学习目标:
在上一篇博客中,我们已经详细地学习了字符分类函数、字符转换函数和内存函数。那这一篇博客和上一篇博客的关系不是那么相连。
这一篇博客主要介绍一下自定义类型,因为在解决实际问题时,由于世界上的因素有很多,我们需要建立不同的数据类型来描述这些变量,但是C语言本身创立的类型不是很多,所以需要我们用户自己根据需求进行创建,于是就有了这一篇博客!
学习内容:
通过上面的学习目标,我们可以列出要学习的内容:
- 结构体的相关知识
- 结构体的内存对齐
- 结构体实现位段
- 枚举的相关知识
- 联合的相关知识
一、结构体的相关知识
1.1 结构的基本知识
通俗来讲,结构是一些值的集合,这些值称为结构成员。读者们看到这句话是不是似曾相识啊,在前面的数组这一章,我们讲过数组的概念——是一些相同类型的值的集合。小编在这里提一嘴,是因为数组存放的值和今天我们讲述结构体存放的值是不一样的。结构体的成员可以是不同类型的变量,一定要区分清楚!
因为在结构体中,我们也可以放置相同类型的值的集合;而数组只能放置相同类型的值的集合。我们要好好利用结构体来解决实际生活中的问题。
1.2 结构体的声明
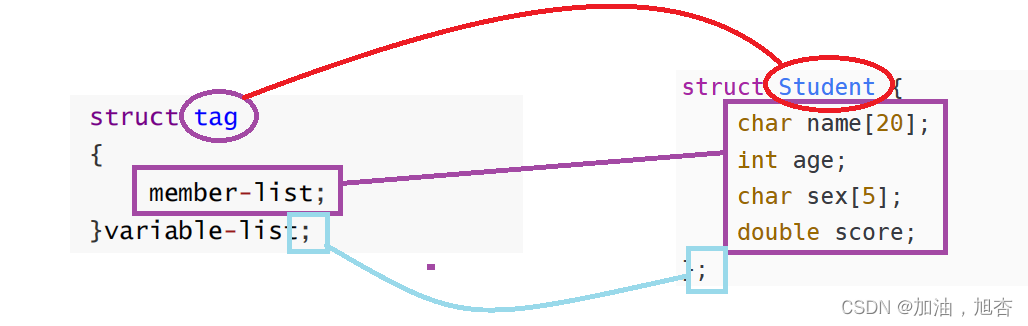
1.2.1 结构体的内容介绍

在上图中,我们介绍了结构体类型中的各个位置的含义和概念,下面,我们来自己设计一个学生的结构体类型:
struct Student {char name[20];int age;char sex[5];double score; };
1.2.2 结构体是如何创建变量
定义完结构体类型后,这就相当于又创建了一个数据类型,我们可以根据这个数据类型来创建一个或多个结构体变量,同时也可以创建一个结构体数组,这和基本数据类型大差不差。接下来,我们就来创建结构体变量:

1.2.3 利用typedef简化类型名字
你们会不会因为结构体类型的名字比较长,而觉得很不方便,我们可以利用 typedef 来进行对类型的重命名:下面,我们来看一个例子:

1.3 特殊的声明
1.3.1 匿名结构体的概念和代码
这个声明就像标题所说的一样,是有点特殊的,也是不常用的。我们在进行编写代码时,在设计结构体时,可以进行不完全的设计声明。因为编写结构体时没有给出相应的名字,所以这种设计的结构体叫做匿名结构体。具体例子我们看下面:
//匿名结构体类型
struct{int a;char b;float c;
}b;1.3.2 匿名结构体和普通结构体的区别
为了便于理解,我们在进行匿名结构体类型与普通结构体类型之间的区别(如下图):

1.3.3 有关匿名结构体的一道题目
在了解完上面匿名结构体的概念后,我们来看这么一道题:
//匿名结构体类型 struct {int a;char b;float c; }b; struct {int a;char b;float c; } *p;上面两个结构体在声明的时候省略掉了结构体标签tag。那么请问:
//在上面的代码基础上,下面的代码合法吗? p = &b;
答案:
警告: 编译器会把上面的两个声明当成 完全不同的两个类型 ,所以是非法的。
1.3.4 匿名结构体的使用场景
说实话,这个匿名结构体的使用次数应该要很少,他的使用场景只有在使用一次之后就不在使用,之后永远不在使用。
1.4 结构体的自引用(错误)
1.4.1 介绍结构体自引用
在讲结构体之前,我们来了解一下数据结构。数据结构有:线性表、栈和队列、串(KMP)、数与二叉树、图、查找、排序。(在之后的笔记中,我也会详细地写出数据结构)。
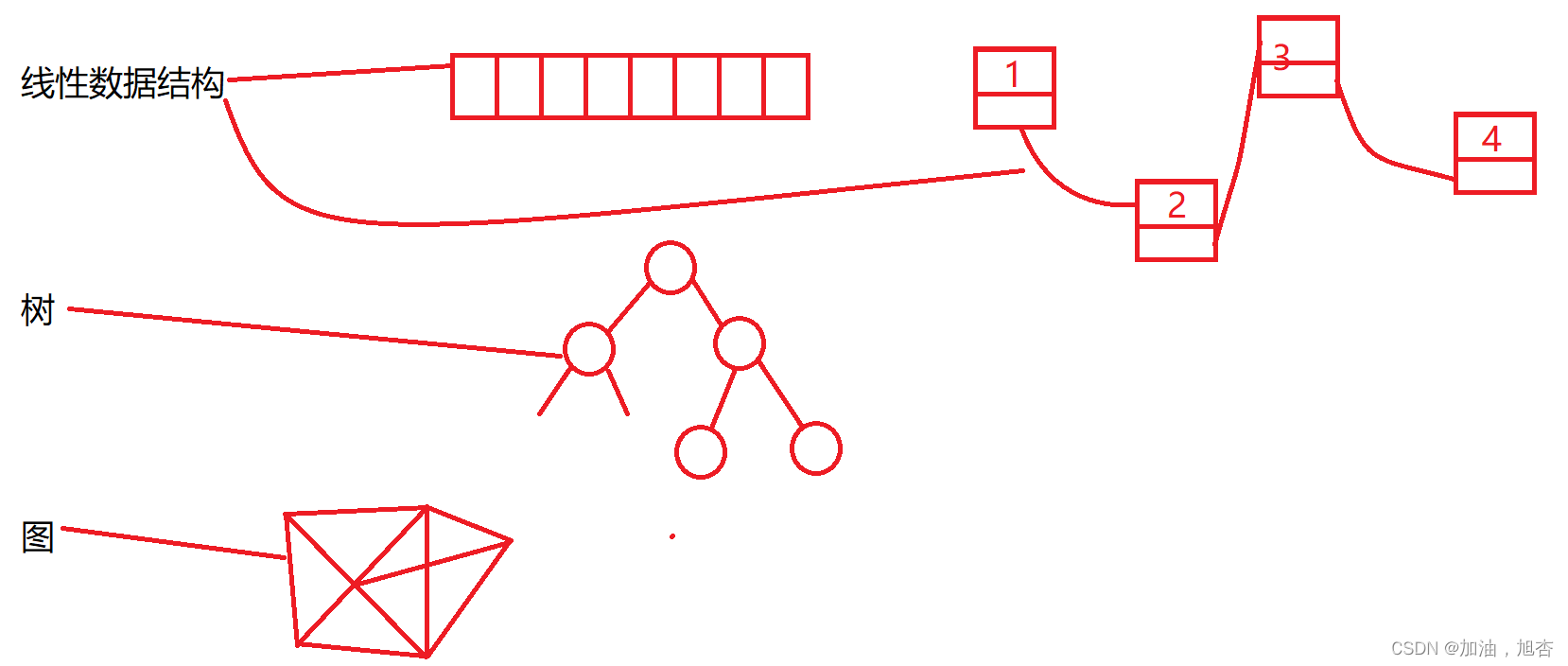
