深度学习笔记
DAY1
深度学习基本知识
1.神经网络
1.1 单一神经元

所有神经元将房屋大小size作为输入x,计算线性方程,结果取max(0,y),输出预测房价y
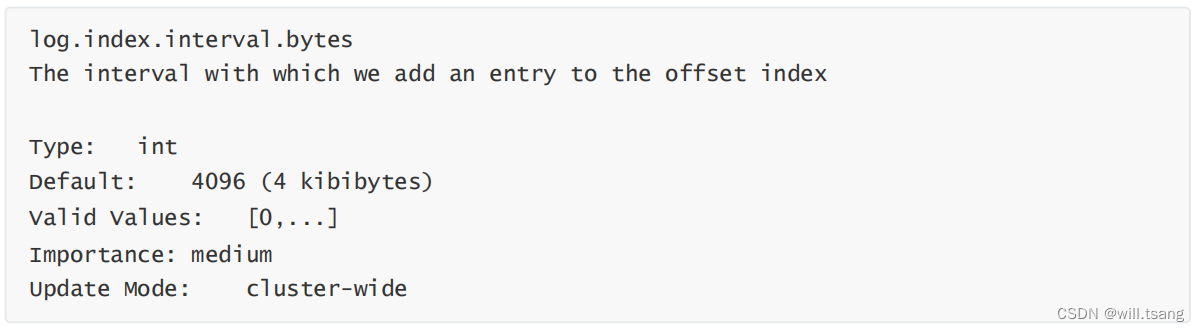
ReLU函数(线性整流函数)–max(0,y)
1.2 神经网络
多个单一神经元组成神经网络
逻辑分析:

小圆圈就是ReUL函数及其他非线性函数

在上面的神经网络中:
x1,x2,x3,x4——输入的特征 (输入层)
小圆圈——神经网络中的隐藏神经元,每个小圆圈都将四个特征作为输入(全连接层)
y——神经网络的工作:根据输入的特征预测y
而与上述逻辑分析不同的是,在神经网络中,网络节点(小圆圈)是神经网络自己决定的,只要给定足够的训练数据(x,y),神经网络就可以很好地拟合一个函数建立x和y的映射关系
2 监督学习与神经网络
2.1神经网络基本分类
神经网络有money的应用:
更多地聚焦结构化数据
在线广告系统
根据用户的信息,预测用户是否会点击某一广告
利润推荐系统
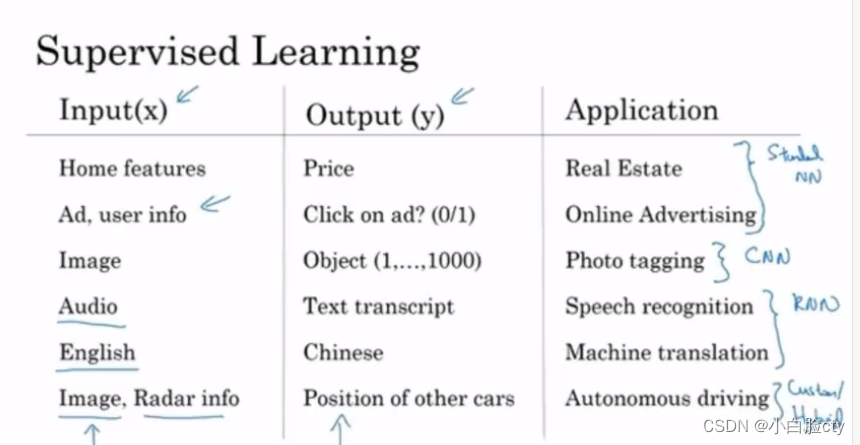
standard NN:
房价预测
在线广告点击预测
CNN(卷积)–图像信息
图像分类
RNN(循环)–对一维序列化数据(时序数据)有很好的效果:音频、文本
语音转文本
机器翻译
定制化的CNN、雷达等其他复合:
自动驾驶技术(根据周围图像信息+雷达位置信息),预测周围车辆位置

2.2 结构化数据与非结构化数据
结构化数据是基于数据库的数据:表格
非结构化数据:原始音频、图像、文本

2.3 Why深度学习好
横坐标表示数据量
纵坐标表示学习算法的性能:例如垃圾邮件分类的准确率

信息化时代,数据爆炸,传统机器学习算法在大规模的数据上性能体现不好
规模驱动深度学习发展
规模:①神经网络的规模(隐藏神经元、参数、连接)②数据的规模
规模大,深度学习的效果好
m:数据量
m小,算法性能取决于特征的提取和算法的细节处理(参数),有可能神经网络效果比SVM差,深度学习可能不如机器学习
算法的优化可以大大减少神经网络的运行时间
例子1
神经网络的重大突破:激活函数从sigmoid函数到ReUL函数的迁移–提高了梯度下降算法速度

回顾:梯度下降(损失函数下降最快的方向)–损失函数最小

sigmoid有个问题:它存在梯度几乎为0的情况,因此在使用梯度下降法寻找损失函数最低点的时候,在sigmod "S"曲线的前后两部分会很缓慢
ReUL:Rectified linear unit修正线性单元
也就是对所有的正输入,梯度都是1
3 二元分类
神经网络:不显式使用for循环来遍历整个训练集
在神经网络组织计算时,常用前向传播和反向传播
为什么训练神经网络时计算可以被正向转播组织为一次前向传播过程以及一次反向传播过程
以LR(logistics regression逻辑回归)
3.1 逻辑回归LR
LR:二元分类1 or 0
应用场景:识别图像是否为猫
在计算机中保存彩图需要存储3个独立矩阵(对应图像的红、绿、蓝通道),若图像大小为6464,则会有36464大小的实数矩阵(也就是该图像向量的维度为364*64)
输入特征向量的维度n=36464
预测输出y:0 or 1
符号表示
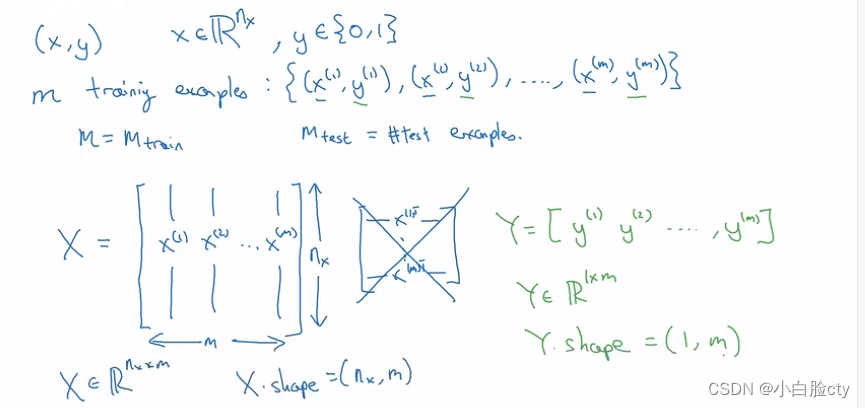
构建神经网络非常有用的惯例:混合不同的训练样本数据,“数据”指的是单个x或y,或者之后其他的数据,混合不同训练样本的数据,将混合后的数据按列排列