目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python环境
- TensorFlow 环境
- 方法一
- 方法二
- 安装其他模块
- 安装MySQL 数据库
- 模块实现
- 1. 数据预处理
- 1)数据整合
- 2)文本清洗
- 3)文本分词
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目以支持向量机(SVM)技术为核心,利用酒店评论数据集进行了情感分析模型的训练。通过使用Word2Vec生成词向量,该项目实现了一个打分推荐系统,其中服务器端提供数据,而客户端则查询数据。
首先,项目使用了酒店评论数据集,这些评论包括了来自不同用户的对酒店的评价。这些评论被用来训练情感分析模型,该模型能够分析文本并确定评论的情感极性,即正面、负面或中性。
其次,项目使用Word2Vec技术,将文本数据转换为词向量表示。这些词向量捕捉了不同词汇之间的语义关系,从而提高了文本分析的效果。这些词向量可以用于训练模型以进行情感分析。
在服务器端,项目提供了处理和存储酒店评论数据的功能。这意味着评论数据可以在服务器上进行管理、存储和更新。
在客户端,用户可以查询酒店评论数据,并获得关于特定酒店的情感分析结果。例如,用户可以输入酒店名称或位置,并获取该酒店的评论以及评论的情感分数,这有助于用户更好地了解其他人对酒店的评价。
总的来说,本项目基于SVM技术和Word2Vec词向量,提供了一个针对酒店评论情感的分析和打分推荐系统。这个系统可以帮助用户更好地了解酒店的口碑和评价,从而做出更明智的决策。
总体设计
本部分包括系统整体结构图和系统流程图。
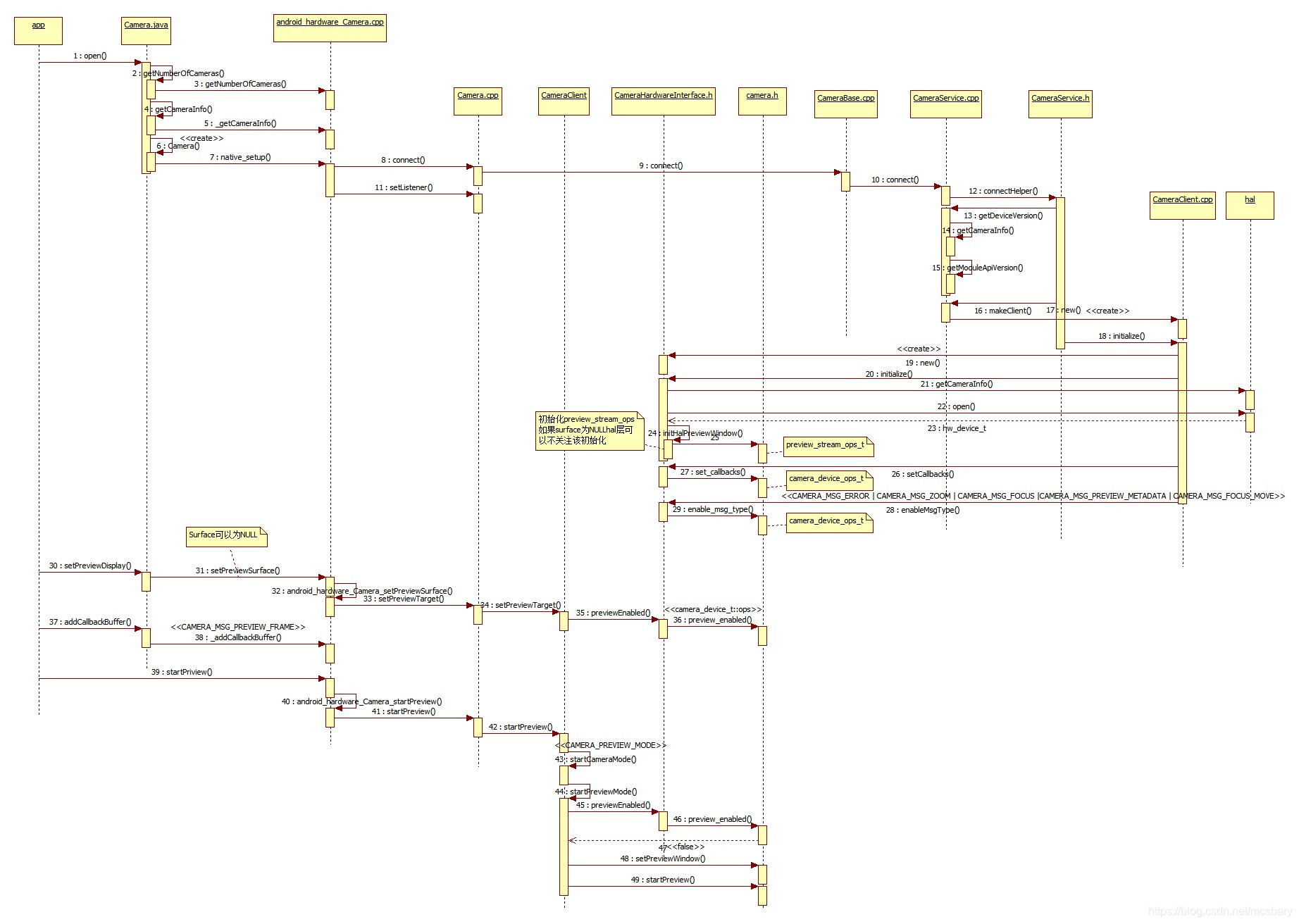
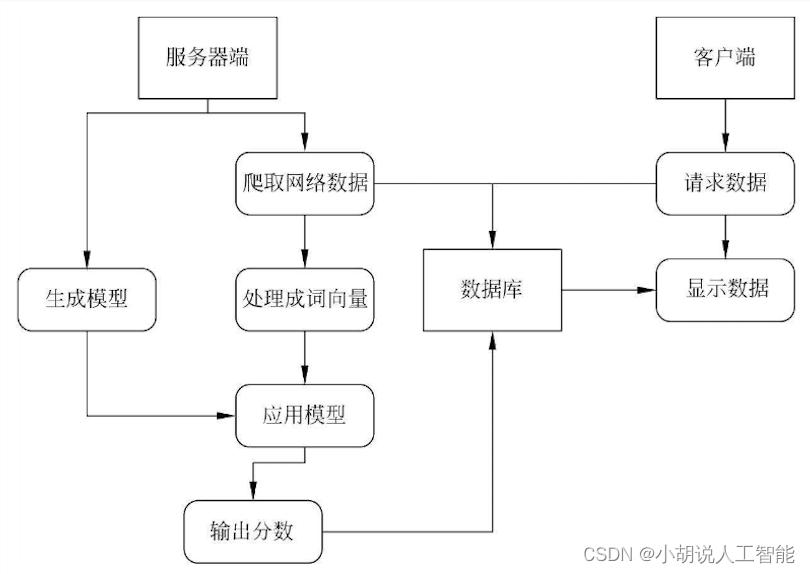
系统整体结构图
系统整体结构如图所示。
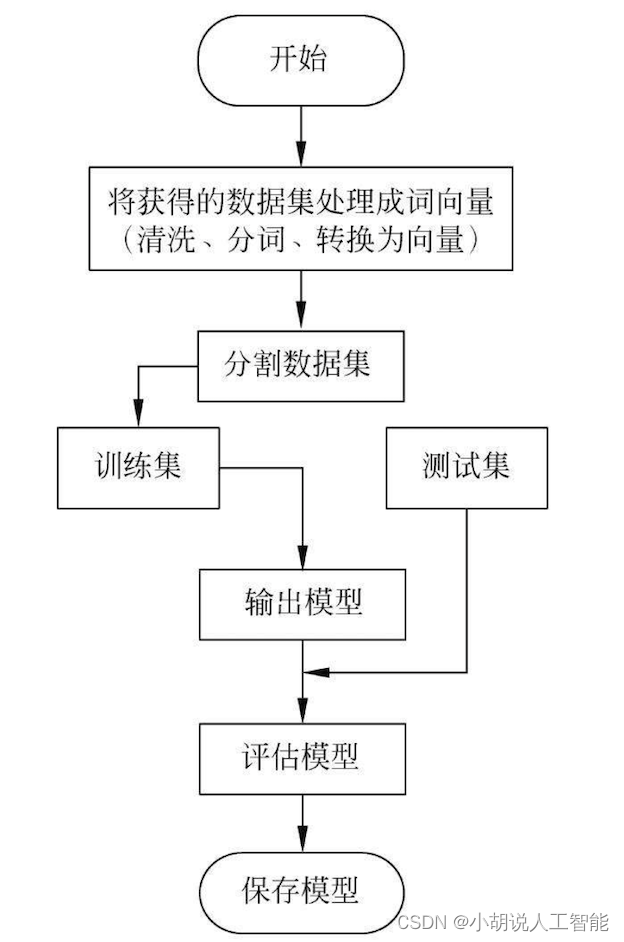
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、 安装模块、MySQL数据库。
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
鼠标右击“我的电脑”,单击“属性”,选择高级系统设置。单击“环境变量”,找到系统变量中的Path,单击“编辑”然后新建,将Python解释器所在路径粘贴并确定。
TensorFlow 环境
安装方法如下:
方法一
打开Anaconda Prompt,输入清华仓库镜像。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
创建Python 3.6的环境,名称为TensorFlow,此时Python版本和后面TensorFlow的版本有匹配问题,此步选择Python 3.x。
conda create -n tensorflow python=3.6
有需要确认的地方,都输入y。在Anaconda Prompt中激活TensorFlow环境:
conda activate tensorflow
安装CPU版本的TensorFlow:
pip install -upgrade --ignore -installed tensorflow
测试代码如下:
import tensorflow as tf
hello = tf.constant( 'Hello, TensorFlow! ')
sess = tf.Session()
print sess.run(hello)
# 输出 b'Hello! TensorFlow'
安装完毕。
方法二
打开Anaconda Navigator,进入Environments 单击Create,在弹出的对话框中输入TensorFlow,选择合适的Python版本,创建好TensorFlow环境,然后进入TensorFlow环境,单击Not installed在搜索框内寻找需要用到的包。例如,TensorFlow,在右下方选择apply,测试是否安装成功。在Jupyter Notebook编辑器中输入以下代码:
