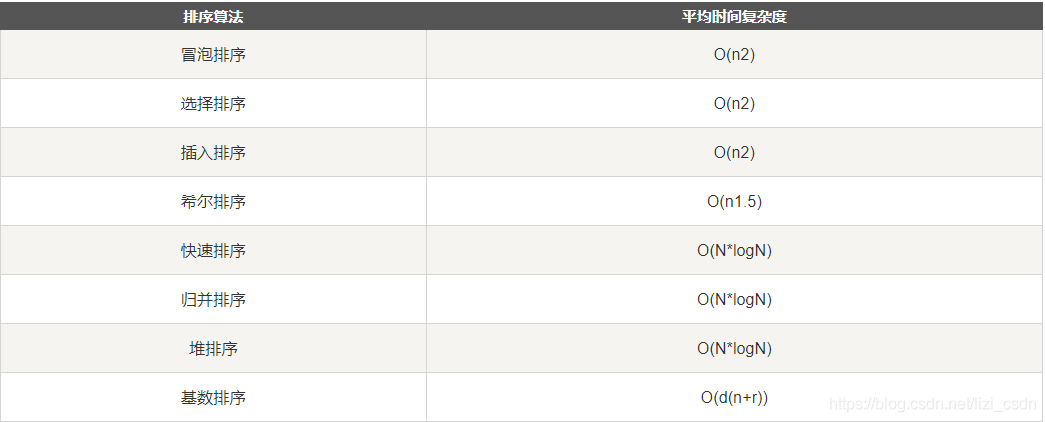
Shapiro-Francia检验是一种用于检验数据是否来自正态分布的统计方法。它是Shapiro-Wilk检验的一个变种,通常适用于小到中等样本大小的数据集。Shapiro-Francia检验的核心思想是通过计算统计量来评估数据的正态性。
Shapiro-Francia检验的零假设是数据来自正态分布,而备择假设是数据不来自正态分布。检验的结果会生成一个p-value,如果p-value较小(通常小于0.05),则通常会拒绝零假设,表明数据不符合正态分布。如果p-value较大,则无法拒绝零假设,表明数据可能来自正态分布。
这种检验方法对于小到中等样本大小的数据集通常效果良好,并且可以用于确定数据是否符合正态分布的假设。
虽然Shapiro-Francia检验在小样本中通常效果较好,但它也依赖于权重参数的准确性,因此在某些情况下可能不如其他正态性检验方法稳健。因此,在使用Shapiro-Francia检验时,应谨慎选择合适的样本大小和检验方法,以确保可靠的结果。
如果您想执行Shapiro-Francia检验,需要使用特定的统计库或编写自定义函数,因为Shapiro-Francia检验不是SciPy的标准功能。以下是一个示例自定义函数来执行Shapiro-Francia检验的方法:
from scipy import stats
import numpy as np# 这个函数的实现是基于Shapiro-Francia检验的一种常见形式,但在特定情况下可能需要根据您的需求进行微调。
def shapiro_francia(data):n = len(data)data = np.sort(data)w = np.corrcoef(data, np.arange(1, n + 1) / (n + 1), rowvar=False)[0, 1]# 参数a和b通常是Shapiro-Francia检验的推荐值,用于计算这些权重。a = 1.0378b = 0.365statistic = (w / a) ** 2p_value = 1 - stats.chi2.cdf(statistic, df=2)return statistic, p_value# 示例数据,用您的实际数据替换这里的数据
# data = [2.5, 3.0, 2.7, 3.2, 2.8, 3.5, 2.9, 3.7, 2.8, 3.9]
data = [34,56,39,71,84,92,44,67,98,49,55,73,50,62,75,44,88,53,61,25,36,66,77,35]# 执行Shapiro-Francia正态性检验
# Shapiro-Francia检验通过计算样本数据的统计量来评估数据是否来自正态分布。
statistic, p_value = shapiro_francia(data)# 输出检验结果
print("Shapiro-Francia Statistic:", statistic)
print("Shapiro-Francia p-value:", p_value)# 根据p-value进行假设检验
alpha = 0.05 # 设置显著性水平
if p_value < alpha:print("拒绝零假设,数据不符合正态分布。\n")
else:print("无法拒绝零假设,数据可能符合正态分布。\n")print("其他检验验证方法参考:")
# 正态性检验 - Shapiro-Wilk检验
stat, p = stats.shapiro(data)
print("Shapiro-Wilk检验统计量:", stat)
print("Shapiro-Wilk检验p值:", p)
print("\n")
# Anderson-Darling检验
result = stats.anderson(data, dist='norm')
# Anderson-Darling统量
print("Anderson-Darling统计量:", result.statistic)
# 临界值
print("临界值:", result.critical_values)
# 显著性水平
print("显著性水平:", result.significance_level)
# 适配结果
fit_result = result.fit_result
print("适配结果 params:", fit_result.params)
print("适配结果 success:", fit_result.success)
print("适配结果 message:", fit_result.message)
print("\n")
# 执行单样本K-S检验,假设数据服从正态分布
statistic, p_value = stats.kstest(data, 'norm')
print("K-S检验统计量:", statistic)
print("K-S检验p值:", p_value)
print("\n")
# 执行正态分布检验
k2, p_value = stats.normaltest(data)
print(f"normaltest正态分布检验的统计量 (K^2): {k2}")
print(f"normaltest检验p值: {p_value}")Shapiro-Francia检验的统计量计算如下:

其中,xi 是排序后的数据样本值,xˉ 是数据的均值,ai 是与排序后的百分位数相对应的权重。
参数a和b通常是Shapiro-Francia检验的推荐值,用于计算这些权重。这些值的来源是数理统计学的研究和模拟,以使Shapiro-Francia检验在一般情况下具有合适的性能。这些值可以使统计量W的分布在数据符合正态分布时更接近于一个特定的理论分布(在这种情况下是F分布),从而可以用于计算p-value。
请注意,Shapiro-Francia检验的实现可以在不同的统计软件和编程语言中略有不同,因此具体的参数值可能会有所变化,但一般来说,这些参数值是经过统计研究确定的,用于Shapiro-Francia检验的统计计算。
--
需要注意的是,Shapiro-Francia检验对于较大样本大小可能会不敏感,因此对于大样本,Shapiro-Wilk检验可能更合适。此外,虽然Shapiro-Francia检验在小样本中通常效果较好,但它也依赖于权重参数的准确性,因此在某些情况下可能不如其他正态性检验方法稳健。因此,在使用Shapiro-Francia检验时,应谨慎选择合适的样本大小和检验方法,以确保可靠的结果。