文章目录
- 处理SQL
- 创建
- 创建表
- RecordManager部分
- CatalogManager部分
- 创建索引
- IndexManager::createIndex部分
- API::createNewIndex部分
- CatalogManager::createIndex部分
- 插入
- 删除
- 删除表
- 删除记录?
- 查询
- B+树
- gif演示B+树增删:
- 插入:
- 删除:
项目源码: MiniSQL: ZJU DBS Course Project – MiniSQL (gitee.com)

处理SQL
Interpreter::Interpret()负责映射不同关键字到不同处理方法, Interpreter::extractWord()负责一个个地获取SQL语句中的字符串
int Interpreter::Interpret(const string &text) {int position = 0;int *shift = &position;string word = extractWord(text, shift);if (word == "create") {return execCreate(text, shift);} else if (word == "drop") {return execDrop(text, shift);} else if (word == "select") {return execSelect(text, shift);} else if (word == "insert") {return execInsert(text, shift);} else if (word == "delete") {return execDelete(text, shift);} else if (word == "quit") {return execQuit(text, shift);} else if (word == "execfile") {return execFile(text, shift);} else if (word == "show") {return execShow(text, shift);} else {cout << "Syntax error" << endl;return 0;}
}
创建
Interpreter::execCreate()读取下一个词,将SQL映射到创建表或索引的方法上
int Interpreter::execCreate(const string &text, int *shift) {string word = extractWord(text, shift);if (word == "table") {return execCreateTable(text, shift);} else if (word == "index") {return execCreateIndex(text, shift);} else {cout << "Syntax error for create" << endl;return 0;}
}
创建表
Interpreter::execCreateTable()继续读取SQL,提取其中的表信息(表名、列名、列类型、约束),Attribute类将列名、列类型、约束flag封装,vector<Attribute> attributes就是列列表。将表名和列列表传入API::createTable()中创建表文件和表信息
void API::createTable(const string& tableName, vector<Attribute> *attributes) {// Create table file by RecordManagerrm->Createtable(tableName);// Create TableInfoif (cm.createTable(tableName, attributes) != -1)cout << "Success to create the table: " << tableName << "!" << endl;
}
RecordManager部分
RecordManager负责管理表文件"…/data/XXX.txt",实质还是调用BufferManager中的方法
bool RecordManager::Createtable(string tablename) {string tablefilename = "../data/" + tablename + ".txt";if (bufferManager.LoadFile(tablefilename) > 0) {bufferManager.SaveFile(tablefilename);return true;}elsereturn false;
}
文件若存在BufferManager::LoadFile()会将文件read一个块到BufferManager::bufferPool的第0个块缓冲中,并且返回该文件有多少个块
int BufferManager::LoadFile(const string& fileName){int size = -1, bufferIdx;ifstream is;is.open(fileName, ios::in);if(is.is_open()){//计算文件中的块数is.seekg(0, ios_base::end);//移动读写位置到开头size = ((int)is.tellg()/*读指针的位置*/ + BLOCK_SIZE - 1) / BLOCK_SIZE;//占用bufferPool中的第一个文件块,获取bufferIdxbufferIdx = FetchBlockFromDisk(is, 0);is.close();if(bufferIdx != -1){//update statebufferPool[bufferIdx]->fileName = fileName;fileBuffer[fileName][0] = bufferIdx;fileSize[fileName] = size;//return how many blocks in the filereturn size;}else{//Bufferpool is full.cout<<"[WARN]: Load fail. Bufferpool is full. Unpin some buffer."<<endl;return -1;}}else{//No such file, create one.//cout<<"[WARN]: No such file.\""<<fileName<<"\" will be created."<<endl;bool ret = CreateFile(fileName);if(ret){return 1;}else{return -1;}}
}
//在硬盘文件中读取第idx个块到bufferPool中
int BufferManager::FetchBlockFromDisk(ifstream &is, int idx){int bufferIdx;is.seekg(idx*BLOCK_SIZE, is.beg);bufferIdx = GetFreeBufferIdx();if(bufferIdx != -1){is.read((char*)(bufferPool[bufferIdx]->block), BLOCK_SIZE);bufferPool[bufferIdx]->used = true;bufferPool[bufferIdx]->created = false;bufferPool[bufferIdx]->idx = idx;bufferPool[bufferIdx]->lastUsedTime = clock();//当前时间,用于LRU()返回最近最少使用时间}return bufferIdx;
}//取一个没有使用的bufferPool的索引,将文件信息赋到bufferPool上,fileBuffer(map<string,map<int,int>>)对应文件的第0个块也指定为该bufferPool索引
bool BufferManager::CreateFile(const string& fileName){int bufferIdx = GetFreeBufferIdx();if(bufferIdx != -1){bufferPool[bufferIdx]->used = true;bufferPool[bufferIdx]->dirty = true;bufferPool[bufferIdx]->created = true; bufferPool[bufferIdx]->idx = 0;bufferPool[bufferIdx]->fileName = fileName;bufferPool[bufferIdx]->lastUsedTime = clock();fileBuffer[fileName][0] = bufferIdx;fileSize[fileName] = 1;//当前文件有几个块return true;}else{return false;}
}int BufferManager::GetFreeBufferIdx(){int bufferIdx, ret;if(freeBufferList == NULL){bufferIdx = LRU();//取最近最少使用的块索引if(bufferIdx == -1){//No buffer can be released with LRUcout<<"[ERROR]: No buffer can bu released. Unpin some buffers."<<endl;return -1; }if(bufferPool[bufferIdx]->dirty){//该块数据为脏,应将数据写入硬盘fstream os;os.open(bufferPool[bufferIdx]->fileName);//这里没必要区分文件是否存在,fstream.open()可以在文件不存在时自动创建,无需使用ofstream.open()/*if(os.is_open()){WriteBlockToDisk(os, bufferPool[bufferIdx]->idx, bufferPool[bufferIdx]->block->data);os.close();}else{//file doesn't existofstream of;of.open(bufferPool[bufferIdx]->fileName);WriteNewBlockToDisk(of, bufferPool[bufferIdx]->idx, bufferPool[bufferIdx]->block->data);of.close();}*/WriteBlockToDisk(os, bufferPool[bufferIdx]->idx, bufferPool[bufferIdx]->block->data);os.close();}FreeBlock(bufferIdx);//块中数据已写入硬盘,释放块}ret = freeBufferList->bufferIdx;freeBufferList = freeBufferList->next;return ret;
}void BufferManager::WriteBlockToDisk(fstream &os, int idx, const char* blockData){os.seekp(idx*BLOCK_SIZE, os.beg);os.write(blockData, BLOCK_SIZE);
}int BufferManager::LRU(){int ret = -1;clock_t lruTime = clock(); for(int i = 0; i < BUFFER_SIZE; i++){if(bufferPool[i]->used && !bufferPool[i]->pinned){if(bufferPool[i]->lastUsedTime <= lruTime){ret = i;lruTime = bufferPool[i]->lastUsedTime;}}}return ret;
}
总的来说,一个文件可以由多个块组成,块数据(4byte大小+4092byte数据)被封装到Block类中,Block又和最近使用时间、数据脏标记、使用标记、所在文件名等信息一起封装到Buffer类,BufferManager的核心是一个Buffer指针列表Buffer** bufferPool
map<string, map<int, int>> fileBuffer是文件名到块索引的映射
FreeBuffer* freeBufferList是空闲块的索引的链表
//将bufferPool中文件的所有脏块写入磁盘,并提交AppendFile或DeleteFileLastBlock。释放所有块,无论块是否固定。
void BufferManager::SaveFile(const string& fileName){ofstream of;fstream os;int idx, bufferIdx, size;vector<int> idxVec;os.open(fileName);if(os.is_open()){//the file exists//check if some block of the file is deletedos.seekp(0, ios_base::end);size = ((int)os.tellp() + BLOCK_SIZE - 1) / BLOCK_SIZE;os.close();//truncate the fileif(size > fileSize[fileName]){//truncate(fileName.c_str(), fileSize[fileName]*BLOCK_SIZE);}os.open(fileName);if(fileBuffer.find(fileName) != fileBuffer.end()){//获取文件名对应的块索引列表for (auto iter = fileBuffer[fileName].begin(); iter != fileBuffer[fileName].end(); ++iter){idxVec.push_back(iter->first);}//将脏的块写入硬盘文件for (auto iter = idxVec.begin(); iter != idxVec.end(); ++iter) {idx = *iter;bufferIdx = fileBuffer[fileName][idx]; if(bufferPool[bufferIdx]->dirty){WriteBlockToDisk(os, idx, bufferPool[bufferIdx]->block->data);}bufferPool[bufferIdx]->dirty = false;//FreeBlock(bufferIdx);}}os.close();}else{//the file does not existof.open(fileName);for (auto iter = fileBuffer[fileName].begin(); iter != fileBuffer[fileName].end(); ++iter){idxVec.push_back(iter->first);}for (auto iter = idxVec.begin(); iter != idxVec.end(); ++iter) {idx = *iter;bufferIdx = fileBuffer[fileName][idx]; if(bufferPool[bufferIdx]->dirty){WriteNewBlockToDisk(of, idx, bufferPool[bufferIdx]->block->data);}bufferPool[bufferIdx]->dirty = false;//FreeBlock(bufferIdx);}of.close();}
}
CatalogManager部分
该部分注重表列信息的处理,是对RecordManager构建的表和块的框架(如果是初始创建表就只是创建的表文件)的"内容"的补充,就是将表列信息保存到内存的bufferPool中,当然是保存到TableInfo.txt文件对应的块中,直到BufferManager对象销毁时调用析构函数才保存到硬盘。
int CatalogManager::createTable(const string& tableName, vector<Attribute> *attributes) {// If the table existsif (findTable(tableName)) {cout << "Table already exists!" << endl;return -1;}// Get table infostring tableInfo = createTableInfo(tableName, attributes);int tableInfoLength = (int) tableInfo.length();// 遍历块以查找是否有存储tableInfo的空间int fileSize = bufferManager.GetFileSize(TABLE_INFO_PATH);//表信息文件TableInfo.txtfor (int i = 0; i < fileSize; ++i) {Block *block = bufferManager.GetFileBlock(TABLE_INFO_PATH, i);string content(block->data);int contentLength = (int) content.length();// If there is enough space for table infoif (contentLength + tableInfoLength <= BLOCK_SIZE) {content.append(tableInfo);
// cout << content << endl;strcpy(block->data, content.c_str());block->SetDirty(true);return 1;}}// No space, so need to append a blockbufferManager.AppendFile(TABLE_INFO_PATH);Block *block = bufferManager.GetFileBlock(TABLE_INFO_PATH, fileSize++);block->SetPin(true);strcpy(block->data, tableInfo.c_str());return 1;
}
int CatalogManager::findTable(const string& tableName) {int fileSize = bufferManager.GetFileSize(TABLE_INFO_PATH);//获取表信息文件TableInfo.txt有多少个块for (int i = 0; i < fileSize; ++i) {//遍历文件的所有块Block *block = bufferManager.GetFileBlock(TABLE_INFO_PATH, i);string content(block->data);int find = (int) content.find("TABLE_NAME:" + tableName);//查找块数据中有无"TABLE_NAME:..."字符串if (find != std::string::npos)return 1;}return 0;
}int BufferManager::GetFileSize(const string& fileName){if(fileBuffer.find(fileName) != fileBuffer.end()){//file is registeredreturn fileSize[fileName];}else{return -1;}
} Block* BufferManager::GetFileBlock(const string& fileName, int idx){int bufferIdx;ifstream is;if(fileBuffer.find(fileName) != fileBuffer.end() && idx >= 0 && idx < fileSize[fileName]){//文件已注册,idx是合理的if(fileBuffer[fileName].find(idx) != fileBuffer[fileName].end()){//block already in the bufferPoolbufferIdx = fileBuffer[fileName][idx];}else{//block not in the bufferPool, fetch block from diskis.open(fileName, ios::in);bufferIdx = FetchBlockFromDisk(is, idx);is.close();//update statebufferPool[bufferIdx]->fileName = fileName;fileBuffer[fileName][idx] = bufferIdx;}bufferPool[bufferIdx]->lastUsedTime = clock();return bufferPool[bufferIdx]->block;}else{//illeagl conditionreturn NULL;}
}/* tableInfo: TABLE_NAME:tableName|ATTRIBUTE_NUM:attributeNum|PRIMARY_KEY:primaryKey|INDEX_NUM:indexNum|ATTRIBUTE_INFO_0:attributeName,dataType,charSize,primaryKey,unique,index|# */
//其实就是根据传入的表名和列列表拼出表信息字符串
string CatalogManager::createTableInfo(const string &tableName, vector<Attribute> *attributes) {string tableInfo;// Store the name of the tabletableInfo.append("TABLE_NAME:" + tableName + "|");// Store the number of attributestableInfo.append("ATTRIBUTE_NUM:" + to_string(((*attributes).size())) + "|");// Store the primary keybool hasKey = false;for (const auto& attribute : (*attributes))if (attribute.primaryKey) {hasKey = true;tableInfo.append("PRIMARY_KEY:" + attribute.name + "|");break;}if (!hasKey)tableInfo.append("PRIMARY_KEY:NONE|");// Store the number of indexesint indexNum = 0;for (const auto& attribute : (*attributes)) {if (attribute.index != "none")indexNum++;}tableInfo.append("INDEX_NUM:" + to_string(indexNum) + "|");// Store the information of attributesint attributeCount = 0;for (const auto& attribute : (*attributes)) {tableInfo.append("ATTRIBUTE_INFO_" + to_string(attributeCount) + ":");tableInfo.append(attribute.name + "," + to_string(attribute.dataType) + "," +to_string(attribute.charSize) + "," + to_string(attribute.primaryKey) + "," +to_string(attribute.unique) + "," + attribute.index + "|");attributeCount++;}// End with "#"tableInfo.append("#");return tableInfo;
}void BufferManager::AppendFile(const string& fileName){int bufferIdx = GetFreeBufferIdx();bufferPool[bufferIdx]->used = true;bufferPool[bufferIdx]->dirty = true;bufferPool[bufferIdx]->created = true; bufferPool[bufferIdx]->idx = fileSize[fileName];bufferPool[bufferIdx]->fileName = fileName;bufferPool[bufferIdx]->lastUsedTime = clock();fileBuffer[fileName][fileSize[fileName]] = bufferIdx;fileSize[fileName] = fileSize[fileName] + 1;
}
创建索引
与Interpreter::execCreateTable()类似,Interpreter::execCreateIndex()继续读取输入SQL的词,获取到索引名、所在表表名、索引的目标列列名(只支持单列索引),进入API层
索引结构(B+树的属性成员)虽然通过这个方法保存到索引文件上,但是索引数据(B+树的结点数据)没有写入硬盘,而是呆在内存的bufferPool中。当然表信息肯定要更新到内存中的bufferPool内TableInfo.txt对应的块中。索引数据和表信息直到BufferManager析构时才保存到硬盘(实际上不止二者,所有的bufferPool中的块都在这时保存到硬盘)
void API::createIndex(const string &tableName, const string &attributeName, const string &indexName) {// Create index by IndexManagervector<Attribute> attributes = getTableAttribute(tableName);for (auto attribute : attributes) {if (attribute.name == attributeName) {im.createIndex(tableName, attribute);createNewIndex(tableName, attributeName, indexName);}}// Update the tableInfocm.createIndex(tableName, attributeName, indexName);
}
IndexManager::createIndex部分
这一部分目的是把索引文件给创建出来,并把B+树的基础信息写进文件
//在IndexManager层对三种数据类型分情况创建B+树
//这里创建对象没有使用new,BplusTree对象创建在栈上,作用域结束时销毁,因此在构造函数结尾有调用写入硬盘方法
bool IndexManager::createIndex(string _tableName, Attribute _attribute)
{string indexFileName = _tableName + "_" + _attribute.name + ".index";bufferManager.CreateFile(indexFileName);switch (_attribute.dataType) {case 0: {BplusTree<int> bptree = BplusTree<int>(_tableName, _attribute.name, getKeyLength(_attribute));}break;case 1: {BplusTree<float> bptree = BplusTree<float>(_tableName, _attribute.name, getKeyLength(_attribute));}break;case 2: {BplusTree<string> bptree = BplusTree<string>(_tableName, _attribute.name, getKeyLength(_attribute));}break;default:cout << "wrong attribute type" << endl;return false;break;}return true;
}//新建B+树
template<typename keyType>
BplusTree<keyType>::BplusTree(string _tableName, string _attributeName, uint32_t _keyLength)
{this->indexFileName = _tableName + "_" + _attributeName + ".index";//索引文件名this->keyLength = _keyLength;this->nodeCount = 1;this->root = 1;this->freePageCount = 0;bufferManager.AppendFile(indexFileName);BplusTreeNode<keyType>* node = new BplusTreeNode<keyType>(/*isLeafNode*/true, /*keyLength*/keyLength, /*parent*/0, /*parent*/1);Block* rootBlock = bufferManager.GetFileBlock(indexFileName, 1);node->setLastPointer(0);//尾插pageVectornode->writeToDisk(rootBlock);writeToDisk();
}//将树保存到硬盘的索引文件内
template<typename keyType>
void BplusTree<keyType>::writeToDisk()
{Block* _block = bufferManager.GetFileBlock(indexFileName, 0);_block->SetPin(true);_block->SetDirty(true);//将B+树属性成员存入索引文件块中memcpy(_block->data + KEY_LENGTH_OFFSET, &keyLength, KEY_LENGTH_SIZE);memcpy(_block->data + NODE_COUNT_OFFSET, &nodeCount, NODE_COUNT_SIZE);memcpy(_block->data + ROOT_POINTER_OFFSET, &root, ROOT_POINTER_SIZE);memcpy(_block->data + FREE_PAGE_COUNT_OFFSET, &freePageCount, FREE_PAGE_COUNT_SIZE);int pageOffset = TREE_HEADER_SIZE;int step = sizeof(uint32_t);for (uint32_t i = 0; i < freePageCount; i++) {memcpy(_block->data + pageOffset, &freePages[i], sizeof(uint32_t));pageOffset += step;}_block->SetPin(false);bufferManager.SaveFile(indexFileName);