import tensorflow as tf
hello = tf.constant( 'Hello, TensorFlow! ')
sess = tf.Session()
print sess.run(hello)
# 输出 b'Hello! TensorFlow'
能够输出hello TensorFlow,说明安装成功。
安装其他模块
在anaconda prompt中使用命令行切换到TensorFlow环境:
activate tensorflow
安装Scikit-learn模块:
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
安装jieba模块:
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
安装gensim模块:
pip install gensim -i https://pypi.tuna.tsinghua.edu.cn/simple
安装Django模块:
下载并解压Django,和Python安装在同一个根目录,进入Django目录,执行:
python setup.py install
Django被安装到Python的Lib下site packages。将这些目录添加到系统环境变量中: C:\Python33\Lib\site packages\django; C:\Python33\Scripts,使用Django的django -admin.py命令新建工程。
安装MySQL 数据库
下载MySQL安装并配置。在计算机高级属性的系统变量中写好MySQL所在位置,方便用命令行操作MySQL,在服务里启动数据库服务,登录数据库:
mysql -u root -P
创建数据库grades:
CREATE DATABASE grades;
在数据库里创建表单:

模块实现
本项目包括3个模块:数据预处理、模型训练及保存、模型测试,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
数据集下载链接为https://www.aitechclub.com/data-detail?data_id=29,停用词典下载链接为http://www.datasoldier.net/archives/636。如果链接失效,可从本博客对应的工程源码中的模型训练目录下的data目录下载相关数据集。
1)数据整合
原始数据包含在两个文件夹中,每个文件夹各有2000条消极和2000条积极的评论,因此,需要先做评论数据整合,将两个评论放在.txt文档中。
#读取每一条文字内容
def getContent(fullname):f = open(fullname,'rb+')content = f.readlines()f.close()return content#将积极和消极评论分别写入两个文件中
for parent,dirnames,filenames in os.walk(rootdir): for filename in filenames:#使用getContent()函数,得到每条评论的具体内容content = getContent(rootdir + '\\' + filename)output.writelines(content)i = i+1output.close()
2)文本清洗
进行文本特殊符号(如表情)的清理删除。
#文本清洗
def clearTxt(line):if line != '':#去掉末尾的空格
