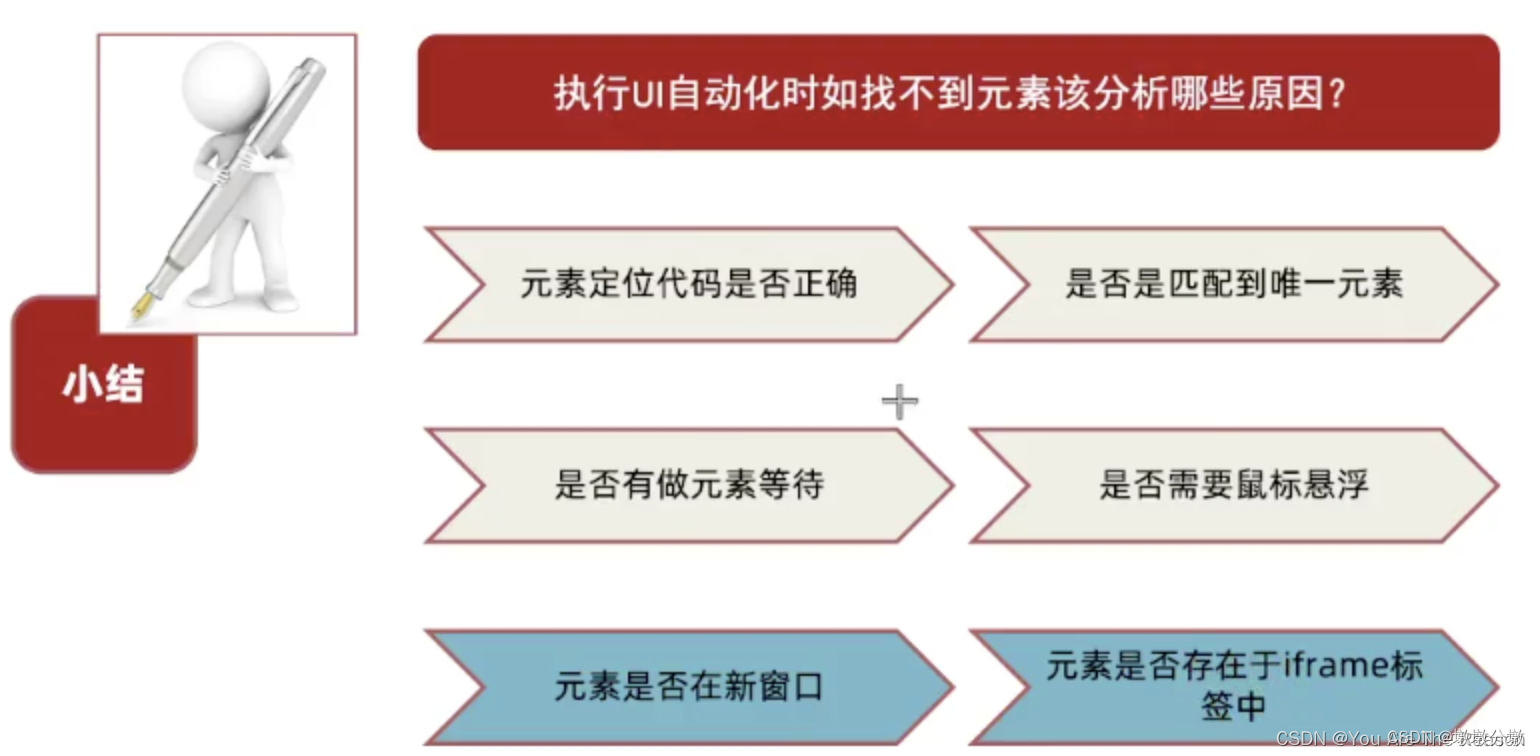
写在前面
- 工作原因,顺便整理
- 博文内容为一个
人脸检测服务分享 - 以打包
Docker镜像,可以直接使用 - 服务目前支持
http方式 - 该检测器主要适用低质量人脸图片处理
- 理解不足小伙伴帮忙指正,多交流,相互学习
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
简单介绍
人脸检测服务, 用于输出适合人脸识别的 人脸数据集,通过 mtcnn cnn检测人脸,通过 hopenet 开源项目确定人脸是姿态,拿到头部姿态欧拉角,通过 拉普拉斯算子 拿到人脸模糊度,通过对mtcnn 三级网络和置信度,欧拉角阈值,模糊度设置阈值筛选合适人脸
详细见项目: https://github.com/LIRUILONGS/mtcnn_demo
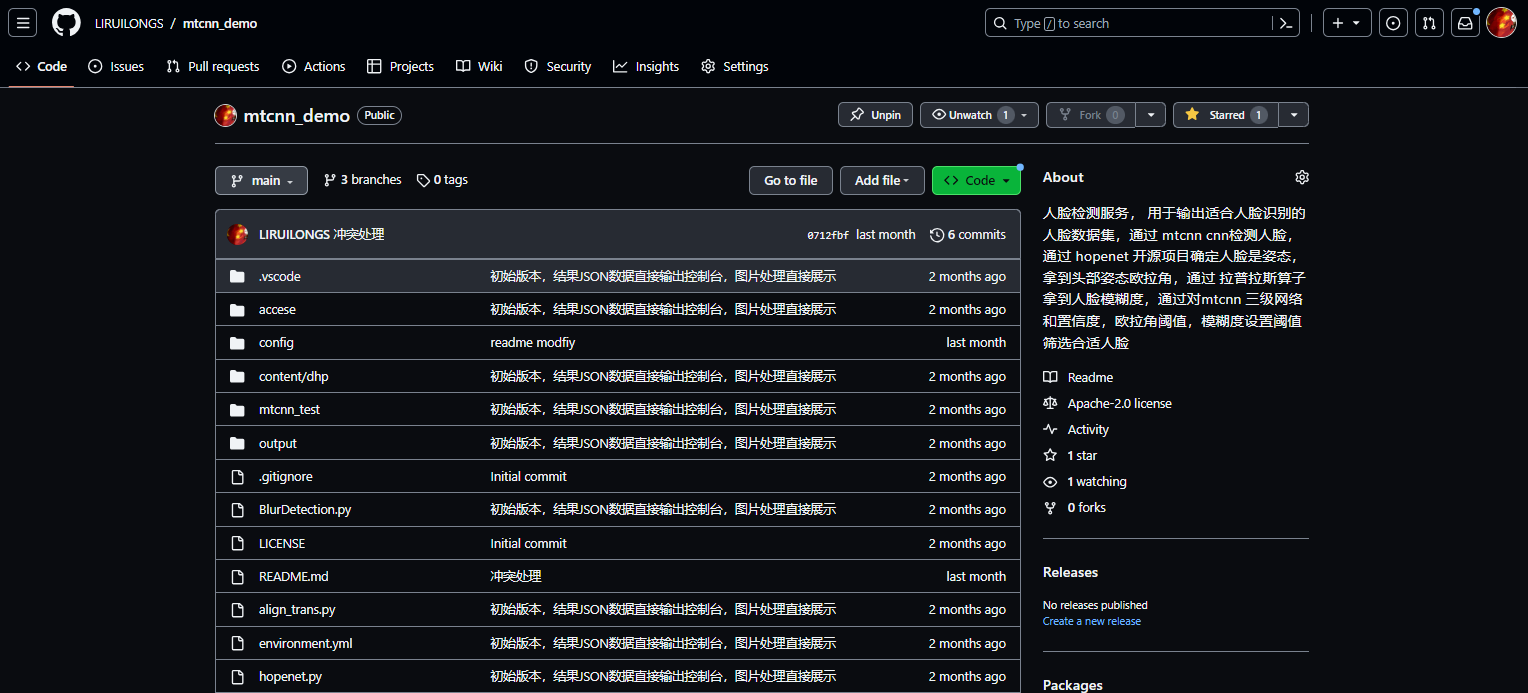
Docker 镜像见: https://hub.docker.com/r/liruilong/mtcnn-hopenet-laplacian-face
生成结果
克隆项目运行脚本直接生成
提供了Demo 可以克隆项目直接运行生成结果
python mtcnn_demo.py
| 原图 |
|---|
 |
| – |
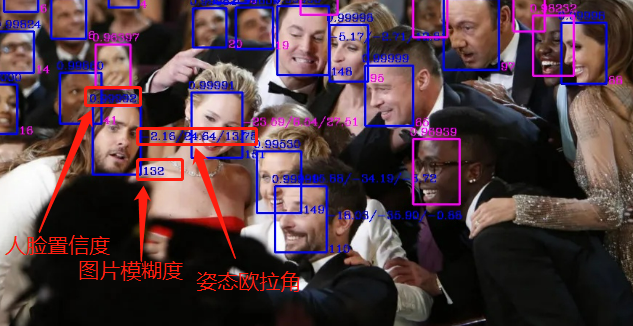
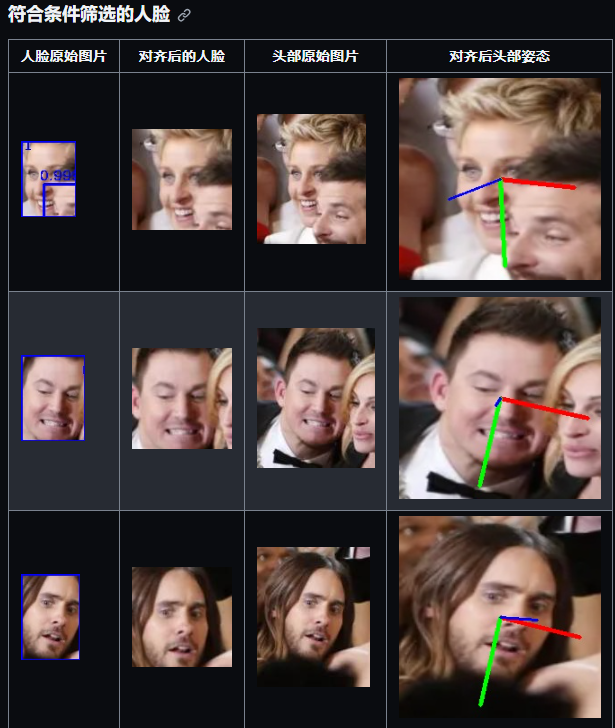
生成标记后图片,粉色数据为标记 不合格数据,全部标记为蓝色数据为合规数据,也就是需要处理的数据 |