}
API::createNewIndex部分
这一部分根据传入的索引列进行B+树的构建,具体就是取出表文件中索引列的数据,将每个记录的该列数据定为一个key,value是一个能确定当前记录的RecordPosition结构体(指定块索引和块内记录编号),这样当where指定索引列的值时就可以快速定位到记录的位置(虽然一开始key和value参数名相反,之后会调换的)。然后value存到BplusTreeNode::recordVector,key存到BplusTreeNode::keyVector,两者会交叉着(先recordVector[i]再keyVector[i])被存到索引文件对应的块中
void API::createNewIndex(const string& tableName, const string& attributeName, const string& indexName) {vector<Attribute> Attributes;Attributes = getTableAttribute(tableName);//表列列表struct RecordPosition recordposition;int p = 1;//属性起始位置int attributeaddress;for (int h = 0; h < Attributes.size(); h++) {if (Attributes[h].name == attributeName) {attributeaddress = h;//传入列的索引break;}p += Attributes[h].charSize;}int recordsize = rm->getrecordsize(&Attributes);string value;string tablefilename = "../data/" + tableName + ".txt";if (!bufferManager.IsFileRegistered(tablefilename)) {bufferManager.LoadFile(tablefilename);}int buffernum = bufferManager.GetFileSize(tablefilename);for (int i = 0; i < buffernum; i++) {Block *btmp = bufferManager.GetFileBlock(tablefilename, i);//遍历文件的块列表int recordNum = (btmp->GetSize() - 4) / recordsize;//这个块里有多少条记录for (int j = 0; j < recordNum; j++) {value = (*(btmp->GetRecords(j, j + 1, recordsize)))[0];//返回1条([j+1]-[j])记录if (value.at(0) == '%') {//一条记录的开头规定为%value = value.substr(p, Attributes[attributeaddress].charSize);//取出传入列在该记录中的数据recordposition.blockNum = i + 1;recordposition.recordNum = j + 1;if (Attributes[attributeaddress].dataType == 0) {int n = stoi(value);//数据类型转换string value1 = to_string(n);insertIndex(tableName, Attributes[attributeaddress], value1, recordposition);} else if (Attributes[attributeaddress].dataType == 1) {float f = stof(value);string value1 = to_string(f);insertIndex(tableName, Attributes[attributeaddress], value1, recordposition);} else {int k;for (k = 0; k < Attributes[attributeaddress].charSize; k++) {if (value.at(k) != '!') break;}value = value.substr(k);insertIndex(tableName, Attributes[attributeaddress], value, recordposition);}}}}
}void API::insertIndex(const string& tableName, Attribute _attribute, const string& _value, struct RecordPosition recordposition)
{char* value;int tempInt = atoi(_value.c_str());float tempFloat = atof(_value.c_str());//数据转换成不同类型的字符串switch (_attribute.dataType) {//intcase 0: value = (char*)&tempInt; break;//floatcase 1: value = (char*)&tempFloat; break;//stringdefault: value = (char*)&_value; break;}im.insertIndex(tableName, _attribute, value, recordposition);
}bool IndexManager::insertIndex(string _tableName, Attribute _attribute, char* _key, RecordPosition _value)
{switch (_attribute.dataType) {case 0: {BplusTree<int> bptree = BplusTree<int>(_tableName, _attribute.name);bptree.insertValueWithKey(CHAR2INT(_key), _value); }break;case 1:{BplusTree<float> bptree = BplusTree<float>(_tableName, _attribute.name);bptree.insertValueWithKey(CHAR2FLOAT(_key), _value); }break;case 2: {BplusTree<string> bptree = BplusTree<string>(_tableName, _attribute.name);bptree.insertValueWithKey(CHAR2STRING(_key), _value);}break;default:cout << "wrong attribute type" << endl;return false;break;}return true;
}//两个参数的B+树构造函数,完成了从索引文件块取值构建B+树的工作
template<typename keyType>
BplusTree<keyType>::BplusTree(string _tableName, string _attributeName)
{this->indexFileName = _tableName + "_" + _attributeName + ".index";Block* _block = bufferManager.GetFileBlock(indexFileName, 0);_block->SetPin(true);//将索引文件块中数据取出放进B+树属性成员memcpy(&keyLength, _block->data + KEY_LENGTH_OFFSET, KEY_LENGTH_SIZE);memcpy(&nodeCount, _block->data + NODE_COUNT_OFFSET, NODE_COUNT_SIZE);memcpy(&root, _block->data + ROOT_POINTER_OFFSET, ROOT_POINTER_SIZE);memcpy(&freePageCount, _block->data + FREE_PAGE_COUNT_OFFSET, FREE_PAGE_COUNT_SIZE);int pageOffset = TREE_HEADER_SIZE;int step = sizeof(uint32_t);for (uint32_t i = 0; i < freePageCount; i++) {uint32_t _freePage;memcpy(&_freePage, _block->data + pageOffset, sizeof(uint32_t));freePages.push_back(_freePage);pageOffset += step;}_block->SetPin(false);
}template<typename keyType>
bool BplusTree<keyType>::insertValueWithKey(const keyType& key, RecordPosition value)
{BplusTreeNode<keyType>* node = getNode(root);//获取root结点uint32_t nodeNumber = root;while (node != nullptr && !node->isLeaf()) {//单个根节点是叶子节点nodeNumber = node->findChildWithKey(key);//在内部节点中查找带有key的子页delete node;node = getNode(nodeNumber);}if (node == nullptr) {cout << "The node is null" << endl;return false;}if (node->insertValueWithKey(key, value)) {if (node->isOverLoad()) {//如果结点过载了就分割结点node->splitNode(this);}else {writeNodeToDisk(node, nodeNumber);}delete node;}return true;
}
template<typename keyType>
bool BplusTreeNode<keyType>::insertValueWithKey(const keyType& _key, RecordPosition _value)
{// If the node is not a leaf nodeif (!isLeaf()) {cout << "Try to insert value in a internal node" << endl;return false;}//insert data into a leaf nodeint sub = lower_bound(keyVector.begin(), keyVector.end(), _key) - keyVector.begin();//lower_bound()查找不小于目标值的第一个元素keyVector.insert(keyVector.begin() + sub, _key);//参数1之前插入recordVector.insert(recordVector.begin() + sub, _value);dataCount++;return true;
}template<typename keyType>
void BplusTree<keyType>::writeNodeToDisk(BplusTreeNode<keyType>* node, uint32_t pageNumber)
{Block* nodeBlock = bufferManager.GetFileBlock(indexFileName, pageNumber);node->writeToDisk(nodeBlock);
}template<typename keyType>
void BplusTreeNode<keyType>::writeToDisk(Block* _block)
{_block->SetPin(true);_block->SetDirty(true);memcpy(_block->data + IS_LEAF_OFFSET, &isLeafNode, IS_LEAF_SIZE);memcpy(_block->data + KEY_LENGTH_OFFSET, &keyLength, KEY_LENGTH_SIZE);memcpy(_block->data + DATA_COUNT_OFFSET, &dataCount, DATA_COUNT_SIZE);memcpy(_block->data + PARENT_POINTER_OFFSET, &parent, PARENT_POINTER_SIZE);int valueOffset = NODE_HEADER_SIZE;int valueSize = isLeaf() ? sizeof(RecordPosition) : sizeof(uint32_t);int keyOffset = valueOffset + valueSize;int step = valueSize + keyLength;if (isLeaf()) {for (uint32_t i = 0; i < getDataCount(); i++) {memcpy(_block->data + valueOffset, &recordVector[i], valueSize);if (instanceof<string>(&keyVector[i])) {string temp = *(string*)&keyVector[i];memcpy(_block->data + keyOffset, temp.c_str(), keyLength);}else {memcpy(_block->data + keyOffset, &keyVector[i], keyLength);}valueOffset += step;keyOffset += step;}}else {for (uint32_t i = 0; i < getDataCount(); i++) {memcpy(_block->data + valueOffset, &pageVector[i], valueSize);if (instanceof<string>(&keyVector[i])) {string temp = *(string*)&keyVector[i];memcpy(_block->data + keyOffset, temp.c_str(), keyLength);}else {memcpy(_block->data + keyOffset, &keyVector[i], keyLength);}valueOffset += step;keyOffset += step;}}if (!pageVector.empty())memcpy(_block->data + valueOffset, &pageVector.back(), sizeof(uint32_t));_block->SetPin(false);
}CatalogManager::createIndex部分
将表中列的索引名更新,删除表信息后重新创建表信息
int CatalogManager::createIndex(const string &tableName, const string &attributeName, const string &indexName) {// If the table not existif (!findTable(tableName)) {cout << "Table not exists!" << endl;return 0;}// If the attribute not existif(!findAttribute(tableName, attributeName)) {cout << "Attribute not exists!" << endl;return 0;}// Create the indexvector<Attribute> attributes = getAttribute(tableName);for (int i = 0; i < attributes.size(); i++) {if (attributes[i].name == attributeName) {attributes[i].index = indexName;}}// Update the tableInfodropTable(tableName);createTable(tableName, &attributes);cout << "Success to creat index " << indexName << " on " << tableName << endl;return 1;
}
插入
int Interpreter::execInsert(const string &text, int *shift) {string tableName;vector<string> tuple;vector<vector<string>> tuples;//检查语法错误// Determine whether "into" existsstring word = extractWord(text, shift);if (word != "into") {cout << "Syntax error for no \"into\"" << endl;return 0;}word = extractWord(text, shift);tableName = word;// Determine whether "values" existsword = extractWord(text, shift);if (word != "values") {cout << "Syntax error for no \"values\"" << endl;return 0;}// Determine whether "(" existsword = extractWord(text, shift);if (word != "(") {cout << "Syntax error for no \"(\"" << endl;return 0;}// 处理插入值word = extractWord(text, shift);do {tuple.push_back(word);word = extractWord(text, shift);if (word == ",")word = extractWord(text, shift);// Determine whether ")" existsif (word == ";") {cout << "Syntax error for no \")\"" << endl;return 0;}} while (word != ")");tuples.push_back(tuple);api->insertValue(tableName, &tuple);return 1;
}
void API::insertValue(const string& tableName, vector<string>* tuples)
{int step;int attrindex[10];int p = 0;vector<Attribute> Attributes;Attributes = getTableAttribute(tableName);//表的列列表for (int j = 0; j < Attributes.size(); j++){step = Attributes[j].charSize;if (Attributes[j].index != "none") {attrindex[p] = j;//有索引的列在Attributes中的下标数组p++;}}vector<string> str;for (int i = 0; i < (*tuples).size(); i++) {step = Attributes[i].charSize;//每个列的数据长度string temp((*tuples)[i]);int interval = step - temp.length();//列的数据长度和插入的值长度的差(空闲的长度)if (Attributes[i].dataType == Attribute::TYPE_CHAR) {for (int j = 0; j < interval; ++j) {temp = "!" + temp;//补上空闲的长度}}else {for (int j = 0; j < interval; ++j) {temp = "0" + temp;}}str.push_back(temp);//补全长度的待插入数组}string record = "%";for (int j = 0;j < str.size();j++)record.append(str[j]);//待插入数组按顺序拼成一个字符串,开头加一个%int recordsize = record.size();struct RecordPosition recordposition;recordposition = rm->InsertRecord(tableName, &record, recordsize);for (int k = 0;k < p;k++) {insertIndex(tableName, Attributes[attrindex[k]], (*tuples)[attrindex[k]], recordposition);//插入值时若列本就有索引,就让插入的值也具备索引}cout << "Success to insert value!" << endl;
}//将记录插入到表文件的块中
struct RecordPosition RecordManager::InsertRecord(string tablename, string* record, int recordsize) {string tablefilename = "../data/" + tablename + ".txt";struct RecordPosition recordposition;recordposition.blockNum = 0;recordposition.recordNum = 0;//初始化if (!bufferManager.IsFileRegistered(tablefilename)) {bufferManager.LoadFile(tablefilename);}int i = bufferManager.GetFileSize(tablefilename);class Block* btmp = bufferManager.GetFileBlock(tablefilename, i - 1);int recordNum = (btmp->GetSize() - 4) / recordsize;if (btmp == NULL) {cout << "insert " << tablename << " record fails" << endl;return recordposition;}if (recordsize + 1 <= BLOCK_SIZE - btmp->GetSize()) {//当前块可以容纳要插入的记录char* addr = btmp->data + btmp->GetSize();//当前块剩余空间的起始地址memcpy(addr, record->c_str(), recordsize);//复制记录到块btmp->SetSize(btmp->GetSize() + recordsize);btmp->SetDirty(true);recordposition.blockNum = i;recordposition.recordNum = recordNum + 1;return recordposition;}else {bufferManager.SaveFile(tablefilename);bufferManager.AppendFile(tablefilename);return InsertRecord(tablename, record, recordsize);}
}
删除
int Interpreter::execDelete(const string &text, int *shift) {string tableName;// Determine whether "from" existsstring word = extractWord(text, shift);if (word != "from") {cout << "Syntax error for no \"from\"" << endl;return 0;}word = extractWord(text, shift);tableName = word;//判断句子是否结束word = extractWord(text, shift);// Sentence is overif (word == ";") {api->deleteTable(tableName);return 1;}// 存在条件语句else if (word == "where") {vector<Condition> conditions;string attributeName;int operate;string value;// 提取所有条件do {word = extractWord(text, shift);attributeName = word;//条件左值word = extractWord(text, shift);if (word == "=")operate = Condition::OPERATOR_EQUAL;else if (word == "<")operate = Condition::OPERATOR_LESS;else if (word == ">")operate = Condition::OPERATOR_MORE;else if (word == "<=")operate = Condition::OPERATOR_LESS_EQUAL;else if (word == ">=")operate = Condition::OPERATOR_MORE_EQUAL;else if (word == "<>")operate = Condition::OPERATOR_NOT_EQUAL;else {cout << "Syntax error for condition" << endl;return 0;}word = extractWord(text, shift);value = word;//条件右值// 创建并存储条件Condition condition(attributeName, operate, value);conditions.push_back(condition);word = extractWord(text, shift);} while (word == "and");// 确定";"是否存在if (word != ";") {cout << "Syntax error for no \";\"" << endl;return 0;}api->deleteRecord(tableName, &conditions);return 1;} else {cout << "Syntax error" << endl;return 0;}
}
删除表
void API::deleteTable(const string &tableName) {vector<Attribute> Attributes;Attributes = getTableAttribute(tableName);rm->DeleteAllRecords(tableName, &Attributes);cout << "Success to delete the table!" << endl;
}bool RecordManager::DeleteAllRecords(string tablename, vector<Attribute>* Attributes)
{string tablefilename = "../data/" + tablename + ".txt";if (!bufferManager.IsFileRegistered(tablefilename)) {bufferManager.LoadFile(tablefilename);}bufferManager.ResetFile(tablefilename);return true;
}void BufferManager::ResetFile(const string& fileName){vector<int> bufferIdxVec;int bufferIdx, firstBufferIdx;ifstream is;ofstream os;//Block* block;if(fileBuffer.find(fileName) != fileBuffer.end()){//查找表文件//block = GetFileBlock(fileName, 0);if(fileBuffer[fileName].find(0) == fileBuffer[fileName].end()){//该表文件没有块is.open(fileName);firstBufferIdx = FetchBlockFromDisk(is, 0);is.close();bufferPool[firstBufferIdx]->fileName = fileName;fileBuffer[fileName][0] = firstBufferIdx;}else{firstBufferIdx = fileBuffer[fileName][0];//文件在bufferPool中的块索引列表中的第一个索引}bufferPool[firstBufferIdx]->pinned = true;//Clear the blockfor (auto iter = fileBuffer[fileName].begin(); iter != fileBuffer[fileName].end(); ++iter){//遍历文件的块索引列表if(iter->first != 0){//剔除第一个块,因为第一个块存放信息bufferIdxVec.push_back(iter->second);//待删除的块索引}}for (auto iter = bufferIdxVec.begin(); iter != bufferIdxVec.end(); ++iter) {bufferIdx = *iter;FreeBlock(bufferIdx);}//Make the first block emptybufferPool[firstBufferIdx]->block->SetSize(4);os.open(fileName);//ofstream.open()清空文件写入os.seekp(0, os.beg);os.write(bufferPool[firstBufferIdx]->block->data, BLOCK_SIZE);os.close();fileSize[fileName] = 1;bufferPool[firstBufferIdx]->lastUsedTime = clock();bufferPool[firstBufferIdx]->dirty = false;bufferPool[firstBufferIdx]->pinned = false;}
}
删除记录?
