domain adaptation 领域理论方向的重要论文. 这篇笔记主要是推导文章中的定理, 还有分析定理的直观解释. 笔记中的章节号与论文中的保持一致.
1. Introduction
domain adaptation 的设定介绍:
有两个域, source domain 与 target domain.
source domain: 一组从 source dist. 采样的带有标签的数据.
target domain: 一组从 target dist. 采样的无标签的数据, 或者有很少的数据带标签.
其中 source dist. ≠ \neq = target dist.
目标: 学习一个能在 target domian 上表现得好的模型.
(第二节跳过)
3. A rigorous model of domain adaptation
首先关注二分类问题. 这节主要是给出了本文中用到的一些notations.
- < D S , f S > <\mathcal{D}_S, f_S> <DS,fS> 表示 source domain, 前者是 source dist, 后者是 source dist. 上的 ground truth function.
- < D T , f T > <\mathcal{D}_T, f_T> <DT,fT> 表示 target domain, 同上.
- h : X → { 0 , 1 } h:\mathcal{X}\rightarrow \{0,1\} h:X→{0,1} 表示一个从输入空间映射到二分类集合的 hypothesis.
- 在分布 D S \mathcal{D}_S DS 上, 两个 hypotheses h h h 与 f f f 的平均差异定义为:
ϵ S ( h , f ) = E x ∼ D S [ ∣ h ( x ) − f ( x ) ∣ ] \epsilon_S(h,f)=\mathbf{E}_{x\sim \mathcal{D}_S}[|h(x)-f(x)|] ϵS(h,f)=Ex∼DS[∣h(x)−f(x)∣]
由于 h h h 与 f f f 的输出是 0 或 1, 所以只有它们输出不同时, 期望中间的部分为 1, 所以上式为两个hypotheses之间的平均差异(或 disagreements). - source error of h h h: ϵ S ( h ) = ϵ S ( h , f S ) \epsilon_S(h)=\epsilon_S(h,f_S) ϵS(h)=ϵS(h,fS), 也就是 h h h 在source domain 上的错误率 (generalization error).
- empirical source error of h h h: ϵ ^ S ( h ) \hat{\epsilon}_S(h) ϵ^S(h), 也就是 h h h 在source domain 上的经验错误率 (empirical error).
- 相同的, 在 target domain 上的 notations: ϵ T ( h , f ) , ϵ T ( h ) , \epsilon_T(h,f),\epsilon_T(h), ϵT(h,f),ϵT(h), 和 ϵ ^ T ( h ) \hat{\epsilon}_T(h) ϵ^T(h).
4. A bound relating the source and target error
现在, 想要分析一个在 source domian 上训练的分类器在 target domian 上的 generalization error (即 ϵ T ( h ) \epsilon_T(h) ϵT(h)) 是多少. 这个值肯定无法计算出来, 所以最直观的想法就是用 source error (即 ϵ S ( h ) \epsilon_S(h) ϵS(h)) 和 两个域之间的差异来 bound target error.
那么用什么来表示两个域之间的差异呢? 文章首先用 L 1 L^1 L1 Divergence 表示这个差异, 并给出了用 L 1 L^1 L1 Divergence 的 bound.
但是 L 1 L^1 L1 Divergence 有很多缺点, 所以作者提出了第二种方法来表示域之间的差异 – H \mathcal{H} H Divergence, 为了给出相应的 bound, 又将 H \mathcal{H} H Divergence 扩展成 H Δ H \mathcal{H}\Delta\mathcal{H} HΔH Divergence.
a) L 1 L^1 L1 Divergence
也叫 Variation Divergence, Variation Distance, TV Distance.
d 1 ( D , D ′ ) = 2 sup B ∈ B ∣ Pr D [ B ] − Pr D ′ [ B ] ∣ d_1(\mathcal{D}, \mathcal{D}')=2\sup_{B\in\mathcal{B}}|\Pr_\mathcal{D}[B]-\Pr_{\mathcal{D}'}[B]| d1(D,D′)=2B∈Bsup∣DPr[B]−D′Pr[B]∣
其中 B \mathcal{B} B 是在 D \mathcal{D} D 和 D ′ \mathcal{D}' D′ 上所有可测子集的集合.
