如果对于二叉搜索树不是太清楚,为什么要使用二叉搜索树?作者推荐:二叉搜索树的初步认识_加瓦不加班的博客-CSDN博客
定义节点
static class BSTNode {int key; // 若希望任意类型作为 key, 则后续可以将其设计为 Comparable 接口Object value;BSTNode left;BSTNode right;public BSTNode(int key) {this.key = key;this.value = key;}public BSTNode(int key, Object value) {this.key = key;this.value = value;}public BSTNode(int key, Object value, BSTNode left, BSTNode right) {this.key = key;this.value = value;this.left = left;this.right = right;}
}查询
参照图:

递归实现
//解题思路:从根节点出发 比根节点大的向右找 比根节点小的向左找 如果相等则返回
public Object get(int key) {return doGet(root, key);
}
//查询方法:递归实现
private Object doGet(BSTNode node, int key) {if (node == null) {return null; // 没找到}if (key < node.key) {return doGet(node.left, key); // 向左找} else if (node.key < key) {return doGet(node.right, key); // 向右找} else {return node.value; // 找到了}
}非递归实现
public Object get(int key) {BSTNode node = root;while (node != null) {if (key < node.key) {node = node.left;} else if (node.key < key) {node = node.right;} else {return node.value;}}return null;
}Comparable
随便给个泛型T就能参与大小比较吗?不能,所以我们要对T进行限制,让它能够参与大小比较,那么就需要实现一个接口: Comparable 接口
如果希望让除 int 外更多的类型能够作为 key,一种方式是 key 必须实现 Comparable 接口。
代码实现:
//<T extends Comparable<T>>:将来我的泛型T就有个上限了,必须是Comparable的子类型,那么T就再也不是任意类型
public class BSTTree2<T extends Comparable<T>> {static class BSTNode<T> {T key; // 若希望任意类型作为 key, 则后续可以将其设计为 Comparable 接口Object value;BSTNode<T> left;BSTNode<T> right;public BSTNode(T key) {this.key = key;this.value = key;}public BSTNode(T key, Object value) {this.key = key;this.value = value;}public BSTNode(T key, Object value, BSTNode<T> left, BSTNode<T> right) {this.key = key;this.value = value;this.left = left;this.right = right;}}//定义根节点BSTNode<T> root;public Object get(T key) {return doGet(root, key);}//注意:key.compareTo(p.key)的方法比较//-1: key p.key//0: key =p.key//1: key p.key//递归的实现private Object doGet(BSTNode<T> node, T key) {if (node == null) {return null;}int result = node.key.compareTo(key);if (result > 0) {return doGet(node.left, key);} else if (result < 0) {return doGet(node.right, key);} else {return node.value;}}//非递归的实现//注意:key.compareTo(p.key)的方法比较//-1: key p.key//0: key =p.key//1: key p.key//非递归的实现public Object get(T key){BSTNode<T> p=root;while (p!=null){int result = key.compareTo(p.key);if(result<0){p=p.left;}else if(result>0){p=p.right;}else {return p.value;}}return null;}}还有一种做法不要求 key 实现 Comparable 接口,而是在构造 Tree 时把比较规则作为 Comparator 传入,将来比较 key 大小时都调用此 Comparator 进行比较,这种做法可以参考 Java 中的 java.util.TreeMap
当然我们也可以实现像Map一样的格式,给value也加个泛型,然后我们将key的泛型修改一下名字,就更像Map<K,V>:
public class BSTTree2<K extends Comparable<K>, V> {
static class BSTNode<K, V> {K key;V value;BSTNode<K, V> left;BSTNode<K, V> right;public BSTNode(K key) {this.key = key;}public BSTNode(K key, V value) {this.key = key;this.value = value;}public BSTNode(K key, V value, BSTNode<K, V> left, BSTNode<K, V> right) {this.key = key;this.value = value;this.left = left;this.right = right;}
}BSTNode<K, V> root;public V get(K key) {BSTNode<K, V> p = root;while (p != null) {/*-1 key < p.key0 key == p.key1 key > p.key*/int result = key.compareTo(p.key);if (result < 0) {p = p.left;} else if (result > 0) {p = p.right;} else {return p.value;}}return null;}
}但是后面,我们为了更加使得我们小白能够更好理解代码,我们还是以int key,object value来实现后续的代码。
查询最小值
参照图:

