诸神缄默不语-个人CSDN博文目录
最近更新时间:2023.6.16
最早更新时间:2023.1.5
有些内容附带了相应的超链接作为可参考资料,有些没有。很多内容可以参考我的其他博文,其中有一部分链接我也会挂到这里来。
文章目录
- 正文
- 1. ML基础
- 2. DL通用基础
- 3. 主要用于NLP的DL基础
- 4. GNN和图论
- 5. KG
- 6. W3C规范
- 7. 时间序列分析
- 8. CV
- 9. 其他CS相关
- 10. 其他数学
- 11. 其他术语
- 12. 常用专业工具
- 本文撰写过程中使用的参考资料
- 其他补充阅读资料
正文
感觉不是MECE的分类,但是算了差不多就这样,建议用Ctrl+F
1. ML基础
- 有监督supervised / 无监督unsupervised / 半监督semi-supervised(弱监督) / 自监督self-supervised
半监督:对未标注的样本生成伪标签
自监督:A Cookbook of Self-Supervised Learning - 分类
- 多分类multi-class
- 多标签multi-label
- 极限多标签文本分类XMTC(NLP课题入门 | 极限多标签文本分类 NLP课题入门 | 极限多标签文本分类 NLP课题入门 | 极限多标签文本分类)
- 情感分析
我说这是NLP界最火(指最卷)的研究课题,应该没什么问题吧- aspect-based sentiment analysis (ABSA) 基于方面的情感分析

对这一课题的介绍和图片来源:方面情感分析-Recurrent Attention Network - 知乎
- aspect-based sentiment analysis (ABSA) 基于方面的情感分析
- 虚假新闻检测(NLP课题入门 day 4 虚假新闻检测)
- 异常检测anomaly detection
- 回归
- Generalized Linear Models (GLMs)
- Generalized Additive Models (GAMs)
- 线性回归模型
- 多重共线性
- 向前选择法forward selection
向前选择法_百度百科
- 排序rank
感觉推荐系统、搜索引擎、信息抽取/检索方面会用得比较多- 指标
Ranking算法评测指标之 CG、DCG、NDCG - 知乎- CG
- DCG
- NDCG
- 指标
- 特征工程 特征工程/数据预处理超全面总结(持续更新ing…)
- generative / discrimination
- 支持向量机SVM
- K近邻分类KNN
- 多标签分类的模型
- 对于标签数的选择:要么直接设定一个超参(top-k),要么设定概率阈值,要么将所有标签分别作为一个二分类任务、然后设定二分类的概率阈值,要么专门做一次number learning任务(一层神经网络)
基于法条外部知识的法条推荐这篇用多种表征来进行二分类,缓解阈值选取造成的性能损失 - Label Powerset:非常直觉的……直接把多标签重新组合成多分类任务的标签集(暴力出奇迹)
- ML-KNN
数据科学实战系列之ML-KNN(一)_mlknn_明曦君的博客-CSDN博客
- 对于标签数的选择:要么直接设定一个超参(top-k),要么设定概率阈值,要么将所有标签分别作为一个二分类任务、然后设定二分类的概率阈值,要么专门做一次number learning任务(一层神经网络)
- graphical model
- 隐马尔科夫模型HMM(隐马尔科夫模型HMM)
- 条件随机场CRF(条件随机场CRF(持续更新ing…))
- 朴素贝叶斯分类器NBC(朴素贝叶斯Naive Bayesian分类器 (NBC) )
- 关联规则
- Welcome to Orange3-Associate documentation! — Orange3-Associate documentation
- 粒子优化算法PSO
- 损失函数可参考这篇:机器学习/深度学习中的常用损失函数公式、原理与代码实践(持续更新ing…)
- 留一法 / leave one out (LOO)
- 模型融合model fusion
- stacking:将数据分成N折,每个基模型学习其中N-1折数据
- bagging
- boosting
- GBDT
- 随机森林
- XGBoost
- LightGBM
- CatBoost
- 聚类
- K均值K-Means
手肘法:通过SSE骤降的拐点选择K值(目测法) kmeans的手肘法_Petyon的博客-CSDN博客 - 谱聚类 A Tutorial on Spectral Clustering
- K均值K-Means
- 归一化 / 正则化
- 最大最小规范化min-max scalar
- Z Score正则化
- batch normalization
- layer normalization
- dropout(也被认为是传统的神经网络随机删减方法)
- 深度学习中的trick | 先BN后dropout:同时使用有争议
- 数据不平衡问题imbalance
2. DL通用基础
- 全连接前馈神经网络FFNN / 多层感知机MLP
- 卷积神经网络CNN
- 循环神经网络RNN(都可以双向Bi-)
- LSTM
- GRU
- 关系RNN
Relational recurrent neural networks
讲解博文:DeepMind提出关系RNN:记忆模块RMC解决关系推理难题 | 机器之心
- 回声状态网络 (echo state network,ESN)
- 回声状态网络(echo state network,ESN)概述_好大一条比目鱼的博客-CSDN博客_回声状态网络
- SAE
- 孪生神经网络Siamese network
Siamese network 孪生神经网络–一个简单神奇的结构 - 知乎 - 置信度传播belief propagation
- 残差网络residual network (ResNet)
identity mapping: 论文阅读之identity mapping_Teague_DZ的博客-CSDN博客_identity mapping - n-gram
- token
- 池化
- 表示学习
- 误差传播
- 耦合 / 解耦
- 剪枝
- 知识蒸馏knowledge distillation
- 优化optimization
- 凸优化convex optimization
- 梯度下降
- 反向传播back propagation (BP)
- 学习率learning rate
- weight decay
- momentum
- 随机梯度下降SGD
- Adam
- EM(变分推断(variational inference)/variational EM)
- NeurIPS 2022上Geoffrey Hinton提出了一种超神奇的、不用反向传播的前向-前向传播的训练方式:
The Forward-Forward Algorithm: Some Preliminary Investigations
反正这个东西大意呢就是说,不用反向传播,而是直接进行两次前向传播(一次用正样本,一次用负样本),直接调整权值(具体算法我没看懂),这样的优势有很多啊,比如模型不可微、或者模型是黑盒的时候,这样就也能计算权值了……
总之我觉得可能是一些RL不够persuasive的场合下能给RL一个灭顶之灾的搞法。
然后2023年就有把这个东西用在GNN上的工作了(你们是真的快啊,别跟我讲2023年你能连综述都搞出来哈):Graph Neural Networks Go Forward-Forward - 蚁群优化算法Ant Colony Optimization (ACO)
- 随机启发式无导数优化方法
- Derivative-Free Optimization via Classification
- AutoML
- Angel-ML/angel: A Flexible and Powerful Parameter Server for large-scale machine learning
- PKU-DAIR/mindware: An efficient open-source AutoML system for automating machine learning lifecycle, including feature engineering, neural architecture search, and hyper-parameter tuning.
