一、原理
该文章仅用于信息防御技术教学,请勿用于其他用途。
1、XSS原理
XSS(跨站脚本攻击)是一种常见的网络安全漏洞,攻击者通常会在网页中插入恶意的 JavaScript 代码。由于服务器对输入数据的过滤和验证不严格,这些恶意的 JavaScript 代码会被当作响应的一部分返回给客户端。当浏览器解析来自服务器的响应时,它会执行这些恶意的 JavaScript 代码,从而导致攻击者能够执行恶意操作。
二、解析及其解码
1、代码解析顺序
s1、DOM树的构建与HTML标记的解析
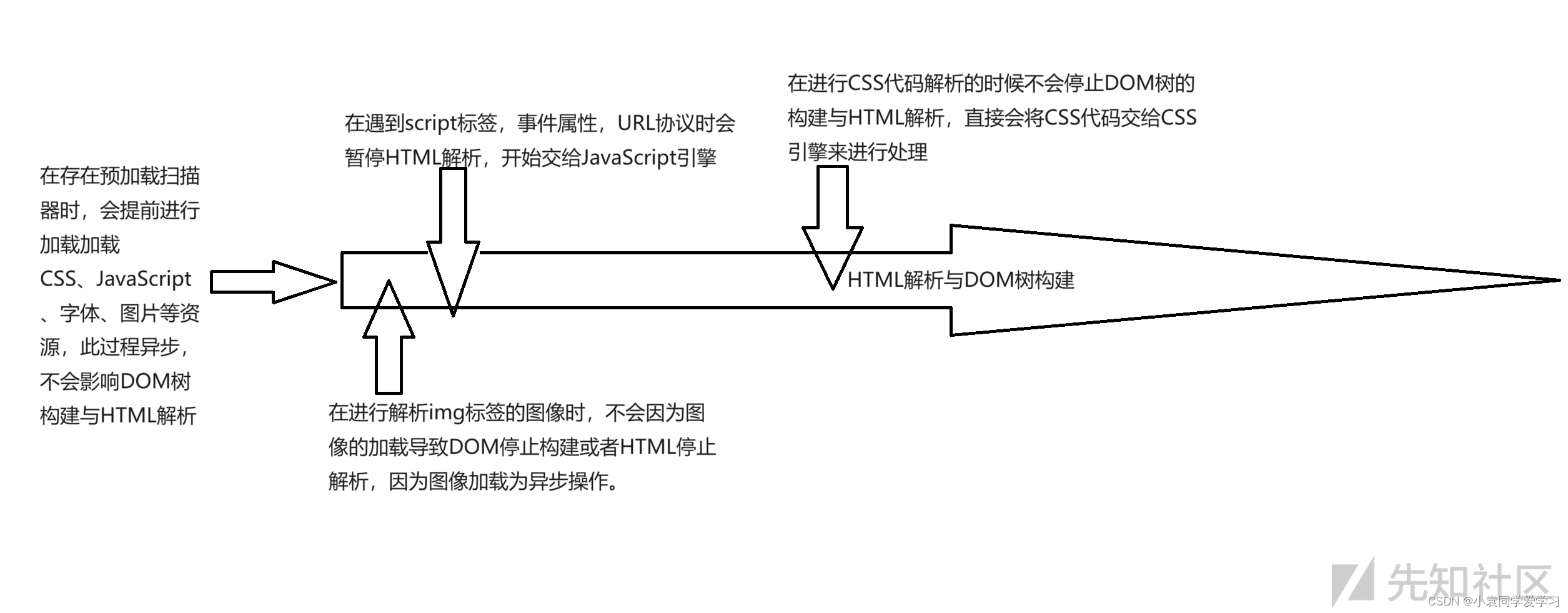
当浏览器收到来自服务端的代码后,会先进行DOM树的构建与HTML标记的解析。
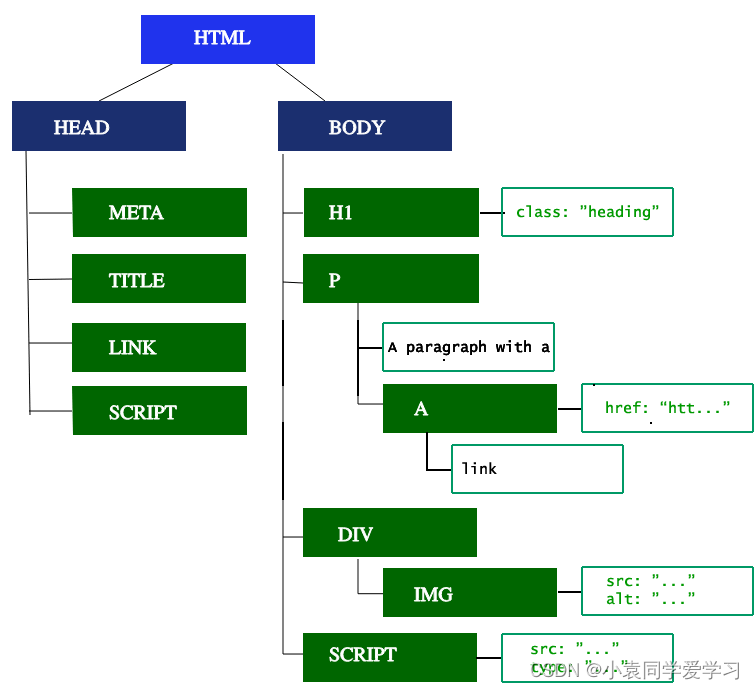
先来说HTML标记的解析,HTML 标记包括开始和结束标记,以及属性名和值。如果文档格式良好,则解析它会简单而快速。解析器将标记化的输入解析到文档中,构建文档树。
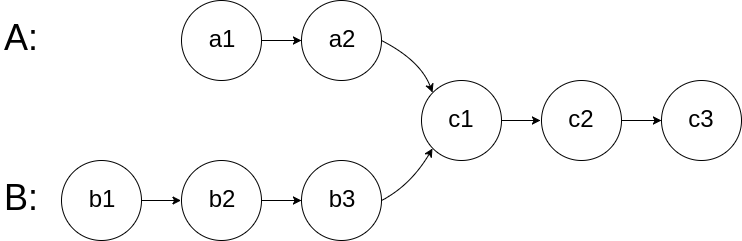
在来说说DOM树的构建,DOM 树描述了文档的内容。元素是第一个标签也是文档树的根节点。树反映了不同标记之间的关系和层次结构。嵌套在其他标记中的标记是子节点(如下图的
,
s2、对JavaScript代码的解析
在遇到JavaScript代码时,HTML解析器会暂停解析,并将控制权交给JavaScript引擎,执行JavaScript代码。一旦JavaScript代码执行完毕,HTML解析器会继续解析未解析的HTML内容。
