目录
提示:
一、移除链表元素
题目:
解答:
二、反转链表
题目:
解答:
三、找到链表的中间结点
题目:
解答:
四、合并两个有序链表(经典)
题目:
解答:
提示:
①:接上一篇文章http://t.csdnimg.cn/vvmIr
本次我们来做一些在线OJ题,进一步加深印象和感觉,并且本次某些方法会沿用上一篇文章的,所以感兴趣的小伙伴可以参考一下上一篇文章。
②:对于这些在线OJ,小编会把具体步骤放在注释里面,然后小编没有画图,大家可自行画图然后跟着解析思路一起思考。
③:链表的在线OJ一般都是用的无哨兵的头指针,所以大家一定要搞懂有哨兵和无哨兵的区别。
一、移除链表元素
题目:

解答:
思路:只需要一边遍历链表,一边进行数据域的比较。若找到指定的值val,则删除该结点;
又因为删除一个结点,我们必须知道该结点的前一个结点,所以采用双指针的思路:
一个指针prve用于记录指定结点的前一个结点;
一个指针cur用于遍历寻找。
另外,找的过程中会发生两种情况;
情况一:指定结点为头结点(即头指针的位置):这时我们需要考虑头指针head的变化,具体实现看注释;
情况二:指定结点为一般结点:这时我们就依靠前一个结点正常删除即可;
源代码即注释如下:
struct ListNode* removeElements(struct ListNode* head, int val) {//双指针prev、curstruct ListNode* prev = NULL, *cur = head;//当cur==NULL。即过了尾结点,遍历完成,退出循环while (cur){//数据域相等,说明找到要删的结点if (cur->val == val){//分为两种情况,一是头删,二是正常删除if (cur == head)//头删{head = cur->next;free(cur);cur = head;}//正常删else{prev->next = cur->next;free(cur);cur = prev->next;}}//数据域不相同,则不是指定结点,向后走一步else{prev = cur;cur = cur->next;}}return head; }
二、反转链表
题目:
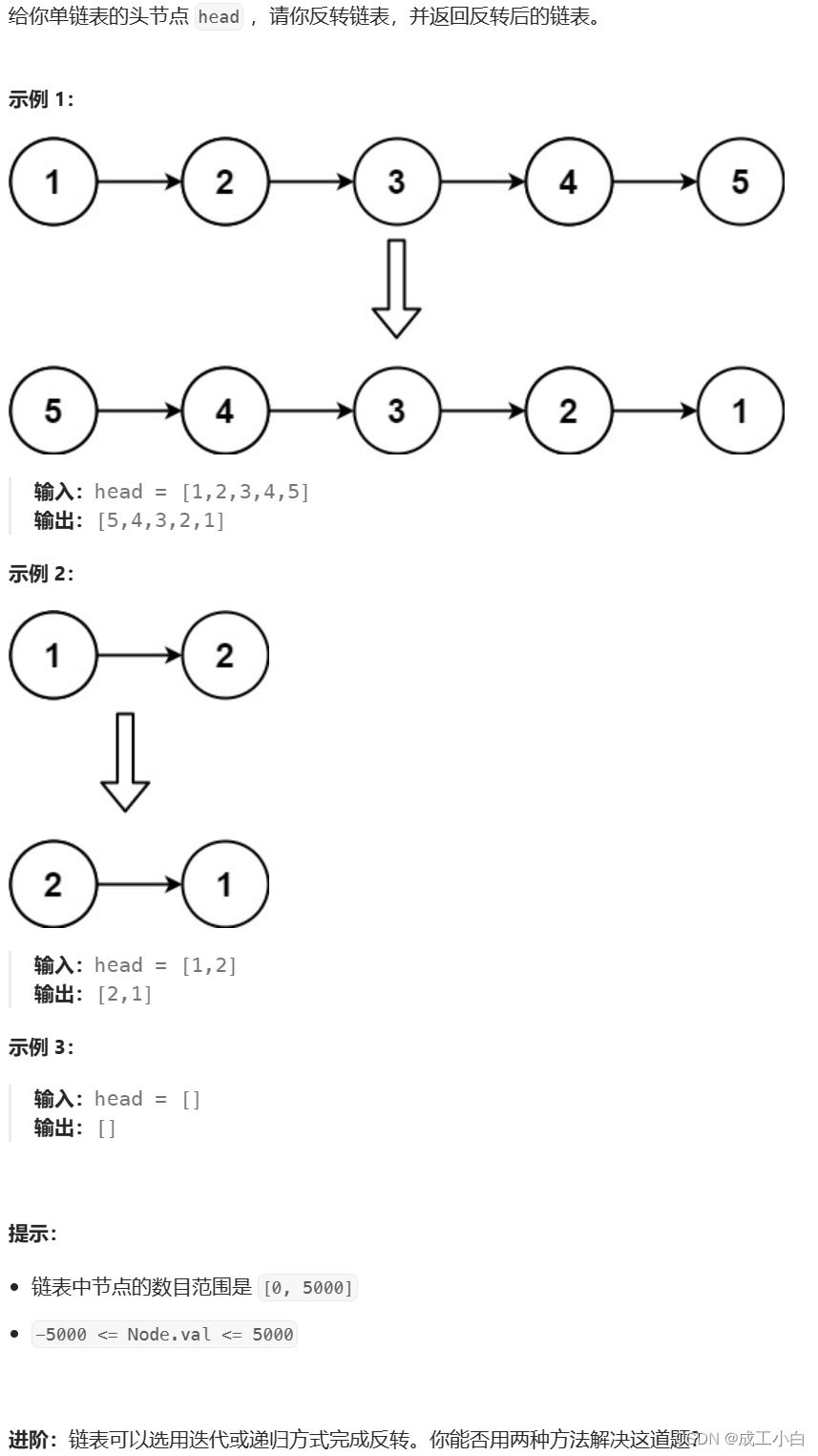