 |
| – |
| 标记含义: |
 |
| – |
| 符合条件筛选的人脸 |
 |
部署
创建 虚拟环境,导入依赖
(base) C:\Users\liruilong>conda create -n mtcnn python==3.8.8
pip instasll -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
也可以直接使用 conda 的方式
conda env create -f /environment.yml
source activate mtcnn
pip install -r /requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple通过 Docker 方式
部署
docker pull liruilong/mtcnn-hopenet-laplacian-face
docker run -it -p 30025:30025 liruilong/mtcnn-hopenet-laplacian-face
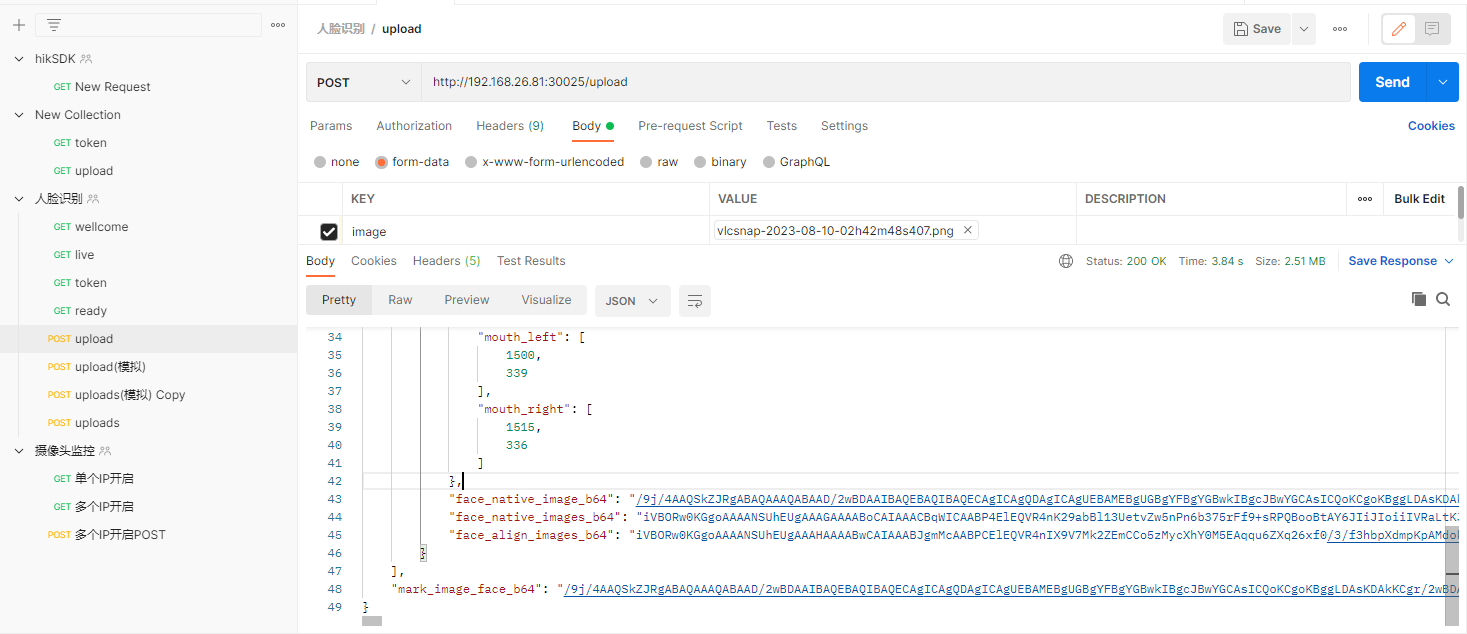
调用方式,上传文件直接解析
curl --location --request POST 'http://192.168.26.81:30025/upload' \
--header 'Authorization: eyJhbGciOiJSUzI1NiIsImtpZCI6ImF2MmJVZ3d6M21JRC1BZUwwaHlDdzZHSGNyaVJON1BkUHF6MlhPV2NfX00ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJoZWFkbGFtcC1hZG1pbi10b2tlbi04ZDVwciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJoZWFkbGFtcC1hZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjI0NDMxNTA4LWU4ZjEtNGYxOC1hMWIxLTlmMmUzZmFhNDU3ZSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTpoZWFkbGFtcC1hZG1pbiJ9.oSA_i8gZOXYNRQMyoUKCK_wivtSiEjJ78EDUzZ1R7_HFxiLBKWLtxYN81wyf19bp9y9BFc2YYAW9lBy9QfVxg6LzBhW1sb4tcJJ0SOldxQX8z9kWK9m1MPMMs3aqtt1S9n8ShMBeobyY5AXSkBMDvVh6_E1P22dnPyOH7r_m0DEM0pgOP7B347sDKHiKx60hHBTfayvF7WDgfVlqsItBrc-MupC7NieRe8pztCllQ8awPksZXPRAJdcKwlSPvskoYxaqOBGbfZvFAFeLJaiGHdwkb6jUKyVfcB_hX_Pm5aEHGU8LZq7twrup859zxLxwn3nAgQpM6-NySZt8ax24kg' \
--form 'image=@"/C:/Users/liruilong/Pictures/vlcsnap-2023-08-10-02h42m48s407.png"'
{"image_id": "f12314cd5c814c1d85137daf774b8806","face_total": 18,"face_efficient_total_resp": 1,"resp": [{"face_id": "d0915a12c1cd4181a15718c812a85f29","face_blur": 246.4111740893992,"face_pose": {"pitch": -17.97052001953125,"yaw": -21.107192993164062,"roll": 0.6877593994140625},"face_confidence": 0.9999333620071411,"face_coordinate": [1484,305,36,44],"facie5points": {"left_eye": [1496,323],"right_eye": [1513,318],"nose": [1509,331],"mouth_left": [1500,339],"mouth_right": [1515,336]},"face_native_image_b64": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAIB.....","face_native_images_b64": "iVBO...............GiAAAAAElFTkSuQmCC"}],"mark_image_face_b64": "/9j/4AA............"