void API::deleteRecord(const string &tableName, vector<Condition> *conditions) {vector<Attribute> Attributes;Attributes = getTableAttribute(tableName);deletewithconditions(tableName, &Attributes, conditions);
}void API::deletewithconditions(string tablename, vector<Attribute>* Attributes, vector<Condition>* conditions)
{int n = conditions->size();int s = Attributes->size();int recordsize = rm->getrecordsize(Attributes);//表列大小之和(记录的大小)vector<RecordPosition> repo;int flag = 0;//标记是否找有索引int flag1 = 0;//标记是否有数据被删除vector<Condition> condwithouindex; //将没有index的conditions放在一起for (int i = 0;i < n;i++){for (int j = 0;j < s;j++) {if ((*conditions)[i].name == (*Attributes)[j].name)//遍历表列列表找条件左值{if ((*Attributes)[j].index != "none" && flag == 0) {repo = indexforcondition(tablename, (*Attributes)[j], (*conditions)[i].operate, (*conditions)[i].value); //在API里调用index搜索,返回有Index的查找条件对应数据所在位置flag = 1;}else {//无索引或者前面的循环已找到了索引,但是因为该项目只支持单列索引,所以只有可能是无索引condwithouindex.push_back((*conditions)[i]);}}}}if (flag == 1) {flag1 = rm->selectwithoutindex(tablename, Attributes, &repo, &condwithouindex); //获得没有条件、不在索引上的被筛选出数据的位置}else {flag1 = rm->deletebyorders(tablename, Attributes, conditions);}bufferManager.SaveFile(tablename);if (flag1 == 0) {cout << "There are no records can be deleted!" << endl;}else {cout << "Sucessfully deleted!" << endl;}
}
vector<RecordPosition> API::indexforcondition(const string& tableName, Attribute attribute, int operate, const string& _value)
{char* value;int tempInt = atoi(_value.c_str());float tempFloat = atof(_value.c_str());switch (attribute.dataType) {//intcase 0: value = (char*)&tempInt; break;//floatcase 1: value = (char*)&tempFloat; break;//stringdefault: value = (char*)&_value; break;}return im.findIndexBlockNumber(tableName, attribute, value, operate);
}//通过索引文件查找块号
vector<RecordPosition> IndexManager::findIndexBlockNumber(string _tableName, Attribute _attribute, char* _key, int type)
{vector<RecordPosition> result;switch (_attribute.dataType) {case 0: {BplusTree<int> bptree = BplusTree<int>(_tableName, _attribute.name);bptree.findValueWithKey(CHAR2INT(_key),result,type);}break;case 1: {BplusTree<float> bptree = BplusTree<float>(_tableName, _attribute.name);bptree.findValueWithKey(CHAR2FLOAT(_key),result,type);}break;case 2: {BplusTree<string> bptree = BplusTree<string>(_tableName, _attribute.name);bptree.findValueWithKey(CHAR2STRING(_key),result,type);}break;default:cout << "wrong attribute type" << endl;break;}return result;