用两个很简单的一维分布来表示一下:

上面两个: B = [ x 1 , x 3 ] ∨ [ x 2 , x 4 ] = [ x 1 , x 4 ] \mathcal{B}=[x_1,x_3] \vee [x_2,x_4]=[x_1,x_4] B=[x1,x3]∨[x2,x4]=[x1,x4]. 红色区域和蓝色区域的面积是相等的, 因为面积就是概率. 很明显, 对于这两种情况而言, d 1 ( D , D ′ ) d_1(\mathcal{D},\mathcal{D}') d1(D,D′) 就等于2倍蓝色区域面积=2倍红色面积=蓝色面积+红色面积.
下面两个: 两个分布没有重合区域, d 1 ( D , D ′ ) d_1(\mathcal{D},\mathcal{D}') d1(D,D′) 等于2倍的 D \mathcal{D} D 的面积=2倍的 D ′ \mathcal{D}' D′ 的面积=2. 这里很容易发现, 无论 D \mathcal{D} D 与 D ′ \mathcal{D}' D′ 相隔多远, 差异多大, 只要它们没有重合部分, d 1 ( D , D ′ ) d_1(\mathcal{D},\mathcal{D}') d1(D,D′) 永远等于2.
从上图还能得出一个公式:
d 1 ( D , D ′ ) = ∣ ∣ D − D ′ ∣ ∣ 1 = ∫ ∣ D ( x ) − D ′ ( x ) ∣ d x d_1(\mathcal{D},\mathcal{D'}) = ||\mathcal{D}-\mathcal{D'}||_1=\int |\mathcal{D}(x)-\mathcal{D'}(x)| dx d1(D,D′)=∣∣D−D′∣∣1=∫∣D(x)−D′(x)∣dx
其中 D ( x ) \mathcal{D}(x) D(x) 表示 D \mathcal{D} D 的 pdf.
Thm1. 对于任意一个 hypothesis h h h,
ϵ T ( h ) ≤ ϵ S ( h ) + d 1 ( D S , D T ) + min { E D S [ ∣ f S ( x ) − f T ( x ) ∣ ] , E D T [ ∣ f S ( x ) − f T ( x ) ∣ ] } \epsilon_T(h)\leq \epsilon_S(h) + d_1(\mathcal{D}_S, \mathcal{D}_T)+\min \{\mathbf{E}_{\mathcal{D}_S}[|f_S(x)-f_T(x)|],\mathbf{E}_{\mathcal{D}_T}[|f_S(x)-f_T(x)|]\} ϵT(h)≤ϵS(h)+d1(DS,DT)+min{EDS[∣fS(x)−fT(x)∣],EDT[∣fS(x)−fT(x)∣]}
证明:
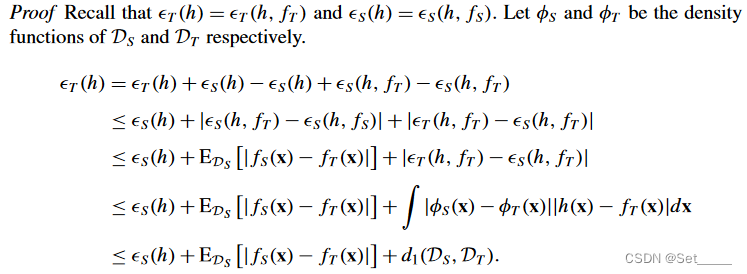
上图是文章给的证明, 前四行很好理解, 解释下最后一行:
∫ ∣ ϕ S ( x ) − ϕ T ( x ) ∣ ∣ h ( x ) − f T ( x ) ∣ d x ≤ ∫ ∣ ϕ S ( x ) − ϕ T ( x ) ∣ d x = d 1 ( D , D ′ ) \int |\phi_S(x)-\phi_T(x)| |h(x)-f_T(x)|dx \leq \int |\phi_S(x)-\phi_T(x)| dx=d_1(\mathcal{D},\mathcal{D'}) ∫∣ϕS(x)−ϕT(x)∣∣h(x)−fT(x)∣dx≤∫∣ϕS(x)−ϕT(x)∣dx=d1(D,D′)
其中 ∣ h ( x ) − f T ( x ) ∣ ≤ 1 |h(x)-f_T(x)| \leq 1 ∣h(x)−fT(x)∣≤1, ∫ ∣ ϕ S ( x ) − ϕ T ( x ) ∣ d x = d 1 ( D , D ′ ) \int |\phi_S(x)-\phi_T(x)| dx=d_1(\mathcal{D},\mathcal{D'}) ∫∣ϕS(x)−ϕT(x)∣dx=d1(D,D′) 在前面讲过. 这里再一次体现了前面提到的缺点, 只要不同, 无论 h , f T h,f_T h,fT 有多远 ∣ h ( x ) − f T ( x ) ∣ |h(x)-f_T(x)| ∣h(x)−fT(x)∣都等于1.
