线程详解第四篇
- 前言
- 正式开始
- 信号量
- 引例
- 信号量的本质
- 信号量相关的四个核心接口
- 生产消费者模型
- 用环形队列实现生产者消费者模型
- 基于环形队列的生产消费模型的原理
- 代码演示
- 单生产者单消费者
- 多生产者多消费者
- 计数器的意义
- 线程池
- 基本概念
- 代码
- 单例模式
- STL,智能指针和线程安全
- STL中的容器是否是线程安全的?
- 智能指针是否是线程安全的?
- 其他常见的各种锁
- 读者写者问题
- 读写锁
- 接口介绍

前言
- 线程详解前三篇:
- 【Linux】详解线程第一篇——由单线程到多线程的转变
- 【Linux】详解线程第二篇——用黄牛抢陈奕迅演唱会门票的例子来讲解【 线程互斥与锁 】
- 【Linux】详解线程第三篇——线程同步和生产消费者模型
本篇主要讲解信号量的概念以及对这些概念进行代码演示,对于线程池提供代码和详细注释,单例模式结合前面C++中的博客来讲解,以及一些线程部分的收尾知识。
正式开始
信号量
说说共享资源,我前面的博客讲临界资源的时候,是按照任意时刻临界资源都只有一个执行流在进行访问的,但讲到信号量这里要变一变。
如果单纯的把某一块临界资源看作是一个整体的话,且线程之间都是互斥的,看图:
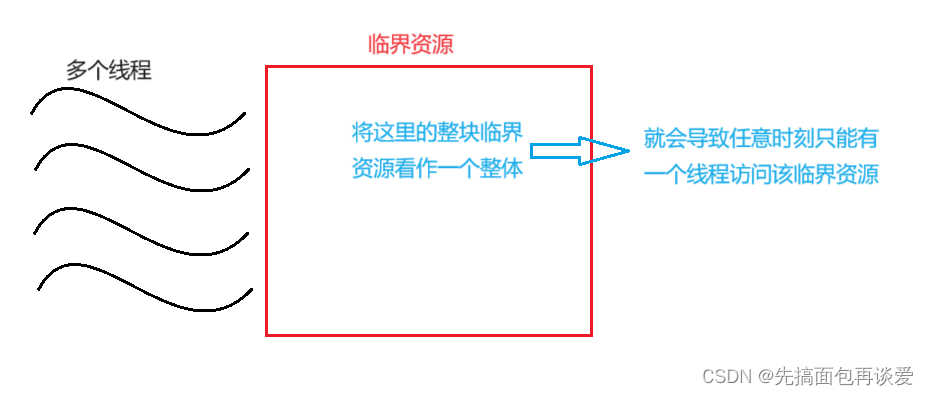
但是如果不把一块共享资源当做一个整体,而是让不同的执行流去访问临界资源中的不同区域的话,就可以继续让多线程并发执行了,而当只有访问其中的小块临界资源的时候才会进行线程同步和互斥,看图:
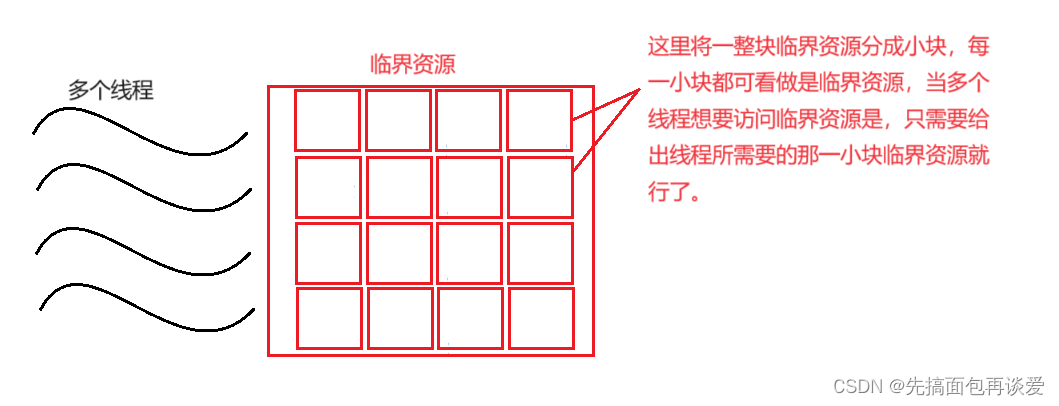
这样多个线程的执行效率就会比上一个高不少。当某一小块被多个线程需要时,此时再加对需要这一小块的线程进行加锁互斥就行。
但是有四个问题:
- 如何确定一整个资源被分成了多少小块的资源?
- 如何确定当申请了m个小块资源后,还剩多少个资源?
- 如何保证某块小资源是给哪个线程的?
- 是否能确定某个线程一定会有一块小资源?
可能屏幕前的你看到这四个问题已经懵了,不要懵,我来给你讲。
引例
来用一个生活中的例子讲讲信号量。
-
我们看电影前都要买票,而买票的就是对座位(资源)的预定机制。把某一个放映厅中的所有座位看作是整块资源,其中的每一个座位当做是一小块资源。其中座位可以分为有效座位和无效座位,有效座位是指某一座位还未被预定,无效座位就是指这个座位被其他人预定了。
-
当买一张票,票上会有你的座位信息,那么该座位就你被提前预定了,此时这个座位就无法被其他人预定,也就从有效座位变为无效座位,但有效座位数是定的,也就是说总票数是定的,那么买一张票就会让总票数减一,也就是有效座位数减一。
-
当电影看完后,走一个人,其对应的座位就不属于这个人了,但座位还是在的,也就是说该座位由无效座位变回了有效座位,人不断走,那么有效的座位数就会不断加一,直到恢复到总的座位数。同样,下一场电影的票数还是总座位数。又是一个循环。
上面有两点比较重要,就是票数和座位数。这两个其实可以看作是一个东西,但是座位数可以分为有效作为和无效座位,假如总的座位数是100,那么两种座位的范围就是 [0 ~ 100] 和 [100 ~ 0],一个增,另一个就会减。
例子就讲到这,其实已经把信号量的核心思想讲出来了,就两个字:预定。
信号量的本质
信号量,英文:semaphore,下面一些关于信号量的东西我就以sem来代替了。
信号量的本质其实就是一个计数器sem,当某一线程想要访问临界资源时,必须先申请信号量资源,此时就是对sem减一,也就是预定信号量资源,在信号量这里有专门的术语,即P操作;当使用完毕信号量资源后,就要让sem加一,也就是释放信号量资源,专业术语即V操作。这里的PV操作是具有原子性的,是库中保证的,不像自增 / 自减操作没有原子性。
对应到上面的买电影票,可以用semValidSet来表示有效座位数,那么semValidSet的起始值就是100,还可以用semInvalidSet来表示无效的座位数,那么semInvalidSet的起始值就是0。当有人买票了之后就会使得semValidSet减一,也就变成了99,对应的semInvalidSet加一,也就变成了1,以此类推,直到semValidSet变为0,semInvalidSet变为100。然后再返回来下一个循环。
再专业点来说,当申请了一个信号量后,当前的执行流就一定具有了某一小块资源,此时如何使用这块资源就要看执行流本身了。具体会分配到哪块资源需要结合场景来看。
信号量相关的四个核心接口
最核心的接口就四个,也是等会要用的,头文件都是semaphore.h。
信号量类型为sem_t,定义一个信号量就和定义一个int变量一样。
- sem_init

这个函数就是给信号量做初始化工作。
第一个参数sem,就是你要初始化的信号量的地址。
第二个参数pshared,是用来说明你当前是的信号量是让进程用的还是让线程用的,如果给零就是让线程用的,如果给非零值就是让进程用的。
man手册中是这么说的:
- The pshared argument indicates whether this semaphore is to be shared between the threads of a process, or between processes.
- If pshared has the value 0, then the semaphore is shared between the threads of a process, and should be located at some address that is visible to all threads (e.g., a global variable, or a variable allocated dynamically on the heap).
- If pshared is nonzero, then the semaphore is shared between processes, and should be located in a region of shared memory (see shm_open(3), mmap(2), and shmget(2)). (Since a child created by fork(2) inherits its parent’s memory mappings, it can also access the semaphore.) Any process that can access the shared memory region can operate on the semaphore using sem_post(3), sem_wait(3), etc.
这里讲的是线程,就直接给零了。
刚刚讲的信号量是一个计数器,是有初始值的,这里第三个参数value就是计数器的初始值,由我们自己来设定。
函数的返回值:成功返回0;失败返回-1,并设置错误码。
- sem_destroy

这个函数就是销毁其参数指向的信号量。没啥讲的。
- sem_wait

这个函数就是前面说的P操作,就是申请信号量,让sem指向的信号量减一。
不过下面还有两个函数,我直接把man手册中的解释给出来吧:
- sem_trywait() is the same as sem_wait(), except that if the decrement cannot be immediately performed, then call returns an error (errno set to EAGAIN) instead of blocking.