}
//不使用索引进行SELECT
int RecordManager::selectwithoutindex(string tablename, vector<Attribute>* Attributes, vector<RecordPosition>* rep, vector<Condition>* conditions) {string tablefilename = "../data/" + tablename + ".txt";int recordsize = getrecordsize(Attributes);if (!bufferManager.IsFileRegistered(tablefilename)) {bufferManager.LoadFile(tablefilename);}int flag = 0;Block* btmp;string str;for (int i = 0; i < rep->size(); i++) {btmp = bufferManager.GetFileBlock(tablefilename, (*rep)[i].blockNum - 1);str = (*(btmp->GetRecords((*rep)[i].recordNum - 1, (*rep)[i].recordNum, recordsize)))[0];if (str.at(0) == '%') {if (isSatisfied(Attributes, &str, conditions)) {if (flag == 0) printouttablehead(Attributes);//打印表头putout(str, Attributes);flag = 1;}}}return flag;
}//记录字符串record的Attributes中标识的列是否满足条件conditions
bool RecordManager::isSatisfied(vector<Attribute>* Attributes, string* record, vector<Condition>* conditions)
{if(conditions->size() == 0)return true;int s = conditions->size();int n = Attributes->size();int attr[100];int position[100];int step = 0;for (int i = 0; i < s; i++){position[i] = 0;for (int j = 0; j < n; j++){step += (*Attributes)[j].charSize;if (((*Attributes)[j].name) == ((*conditions)[i].name)){attr[i] = j;position[i] += step;break;}}step = 0;}for (int k = 0;k < s;k++){if ((*conditions)[k].value != "") {if ((*Attributes)[attr[k]].dataType == 0) {int step = (*Attributes)[attr[k]].charSize;string com = (*conditions)[k].value;string tem = (*record).substr(position[k] - step + 1, step);int temp = stoi(tem);int con = stoi(com);switch ((*conditions)[k].operate) {case 0: if (!(temp == con)) return false; break;case 1: if (!(temp != con)) return false; break;case 2: if (!(temp < con)) return false; break;case 3: if (!(temp > con)) return false; break;case 4: if (!(temp <= con)) return false; break;case 5: if (!(temp >= con)) return false; break;default: break;}}else if ((*Attributes)[attr[k]].dataType == 1) {int step = (*Attributes)[attr[k]].charSize;string com = (*conditions)[k].value;string tem = (*record).substr(position[k] - step + 1, step);float temp = stof(tem);float con = stof(com);switch ((*conditions)[k].operate) {case 0: if (!(abs(temp - con) < 1e-3)) return false; break;case 1: if (!