用 L 1 L^1 L1 Divergence 来做 bound 有以下两个缺点: 1) 无法从有限的样本来估计; 2) bound 很松.
b) H \mathcal{H} H Divergence
Def. 1 给定在输入空间 X \mathcal{X} X 上的两个概率分布 D \mathcal{D} D 和 D ′ \mathcal{D'} D′, H \mathcal{H} H 表示 X \mathcal{X} X上的hypothesis space, I ( h ) I(h) I(h) 为指示函数(即 x ∈ I ( h ) ⇔ h ( x ) = 1 x\in I(h)\Leftrightarrow h(x)=1 x∈I(h)⇔h(x)=1). 那么, D \mathcal{D} D 和 D ′ \mathcal{D'} D′ 之间的 H \mathcal{H} H divergence 为:
d H ( D , D ′ ) = 2 sup h ∈ H ∣ Pr D [ I ( h ) ] − Pr D ′ [ I ( h ) ] ∣ d_{\mathcal{H}}(\mathcal{D},\mathcal{D}')=2\sup_{h\in\mathcal{H}}|\text{Pr}_\mathcal{D}[I(h)]-\text{Pr}_{\mathcal{D}'}[I(h)]| dH(D,D′)=2h∈Hsup∣PrD[I(h)]−PrD′[I(h)]∣
I ( h ) I(h) I(h) 可以理解为 h h h 将输入空间分类成 1 1 1 的那部分集合, i.e. I ( h ) = { x ∣ h ( x ) = 1 } I(h)=\{x|h(x)=1\} I(h)={x∣h(x)=1}. 所以 d H d_{\mathcal{H}} dH 就是 I ( h ) I(h) I(h) 在分布 D \mathcal{D} D 和 D ′ \mathcal{D}' D′ 上的概率之差, 其中注意 sup \sup sup over all h ∈ H h \in \mathcal{H} h∈H, 也就是选取令概率之差最大的那个假设 h h h.
H \mathcal{H} H Divergence 的好处是: 1) 可以使用有限的样本来估计, 也就是 d H d_{\mathcal{H}} dH 可以用 d ^ H \hat{d}_{\mathcal{H}} d^H 来近似. 文章给出了 Lemma 2 和 Lemma 1, 分别为 d ^ H \hat{d}_{\mathcal{H}} d^H 的计算公式和使用 VC dimension 作为复杂度计算 d H d_{\mathcal{H}} dH 与 d ^ H \hat{d}_{\mathcal{H}} d^H 的 bound . 2) d H ≤ d 1 d_{\mathcal{H}} \leq d_{1} dH≤d1.
这里 empirical 版本的计算与估计并不重要, 使用不同的复杂度可以得到不同的 bound 方式, 所以跳过 Lemma 1,2.