- PKU-DAIR/open-box: Generalized and Efficient Blackbox Optimization System [SIGKDD’21].
- 神经网络结构搜索NAS
大概来说就是不再由人工设置超参,而是直接给定一个搜索空间search space(一堆模型结构组成的空间),然后让模型自己根据模型优化结果来学它应该长成什么结构。
比较容易联想到ML中传统的网格搜索之类的。DL之所以一般不那么干就是因为那样时间久嘛(我以前做小图GNN的时候,因为跑得快,所以也上网格搜索来着,直到我后来来做了NLP……)
神经网络结构搜索(NAS)简介 - 知乎
- adaptive(加可训练的参数,比如线性转换之类的) / non-adaptive(平均值、最大值etc)
- attention(你给我解释解释,什么TMD叫TMD attention(持续更新ing…))
- transformers(Transformer/Bert)
- 小样本学习few-shot learning(N-way/shot就表示每类能看到几个训练集样本)
- 零样本学习zero-shot learning
- 数据漂移data shift
机器学习中的数据漂移问题 - 哔哩哔哩 - 关系学习relational learning(relational learning关系学习)
- 度量学习metric learning
- 对比学习contrastive learning
参考我写的另一篇博文:对比学习(持续更新ing…) - consistency learning:意思是对数据做微小扰动后,应该使其预测结果不变(呃感觉听起来跟对比学习很像啊)
【半监督】半监督方法中的Consistency learning - 知乎:只看了概念部分。实例部分咔咔一上来全是CV,看不懂! - 数据增强data augmentation
- CV中常用的:随机裁剪,图像反转,图像缩放
- NLP中常用的
- 回译
- 生成(问就是ChatGPT):近义词替换,embedding相近词替换,句子shuffle
- 文本对抗
- TextFooler(单词重要性排序,单词替换模型)1
- 数据抽样sampling
- 对抗攻击
- 对抗防御
- 推荐系统recommendation system
- 协同过滤
- 冷启动问题cold-start problem
- CTR
- 黑盒模型 / 白盒模型
- 可解释性explainbility
- attention
- 隐藏层(这个感觉CV那边会用得多一点,毕竟NLP的话……你都不连续了,谁知道你是个啥啊)
- rationale:大概就是从原文中抽取出一部分内容,作为解释原因
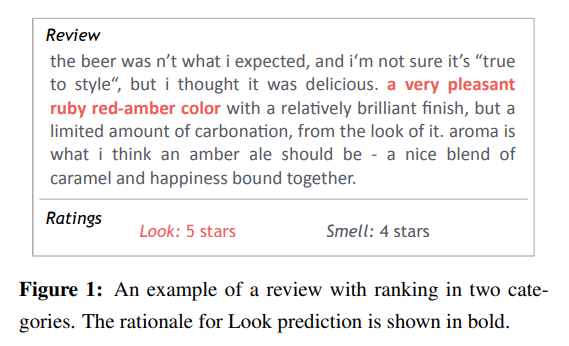
图源:Rationalizing Neural Predictions - 加一个中间任务:抽取特征(感觉上就像是把机器学习的逻辑用深度学习做一遍)
- SHAP
不再黑盒,机器学习解释利器:SHAP原理及实战 - 知乎 看这篇文章的介绍,shapley value(沙普利值) 应该是算每一个特征维度对结果的边际贡献。中间的原理巴拉巴拉的都没看。
- 鲁棒性robustness
- auto-encoder
- GAN
- 联邦学习federated learning
- 差分隐私differential privacy
- 多任务学习multi-task learning:就是在训练多种任务时共用一部分模型参数
多目标优化:(这部分我是真的没看懂啊,以后慢慢看吧)- 帕累托最优
一篇用MGDA实现帕累托优化的paper,博文可参考:深度学习中的trick | day 14 | 多任务学习 - borg 算法
- NSGA-II算法
- 遗传算法
- 进化算法
- 帕累托最优
- 强化学习reinforcement learning
Autonomous reinforcement learning on raw visual input data in a real world application
Self-critical Sequence Training for Image Captioning- sequential decision-making problems
- valuebased models
- policy-based models
- 策略梯度方法
- Q-learning
- Actor-Critic framework(策略policy函数-生成动作-环境交互,价值函数)
- asynchronous advantage actorcritic (A3C) algorithm:强化学习算法的训练方法
Asynchronous Methods for Deep Reinforcement Learning - RLHF(最近应该是因ChatGPT而比较出名)
- 模型量化quantization2
- 灾难性遗忘Catastrophic Forgetting
- 迁移学习transfer learning
Jindong Wang | Book - lifelong learning / continuous learning / never ending learning / 增量学习incremental learning:学习新的任务,并保持对以前任务的预测指标
- 课程学习Curriculum Learning (CL):安排任务的学习顺序
the process of ANN training in which samples are used in a meaningful order,把数据分批丢进去学习,或者先学所有数据集,然后逐渐减少样本3 - Taskonomy:(感觉跟上一个差不多,我有点懵了)
- 2020机器学习前沿技术----LifeLong learning - 知乎
- 课程学习Curriculum Learning (CL):安排任务的学习顺序
- 主动学习active learning (AL):通过选择性的标记较少数据而训练出表现较好的模型
- 主动学习(Active Learning),看这一篇就够了 - 知乎
- 遗传编程/基因规划 Genetic Programming
- 【遗传编程/基因规划】Genetic Programming初学者笔记:基本概念与过程_ocd_with_naming的博客-CSDN博客_gp算法grow方法
- 遗传编程(Genetic Programming)_美好在悄悄发生的博客-CSDN博客_遗传编程
- 遗传编程(Genetic Programming)入门指南 - 知乎
- 上下文学习in-context learning (ICL):看起来意思就是用相关样本来预测目标样本。