这种行为称为"阻塞解析",因为HTML解析器会等待JavaScript代码执行完毕后才能继续解析后续的HTML内容。这意味着,如果JavaScript代码的执行时间过长,会导致页面加载的延迟。
为了改善页面加载性能,可以使用async或defer属性来加载JavaScript文件。当使用async属性时,浏览器会异步加载JavaScript文件,并继续解析HTML内容,不会阻塞解析。而使用defer属性时,浏览器会异步加载JavaScript文件,但会等到HTML解析完毕后再执行JavaScript代码,不会阻塞解析。
需要注意的是,当JavaScript代码执行时,如果该代码修改了DOM结构或样式,可能会触发浏览器重新构建DOM树和应用样式,从而导致页面的重绘和回流,影响页面的性能。
那么浏览器是怎么知道什么时候开始解析JavaScript代码?
正常在遇到
当浏览器遇到下面的两类会先进行HTML标记解析然后进行JavaScript解析,当HTML无法解析时就会来将控制权交给JavaScript引擎来执行JavaScript代码,假如JavaScript引擎也无法进行解析,那么这段代码就有问题了。
事件属性,例如onload,onerror等
URL协议,例如javascript伪协议等
这也就是为什么有时候在某个页面插入了XSS弹窗后,假如你不点击你的弹窗的相应的操作,某些元素就无法进行加载。
s3、对CSS代码的解析
在遇到CSS代码时,浏览器不会像JavaScript代码一样去停止HTML标记的解析,相反它会继续进行HTML代码的解析,并且将CSS代码交给CSS引擎来进行处理。
2、解码顺序
一般情况下,解码顺序是按照HTML实体化解码–>JavaScript解码进行的。
Q1、什么是HTML实体化解码?