- sem_timedwait() is the same as sem_wait(), except that abs_timeout specifies a limit on the amount of time that the call should block if the decrement cannot be immediately performed. The abs_timeout argument points to a structure that specifies an absolute timeout in seconds and nanoseconds since the Epoch, 1970-01-01 00:00:00 +0000 (UTC). This structure is defined as follows:
struct timespec {time_t tv_sec; /* Seconds */long tv_nsec; /* Nanoseconds [0 .. 999999999] */};
If the timeout has already expired by the time of the call, and the semaphore could not be locked immediately, then sem_timedwait() fails with a timeout error (errno set to ETIMEDOUT).
If the operation can be performed immediately, then sem_timedwait() never fails with a timeout error, regardless of the value of abs_timeout. Furthermore, the validity of abs_timeout is not checked in this case.
- sem_post

这个函数就是V操作,也就是对信号量资源的释放,让sem指向的信号量加一。
核心的就是这四个,init、destroy、wait、post。
生产消费者模型
我上一篇已经细讲过生产消费者模型了,如果屏幕前的你不懂可以看看我上一篇博客,也就是线程详解第三篇:【Linux】详解线程第三篇——线程同步和生产消费者模型。
我等会就要用到其中的一些术语来讲某些东西了。
用环形队列实现生产者消费者模型
看到这的同学我就默认你懂生消模型了。如果屏幕前的你不懂,那我建议你还是回头看一下那篇博客。因为等会的讲解中要用到生消模型中的很多概念。
先来说说环形队列,逻辑结构长这样:
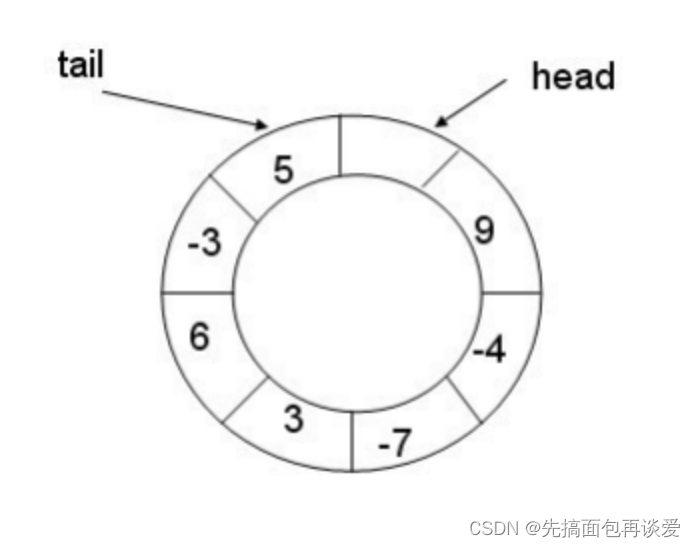
其实我前面讲数据结构中有一篇博客对于模拟实现了环形队列,我这里就不再讲的那么细了,如果你想了深入了解一下,可以看看这篇:【C】循环队列(力扣622)
上面那张图给出的是逻辑结构,而真实的物理结构可以用顺序表,也可用链表,还可用别的,就不说那么多了,这里我就直接用顺序表了,上面给的链接中用的是定长的顺序表,这里也就用顺序表来表示了,只不过我直接用STL中的vector了。就不自己模拟实现一个了。
物理结构:
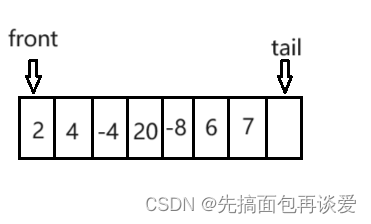
上面的逻辑结构和物理结构,都是空出来一个位置,方便判断队列是否已满,(tail + 1) % N 如果等于front就是满了,不等于就是没满。
但是今天我们用的信号量可以不需要空出来这一个位置。
基于环形队列的生产消费模型的原理
队列还是那个队列,不过这次是一个生产者和一个消费者在用这个队列。
先来个生产者不断生产的大致流程:
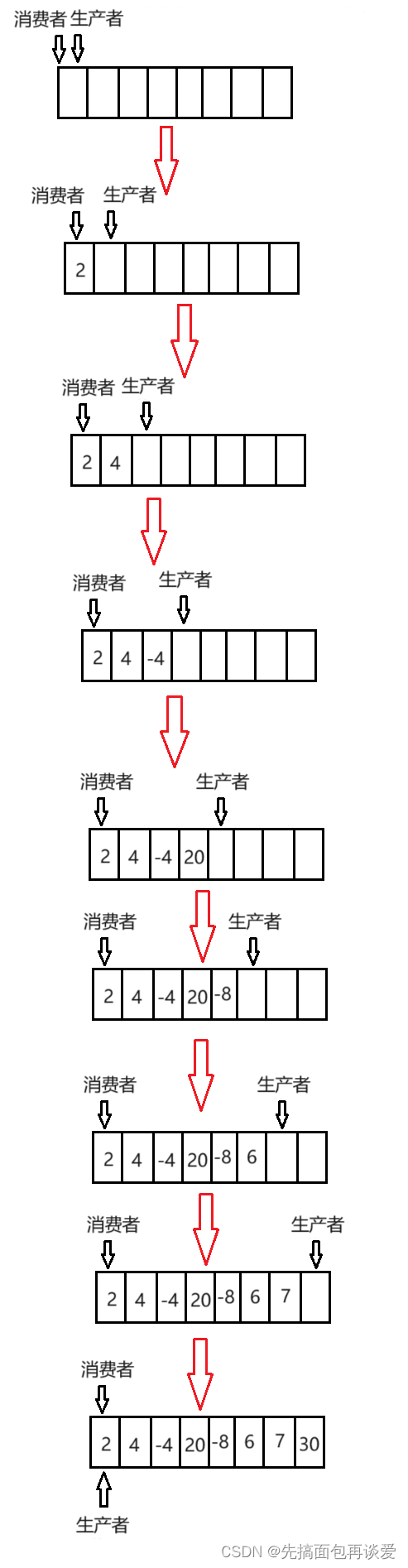
各位知道为什么最后可以让生产者和消费者指向同一块空间吗?
我先不说为啥,先来讲点概念。
生产者最关心的是空间资源,因为没有空间就无法生产数据,当生产数据的同时,空间也在减小。
消费者最关心的是数据资源,因为没有数据就无法消费数据,当消费数据的同时,空间也在增加。
而上面图中每个空格子就是空间,其中的数字就是数据。
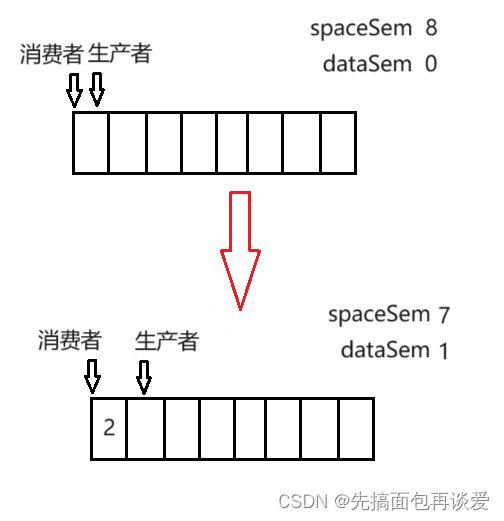
我们可以用一个计数器spaceSem来表示空间个数,用一个计数器dataSem来表示数据个数。
这里队列的总大小是8,那么spaceSem的初始值就是8,dataSem的初始值就是0。
生产者生产时,先申请空间资源,申请不到了就会阻塞,这是sem_wait本身所能保证的(下面我就用P来表示sem_wait,用V来表示sem_post了),当生产者线程申请到了信号量时,spaceSem就会减一,而减的这个一就是一个空格子,这个空格子就会被这个生产者线程所拥有,在这个空格子生产完后,这个空格子就不为空了,也就是说这个空格子被数据占有了,对应到上面买票的那个例子,就可以说空格子被数据占有了后就变成了无效空格(对于生产者而言的无效空格)。
P操作后要紧跟着V操作,但是这里不能对spaceSem进行V操作,因为V操作会使得spaceSem加一,而空格子数是减少了的,显然是错误的。但是数据个数增加了,所以说要对dataSem进行V操作。
看图:
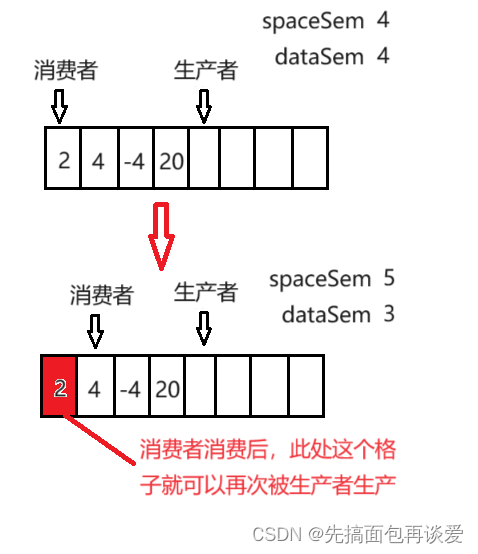
这就能对上了,空格子少一个,数据就多一个。不过也不能完全说空格子,因为会出现消费者消费的情况,有数据的格子被消费过后就不能再次被消费了,也就成了“空格子”,不过说成有效格子更好。来一个消费者消费的图:
再来看看队列数据装满后是啥样子的:
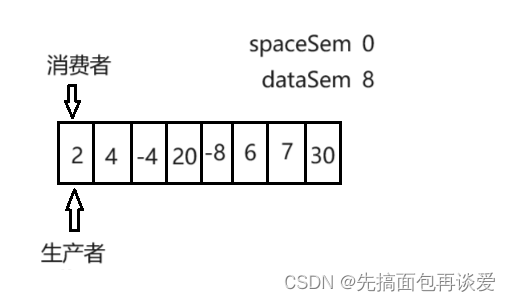
此时spaceSem为0,这样生产者在申请信号量的时候就会直接阻塞,因为spaceSem为0,无法继续减一操作。所以此时一定会让消费者线程执行消费。
再来看看空:
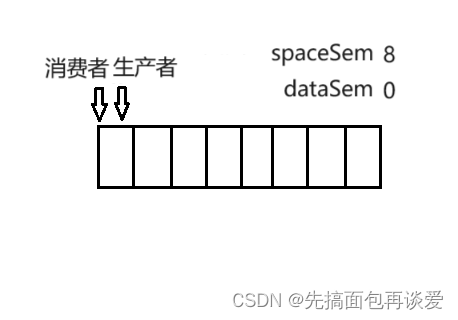
此时dataSem为0,这样消费者在申请信号量的时候就会直接阻塞,因为dataSem为0,无法继续减一操作。所以此时一定会让生产者线程执行生产。
故生产者消费者初始情况下的执行先后顺序不必关心,在逻辑上一定能让生产者先执行。因为若消费者先执行,那么就是上面这张图的情况。生产者先执行,那就直接生产。
代码演示
单生产者单消费者
先来说单生产者和单消费者的,大致思路:
定义一个类,类中成员变量有一个vector,一个capacity表示环形队列的大小,一个消费者位置的下标c_index,一个生产者位置的下标p_index,一个spaceSem信号量,一个dataSem信号量。大概就这么些,写出来大概就是这样:
先对信号量的几个操作封装一下:
// 对信号量的四个核心操作进行封装
class Sem
{
public:// 构造的时候就初始化信号量Sem(int val){sem_init(&_sem, 0, val);}// P操作void P(){sem_wait(&_sem);}// V操作void V(){sem_post(&_sem);}// 析构的时候就销毁掉信号量~Sem(){sem_destroy(&_sem);}private:sem_t _sem;
};
然后定义循环队列:
// 默认情况下的队列大小
const int DEFAULT_CAPACITY = 5;template<class T>
class RingQueue
{
public:RingQueue(int capacity = DEFAULT_CAPACITY): _rq(capacity) // 给顺序表开空间, _capacity(capacity) // 设置容量大小, _proIndex(0) // 生产者下标, _conIndex(0) // 消费者下标, _spaceSem(capacity) // 空间信号量,初始值为就是队列大小, _dataSem(0) // 数据信号量,初始值为0{}private:// 物理结构的循环队列std::vector<T> _rq;// 队列大小int _capacity;// 生产者下标int _proIndex;// 消费者下标int _conIndex;// 生产者所需信号量Sem _spaceSem;// 消费者所需信号量Sem _dataSem;
};
在往队列中Push的时候,先让生产者申请spaceSem信号量,也就是让spaceSem进行P操作,然后往p_index++处生产数据,然后再让p_index %= capacity(循环队列,若越界了%一下就回到开头了),最后让dataSem进行V操作。
队列Pop和Push同理,就不说了。
代码如下(放在RingQueue中):
// 生产者生产
void Push(const T& data)
{// 生产前先申请信号量,spaceSem减少_spaceSem.P();// 申请完信号量后就进行生产_rq[_proIndex++] = data;_proIndex %= _capacity;// spaceSem减少,dataSem增加 _dataSem.V();
}// 消费者消费
void Pop(T& data)
{// 消费前先申请信号量,dataSem减少_dataSem.P();// 申请完信号量后就进行消费data = _rq[_conIndex++];_conIndex %= _capacity;// dataSem减少,spaceSem增加 _spaceSem.V();
}
然后就是创建生产者线程和消费者线程:
void* Consumer(void* args)
{ /*这里用到了reinterpret_cast强转,不懂的同学可以点我下面给的博客*/RingQueue<int>* rq = reinterpret_cast<RingQueue<int>*>(args);// 消费者消费while(1){int data;rq->Pop(data);printf("[ %lu ] consumer get data ::%d\n\n", pthread_self(), data);}
}void* Productor(void* args)
{RingQueue<int>* rq = reinterpret_cast<RingQueue<int>*>(args);int data = 0;// 生产者生产while(1){rq->Push(data);printf("[ %lu ] productor send data ::%d\n", pthread_self(), data);++data;}
}int main()
{RingQueue<int>* rq = new RingQueue<int>(10);// 创建生产者消费者线程pthread_t c, p; /*这里用到了reinterpret_cast强转,不懂的同学可以点我下面给的博客*/pthread_create(&c, nullptr, Consumer, reinterpret_cast<void*>(rq));pthread_create(&p, nullptr, Productor, reinterpret_cast<void*>(rq));// 等待两个线程pthread_join(c, nullptr);pthread_join(p, nullptr);// delete掉rq,防止内存泄漏delete rq;return 0;
}
不太懂reinterpret_cast的同学,可以看我这篇博客:【C++】类型转换。
不过上面没有进行控制,打印会特别快,可以给生产者或消费者加sleep来控制一下。
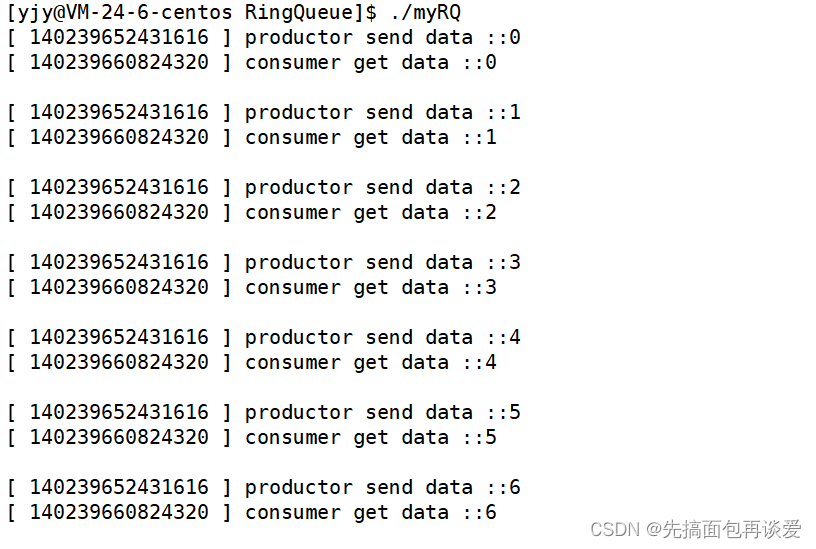
给生产者加sleep(1):

这里消费者更快,所以生产者生产一个就被消费者拿走一个。
运行:
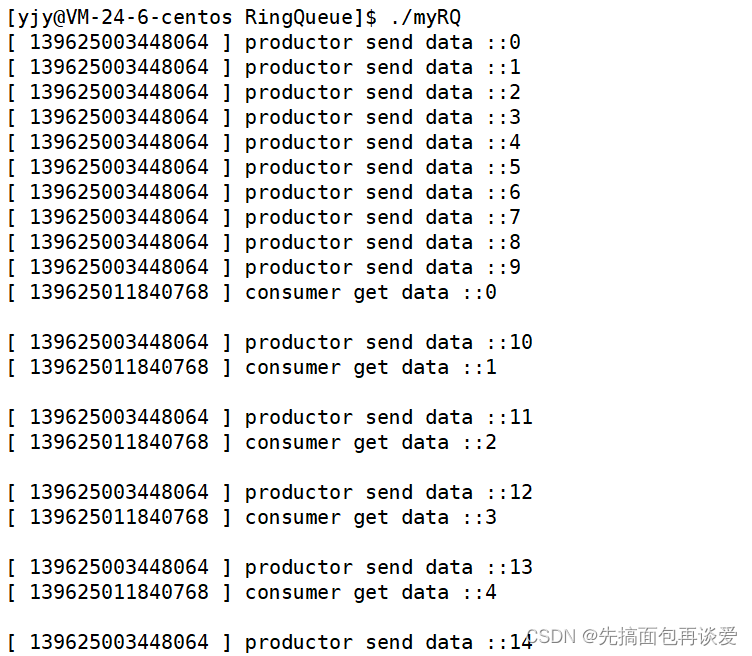
给消费者加sleep(1):
这里生产者更快,所以会先将队列生产满,然后消费者一秒消费一个,生产者跟着消费者的节奏就会一秒生产一个。
运行:
多生产者多消费者
上方的代码演示是单生产者和单消费者的,生生、消消、生消三种关系中只有生消的互斥和同步关系(如果有听不懂的同学,详看线程详解第三篇),而且信号量本身的性质就可以满足生消的同步和互斥的关系。
-
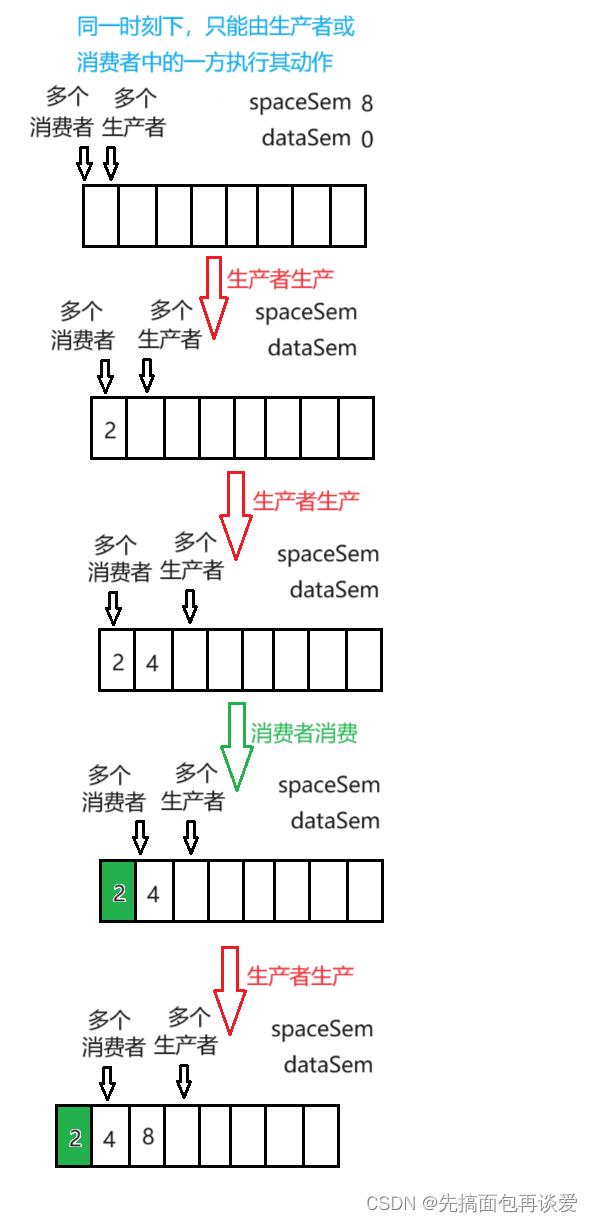
互斥体现在生产者和消费者同时指向同一块空间时,要么为空,要么为满。当为空时一定是生产者先,当为满时,一定是消费者先。
-
同步体现在,生产者生产后会是dataSem加一,消费者消费后会使spaceSem加一,只要一方执行其动作,另一方就能有新的资源。
但是此时多生产和多消费,就会多出两种关系,一种是生生间的互斥,一种是生消间的互斥。信号量无法保证者两种关系,那么就得要用互斥锁来保证这两种互斥关系。
用一把锁可以吗?
- 答案是不可以,因为一把锁会使得将整个队列看作一个整体,也就是说一次只能让生产者 / 消费者中的一个角色来对循环队列进行操作,但我们这里想让生产者和消费者同时都能执行,故可以用两把锁,一把锁锁住所有的生产者,一把锁锁住所有的消费者,把生产者和消费者分来锁。
一把锁会造成这样的情况:
但是两把锁可以让生产和消费同时进行:
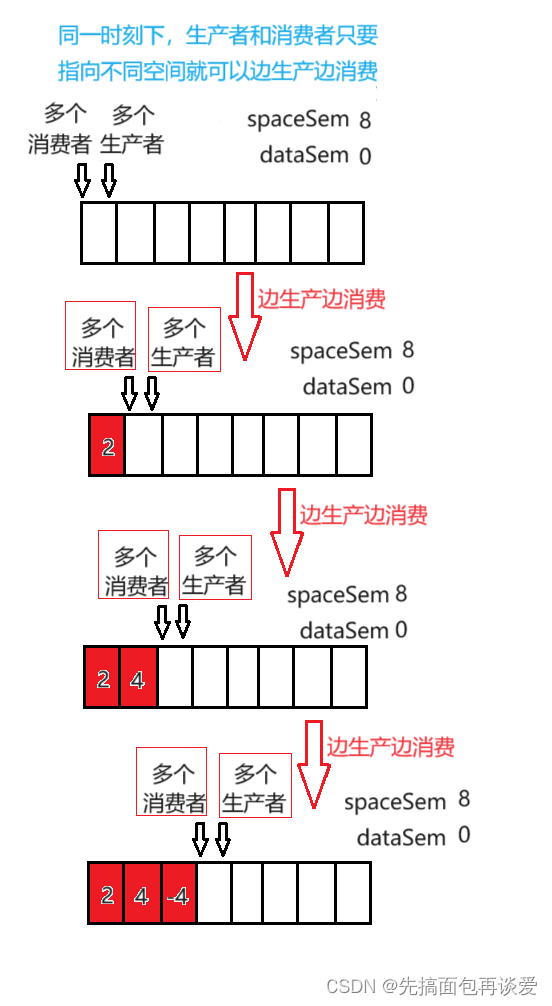
这样在进行Push操作的时候,就会使得所有的生产者之间互斥,也就是说一次只能有一个生产者push,而其他消费者还能进行Pop。Pop操作的时候,就会使得所有的消费者之间互斥,也就是说一次只能有一个消费者Pop,而其他生产者者还能进行Push。
不会出现当生产者和消费者指向不同位置的时候二者只能有一种角色进行操作。即二者指向不同位置的时候就不会造成生消互斥,生产者可以生产,消费者还可消费,同时进行,互不影响。
故可在RingQueue中加两把锁,一把锁锁生产者,一把锁锁消费者,在Push的时候用生产者的锁,在Pop的时候用消费者的锁。
下面的代码基于上面单生产和单消费来修改:
循环队列代码(信号量封装的Sem没变):
const int DEFAULT_CAPACITY = 5;template<class T>
class RingQueue
{
public:RingQueue(int capacity = DEFAULT_CAPACITY): _rq(capacity) // 给顺序表开空间, _capacity(capacity) // 设置容量大小, _proIndex(0) // 生产者下标, _conIndex(0) // 消费者下标, _spaceSem(capacity) // 空间信号量,初始值为就是队列大小, _dataSem(0) // 数据信号量,初始值为0{// 构造的时候对两把锁进行初始化pthread_mutex_init(&_proMtx, nullptr);pthread_mutex_init(&_conMtx, nullptr);}// 生产者生产void Push(const T& data){// 生产前先申请信号量,spaceSem减少_spaceSem.P();// 多个生产者一同Push的时候要上锁,让一个生产者生产pthread_mutex_lock(&_proMtx);// 申请完信号量后就进行生产_rq[_proIndex++] = data;_proIndex %= _capacity;// 单个生产者生产完毕后解锁pthread_mutex_unlock(&_proMtx); // spaceSem减少,dataSem增加 _dataSem.V();}// 消费者消费void Pop(T& data){// 消费前先申请信号量,dataSem减少_dataSem.P();// 多个消费者一同Pop的时候要上锁,让一个消费者消费pthread_mutex_lock(&_conMtx);// 申请完信号量后就进行消费data = _rq[_conIndex++];_conIndex %= _capacity;// 单个消费者消费完毕,解锁pthread_mutex_unlock(&_conMtx);// dataSem减少,spaceSem增加 _spaceSem.V();}~RingQueue(){// 析构的时候记得释放锁pthread_mutex_destroy(&_proMtx);pthread_mutex_destroy(&_conMtx);}private:// 物理结构的循环队列std::vector<T> _rq;// 队列大小int _capacity;// 生产者下标int _proIndex;// 消费者下标int _conIndex;// 生产者所需信号量Sem _spaceSem;// 消费者所需信号量Sem _dataSem;// 所有生产者的锁pthread_mutex_t _proMtx;// 所有消费者的锁pthread_mutex_t _conMtx;
};
创建多线程:
const int CONSUMER_NUM = 4;
const int PRODUCTOR_NUM = 2;void* Consumer(void* args)
{ /*这里用到了reinterpret_cast强转,不懂的同学可以点我下面给的博客*/RingQueue<int>* rq = reinterpret_cast<RingQueue<int>*>(args);// 消费者消费while(1){sleep(1);int data;rq->Pop(data);printf("[ %lu ] consumer get data ::%d\n", pthread_self(), data);}
}void* Productor(void* args)
{RingQueue<int>* rq = reinterpret_cast<RingQueue<int>*>(args);int data = 0;// 生产者生产while(1){rq->Push(data);printf("[ %lu ] productor send data ::%d\n", pthread_self(), data);++data;}
}int main()
{RingQueue<int>* rq = new RingQueue<int>();// 创建生产者消费者线程pthread_t c[CONSUMER_NUM];pthread_t p[PRODUCTOR_NUM]; for(int i = 0; i < CONSUMER_NUM; ++i){pthread_create(c + i, nullptr, Consumer, reinterpret_cast<void*>(rq));}for(int i = 0; i < PRODUCTOR_NUM; ++i){pthread_create(p + i, nullptr, Productor, reinterpret_cast<void*>(rq));}// 等待两个线程for(int i = 0; i < CONSUMER_NUM; ++i){pthread_join(c[i], nullptr);}for(int i = 0; i < PRODUCTOR_NUM; ++i){pthread_join(p[i], nullptr);}// delete掉rq,防止内存泄漏delete rq;return 0;
}
运行:
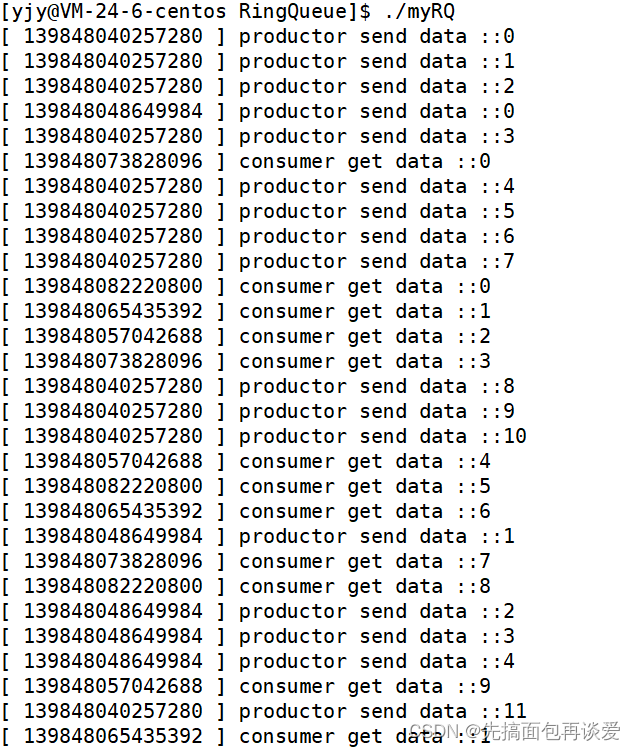
注意我代码中的Push和Pos将申请信号量放在了加锁之前,这样能够使所有在串行前的线程都预先的到其所需要的信号量资源,效率更高。如电影院里不会在电影放映前10~15分钟售票 + 检票,售票和检票放到一块排队效率太低了。我们正常情况下是先在app上买票,然后电影放映前10~15进行检票,此时无需再花买票的时间,买票和检票分开,耦合度降低,就会更节省时间。上面代码中申请信号量资源就买票,加锁即检票,故先申请信号量后加锁。
计数器的意义
前面说了信号量本质是一把计数器,这把计数器的意义是什么?
前面三篇线程的博客加上这篇的,一共有三种线程数据传递对临界资源的判断方式:
-
第一次进行线程间的数据传递,先进行加锁,但加锁后要用if判断临界资源是否准备就绪,若资源长时间没有准备就绪,会导致一个线程不断重复申请锁和释放锁,造成大量的时间浪费。
-
第二次进行线程间的数据传递时,用条件变量替换了if判断,这样会减少锁的申请和释放,比第一种方法稍微好一点,但还是需要检测临界资源是否准备就绪,没有就绪就会阻塞的等待,直到资源就绪了被其他线程唤醒。
-
第三次就是这里的信号量了,本篇的代码中,并没有进行直接进行临界资源就绪的判断,不过也做了,只是在锁外做的,前面两种方式都是要先申请锁,然后再判断资源是否就绪,最后再释放锁,根本原因是因为线程不知道临界资源的分配情况,所以必须要检测临界资源,但是信号量要提前预设资源的情况,而在PV操作的变化过程中,我们在任何地方都可以知晓临界资源的分配情况。
所以计数器的意义就是可以不用进入临界区就可得知资源的分配情况,甚至可以减少临界区内部的判断,未来在执行申请信号量时,即使阻塞了也是在锁外阻塞的,只要申请信号量成功了,那么拿到锁后就可以直接对临界资源进行操作,而不是等拿到锁后还要判断资源是否就绪,不就绪还要等待的情况。这样就能使得加锁区间尽量短,效率更高。
线程池
基本概念
池化技术,是一种资源预分配的技术。在我前面博客中我写过一个简单的进程池,本篇要写一个简单的线程池,虽然应该把线程池放到我后面的网络的博客中再讲的,不过既然学了线程了,稍微写写也没什么坏处。
池化技术,本质上是以空间换时间的计数,像STL库中的内存池,了解过的同学应该知道,就是以空间换时间,先开一大块内存,然后一点一点的分配,而不是需要一小块内存了再一小块一小块的开,后者效率比前要低,因为开空间这个动作也是有时间消耗的。
线程池就是先创建一批线程,当任务来的时候直接将任务分配给某一个线程,而不是等任务来的时候再创建线程。
说一下大致思路就写代码:
首先主线程负责派发任务(当然你也可以设置多个线程来派发任务),多个从线程负责接受任务并执行任务。这是不是就很像生产消费者模型,不是很像,是就是。
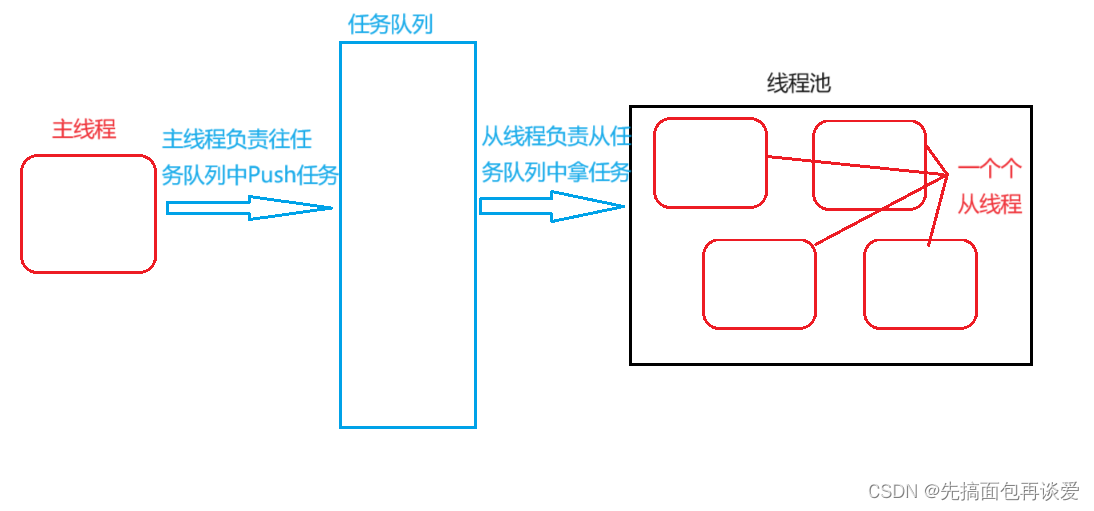
线程池中存放的就是从线程,主线程在线程池之外。
这样的话,就是单生产者多消费者,那么我们需要维护的关系就是消消的互斥和生消的同步与互斥。
代码
代码量有点大,我先给出运行结果:

代码有点多,我就不细讲了,这也花了我不少时间写的,讲起来太麻烦了,有不懂的同学可以评论区问,好几个文件:
Makefile就不给了,其他的给出来:
ThreadPool.hpp
#pragma once#include "Thread.hpp"
#include "LogMessage.hpp"
#include "lockGuard.hpp"
#include "caculator.hpp"#include <vector>
#include <queue>const int DEFAULT_SIZE = 5;template<class T>
class ThreadPool
{
private: // Routine专用接口// 获取锁地址pthread_mutex_t* _GetMTX(){return &_mtx;}// 获取生消信号量地址pthread_cond_t* _GetCond(){return &_cpCond;}// 判断任务队列中是否为空bool _IsEmpty(){return _taskQueue.empty();}T _GetTask(){T task = _taskQueue.front();_taskQueue.pop();return task;}// 非static函数会有this指针,这样在创建线程的时候函数指针pfunc会// 和非static函数不匹配,报错,所以要改为staticstatic void* Routine(void* args){// 获取到当前线程池的地址,因为Routine没有this指针,就无法拿到任务Thread_name_and_Args* tNA = reinterpret_cast<Thread_name_and_Args*>(args);ThreadPool<T>* pt = reinterpret_cast<ThreadPool<T>*>(tNA->_args);while(1){T task;{// 多个消费者获取任务先上锁LockGuard lg(pt->_GetMTX());// 上完锁判断是否有任务,没有任务就等while(pt->_IsEmpty()) pthread_cond_wait(pt->_GetCond(), pt->_GetMTX());// 此处一定可以获取任务task = pt->_GetTask();}task(tNA->_name);}}public:ThreadPool(int size = DEFAULT_SIZE): _size(size){// 锁和条件变量初始化pthread_cond_init(&_cpCond, nullptr);pthread_mutex_init(&_mtx, nullptr);// 线程池中创建线程for(int i = 0; i < _size; ++i){// 线程名字std::string name("Thread[");name += (std::to_string(i + 1) + ']');// 往线程池中加入线程 /*给ThreadData传this指针,不然Routine中线程拿不到任务*/_threadPool.push_back(new Thread(name, Routine, this));}}// 添加任务void PushTask(const T& task){// 生消互斥,先上锁LockGuard lg(&_mtx);_taskQueue.push(task);// 添加好任务就发送条件信号,让消费者消费pthread_cond_signal(&_cpCond);}// 启动所有线程void RunAllThread(){for(int i = 0; i < _size; ++i){_threadPool[i]->CreateThread();LogMessage(0, _F, _L, "%s启动成功", _threadPool[i]->getName().c_str());}}// 析构,附加等待线程~ThreadPool(){for(int i = 0; i < _size; ++i){_threadPool[i]->JoinThread();delete _threadPool[i];}pthread_mutex_destroy(&_mtx);pthread_cond_destroy(&_cpCond);}
private:// 线程池std::vector<Thread*> _threadPool;// 线程池大小int _size;// 任务队列std::queue<T> _taskQueue;// 消消锁和生消锁pthread_mutex_t _mtx;// 生消条件变量pthread_cond_t _cpCond;
};
calculator.hpp
#pragma once#include <functional>
#include <vector>
#include <string>
#include "LogMessage.hpp"typedef std::function<int(int, int)> func;std::vector<std::pair<char, func>> kv;class Calculator
{
public:Calculator(){}Calculator(int x, int y, func fun, int index): _x(x), _y(y), _fun(fun), _index(index){}void operator()(const std::string& name){// 执行任务LogMessage(NORMAL, _F, _L, "%s 执行任务 :: %d %c %d = %d", name.c_str(), _x, kv[_index].first, _y, _fun(_x, _y));}public:int _x;int _y;func _fun;int _index;
};void loadCal()
{func MyAdd = [](int x, int y){ return x + y; };func MySub = [](int x, int y){ return x - y; };func MyMul = [](int x, int y){ return x * y; };func MyDiv = [](int x, int y){ return x / y; };kv.push_back(std::pair<char, func>('+', MyAdd));kv.push_back(std::pair<char, func>('-', MySub));kv.push_back(std::pair<char, func>('*', MyMul));kv.push_back(std::pair<char, func>('/', MyDiv));
}
lockGuard.hpp
#pragma once#include <pthread.h>class LockGuard
{
public:LockGuard(pthread_mutex_t* pmtx):_pmtx(pmtx){pthread_mutex_lock(_pmtx);}~LockGuard(){pthread_mutex_unlock(_pmtx);}public:pthread_mutex_t* _pmtx;
};
LogMessage.hpp
#pragma once
#include <cstdio>
#include <vector>
#include <ctime>
#include <cstdarg>
#include <unistd.h>
#include "LogMessage.hpp"// 文件名
#define _F __FILE__
// 所在行
#define _L __LINE__enum level
{DEBUG, // 0NORMAL, // 1WARING, // 2ERROR, // 3FATAL // 4
};std::vector<const char*> gLevelMap = {"DEB","NOR","WAR","ERR","FAT"
};#define FILE_NAME "./log.txt"// 格式化打印日志信息
void LogMessage(int level/*日志等级*/, const char* file/*文件名*/, int line/*所在行*/, const char* format, .../*自定义格式*/)
{// 选择性打印等级为DEBUG的信息,编译的时候加上命令行定义NO_DEBUG就不会打印DEBUG信息
#ifdef NO_DEBUGif(level == DEBUG) return;
#endif// 固定格式char FixBuffer[128];time_t tm = time(nullptr); // 获取时间戳// 日志级别 时间 哪一个文件 哪一行snprintf(FixBuffer, sizeof(FixBuffer), "---------------------------------------<%s> |%s|->%d\n%s", \gLevelMap[level], // 等级file, // 文件名line, // 所在行ctime(&tm) // 时间戳转正常时间);// 用户自定义格式char DefBuffer[128];va_list args; // 定义一个可变参数va_start(args, format); // 用format初始化可变参数vsnprintf(DefBuffer, sizeof DefBuffer, format, args); // 将可变参数格式化打印到DefBuffer中va_end(args); // 销毁可变参数// 往显示器打printf("%s%s\n_______________________________________\n", FixBuffer, DefBuffer);// 往文件中打// FILE* pf = fopen(FILE_NAME, "a");// fprintf(pf, "%s%s\n\n", FixBuffer, DefBuffer);// fclose(pf);