直接这么说有点像transductive learning,但看示例似乎其实是prompt,就是给模型提供几个示例样本,然后让模型进行预测。- 上下文学习(in-context learning),检索和OOD外推 - 知乎
- A Survey for In-context Learning
- Larger language models do in-context learning differently:这篇认为只有大模型才会做in-context learning,给出错误答案后效果会下降,但如果给出与正确答案一样分布的错误答案,则不会下降太多,说明大模型能学到问题与答案之间的映射关系
In-context learning只对大模型有效! - In-Context Learning中的示例选择及效果
- i.i.d. / out-of-distribution (OOD)
- OOD detection
- 基于分类模型的方法
- 基于生成模型的方法
- Energy-based Out-of-distribution Detection
- online learning
- Online Learning算法理论与实践 - 知乎
- 领域自适应
- 元学习meta-learning
- 捷径学习shortcut learning
- 走不得的捷径:shortcut learning捷径学习 - 知乎
- 解耦学习
- 因果推理
- 反事实学习counterfactual learning
- AI伦理问题
- AI公平性问题
这个我可能以后也会专门出个专题来写,现在先把收集到的资料整理到这里- 词嵌入中的性别偏见(直接计算距离):
如何消除机器学习模型中的性别偏见:NLP和词嵌入 - 雷锋字幕组- AI研习社
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
- 词嵌入中的性别偏见(直接计算距离):
- Ethics consideration sections in natural language processing papers
- AI公平性问题
- 多模态multi-modal
- label embedding
- label smoothing
- 几何深度学习
Geometric deep learning: going beyond Euclidean data
几何深度学习从古希腊到AlphaFold,图神经网络起源于物理与化学:这一篇感觉就是先讲了讲深度学习,然后介绍了图论、化学式、图神经网络 - symbolic AI
- Neural-Symbolic Integration4
- 反绎学习abductive learning (ABL)5
大概来说是生成伪标签,然后用逻辑推理进行修正,再重新训练分类器,反复迭代,直至分类器不再更新或标签与逻辑统一 - Human-level concept learning through probabilistic program induction
- 自动定理证明Automated Theorem Proving
就是让模型证明数学定理- 自动定理证明_百度百科
- dual learning对偶学习
- Dual learning for machine translation
- Dual Supervised Learning
- 参考博文:
- 9/17 Dual learning_NANCYGOODENOUGH的博客-CSDN博客
- 城市计算urban computing:感觉大概来说就是搞“智慧城市”
群体感知
城市计算概述(introduction to urban computing) 笔记 - 知乎 这篇讲的是这篇paper:Introduction to Urban Computing - AI+X
- 化学
[IJCAI 2023] 化学小分子预训练模型(Chemical Pre-trained Models, CPMs)首篇综述
- 化学
3. 主要用于NLP的DL基础
- OOV (out of vocabulary)
- 停用词
- 词干化stemming:将英文中所有同一个词的各种形式统一,如stopped, stopping都统一到stop
- 序列标注
常见任务:分词tokenization,短语识别,分句 / 句子边界检测,命名实体识别NER (named entity recognition),词性标注PoS Tagging,实体抽取,关系抽取relation extraction,事件检测/事件抽取,measurement extraction,指代消解coreference resolution
可参考我撰写的另一篇博文:序列标注/信息抽取任务(持续更新ing…) - TF-IDF模型
- 词袋模型BoW
- LDA
LDA原始论文:Latent Dirichlet Allocation - word2vec
- CBOW
- skip-gram
- 句子表征
- 对句子的表示可以分为composion(从词向量到句向量)和distributed(将句子当成一个unit,前后文作为context)
- 自然语言处理中句向量 - 知乎
- Sentence Embedding 现在的 sota 方法是什么? - 知乎
- 预训练语言模型pretrained language model
- 可参考我撰写的这两篇博文:预训练语言模型概述(持续更新ing…) 和 各种预训练模型的理论和调用方式大全
[CLS][SEP][BOS][EOS]
自然语言处理加BOS和EOS的作用是什么? - 知乎- 突现能力
深入理解语言模型的突现能力
137 emergent abilities of large language models — Jason Wei
On Emergent Abilities, Scaling Architectures and Large Language Models — Yi Tay - 思维链chain-of-thought (CoT):大概来说就是让LLM在生成结果前先生成文本形式的推理过程。其实我个人还是觉得这样太简单粗暴了……
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Chain of Thought 开山之作论文详解_qq_42190727的博客-CSDN博客
思维链(Chain-of-Thought, CoT)的开山之作 - 知乎
- 微调finetune
- prompt / 提示学习prompt learning
- bootstraping
- 远程监督distant supervision
认为如果句子中含有一对知识库原本就存在关系的实体,那么这句话大概率表示了这一关系
关系抽取之远程监督算法(Distant Supervision)_Dr.sky_的博客-CSDN博客:这一篇我只主要看了介绍部分,终于看懂远程监督是啥意思了!