}项目简单介绍:
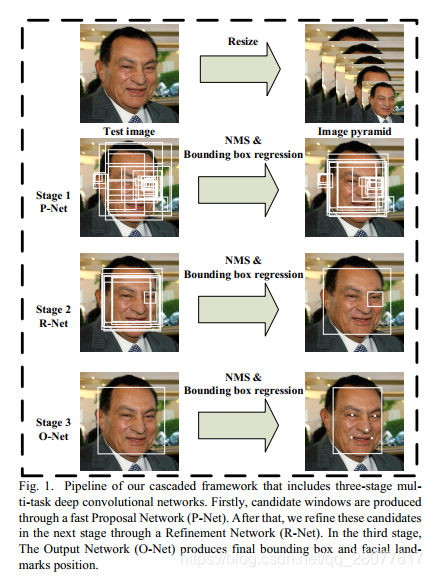
检测使用 mtcnn
使用的下面的库,关于 mtcnn 是什么,这里不多介绍,综合考虑使用这个,这里主要看下和识别精度相关的参数
对应的pip 库位置: https://pypi.org/project/mtcnn/
def __init__(self, weights_file: str = None, min_face_size: int = 20, steps_threshold: list = None,scale_factor: float = 0.709):"""Initializes the MTCNN.:param weights_file: file uri with the weights of the P, R and O networks from MTCNN. By default it will loadthe ones bundled with the package.:param min_face_size: minimum size of the face to detect:param steps_threshold: step's thresholds values:param scale_factor: scale factor"""if steps_threshold is None:steps_threshold = [0.6, 0.7, 0.7]if weights_file is None:weights_file = pkg_resources.resource_stream('mtcnn', 'data/mtcnn_weights.npy')self._min_face_size = min_face_sizeself._steps_threshold = steps_thresholdself._scale_factor = scale_factorself._pnet, self._rnet, self._onet = NetworkFactory().build_P_R_O_nets_from_file(weights_file)
影响 MTCNN 单张测试结果的准确度和测试用时的主要因素为:
网络阈值(steps_threshold)
MTCNN 使用了一系列的阈值来进行人脸检测和关键点定位。这些阈值包括人脸 置信度阈值(Face Confidence Threshold)、人脸框与 关键点之间的IoU(Intersection over Union)阈值等。上面的构造函数 MTCNN的三个阶段(P-Net、R-Net和O-Net)中,相应的阈值设置为0.6、0.7和0.7。
- 在
P-Net阶段,它是一个浅层的卷积神经网络,生成候选人脸框时,只有置信度大于等于0.6的候选框将被接受,其他低于该阈值的候选框将被拒绝。 - 在
R-Net阶段,一个较深的卷积神经网络,用于对P-Net生成的候选框进行筛选和精细调整。R-Net会对每个候选框进行特征提取,并输出判断该框是否包含人脸的概率以及对应的边界框调整值,对于从P-Net阶段获得的候选框,只有置信度大于等于0.7的框将被接受,其他低于该阈值的框将被拒绝。 - 在
O-Net阶段,最深的卷积神经网络,用于进一步筛选和精细调整R-Net输出的候选框。O-Net与R-Net类似,对于从R-Net阶段获得的候选框,同样只有置信度大于等于0.7的框将被接受,其他低于该阈值的框将被拒绝。O-Net还可以输出人脸关键点的位置坐标。最终,O-Net提供了最终的人脸检测结果和人脸关键点的位置信息。
影响因子(原始图像的比例跨度)(scale_factor):
MTCNN 使用了图像金字塔来检测不同尺度的人脸。通过对图像进行 缩放,可以检测到不同大小的人脸。影响因子是指图像金字塔中的 缩放因子,控制了不同尺度之间的跨度。较小的影响因子会导致 更多的金字塔层级,可以检测到 更小的人脸,但会增加计算时间。较大的影响因子可以 加快检测速度,但可能会错过 较小的人脸。因此,选择合适的影响因子是在准确度和速度之间进行权衡的关键。