line = line.strip()pun_num = string.punctuation + string.digitsintab = pun_numouttab = " "*len(pun_num)#去除所有标点和数字trantab = str.maketrans(intab, outtab)line = line.translate(trantab)#去除文本中的英文和数字line = re.sub("[a-zA-Z0-9]", "", line)#去除文本中的中文符号和英文符号line = re.sub("[\s+\.\!\/_,$%^*(+\"\';:“”.]+|[+——!==°【】,÷。??、 ~@#¥%……&*()]+", "", line)return line
3)文本分词
将分词后的文本转化为以高维向量表示的方式,这里使用微信中文语料训练的开源模型。
#进行文本分词
#引入jieba模块
import jieba
import jieba.analyse
import codecs,sys,string,re#文本分词
def sent2word(line):segList = jieba.cut(line,cut_all=False) segSentence = ''for word in segList:if word != '\t':segSentence += word + " "return segSentence.strip()
#删除分词后文本里的停用词
def delstopword(line,stopkey):wordList = line.split(' ') sentence = ''for word in wordList:word = word.strip()#spotkey是在主函数中获取的评论行数
#逐行删除,不破坏词所在每行的位置,始终保持每条评论的间隔if word not in stopkey:if word != '\t':sentence += word + " "return sentence.strip()
#载入模型
fdir = 'E:\word2vec\word2vec_from_weixin\word2vec'
inp = fdir + '\word2vec_wx'
model = gensim.models.Word2Vec.load(inp)
#把词语转化为词向量的函数
def getWordVecs(wordList,model):vecs = []for word in wordList:word = word.replace('\n','')#print wordtry:vecs.append(model[word])except KeyError:continuereturn np.array(vecs, dtype='float')
#转化为词向量
def buildVecs(filename,model):fileVecs = []with codecs.open(filename, 'rb', encoding='utf-8') as contents:for line in contents:wordList = line.split(' ')#调用getwordVecs()函数,获取每条评论的词向量vecs = getWordVecs(wordList,model)if len(vecs) >0:vecsArray = sum(np.array(vecs))/len(vecs) fileVecs.append(vecsArray)return fileVecs
#建立词向量表,其中积极的首列填充为1,消极的首列填充为0Y = np.concatenate((np.ones(len(posInput)), np.zeros(len(negInput))))X = posInput[:]for neg in negInput:X.append(neg)X = np.array(X)
相关其它博客
基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(二)
基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。