Distant supervision for relation extraction without labeled data:远程监督界的开山之作 - cross-view training:感觉意思差不多是说,在有监督的训练方法之外,新增了其他挖空方式(cross-view)来进行训练
- 信息检索information retrieval (IR)6
- 召回-重排rerank
- 文本匹配
- 句子相似度
- 算法:BM25
- NLP基础知识 | 常见任务类型 | 信息检索
- 向量检索/向量相似性计算方法(持续更新ing…)
- ad-hoc检索:集合中的文档相对稳定,query变化很大
routing检索:query要求相对稳定,被查询的文档(数据库)不断变化
ad hoc检索 & routing检索_ad hoc 检索_Mr.DC30的博客-CSDN博客
- 搜索引擎
Sponsored Search付费搜索 - 关键词提取(常用的Python3关键词提取方法)
- 主题分类/抽取
- 文本生成natural language generation (NLG)
- 文本摘要text summarization(可以直接参考我写的博文:文本摘要(text summarization)任务:研究范式,重要模型,评估指标(持续更新ing…))
- 机器翻译machine translation
- paraphrase generation / rephrasing:生成输入文本的同义文本(相当于转述)
- PPT生成
- 问答QA
QA相关我之前写过一个回答,列过一些paper,可供参考:https://www.zhihu.com/question/536413640/answer/2533262058 - 问题生成question generation
- Multiple Choice Question Generation (MCQG)
- 文本风格转换text style transfer(是NLG任务,但不像一般NLG任务是源域与目标域样本一比一匹配的,而是那种(比划)就是一堆对应一堆的那种)
- 文本纠错text correction
- 创新度novelty
- encoder-decoder架构
- seq2seq任务
- BLEU指标
- 自然语言理解NLU / 自然语言推理Natural Language Inferencing (NLI)
一文看懂自然语言理解-NLU(基本概念+实际应用+3种实现方式)
NLU调研 - 给荔枝打气- 蕴含识别entailment
- 意图识别/检测(NLP课题入门 | day 14 | 意图分类)
- 槽填充slot filling(NLP基础知识 | 常见任务类型 | 槽填充 NLP课题入门 | day 15 | 槽填充)

开放域/域外意图检测 - Text-to-SQL
- Spoken Language Understanding (SLU)
- 阅读理解Machine Reading Comprehension (MRC)
- 讽刺检测sarcasm detection(NLP课题入门 | day 9 | 讽刺检测)
- 抄袭检测plagiarism detection
A Review of Machine Learning based Plagiarism Detection Approaches - 跨语言cross-language
- emotional recogniton
- decontectualization:大致来说就是把文中的一句话单拎出来进行修改,补全该句所需的上下文,表示原句意。说来复杂总之可以参考:为什么每次有人大声通电话时,我就很烦躁…_51CTO博客_有人大声说话就烦躁
- language detection
- 这篇工作上次更新代码已是5年前,上次回复issue已是2020年,所以感觉不太维护了:saffsd/langid.py: Stand-alone language identification system
- 语义标记semantic markup:标注语义/内容相关的信息,举个栗子就像这样:

(图源Semantic mark-up of Italian legal texts through NLP-based techniques)
参考资料:- 语义标记_百度百科
- Semantic Markup | What is Semantic Markup? | Fable:说这是个辅助技术
- What On Earth Is Semantic Markup? (And Why Should You Learn To Write It) »:在HTML的领域上解释了一下这是个啥
- 论点挖掘argument mining
论点挖掘小技巧-CSDN博客 - 语义表示
- 抽象语义表示Abstract Meaning Representation (AMR)

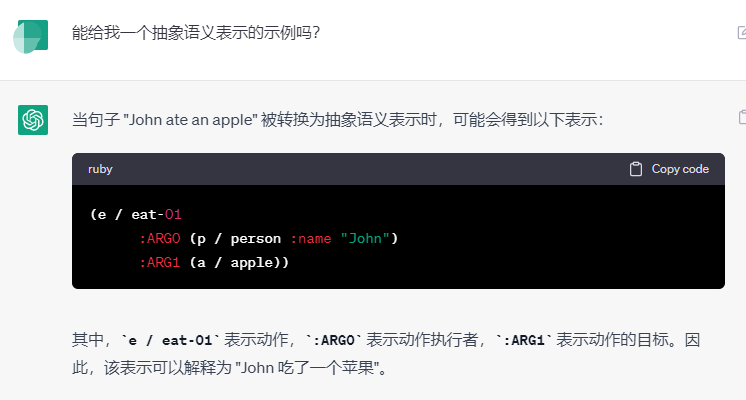
- 抽象语义表示Abstract Meaning Representation (AMR)
- 框架语义学frame semantics

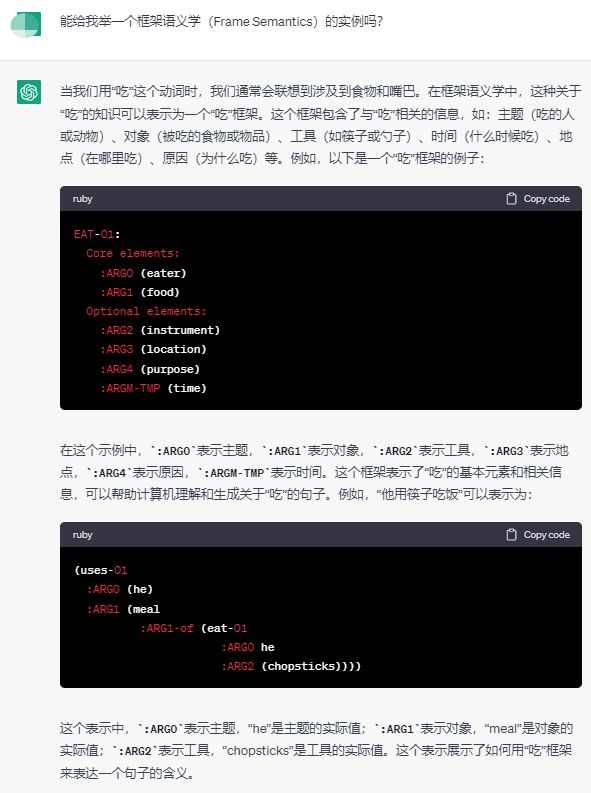
- 框架语义解析(Frame Semantic Parsing,FSP)是自然语言处理领域中的一项重要任务,其目标是从句中提取框架语义结构,实现对句子中涉及到的事件或情境的深层理解
- 空间语义理解

- 潜在语义索引latent semantic indexing (LSI)

