Kafka 的核心集群机制,重点保证了在复杂运行环境下,整个 Kafka 集群如何保证 Partition 内消息
的一致性。这就相当于一个军队,有了完整统一的编制。但是,在进行具体业务时,还是需要各个 Broker 进行分工,各自处理好自己的工作。
每个 Broker 如何高效的处理以及保存消息,也是 Kafka 高性能背后非常重要的设计。这一章节还是按照之前的方式,从可见的Log 文件入手,来逐步梳理 Kafka 是如何进行高效消息流转的。 Kafka 的日志文件记录机制也是Kafka 能够支撑高吞吐、高性能、高可扩展的核心所在。对于业界的影响也是非常巨大的。比如RocketMQ就直接借鉴了 Kafka 的日志文件记录机制。
一、 Kafka 的 Log 日志梳理
这一部分数据主要包含当前 Broker 节点的消息数据 ( 在 Kafka 中称为 Log 日志 ) 。这是一部分无状态的数据,也就是说每个Kafka 的 Broker 节点都是以相同的逻辑运行。这种无状态的服务设计让 Kafka 集群能够比较容易的进行水平扩展。比如你需要用一个新的Broker 服务来替换集群中一个旧的 Broker 服务,那么只需要将这部分无状态的数据从旧的Broker 上转移到新的 Broker 上就可以了。

1 、 Topic 下的消息是如何存储的?
在搭建 Kafka 服务时,我们在 server.properties 配置文件中通过 log.dir 属性指定了 Kafka 的日志存储目录。实际上,Kafka 的所有消息就全都存储在这个目录下。

这些核心数据文件中, .log 结尾的就是实际存储消息的日志文件。他的大小固定为 1G( 由参数
log.segment.bytes 参数指定 ) ,写满后就会新增一个新的文件。一个文件也成为一个 segment 文件名表示当前日志文件记录的第一条消息的偏移量。
.index 和 .timeindex 是日志文件对应的索引文件。不过 .index 是以偏移量为索引来记录对应的 .log 日志文件中的消息偏移量。而.timeindex 则是以时间戳为索引。

这些文件都是二进制的文件,无法使用文本工具直接查看。但是, Kafka 提供了工具可以用来查看这些日志文件的内容。
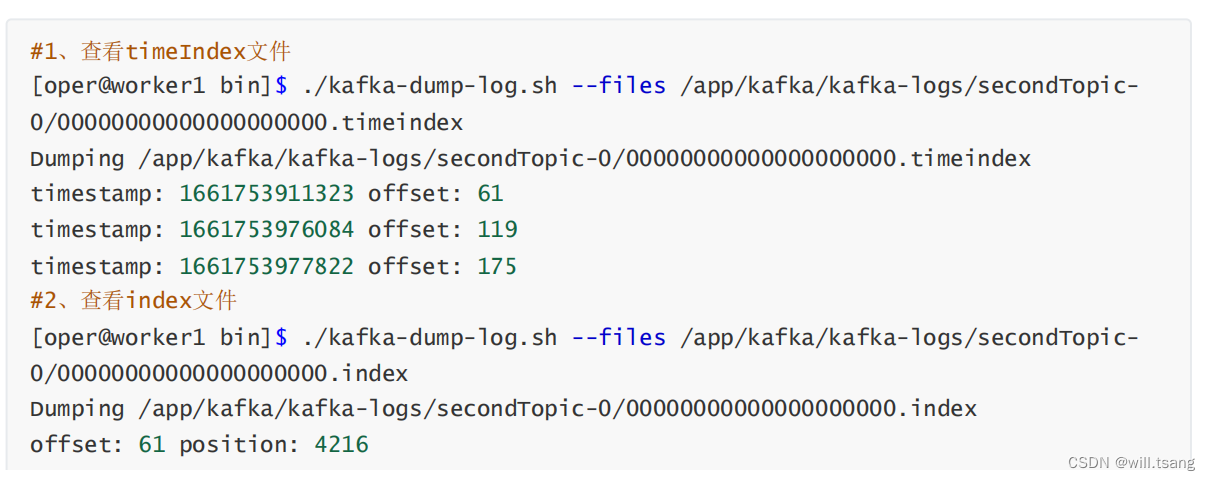

这些数据文件的记录方式,就是我们去理解 Kafka 本地存储的主线。 对这里面的各个属性理解得越详细,也就表示对Kafka 的消息日志处理机制理解得越详细。
1 log 文件追加记录所有消息
首先:在每个文件内部, Kafka 都会以追加的方式写入新的消息日志。 position 就是消息记录的起点, size就是消息序列化后的长度。Kafka 中的消息日志,只允许追加,不支持删除和修改。所以,只有文件名最大的一个log 文件是当前写入消息的日志文件,其他文件都是不可修改的历史日志。
然后:每个 Log 文件都保持固定的大小。如果当前文件记录不下了,就会重新创建一个 log 文件,并以这个log文件写入的第一条消息的偏移量命名。这种设计其实是为了更方便进行文件映射,加快读消息的效率。
2 index 和 timeindex 加速读取 log 消息日志。
详细看下这几个文件的内容,就可以总结出 Kafka 记录消息日志的整体方式:

首先: index 和 timeindex 都是以相对偏移量的方式建立 log 消息日志的数据索引。比如说 0000.index 和0550.index中记录的索引数字,都是从 0 开始的。表示相对日志文件起点的消息偏移量。而绝对的消息偏移量可以通过日志文件名 + 相对偏移量得到。
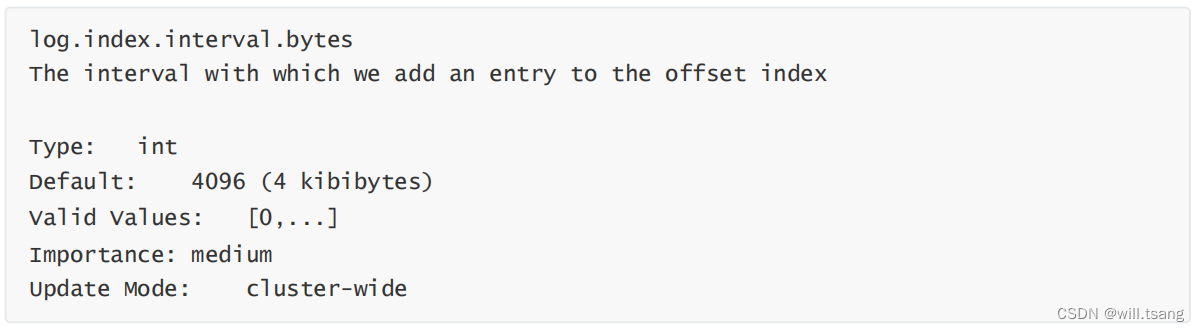
然后:这两个索引并不是对每一条消息都建立索引。而是 Broker 每写入 40KB 的数据,就建立一条 index 索引。由参数log.index.interval.bytes 定制。
index 文件的作用类似于数据结构中的跳表,他的作用是用来加速查询 log 文件的效率。而 timeindex 文件的作用则是用来进行一些跟时间相关的消息处理。比如文件清理。
这两个索引文件也是 Kafka 的消费者能够指定从某一个 offset 或者某一个时间点读取消息的原因。







![[CISCN2019 总决赛 Day2 Web1]Easyweb 盲注 \\0绕过 文件上传文件名木马](https://img-blog.csdnimg.cn/e876bb0bc5354b89aa24823d296a9774.png)