浅谈wor2vec,RNN,LSTM,Transfermer之间的关系
今天博主谈一谈wor2vec,RNN,LSTM,Transfermer这些方法之间的关系。
首先,我先做一个定位,其实Transfermer是RNN,LSTM,和word2vec的一种“提升版”。这里的提升并不是说他们是一种迭代版本,而是说Transfermer它解决了RNN,LSTM,和word2vec的一些缺点。
下面我们先说一下RNN,LSTM,和word2vec主要i的缺点。
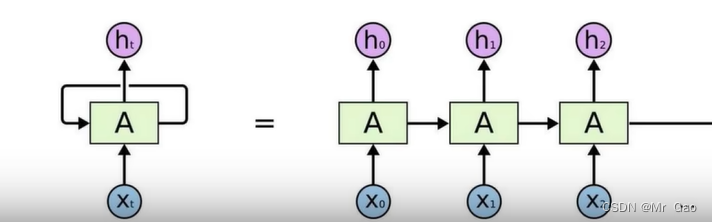
下面是RNN的模型示意图。我们可以很显然的发现,RNN在做一些任务的时候,是一个个的输入一个句子的单词,这样的计算方式,会导致忽略句子内单词之间的内在联系。虽然RNN,和LSTM有这种记忆,可以记忆之前句子留下来的信息,但是这种单向不并行计算方式,还是很大程度上不能考虑句子单词之间的内在联系。
同样word2vec其实也是如此,word2vec生成的词向量是固定的,这很大的限制了词向量的灵活性、表达能力。同时,我们知道word2vec其实只是从集合的角度去考虑句子内单词之间的联系,没有考虑单词间位置的关系。而且不能根据特定任务去灵活的发挥词向量的表达能力。
所以这两类模型的问题,渐渐的使得研究者去思考更好的模型,transfermer也因此诞生。
在transfermer论文中,作者说过,其实transfermer很大程度上是为了解决长句子的句子间因为有些词语距离太远,当时的很多模型不能很好的去学习词语间的联系这一问题。
transfermer则可以较好的解决这一问题。
那么对于transfermer 其自注意力机制,很特别的一个地方,就是对于一个句子,先对词向量进行一次提取,每一个词语先经过一个V矩阵进行一次提取。然后呢,其再用一个Q矩阵个一个K矩阵对x进行两次信息提取,提取完之后,得到的 q向量和k向量乘积作为V矩阵提取信息的权值。所以,其充分利用了神经网络的强大表征能力。但是也存在冒险,在学习的时候,神经网络需要自己知道Q K矩阵是为了权值而学习的,而V矩阵则是对数据进行最后的信息提取而学习的。我们可以给与transfermer更多的提示,让其对于这三个矩阵的学习更加具有目的性,这样或许可以更好的提升transfermer的学习能力,否则直接让其再目标函数的驱动下去学习这三个矩阵,目的性较弱,且会局限于数据初始化。





![【GSEP202303 C++]】1级 每月天数](https://img-blog.csdnimg.cn/22e14bf249134ee79df4741623785cc7.png)