在数据结构中,我们线性表中的链表与结构体的自引用有一定的关系。正如标题所示那样,结构体的自引用是错误的,而真正正确的是链表的写法。
错误的写法:
正确的写法:
在链表中,我们的数据不同于数组一样是连续的放在一起,而链表是将数据不连续的放在内存空间中,我们怎么找到下一个结点呢?在内存中,每一个数据都有一个自己的地址,我们如果将下一个结点的地址存在这一个结点中,就能找到下一个结点。
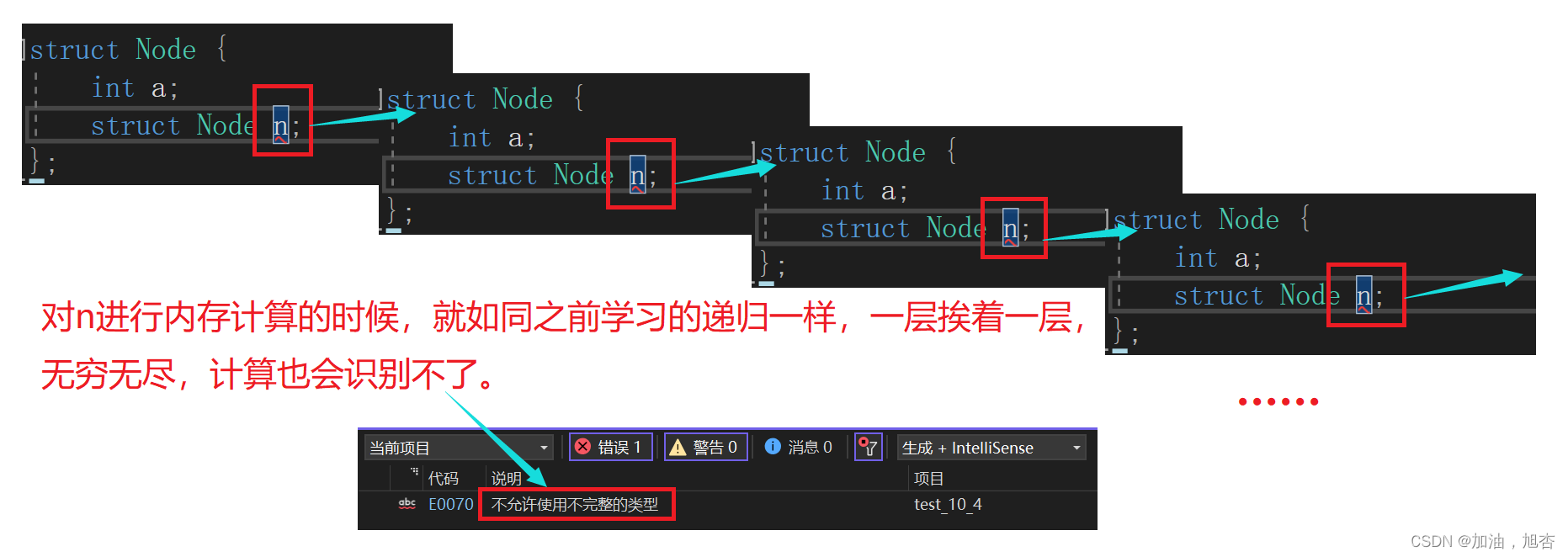
1.4.2 结构体自引用的一些问题
问题:
typedef struct{int a;Node* n; }Node; //这样写代码,可以吗?答案:
显然是错误的,这是一个先有鸡还是先有蛋的问题。原因在于这个结构体在创立的时候,还没有来得及给其重命名,就已经有了重命名后的指针,所以是错误的。
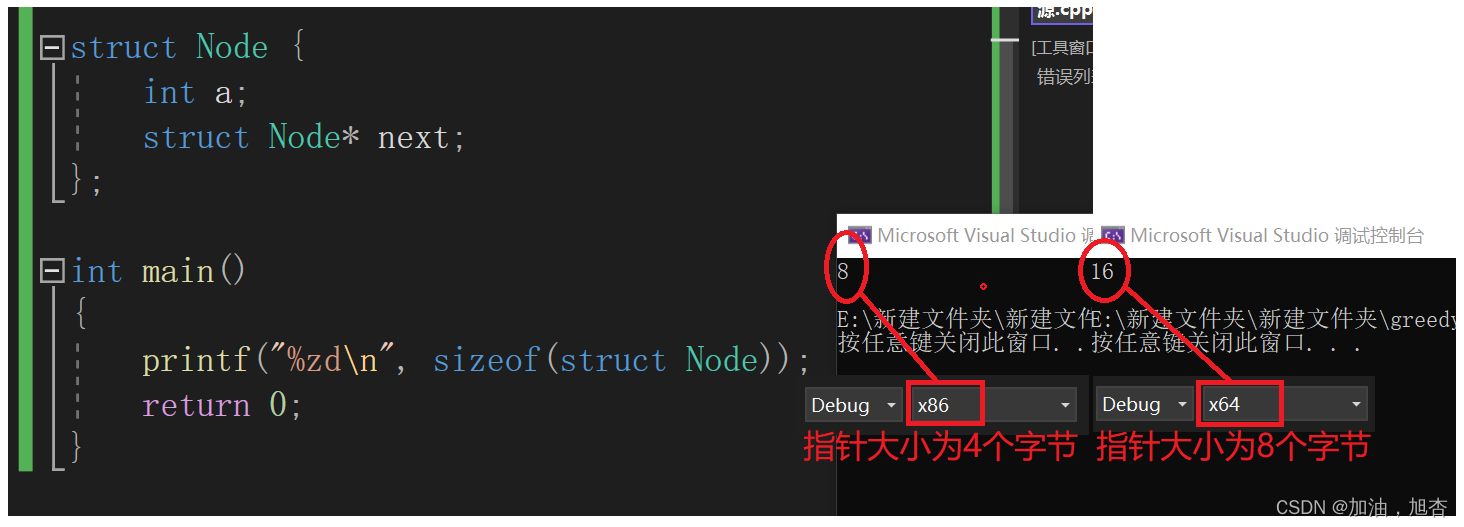
改进方法:
typedef struct Node {int a;struct Node* next; }Node;
1.5 结构体变量的定义和初始化
在标题为1.2.2中,我们讲述了如何创建结构体的全局变量和局部变量。那么接下来,我们来简单介绍一下初始化。说起初始化,想必大家都不陌生,在之前的课程中,我们就会对基本结构数据类型进行初始化。
第一种写法:
struct Point {int x;int y; }p1 = { 1,2 }; //声明类型的同时定义变量p1,并初始化p1第二种写法:
//初始化:定义变量的同时赋初值。 int x = 20; int y = 40; struct Point p3 = { x, y };第三种写法:
struct Stu //类型声明 {char name[15];//名字int age; //年龄 }; //我们可以使用下面这一种方法,不用按照顺序进行初始化 struct Stu s1 = { .age = 19, .name = "hskod" };
下面,我们来介绍一下结构体的嵌套使用:
struct Node
{int data;struct Point p;struct Node* next;
}n1 = { 10, {4,5}, NULL }; //结构体嵌套初始化
struct Node n2 = { 20, {5, 6}, NULL };//结构体嵌套初始化1.6 结构体内存对齐
1.6.1 引出offsetof
在这之前,我们先来写一段前言用于激发读者思考!我们来看下面这两个结构体大小的对比,先来预告一波:结构体的内存对齐与结构体时候如何计算内存大小是有关。看下图:
struct Stu1 {int a;char c1;char c2; };struct Stu2 {char c1;int a;char c2; };在这两个结构体中,所有的变量都是一样的,只有变量的顺序是不一样的,这种顺序会造成结构体的内存大小是不同。为什么呢?这就和下面要介绍的内存对齐有关!

为了便于更好地理解这一现象,我们来引出一个宏:offsetof。这个宏的作用是:此具有函数形式的宏返回数据结构或联合类型类型中成员成员的偏移值(以字节为单位)。返回的值是类型为 size_t 的无符号整数值,具有指定成员与其结构开头之间的字节数。
举个例子:


1.6.2 结构体的内存对齐讲解
1.7 修改默认对齐数
1.8 结构体传参
学习产出:
- 结构体的相关知识
- 结构体的内存对齐
- 结构体实现位段
- 枚举的相关知识
- 联合的相关知识