c) H Δ H \mathcal{H}\Delta\mathcal{H} HΔH Divergence
首先给出一个定义:
Def. 2: h ∗ h^* h∗ 为 ideal joint hypothesis, 它最小化了源域和目标域的联合误差(combined error). 用 λ \lambda λ 表示相对应的combined error:
h ∗ = arg min h ∈ H { ϵ S ( h ) + ϵ T ( h ) } λ = ϵ S ( h ∗ ) + ϵ T ( h ∗ ) h^* = \arg\min_{h\in\mathcal{H}} \{\epsilon_S(h)+\epsilon_T(h)\}\\ \lambda =\epsilon_S(h^*)+\epsilon_T(h^*) h∗=argh∈Hmin{ϵS(h)+ϵT(h)}λ=ϵS(h∗)+ϵT(h∗)
然后给出一个新的 hypothesis space: H Δ H \mathcal{H}\Delta\mathcal{H} HΔH
Def.3 对于一个 hypothesis space H \mathcal{H} H, 它相对应的 H Δ H \mathcal{H}\Delta\mathcal{H} HΔH 空间为:
g ∈ H Δ H ⇔ g ( x ) = h ( x ) ⊕ h ′ ( x ) for some h , h ′ ∈ H g \in \mathcal{H}\Delta\mathcal{H} \Leftrightarrow g(x)=h(x)\oplus h'(x) \text{ for some } h, h'\in\mathcal{H} g∈HΔH⇔g(x)=h(x)⊕h′(x) for some h,h′∈H
举个一维输入空间的简单例子: 考虑这样的一个 hypothesis class:
H : = { h α : α ∈ R } . h α ( x ) = { 1 , α ≥ α 0 , α < α \mathcal{H}:=\{h_\alpha: \alpha\in \mathbb{R}\}.\\ h_\alpha(x)=\left\{\begin{matrix} 1, & \alpha \geq \alpha \\ 0, & \alpha < \alpha \end{matrix}\right. H:={hα:α∈R}.hα(x)={1,0,α≥αα<α
那么, 它相应的 H Δ H \mathcal{H}\Delta\mathcal{H} HΔH 空间就是:
H Δ H = { g α 1 , α 2 : α 1 , α 2 ∈ R } . g α 1 , α 2 = { 1 , x ∈ ( α 1 , α 2 ) 0 , o . w . \mathcal{H}\Delta\mathcal{H}=\{g_{\alpha_1,\alpha_2}:\alpha_1,\alpha_2\in\mathbb{R}\}.\\ g_{\alpha_1,\alpha_2}=\left\{\begin{matrix} 1, & x\in(\alpha_1,\alpha_2)\\ 0, & o.w. \end{matrix}\right. HΔH={gα1,α2:α1,α2∈R}.gα1,α2={1,0,x∈(α1,α2)o.w.
这时, 将 H \mathcal{H} H Divergence 中的假设空间换成 H Δ H \mathcal{H}\Delta\mathcal{H} HΔH 空间, 就得出了 H Δ H \mathcal{H}\Delta\mathcal{H} HΔH Divergence. 如果按照定义从头推算一遍就是:
d H Δ H ( D S , D T ) = 2 sup g ∈ H Δ H ∣ Pr D S [ I ( g ) ] − Pr D T [ I ( g ) ] ∣ = 2 sup h , h ′ ∈ H ∣ Pr x ∼ D S [ h ( x ) ≠ h ′ ( x ) ] − Pr x ∼ D T [ h ( x ) ≠ h ′ ( x ) ] ∣ = 2 sup h , h ′ ∈ H ∣ ϵ S ( h , h ′ ) − ϵ T ( h , h ′ ) ∣ d_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)=2\sup_{g \in \mathcal{H}\Delta\mathcal{H}} |\Pr_{\mathcal{D}_S}[I(g)]-\Pr_{\mathcal{D}_T}[I(g)]|\\ =2\sup_{h,h' \in \mathcal{H}} |\Pr_{x\sim\mathcal{D}_S}[h(x)\neq h'(x)]-\Pr_{x\sim\mathcal{D}_T}[h(x)\neq h'(x)]|\\ =2\sup_{h,h' \in \mathcal{H}} |\epsilon_S(h,h')-\epsilon_T(h,h')| dHΔH(DS,DT)=2g∈HΔHsup∣DSPr[I(g)]−DTPr[I(g)]∣=2h,h′∈Hsup∣x∼DSPr[h(x)=h′(x)]−x∼DTPr[h(x)=h′(x)]∣=2h,h′∈Hsup∣ϵS(h,h′)−ϵT(h,h′)∣
其中第二行是因为, I ( g ) I(g) I(g) 即为 g ( x ) = 1 g(x)=1 g(x)=1 的那部分输入空间的集合, 由 Def.3 可知, g ( x ) = 1 g(x)=1 g(x)=1 等价于 h ( x ) ≠ h ′ ( x ) h(x)\neq h'(x) h(x)=h′(x), 虽然不知道具体哪个 h , h ′ h,h' h,h′, 但只关心在假设空间中令概率差值最大的那两个.