递归实现
思路:从根节点开始,一直往左走,一直走到最后的节点没有左孩子就停止
//思路:从根节点开始,一直往左走,一直走到最后的节点没有左孩子就停止
public Object min() {return doMin(root);
}public Object doMin(BSTNode node) {if (node == null) {//当给的节点为Null 我们就不需要去找return null;}// 左边已走到头if (node.left == null) { //最小的节点return node.value;}return doMin(node.left);
}非递归实现
public Object min() {if (root == null) {return null;}BSTNode p = root;// 左边未走到头while (p.left != null) {p = p.left;}return p.value;
}查询最大值
参考:其实现方法与《最小》的操作基本上是一样的

递归实现
public Object max() {return doMax(root);
}public Object doMax(BSTNode node) {if (node == null) {return null;}// 右边已走到头if (node.left == null) { return node.value;}return doMin(node.right);
}非递归实现
public Object max() {if (root == null) {return null;}BSTNode p = root;// 右边未走到头while (p.right != null) {p = p.right;}return p.value;
}新增操作
参考图:

解题思路:
//1.key在该二叉树中有 那就更新key所对应的value值
//2.key在该二叉树中没有 那就新增key与所对应的value值
新增前:
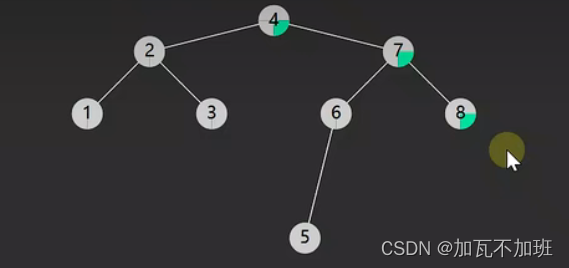
新增后:

图示解析:以上述图为例,新增前,从根节点开始找,找到8时,9大于8,那么就要要继续向右找,但是此时前进不了了,因为8已经是叶子节点,走到头还没有找到9,那么就新增9连通值一起创建出来,做为8的右孩子新增进去。
递归实现
public void put(int key, Object value) {root = doPut(root, key, value);
}private BSTNode doPut(BSTNode node, int key, Object value) {if (node == null) {return new BSTNode(key, value);}if (key < node.key) {node.left = doPut(node.left, key, value);} else if (node.key < key) {node.right = doPut(node.right, key, value);} else {node.value = value;}return node;
}
若找到 key,走 else 更新找到节点的值
若没找到 key,走第一个 if,创建并返回新节点
返回的新节点,作为上次递归时 node 的左孩子或右孩子
缺点是,会有很多不必要的赋值操作
非递归实现
public void put(int key, Object value) {BSTNode node = root;BSTNode parent = null;while (node != null) {parent = node;// 4 7 8if (key < node.key) {node = node.left;} else if (node.key < key) {node = node.right;//4->7 7->8 8->null} else {// 1. key 存在则更新node.value = value;return;}}// 2. key 不存在则新增if (parent == null) {//当我二叉树是null,那么parent初始就是Null 那么新增的key就是根节点root = new BSTNode(key, value);} else if (key < parent.key) {parent.left = new BSTNode(key, value);} else {parent.right = new BSTNode(key, value);}
}查询节点的前驱后继
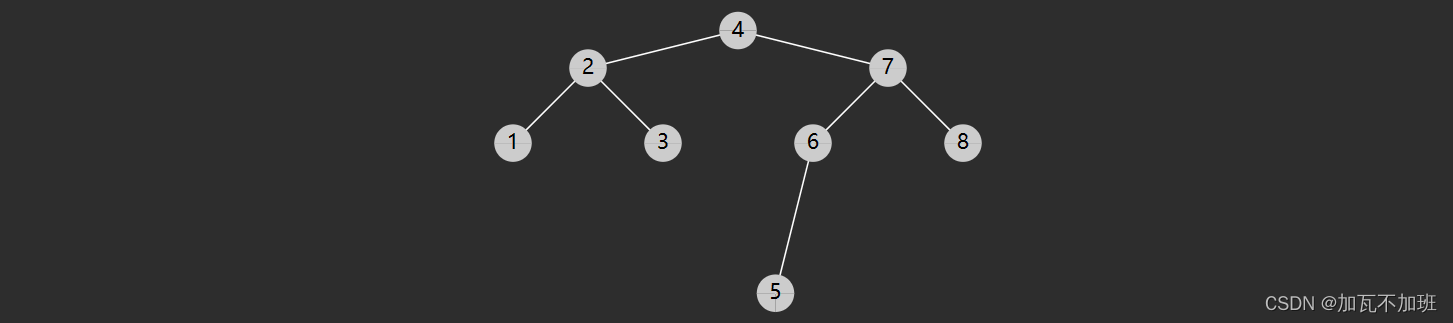
什么叫屈曲与后继?
答:
一个节点的前驱(前任)节点是指比它小的节点中,最大的那个
一个节点的后继(后任)节点是指比它大的节点中,最小的那个
1 2 3 4 5 6 7 8
例如上图中
1 没有前驱,后继是 2
2 前驱是 1,后继是 3
3 前驱是 2,后继是 4
...
查询节点前驱
简单的办法是中序遍历,即可获得排序结果,此时很容易找到前驱后继
二叉树的中序遍历就是升序的结果
要效率更高,需要研究一下规律,找前驱分成 2 种情况:

-
节点有左子树,此时前驱节点就是左子树中的最大值, 图中属于这种情况的有
-
2 的前驱是1
-
4 的前驱是 3
-
6 的前驱是 5
-
7 的前驱是 6
个人理解:比如:(4的前驱节点有 1 2 3,其中最大值就是3)
-
-
节点没有左子树,若离它最近的祖先自从左而来,此祖先即为前驱,如
-
3 的祖先 2 自左而来,前驱 2
-
5 的祖先 4 自左而来,前驱 4
-
8 的祖先 7 自左而来,前驱 7
-
1 没有这样的祖先,前驱 null
-
个人理解:比如:(5的祖先节点有 6 7 4,其中以5为参考点,右边6和7都是比5大的,左边4是比5小的,从左而来的祖先4即为前驱)
比如:(3的祖先节点有 2 4,其中以3为参考点,右边4是比3大的,左边2是比3小的,从左而来的祖先2即为前驱)
// 情况2 - 有祖先自左而来
//对于情况2,我们如何知道哪些节点是要找节点的祖先,又是如何知道这些祖先节点哪些是自从左而来的呢?
//以5节点为例,那我要找到5这个节点的过程中,它必然已经经历过一些节点了,从根节点4开始找,5比4大就向右找,7比5大就向左找,6比5大就像左找,找到了
//在从根节点开始4 7 6是不是都是5的祖先?是的 其实循环的每步都是在经历他这些祖先节点,好,现在知道怎么去获取祖先节点。
//那我们怎么去进一步判断 它这个祖先是左边来还是从右边来呢?
//答:你看4到7是不是向右走,那么以5为参考点,那么4是不是在左边?那么7到6、6到5都是向左走,但是以5为参考点,那么7到6、6到5都是向右走
//所以只要我们看到这种向右走的代码if (p.key < key) {p = p.right;}那就表示祖先是自左而来
//而且我们每次循环更新都是最新也就是最近的自左而来的祖先节点
在predecessor方法之前,我们对于Max方法进行简单的修改,因为我们上面写的Max方法仅仅只是针对于root根节点来查询最大:
//非递归实现 针对于root的max方法public Object max() {return max(root);
// if (root == null) {
// return null;
// }
// BSTNode p = root;
// // 右边未走到头
// while (p.right != null) {
// p = p.right;
// }
// return p.value;}//通用的Max方法private Object max(BSTNode node){if (node == null) {return null;}BSTNode p = node;// 右边未走到头while (p.right != null) {p = p.right;}return p.value;}然后我们就开始书写查询节点的前驱代码:
public Object predecessor(int key) {BSTNode ancestorFromLeft = null;BSTNode p = root;//查找用户给的Key在二叉树中是否有while (p != null) {if (key < p.key) {p = p.left;} else if (p.key < key) {ancestorFromLeft = p;p = p.right;} else {break;}}//key没找到,说明也就没有前任节点if (p == null) {return null;}// 情况1 - 有左孩子if (p.left != null) {return max(p.left);}// 情况2 - 有祖先自左而来//对于情况2,我们如何知道哪些节点是要找节点的祖先,又是如何知道这些祖先节点哪些是自从左而来的呢?//以5节点为例,那我要找到5这个节点的过程中,它必然已经经历过一些节点了,从根节点4开始找,5比4大就向右找,7比5大就向左找,6比5大就像左找,找到了//在从根节点开始4 7 6是不是都是5的祖先?是的 其实循环的每步都是在经历他这些祖先节点,好,现在知道怎么去获取祖先节点。//那我们怎么去进一步判断 它这个祖先是左边来还是从右边来呢?//答:你看4到7是不是向右走,那么以5为参考点,那么4是不是在左边?那么7到6、6到5都是向左走,但是以5为参考点,那么7到6、6到5都是向右走//所以只要我们看到这种向右走的代码if (p.key < key) {p = p.right;}那就表示祖先是自左而来//而且我们每次循环更新都是最新也就是最近的自左而来的祖先节点return ancestorFromLeft != null ? ancestorFromLeft.value : null;
}查询节点后继
找后继也分成 2 种情况 与找前任的代码相类似