- 程序语言处理PLP (programming language processing)
- program representation
- algorithm detection
- LegalAI:准备专门写一篇,等等吧
- 语言学上的一些概念
- 计算语言学CL (Computational Linguistics)
- 齐夫定律 - 维基百科,自由的百科全书:在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比
- 同指关系referentiality:指称同一对象的不同词之间的意义关系。指称同一对象的这些词可能同义,也可能异义。例如“老虎”“於菟”“百兽之王”都可指称虎。7
- surface form:词语本身的表现形式8
- 量子自然语言处理QNLP (Quantum Natural Language Processing)
量子+AI:自然语言处理 - 腾讯云开发者社区-腾讯云
GitHub - ICHEC/QNLP: ICHEC Quantum natural language processing (QNLP) toolkit
4. GNN和图论
- transductive learning / inductive learning
直推 / 归纳(这两个词的翻译真的很诡异)
如何理解 inductive learning 与 transductive learning? - 知乎 - 图的表示:
定义一(图)
定义二(图的邻接矩阵) - 图的属性:
定义三(结点的度,degree)
定义四(邻接结点,neighbors)
定义五(行走,walk)
定理六(行走的个数)
定义七(路径,path)
定义八(子图,subgraph)
定义九(连通分量,connected component)
定义十(连通图,connected graph)
定义十一(最短路径,shortest path)
定义十二(直径,diameter)
定义十三(拉普拉斯矩阵,Laplacian Matrix)
定义十四(对称归一化的拉普拉斯矩阵,Symmetric normalized Laplacian) - 节点分类
- 典型任务
- 生物医药领域:药物发现drug discovery,蛋白质结构预测protein structure prediction9
- 典型任务
- 链路预测(图学习中的链路预测任务(持续更新ing…))
- 图分类
- 图着色graph coloring
- 四色定理_百度百科
- 10.8图着色(Graph Coloring) - 进击の辣条 - 博客园
- clique是一个点集,在一个无向图中,这个点集中任意两个不同的点之间都是相连的。maximal clique是一个clique,这个clique不可以再加入任何一个新的结点构成新的clique
- 1142 Maximal Clique_小鱼朵~的博客-CSDN博客
- graph summarization
A Survey on Graph Neural Networks for Graph Summarization - 子图学习
- subgraph neural networks / subgraph mining(NLP课题入门 | day 20)
- 对于同质图节点表征模型,我专门另外写了一个博文,可作参考:各种同质图神经网络模型的理论和节点表征学习任务的集合包rgb_experiment
- 图扩散卷积graph diffusion convolution (GDC)(仅适用于同配图):怎么说呢,感觉就是用PPR之类的扩散方法重新构建出了一个新图
Diffusion improves graph learning
gasteigerjo/gdc: Graph Diffusion Convolution, as proposed in “Diffusion Improves Graph Learning” (NeurIPS 2019)
原博文:Graph Diffusion Convolution - MSRM Blog
中文翻译:图扩散卷积:Graph_Diffusion_Convolution_jialonghao的博客-CSDN博客_图扩散 - 异质图神经网络HGNN(异质图神经网络(持续更新ing…))
- metapath
- meta-graph
- metapath-based neighborhood
- meta-path neighbor graph / metapath-based graph
- network schema
- metapath及其相关概念(持续更新ing…)
- 动态图神经网络
- 动态网络(dynamic network)和时态网络(temporal network)有区别吗? - 知乎:感觉结论是没有区别
- multiplex network:大概就是说,同样的节点,但是有多种不同的组边方式(只有1种节点,但是有多种边的异质图)
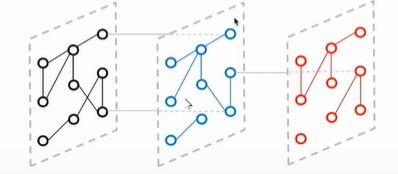
(图源:Graph Representation Learning 笔记 Ch1&Ch2(未读))
Representation learning for attributed multiplex heterogeneous network - hyperbolic
- graph un-learning:理念是从模型中去掉已学习的部分训练集(想要保护隐私,所以要删除指定用户数据,这种scenario)