如果服务器与客户端之间要传输某个特殊字符,像是<>,'等这类会被当做标签或者属性值等来解析的字符,为了避免歧义就需要使用到HTML实体化编码来进行编码了。
Q2、HTML编码的几种方式
别名形式:因为比较多可以见HTML 字符实体 (w3school.com.cn)
十六进制:像
十进制:上述标签在十进制会被编码为<div>
Q3、为什么需要JavaScript解码?
通过JavaScript编码,可以对特殊字符进行转义,防止数据在传输过程中产生语法错误或安全漏洞。例如,对于包含特殊字符(如引号、尖括号等)的数据,可以使用转义字符进行编码,以确保数据的完整性和安全性。
Q4、明明有了HTML实体化编码为什么是还需要JavaScript编码
在HTML进行解析的时候,遇到了
Q5、JS编码有哪些方式?
以\uxxxx,\UXXXXXXXX,\xXX都是JavaScript编码
但是注意:某些特殊字符不能够进行JavaScript编码,否则浏览器无法进行解析,如:
< > ’ " ( )
举个栗子:
特别的:
在线工具见:在线编码转换工具(utf-8/utf-32/Punycode/Base64) - 编码转换工具 - 脚本之家在线工具 (jb51.net)
URL编码在进行GET传参的时候可以使用
三、XSS实战
1、基础XXS
基础的payload就这几种见如下表(当然还有很多,这里列出部分)
当然也可以使用fuzz,分别插入大量的XSSpayload,根据回显的不同来挑出可用的payload。
3、攻击位置
留言板处、搜索框、个人资料等
这类通常是比较好进行插入的,直接在可以输入的地方直接输入payload即可。
Markdown编辑器
下面是一个Markdown当中插入超链接的一个操作。
Click Me
在转换为HTML代码后为
Click Me
下面是一个插入图片的Markdown语法,与上面不同的是下面的最前面会有一个感叹号
在转换为HTML代码后为
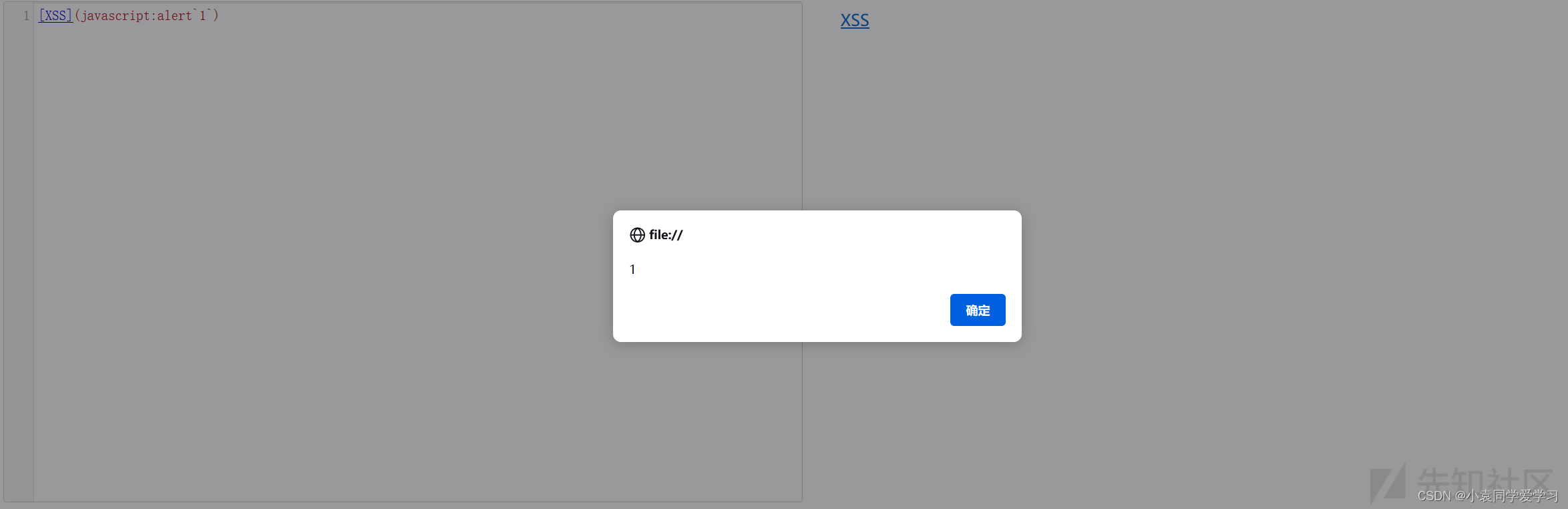
 第一种:使用伪协议进行超链接处XSS 直接进行插入此XSS代码会被解析为超链接,点击后就会弹窗。
第一种:使用伪协议进行超链接处XSS 直接进行插入此XSS代码会被解析为超链接,点击后就会弹窗。
a

按照Markdown语法进行插入(此处使用了反引号来代替了(),因为我测试了多个网站发现小括号不能被解析),此处可以见XSS编码绕过。
第二种、使用插入图片的方式插入XSS代码
对于图片的插入方式很明确,要么我们直接插入标签的XSSpayload,要么直接插入以Markdown形式的XSS
对于第一种来说,直接进行插入XXS代码

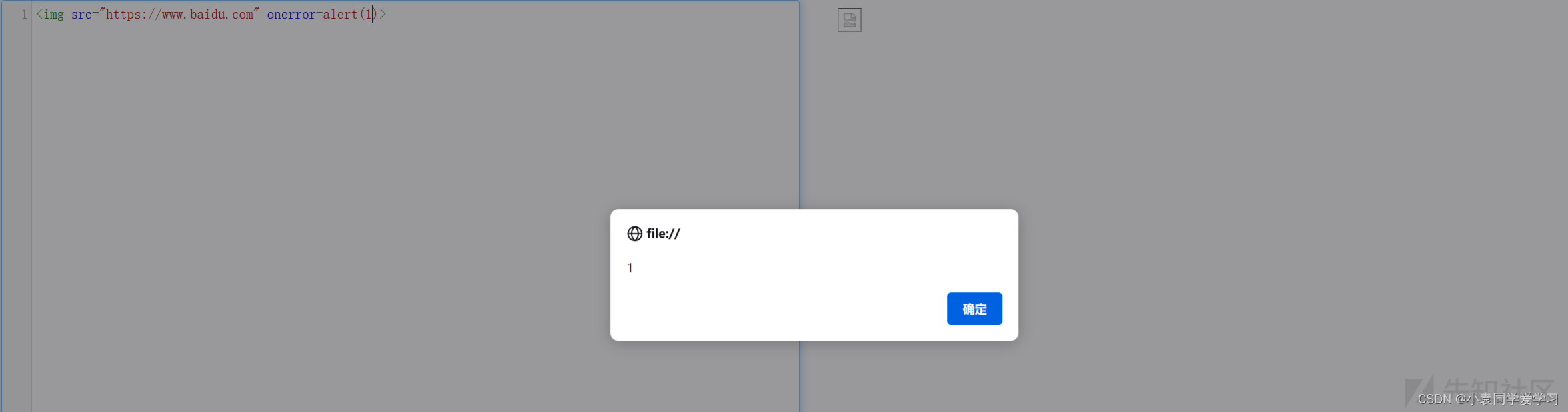
对于第二种来说,我们需要逃逸出src属性或者alt属性当中的双引号,然后直接在后面接上onerror等属性即可。
逃逸alt属性(暂时没有测试成功)
PDF XSS
有关于在pdf文档当中插入xss代码的步骤见下图
成功制作好PDF文件后,直接使用浏览器打开,就会弹窗(各个浏览器可能会不太一样)。
但是这不是我们最终的目的,在本地弹窗的意义不大,我们需要让某个网站在线解析或者打开我们制作好的PDF文件才可以,当然防御的方法就是用户在打开PDF文件时候,强制让用户在本地下载打开。
文件上传XSS
第一类:修改文件后缀
文件上传当中,修改后缀名为.html,.htm然后在文件内容当中插入XSS代码
1、如何进行攻击?
在进行文件上传时进行抓包
修改数据包当中文件后缀为html或者htm
在文件内容当中插入XSS语句
放包,观察弹窗
第二类:svg中写入XSS
当然如果网站支持svg格式的文件进行上传的话,可以上传带有XSS的svg文件,具体文件如下
1、什么是svg?
SVG允许3种图形物件类型:矢量图形、栅格图像以及文本。图形物件——包括PNG、JPEG这些栅格图像——能够被编组、设计、转换及集成进先前的渲染物件中。文本可以在任何适用于应用程序的XML命名空间之内,从而提高SVG图形的搜索能力和无障碍性。SVG提供的功能集涵盖了嵌套转换、裁剪路径、Alpha通道、滤镜效果、模板对象以及可扩展性。
SVG严格遵从XML语法,并用文本格式的描述性语言来描述图像内容,因此是一种和图像分辨率无关的矢量图形格式。
SVG文件还可嵌入JavaScript(严格地说,应该是ECMAScript)脚本来控制SVG对象。
2、如何生成payload?
4、如何进行攻击?
由于svg格式的文件可以执行JavaScript代码,所以我们直接上传带有xss代码的svg文件即可,然后打开它,就可以执行恶意的xss语句。
第三类:exif写入
当然还有一种方法就是使用exiftool进行XSS代码嵌入(Metadata写入)
前提就是需要网站解析图片的exif信息才可以成功使用此方法(当然没有解析也可以试试)
1、什么是exif?
可交换图像文件格式(英语:Exchangeable image file format,官方简称Exif),是专门为数码相机的照片设定的文件格式,可以记录数码照片的属性信息和拍摄数据。
Exif最初由日本电子工业发展协会在1996年制定,版本为1.0。1998年,升级到2.1版,增加了对音频文件的支持。2002年3月,发表了2.2版。
Exif可以附加于JPEG、TIFF、RIFF等文件之中,为其增加有关数码相机拍摄信息的内容和索引图或图像处理软件的版本信息。
2、怎么在图片当中写入payload?
下载exiftool
准备好一张图片
打开shell执行 exiftool -Comment=“ filename.png”(-Comment为指定的exif名称,等号后面为其值)
3、如何使用exif进行攻击?
下载一张图片
查看其具体信息
写入payload
上传图片到服务器当中
查看图片或者其他操作,可能会进行弹窗
由于篇幅有限还有部分XSS攻击方式暂时无法呈现
四、XSS防御
逻辑层次
针对一般XSS的防御---->过滤/HTML实体化编码特殊字符:<> ’ "等。
对于PDF XSS的防御---->强制用户下载要打开的PDF文件
对于文件上传XSS的防御----> 检查文件内容,检查后缀格式,剥离exif标签
代码层次
主要是对于HTML标签的剥离
PHP的htmlentities()或是htmlspecialchars()。
Python的cgi.escape()。
ASP的Server.HTMLEncode()。
ASP.NET的Server.HtmlEncode()或功能更强的Microsoft Anti-Cross Site Scripting Library
Java的xssprotect (Open Source Library)
Node.js的node-validator。
HTTP头层次
设置以下的响应头
X-XSS-Protection
通过设置其值为1,启用浏览器的XSS防护,浏览器会做出下面的措施:
自动关闭或过滤掉潜在的XSS攻击脚本:浏览器会检测响应内容是否包含恶意脚本,并自动关闭或过滤掉这些脚本,防止它们被执行。
重定向到安全页面:如果浏览器检测到具有潜在XSS威胁的内容,它可能会将用户重定向到一个更安全的页面,以防止攻击脚本的执行。
X-Download-Options
通过设置其值为noopen,使得浏览器下载文件时不自动打开,不关联下载文件和浏览器内嵌程序。这样可以防止一些特定类型的文件(例如html、pdf等)被当作网页打开,降低XSS攻击的风险。
X-Content-Type-Options
通过设置X-Content-Type-Options头的值为"nosniff",可以防止浏览器将响应内容以错误的方式解析,减少了XSS攻击的风险。
X-Frame-Options
通过设置X-Frame-Options头,可以阻止通过嵌入iframe或frame的方式进行点击劫持攻击。可以设置该头的值为"DENY",“SAMEORIGIN"或"ALLOW-FROM <域名>”。
Content Security Policy(CSP)
通过设置CSP头,可以限制资源加载的来源,以防止执行不受信任的脚本。CSP可以指定允许的域名、允许的脚本类型以及其他安全策略。