-
节点有右子树,此时后继节点即为右子树的最小值,如
-
2 的后继 3
-
3 的后继 4
-
5 的后继 6
-
7 的后继 8
-
-
节点没有右子树,若离它最近的祖先自从右而来,此祖先即为后继,如
-
1 的祖先 2 自右而来,后继 2
-
4 的祖先 5 自右而来,后继 5
-
6 的祖先 7 自右而来,后继 7
-
8 没有这样的祖先,后继 null
-
在successor方法之前,我们对于Min方法进行简单的修改,因为我们上面写的Min方法仅仅只是针对于root根节点来查询最小:
//非递归实现public Object min() {return min(root);
// if (root == null) {
// return null;
// }
// BSTNode p = root;
// // 左边未走到头
// while (p.left != null) {
// p = p.left;
// }
// return p.value;}private Object min(BSTNode node){if (node == null) {return null;}BSTNode p = node;// 左边未走到头while (p.left != null) {p = p.left;}return p.value;}然后我们就开始书写查询节点的后继代码:
public Object successor(int key) {BSTNode ancestorFromRight = null;BSTNode p = root;while (p != null) {if (key < p.key) {ancestorFromRight = p;p = p.left;} else if (p.key < key) {p = p.right;} else {break;}}if (p == null) {return null;}// 情况1 - 有右孩子if (p.right != null) {return min(p.right);}// 情况2 - 有祖先自右而来return ancestorFromRight != null ? ancestorFromRight.value : null;
}删除操作
要删除某节点(称为 D),必须先找到被删除节点的父节点,这里称为 Parent
1.删除节点没有左孩子,将右孩子托孤给 Parent

2.删除节点没有右孩子,将左孩子托孤给 Parent

3.删除节点左右孩子都没有,已经被涵盖在情况1、情况2当中,把null托孤给Parent
4.删除节点左右孩子都有,可以将它的后继节点(称为S)托孤给Parent,设S的父亲为SP,又分两种情况:
1.SP 就是被删除节点,此时 D 与 S 紧邻,只需将 S 托孤给 Parent

