Flink开发环境搭建与提交运行Flink应用程序
- Flink
- 概述
- 环境
- Flink程序开发
- 项目构建
- 添加依赖
- 安装Netcat
- 实现经典的词频统计
- 批处理示例
- 流处理示例
- Flink Web UI
- 命令行提交作业
- 编写Flink程序
- 打包
- 上传Jar
- 提交作业
- 查看任务
- 测试
- Web UI提交作业
- 提交作业
- 测试
Flink
概述
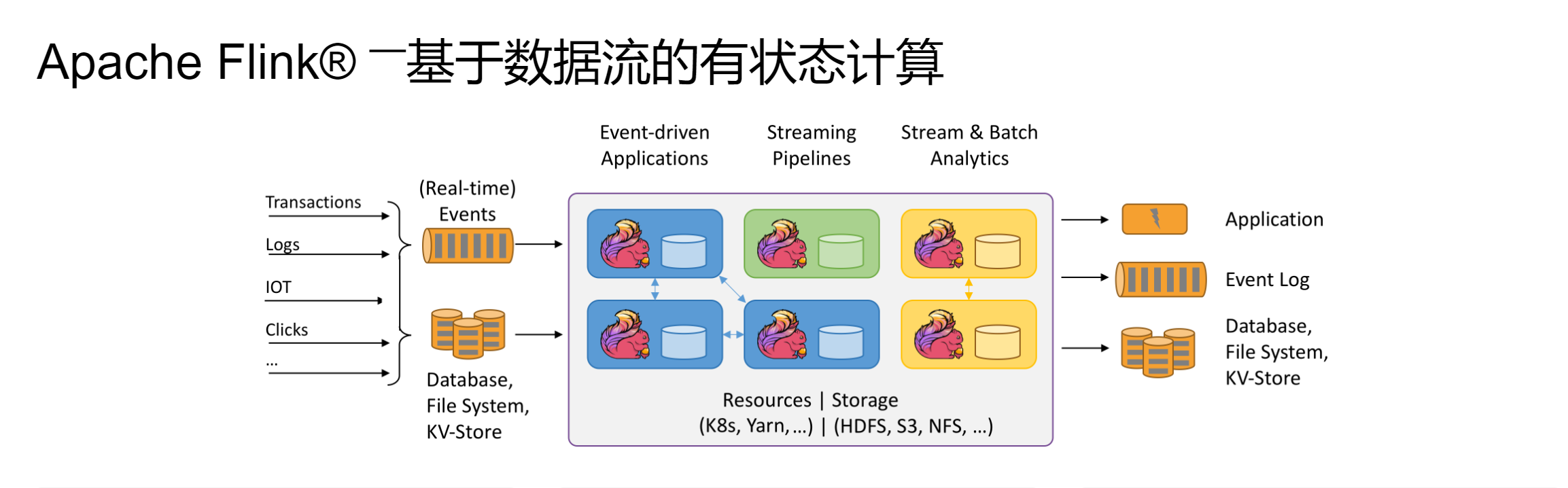
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
官网:https://flink.apache.org/
GitHub: https://github.com/apache/flink
环境
Flink分别提供了基于Java语言和Scala语言的 API ,如果想要使用Scala语言来开发Flink程序,可以通过在IDEA中安装Scala插件来提供语法提示,代码高亮等功能。
推荐使用Java来作为开发语言,Maven 作为编译和包管理工具进行项目构建和编译。
Flink程序开发
项目构建
1.基于 Maven Archetype 构建
根据交互信息的提示,依次输入 groupId , artifactId 以及包名等信息后等待初始化的完
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.17.0
2.使用官方脚本快速构建
官方提供了快速构建脚本,在Linux系统终端,直接通过以下命令来进行调用:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.17.0
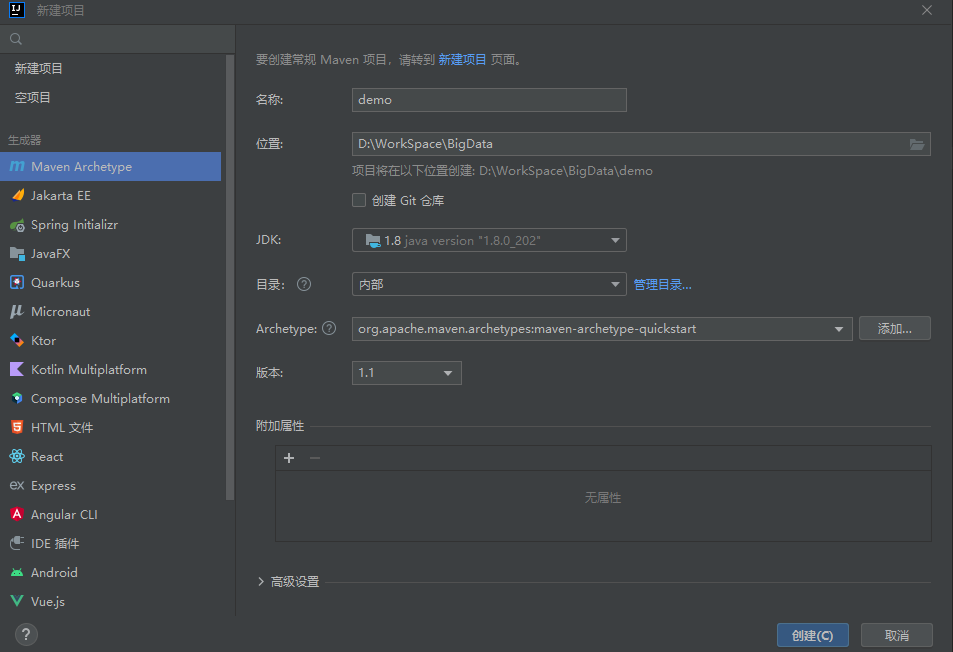
3.使用 IDEA 构建
使用 IDEA开发工具,直接在项目创建页面选择 Maven Flink Archetype 进行项目初始化:
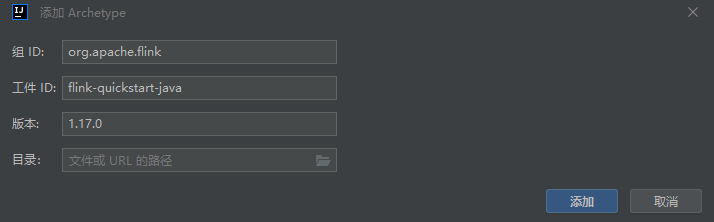
可以配置一个Flink Archetype,指定groupId 、 artifactId、version。这样就会自动引入pom.xml相关依赖与批处理、流处理demo例子,否则需要手动添加依赖。
添加依赖