HttpOnly
当一个 cookie 设置了 HttpOnly 标志后,浏览器会禁止通过 JavaScript 脚本来读取这个 cookie 的值。这意味着即使有 XSS 攻击成功注入了恶意脚本,也无法从受害者浏览器中获取敏感的 cookie 值,从而有效防止了 cookie 盗取和会话劫持攻击。
但是HttpOnly不能够完全防御XSS,只能减少XSS带来的危害。
下面是不同语言设置HttpOnly的方式(仅供参考):
PHP
setcookie(‘cookie_name’, ‘cookie_value’, time()+3600, ‘/’, ‘’, false, true); // 最后一个参数设置为 true 表示设置 HttpOnly 标志,false 表示不设置
Java
import javax.servlet.http.Cookie;
Cookie cookie = new Cookie(“cookie_name”, “cookie_value”);
cookie.setMaxAge(3600);
cookie.setPath(“/”);
cookie.setHttpOnly(true); // 设置 HttpOnly 标志
response.addCookie(cookie);
Python(Django 框架)
response.set_cookie(‘cookie_name’, ‘cookie_value’, max_age=3600, httponly=True) # 设置 httponly=True 表示设置 HttpOnly 标志
ASP.NET
HttpCookie cookie = new HttpCookie(“cookie_name”, “cookie_value”);
cookie.Expires = DateTime.Now.AddHours(1);
cookie.HttpOnly = true; // 设置 HttpOnly 标志
Response.Cookies.Add(cookie);
安全设备及安全软件
过滤数据包当中的XSS代码
五、XSS绕过
某些特殊字符绕过
(空格绕过)
空格使用由/来进行替代,例如:
<img/src=x/οnerrοr=alert(1)>
()括号绕过
空格有`来进行代替,例如:
<img src=x οnerrοr=alert1>
大小写绕过
由于正则表达式的不严密导致可以使用大小写来进行绕过
解决方案:使用正则表达式忽略大小写的模式
双写绕过
由于只进行了一次关键字符的替换导致可以被双写绕过
解决方案:循环检测关键字符
编码绕过
利用文章开头提到的编码顺序进行编码payload,例如:
<img src=# οnerrοr=alert(‘xss’)>
经过JavaScript编码(unicode编码)后为
<img src=# οnerrοr=\u0061\u006C\u0065\u0072\u0074(‘\u0078\u0073\u0073’)>
经过HTML实体化编码后为
标签绕过
假如所有HTML标签都被过滤,可以尝试自定义标签来进行绕过。
锚点:#可以迅速定位到某个id,或者class的位置,只要能让锚点指向到我们自定义标签,然后在自定义标签当中写入onfocus事件就可以直接完成XSS。
首先写入一个自定义标签的XSS,注意标注id值,与tabIndex的值
tabIndex的作用见:tabindex - HTML(超文本标记语言) | MDN (mozilla.org),主要目的是让自定义标签获得focus在GET请求最后追加上锚点+id值,直接进行访问即可。
https://xxxxx.com?id=#qweasd
假如是存储型XSS可以直接进行加上锚点访问。
解决方案:禁止<>的输入或者进行HTML编码
CSP绕过
篇幅有限,见大佬文章:
Content Security Policy 入门教程 - 阮一峰的网络日志 (ruanyifeng.com)
我的CSP绕过思路及总结 - 先知社区 (aliyun.com)
HttpOnly绕过
可以使用CVE-2012-0053来尝试进行绕过,通过给网站插入超长Cookie值,当http头部大于apache的最大长度,apache便会返回400错误,状态页中就包含了httponly保护的cookie。
在实战当中可以XSS平台当中的模块来实现此功能,因为实在是不好复现。
也可以利用phpinfo页面来输出Cookie值
当然也可以表单(登录框)劫持数据,但是要注意同源策略的限制。
解决方案:升级apache到最新版,删除phpinfo页面,过滤危险XSS代码。