2.SP 不是被删除节点,此时 D 与 S 不相邻,此时需要将 S 的后代托孤给 SP,再将 S 托孤给 Parent

非递归实现
/*** <h3>根据关键字删除</h3>** @param key 关键字* @return 被删除关键字对应值*/
public Object delete(int key) {BSTNode p = root;BSTNode parent = null;//记录待删除节点的父亲while (p != null) {if (key < p.key) {parent = p;p = p.left;} else if (p.key < key) {parent = p;p = p.right;} else {break;}}if (p == null) {return null;}// 删除操作if (p.left == null) {shift(parent, p, p.right); // 情况1} else if (p.right == null) {shift(parent, p, p.left); // 情况2} else {// 情况4:被删除节点是左、右都有子节点,所以找后继节点:节点有右子树,此时后继节点即为右于树的最小值// 4.1 被删除节点找后继BSTNode s = p.right;//后继节点BSTNode sParent = p; // 后继父亲while (s.left != null) { //当循环结束,后继节点即为ssParent = s;s = s.left;}// 4.2 删除和后继不相邻, 处理后继的后事if (sParent != p) { shift(sParent, s, s.right); // 不可能有左孩子:因为节点有右子树,此时后继节点即为右于树的最小值s.right = p.right;//顶上去的后继节点的右孩子==被删除节点的右孩子}// 4.3 后继取代被删除节点shift(parent, p, s);s.left = p.left;//shift方法只改变了父类节点的左右孩子的指向,而没有改变你后继节点的做左右孩子的指向}return p.value;
}/*** 托孤方法** @param parent 被删除节点的父亲* @param deleted 被删除节点* @param child 被顶上去的节点*/
// 只考虑让 n1父亲的左或右孩子指向 n2, n1自己的左或右孩子并未在方法内改变
private void shift(BSTNode parent, BSTNode deleted, BSTNode child) {//情况讨论:当被删除节点就是根节点,而根节点是没有父亲的if (parent == null) {root = child;//你们被删除节点的子节点就成根节点} else if (deleted == parent.left) {parent.left = child;} else {parent.right = child;}
}递归实现
/*** <h3>根据关键字删除</h3>** @param key 关键字* @return 被删除关键字对应值 是删除单个节点,当该节点被删除,则它的子节点将会与该节点的父类节点进行连接*/public Object remove(int key) {ArrayList<Object> result = new ArrayList<>(); // 保存被删除节点的值root = doRemove(root, key, result);return result.isEmpty() ? null : result.get(0);}/*4/ \2 6/ \1 7node 起点返回值 删剩下的孩子(找到) 或 null(没找到)*///递归实现删除操作 BSTNode node:我要删除时,从哪个节点开始删除 node是起点private BSTNode doRemove(BSTNode node, int key, ArrayList<Object> result) {//1.没有找到的情况:if (node == null) {return null;}//2.找到的情况:if (key < node.key) {//向左查找node.left = doRemove(node.left, key, result);return node;}if (node.key < key) {//向右查找node.right = doRemove(node.right, key, result);return node;}result.add(node.value);if (node.left == null) { // 情况1 - 只有右孩子return node.right;}if (node.right == null) { // 情况2 - 只有左孩子return node.left;}//s:后继节点BSTNode s = node.right; // 情况3 - 有两个孩子while (s.left != null) {s = s.left;}//while循环结束以后,找到了后继节点s.right = doRemove(node.right, s.key, new ArrayList<>());s.left = node.left;return s;}对于第四种情况进行代码解析:
当D与S紧邻:

当D与S不是紧邻:

