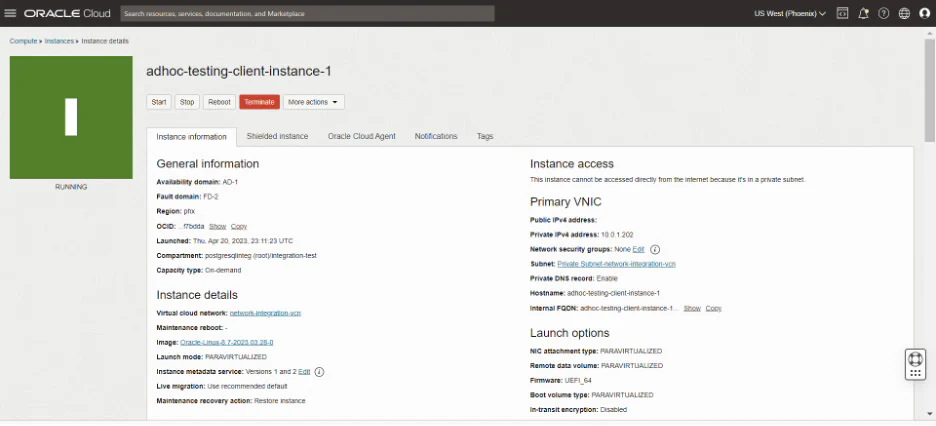
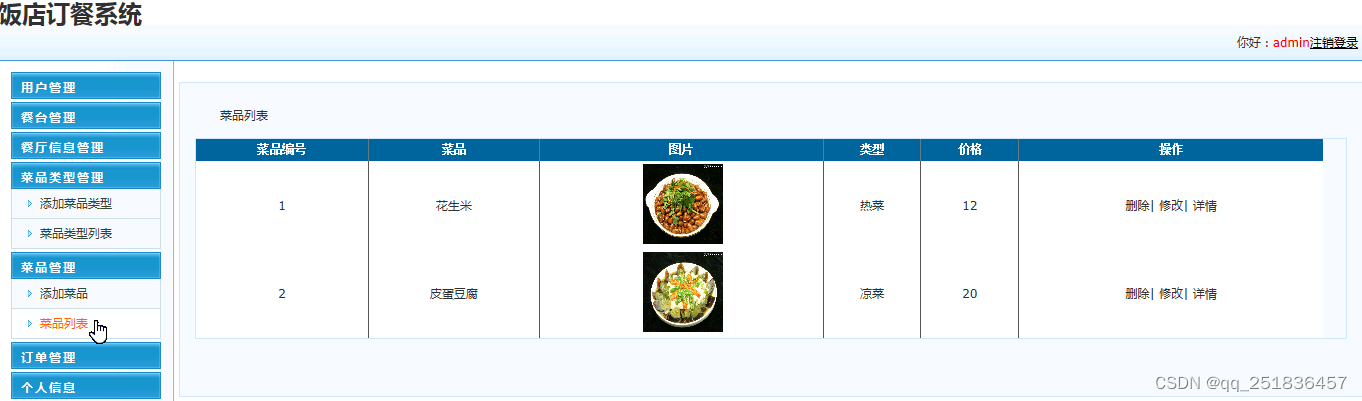
先看一个实例:
; 使用 Win32ASM 写的 Hello, world 程序
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
; 使用 nmake 或下列命令进行编译和链接:
; ml /c /coff Hello.asm
; Link /subsystem:windows Hello.obj
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.386.model flat,stdcalloption casemap:none
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
; Include 文件定义
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
include \masm32\include\windows.inc
include \masm32\include\user32.inc
includelib \masm32\lib\user32.lib
include \masm32\include\kernel32.inc
includelib \masm32\lib\kernel32.lib
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
; 数据段
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.data
szCaption db 'win32-Compilation exercise', 0
szText db 'Hello, World !', 0;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
; 代码段
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.code
start:invoke MessageBox,NULL,offset szText,offset szCaption,MB_OKinvoke ExitProcess,NULL
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>end start模式定义
程序的第一部分是模式和源程序格式的定义语句:
.386
.model flat,stdcall
option casemap:none
这些指令定义了程序使用的指令集、工作模式和格式。
1.指定使用的指令集
.386 语句是汇编语言的伪指令,它在低版本的宏汇编中就已经存在,类似的指令还有.8086,.186,.286,.386/.386p,.486/.486p和.586/.586p等,用于告诉编译器在本程序中使用的指令集。在DOS的汇编中默认使用的是8086指令集, 那时候如果在源程序中写入80386所特有的指令或使用32位的寄存器就会报错, 为了在DOS环境下进行保护模式编程或仅为了使用32位寄存器, 常在DOS的汇编中使用.386来定义。Win 32环境工作在80386及以上的处理器中,所以这一句.386是必不可少的。
后面带p的伪指令则表示程序中可以使用特权指令,如:
mov cr0,eax
这一类指令必须在特权级0上运行,如果只指定.386,那么使用普通的指令是可以的,编译时到这一句就会报错, 如果我们要写的程序是VxD等驱动程序, 中间要用到特权指令, 那么必须定义.386p, 在应用程序级别的Win 32编程中, 程序都是运行在优先级3上, 不会用到特权指令, 只需定义.386就够了。80486和Pentium处理器指令是80386处理器指令的超集,
同理, 如果程序中要用80486处理器或Pentium处理器的指令,则必须定义.486或.586。另外, Intel公司的80x86系列处理器从Pentium MMX开始增加了MMX指令集, 为了使用MMX指令, 除了定义.586之外, 还要加上一句.mmx伪指令:
.586
.mmx
2.model语句
.model语句在低版本的宏汇编中已经存在, 用来定义程序工作的模式, 它的使用方法是:
.model 内存模式 [,语言模式] [,其他模式]
内存模式的定义影响最后生成的可执行文件,可执行文件的规模从小到大,可以有很多种类型, 在DOS的可执行程序中, 有只用到64KB的.com文件, 也有大大小小的.exe文件。到了Win 32环境下, 又有了可以用4GB内存的PE格式可执行文件, 编写不同类型的可执行文件要用.model语句定义不同的参数, 具体如表3.1所示。
在前面章节中已经提到过:Windows程序运行在保护模式下, 系统把每一个Win 32应用程序都放到分开的虚拟地址空间中去运行,也就是说,每一个应用程序都拥有其相互独立的4GB地址空间, 对Win 32程序来说, 只有一种内存模式, 即flat(平坦) 模式, 意思是内存是很“平坦”地从0延伸到4GB, 再没有64KB段大小限制。
如果定义了.model flat, MASM自动为各种段寄存器做了如下定义:
ASSUME CS:FLAT,ds:FLAT,SS:FLAT,es:FLAT,fs:ERROR,gs:ERROR
在Win 32汇编中, .model语句中还应该指定语言模式, 即子程序的调用方式, 例子中用的是stdcall, 它指出了调用子程序或Win32API时参数传递的次序和堆栈平衡的方法, 相对于stdcall, 不同的语言类型还有C, SysCall, BASIC, FORTRAN和PASCAL, 虽然各种高级语言在调用子程序时都是使用堆栈来传递参数,但它们的处理方法各有不同。要和其他语言配合, 就必须指定相应的语言种类。Windows的API调用使用的是stdcall格式, 所以在Win 32汇编中没有选择, 必须在.model中加上stdcall参数。
3.option语句
用option语句定义的选项有很多, 如option language定义和option segment定义等, 在Win 32汇编程序中, 需要的只是定义option case map:none, 这个语句定义了程序中的变量和子程序名是否对大小写敏感, 由于Win32API中的API名称是区分大小写的, 所以必须指定这个选项, 否则在调用API的时候会有问题。
段的定义
1.段的概念
把上面的Win32的Hello World源程序中的语句归纳精简一下,再列在下面:
.386.model flat,stdcalloption casemap:none<一些include语句>.data<一些字符串、变量定义>.code<代码><开始标号><其他语句>end 开始标号
下面是包含全部段的源程序结构:
.386.model flat,stdcalloption casemap:none<一些include语句>.stack [堆栈段的大小].data<一些初始化过的变量定义>.data?<一些没有初始化过的变量定义>.const<一些常量定义>.code<代码><开始标号><其他语句>end 开始标号
.stack, .data,.data?, .const和.code是分段伪指令, Win 32中实际上只有代码和数据之分, .data, .data?和.const都是数据段, .code是代码段, 与DOS汇编不同, 由于Win 32汇编不必考虑堆栈, 系统会为程序分配一个向下扩展的、足够大的段作为堆栈段, 所以.stack段定义常常被忽略。
2.数据段
.data, .data?和.const定义的是数据段, 分别对应不同方式的数据定义, 在最后生成的可执行文件中也分别放在不同的节区(Section) 中。程序中的数据定义一般可以归纳为3类。
第一类是可读可写的已定义变量。这些数据在源程序中已经被定义了初始值,而且在程序的执行中有可能被更改, 如一些标志等, 这些数据必须定义在.data段中, .data段是已初始化数据段,其中定义的数据是可读可写的,在程序装入完成的时候,这些值就已经在内存中了, .data段一般存放在可执行文件的_DATA节区内。
第二类是可读可写的未定义变量。这些变量一般是当做缓冲区或者在程序执行后才开始使用的, 这些数据可以定义在.data段中, 也可以定义在.data?段中, 但一般把它放到.data?段中。虽然定义在这两种段中都可以正常使用, 但定义在.data?段中不会增大.exe文件的大小。举例说明,如果要用到一个100KB的缓冲区,可以用下面的语句定义:
szBuffer db 100 * 1024 dup (?)