- 图结构学习graph structure learning (GSL):学习节点表示的同时,学习更合适的图结构
论文笔记:A Survey on Graph Structure Learning: Progress and Opportunities - 知乎 - 用GNN做NLP:准备等有缘分了,把这个主题的博文也写了(因为我读书报告已经确定不写这个主题的了,所以不用担心出现自己抄自己的问题了)
- AutoGraph:这个我主要是听过北大一位毕业博士给我们实验室讲的talk。我自己不是做这个的,所以只在此简单罗列。对slides或者相关专业人士有需求的可以联系我,我再去帮你找人。
补充知识点:GNN算子可以分为propagate(P)和transform(T)
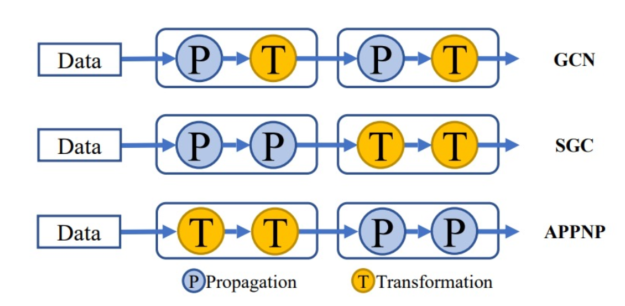
- G-NAS:PT的pipeline(模式和深度)是固定的
GraphNAS Graph Neural Architecture Search
Auto-GNN: Neural Architecture Search of Graph Neural Networks - Model Degradation Hinders Deep Graph Neural Networks:这篇paper考虑了以前工作太浅导致对全图信息的表现力不足,GNN很难做深是个经典问题了,本文这里给出的解释是拉普拉斯平滑(slides这里还有一些相关论文列表,JKNet,SGC,APPNP,DAGNN等,其他略,可以看下面一条的deep GNN工作集锦),主要探讨了P和T两种算子的深度分别对GNN产生的影响
- DFG-NAS: Deep Graph Neural Architecture Search:design space考虑不同的PT顺序、组合和数量,加入门机制、skip connection等
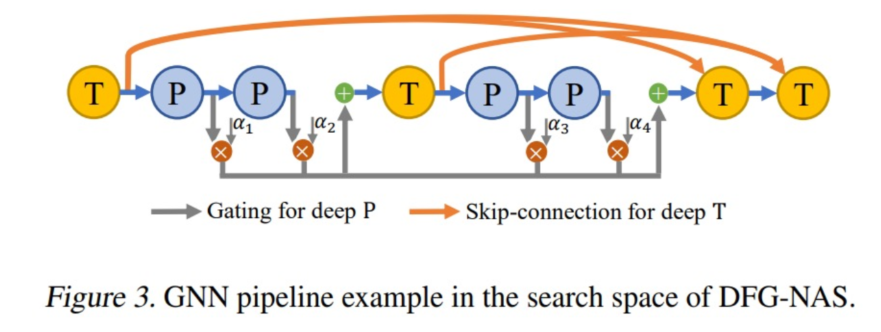
(架构的选择与图的稀疏程度、大小等有关) - PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm:这篇主要考虑信息通讯代价的问题,提升GNN的scalability
PKU-DAIR/SGL: A scalable graph learning toolkit for extremely large graph datasets. (WWW’22, 🏆 Best Student Paper Award)
Neural Message Passing (NMP) 范式(聚合过程是通讯,更新过程是计算)会导致图运算耗时
SGAP范式:

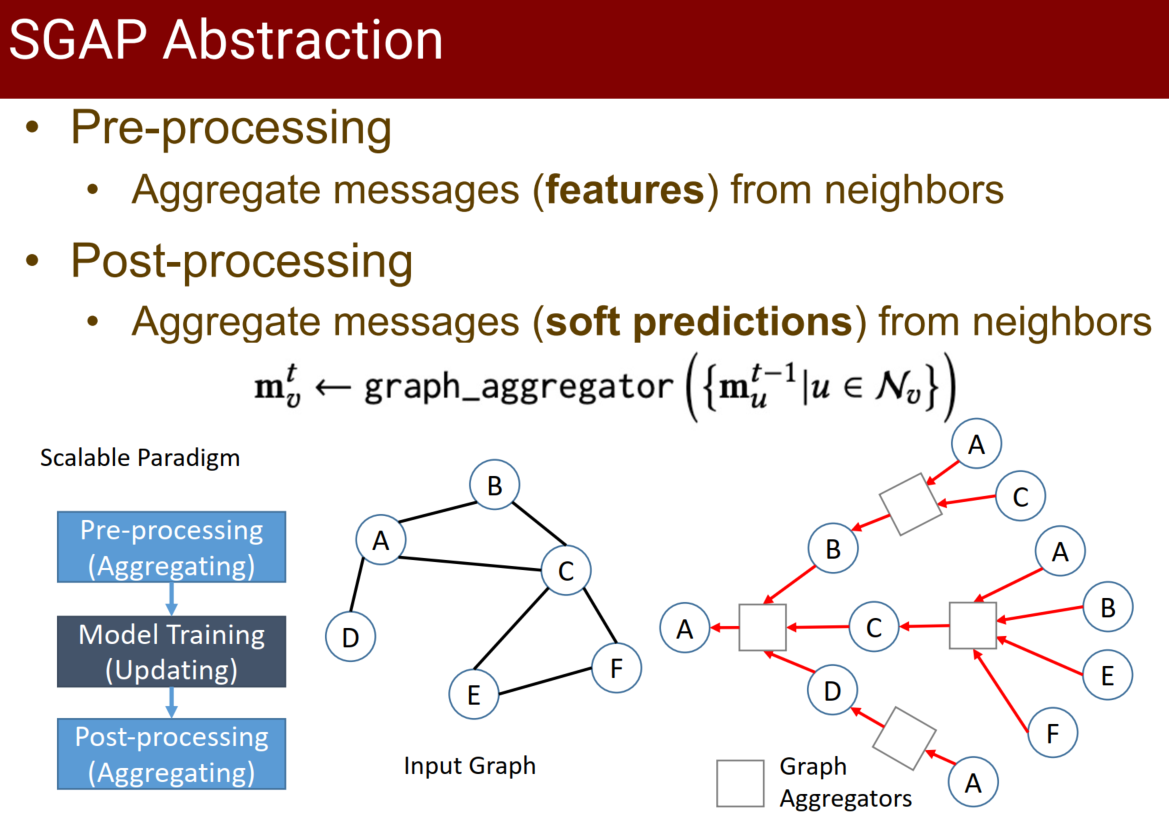
这个架构看起来是传播→训练→传播again(这回用的是训练后得到的软标签),具体的没看
design space是3个SGAP步骤中的参数选择 - Angel Graph
- G-NAS:PT的pipeline(模式和深度)是固定的
- mengliu1998/awesome-deep-gnn: Papers about developing deep Graph Neural Networks (GNNs):关注GNN深度的相关工作
- 图神经网络随机删减方法
AAAI 2023 | DropMessage: 图神经网络随机删减方法的归并统一 - 图联邦学习
- 符号网络signed network:网络中每条边带了正负sign
- balanced:每个环的所有边的sign的乘积都是正数
- balanced edge set
5. KG
- 知识图谱指南:从理论到应用 - 知乎
- 实体对齐
- 知识图谱补全KG Completion
- query answering
- TransE
- TransR
- DistMult
- 实体消歧
- 本体对齐ontology alignment
6. W3C规范
- RuleML
- SWRL (Semantic Web Rule Language):以语义的方式呈现规则的一种语言
- OWL本体论
7. 时间序列分析
可以参考我之前撰写的博文:从隔壁老王开始的信号处理入门
- 语音处理
- speech recogniton
- speech synthesis
8. CV
- 点云
- object classification
- 目标检测object detection
- two-stage detector:faster RCNN, RFCN
- one-stage detector:YOLO, SSD
- 边界框bounding box
- object segmentation
- 语义分割
- 实例分割
- style transfer
- 降噪denoising
- image generation
- image caption
- ViT
- MLP-Mixer:总之感觉就是用MLP和别的一些基础模块替代transformer里的模块
- 深度学习之图像分类(二十一)-- MLP-Mixer网络详解_木卯_THU的博客-CSDN博客_mlp-mixer
- 可解释性
- CAM方法:看起来意思是把原本的预测头换成池化层,然后加权求和其池化结果,最后得到图上的重点部分吧
01 CAM方法(《CAM:Learning Deep Features for Discriminative Localization》) - 知乎
可解释性(一)之CAM和Grad_CAM_cam grad_打着灯笼摸黑的博客-CSDN博客