使用使用IDEA 、普通Archetype构建,需要进行添加相关依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.17.0</version></dependency>
注意:
在打包时,需要将部分依赖的scope标签全部被标识为provided,标记这些依赖不会被打入最终的 JAR 包。
因为Flink的安装包中已经提供了这些依赖,位于其lib目录下,名为
flink-dist_*.jar,它包含了Flink的所有核心类和依赖
安装Netcat
Netcat(又称为NC)是一个计算机网络工具,它可以在两台计算机之间建立 TCP/IP 或 UDP 连接。它被广泛用于测试网络中的端口,发送文件等操作。使用 Netcat 可以轻松地进行网络调试和探测,也可以进行加密连接和远程管理等高级网络操作。因为其功能强大而又简单易用,所以在计算机安全领域也有着广泛的应用。
安装nc命令
yum install -y nc
启动socket端口
[root@node01 bin]# nc -lk 8888
注意:
测试时,先启动端口,后启动程序,否则会报超时连接异常。
实现经典的词频统计
统计一段文本中,每个单词出现的频次。
在项目resources目录下创建words.txt 文件,内容如下:
abc bcd cde
bcd cde fgh
cde fgh hij
Flink 它可以处理有界的数据集、也可以处理无界的数据集、它可以流式的处理数据、也可以批量的处理数据。
批处理示例
批处理是基于
DataSet API操作,对数据的处理转换,可以看作是对数据集的操作,批量的数据集本质上也是流。
public class WordCountBatch {public static void main(String[] args) throws Exception {// 创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 获取文件路径String path = WordCountBatch.class.getClassLoader().getResource("word.txt").getPath();// 从文件中读取数据DataSource<String> lineDS = env.readTextFile(path);// 切分、转换,例如: (word,1)FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDS.flatMap(new MyFlatMapper());// 按word分组 按照第一个位置的word分组UnsortedGrouping<Tuple2<String, Integer>> wordAndOneGroupby = wordAndOne.groupBy(0);// 分组内聚合统计 将第二个位置上的数据求和AggregateOperator<Tuple2<String, Integer>> sum = wordAndOneGroupby.sum(1);// 输出sum.print();}/*** 自定义MyFlatMapper类,实现FlatMapFunction接口* 输出: String 元组Tuple2<String, Integer>> Tuple2是flink提供的元组类型*/public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {@Override//value是输入,out就是输出的数据public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {// 按空格切分单词String[] words = value.split(" ");// 遍历所有word,包成二元组输出 将单词转换为 (word,1)for (String word : words) {Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);// 使用Collector向下游发送数据out.collect(wordTuple2);}}}
}本机不需要配置其他任何的 Flink 环境,直接运行 Main 方法即可
输出结果:
(bcd,2)
(cde,3)
(abc,1)
(hij,1)
(fgh,2)
流处理示例
DataSet API是基于批处理的API,从Flink 1.12开始,官方推荐使用DataStream API,它是流批统一处理的API
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批统一之后的DataStream API
更加强大,可以直接处理批处理和流处理的所有场景。
1.有界流之读取文件
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 从项目根目录下的data目录下的word.txt文件中读取数据DataStreamSource<String> source = env.readTextFile("data/word.txt");// 处理数据: 切分、转换SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {// 按空格切分String[] words = value.split(" ");for (String word : words) {// 转换成二元组 (word,1)Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1);// 通过采集器向下游发送数据out.collect(wordsAndOne);}}});// 处理数据:分组KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});// 处理数据:聚合SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.sum(1);// 输出数据sumDS.print();// 执行env.execute();}
输出结果如下:
10> (bcd,1)
10> (cde,1)
10> (cde,2)
3> (fgh,1)
3> (fgh,2)
11> (abc,1)
10> (bcd,2)
10> (cde,3)
8> (hij,1)
注意:
1.前面编号:并行度,与电脑线程数相关2.(cde,1)、(cde,2)、(cde,3):切分、转换、分组、聚合,是有状态的计算
2.无界流之读取socket文本流
在实际的生产环境中,真正的数据流其实是无界的,有开始却没有结束,这就需要持续地处理捕获的数据。为了模拟这种场景,可以监听socket端口,然后向该端口不断的发送数据。
Flink的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
DataStream API支持从Socket套接字读取数据。只需要指定要从其中读取数据的主机和端口号即可。
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 指定并行度,默认电脑线程数env.setParallelism(3);// 读取数据socket文本流 指定监听 IP 端口 只有在接收到数据才会执行任务DataStreamSource<String> socketDS = env.socketTextStream("IP", 8080);// 处理数据: 切换、转换、分组、聚合 得到统计结果SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).setParallelism(2)// // 显式地提供类型信息:对于flatMap传入Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式设置系统当前返回类型,才能正确解析出完整数据.returns(new TypeHint<Tuple2<String, Integer>>() {})
// .returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(value -> value.f0).sum(1);// 输出sum.print();// 执行env.execute();}
注意:
Flink具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。
但是,由于Java中泛型擦除的存在,在某些特殊情况下(如Lambda表达式中),自动提取的信息是不够准确的。因此,就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
执行以下命令,发送测试数据
[root@master ~]# nc -l 8080
abc bcd cde
bcd cde fgh
cde fgh hij
输出结果内容
3> (abc,1)
3> (bcd,1)
3> (cde,1)
1> (fgh,1)
3> (bcd,2)
3> (cde,2)
1> (fgh,2)
2> (hij,1)
3> (cde,3)
Flink Web UI
在本地开发环境中,可以添加
flink-runtime-web依赖,启动Flink Web UI界面,方便开发测试使用 。
添加flink-runtime-web依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>1.17.0</version><scope>provided</scope>
</dependency>
/*** 并行度优先级:算子 > 全局env > 提交指定 > 配置文件* @param args* @throws Exception*/public static void main(String[] args) throws Exception {// 本地模式Configuration conf = new Configuration();// 指定端口conf.setString(RestOptions.BIND_PORT, "7777");// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);// 全局指定并行度,默认是电脑的线程数env.setParallelism(2);// 读取socket文本流DataStreamSource<String> socketDS = env.socketTextStream("node01", 8888);// 处理数据: 切割、转换、分组、聚合 得到统计结果SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}})// 局部设置算子并行度.setParallelism(3).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(value -> value.f0).sum(1)// 局部设置算子并行度.setParallelism(4);// 输出sum.print();// 执行env.execute();}
启动Netcat
[root@node01 ~]# nc -l 8888
启动Flink程序,访问:http://localhost:7777/
若出现如下提示,需要在pom.xml中将依赖
flink-runtime-web的指定<scope>provided</scope>作用域标签去掉

注释后再次启动项目,访问:http://localhost:7777/
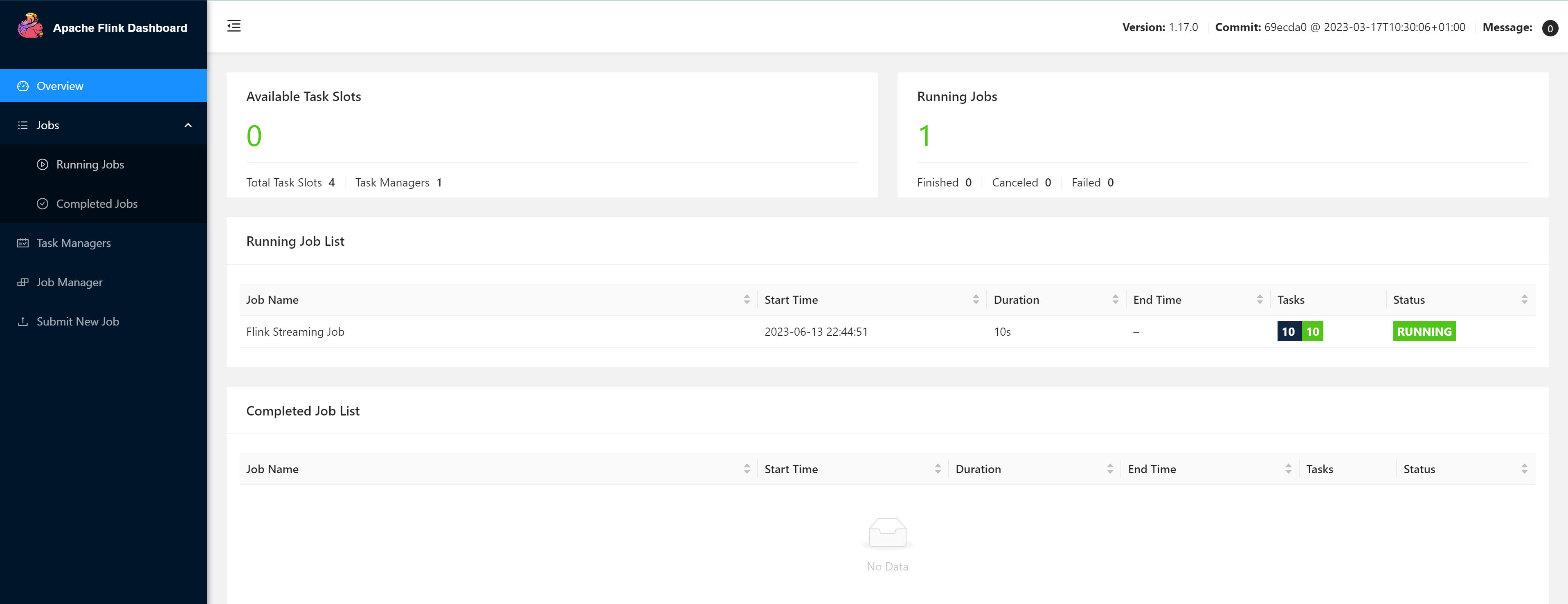
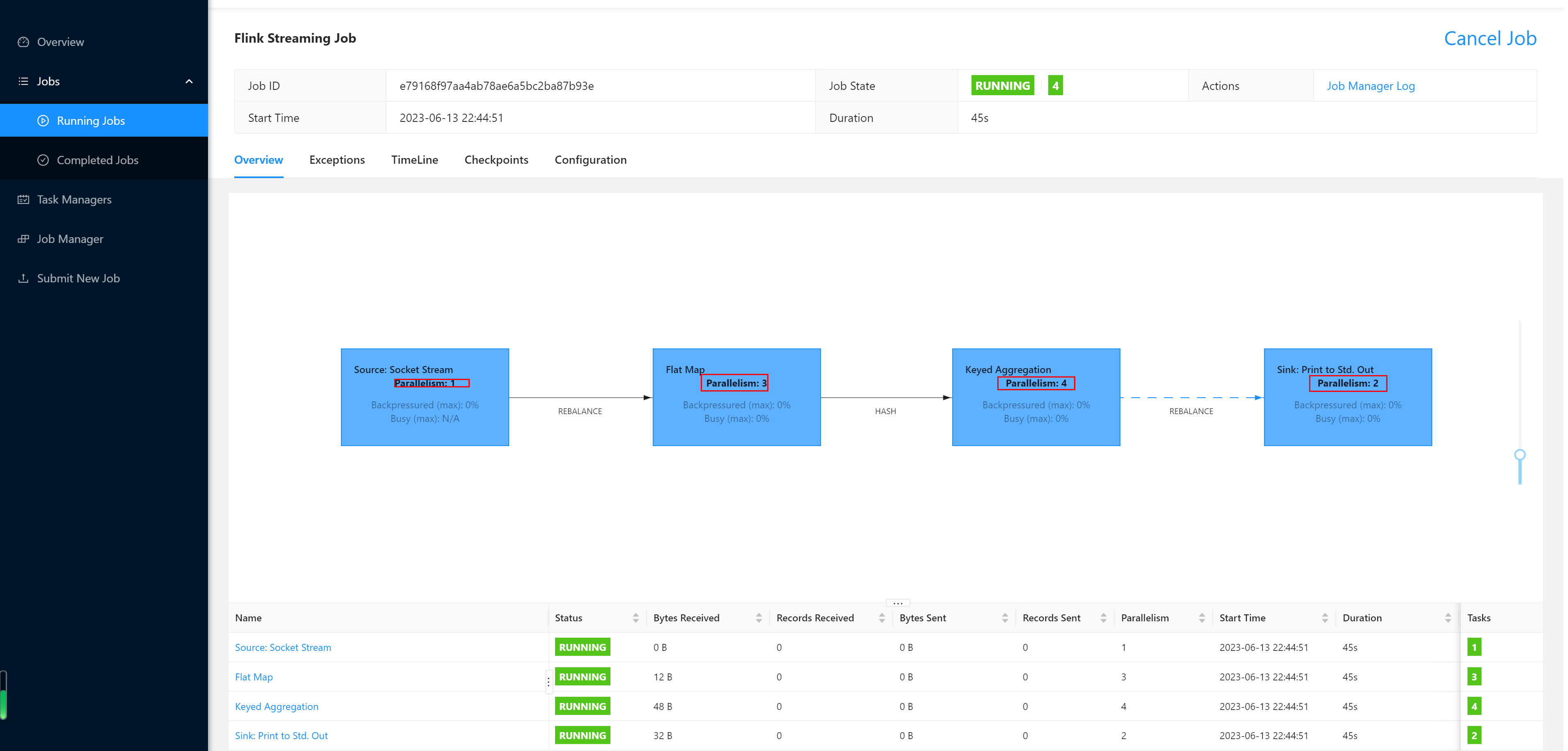
查看任务执行详情,可以看出开发Flink应用程序时指定的并发度与此执行流程图上的并发度一致。
命令行提交作业
编写Flink程序
编写一个读取
socket发送单词并统计单词个数的程序
public static void main(String[] args) throws Exception {// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 指定并行度,默认电脑线程数env.setParallelism(3);// 读取数据socket文本流 指定监听 IP 端口 只有在接收到数据才会执行任务DataStreamSource<String> socketDS = env.socketTextStream("IP", 8080);// 处理数据: 切换、转换、分组、聚合 得到统计结果SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).setParallelism(2)// // 显式地提供类型信息:对于flatMap传入Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式设置系统当前返回类型,才能正确解析出完整数据.returns(new TypeHint<Tuple2<String, Integer>>() {})
// .returns(Types.TUPLE(Types.STRING,Types.INT)).keyBy(value -> value.f0).sum(1);// 输出sum.print();// 执行env.execute();}
打包
在项目pom.xml文件添加打包插件配置
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- Replace this with the main class of your job --><mainClass>my.programs.main.clazz</mainClass></transformer><transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/></transformers></configuration></execution></executions></plugin></plugins>
</build>
注意:
Flink集群内部依赖实则包含了Flink相关依赖,在打包Flink应用程序时,可以在
pom.mxl中指定Flink相关依赖作用域。
1.使用内置在Flink集群内部依赖
# 作用在编译和测试时,同时没有传递性
# 项目打包发布,不包含该依赖
<scope>provided</scope>
2.不使用内置在Flink集群内部依赖
# 使用默认作用域,即scope标签可省略
# 作用在所有阶段,会传递到依赖项目中,项目打包发布,含该依赖
<scope>compile</scope>
上传Jar
将编写好的Flink程序打包后上传到服务器的
/root目录
提交作业
进入到flink的bin目录,使用
flink run命令提交作业
[root@node01 flink]# ./bin/flink run -m node01:8081 -c cn.ybzy.demo.WordCountStreamUnboundedDemo demo-1.0-SNAPSHOT.jar
Job has been submitted with JobID 33a87b974d19880887ffe9b34efc8ac8
-m:指定提交到的JobManager-c:指定入口类
查看任务
浏览器中打开Web UI,访问http://node01:8081查看任务
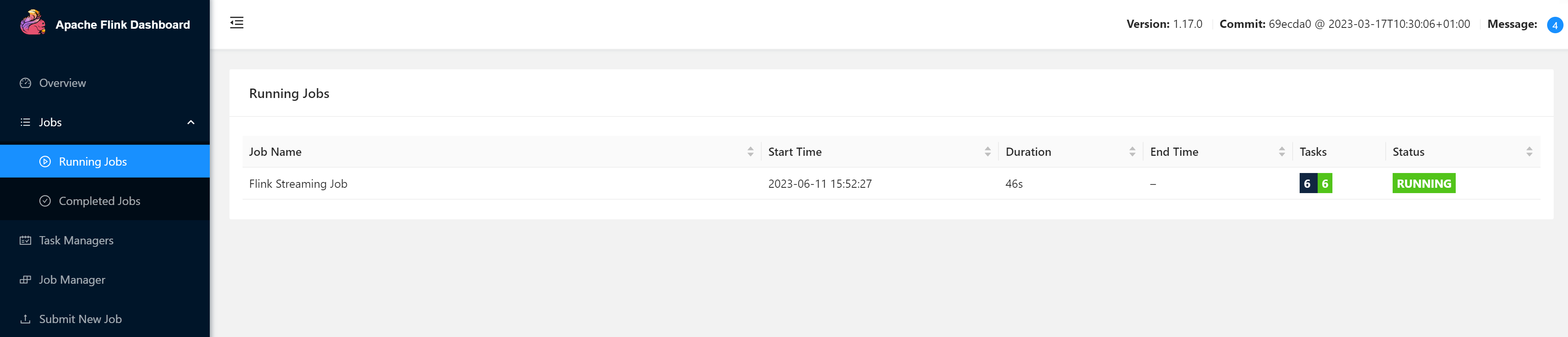
点击任务查询详情
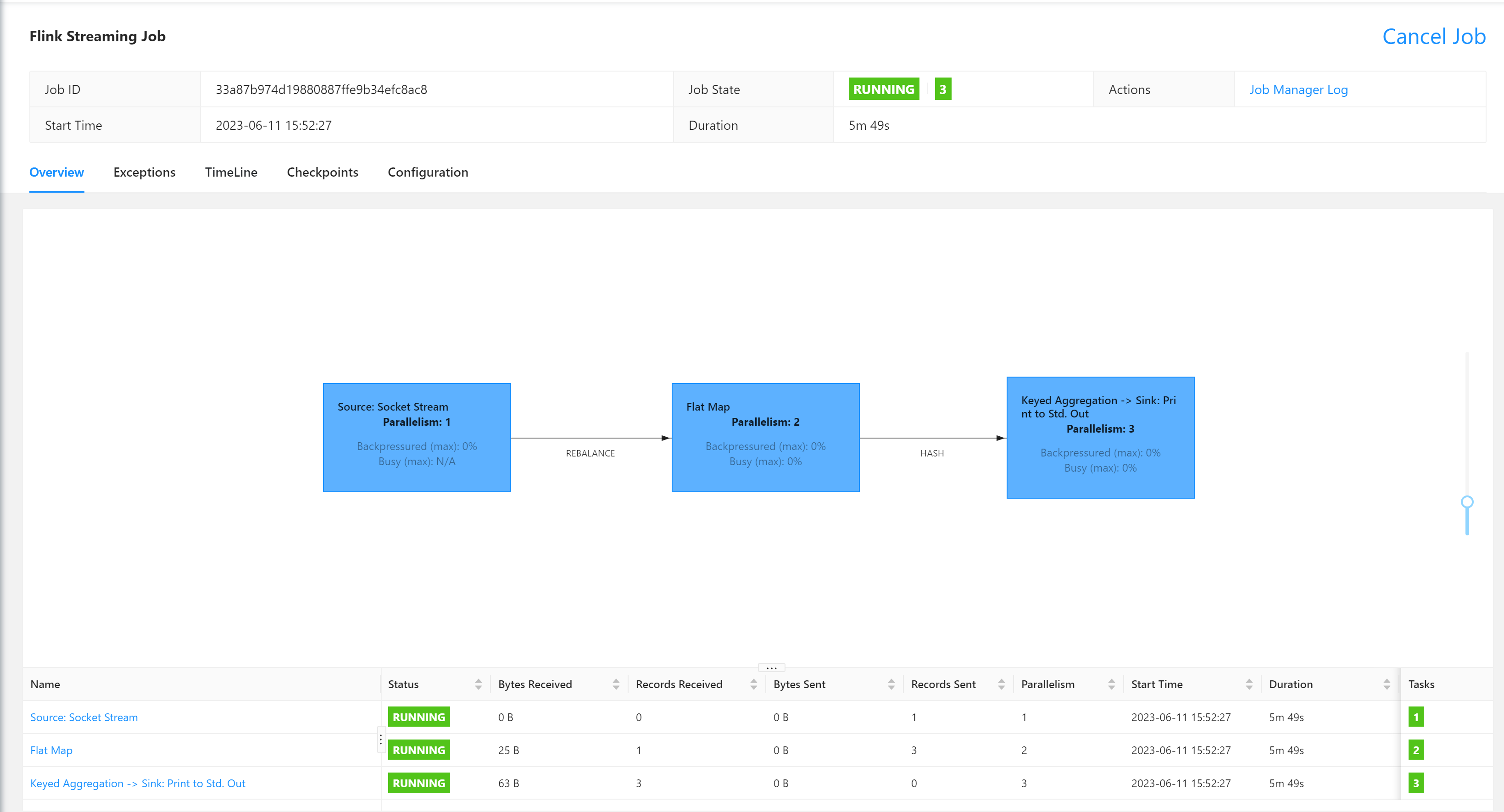
测试
在socket端口,发送测试数据
[root@node01 bin]# nc -lk 8888
abc bcd cdf
在TaskManagers列表中寻找执行节点,并查看执行日志。
这里很明显node01节点有数据接收,故应该查看它,否则应该在其他TaskManager节点查看
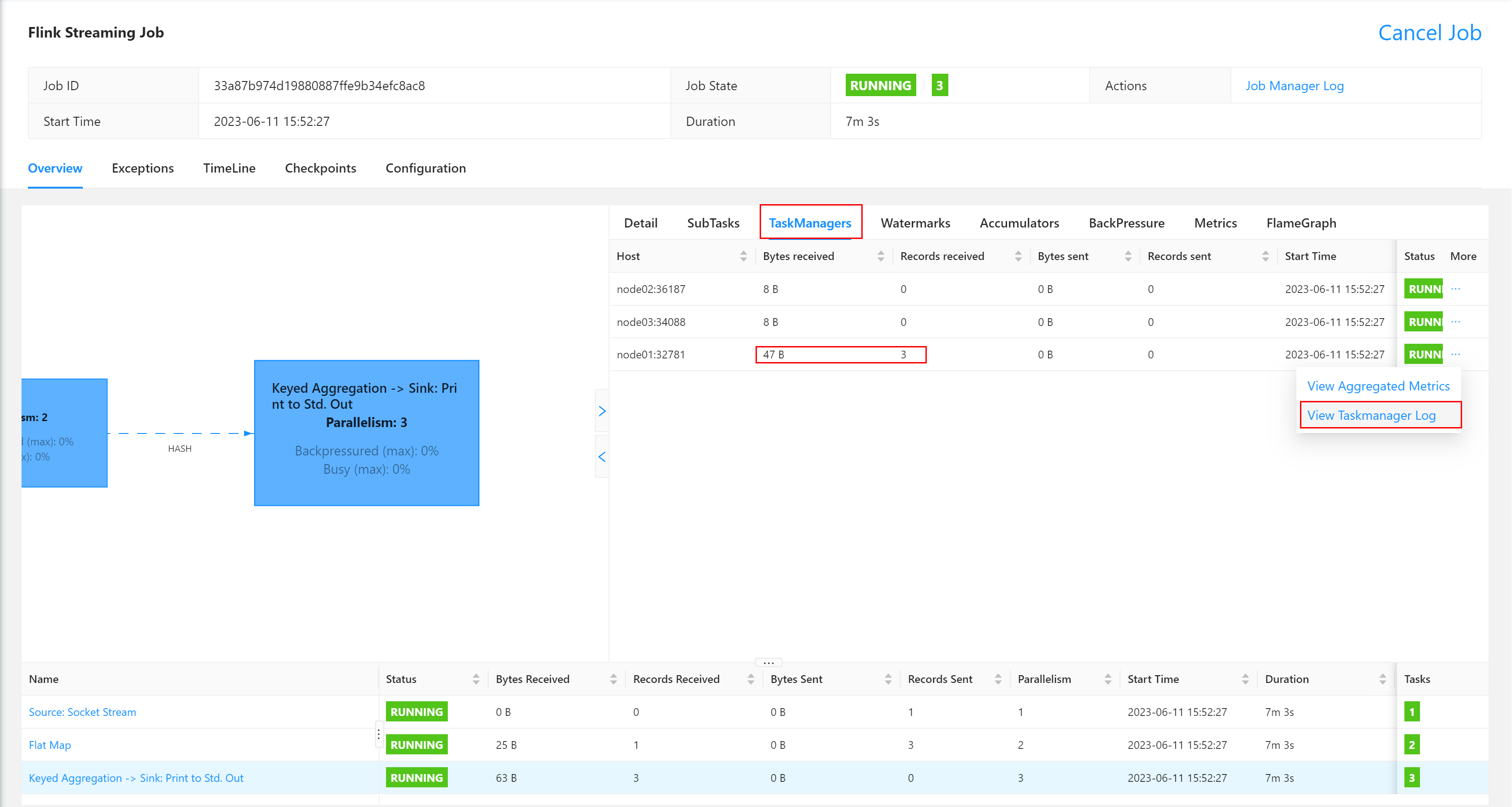
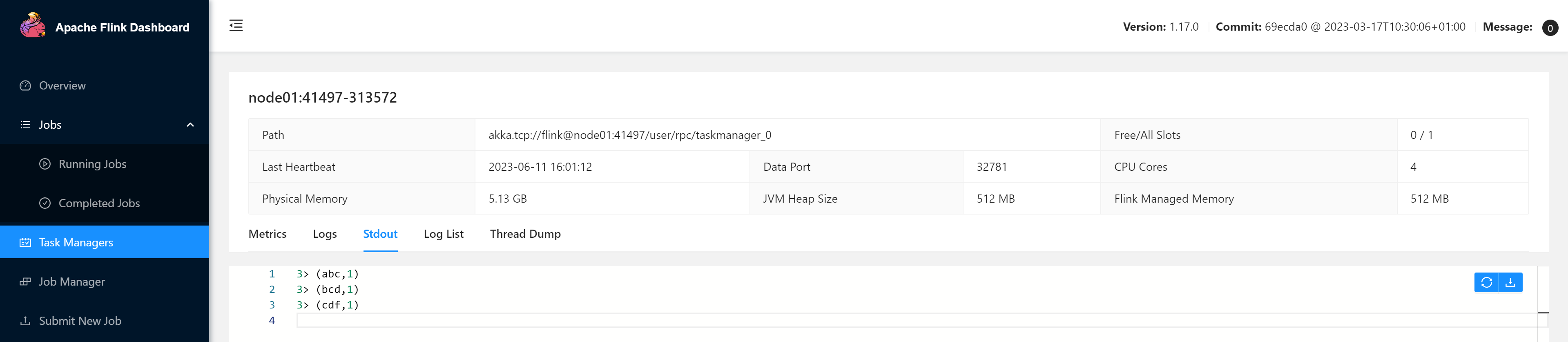
在TaskManager的标准输出(Stdout)看到对应的统计结果。
Web UI提交作业
除了通过命令行提交任务之外,也可以直接通过WEB UI界面提交任务。
提交作业
打开Flink的WEB UI页面,选择上传运行的JAR 包

JAR包上传完成

点击该 JAR 包,出现任务配置页面,进行相应配置。
配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等
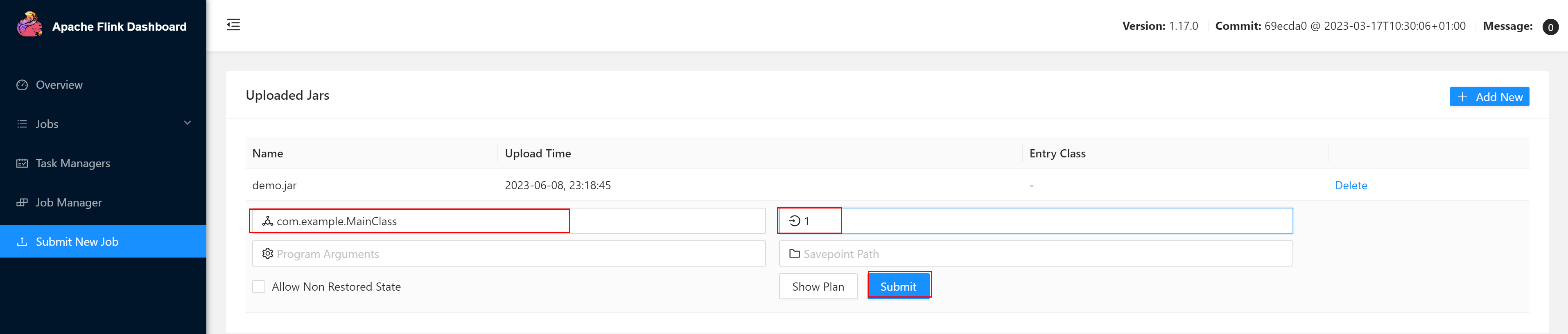
配置完成后,即可点击按钮“Submit”,将任务提交到集群运行,默认显示任务运行的具体情况
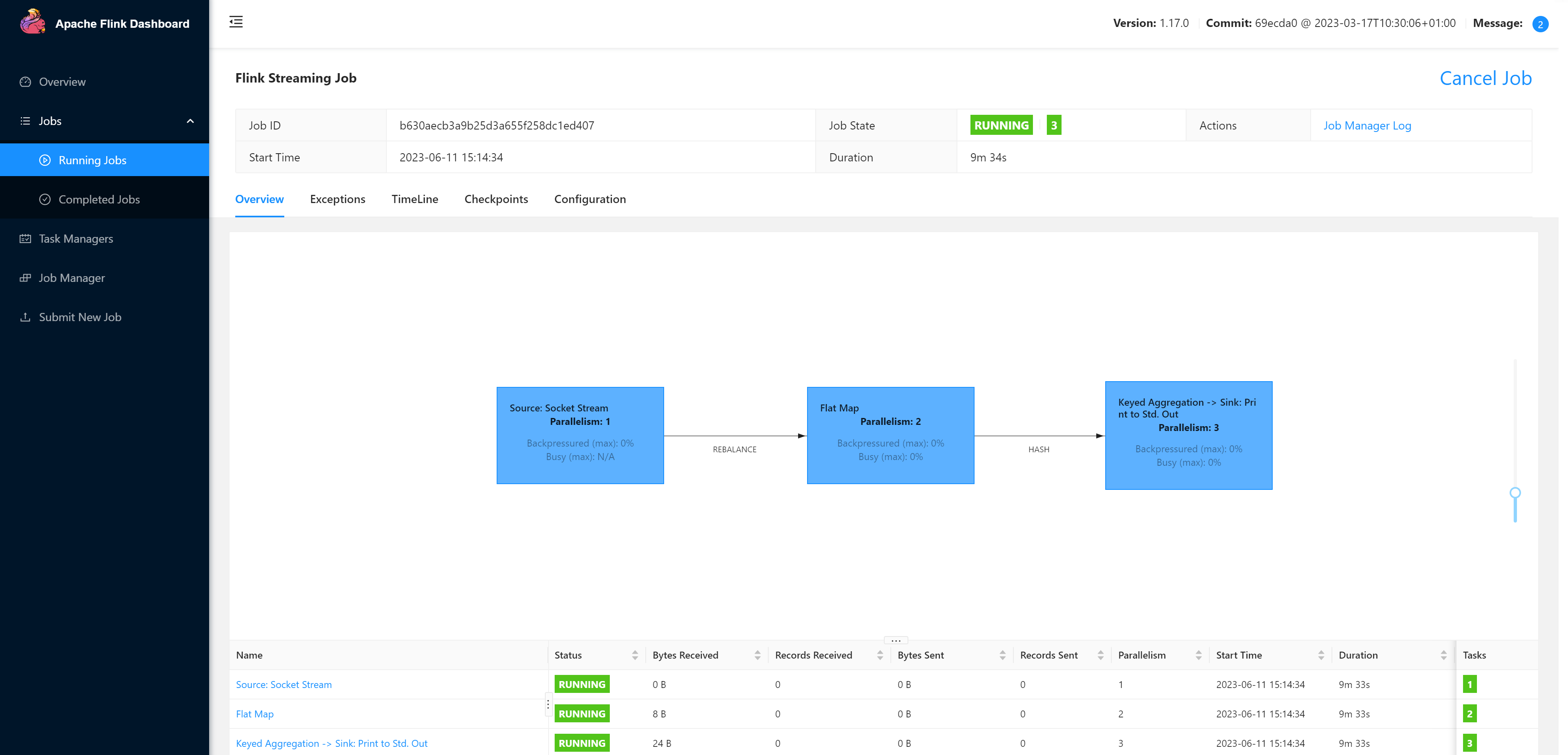
测试
在socket端口,发送测试数据
[root@node01 bin]# nc -lk 8888
abc bcd cdf
在TaskManagers列表中寻找执行节点,并查看执行日志。
这里很明显node02节点有数据接收,故应该查看它,否则应该在其他TaskManager节点查看