(temp != con)) return false; break;case 2: if (!(temp < con)) return false; break;case 3: if (!(temp > con)) return false; break;case 4: if (!(temp <= con)) return false; break;case 5: if (!(temp >= con)) return false; break;default: break;}}else {int step = (*Attributes)[attr[k]].charSize;string con = (*conditions)[k].value;string temp = (*record).substr(position[k] - step + 1, step);int h;for (h = 0;h < step;h++) {if (temp.at(h) != '!') break;}temp = temp.substr(h);switch ((*conditions)[k].operate) {case 0: if (!(temp == con)) return false; break;case 1: if (temp == con) return false; break;case 2: if (!(temp < con)) return false; break;case 3: if (!(temp > con)) return false; break;case 4: if (!(temp < con || temp == con)) return false; break;case 5: if (!(temp > con || temp == con)) return false; break;default: break;}}}}return true;
}void RecordManager::printouttablehead(vector<Attribute>* Attributes)
{cout << "|";for (int i = 0;i < Attributes->size();i++){cout.setf(ios::left);cout.width(10);cout << (*Attributes)[i].name;cout << "|";}cout << endl;
}void RecordManager::putout(string str, vector<Attribute>* Attributes)
{int p = 1;cout << "|";for (auto& Attribute : *Attributes) { //遍历所有属性int typesize = Attribute.charSize;string tem = str.substr(p, typesize);if (Attribute.dataType == 0) {int n = stoi(tem);cout.width(10);cout << n;cout << "|";}else if (Attribute.dataType == 1) {float f = stof(tem);cout.width(10);cout << f;cout << "|";}else {int k;for (k = 0;k < typesize;k++) {if (tem.at(k) != '!') break;}tem = tem.substr(k);cout.width(10);cout << tem;cout << "|";}p += typesize;}cout << endl;
}
查询
/* Process the word "select" 只支持全列查找和where-and */
int Interpreter::execSelect(const string &text, int *shift) {// In case we need to select specific attributes later, use vectorvector<string> attributes;string tableName;// Determine whether "*" existsstring word = extractWord(text, shift);if (word != "*") {cout << "Syntax error for missing \"*\"" << endl;return 0;}attributes.push_back(word);// Determine whether "from" existsword = extractWord(text, shift);if (word != "from") {cout << "Syntax error for missing \"from\"" << endl;return 0;}word = extractWord(text, shift);tableName = word;// Determine whether the sentence is overword = extractWord(text, shift);// Sentence is overif (word == ";") {api->select(tableName, &attributes, nullptr);return 