- CAM方法:看起来意思是把原本的预测头换成池化层,然后加权求和其池化结果,最后得到图上的重点部分吧
- 常用工具包:OpenCV,OpenMMlab
9. 其他CS相关
- 万物互联IoE:Internet of Everything
- 模块化
- 重构
- 事件日志
- 过程挖掘PM (process mining)
- 过程挖掘(Process Mining)1——始于颜值_hyhy12580的博客-CSDN博客_process mining
- 软件测试
- Metamorphic testing - Wikipedia
- 数据结构
- static structure - segment tree:存储一个整数序列的树(反正就这种感觉)
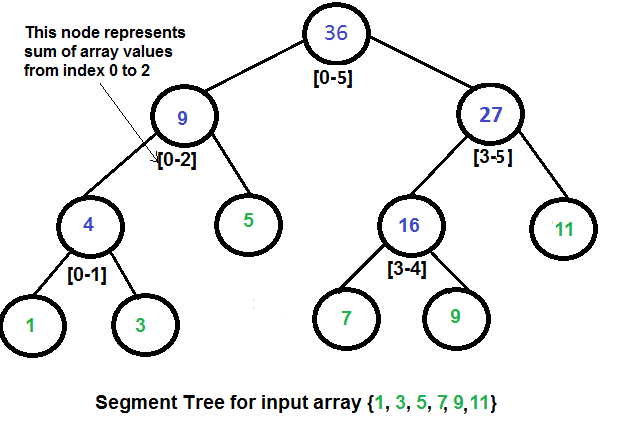
Segment Tree - GeeksforGeeks:上图也源自该文(感觉有点复杂,还没仔细看) - Trie树 / 字典树:在字符串集合中快速查找某个字符串,合并重复前缀
- 前缀表示法 / 普通波兰表示法
- 栈
- static structure - segment tree:存储一个整数序列的树(反正就这种感觉)
- 算法
- 校验和算法:Luhn算法/模10算法
Luhn算法_百度百科
- 校验和算法:Luhn算法/模10算法
- FPGA
- 元胞自动机cellular automata (CA)
元胞自动机_百度百科 - 跳板机
- 矩阵分解
- PCA
- SVD
- 张量分解
- 机器学习|Tucker张量分解 - 知乎
- 计算机体系结构
- cuda
- GPU
- OpenCL
- 异构计算
- AI编译器
- compiler
- LLVM
- TensorRT
- TVM
- MLIR
- Neon
- 栈帧stack frame
- 栈帧(Stack Frame)_ATFWUS的博客-CSDN博客
- 10抽象语法树(Abstract Syntax Tree,AST)
语法树(Syntax tree)
是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。 - 具体语法树
分析树 - 语法分析(英语:syntactic analysis,也叫parsing)
- 安全
- 红队:红队是在军事演习、网络安全演习等领域中扮演敌人或竞争对手角色的群体,扮演己方角色的则称作蓝队。
在兵棋推演时,红队假设为敌方部队,并站在敌方角色立场来思考作战,红队成员中至少有一部分在演习前不能将身份告知蓝队。
(来源:https://zh.wikipedia.org/zh-cn/紅隊) - red teaming:模仿真实场景进行攻击
定义:Red teaming, also known as red cell, adversary simulation, or Cyber Red Team, involves simulating real-world cyber attackers’ tactics, techniques, and procedures (TTPs) to assess an organization’s security posture.(来源:What is Red Teaming & How it Benefits Orgs)
- 红队:红队是在军事演习、网络安全演习等领域中扮演敌人或竞争对手角色的群体,扮演己方角色的则称作蓝队。
10. 其他数学
- 最优传输optimal transport
- 最优传输简介 - Kawayikiwi的文章 - 知乎
- 分布相似度
Wasserstein距离_wasserstein distance_Wanderer001的博客-CSDN博客- Kullback-Lieber (KL) 散度
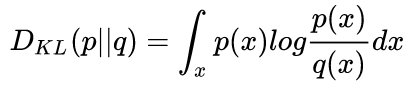
- JS散度:具有对称性
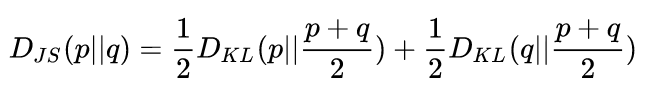
- Wasserstein距离 / 推土机距离Earth Mover’s distance
- Kullback-Lieber (KL) 散度
- 随机过程
- 伊辛模型Ising model
- 泰森多边形 / 冯洛诺伊图(Voronoi diagram):这玩意有点复杂,我也没太看懂
泰森多边形_百度百科
11. 其他术语
- asynchronous异步的
- 深度学习数据集的In-the-Wild是什么意思? - 知乎:大概来说就是指应用于真实场景
- auxiliary task
- out of the box开箱即用
- in-domain
- out-of-domain
- open-domain
- POS tag
- 数据分析领域的专业术语
- 用户画像
- lay summary:给外行看的摘要
Lay Summary是什么?为什么要写好外行也能看懂的lay summary? - 计算机各领域的著名会议/期刊(NCS显然是另一种级别的,别说了,别说了.jpg)
- NLP: EMNLP, ACL, COLING, NAACL, IP&M
- CV: CVPR
- AI: AAAI, KDD, WSDM
- 计算机底层系统:OSDI
- Prolog逻辑编程语言
12. 常用专业工具
有些我其他博文里写了的,就不再赘述了。
- 数据打标:doccano, prodigy, label studio
使用文本标注工具-doccano - 简书 - 数据分析/处理/挖掘工具包:numpy, pandas, SciPy
