HAT是CVPR2023上的自然图像超分辨率重建论文《activating More Pixels in Image Super-Resolution Transformer》所提出的模型。本文旨在记录在Window系统下运行该官方代码(https://github.com/XPixelGroup/HAT)的过程,中间会遇到一些问题,供大家参考。
环境安装
参考官方代码,进行环境安装
pip install -r requirements.txt
python setup.py develop代码运行
这里我在遥感图像的数据集UCMerced上进行重新训练,需要首先在./options/train文件夹中设置对应的yaml文件,然后执行训练过程:
python hat/train.py -opt options/train/train_HAT_SRx4_UCMerced_from_scratch.yml
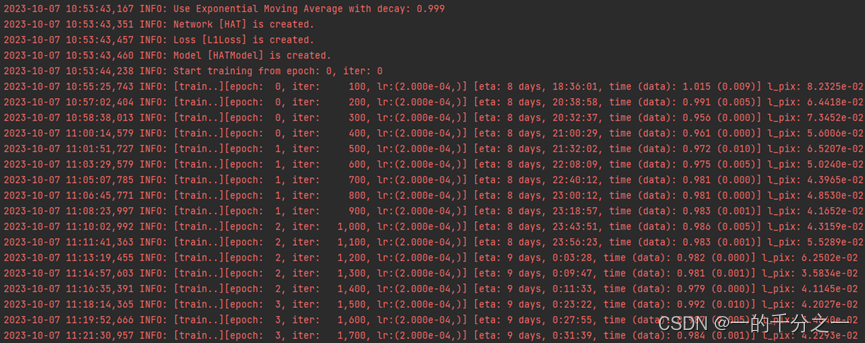
开始训练了
遇到的问题
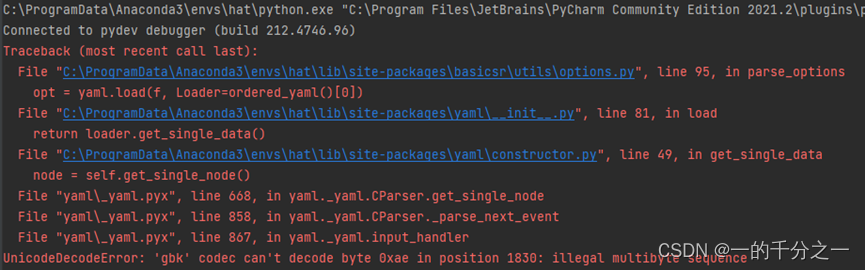
问题1: UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xae
由于相关开源代码都是在linux下编写和调试的,放在window系统中会出现不少问题,如下读取yaml文件时遇到的问题:
使用notepad++ “编码”查看对应文件的编码格式。修改报错位置代码,使用‘utf-8’编码格式:
with open(filename, 'r+', encoding='utf-8') as f:
《关于UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte的解决办法》
《真正解决Windows下UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xff in position 0错误的方法》
问题2: TypeError: expected str, bytes or os.PathLike object, not NoneType
因为自己在训练配置文件yml中,没有设置meta_info的信息,所以报下面的问题:
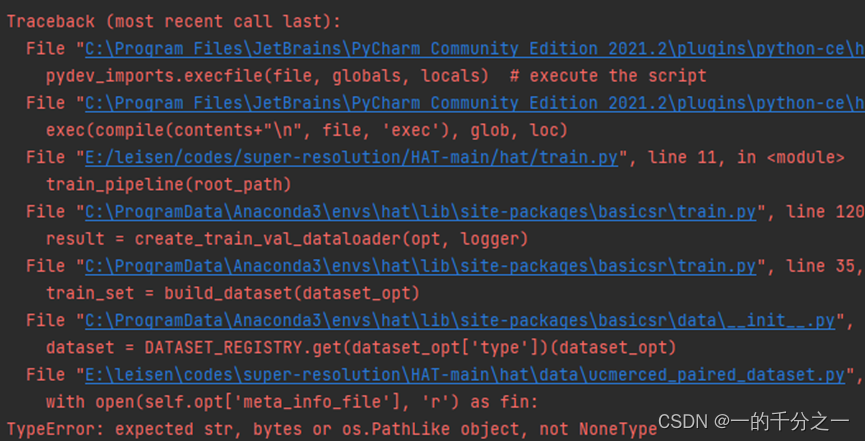
参考hat/data/meta_info/meta_info_DF2Ksub_GT.txt:
解决方式有两种:一种是将yml中meta_info给注释掉,或者使用在github/basicsr库中使用generate_meta_info.py文件,生成meta_info文件。我这里直接选择注释掉了。
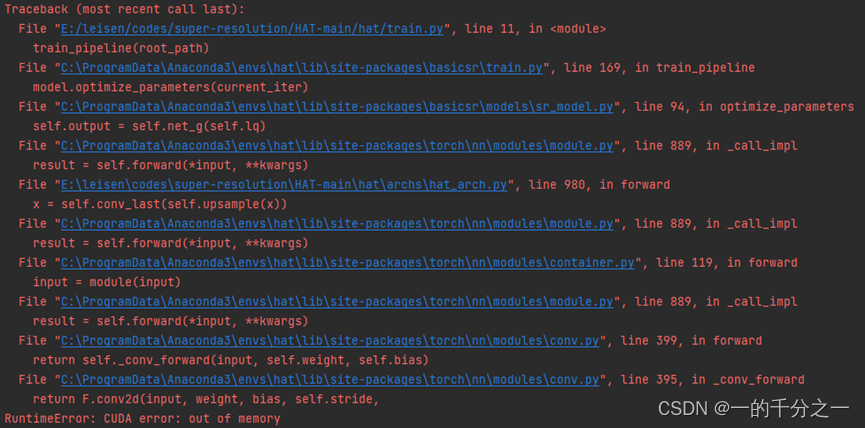
问题3: RuntimeError: CUDA error: out of memory
直接运行会报错,out of memory了
将batch_size_per_gpu设置成2,倒是可以跑起来:
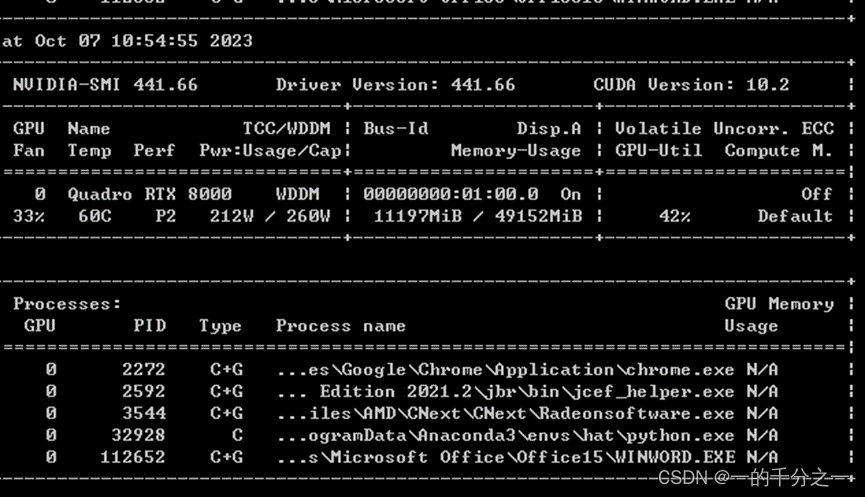
这里可以看出HAT很吃内存啊!