1;}// Conditional statement existselse if (word == "where") {vector<Condition> conditions;string attributeName;int operate;string value;// Extract all conditionsdo {word = extractWord(text, shift);attributeName = word;word = extractWord(text, shift);if (word == "=")operate = Condition::OPERATOR_EQUAL;else if (word == "<")operate = Condition::OPERATOR_LESS;else if (word == ">")operate = Condition::OPERATOR_MORE;else if (word == "<=")operate = Condition::OPERATOR_LESS_EQUAL;else if (word == ">=")operate = Condition::OPERATOR_MORE_EQUAL;else if (word == "<>")operate = Condition::OPERATOR_NOT_EQUAL;else {cout << "Syntax error for condition" << endl;return 0;}word = extractWord(text, shift);value = word;// Create and store the conditionCondition condition(attributeName, operate, value);conditions.push_back(condition);word = extractWord(text, shift);} while (word == "and");// Determine whether the ";" existsif (word != ";") {cout << "Syntax error for no \";\"" << endl;return 0;}api->select(tableName, &attributes, &conditions);return 1;} else {cout << "Syntax error" << endl;return 0;}
}
void API::select(const string& tableName, vector<string>* attributeName, vector<Condition>* conditions) {vector<Attribute> attributes = getTableAttribute(tableName);if (conditions == nullptr) {//无条件,即全列全记录查询rm->PrintAllRecord(tableName, &attributes);}else {selectwithconditions(tableName, &attributes, conditions);}
}void RecordManager::PrintAllRecord(string tablename, vector<Attribute>* Attributes)
{Block* btmp;int recordsize = getrecordsize(Attributes);string tablefilename = "../data/" + tablename + ".txt";if (!bufferManager.IsFileRegistered(tablefilename)) {bufferManager.LoadFile(tablefilename);}int blocknum = bufferManager.GetFileSize(tablefilename);//文件块数string str;string tem;for (int i = 0;i < blocknum;i++) {//遍历块btmp = bufferManager.GetFileBlock(tablefilename, i);int recordnum = (btmp->GetSize() - 4) / recordsize;//块中记录数if (i == 0 && recordnum == 0) {cout << "The table is empty!" << endl;break;}for (int j = 0;j < recordnum;j++) {//遍历块中记录if (i == 0 & j == 0) {printouttablehead(Attributes);}int p = 1;str = (*(btmp->GetRecords(j, j + 1, recordsize)))[0];if (str.at(0) == '%') {cout << "|";for (auto& Attribute : *Attributes) { //遍历表中所有属性int typesize = Attribute.charSize;tem = str.substr(p, typesize);//取出记录中对应属性列的数据if (Attribute.dataType == 0) {int n = stoi(tem);cout.width(10);cout << n;cout << "|";}else if (Attribute.dataType == 1) {float f = stof(tem);cout.width(10);cout << f;cout << "|";}else {int k;for (k = 0;k < typesize;k++) {if (tem.at(k) != '!') break;}tem = tem.substr(k);cout.width(10);cout << tem;cout << "|";}p = p + typesize;}cout << endl;}}}