(我的意见是学好Excel,走遍天下都不怕) - 除Python以外常用的数据分析工具:R, MATLAB, Lingo
- Python包管理工具:Anaconda
- Python编程工具(IDE等):VSCode, CodeBlock, PyCharm
- 深度学习已组装好的环境:colab
- 可视化工具包:matplotlib, seaborn
- 机器学习工具包:sklearn
- 深度学习框架:PyTorch, TensorFlow(以前还有Keras,现在Keras和TensorFlow合并了), PaddlePaddle, Caffe(已经快没人用了吧)
- 自然语言处理工具包:transformers(同属huggingface旗下的包还有datasets, sentence-transformer), fastText, sent2vec,spacy, NLTK, torchtext, gensim
- GNN工具包:DGL, PyG, NetworkX
- 代码运行日志记录工具:logging, wandb, tensorboard, tensorboardX, fitlog
我写的wandb教程:wandb使用教程(持续更新ing…)
我写的fitlog教程:fitlog使用教程(持续更新ing…) - 文本摘要指标rouge相关:pyrouge和rouge在Linux上的安装方法以及结果比较
- 大数据工具:Hadoop, Spark
- 科研绘图软件:PPT, PS, Visio
- 思维导图工具:XMind, MindMaster
本文撰写过程中使用的参考资料
- OOD Detection:挖掘生活中的椅子:这一篇之所以没拿来放在正文中当参考文献主要是因为我觉得题图有点吓人
- 浅谈自动微分是个啥?真的很浅。:简单瞅了一眼
- #DeepLearningBook#算法概览之五:Sequence Modeling_咸鱼酱的博客-CSDN博客:充满年代感的博文,介绍了RNN
其他补充阅读资料
- NLP|分类与匹配的各类评价指标 | codewithzichao:这篇挺全的,还有EM和信息抽取的各种指标都有
Is bert really robust? a strong baseline for natural language attack on text classification and entailment.
参考博文:文本对抗之TextFooler - 知乎 ↩︎哈佛大学在读博士:模型量化——更小更快更强 – 闪念基因 – 个人技术分享 ↩︎
Cyclical Curriculum Learning ↩︎
参考资料:
①Neural-Symbolic Learning Systems ↩︎参考资料:
①论文阅读 (35):Abductive Learning (反绎学习)_因吉的博客-CSDN博客:这篇我看了归看了,其实没太看懂,只产生了一个模糊的印象,以及这个做法看起来好难,而且好像对我的课题没什么用,我就没再继续看了。
②Abductive Learning:上一篇博文参考的原英文论文
③周志华:“数据、算法、算力”人工智能三要素,在未来要加上“知识”| CCF-GAIR 2020…_人工智能学家的博客-CSDN博客:周志华讲的就是上面那篇论文
④反绎学习简介_Cheng_0829的博客-CSDN博客
数据算法算力知识反绎学习_weixin_ry5219775的博客-CSDN博客
[CCF-GAIR 2020]Abductive Learning(反绎学习)-周志华 - 枫之羽
似乎也是对周志华那篇的笔记
⑤[论文解读] Bridging Machine Learning and Logical Reasoning by Abductive Learning_年糕糕糕的博客-CSDN博客:简单看了下,嗯,没看懂
⑥周志华教授发表首届国际学习与推理联合大会 IJCLR 开场 Keynote:探索从纯学习到学习 + 推理的 AI-ZAKER新闻
⑦机器学习笔记(20)读周老师《探索从纯学习到学习 + 推理的 AI》有感_是魏小白吗的博客-CSDN博客
⑧干货!原始数据中的反绎知识归纳_AITIME论道的博客-CSDN博客
⑨论文阅读 (77):Abductive Learning with Ground Knowledge Base_因吉的博客-CSDN博客
⑩Abductive Logic Programming
①①The Role of Abduction in Logic Programming A.C. Kakas ↩︎基于深度学习的信息检索模型_深度学习检索_xiaobin199cs的博客-CSDN博客 ↩︎
定义复制自:同指关系_百度百科 ↩︎
我看的是这篇博文:最先进的语义搜索句子相似度计算_zenRRan的博客-CSDN博客 ↩︎
有一个贼出名的工作AlphaFold,我之前写的笔记里面简单介绍过一波:cs224w(图机器学习)2021冬季课程学习笔记1 Introduction; Machine Learning for Graphs ↩︎
抽象语法树_百度百科 ↩︎







![Prompt learning 教学[进阶篇]:简介Prompt框架并给出自然语言处理技术:Few-Shot Prompting、Self-Consistency等;项目实战搭建知识库内容机器人](https://img-blog.csdnimg.cn/img_convert/dfed1c9335e6ee97556c855e608bf712.png)