对于remove方法的解析:
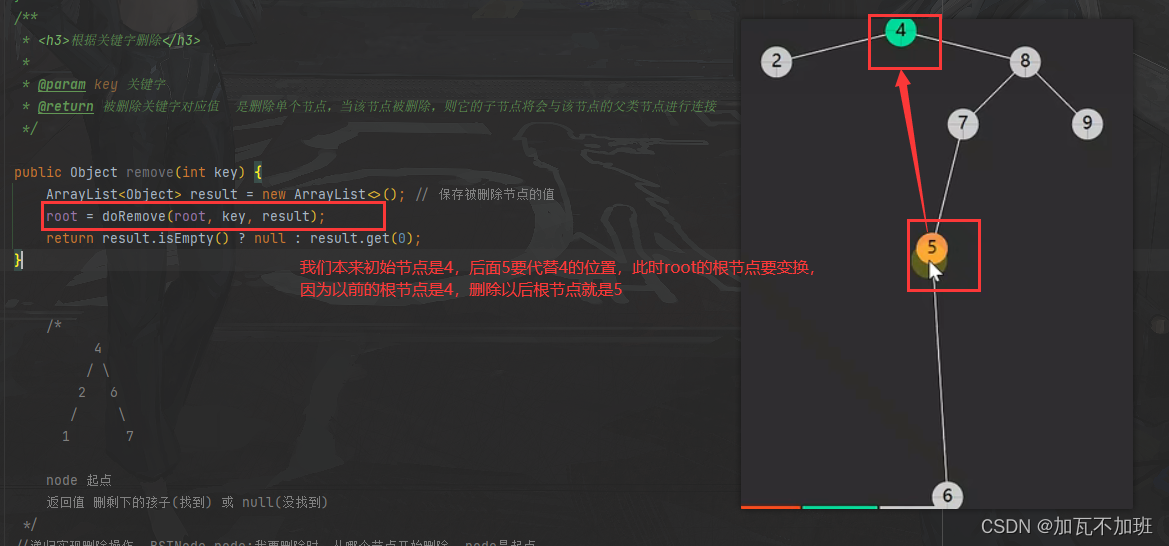
说明
ArrayList<Object> result用来保存被删除节点的值第二、第三个 if 对应没找到的情况,继续递归查找和删除,注意后续的 doDelete 返回值代表删剩下的,因此需要更新
最后一个 return 对应删除节点只有一个孩子的情况,返回那个不为空的孩子,待删节点自己因没有返回而被删除
第四个 if 对应删除节点有两个孩子的情况,此时需要找到后继节点,并在待删除节点的右子树中删掉后继节点,最后用后继节点替代掉待删除节点返回,别忘了改变后继节点的左右指针
范围查询
下面三种题型的核心解题思路:
我们利用中序遍历的特性:遍历出来的都是升序的结果来进行范围查询
找小的
/*4/ \2 6/ \ / \1 3 5 7*/
//找 > key 的所有 value
//解题思路:我们利用中序遍历的特性:遍历出来的都是升序的结果
public List<Object> less(int key) { //当我们输入的是6//result:将符合条件的加入到result中ArrayList<Object> result = new ArrayList<>();//中序遍历过程:BSTNode p = root;LinkedList<BSTNode> stack = new LinkedList<>();while (p != null || !stack.isEmpty()) {if (p != null) {stack.push(p);p = p.left;} else {BSTNode pop = stack.pop();if (pop.key < key) {result.add(pop.value);} else {//当我们遇到比key大的分支时,该分支的子分支就没必要多此一举的进行判断,直接跳出//比如:当key=6,那么我们6右节点就不需要多此一举的去判断,而是直接跳出break;}p = pop.right;}}return result;
}找大的
方法与《找小的》操作类似
第一种方法:
/*4/ \2 6/ \ / \1 3 5 7*/
//解题思路:我们利用中序遍历的特性:遍历出来的都是升序的结果
public List<Object> greater(int key) {ArrayList<Object> result = new ArrayList<>();BSTNode p = root;LinkedList<BSTNode> stack = new LinkedList<>();while (p != null || !stack.isEmpty()) {if (p != null) {stack.push(p);p = p.left;} else {BSTNode pop = stack.pop();if (pop.key > key) {//在这里,我们遍历>key的就不需要break,让它执行到子节点为Nullresult.add(pop.value);}p = pop.right;}}return result;
}但这样效率不高,可以用 RNL 遍历
什么是RNL 遍历?
答:
注:
前三中就是我们之前所讲的前、中、后序遍历 N:值 L:左 R:右
Pre-order, NLR
In-order, LNR
Post-order, LRN
以下三种遍历与上三种遍历的区别:上三种是先左后右,下三种是先右后左
Reverse pre-order(反向前序遍历), NRL
Reverse in-order(中向前序遍历), RNL
Reverse post-order(反向后序遍历), RLN
第二种方法:
public List<Object> greater(int key) {ArrayList<Object> result = new ArrayList<>();BSTNode p = root;//RNL 遍历:得到的是降序的结果LinkedList<BSTNode> stack = new LinkedList<>();while (p != null || !stack.isEmpty()) {if (p != null) {stack.push(p);p = p.right;} else {BSTNode pop = stack.pop();if (pop.key > key) {result.add(pop.value);} else {break;}p = pop.left;}}return result;
}找之间
方法与《找小的》操作类似
public List<Object> between(int key1, int key2) {ArrayList<Object> result = new ArrayList<>();BSTNode p = root;LinkedList<BSTNode> stack = new LinkedList<>();while (p != null || !stack.isEmpty()) {if (p != null) {stack.push(p);p = p.left;} else {BSTNode pop = stack.pop();if (pop.key >= key1 && pop.key <= key2) {result.add(pop.value);} else if (pop.key > key2) {break;}p = pop.right;}}return result;
}小结
优点:
如果每个节点的左子树和右子树的大小差距不超过一,可以保证搜索操作的时间复杂度是 O(log n),效率高。
插入、删除结点等操作也比较容易实现,效率也比较高。
对于有序数据的查询和处理,二叉查找树非常适用,可以使用中序遍历得到有序序列。
缺点:
如果输入的数据是有序或者近似有序的,就会出现极度不平衡的情况,可能导致搜索效率下降,时间复杂度退化成O(n)。
对于频繁地插入、删除操作,需要维护平衡二叉查找树,例如红黑树、AVL 树等,否则搜索效率也会下降。
对于存在大量重复数据的情况,需要做相应的处理,否则会导致树的深度增加,搜索效率下降。
对于结点过多的情况,由于树的空间开销较大,可能导致内存消耗过大,不适合对内存要求高的场景。