}//有where条件的查询
void API::selectwithconditions(string tablename, vector<Attribute>* Attributes, vector<Condition>* conditions)
{int n = conditions->size();int s = Attributes->size();int recordsize = rm->getrecordsize(Attributes);vector<RecordPosition> repo;int flag = 0;//标记是否找有索引int flag1 = 0;//标记是否找到相应记录vector<Condition> condwithouindex; //将没有index的conditions放在一起for (int i = 0;i < n;i++){for (int j = 0;j < s;j++) {if ((*conditions)[i].name == (*Attributes)[j].name){if ((*Attributes)[j].index != "none" && flag == 0) {repo = indexforcondition(tablename, (*Attributes)[j], (*conditions)[i].operate, (*conditions)[i].value); //在API里调用index搜索,返回有Index的查找条件对应数据所在位置flag = 1;}else {condwithouindex.push_back((*conditions)[i]);}}}}if (flag == 1) {flag1 = rm->selectwithoutindex(tablename, Attributes, &repo, &condwithouindex); //获得没有条件不在索引上的被筛选出数据的位置}else {flag1 = rm->selectbyorders(tablename, Attributes, conditions);}if (flag1 == 0){cout << "No records!" << endl;}
}int RecordManager::selectbyorders(string tablename, vector<Attribute>* Attributes, vector<Condition>* conditions)
{string tablefilename = "../data/" + tablename + ".txt";if (!bufferManager.IsFileRegistered(tablefilename)) {bufferManager.LoadFile(tablefilename);}int i = bufferManager.GetFileSize(tablefilename.c_str()); //block的数量Block* btmp;int flag = 0;int recordNum;int p = 0;int recordsize;recordsize = getrecordsize(Attributes);string putouts;for (int j = 0;j < i;j++){btmp = bufferManager.GetFileBlock(tablefilename.c_str(), j);if (btmp == NULL) {cout << "The records don't exsit!" << endl;}recordNum = (btmp->GetSize() - 4) / recordsize;for (int k = 0;k < recordNum;k++) //第k+1条记录{putouts = (*(btmp->GetRecords(k, k + 1, recordsize)))[0];if (putouts.at(0) == '%') {if (isSatisfied(Attributes, &putouts, conditions)) {if (flag == 0) printouttablehead(Attributes);putout(putouts, Attributes);flag = 1;}}}}return flag;
}
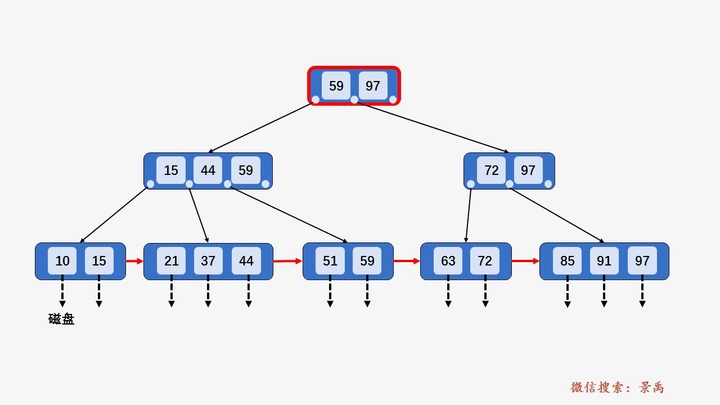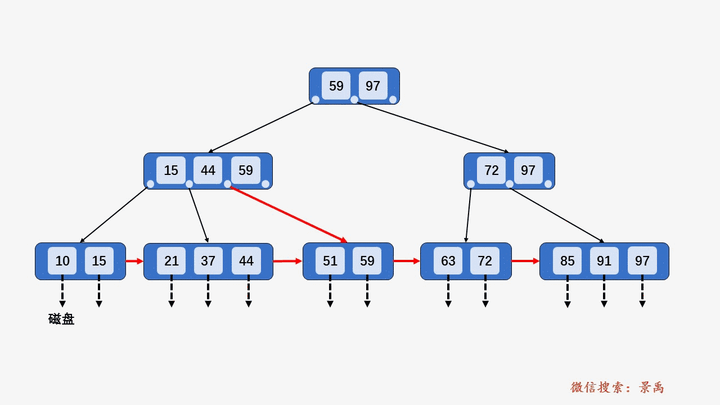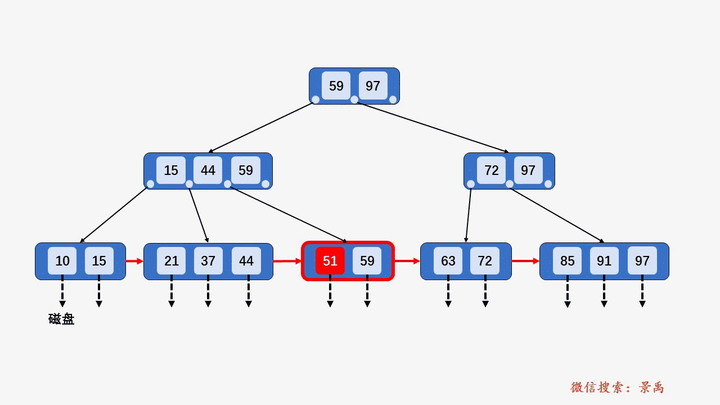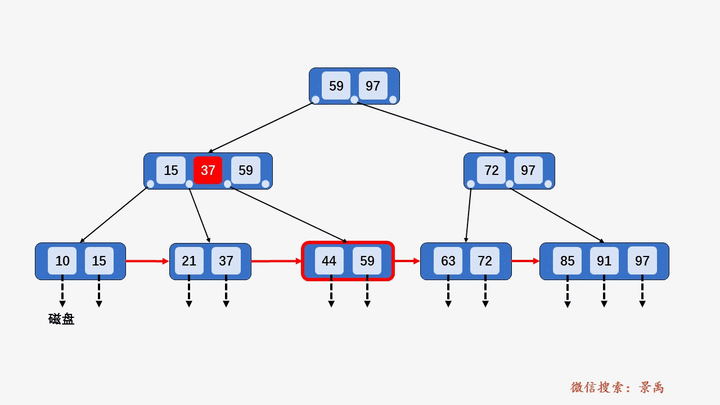