}
Thread.hpp
#ifndef __THREAD_HPP__
#define __THREAD_HPP__#include <iostream>
#include <string>typedef void*(*pfunc)(void*);#include <pthread.h>// 封装线程名称和线程回调函数的参数
class Thread_name_and_Args
{
public:Thread_name_and_Args(const std::string& name, void* args): _name(name), _args(args){}
public:std::string _name;void* _args;
};// 线程接口的封装
class Thread
{
public:Thread(const std::string& name, pfunc func, void* args): _NA(name, args), _func(func){}// 创建线程void CreateThread(){pthread_create(&_tid, nullptr, _func, &_NA);}// 等待线程void JoinThread(){pthread_join(_tid, nullptr);}const std::string& getName()const{return _NA._name;}~Thread(){}private:pthread_t _tid; // 线程idThread_name_and_Args _NA; // 线程名称和回调函数参数pfunc _func; // 回调函数的指针
};
#endif
test.cc
#include "LogMessage.hpp"
#include "Thread.hpp"
#include "ThreadPool.hpp"
#include "caculator.hpp"#include <unistd.h>int main()
{srand((unsigned int)time(nullptr));loadCal();ThreadPool<Calculator>* tp = new ThreadPool<Calculator>();// 主线程创建所有从线程tp->RunAllThread();// 主线程派发任务while(1){sleep(1);int x = rand() % 200 + 1;int y = rand() % 100 + 1;int index = rand() % 4;LogMessage(NORMAL, _F, _L, "主线程派发任务 :: %d %c %d = ?", x, kv[index].first, y);tp->PushTask(Calculator(x, y, kv[index].second, index));}// 析构就会等待线程delete tp;return 0;
}
前面也说了,这里的线程池应该放到后面的网络再讲的,所以这里的线程池只是一个简单的任务分发,没有什么经过网络接收任务啥的,比较简陋,不过新手想搞懂也得花点时间的。
单例模式
关于单例模式,我前面有一篇博客讲过了,不过是在C++的博客中讲的,那时候还没写关于线程的博客,这里再讲单例模式就是为了和线程结合一下,但是不会再细说了,只是把线程池中的代码改成单例模式的,如果想要了解单例模式的话可以看我这篇:【C++】特殊类的设计。
单例模式有两种,一种是饿汉模式,一种是懒汉模式,其中懒汉模式有线程不安全问题,这里我就用懒汉模式来修改一下上面的线程池,并对懒汉模式进行优化,变为线程安全的懒汉。
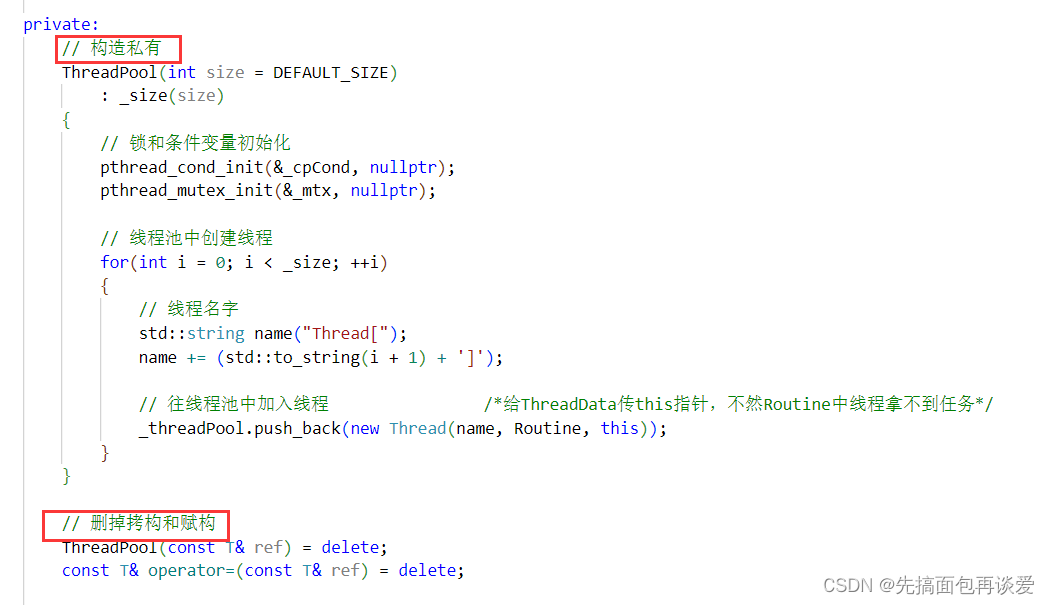
其实上面的线程池就可以说是单例模式了,整块代码下来就创建了一个线程池对象,但是仅凭这一点也不能说是单例,因为还可以再创建对象或者拷贝对象,这两点不能满足。所以需要把这两点也加上。代码中要改的地方不多。
对于ThreadPool做的第一步工作:
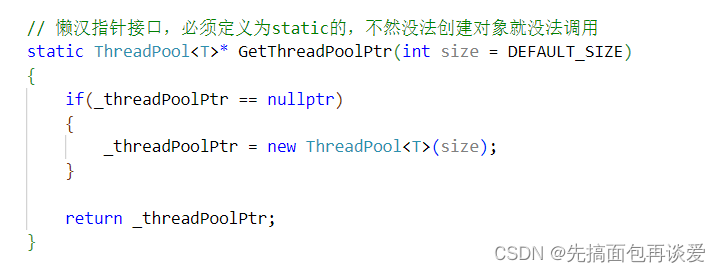
然后创建一个静态的指针:

然后再提供一个接口来为这个指针初始化和获取这个指针:
然后再改一下主线程部分:

这样就是一个懒汉模式,运行:

其实运行结果就和上面的一样。
还可以不保存类中的那个指针,直接用静态的接口去调用类中的函数:
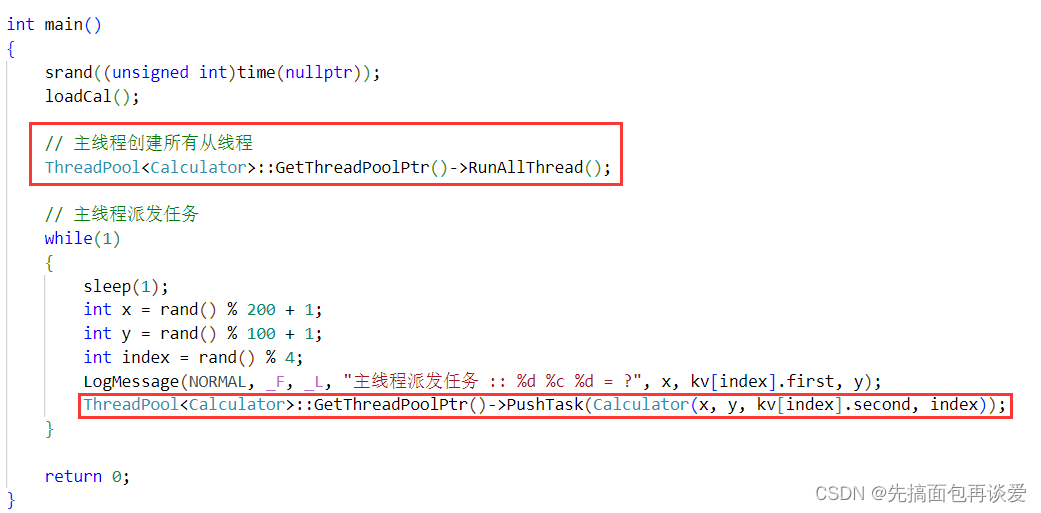
也可以的。
但是因为只有一个主线程,这里的场景不会造成线程不安全的问题,但是当多个线程同时调用懒汉模式下的接口时就会出问题,再来看一下这个接口:
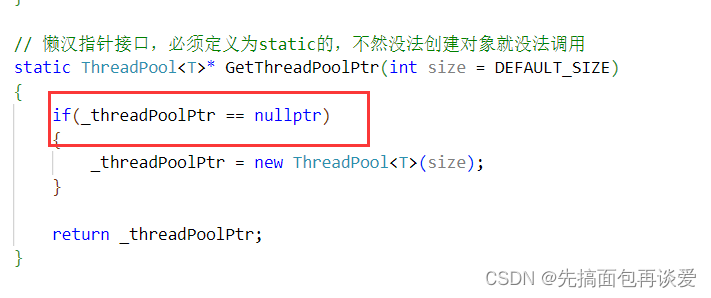
此处的判空是有问题的,因为这里没有加锁,当多个线程同时进入时,可能一个线程进入了if中但是_threadPoolPtr还没修改,但此时多个线程就已经判断了_threadPoolPtr为空了,那么就会有多个线程同时进到if中,这样问题就大了,因为多个线程都会执行new操作,但是最终只会有一个new出来的空间被_threadPoolPtr所指,剩下new出来的空间就找不到了,进而就导致了内存泄漏。
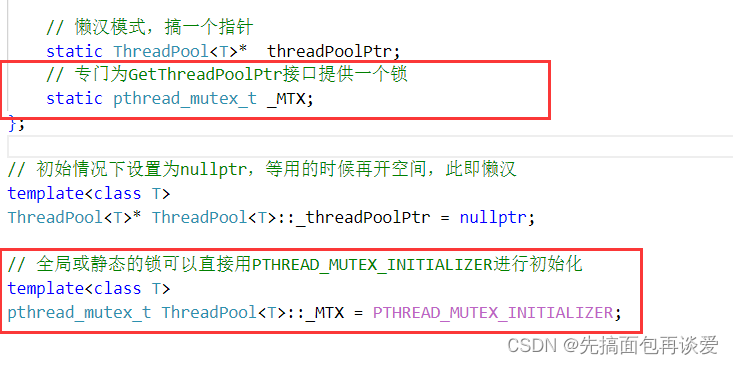
所以说我们要把这里改一改,加个锁:
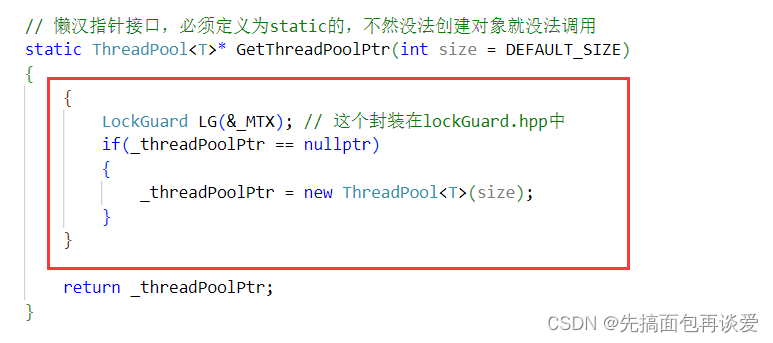
但是此时还有问题,只要该接口被调用了,调用其的线程都必须要执行一次加锁和解锁的操作,这样就算_threadPoolPtr开了空间,还是会进行判断,效率就会很低。
所以还得优化优化:
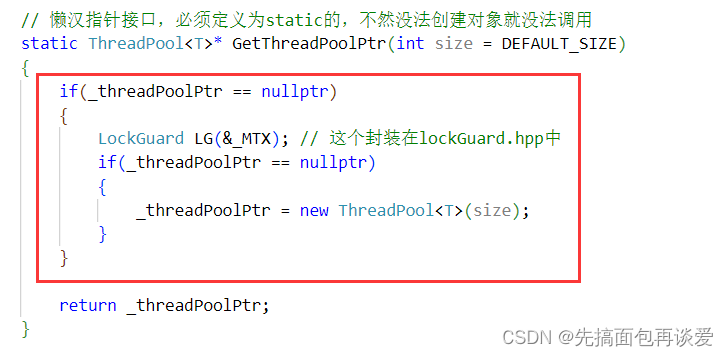
再套上一层if判断,如果不为空,就不会再进行加锁了,也是只有第一次为空的时候会出现多个线程申请锁的情况,剩下的情况都不会申请锁,这样效率就高多了。
STL,智能指针和线程安全
STL中的容器是否是线程安全的?
不是。
原因如下:
- STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全, 会对性能造成巨大的影响,而且对于不同的容器, 加锁方式的不同, 性能可能也不同(例如hash表的锁表和锁桶)。
因此 STL 默认不是线程安全. 如果需要在多线程环境下使用, 往往需要调用者自行保证线程安全
智能指针是否是线程安全的?