这同时也十分直观的得到了 Lemma 3:
对任意两个 hypotheses h , h ′ h,h' h,h′,
∣ ϵ S ( h , h ′ ) − ϵ T ( h , h ′ ) ∣ ≤ 1 2 d H Δ H ( D S , D T ) |\epsilon_S(h,h')-\epsilon_T(h,h')|\leq\frac{1}{2} d_{\mathcal{H}\Delta\mathcal{H}}(D_S,D_T) ∣ϵS(h,h′)−ϵT(h,h′)∣≤21dHΔH(DS,DT)
有了以上信息, 我们可以用 d H Δ H d_{\mathcal{H}\Delta\mathcal{H}} dHΔH给出 ϵ T \epsilon_T ϵT 的上界:
Thm.2: H \mathcal{H} H 为 VC-dim = d 的假设空间, U S , U T \mathcal{U}_S, \mathcal{U}_T US,UT 为来自于 D S , D T \mathcal{D}_S, \mathcal{D}_T DS,DT 的, 大小为 m ′ m' m′ 的样本. 那么对于任意的 δ ∈ ( 0 , 1 ) \delta\in(0,1) δ∈(0,1) 和任意的 h ∈ H h\in\mathcal{H} h∈H , 以下不等式至少 1 − δ 1-\delta 1−δ 的概率成立:
ϵ T ( h ) ≤ ϵ S ( h ) + 1 2 d H Δ H ( D S , D T ) + λ ≤ ϵ S ( h ) + 1 2 d ^ H Δ H ( U S , U T ) + 4 2 d log ( 2 m ′ ) + log ( 2 δ ) m ′ + λ \epsilon_T(h)\leq\epsilon_S(h)+\frac{1}{2}{d}_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T)+\lambda\\ \leq\epsilon_S(h)+\frac{1}{2}\hat{d}_{\mathcal{H}\Delta\mathcal{H}}(U_S,U_T)+4\sqrt{\frac{2d\log(2m')+\log(\frac{2}{\delta})}{m'}}+\lambda ϵT(h)≤ϵS(h)+21dHΔH(DS,DT)+λ≤ϵS(h)+21d^HΔH(US,UT)+4m′2dlog(2m′)+log(δ2)+λ
同样的, 先忽略 empircal 的那部分, 也就是看不等式的第一行. d H Δ H ( D S , D T ) {d}_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) dHΔH(DS,DT) 表示了两个域的分布之间的差异, 同时与 H \mathcal{H} H 有关. λ \lambda λ 表示的是 H \mathcal{H} H 在两个域上最小的联合错误率, 其实也蕴含了两个域分布之间的关系, 同时又与 H \mathcal{H} H 有关. 所以 ϵ T ( h ) − ϵ S ( h ) \epsilon_T(h)-\epsilon_S(h) ϵT(h)−ϵS(h) 用 d H Δ H ( D S , D T ) {d}_{\mathcal{H}\Delta\mathcal{H}}(\mathcal{D}_S,\mathcal{D}_T) dHΔH(DS,DT) 和 λ \lambda λ 进行 bound 很合理.
证明十分简单, 主要就是用到 triangle inequality, 文章中也给出了完整的证明过程, 这里就不粘贴了.
5. A learning bound combining source and target training data
现在考虑这样的学习模式:
训练集为 S = ( S T , S S ) S=(S_T,S_S) S=(ST,SS), 其中 S T S_T ST 为 β m \beta m βm 个从分布 D T \mathcal{D}_T DT 中独立抽取的实例, S S S_S SS 为 ( 1 − β ) m (1-\beta)m (1−β)m 个从分布 D S \mathcal{D}_S DS 中独立抽取的实例. 学习的目标是寻找一个 h h h 以最小化 ϵ T ( h ) \epsilon_T(h) ϵT(h). 这里考虑使用 ERM, 但 Domain adaptation 任务中 β \beta β 往往很小, 所以直接最小化 target error 不合适. 作者考虑在训练过程中, 最小化 source error 和 target error 的和:
ϵ ^ α ( h ) = α ϵ ^ T ( h ) + ( 1 − α ) ϵ ^ S ( h ) \hat{\epsilon}_\alpha(h)=\alpha\hat{\epsilon}_T(h)+(1-\alpha)\hat{\epsilon}_S(h) ϵ^α(h)=αϵ^T(h)+(1−α)ϵ^S(h)
其中 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1]. 接下来, 文章给出了两个 定理, 分别为 ϵ T ( h ) \epsilon_T(h) ϵT(h) 与 ϵ α ( h ) \epsilon_\alpha(h) ϵα(h) 之间的bound (Lemma 4) 和 ϵ α ( h ) \epsilon_\alpha(h) ϵα(h) 与 ϵ ^ α ( h ) \hat{\epsilon}_\alpha(h) ϵ^α(h) 之间的 bound (Lemma 5).
Lemma. 4:
对于任意一个 h ∈ H h\in\mathcal{H} h∈H,
∣ ϵ α ( h ) − ϵ T ( h ) ∣ ≤ ( 1 − α ) ( 1 2 d H Δ H ( D S , D T ) + λ ) |\epsilon_\alpha(h)-\epsilon_T(h)|\leq(1-\alpha)\left(\frac{1}{2} d_{\mathcal{H}\Delta\mathcal{H}}(D_S,D_T)+\lambda \right) ∣ϵα(h)−ϵT(h)∣≤(1−α)(21dHΔH(DS,DT)+λ)
证明同样依赖于 用到 triangle inequality:
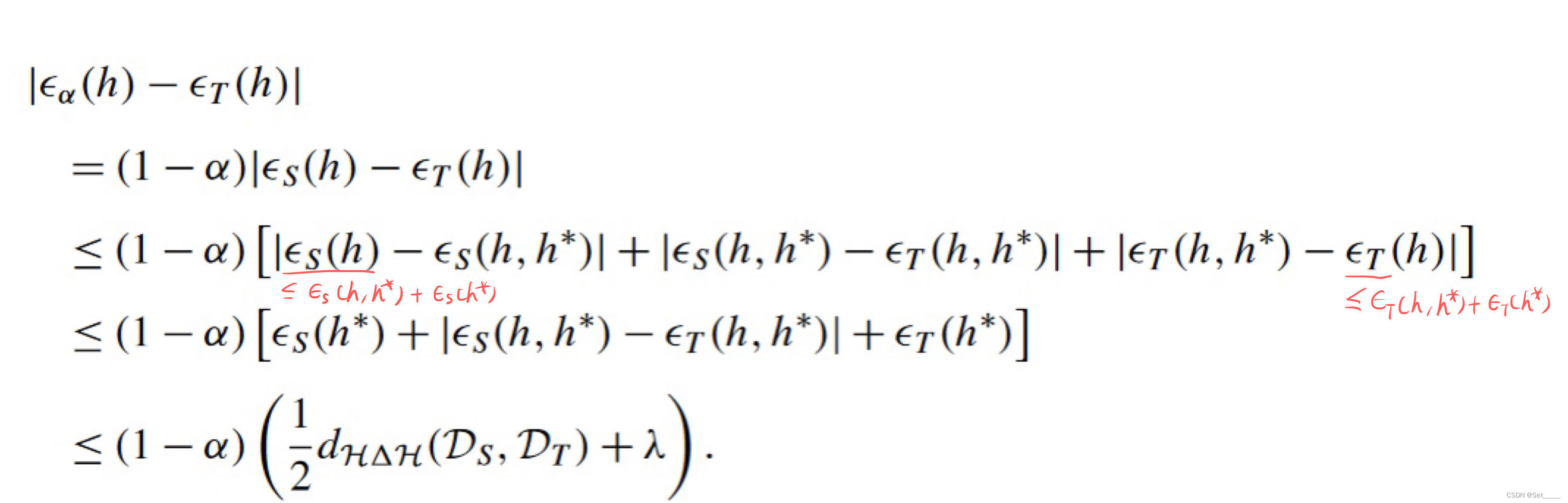
而且如果把 Lemma 4 左边的 ϵ α \epsilon_\alpha ϵα 展开, 再左右两边消掉 ( 1 − α ) (1-\alpha) (1−α), 此时 Lemma 4 与 Thm.2 其实是等价的.