要检测的 最小面容参数(min_face_size):
这是 MTCNN 中用于 过滤掉较小人脸的参数。最小面容参数定义了一个 人脸框的 最小边长,小于此值的人脸将被 忽略。较小的最小面容参数可以检测到更小的人脸,但可能会增加 虚警(错误接受)的机会。较大的最小面容参数可以 减少虚警,但可能会漏检一些较小的人脸。因此,根据应用需求和场景,需要调整最小面容参数以平衡 准确度和召回率。
from mtcnn import MTCNN
import cv2img = cv2.cvtColor(cv2.imread("ivan.jpg"), cv2.COLOR_BGR2RGB)
detector = MTCNN()
detector.detect_faces(img)
box 为人脸矩形框,keypoints 为人脸特征点,confidence 为置信度
[{'box': [277, 90, 48, 63],'keypoints':{'nose': (303, 131),'mouth_right': (313, 141),'right_eye': (314, 114),'left_eye': (291, 117),'mouth_left': (296, 143)},'confidence': 0.99851983785629272}
]
姿态判断 Hopenet
姿态判断使用 Hopenet ,论文地址: https://arxiv.org/abs/1710.00925
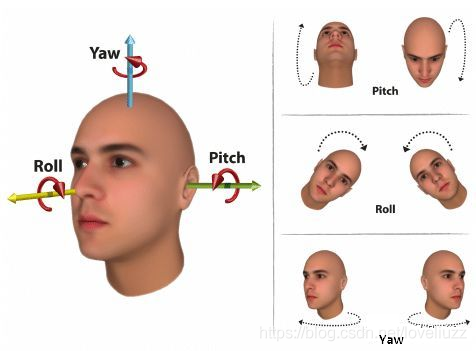
使用的模型来自项目
https://github.com/natanielruiz/deep-head-pose
一个 大佬写好的 colab Demo
https://colab.research.google.com/drive/1vvntbLyVxxBHoVN0e6-pfs7gB3pp-VUS?usp=sharing
模糊度检测 拉普拉斯算子
opencv 拉普拉斯方差方法 方法

def calculate_blur(image):# 计算图像的拉普拉斯梯度gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)laplacian = cv2.Laplacian(gray, cv2.CV_64F).var()return laplacian
来源 : https://pyimagesearch.com/2015/09/07/blur-detection-with-opencv/
配置文件简单说明:
### 人脸检测配置文件
## mtcnn 检测相关:
mtcnn:zero:# 最小人脸尺寸min_face_size: 20# 影响因子scale_factor: 0.709# 三层网络阈值steps_threshold: - 0.6- 0.7- 0.7# 结果置信度阈值face_threshold: 0.995# 模糊度阈值blur_threshold: 100
## hopenet 姿态检测相关
hopenet:zero:# 模型位置snapshot_path: "./content/dhp/hopenet_robust_alpha1.pkl"# 欧拉角阈值yaw_threshold: 45pitch_threshold: 20roll_threshold: 25
# 是否输出结果图片
is_objectification: true
# 输出图片结果
objectification_dir: './output/'
# 需要处理的图片位置
parse_dir: "./mtcnn_test/"
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 😃
https://pyimagesearch.com/2015/09/07/blur-detection-with-opencv/
https://github.com/natanielruiz/deep-head-pose
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)