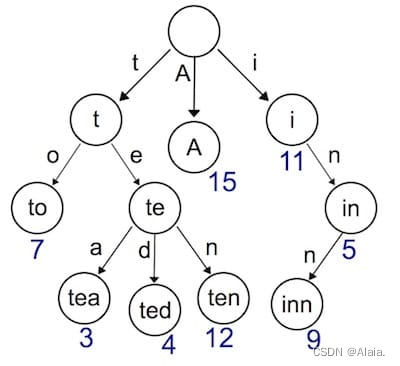
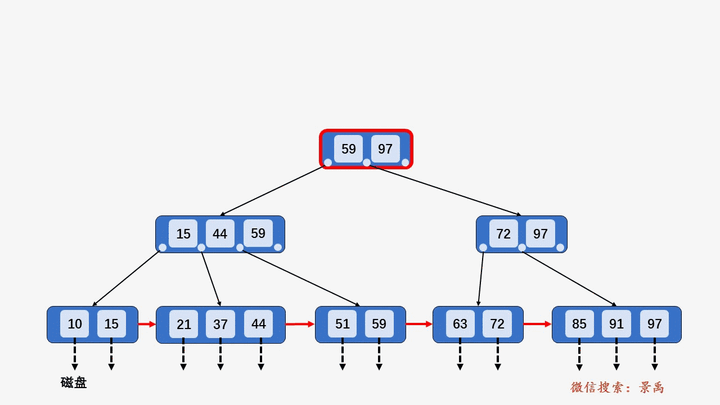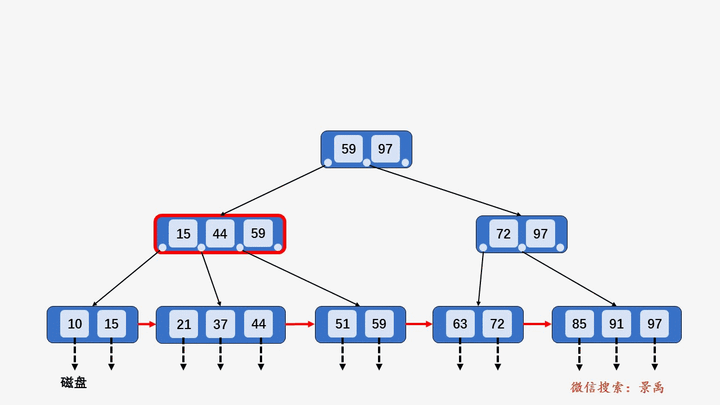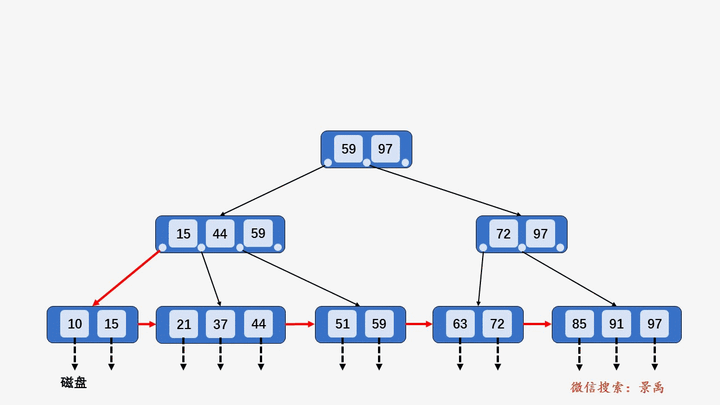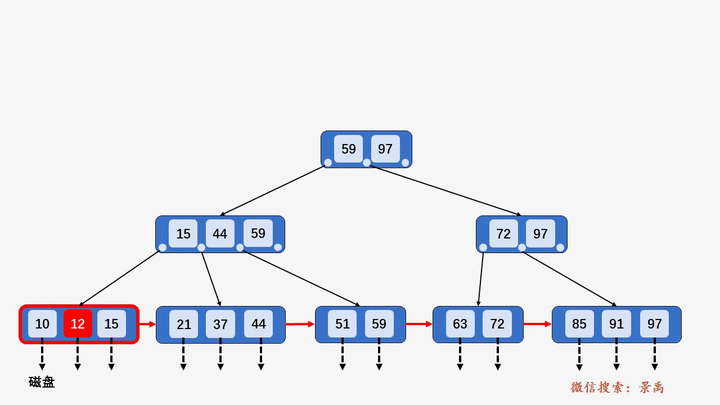
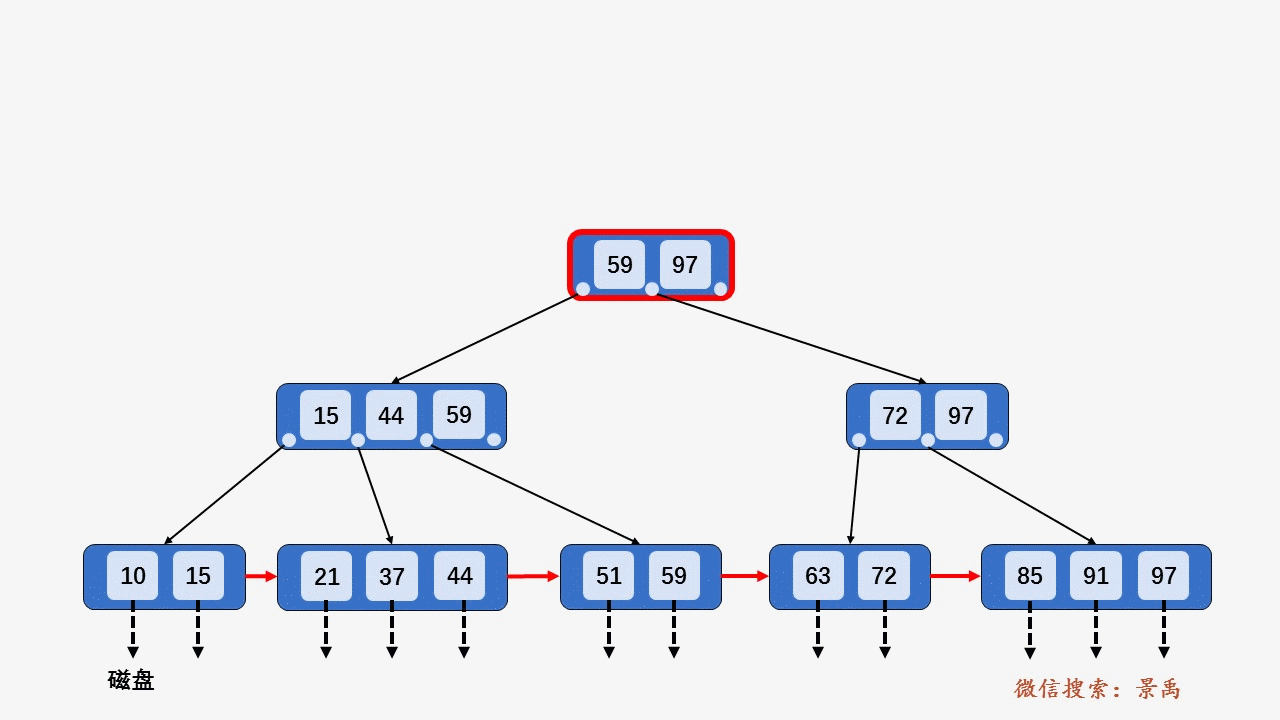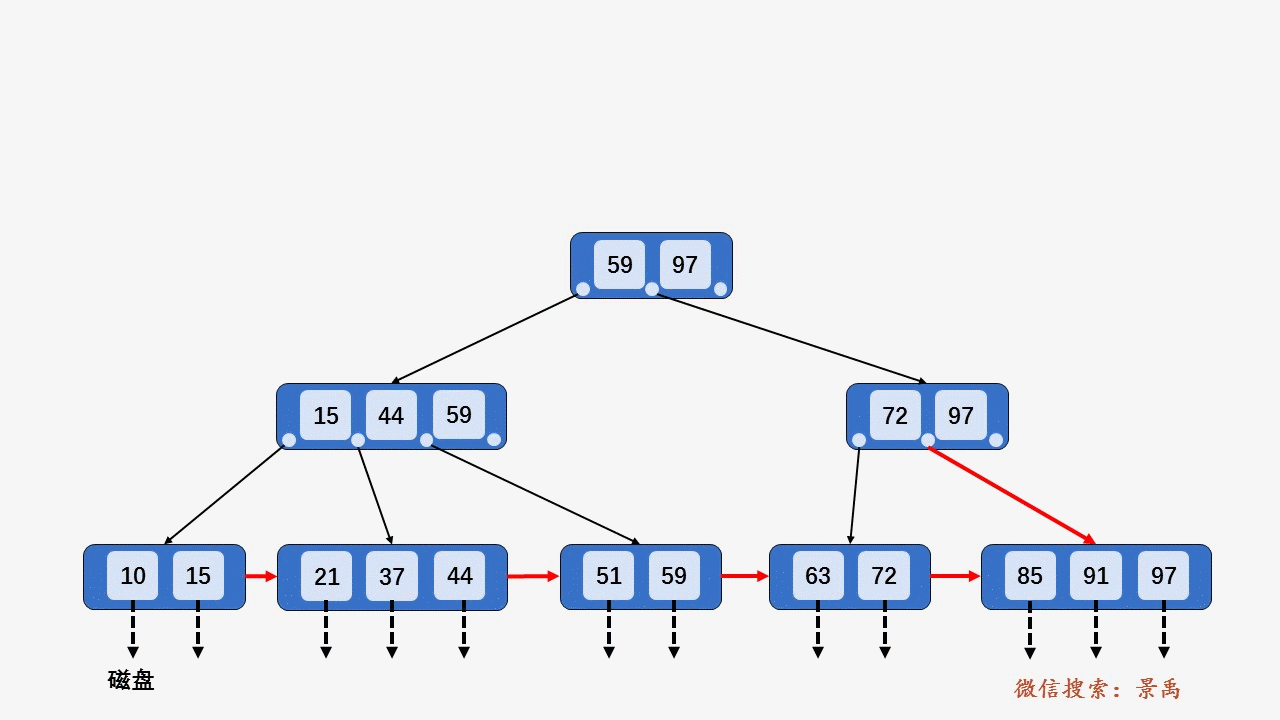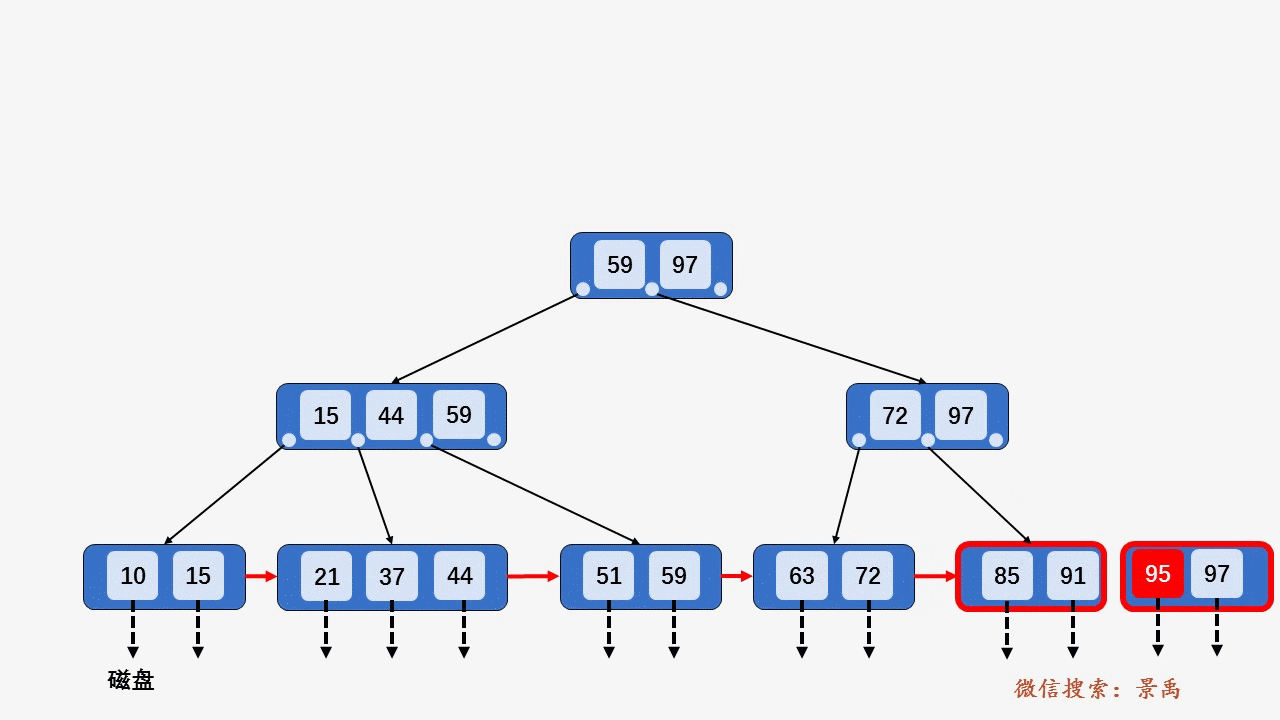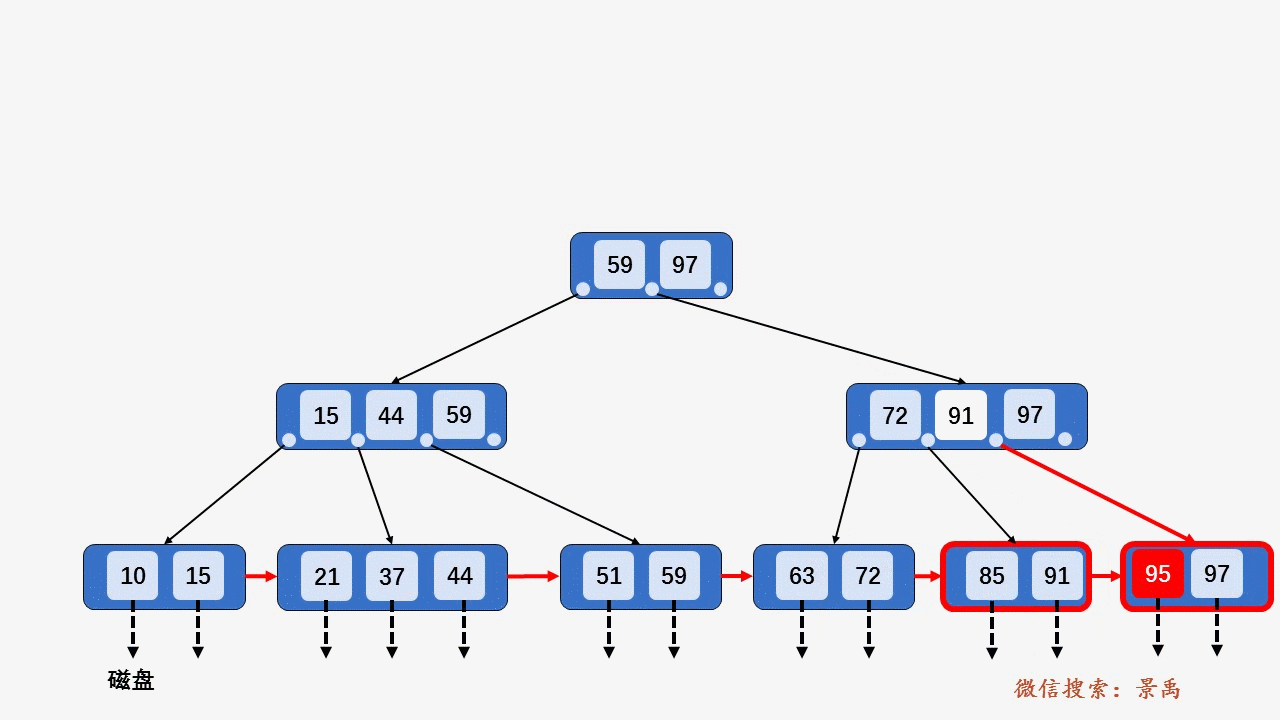
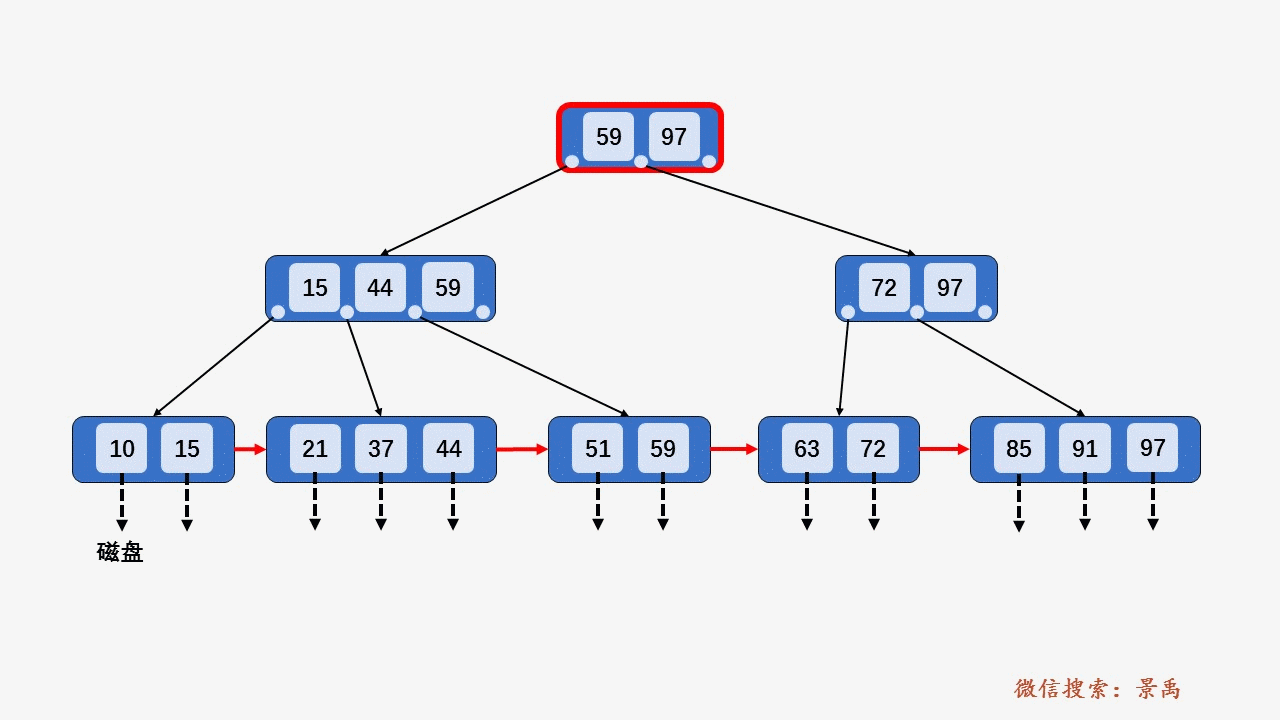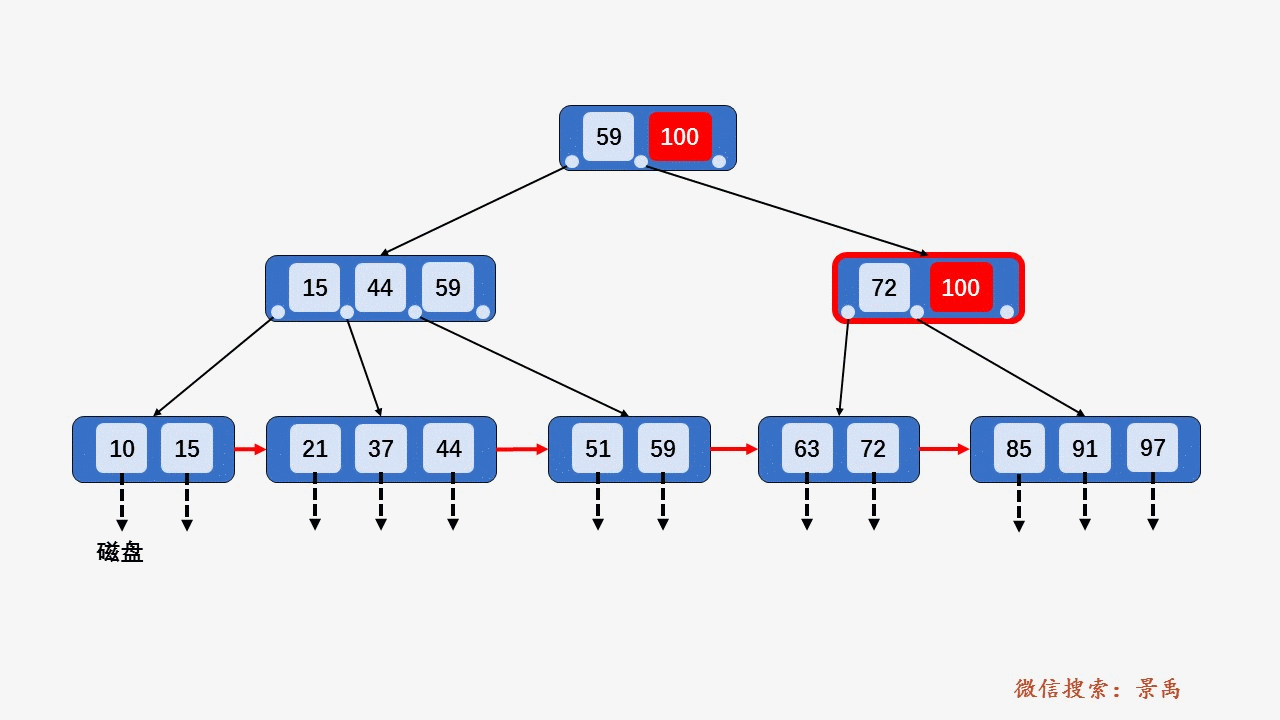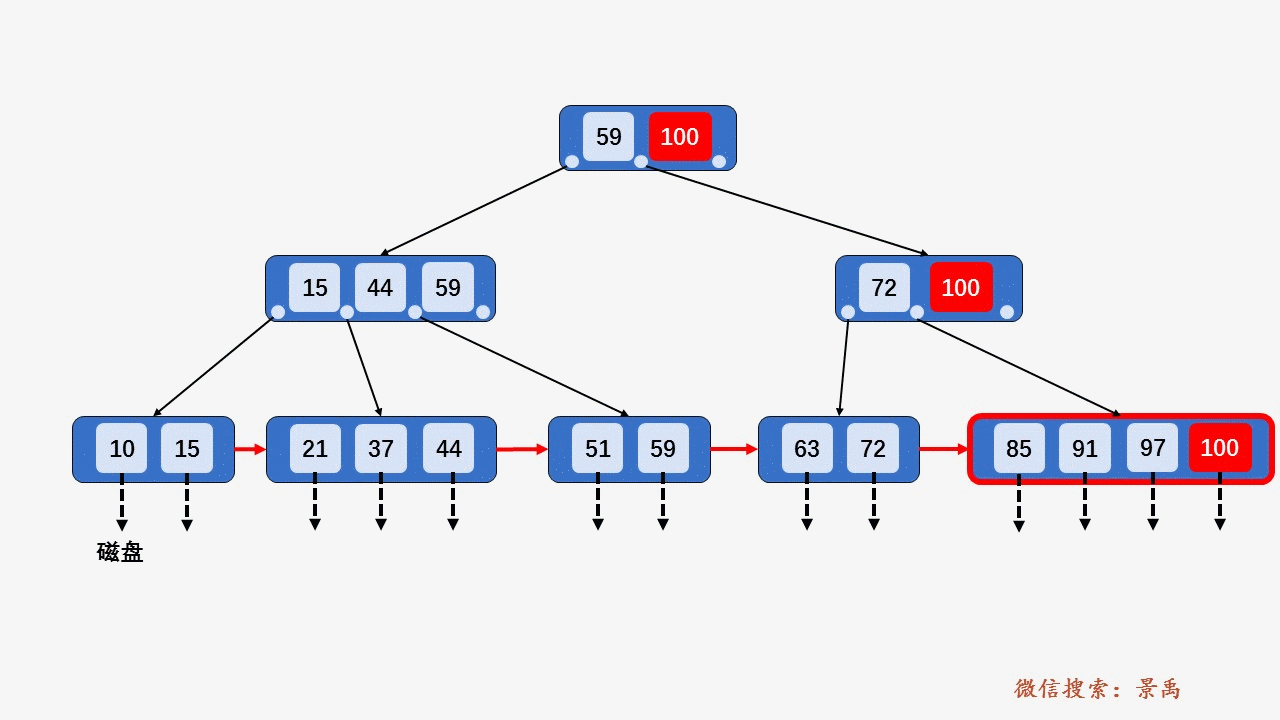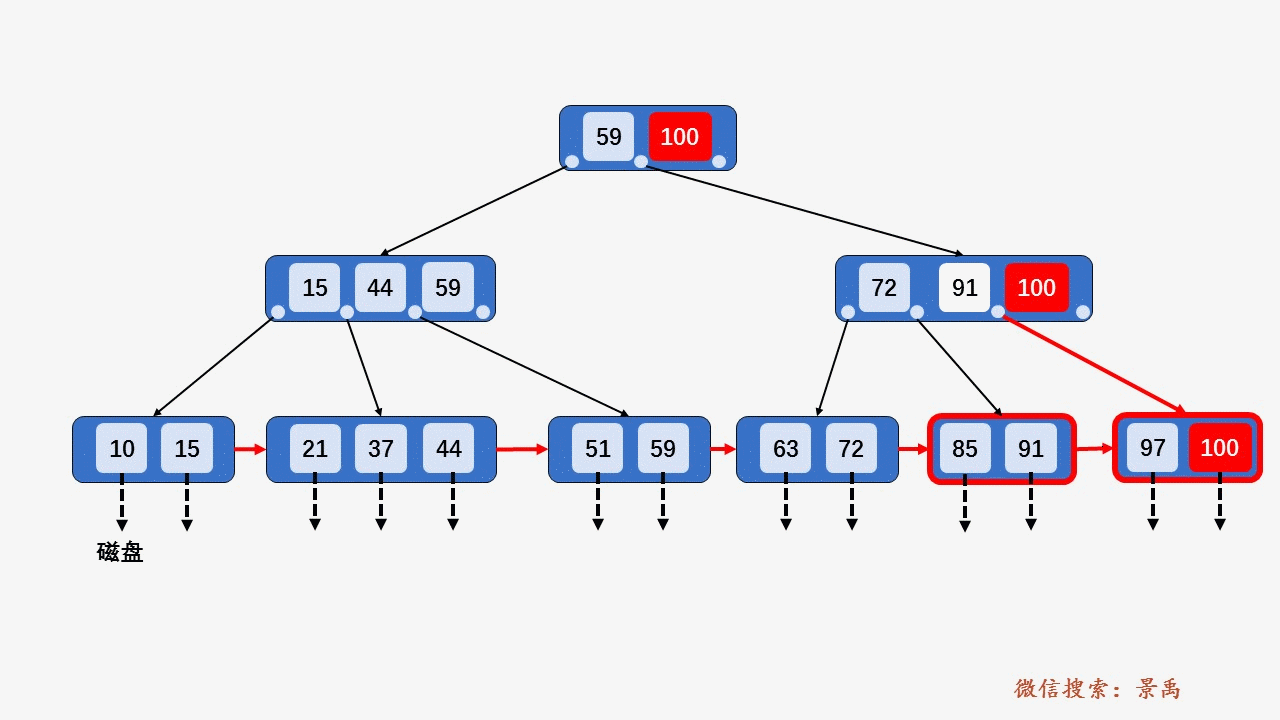
B+树
该项目的索引功能是通过B+树实现的,需要索引时从索引文件中读出索引信息构建B+树,之后B+树销毁,但是索引文件的块一直保存在内存中,如再需要索引就再从索引文件块中读取构建,直到析构BufferMananger时写回到索引文件
BufferManager::~BufferManager(){SaveFile(TABLE_INFO_PATH);for(int i = 0; i < BUFFER_SIZE; i++){if(bufferPool[i]->dirty){fstream os ;os.open(bufferPool[i]->fileName);WriteBlockToDisk(os, bufferPool[i]->idx, bufferPool[i]->block->data);os.close();}delete bufferPool[i];}delete[] bufferPool;delete freeBufferList;
}
在B+树结点类中有如下属性成员:
bool isLeafNode;
uint32_t keyLength;//键长度
uint32_t dataCount;
uint32_t parent;//内部节点使用,指向父节点
uint32_t pageNum;vector<keyType> keyVector;//键数组,若为内部节点用作分隔数据范围,若为叶子节点用作记录的键
vector<uint32_t> pageVector;//页数组,内部节点使用时,与keyVector对应,是子节点的数组。叶子节点使用时,尾结点为下一个叶子节点
vector<RecordPosition> recordVector;//记录数组,叶子节点使用,与keyVector对应,是记录(位置)的数组
B+树类属性成员:
string indexFileName;
uint32_t keyLength;
uint32_t nodeCount;
uint32_t root;//根节点的页编号,也就是在索引文件的第几个块中
uint32_t freePageCount;
vector<uint32_t> freePages;//空闲页数组,当删除结点时存入,减少内存操作,提高B+树性能
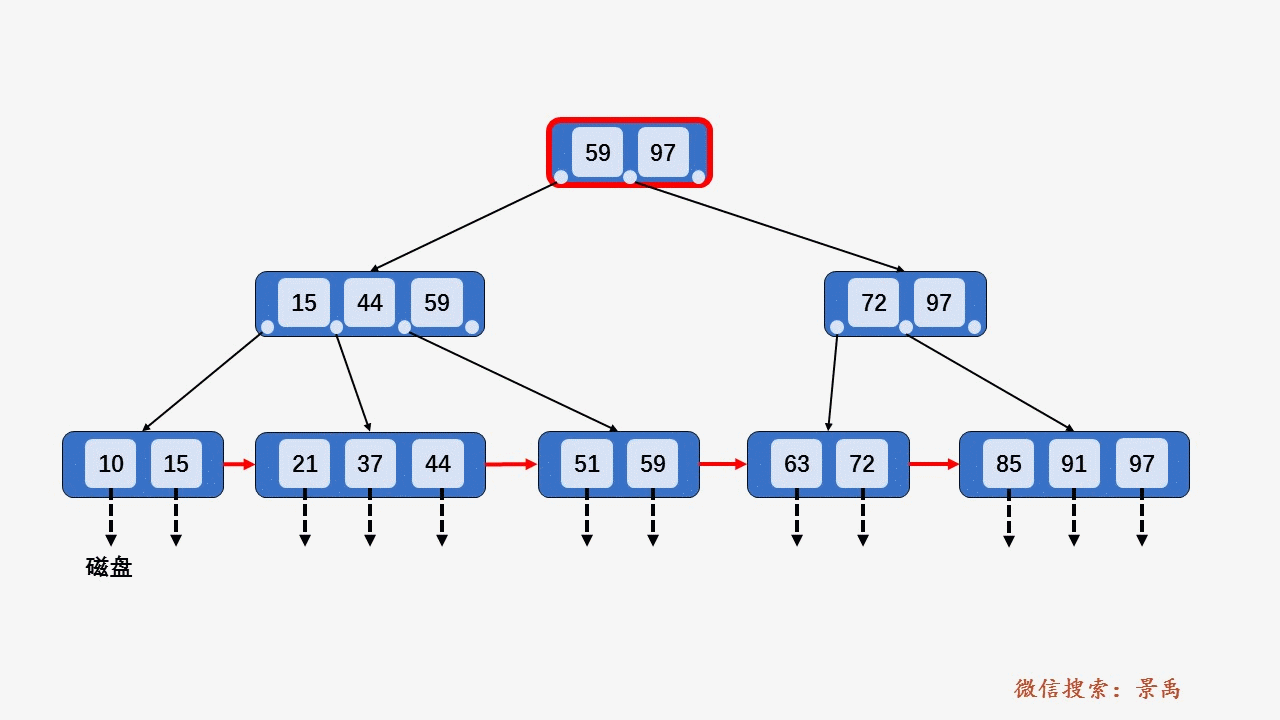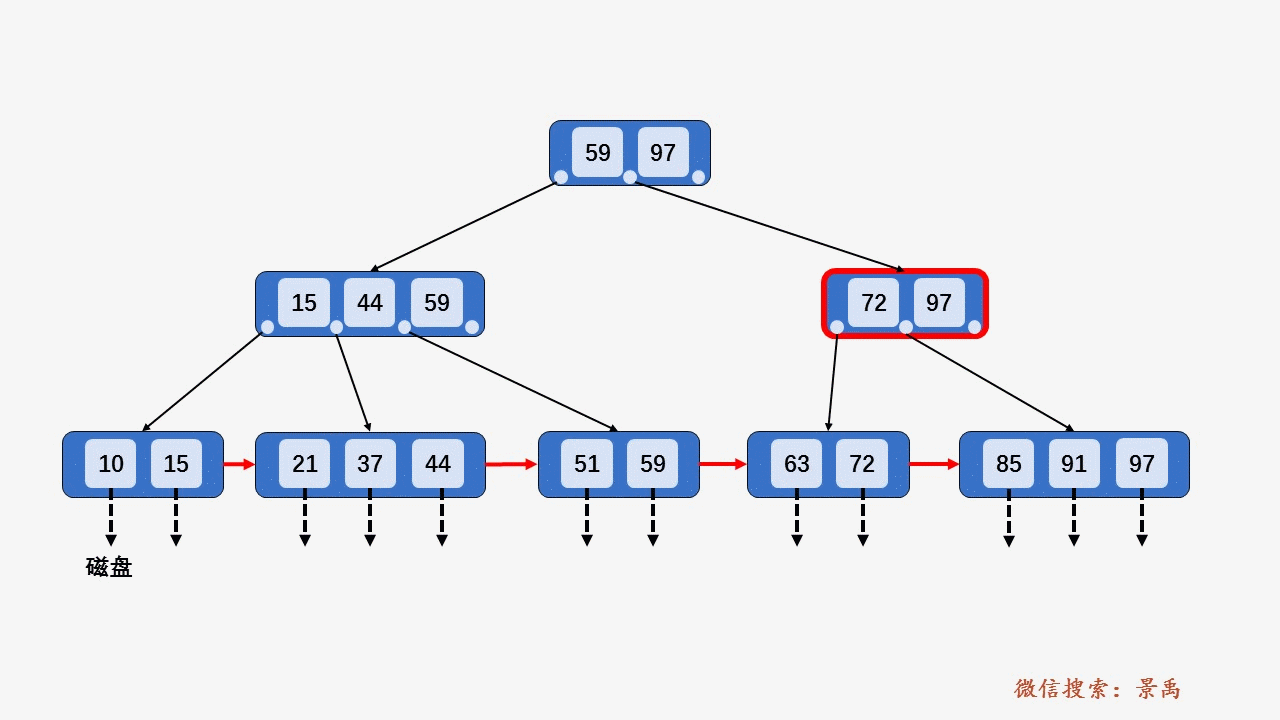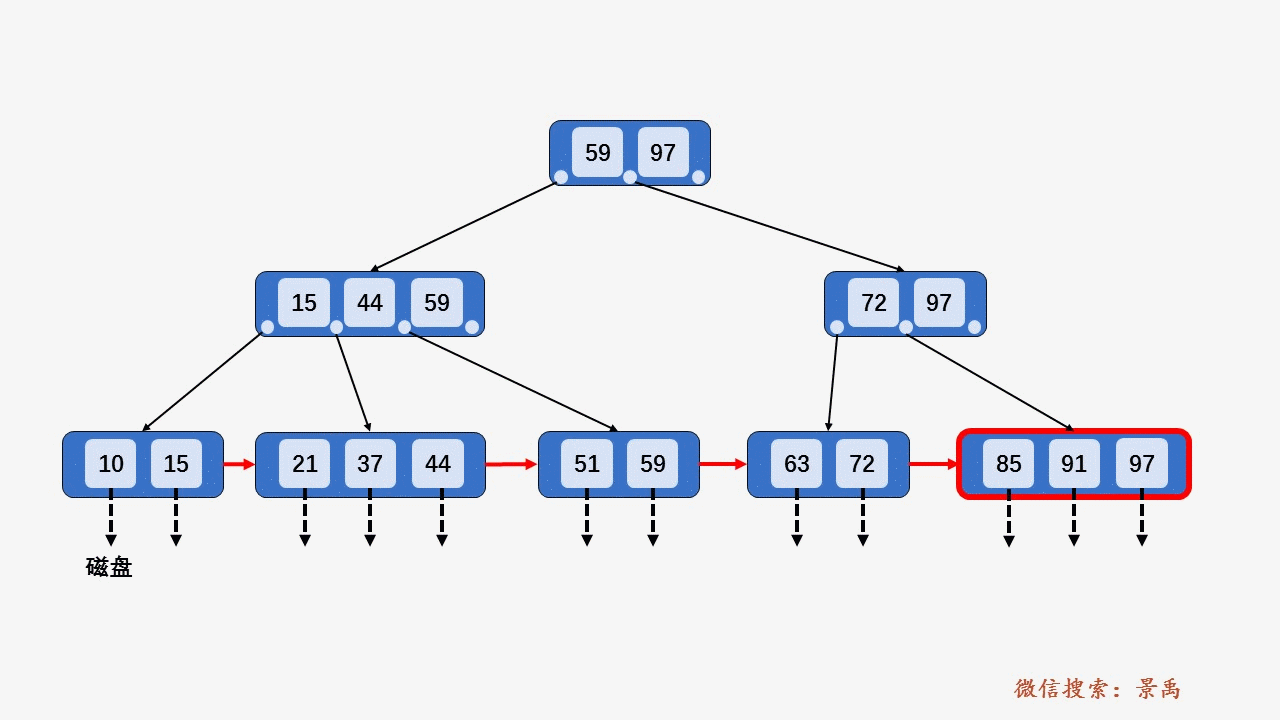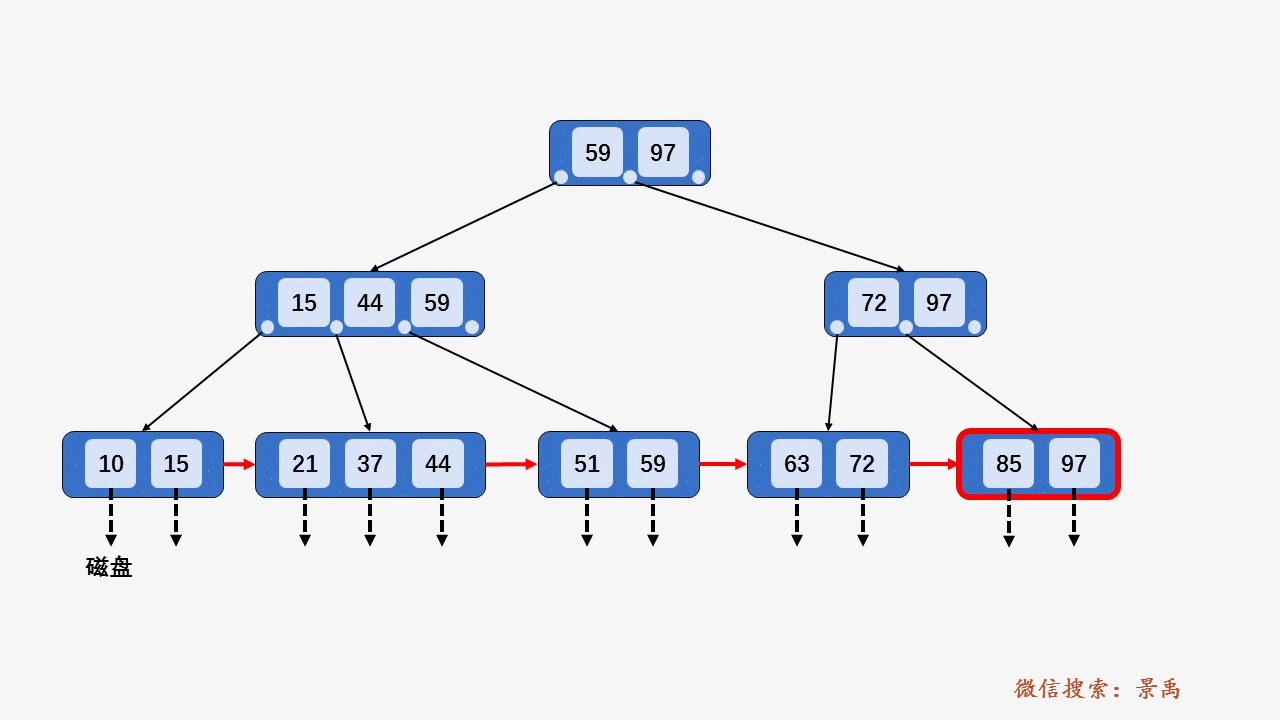
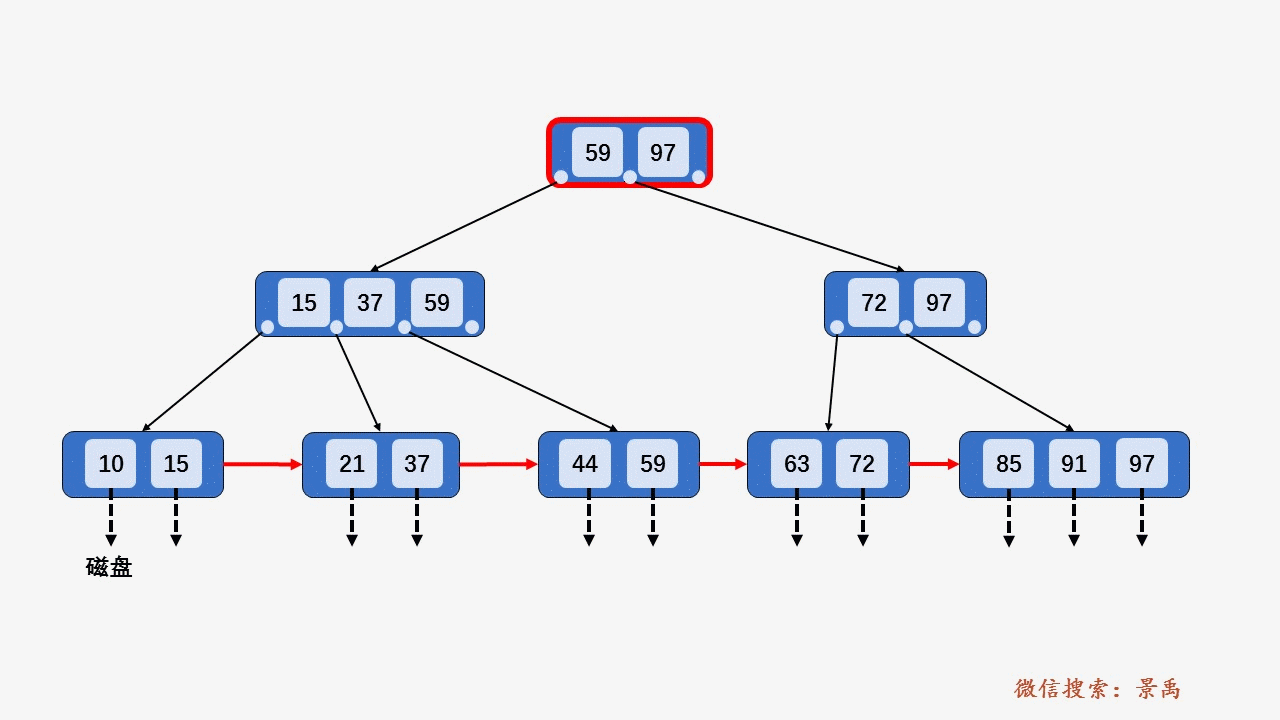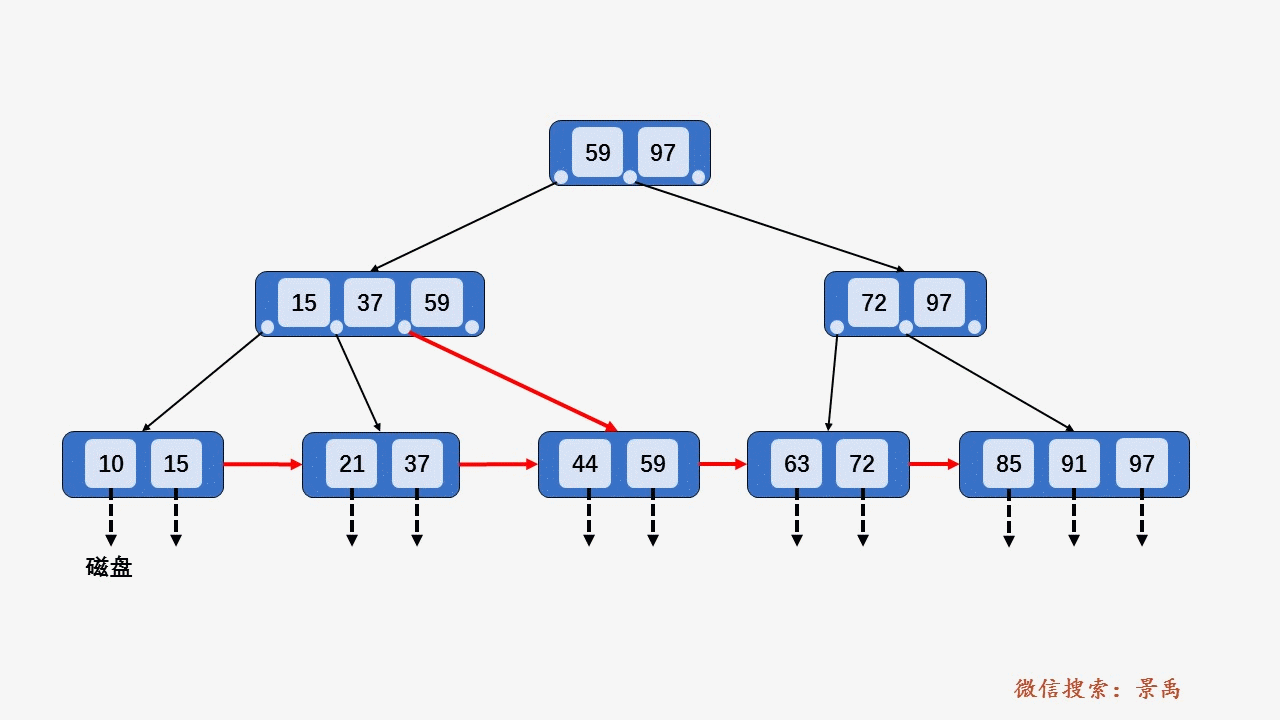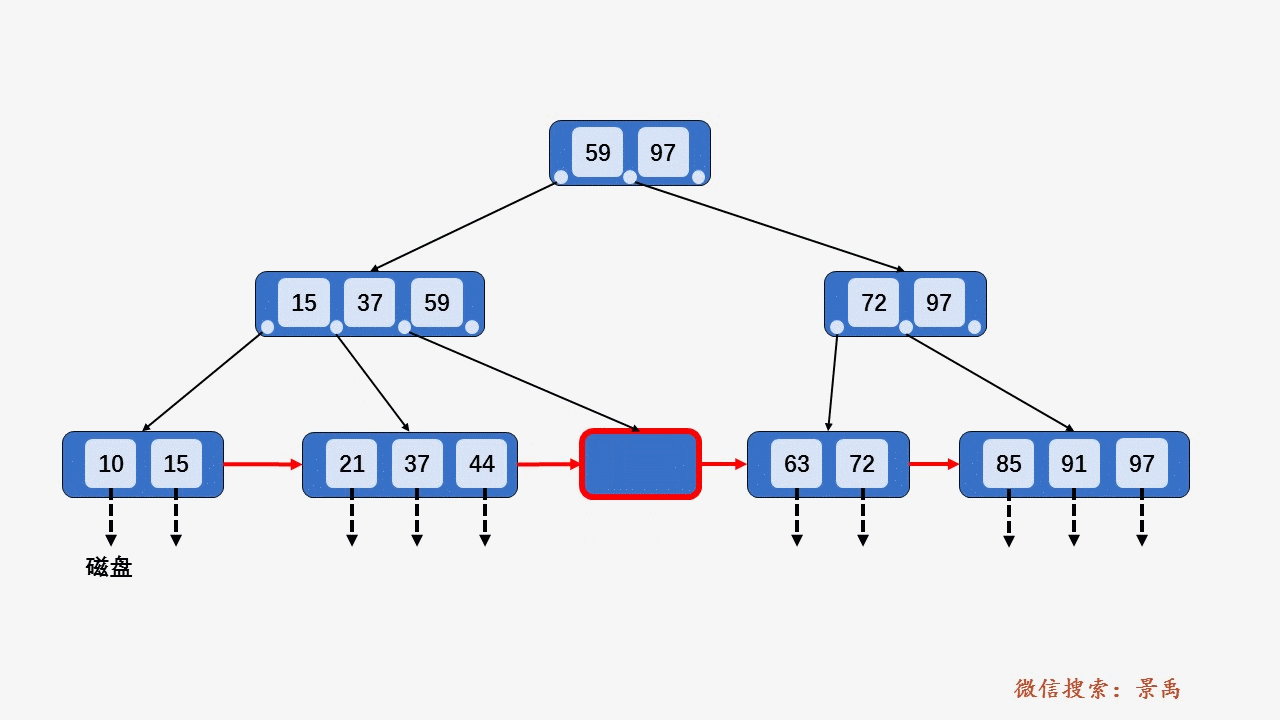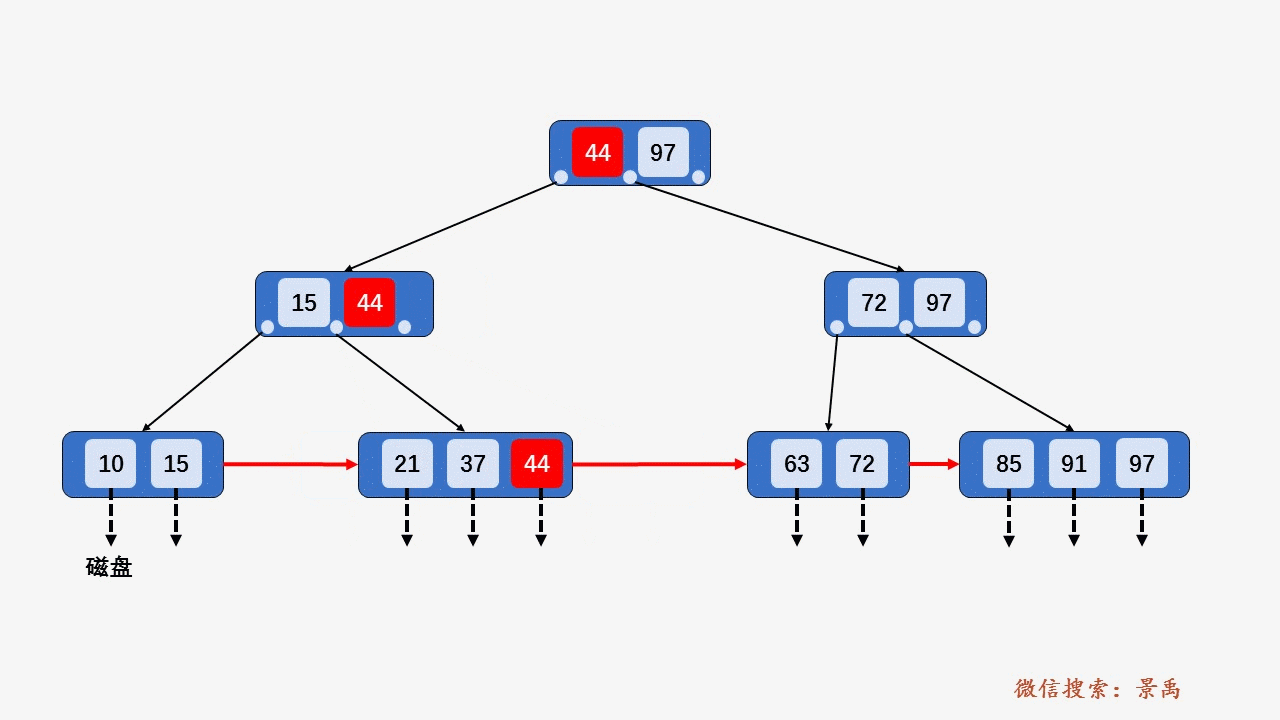
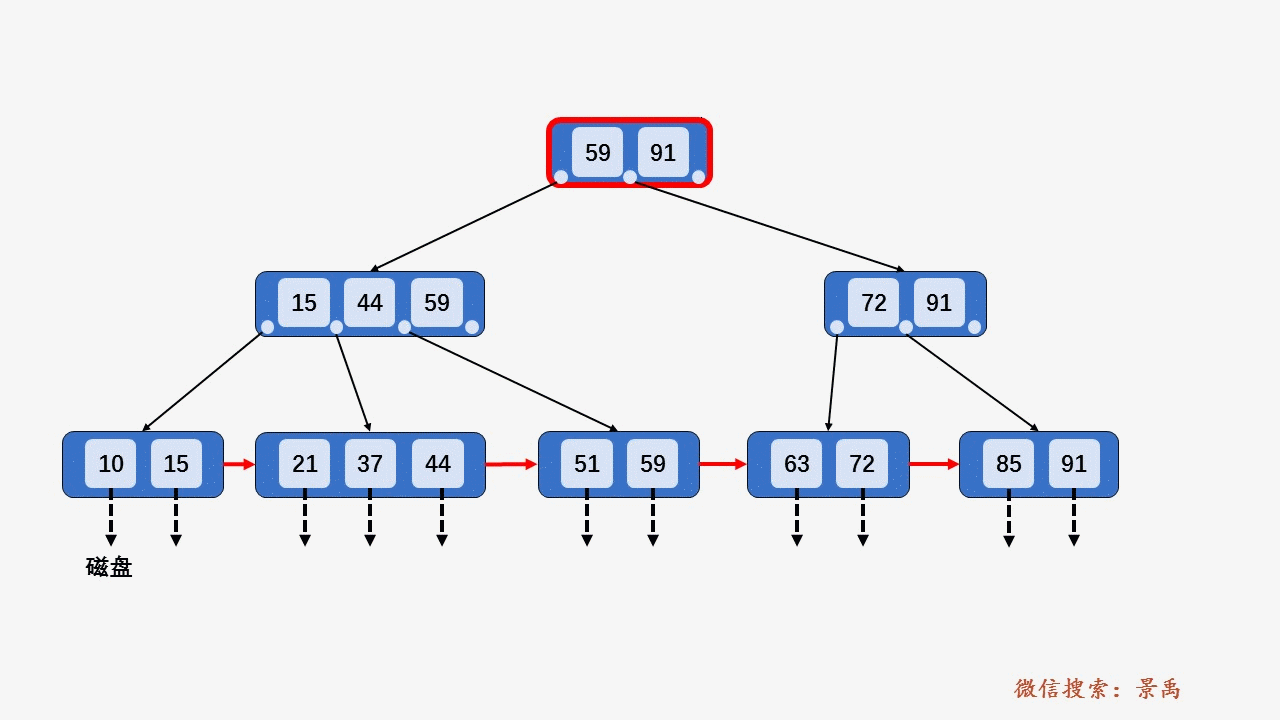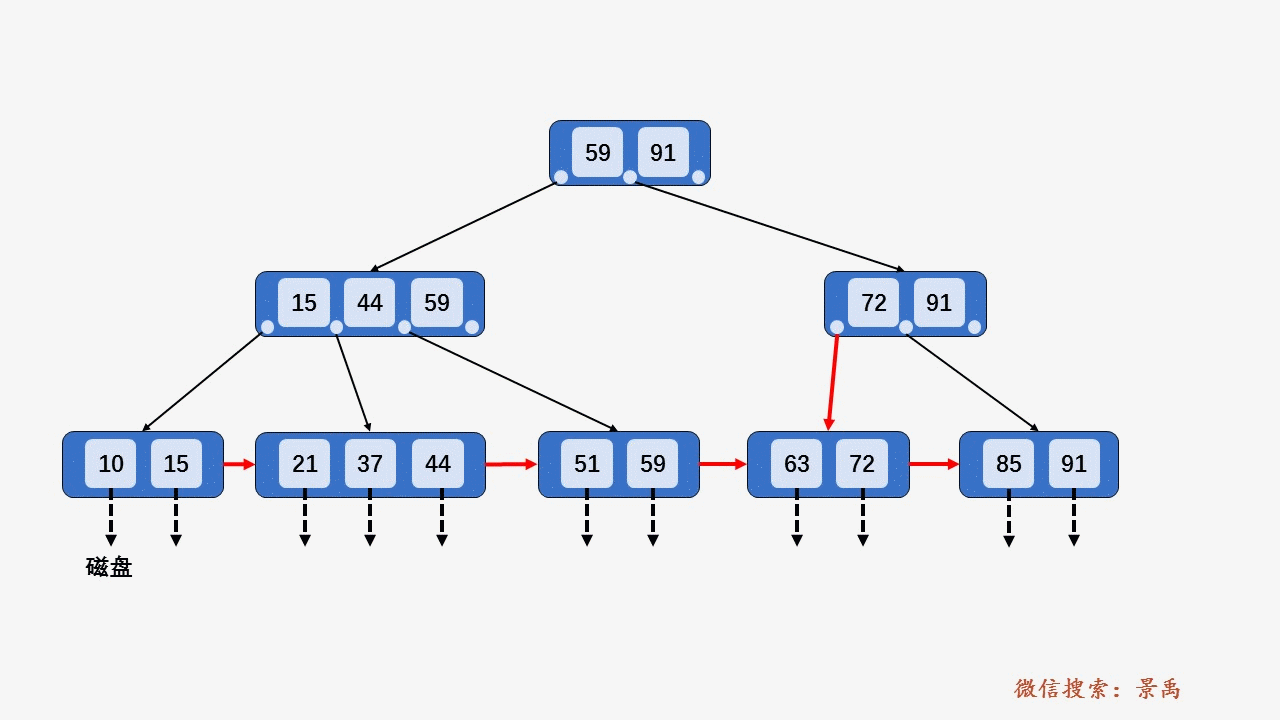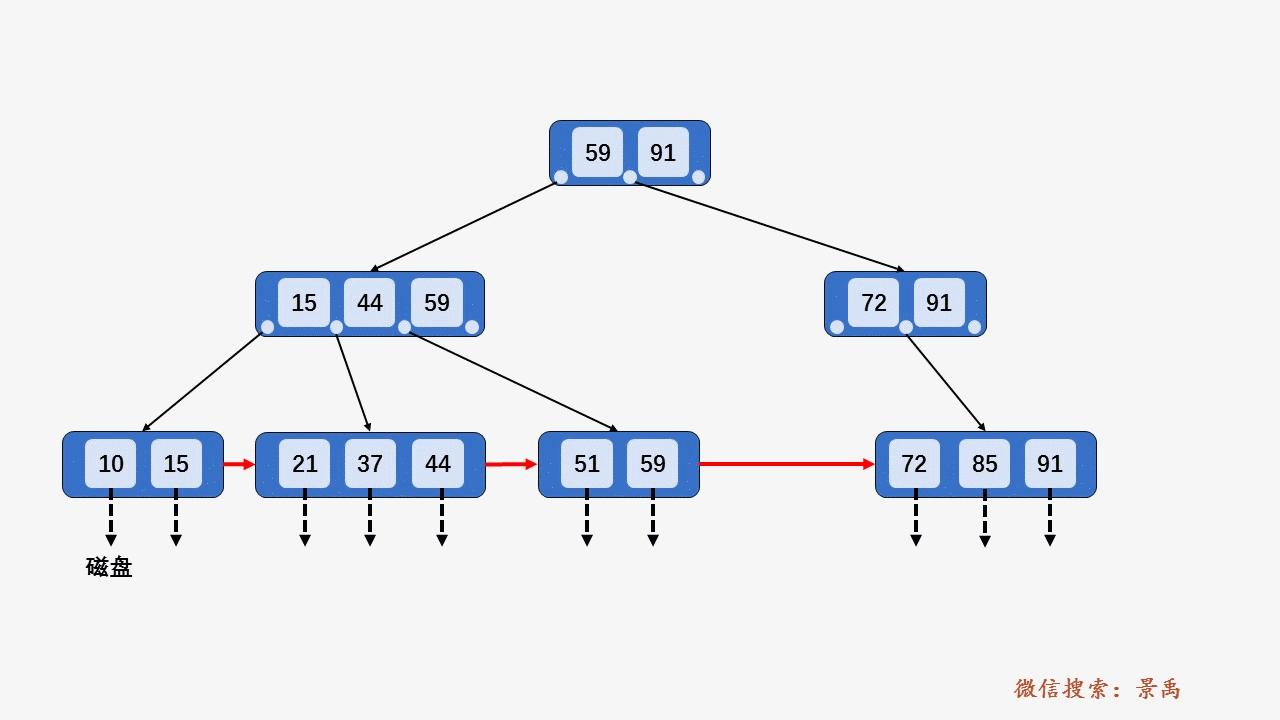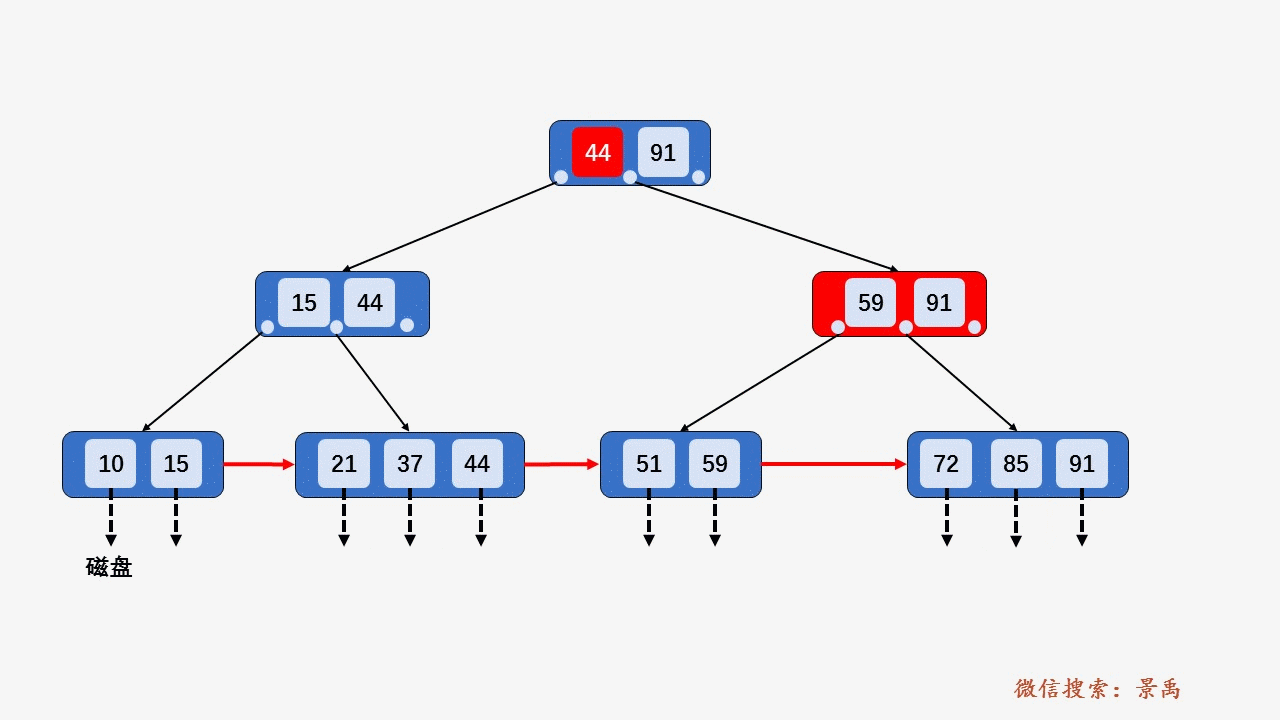
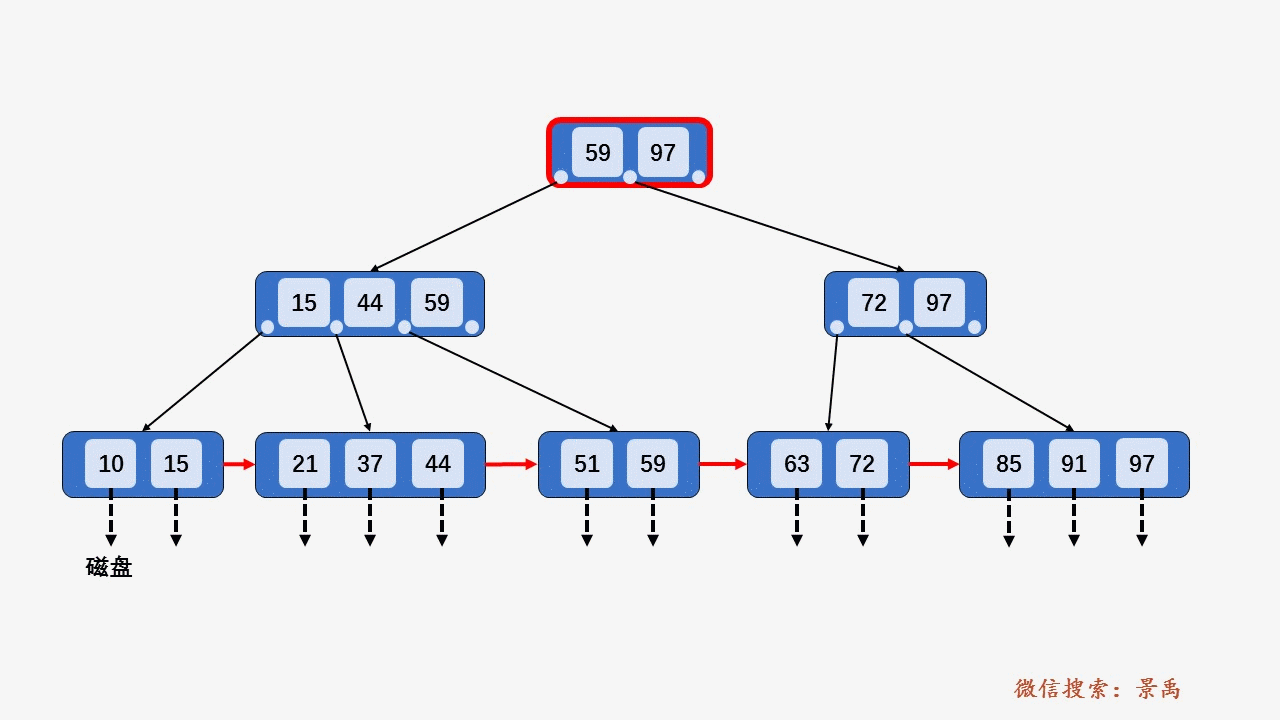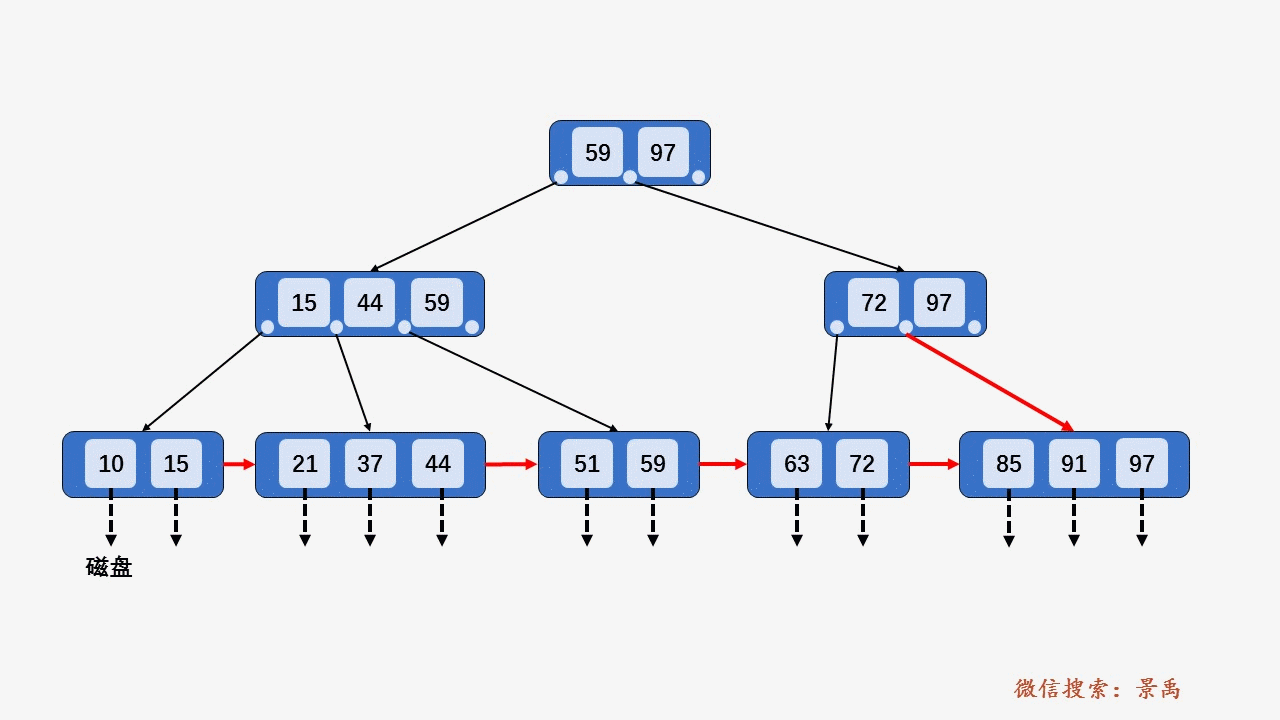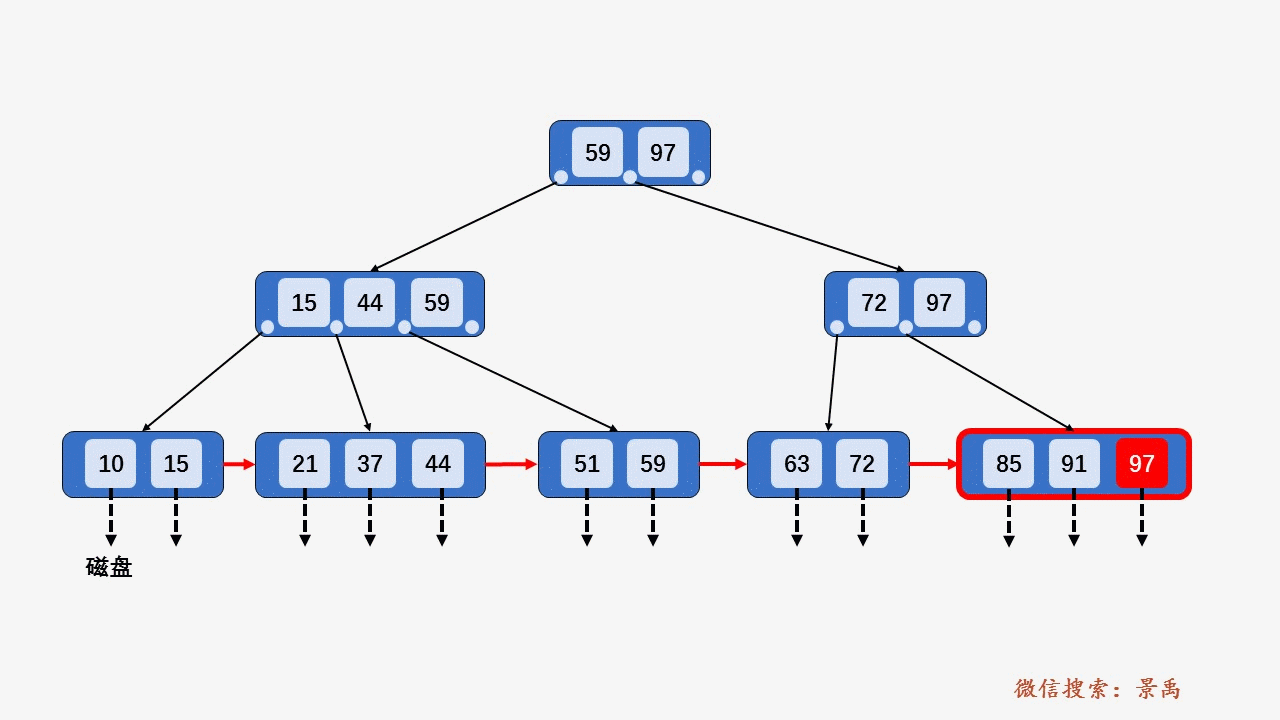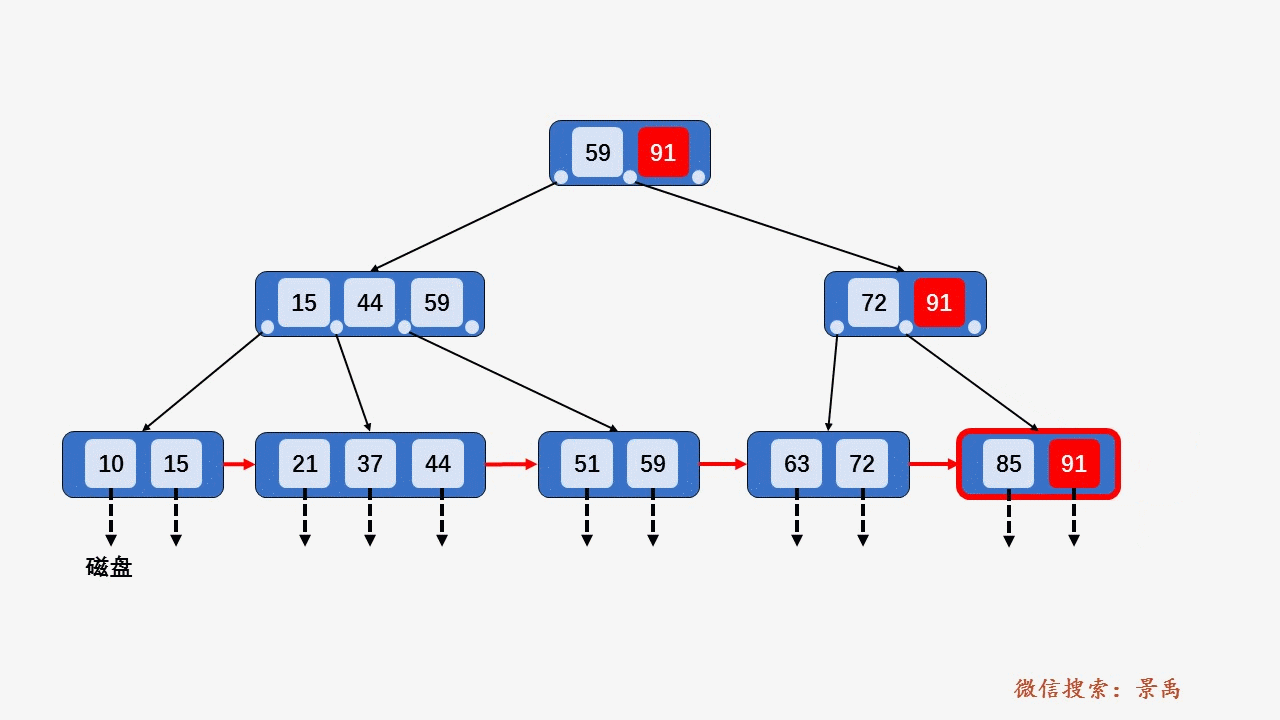
gif演示B+树增删:
插入:
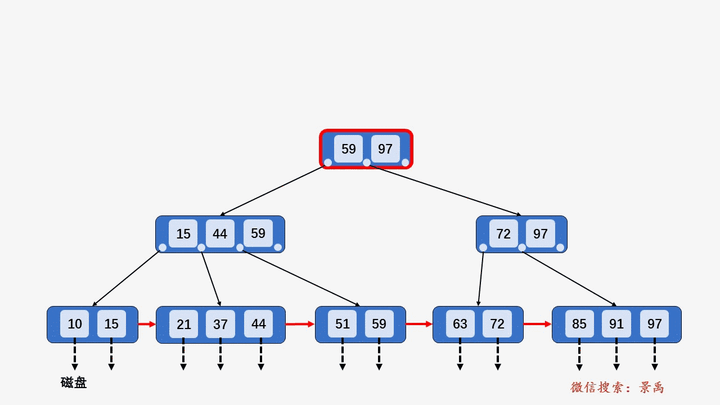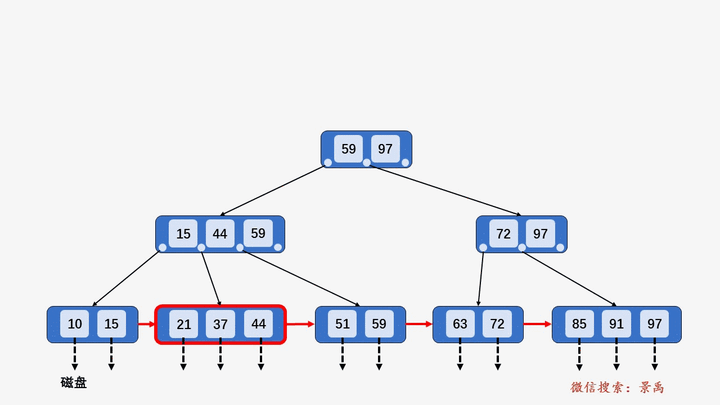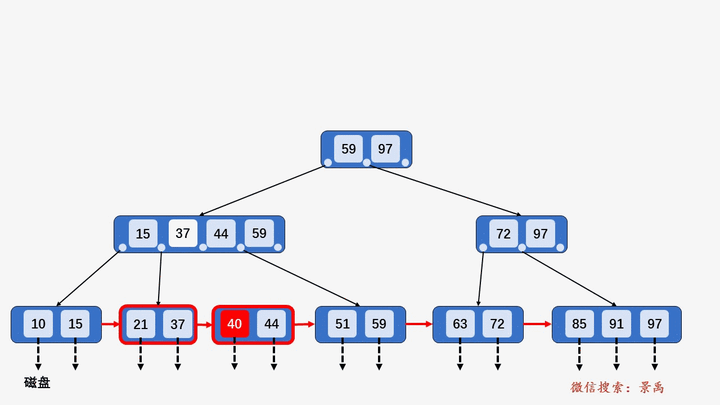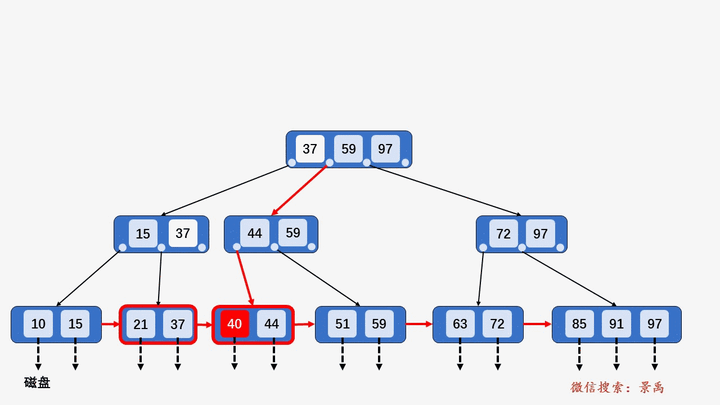
删除: