一、数据预处理
1.1概述
- 数据预处理的重要性
- 杂乱性:如命名规则。
- 重复性:同一客观事再
- 不完整性:
- 噪声数据:数据中存在错误或异常的现象。
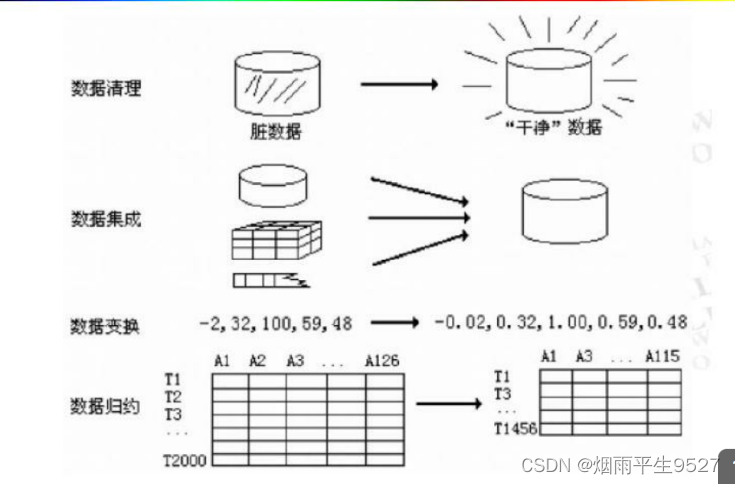
- 数据预处理的常见方法
- 数据清洗:去掉数据中的噪声,纠正不一致。
- 数据集成:将多个数据源合成一致的数据存储
- 数据变换(转换):对数据的格式进行转换,如数据的归一化处理。
- 数据归约(消减):通过聚集、删除冗余属性、局类等方法,来实现数据的压缩。
1.2数据清洗
1.空缺值
- 忽略该元组:
- 其中一条记录中有属性值被遗漏
- 缺少类标号
- 但是,当某一类属性的空缺值占百分比很大,若直接忽略,则会使挖掘性能变得非常差。
- eg:Y:N=1:1,忽略后会变成Y:N=3:1
- 人工填写空缺值
- 使用属性的平均值来填充空缺值
- 使用与给定元组属同一类的平均值来代替
- 使用一个全局变量填充空缺值(不推荐)
- 使用最可能的值填充空缺值
- 回归、贝叶斯、判定树归纳确定
2.噪声数据的处理

-
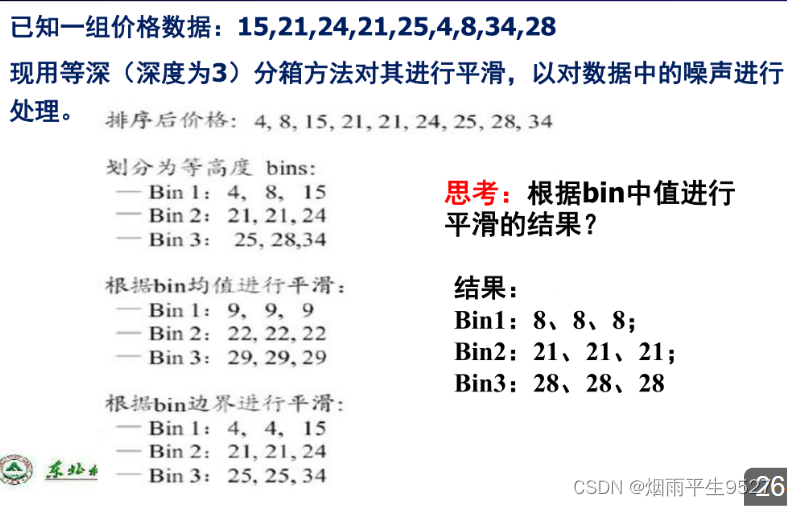
分箱方法(重点)
分箱的步骤:
- 先排 序排序,将其分到等深(等宽)的箱中
- 按箱的平 均 值(在出现极端数据的情况下,不能用均值处理)、中 值、边界(用左右边界进行替换)进行平滑
等深分箱(分块)
按记录数进行分箱,每箱具有相同的记录数,每箱的记录数称为箱的权重,也称箱子的深度。
等宽分箱
在整个属性值的区间上平均分布,即每个箱的区间范围设定为一一个常量,称为箱子的宽度。