解答:
思路:我们可以将当前结点的next域指向前一结点,但在此之前我们应该把当前结点的前一个结点和后一个结点给保存下来,防止结点丢失;
所以我们可以创建两个临时指针prve和cur;
cur用于保存下一个结点;
prve用于保存前一个结点;
而头结点head就用于保存当前结点;
struct ListNode* reverseList(struct ListNode* head) {//两个临时指针struct ListNode* cur = head, * prve = NULL;//因为cur是用于保存下一个结点,所以当cur为空时,即遍历完链表,循环结束while (cur){//cur保存下一个结点cur = cur->next;//将当前结点的next域指向前一个结点head->next = prve;//将prve保存当前结点,也就是保存下一轮操作的"前一个结点"prve = head;//完成一轮操作,head重定位当前结点head = cur;}//最后当head和cur都为NULL时,prve作为前一个结点即为"原链表的尾结点,反转链表的首结点”,所以返回prvereturn prve; }
三、找到链表的中间结点
题目:
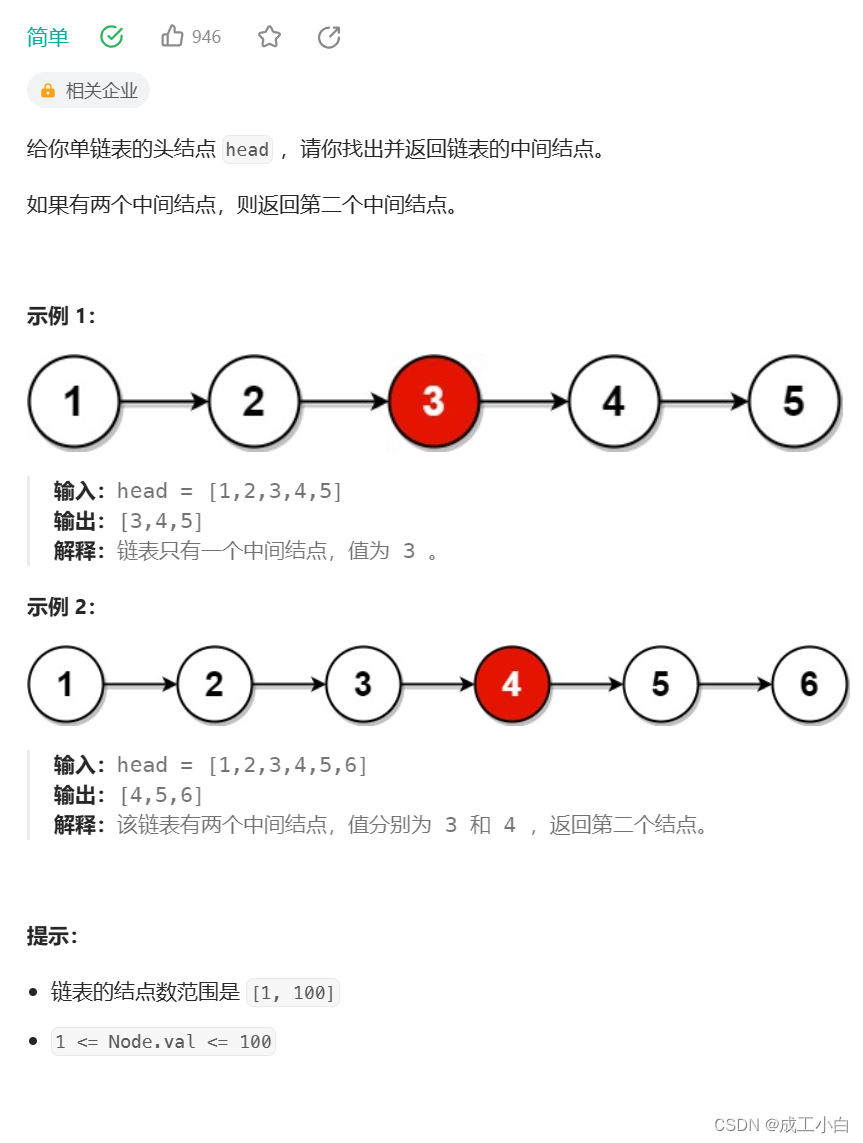
解答:
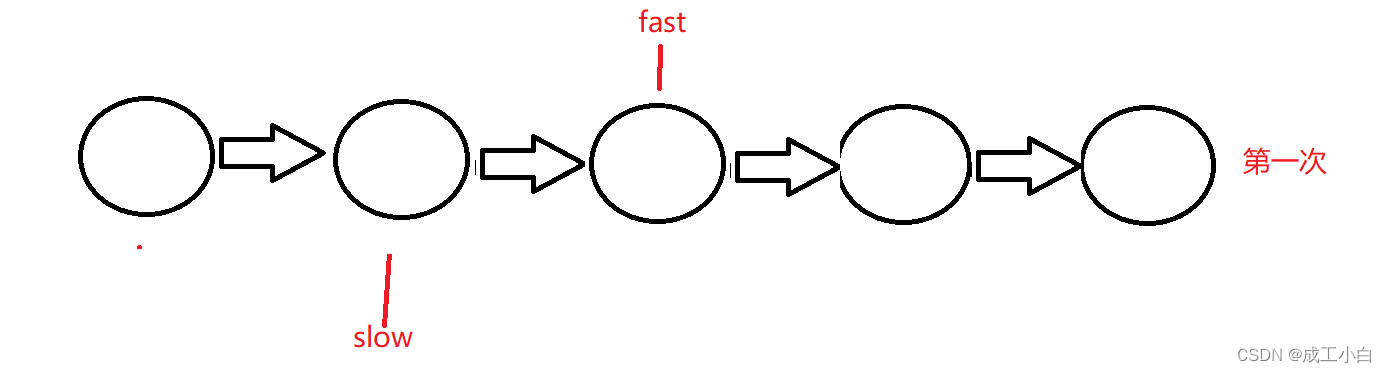
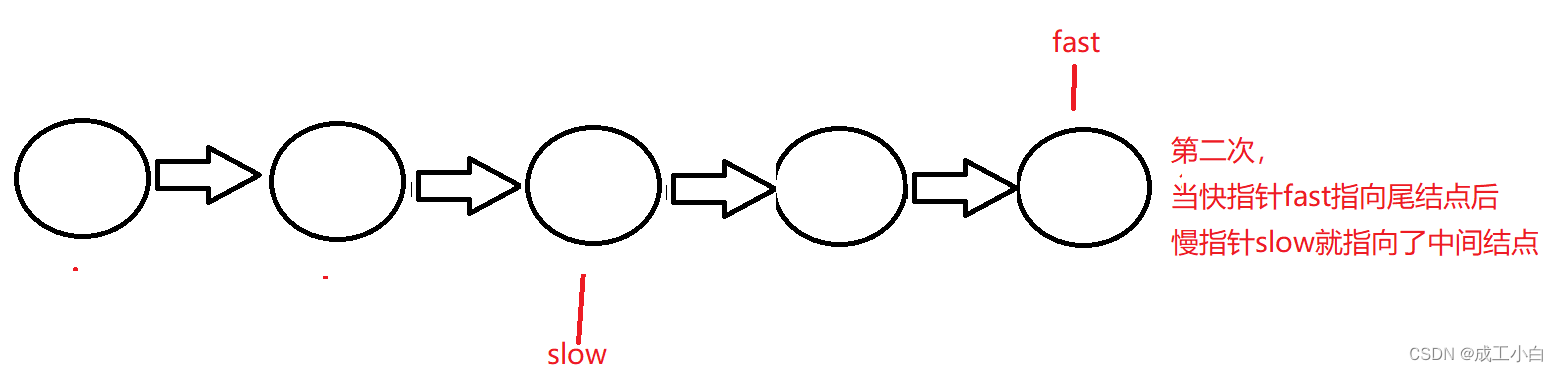
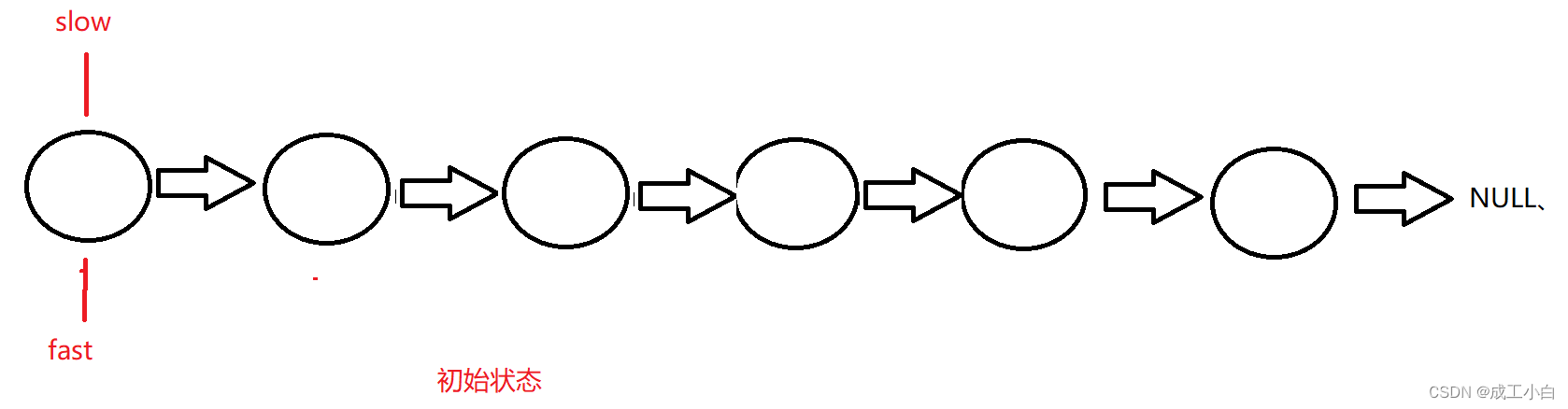
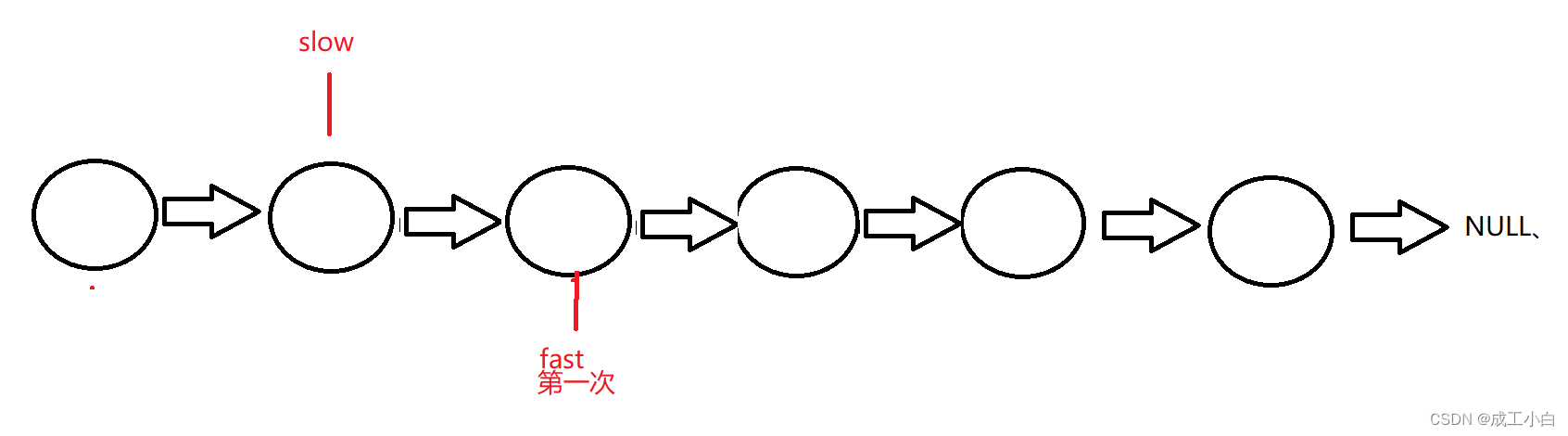
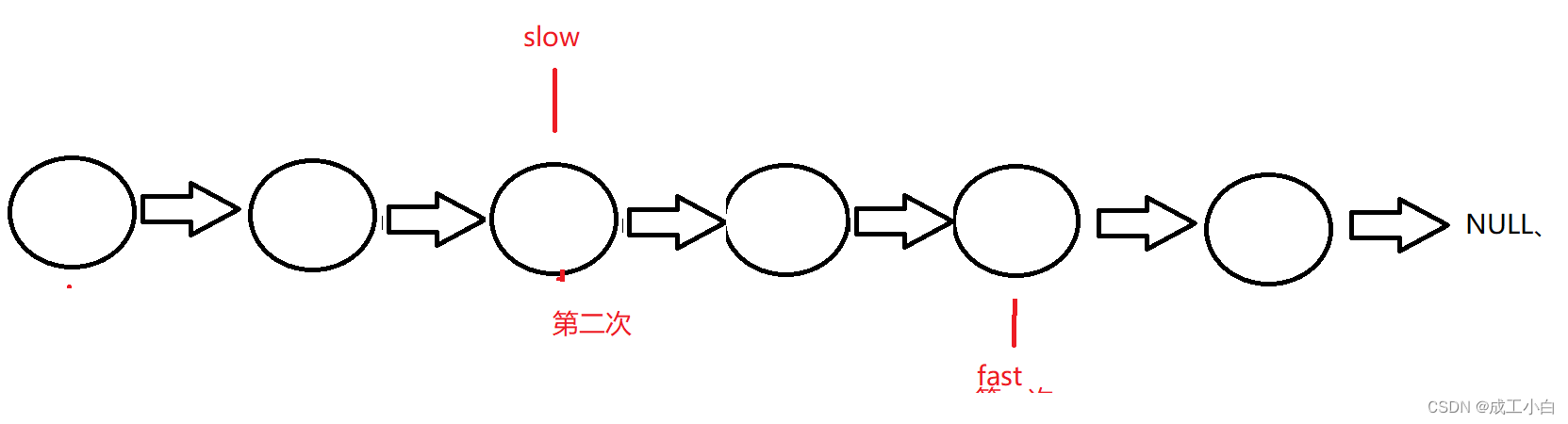
这道题用到一个经典思路叫:“快慢指针”;
即定义两个指针;
一个快指针fast,一次向后跳过两个结点;
一个慢指针slow,一次向后跳过一个结点;
初略想一下,当fast指针遍历完数组后,solw指针就是我们想要的中间结点;
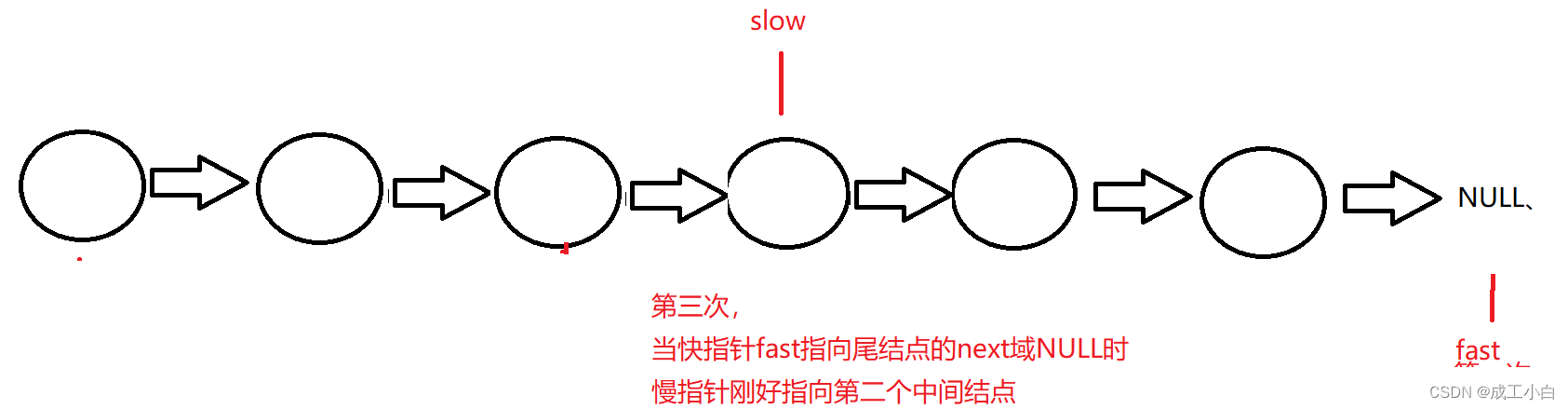
但这里要分奇数个结点还是偶数个结点,如下:
奇数个结点的情况:
偶数个结点的情况:
所以结束有两个可能,即快指针指向尾结点或者快指针指向NULL;
struct ListNode* middleNode(struct ListNode* head) {//快指针fast,慢指针slowstruct ListNode* fast = head, * slow = head;//因为不确定奇数个还是偶数个,所以当快指针任意满足一种情况,则结束while (fast && fast->next){//慢指针走一步slow = slow->next;//快指针走两步fast = fast->next->next;}return slow; }

四、合并两个有序链表(经典)
题目:
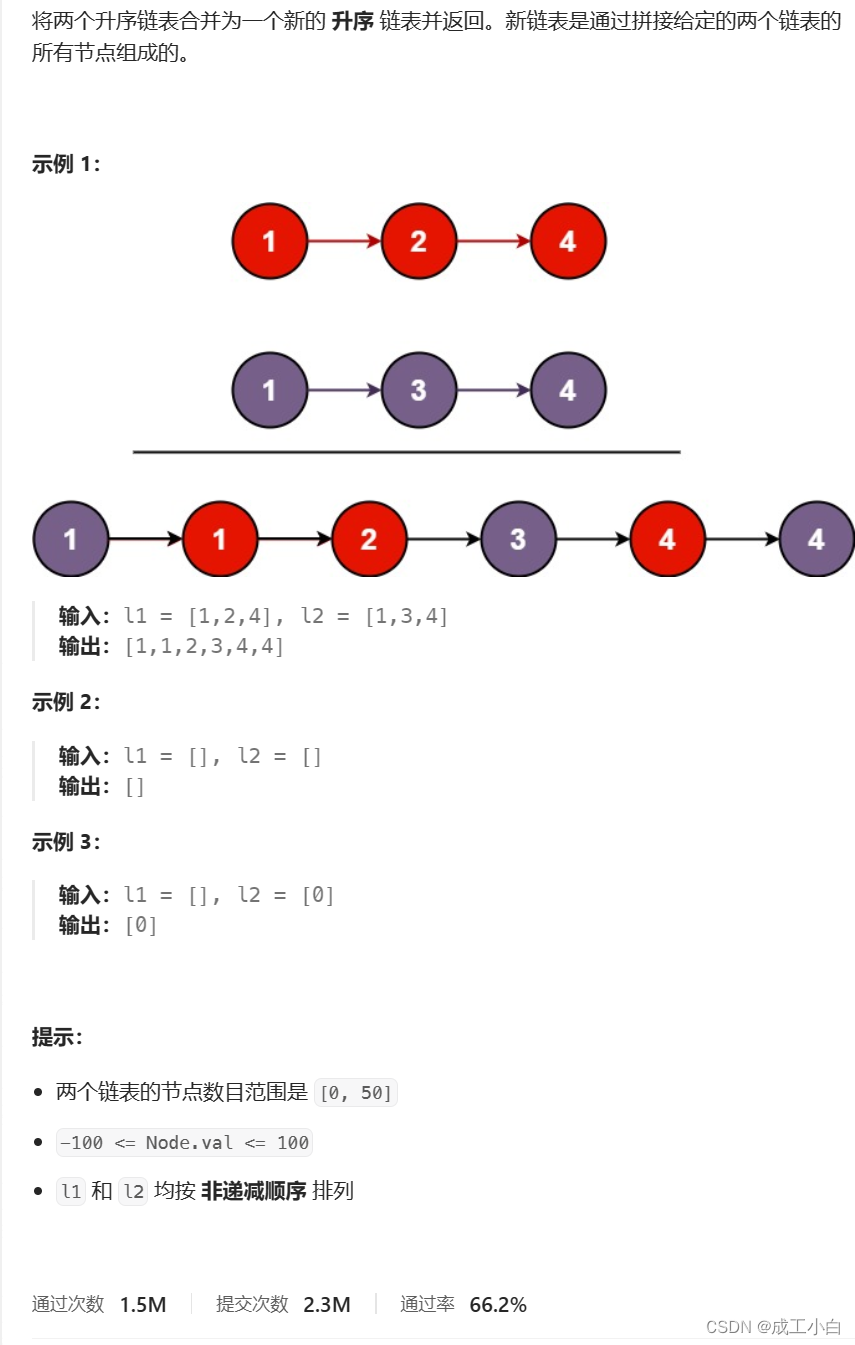
解答:
①:由合并升序链表,我们可以联想到合并升序顺序表(数组),我们知道是将大的一个数放在大空间的末尾,第二大的数放在大空间的倒数第二个位置,重复此操作,直到短的一方比较完,再把长的一方剩下的元素连接在末尾;
②:但链表和顺序表有一点区别是,链表只需要逻辑上相邻即可;
③:所以我们可以创建两个临时指针:
一个临时指针head用于充当新合并链表的头指针;
一个临时指针tail用于插入操作;
④:具体我们只需要将两个链表中的元素依次比较,再将数据域小的结点尾插到tail链表后面,因为tail和head指向同一个链表,只是head是头指针,过程中是tail再变,所以要注意tail指针的变化,最后返回head头指针即可。
⑤:其中我们可能遇到三种情况:
情况一、链表一或链表二为空,则直接返回另一个链表;
情况二、链表一和链表二长度相等,则循环上述操作;
情况三、长度不相等,则操作到某一时刻,链表一或二就会为NULL,这时就会出循环,然后再将长的链表剩下的元素插到tail结点后面。
//将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {//情况一、表一或表二为NULL,直接返回另一个表if (list1 == NULL)return list2;if (list2 == NULL)return list1;//情况二、按正常操作来进行struct ListNode* head = NULL, * tail = NULL;while (list1 && list2){//依次比较数据域if (list1->val < list2->val){//第一次需要将head和tail指针指向首结点较小的表,以便后续能尾插结点if (tail == NULL){head = tail = list1;}//尾插else{tail->next = list1;tail = tail->next;}list1 = list1->next;}else{//第一次需要将head和tail指针指向首结点较小的表,以便后续能尾插结点if (tail == NULL){head = tail = list2;}//尾插else{tail->next = list2;tail = tail->next;}list2 = list2->next;}}//情况三、两个表长度不相等,会有一个表有剩余//因为是升序表,所以直接将剩余的表插入tail的next域即可if (list1){tail->next = list1;}if (list2){tail->next = list2;}//最后返回合并的表的头指针return head; }
本次知识到此结束,希望对你有所帮助!