这个语句如果放在.data段中, 编译器认为这些数据在程序装入时就必须有效, 所以它在生成可执行文件的时候保留了所有的100KB的内容,即使它们是全零!假设程序其他部分的大小是50KB, 那么最后的.exe文件就会是150KB大小, 如果缓冲区定义为1MB, 那么.exe文件会增大到1050KB。.data?段则不同, 其中的内容编译器会认为程序在开始执行后才会用到,所以在生成可执行文件的时候只保留了大小信息,不会为它浪费磁盘空间。在与上面同样的情况下, 即使缓冲区定义为1MB, 可执行文件同样只有50KB!总之, .data?段是未初始化数据段, 其中的数据也是可读可写的, 但在可执行文件中不占空间, .data?段在可执行文件中一般存放在_BSS节区中。
第三类数据是一些常量。如一些要显示的字符串信息,它们在程序装入的时候也已经有效, 但在整个执行过程中不需要修改, 这些数据可以放在.const段中, .const段是常量段,它是可读不可写的。为了方便起见, 在小程序中常常把常量一起定义到.data段中, 而不另外定义一个.const段。在程序中如果不小心用了对.const段中的数据做写操作的指令, 会引起保护错误, Windows会显示一个如图3.2所示的提示框并结束程序。
如果不怕程序可读性不佳的话, 把.const段中定义的东西混到.code段中去也可以正常使用, 因为.code段也是可以读的。
3.代码段
.code段是代码段, 所有的指令都必须写在代码段中, 在可执行文件中, 代码段一般是放在_TEXT节区中的。Win 32环境中的数据段是不可执行的, 只有代码段有可执行的属性。对于工作在特权级3的应用程序来说, .code段是不可写的, 在编DOS汇编程序的时候, 好事的程序员往往有个习惯,就是靠改动代码段中的代码来做一些反跟踪的事情,如果企图在Win 32汇编下做同样的事情, 结果就是和上面同样的“非法操作”。
当然事物总有两面性, 在Windows 95下, 在特权级0下运行的程序对所有的段都有读写的权利,包括代码段。另外,在优先级3下运行的程序也不是一定不能写代码段,代码段的属性是由可执行文件PE头部中的属性位决定的, 通过编辑磁盘上的.exe文件, 把代码段属性位改成可写,那么在程序中就允许修改自己的代码段。一个典型的应用就是一些针对可执行文件的压缩软件和加壳软件, 如Up x和PeCompact等, 这些软件靠把代码段进行变换来达到解压缩或解密的目的,被处理过的可执行文件在执行时需要由解压代码来将代码段解压缩,这就需要写代码段,所以这些软件对可执行文件代码段的属性预先做了修改
4.堆栈段
在程序中不必定义堆栈段,系统会自动分配堆栈空间。惟一值得一提的是,堆栈段的内存属性是可读写并且是可执行的,这样靠动态修改代码的反跟踪模块可以拷贝到堆栈中去边修改边执行。一些病毒或者黑客工具用到的缓冲区溢出技术也用到了这个特征,有兴趣了解的读者可以查阅相关的资料。
程序结束和程序入口
在C语言源程序中,程序不必显式地指定程序由哪里开始执行,编译器已经约定好从main() 函数开始执行了。而在汇编源程序中, 并没有一个main函数, 程序员可以指定从代码段的任何一个地方开始执行, 这个地方由程序最后一句的end语句来指定:
end [开始地址]
这句语句同时表示源程序结束, 所有的代码必须在end语句之前, 例如:
end start
上述语句指定程序从start这个标号开始执行。当然, start标号必须在程序的代码段中有所定义。
但是,一个源程序不必非要指定入口标号,这时候可以把开始地址忽略不写,这种情况发生在编写多模块程序的单个模块的时候。当分开写多个程序模块时,每个模块的源程序中也可以包括.data, .data?, .const和.code段, 结构就和上面的Win32 HelloWorld一样, 只是其他模块最后的end语句必须不带开始地址。当最后把多个模块链接在一起的时候,只能有一个主模块指定入口地址,在多个模块中指定入口地址或者没有一个模块指定了入口地址,链接程序都会报错。
注释和换行
注释是源程序中不可忽略的一部分,汇编源程序的注释以分号(;)开始,注释既可以在一行的头部,也可以在一行的中间,一行中所有在分号之后的字符全部当做注释处理,但在字符串的定义中包含在引号内的分号不当做是注释的开始。
当源程序的某一行过长,不利于阅读的时候,可以分行书写,分行的办法是在一行的最后用反斜杠(\)做换行符,如:

“一行的最后”指的是最后一个有用的字符,反斜杠后面多几个空格或加上注释并不影响换行符的使用, 如上例所示, 这一点与makefile文件中换行符的规定有所不同。