聚类方法
- 相似、向邻近的数据集合在一起形成各个聚类集合。
- 特点:直接形成一簇,不需要先验知识。
- 查找孤立点,消除噪声
线性回归
- 通过回归方程获得拟合函数
人机结合共同检测
3.不一致数据
- 人工更正
- 利用知识工程工具
- 属性之间的函数依赖关系
- 数据字典
1.3数据集成和变换
- 数据集成:将来自多个数据源的数据合并到一起
- 数据变换:对数据进行规范化操作,将其转换成适合于数据挖掘的形式。
1.数据集成
- 需要统一原始数据中的所有矛盾之处
- 同名异义、异名同义、单位不不统一、字长不一致。
- 需要注意的问题:
- 模式匹配
- 整合不同数据源中的元数据。
- 进行实 体 识 别
- 借助于数据字典、元数据
- 数据冗余
- 计算相关分析检测:
- 若有高的相关系数,则可以去除掉。
- 计算相关分析检测:
- 数据值冲突
- 产生原因:表示、比例、编码不同
- 比如:单位不统一、成绩的百分之和五分值。
- 模式匹配
2.数据变换(重点)
常用方法:
- 平滑处理:消除噪声
- 分箱
- 聚集操作:对数据进行综合
- 函数:avg(),count(),min(),max()…
- 数据规范化:将数据转换到一个较小的范围内,两个数据相差比较大。
- 最小-最大规范化
- 将原始属性映射到区间[new_min,new_max]
- 公式:

- z-score规范化
- 根据均值、标准差进行计算
- 常用于:最大值、最小值未知
- 不保证取值区间一致,但新的取值满足01分布

- 小数定标规范化


1.4数据规约
1. 数据规约的标准:
- 时间:原始数据集挖掘时间:t,数据规约时间:t0,挖掘后时间t’,满足: t_0+t'≤t
- 性能:归约后得到的数据比原数据小的多,并可以产生相同或差不多的结果。
2. 策略:
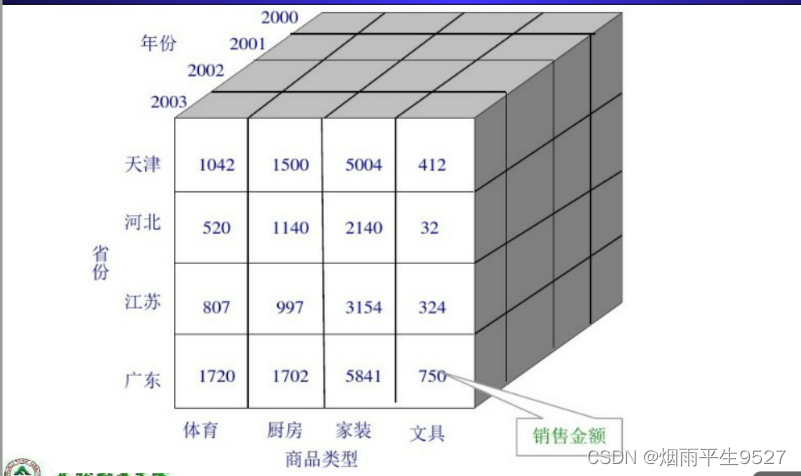
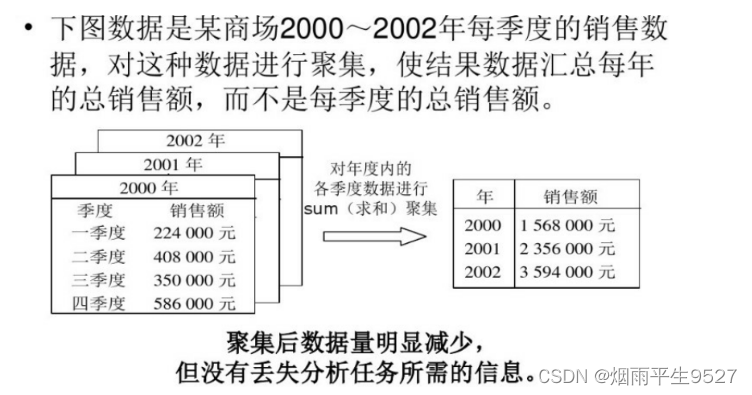
- 数据立方体聚集:
- 维 归 约 ( 重 点 )
- 主要检测并删除不相关、弱相关或冗余的属性维
- .方法:属性子集选择
- 目标:寻找出最小的属性子集,并确保新数据子集的概率分布尽可能接近原来的数据集的概率分布。
- 启发式算法找出"好的’子集
- 逐步向前选择:选择原属性集中最好的属性,并将它添加到该集合中。
- 逐步向后删除:由整个属性集开始,每一步都删除现在属性集中最坏的属性。
- 向前选择和向后删除结合:每一步选择一个最好的属性,并在剩余属性中删除一个最坏的属性。
- 判定树归纳:出现在判定树中的属性形成规约后的属性子集。

1.5数据离散化(重点)
1.三种类型的属性值
- 标称型(名称、名义):数值来自于无序集合,不需要离散化,如性别、地名、人名。
- 不可比、不可加
- 序数型:来自于有序集合,不需要离散化,如等级
- 可比、不可加
- 连续型:实数值,需要离散化,如温度、体重、考试成绩。
- 可比、可加
2.离散化技术
- 分箱
- 基于熵的离散化
- 通过自然划分分段
- 聚类(不推荐)