-
对于 unique_ptr, 由于只是在当前代码块范围内生效, 因此不涉及线程安全问题。
-
对于 shared_ptr, 多个对象需要共用一个引用计数变量, 所以会存在线程安全问题. 但是标准库实现的时候考虑到了这个问题, 基于原子操作(CAS)的方式保证 shared_ptr 能够高效, 原子的操作引用计数。
其他常见的各种锁
- 悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
我们前面讲的锁都是悲观锁。 - 乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。
这里的乐观锁和下面的CAS操作在JAVA中讲的更多一点,这里就不详细解释啥了。
- CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
自旋锁,公平锁,非公平锁。
说说自旋锁。
其和我们前面悲观锁的区别就一点,会进行轮询检测。先不说是干啥的。
先来讲个小例子:
假如你朋友家跟你家不在一块,你去TA家楼下找TA,叫TA出去玩。两种场景:
第一种:
此时TA说TA不能去,因为TA妈妈让TA写作业,但TA得一个小时才能写完,你俩约定好一个小时候再在TA家楼下集合,此时有一个小时的时间,你会干什么?应该不会站在TA家楼下干等着吧。或许你会先找个网吧坐一会或者去奶茶店买杯奶茶啥的,反正这一个小时就是在等TA。
第二种
TA说等TA几分钟,TA正在吃饭,吃完了马上就下来,你答应了,此时你应该是直接在TA家楼下等就行,不会说再跑去网吧或者买奶茶了吧,跑到半路有可能人家就下来了。三分钟后,你问TA好了没,TA说再等几分钟,马上就好,你又答应了,继续等。又过了一分钟,你问好了没,TA又说马上,你又打答应了,又过了……
第一种方式,等的时间比较长,你就会决定去网吧或奶茶店休息去。
第二种方式,你是直接在人家楼下等,过一段时间问一下好了没,没好久再过一段时间问一下,知道人家好了。
那么第二种就是轮询检测,不断地去询问资源是否准备就绪,而不是进阻塞队列中干等。这就是自旋锁。
其实和悲观锁差不了多少,也不是什么重点,就说说其接口:
初始化和销毁的
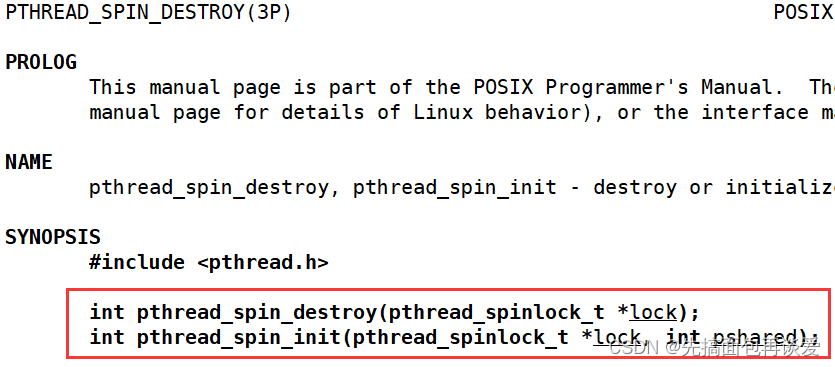
上锁的
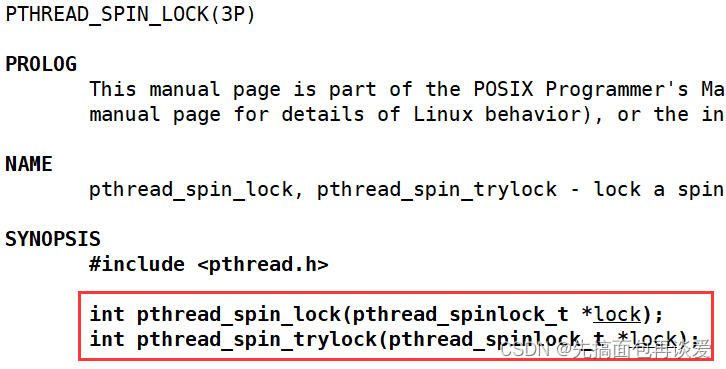
解锁的
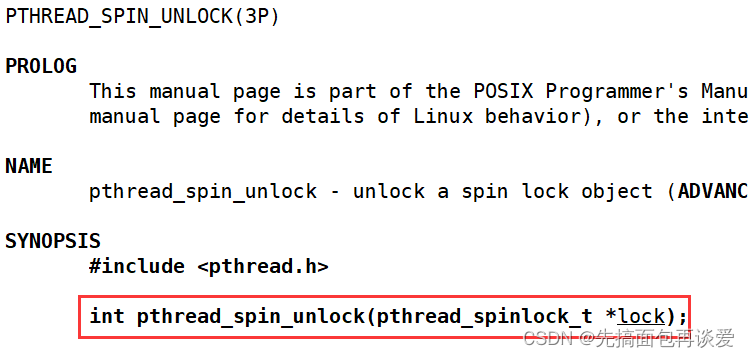
其实就和互斥锁的接口差不多,用起来只是吧mutex换成spin就行了。
读者写者问题
读写锁
在编写多线程的时候,有一种情况是十分常见的。
那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。
通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低我们程序的效率。
那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有,那就是读写锁。
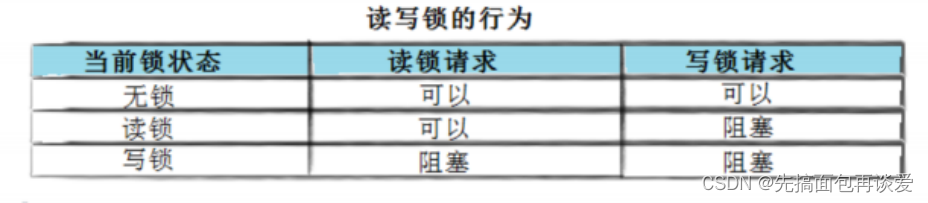
其实读写锁这里也遵循321原则(321原则不懂的同学,在我的第三篇中)。
三种关系:读读(共享)、写写(互斥)、读写(同步与互斥)。
两种角色:读者和写者。
一种交易场所:某种数据结构。
说一下读写者问题和生消模型的本质区别:
消费者会取走数据,但读者不会。
当有读者在读的时候,写者不能写,读者会有一个计数器来统计当前读者人数,每次读前都要使该计数器加一,读后都要使该计数器减一,且加一和减一都要使原子的。
大致流程如下:

所以总体看来是读者优先的。当读写同时开始执行时,必须让读者先读。但是这样可能会导致写者饥饿问题,因为可能会有读者不断在读,此时写者就会一直得不到资源,从而无法进行写操作。
但是也可设置写者优先,当读写同时开始执行,必须让写者进行,如果后续有读者要读,则必须要等写者写完后才能进去读。
接口介绍
初始化和销毁

上锁分两种:
上写锁
上读锁
解锁只有一种,读锁和写锁都能解:
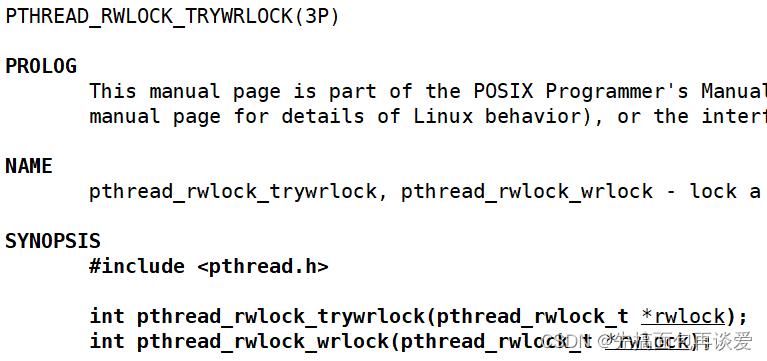
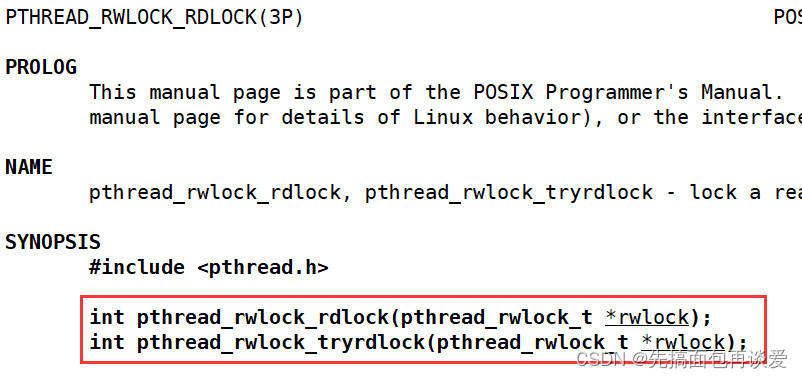
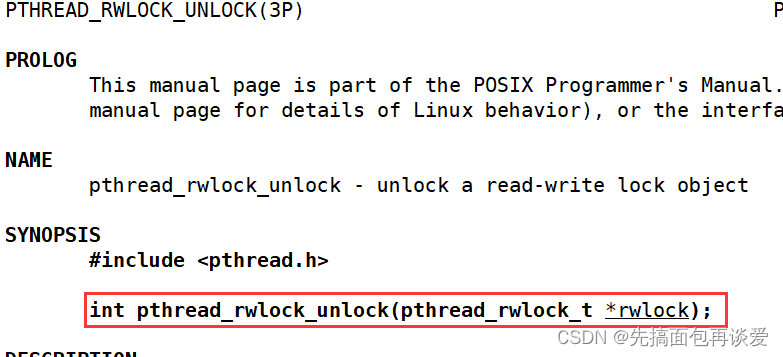
这里就不展开讲了。
到此结束。。。