩阵。黑森矩阵的行列式用于决定是否可以选择一个点作为兴趣点。在图像 I 中,点 X 处的 Hessian 矩阵由下式定义:
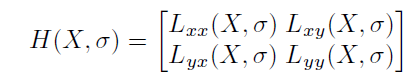
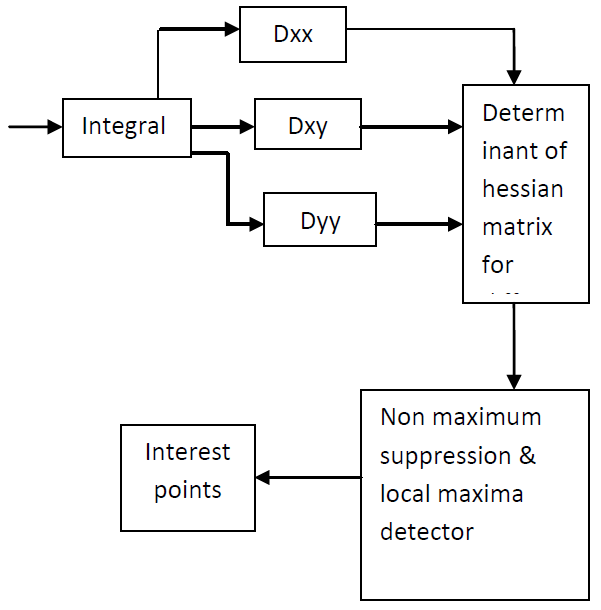
在对图像执行卷积之前,需要对高斯二阶导数进行离散化。Dxx、Dyy 和 Dxy 表示框滤波器与图像的卷积。这些近似的二阶高斯导数计算是通过使用积分图像快速进行的。
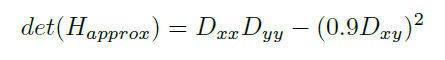
通过更改框过滤器的大小来分析图像的比例空间。通常,Box 滤波器以默认大小 9x9 开头,对应于 σ= 1.2 的高斯导数。过滤器大小稍后会放大到 15x15、21x21、27x27 等大小。在每个尺度上计算黑森矩阵的近似行列式,并应用 333 个邻域中的非极大抑制来求最大值。SURF 点的位置和比例 s 是用最大值获得的。
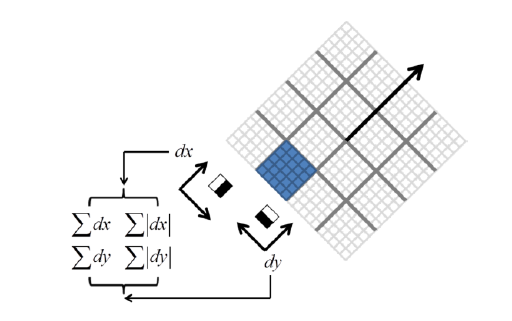


获得的SURF点的方向使用Haar小波响应进行分配。在 SURF 点附近,即半径 6s 以内,在 x 和 y 方向上计算哈尔小波响应。使用这些响应,确定主要方向。在主导方向上,构建了一个以SURF点为中心的20s大小的正方形。这分为44个子区域。在这些子区域中,在55个规则放置的采样点处计算水平和垂直Haar小波响应dx和dy。这些响应以特定的区间相加,得到 Σdx , Σdy。此外,这些响应的绝对值以特定区间求和,得到 Σ|dx|, Σ|dy|.使用这些值,为每个子区域构造一个 4 维特征向量 V = (Σdx, Σdy, Σ|dx| , Σ|dy|)。因此,每个提取的 SURF 点都与一个 4x(4x4) 描述符相关联,该描述符是一个 64 维描述符。此 64 维描述符用于执行匹配操作。



八、ORB (定向快速和旋转简报)
ORB基本上是FAST关键点检测器和BRIEF描述符的融合,并进行了许多修改以增强性能。首先,它使用 FAST 查找关键点,然后应用 Harris 角度量来查找其中的前 N 个点。它还使用金字塔来生成多尺度特征。
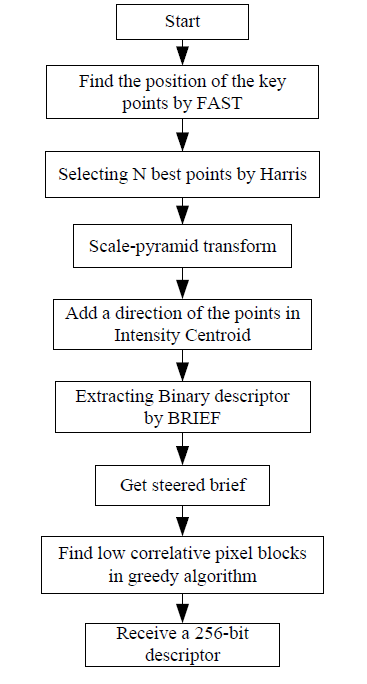
ORB的算法:
它计算角位于中心的修补程序的强度加权质心。矢量从此角点到质心的方向给出了方向。为了提高旋转不变性,用 x 和 y 计算弯矩,它们应该在半径为 r 的圆形区域中,其中 r 是补丁的大小。现在对于描述符,ORB 使用 BRIEF 描述符。BRIEF是旋转不变的,因此ORB根据关键点的方向来操纵BRIEF。对于位置 xi,yi 处的 n 个二进制测试的任何特征集,定义一个 2 x n 矩阵 S,其中包含这些像素的坐标。然后利用贴片的方向θ,找到它的旋转矩阵,旋转S得到转向(旋转)版本Sθ。
随着轮换的不变,BRIEF变得更加分散。ORB 在所有可能的二元检验中运行贪婪搜索,以找到方差高且均值接近 0.5 且不相关的检验。结果称为 rBRIEF。对于描述符匹配,使用了在传统LSH基础上改进的多探针LSH。
OpenCV 中的 ORB:
import numpy as np
import cv2
from matplotlib import pyplot as pltimg = cv2.imread('simple.jpg',0)# Initiate STAR detector
orb = cv2.ORB()# find the keypoints with ORB
kp = orb.detect(img,None)# compute the descriptors with ORB
kp, des = orb.compute(img, kp)# draw only keypoints location,not size and orientation
img2 = cv2.drawKeypoints(img,kp,color=(0,255,0), flags=0)
plt.imshow(img2),plt.show() 

使用 ORB 进行图像匹配