Lemma 5: 对于一个 hypothesis h h h, 如果训练样本是由 β m \beta m βm 个从分布 D T \mathcal{D}_T DT 中独立抽取的实例和 ( 1 − β ) m (1-\beta)m (1−β)m 个从分布 D S \mathcal{D}_S DS 中独立抽取的实例构成的, 且这些实例被 f S , f T f_S, f_T fS,fT 打上标签. 那么, 对于任何的 δ ∈ ( 0 , 1 ) \delta\in(0,1) δ∈(0,1), 下式至少有 1 − δ 1-\delta 1−δ 的概率成立:
Pr [ ∣ ϵ ^ α ( h ) − ϵ α ( h ) ∣ ≥ ϵ ] ≤ exp [ − 2 m ϵ 2 α 2 β + ( 1 − α ) 2 1 − β ] \Pr[|\hat{\epsilon}_\alpha(h)-\epsilon_\alpha(h)|\geq \epsilon]\leq\exp[\frac{-2m\epsilon^2}{\frac{\alpha^2}{\beta}+\frac{(1-\alpha)^2}{1-\beta}}] Pr[∣ϵ^α(h)−ϵα(h)∣≥ϵ]≤exp[βα2+1−β(1−α)2−2mϵ2]
证明依赖于 Hoeffding Inequality, 我在这篇博客中给了 2) Chernoff bound, Hoeffding’s Lemma, Hoeffding’s inequality 定理的介绍和推导.
证明:
按 ϵ ^ α \hat{\epsilon}_{\alpha} ϵ^α 的定义和 empirical error 的定义展开, 有:
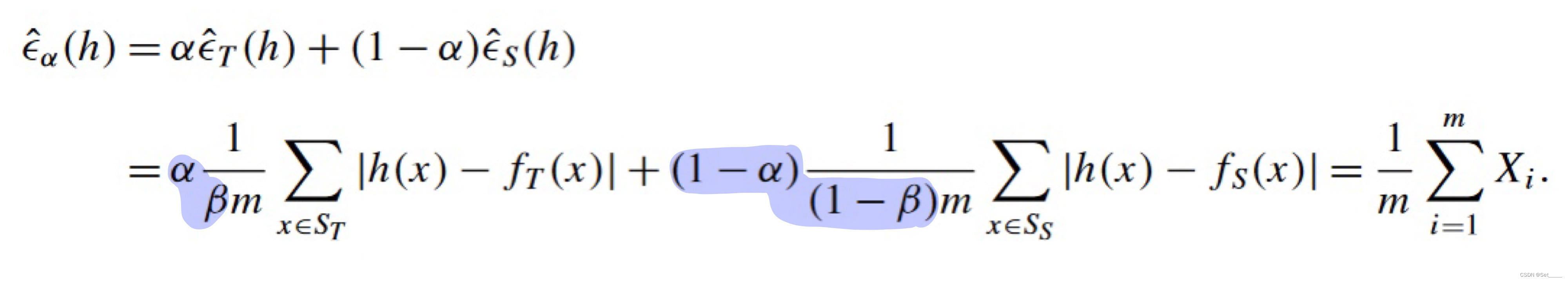
这个形式就很容易观察了.
令 X 1 , . . . , X β m X_1,..., X_{\beta m} X1,...,Xβm 表示值为 α β ∣ h ( x ) − f T ( x ) ∣ \frac{\alpha}{\beta}|h(x)-f_T(x)| βα∣h(x)−fT(x)∣ 的随机变量.
令 X β m + 1 , . . . , X m X_{\beta m + 1},..., X_{m} Xβm+1,...,Xm 表示值为 1 − α 1 − β ∣ h ( x ) − f S ( x ) ∣ \frac{1-\alpha}{1-\beta}|h(x)-f_S(x)| 1−β1−α∣h(x)−fS(x)∣ 的随机变量.
那么, 很容易计算出 ϵ ^ α ( h ) = 1 m ∑ i = 1 m X i \hat{\epsilon}_{\alpha}(h)=\frac{1}{m}\sum_{i=1}^m X_i ϵ^α(h)=m1∑i=1mXi , 且 E [ ϵ ^ α ( h ) ] = ϵ α ( h ) \mathbf{E}[\hat{\epsilon}_{\alpha}(h)]=\epsilon_{\alpha}(h) E[ϵ^α(h)]=ϵα(h), 所以直接应用 Hoeffding Inequality 就得到 Lemma 5 的不等式.
未完待续.