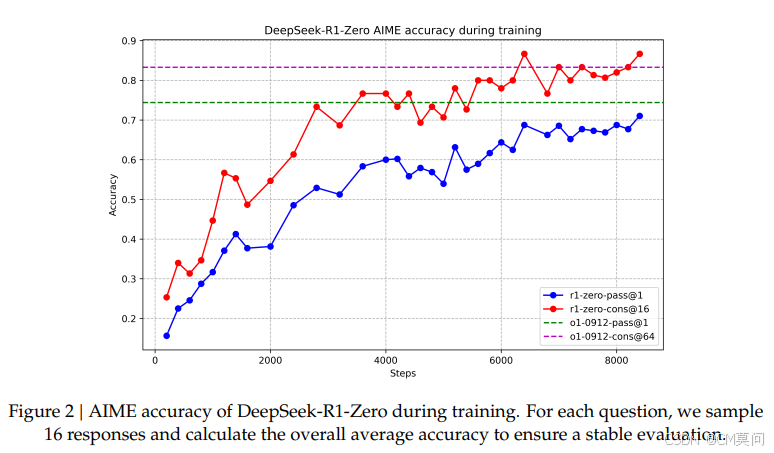
ds复杂度分析:
-
双指针遍历:使用两个指针
i和j,其中i指向待填充的位置,j用于遍历数组。两个指针均单向移动,不会回退,保证了每个元素最多被访问一次。 -
处理重复元素:
- 连续重复元素:当
nums[j] == nums[j+1]时,将这两个元素放到i和i+1的位置,随后i增加2。接着通过内部while循环将j直接跳到第一个大于当前值的元素,跳过所有重复项。这部分操作使得每个重复元素仅被处理一次。 - 无重复元素:直接交换
i和j的元素,并递增i和j,每个元素处理一次。
- 连续重复元素:当
-
操作次数:无论数组是否包含重复元素,每个元素最多被访问两次(一次由
j遍历,另一次在while跳过重复时),但总体操作次数与数组长度成线性关系。
综上,算法的时间复杂度为 O(n),空间复杂度为 O(1)(原地修改数组)。
实测提交到leetcode时4-10ms居多,所以该做法时间复杂度比题解区大神做法略高,在此仅作提供思路用。
class Solution {
public:int removeDuplicates(vector<int>& nums) {int i, j, n = nums.size(); // 双指针,i为answer,j为operationfor(i = 0,j = 0;j<n;) {if(j<n-1 && nums[j]==nums[j+1]) { // 两个相同新元素int t = nums[j];swap(nums[i], nums[j]);swap(nums[i+1], nums[j+1]);i+=2;while(j<n && nums[j]<=t) j++; // 利用数组的正序,保证下一个操作的元素是新的} else {swap(nums[i++],nums[j++]);}}return i;}
};




![[笔记] 汇编杂记(持续更新)](https://i-blog.csdnimg.cn/direct/6d56fc7688384b6a833fe0357f7747fe.png)