目录
一.引言
二.RoPE 理论
1.RoPE 矩阵形式
2.RoPE 图例形式
3.RoPE 实践分析
三.RoPE 代码分析
1.源码获取
2.源码分析
3.rotary_emb
3.1 __init__
3.2 forward
4.apply_rotary_pos_emb
4.1 rotate_half
4.2 apply_rotary_pos_emb
四.RoPE 代码实现
1.Q/K/V States
2.rotary_emd
3.apply_rotray_pos_emd
五.总结
一.引言
LLM - 通俗理解位置编码与 RoPE 一文我们介绍了 RoPE 的理论基础和实现思路,下面我们再简单回顾下 RoPE 的实现思路并结合最新 LLM 模型的源代码看下 RoPE 具体是如何实现的。
二.RoPE 理论
1.RoPE 矩阵形式
结合内积的线性叠加性,我们可以将 2 维的旋转矩阵 R 推广到多维。相当于在原始 token 的向量上,两两截断通过 R 实现旋转操作,最后拼接为 R 维向量。犹如我们常用的向量维度都是偶数且是 2 的倍数,所以这里针对偶数向量:

由于上述 R 矩阵的稀疏性,使用矩阵乘法会造成算力的严重浪费,所以推荐使用下述线性方式计算 RoPE:

其中 ⊗ 是逐位对应相乘,即 Numpy、Tensorflow 等计算框架中的∗运算。从这个实现也可以看到,RoPE 可以视为是乘性位置编码的变体,将多个二维旋转的叠加:

2.RoPE 图例形式
上面将二维旋转矩阵 R 推广到多维旋转矩阵,并基于其矩阵特点,将稀疏矩阵计算简化至对位相乘,通过下图可以更清晰地理解计算过程:

因为上面的 是两两表示的,所以实际计算中,也是将 token 词向量两两分成,这也解释了为什么公式里到处是 d/2。其添加位置信息步骤如下:
- 遍历每个位置的 token,位置为 m,范围为 Query / Key 的长度
- 获取对应 token Embedding,dim = d
- [2i: 2i+1] for i in range(0, d/2) 两两获取向量,根据公式计算 θ 并通过 R 进行旋转变换
- 得到新的 Position Encoded Query / Key
- Attention 操作并自动引入 (m-n) 的相对距离信息
从右上角的图中也可以更直观的看到向量旋转的过程。
3.RoPE 实践分析
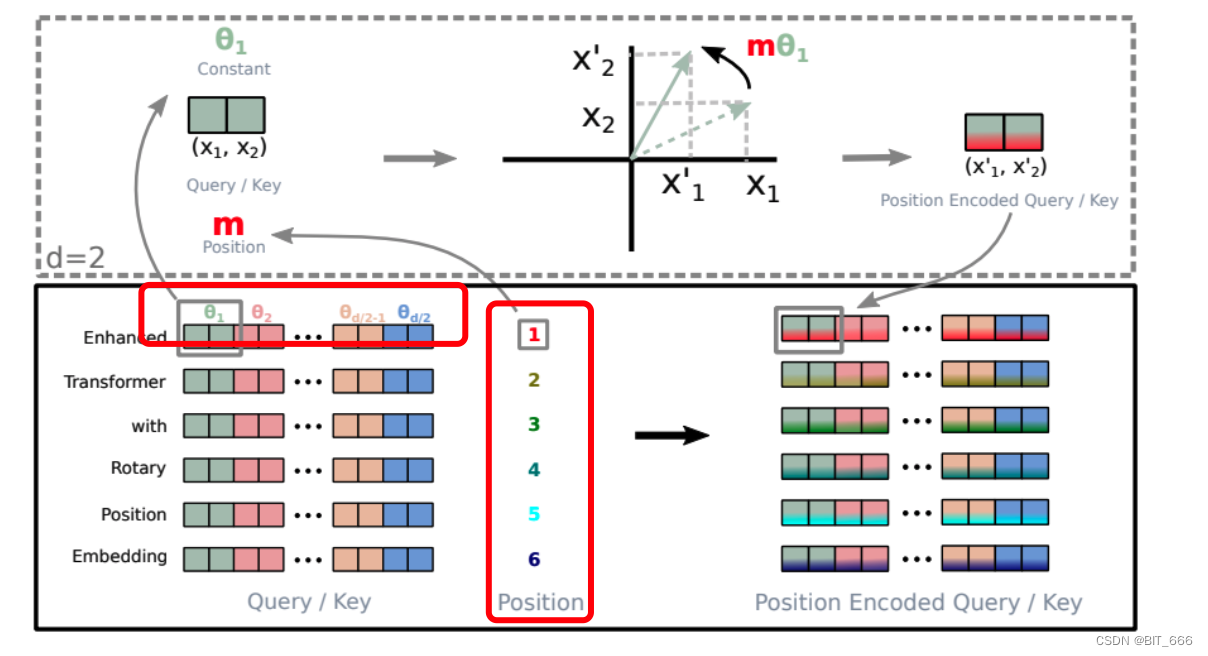
观察上面的图我们可以看到 RoPE 计算主要分两部分
◆ 旋转角度 θ
![]()
这里 theta 完全由 Q、K、V 的向量长度 d 决定,即 dim。
◆ 位置 Position m
位置 m 对应我们的 query 长度,实际代码中由 max_position_embeddings 参数决定,可以理解为模型支持的最长 query 的长度,因此 max 有了,m 的范围也就有了。
◆ Freq 频次矩阵
结合上面的信息,针对一个固定了最长 query 长度 m 和向量维度 d 的 LLM,我们可以提前将其对应的旋转变换矩阵构造完成:
θ 有的地方写 [1, d/2],有的地方范围写 [0, d/2-1];其次位置 Position 有的地方写 [0, m-1],有的写 [1, m],这里写成从 1 开头为了方便大家理解,实际代码中会从 0 开始。结合这个 Rd 的变换矩阵,分别执行 cos 和 sin,便可以得到我们计算所需的全位置全维度的变换矩阵。下面看下代码如何实现。
三.RoPE 代码分析
1.源码获取
开始分析前,我们首先需要搞清楚源代码在哪,然后再开始分析。InternLM-20B 是最近最新推出的新版大模型,我们找最新模型的源码看下对应 RoPE Embedding 部分怎么执行。
◆ Hugging Face
在搜索框搜索对应模型名称。

◆ InternLM-20B
点击模型的 Files and versions 选项,对应的 modeling_xxx.py 即为实现源码。

◆ modeling_internlm.py
一共 999 行,粘过来省的大家再去 HF 上翻了。
# coding=utf-8
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
#
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
# and OPT implementations in this library. It has been modified from its
# original forms to accommodate minor architectural differences compared
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch InternLM model."""
import math
from typing import List, Optional, Tuple, Union
import threading, queueimport torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELossfrom transformers.activations import ACT2FN
from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
from transformers.modeling_utils import PreTrainedModel
from transformers.generation.streamers import BaseStreamer
from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
from .configuration_internlm import InternLMConfiglogger = logging.get_logger(__name__)_CONFIG_FOR_DOC = "InternLMConfig"# TODO: https://bitddd.blog.csdn.net/article/details/133174206
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
):"""Make causal mask used for bi-directional self-attention."""bsz, tgt_len = input_ids_shapemask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)mask_cond = torch.arange(mask.size(-1), device=device)mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)mask = mask.to(dtype)if past_key_values_length > 0:mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)# Copied from transformers.models.bart.modeling_bart._expand_mask
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):"""Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`."""bsz, src_len = mask.size()tgt_len = tgt_len if tgt_len is not None else src_lenexpanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)inverted_mask = 1.0 - expanded_maskreturn inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)class InternLMRMSNorm(nn.Module):def __init__(self, hidden_size, eps=1e-6):"""InternLMRMSNorm is equivalent to T5LayerNorm"""super().__init__()self.weight = nn.Parameter(torch.ones(hidden_size))self.variance_epsilon = epsdef forward(self, hidden_states):variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)# convert into half-precision if necessaryif self.weight.dtype in [torch.float16, torch.bfloat16]:hidden_states = hidden_states.to(self.weight.dtype)return self.weight * hidden_statesclass InternLMRotaryEmbedding(torch.nn.Module):def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):super().__init__()inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))self.register_buffer("inv_freq", inv_freq, persistent=False)# Build here to make `torch.jit.trace` work.self.max_seq_len_cached = max_position_embeddingst = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculationemb = torch.cat((freqs, freqs), dim=-1)self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)def forward(self, x, seq_len=None):# x: [bs, num_attention_heads, seq_len, head_size]# This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case.if seq_len > self.max_seq_len_cached:self.max_seq_len_cached = seq_lent = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculationemb = torch.cat((freqs, freqs), dim=-1).to(x.device)self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)return (self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),)def rotate_half(x):"""Rotates half the hidden dims of the input."""x1 = x[..., : x.shape[-1] // 2]x2 = x[..., x.shape[-1] // 2 :]return torch.cat((-x2, x1), dim=-1)def apply_rotary_pos_emb(q, k, cos, sin, position_ids):# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]q_embed = (q * cos) + (rotate_half(q) * sin)k_embed = (k * cos) + (rotate_half(k) * sin)return q_embed, k_embedclass InternLMMLP(nn.Module):def __init__(self,hidden_size: int,intermediate_size: int,hidden_act: str,):super().__init__()self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)self.act_fn = ACT2FN[hidden_act]def forward(self, x):return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))class InternLMAttention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def __init__(self, config: InternLMConfig):super().__init__()self.config = configself.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.hidden_size // self.num_headsself.max_position_embeddings = config.max_position_embeddingsif (self.head_dim * self.num_heads) != self.hidden_size:raise ValueError(f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"f" and `num_heads`: {self.num_heads}).")self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.bias)self.k_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.bias)self.v_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.bias)self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.bias)self.rotary_emb = InternLMRotaryEmbedding(self.head_dim, max_position_embeddings=self.max_position_embeddings)def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Tuple[torch.Tensor]] = None,output_attentions: bool = False,use_cache: bool = False,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size()query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)kv_seq_len = key_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value[0].shape[-2]cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)# [bsz, nh, t, hd]if past_key_value is not None:# reuse k, v, self_attentionkey_states = torch.cat([past_key_value[0], key_states], dim=2)value_states = torch.cat([past_key_value[1], value_states], dim=2)past_key_value = (key_states, value_states) if use_cache else Noneattn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):raise ValueError(f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"f" {attn_weights.size()}")if attention_mask is not None:if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):raise ValueError(f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")attn_weights = attn_weights + attention_maskattn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))# upcast attention to fp32attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_output = torch.matmul(attn_weights, value_states)if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):raise ValueError(f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"f" {attn_output.size()}")attn_output = attn_output.transpose(1, 2)attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)attn_output = self.o_proj(attn_output)if not output_attentions:attn_weights = Nonereturn attn_output, attn_weights, past_key_valueclass InternLMDecoderLayer(nn.Module):def __init__(self, config: InternLMConfig):super().__init__()self.hidden_size = config.hidden_sizeself.self_attn = InternLMAttention(config=config)self.mlp = InternLMMLP(hidden_size=self.hidden_size,intermediate_size=config.intermediate_size,hidden_act=config.hidden_act,)self.input_layernorm = InternLMRMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.post_attention_layernorm = InternLMRMSNorm(config.hidden_size, eps=config.rms_norm_eps)def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Tuple[torch.Tensor]] = None,output_attentions: Optional[bool] = False,use_cache: Optional[bool] = False,) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:"""Args:hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`attention_mask (`torch.FloatTensor`, *optional*): attention mask of size`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.output_attentions (`bool`, *optional*):Whether or not to return the attentions tensors of all attention layers. See `attentions` underreturned tensors for more detail.use_cache (`bool`, *optional*):If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding(see `past_key_values`).past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states"""residual = hidden_stateshidden_states = self.input_layernorm(hidden_states)# Self Attentionhidden_states, self_attn_weights, present_key_value = self.self_attn(hidden_states=hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,)hidden_states = residual + hidden_states# Fully Connectedresidual = hidden_stateshidden_states = self.post_attention_layernorm(hidden_states)hidden_states = self.mlp(hidden_states)hidden_states = residual + hidden_statesoutputs = (hidden_states,)if output_attentions:outputs += (self_attn_weights,)if use_cache:outputs += (present_key_value,)return outputsINTERNLM_START_DOCSTRING = r"""This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods thelibrary implements for all its model (such as downloading or saving, resizing the input embeddings, pruning headsetc.)This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usageand behavior.Parameters:config ([`InternLMConfig`]):Model configuration class with all the parameters of the model. Initializing with a config file does notload the weights associated with the model, only the configuration. Check out the[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""@add_start_docstrings("The bare InternLM Model outputting raw hidden-states without any specific head on top.",INTERNLM_START_DOCSTRING,
)
class InternLMPreTrainedModel(PreTrainedModel):config_class = InternLMConfigbase_model_prefix = "model"supports_gradient_checkpointing = True_no_split_modules = ["InternLMDecoderLayer"]_keys_to_ignore_on_load_unexpected = [r"decoder\.version"]def _init_weights(self, module):std = self.config.initializer_rangeif isinstance(module, nn.Linear):module.weight.data.normal_(mean=0.0, std=std)if module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.Embedding):module.weight.data.normal_(mean=0.0, std=std)if module.padding_idx is not None:module.weight.data[module.padding_idx].zero_()def _set_gradient_checkpointing(self, module, value=False):if isinstance(module, InternLMModel):module.gradient_checkpointing = valueINTERNLM_INPUTS_DOCSTRING = r"""Args:input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provideit.Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and[`PreTrainedTokenizer.__call__`] for details.[What are input IDs?](../glossary#input-ids)attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:- 1 for tokens that are **not masked**,- 0 for tokens that are **masked**.[What are attention masks?](../glossary#attention-mask)Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and[`PreTrainedTokenizer.__call__`] for details.If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see`past_key_values`).If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for moreinformation on the default strategy.- 1 indicates the head is **not masked**,- 0 indicates the head is **masked**.position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,config.n_positions - 1]`.[What are position IDs?](../glossary#position-ids)past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attentionblocks) that can be used (see `past_key_values` input) to speed up sequential decoding.If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those thatdon't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all`decoder_input_ids` of shape `(batch_size, sequence_length)`.inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. Thisis useful if you want more control over how to convert `input_ids` indices into associated vectors than themodel's internal embedding lookup matrix.use_cache (`bool`, *optional*):If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see`past_key_values`).output_attentions (`bool`, *optional*):Whether or not to return the attentions tensors of all attention layers. See `attentions` under returnedtensors for more detail.output_hidden_states (`bool`, *optional*):Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors formore detail.return_dict (`bool`, *optional*):Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""@add_start_docstrings("The bare InternLM Model outputting raw hidden-states without any specific head on top.",INTERNLM_START_DOCSTRING,
)
class InternLMModel(InternLMPreTrainedModel):"""Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`InternLMDecoderLayer`]Args:config: InternLMConfig"""_auto_class = "AutoModel"def __init__(self, config: InternLMConfig):super().__init__(config)self.padding_idx = config.pad_token_idself.vocab_size = config.vocab_sizeself.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)self.layers = nn.ModuleList([InternLMDecoderLayer(config) for _ in range(config.num_hidden_layers)])self.norm = InternLMRMSNorm(config.hidden_size, eps=config.rms_norm_eps)self.gradient_checkpointing = False# Initialize weights and apply final processingself.post_init()def get_input_embeddings(self):return self.embed_tokensdef set_input_embeddings(self, value):self.embed_tokens = value# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_maskdef _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):# create causal mask# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]combined_attention_mask = Noneif input_shape[-1] > 1:combined_attention_mask = _make_causal_mask(input_shape,inputs_embeds.dtype,device=inputs_embeds.device,past_key_values_length=past_key_values_length,)if attention_mask is not None:# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(inputs_embeds.device)combined_attention_mask = (expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask)return combined_attention_mask@add_start_docstrings_to_model_forward(INTERNLM_INPUTS_DOCSTRING)def forward(self,input_ids: torch.LongTensor = None,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_values: Optional[List[torch.FloatTensor]] = None,inputs_embeds: Optional[torch.FloatTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple, BaseModelOutputWithPast]:output_attentions = output_attentions if output_attentions is not None else self.config.output_attentionsoutput_hidden_states = (output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states)use_cache = use_cache if use_cache is not None else self.config.use_cachereturn_dict = return_dict if return_dict is not None else self.config.use_return_dict# retrieve input_ids and inputs_embedsif input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")elif input_ids is not None:batch_size, seq_length = input_ids.shapeelif inputs_embeds is not None:batch_size, seq_length, _ = inputs_embeds.shapeelse:raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")seq_length_with_past = seq_lengthpast_key_values_length = 0if past_key_values is not None:past_key_values_length = past_key_values[0][0].shape[2]seq_length_with_past = seq_length_with_past + past_key_values_lengthif position_ids is None:device = input_ids.device if input_ids is not None else inputs_embeds.deviceposition_ids = torch.arange(past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device)position_ids = position_ids.unsqueeze(0).view(-1, seq_length)else:position_ids = position_ids.view(-1, seq_length).long()if inputs_embeds is None:inputs_embeds = self.embed_tokens(input_ids)# embed positionsif attention_mask is None:attention_mask = torch.ones((batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device)attention_mask = self._prepare_decoder_attention_mask(attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length)hidden_states = inputs_embedsif self.gradient_checkpointing and self.training:if use_cache:logger.warning_once("`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")use_cache = False# decoder layersall_hidden_states = () if output_hidden_states else Noneall_self_attns = () if output_attentions else Nonenext_decoder_cache = () if use_cache else Nonefor idx, decoder_layer in enumerate(self.layers):if output_hidden_states:all_hidden_states += (hidden_states,)past_key_value = past_key_values[idx] if past_key_values is not None else Noneif self.gradient_checkpointing and self.training:def create_custom_forward(module):def custom_forward(*inputs):# None for past_key_valuereturn module(*inputs, output_attentions, None)return custom_forwardlayer_outputs = torch.utils.checkpoint.checkpoint(create_custom_forward(decoder_layer),hidden_states,attention_mask,position_ids,None,)else:layer_outputs = decoder_layer(hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,)hidden_states = layer_outputs[0]if use_cache:next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)if output_attentions:all_self_attns += (layer_outputs[1],)hidden_states = self.norm(hidden_states)# add hidden states from the last decoder layerif output_hidden_states:all_hidden_states += (hidden_states,)next_cache = next_decoder_cache if use_cache else Noneif not return_dict:return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)return BaseModelOutputWithPast(last_hidden_state=hidden_states,past_key_values=next_cache,hidden_states=all_hidden_states,attentions=all_self_attns,)class InternLMForCausalLM(InternLMPreTrainedModel):_auto_class = "AutoModelForCausalLM"def __init__(self, config):super().__init__(config)self.model = InternLMModel(config)self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)# Initialize weights and apply final processingself.post_init()def get_input_embeddings(self):return self.model.embed_tokensdef set_input_embeddings(self, value):self.model.embed_tokens = valuedef get_output_embeddings(self):return self.lm_headdef set_output_embeddings(self, new_embeddings):self.lm_head = new_embeddingsdef set_decoder(self, decoder):self.model = decoderdef get_decoder(self):return self.model@add_start_docstrings_to_model_forward(INTERNLM_INPUTS_DOCSTRING)@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)def forward(self,input_ids: torch.LongTensor = None,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_values: Optional[List[torch.FloatTensor]] = None,inputs_embeds: Optional[torch.FloatTensor] = None,labels: Optional[torch.LongTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple, CausalLMOutputWithPast]:r"""Args:labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.Returns:Example:```python>>> from transformers import AutoTokenizer, InternLMForCausalLM>>> model = InternLMForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)>>> prompt = "Hey, are you consciours? Can you talk to me?">>> inputs = tokenizer(prompt, return_tensors="pt")>>> # Generate>>> generate_ids = model.generate(inputs.input_ids, max_length=30)>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]"Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."```"""output_attentions = output_attentions if output_attentions is not None else self.config.output_attentionsoutput_hidden_states = (output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states)return_dict = return_dict if return_dict is not None else self.config.use_return_dict# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)outputs = self.model(input_ids=input_ids,attention_mask=attention_mask,position_ids=position_ids,past_key_values=past_key_values,inputs_embeds=inputs_embeds,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)hidden_states = outputs[0]logits = self.lm_head(hidden_states)loss = Noneif labels is not None:# Shift so that tokens < n predict nshift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()# Flatten the tokensloss_fct = CrossEntropyLoss()shift_logits = shift_logits.view(-1, self.config.vocab_size)shift_labels = shift_labels.view(-1)# Enable model parallelismshift_labels = shift_labels.to(shift_logits.device)loss = loss_fct(shift_logits, shift_labels)if not return_dict:output = (logits,) + outputs[1:]return (loss,) + output if loss is not None else outputreturn CausalLMOutputWithPast(loss=loss,logits=logits,past_key_values=outputs.past_key_values,hidden_states=outputs.hidden_states,attentions=outputs.attentions,)def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs):if past_key_values:input_ids = input_ids[:, -1:]position_ids = kwargs.get("position_ids", None)if attention_mask is not None and position_ids is None:# create position_ids on the fly for batch generationposition_ids = attention_mask.long().cumsum(-1) - 1position_ids.masked_fill_(attention_mask == 0, 1)if past_key_values:position_ids = position_ids[:, -1].unsqueeze(-1)# if `inputs_embeds` are passed, we only want to use them in the 1st generation stepif inputs_embeds is not None and past_key_values is None:model_inputs = {"inputs_embeds": inputs_embeds}else:model_inputs = {"input_ids": input_ids}model_inputs.update({"position_ids": position_ids,"past_key_values": past_key_values,"use_cache": kwargs.get("use_cache"),"attention_mask": attention_mask,})return model_inputs@staticmethoddef _reorder_cache(past_key_values, beam_idx):reordered_past = ()for layer_past in past_key_values:reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)return reordered_pastdef build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = []):prompt = ""for record in history:prompt += f"""<s><|User|>:{record[0]}<eoh>\n<|Bot|>:{record[1]}<eoa>\n"""if len(prompt) == 0:prompt += "<s>"prompt += f"""<|User|>:{query}<eoh>\n<|Bot|>:"""return tokenizer([prompt], return_tensors="pt")@torch.no_grad()def chat(self, tokenizer, query: str,history: List[Tuple[str, str]] = [], streamer: Optional[BaseStreamer] = None,max_new_tokens: int = 1024,do_sample: bool = True,temperature: float = 0.8,top_p: float = 0.8,**kwargs):inputs = self.build_inputs(tokenizer, query, history)inputs = {k: v.to(self.device) for k, v in inputs.items() if torch.is_tensor(v)}outputs = self.generate(**inputs, streamer=streamer, max_new_tokens=max_new_tokens, do_sample=do_sample, temperature=temperature, top_p=top_p, **kwargs)outputs = outputs[0].cpu().tolist()[len(inputs["input_ids"][0]):]response = tokenizer.decode(outputs, skip_special_tokens=True)response = response.split("<eoa>")[0]history = history + [(query, response)]return response, history@torch.no_grad()def stream_chat(self, tokenizer,query: str,history: List[Tuple[str, str]] = [], max_new_tokens: int = 1024,do_sample: bool = True,temperature: float = 0.8,top_p: float = 0.8,**kwargs):"""Return a generator in format: (response, history)Eg.('你好,有什么可以帮助您的吗', [('你好', '你好,有什么可以帮助您的吗')])('你好,有什么可以帮助您的吗?', [('你好', '你好,有什么可以帮助您的吗?')])"""response_queue = queue.Queue(maxsize=20)class ChatStreamer(BaseStreamer):def __init__(self, tokenizer) -> None:super().__init__()self.tokenizer = tokenizerself.queue = response_queueself.query = queryself.history = historyself.response = ""self.received_inputs = Falseself.queue.put((self.response, history + [(self.query, self.response)]))def put(self, value):if len(value.shape) > 1 and value.shape[0] > 1:raise ValueError("ChatStreamer only supports batch size 1")elif len(value.shape) > 1:value = value[0]if not self.received_inputs:# The first received value is input_ids, ignore hereself.received_inputs = Truereturntoken = self.tokenizer.decode([value[-1]], skip_special_tokens=True)if token.strip() != "<eoa>":self.response = self.response + tokenhistory = self.history + [(self.query, self.response)]self.queue.put((self.response, history))def end(self):self.queue.put(None)def stream_producer():return self.chat(tokenizer=tokenizer,query=query,streamer=ChatStreamer(tokenizer=tokenizer),history=history, max_new_tokens=max_new_tokens,do_sample=do_sample,temperature=temperature,top_p=top_p,**kwargs)def consumer():producer = threading.Thread(target=stream_producer)producer.start()while True:res = response_queue.get()if res is None:returnyield resreturn consumer()@add_start_docstrings("""The InternLM Model transformer with a sequence classification head on top (linear layer).[`InternLMForSequenceClassification`] uses the last token in order to do the classification, as other causal models(e.g. GPT-2) do.Since it does classification on the last token, it requires to know the position of the last token. If a`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. Ifno `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess thepadding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value ineach row of the batch).""",INTERNLM_START_DOCSTRING,
)
class InternLMForSequenceClassification(InternLMPreTrainedModel):_keys_to_ignore_on_load_missing = [r"lm_head.weight"]def __init__(self, config):super().__init__(config)self.num_labels = config.num_labelsself.model = InternLMModel(config)self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)# Initialize weights and apply final processingself.post_init()def get_input_embeddings(self):return self.model.embed_tokensdef set_input_embeddings(self, value):self.model.embed_tokens = value@add_start_docstrings_to_model_forward(INTERNLM_INPUTS_DOCSTRING)def forward(self,input_ids: torch.LongTensor = None,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_values: Optional[List[torch.FloatTensor]] = None,inputs_embeds: Optional[torch.FloatTensor] = None,labels: Optional[torch.LongTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple, SequenceClassifierOutputWithPast]:r"""labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If`config.num_labels > 1` a classification loss is computed (Cross-Entropy)."""return_dict = return_dict if return_dict is not None else self.config.use_return_dicttransformer_outputs = self.model(input_ids,attention_mask=attention_mask,position_ids=position_ids,past_key_values=past_key_values,inputs_embeds=inputs_embeds,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)hidden_states = transformer_outputs[0]logits = self.score(hidden_states)if input_ids is not None:batch_size = input_ids.shape[0]else:batch_size = inputs_embeds.shape[0]if self.config.pad_token_id is None and batch_size != 1:raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")if self.config.pad_token_id is None:sequence_lengths = -1else:if input_ids is not None:sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device)else:sequence_lengths = -1pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]loss = Noneif labels is not None:labels = labels.to(logits.device)if self.config.problem_type is None:if self.num_labels == 1:self.config.problem_type = "regression"elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):self.config.problem_type = "single_label_classification"else:self.config.problem_type = "multi_label_classification"if self.config.problem_type == "regression":loss_fct = MSELoss()if self.num_labels == 1:loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())else:loss = loss_fct(pooled_logits, labels)elif self.config.problem_type == "single_label_classification":loss_fct = CrossEntropyLoss()loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))elif self.config.problem_type == "multi_label_classification":loss_fct = BCEWithLogitsLoss()loss = loss_fct(pooled_logits, labels)if not return_dict:output = (pooled_logits,) + transformer_outputs[1:]return ((loss,) + output) if loss is not None else outputreturn SequenceClassifierOutputWithPast(loss=loss,logits=pooled_logits,past_key_values=transformer_outputs.past_key_values,hidden_states=transformer_outputs.hidden_states,attentions=transformer_outputs.attentions,)
2.源码分析
这里 modeling_xxx.py 里,除了我们提到的 RoPE 位置编码的实现过程,还有前面提到的归一化函数 RMSNormal,MLP 的多个 proj,激活函数 SiLU 等等。有兴趣的同学可以有选择的阅读其他部分的代码,加深对大模型实现过程的认识。言归症状,先找到 RoPE 的调用位置,L199-L207,对应 Class InternLMAttention 注意力层的 forward 前向传递部分:
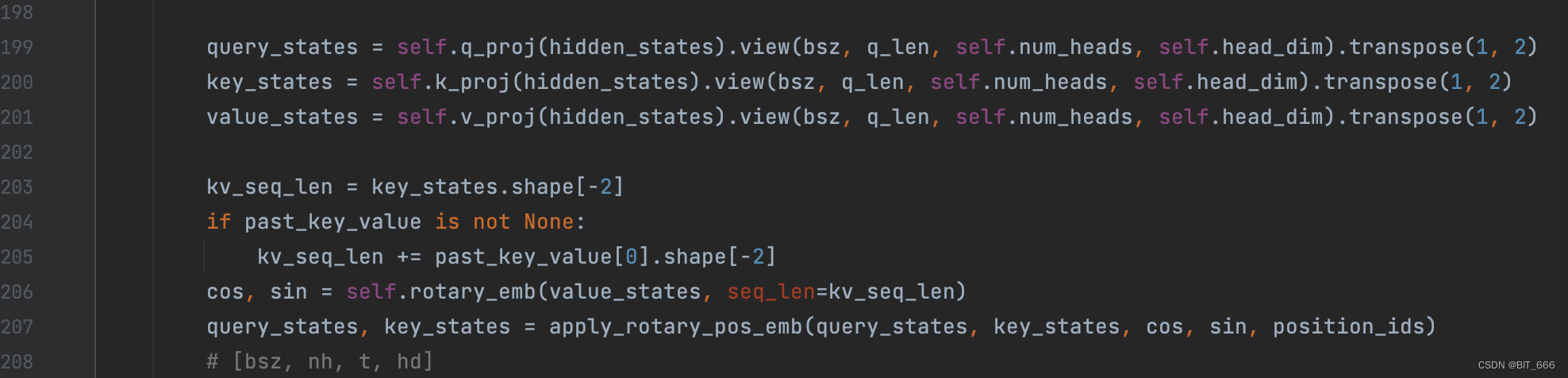
query、key、value 获取可以理解为从 Embedding 层 lookup 获取向量,除此之外还有两个方法:
◆ rotary_emb
rotary_emb 对应 InternLMRotaryEmbedding 层,其中内置 init 初始化方法和 forward 前向调用,这个方法负责生成我们上面实践分析中提到的 cos 和 sin。

◆ apply_rotary_pos_emb
该方法用于将旋转编码应用到 k、v 上,内部还用到了 rotate_half 的辅助函数。

3.rotary_emb
rotary_emb 继承 torch.nn.Module 实现了 InternLMRotaryEmbedding,其中包含 init 和 forward 前向计算的方法,下面看下两个方法的实现步骤。
3.1 __init__

◆ 参数分析
首先看 InternLMRotaryEmbedding init 方法的四个参数:
dim - 向量维度
max_position_embedding - 最大位置向量,其实就是我们上面分析的最大的 position: m
base - 计算 θ 的底数是 base,默认取 10000,和论文的公式是一致的
device - 设备,这个参数目前对我们代码理解没有影响,所以后续会取 None
◆ 构造 θ 全集
下面我们逐行执行代码,这里取向量维度 dim=8,底数 base=10000,设备 device=None。
dim = 8base = 10000device = None# 根据概率计算θ, dim/2个θinv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))![]()
这里就是根据维度 d 将所有的 θ 得到,由于是将向量两两旋转应用 RoPE,所以共有 d/2 个 θ,所以下面会得到 8/2 = 4 个 θ,即 inv_freq:
tensor([1.0000, 0.1000, 0.0100, 0.0010])
◆ 扩展至 m x d/2
inv_freq_cached = inv_freqmax_seq_len_cached = max_position_embeddingst = torch.arange(max_seq_len_cached, device=device, dtype=inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, inv_freq)这里 max_seq_len_cache 即为 max_position_embeddings 即为最大位置,我们可以到代码的 config.py 文件中查看该配置,此处 max_position_embeddings 的值为 4096:

arange 根据 max_position_embeddings 的 4096 生成对应的 Tensor:
tensor([0.0000e+00, 1.0000e+00, 2.0000e+00, ..., 4.0660e+03, 4.0670e+03, 4.0680e+03])而 torch.einsum 则是通过爱因斯坦求和约定,将 arange Tensor 与 θ Tensor 进行合并,生成 4096 x d/2 的初始旋转矩阵,也就是下面这个 Rd:
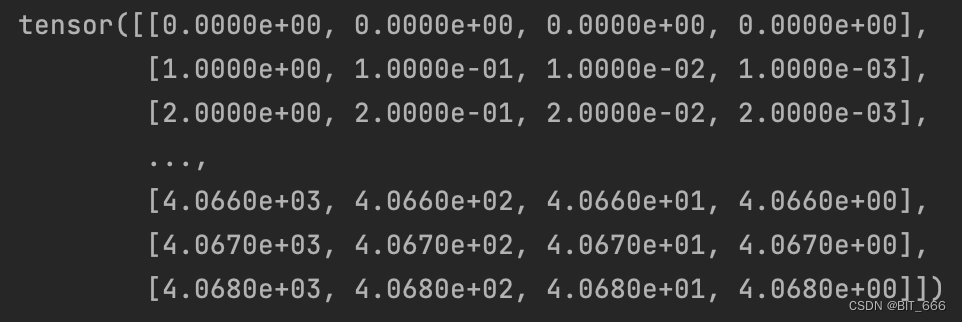
这里 inv_freq.shape = [4],t.shape = [4096],enisum 乘法后维度为 torch.Size([4069, 4])。关于 enisum 的使用之前也出了示例,大家可以参考: 深度学习矩阵乘法大全。
◆ R 旋转矩阵扩展
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)这里将提前计算的 freq 矩阵叠加得到 m x d 的旋转矩阵:
[θ1,θ2,θ3,θ4] [4069, 4] x 2 -> [θ1,θ2,θ3,θ4,θ1,θ2,θ3,θ4] torch.Size([4069, 8])
扩展一倍也很好理解,因为每个位置的 θ 需要对应两个 dim 的向量值。最后将扩展后的矩阵分别执行 cos 和 sin 即得到可用的旋转矩阵。而 [None, None, :, :] 的操作则是为了匹配原始 query、key 和 value 的维度。
- cos

- sin

3.2 forward

仔细观察 forward 函数,这里对于输入的 Tensor x,仅获取其对应 device 和 dtype。而且可以注意到其实现逻辑与 __init__ 一致,只是只是新增了判断 seq_len > max_seq_len_cache 的情况,将 max_seq_len_cache 的长度 m 提高,不过按照官方的注释 # 在'__init__'中构建sin/cos之后,这个'if'块不太可能运行。把逻辑放在这里以防万一:
# This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case.所以调用 forward 函数可以理解为直接获取 init 函数中的 cos 和 sin 的旋转矩阵,唯一做的就是转换其 dtype 与当前传入的 Tensor x 保持类型一致,观察 config 我们可以看到 InternLM 使用的类型为 bfloat16。最终 [:, :, :seq_len, ...] 取与当前 seq_len 匹配的矩阵,防止多余的空间和计算资源浪费,此时 cos 和 sin 的维度为:
torch.Size([1, 1, 4069, 8])4.apply_rotary_pos_emb
该方法用于将 cos、sin 的旋转矩阵应用到原始的 query 和 key 向量上,这样在 Attention 内积时,就会为 query 和 key 引入位置信息,其中还涉及到了辅助函数 ratate_half 用于调整向量位置。
4.1 rotate_half

这个函数很好理解,就是将原始向量从中间劈开分为 A、B 两份,然后拼接为 [-B, A] 的状态:
v1: [q0,q1,q2,q3,q4,q5,q6,q7] -> [-q4,-q5,-q6,-q7,q0,q1,q2,q3]4.2 apply_rotary_pos_emb
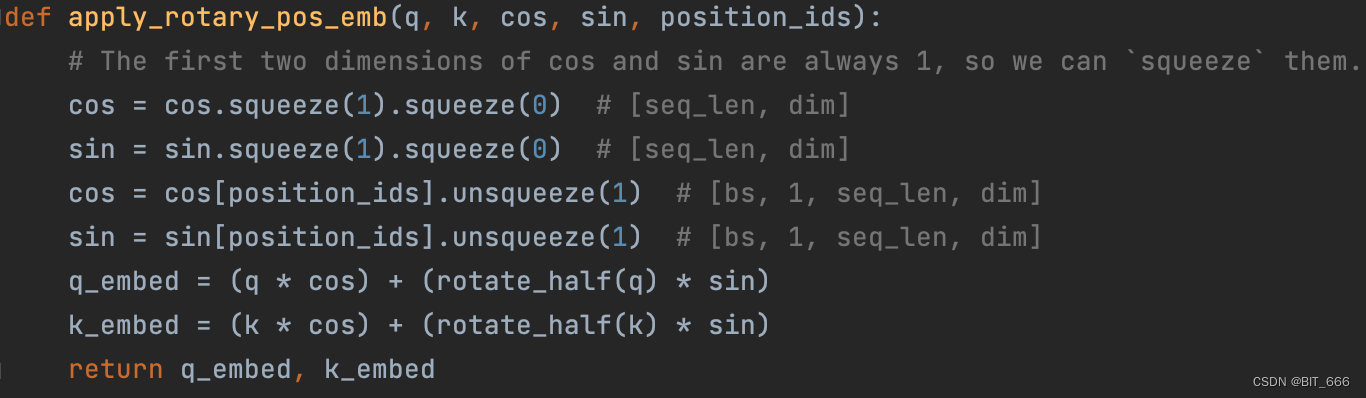
这个方法对照着前面矩阵形式里的公式就很好理解了,首先 lookup 获取对应位置的 cosmθ 和 sinmθ 值,然后分别计算前面的 cos 部分,再计算后面的 sinθ * rotate_half 部分。

不过按照代码的逻辑,rotate_half 后计算结果似乎与上图不匹配:
# v1: [q0,q1,q2,q3,q4,q5,q6,q7] -> [-q4,-q5,-q6,-q7,q0,q1,q2,q3]# [cosθ1, cosθ2, cosθ3, cosθ4, cosθ1, cosθ2, cosθ3, cosθ4]# [sinθ1, sinθ2, sinθ3, sinθ4, sinθ1, sinθ2, sinθ3, sinθ4]cos 部分不影响,两两与对应 θ 相乘即可,出问题部分是 sin 计算,这里按照 rotate_half 翻转后,对应的向量 4,5,6,7 部分变负,但是矩阵中应该是 1,3,5,7 变负,这里暂时没有搞清楚原因,但是大体的计算流程是与示意图匹配的。博主这里参考剑神论文给的代码稍微修改了一下 rotate_half 函数,修改后可以达到正确的 cos、sin 计算:
def rotate_half_v2(x):x1 = x[..., ::2]x2 = x[..., 1::2]return torch.cat((-x2, x1), dim=-1)使用该旋转函数后,sin 计算逻辑正常:
# v2: [q0,q1,q2,q3,q4,q5,q6,q7] -> [-q1,-q3,-q5,-q7,q0,q2,q4,q6]# [cosθ1, cosθ2, cosθ3, cosθ4, cosθ1, cosθ2, cosθ3, cosθ4]# [sinθ1, sinθ2, sinθ3, sinθ4, sinθ1, sinθ2, sinθ3, sinθ4]四.RoPE 代码实现
原始代码如上,我们只需自己构造 query、key、value states 和 position_ids 即可跑通流程。
1.Q/K/V States
Q/K/V 对应维度为 [bsz, seq_len, num_heads, head_dim],transpose 将 seq_len 和 num_heads 的维度调换了,得到的 states 维度为 [bsz, num_heads, seq_len, head_dim]。这个变换是为了将 seq_len x head_dim = 4096 x 8 挪到一起,方便后面的 ⊗ 对位相乘。
# Query、Key、Value 信息batch_size = 2query_length = 10num_heads = 4head_dim = 8past_key_value = None# 获取 Query、Key、Value Matrixquery_states = torch.rand(batch_size, query_length, num_heads, head_dim).transpose(1, 2)key_states = torch.rand(batch_size, query_length, num_heads, head_dim).transpose(1, 2)value_states = torch.rand(batch_size, query_length, num_heads, head_dim).transpose(1, 2)随机初始化后的 states 维度为: torch.Size([2, 4, 10, 8]),这里使用 torch.rand 随机生成并展示 query_states:
tensor([[[[2.9183e-01, 5.9775e-02, 3.5425e-01, 2.7915e-01, 5.2601e-01,8.3887e-01, 3.3162e-01, 1.3850e-01],[2.8997e-01, 1.5348e-01, 6.1809e-01, 6.7418e-01, 2.4923e-02,3.9746e-01, 7.3853e-01, 3.4693e-02],[4.1272e-01, 8.2844e-01, 3.2101e-01, 9.3669e-01, 9.9066e-01,7.3192e-01, 4.9623e-01, 3.6537e-01],[9.3123e-01, 6.0658e-01, 5.1689e-02, 4.8995e-01, 8.3494e-01,9.5322e-01, 4.4755e-01, 4.6204e-01],[2.2266e-01, 7.8899e-01, 3.1150e-01, 8.6672e-01, 5.7448e-01,1.8205e-02, 1.4669e-01, 1.4783e-01],[2.3940e-01, 8.3407e-01, 2.4727e-01, 4.8705e-02, 7.4942e-01,3.3560e-01, 5.5196e-01, 9.0414e-01],[5.7593e-01, 3.1633e-01, 1.8330e-01, 7.7621e-01, 5.8697e-01,1.8219e-01, 8.6412e-01, 4.4979e-02],[7.9487e-01, 2.2888e-02, 7.1163e-01, 1.7849e-01, 5.7600e-01,8.9930e-01, 3.5231e-01, 1.5648e-01],[5.2896e-02, 3.2068e-01, 7.3980e-01, 7.7020e-01, 4.4519e-01,7.1207e-01, 2.2424e-01, 1.2025e-01],[6.8193e-01, 4.9851e-01, 1.0965e-02, 1.3012e-02, 8.7816e-01,8.8564e-01, 5.6333e-01, 8.6411e-01]],[[6.8500e-01, 7.0738e-01, 2.9308e-01, 9.2951e-01, 6.1441e-02,3.6203e-02, 6.3757e-01, 4.7221e-01],[4.3020e-01, 5.7936e-01, 5.8797e-01, 5.2842e-01, 2.1757e-01,8.2139e-01, 8.1286e-01, 5.1831e-01],[5.0025e-01, 4.9856e-01, 8.6077e-01, 4.8580e-01, 6.7289e-01,1.6959e-01, 9.1899e-01, 7.0452e-02],[6.8620e-01, 5.9861e-01, 6.1024e-01, 9.4969e-01, 8.7641e-01,2.1290e-01, 2.9642e-01, 6.4476e-01],[4.0705e-02, 3.1697e-02, 9.2447e-01, 6.6854e-02, 2.7703e-01,1.0916e-01, 1.8328e-01, 8.0773e-01],[7.6717e-02, 3.4182e-01, 8.6993e-01, 3.9317e-01, 5.4155e-01,9.5709e-01, 3.4793e-01, 7.6505e-01],[8.4284e-01, 7.8279e-01, 3.6731e-01, 8.2489e-01, 7.0346e-01,9.5639e-01, 8.0766e-01, 9.2304e-01],[7.2185e-01, 2.5139e-01, 4.0992e-01, 2.3913e-01, 9.5667e-01,8.7461e-01, 5.1859e-02, 6.5691e-01],[5.9603e-01, 5.5759e-01, 6.1473e-01, 4.7875e-01, 7.2805e-01,7.7380e-02, 1.4822e-01, 4.0581e-01],[8.4941e-01, 5.4692e-01, 1.9650e-01, 7.9873e-01, 4.7650e-01,4.1342e-01, 5.8423e-01, 4.6351e-02]],[[6.4038e-01, 9.8298e-01, 3.1733e-01, 9.0533e-01, 5.8110e-01,4.9543e-01, 2.5562e-01, 9.5430e-01],[8.4416e-01, 1.5592e-01, 5.0446e-01, 9.4544e-01, 7.0241e-01,1.1321e-01, 9.0690e-01, 5.6367e-01],[6.8041e-01, 4.5696e-01, 8.0091e-01, 6.6836e-01, 3.1932e-01,2.5314e-02, 4.5553e-01, 3.2404e-03],[8.5800e-01, 6.9543e-01, 7.2294e-01, 1.3468e-01, 2.9467e-01,4.5119e-01, 6.0176e-01, 5.9708e-01],[4.7581e-01, 9.5652e-01, 3.6950e-01, 8.5315e-01, 1.5493e-01,4.5351e-01, 5.5274e-02, 3.9174e-01],[6.7330e-01, 4.2024e-01, 4.5872e-01, 3.6176e-01, 5.6271e-01,7.4545e-01, 1.9587e-01, 9.3089e-01],[3.6712e-01, 7.1372e-01, 1.8244e-01, 9.1078e-01, 1.4220e-01,9.6800e-01, 2.0999e-01, 2.3815e-01],[6.0856e-01, 5.5768e-01, 4.7132e-01, 5.1918e-01, 8.2279e-01,5.6378e-01, 6.5475e-01, 8.8963e-01],[4.7355e-01, 8.9392e-01, 5.2195e-01, 9.9627e-01, 7.1131e-01,9.4066e-01, 9.6293e-01, 2.1514e-01],[6.6799e-01, 1.5106e-03, 1.0987e-01, 7.2399e-01, 5.0414e-01,2.2703e-01, 2.2963e-01, 3.0123e-01]],[[3.4204e-01, 5.2402e-01, 5.7015e-01, 2.3358e-02, 8.8628e-01,7.8516e-01, 3.6371e-01, 8.4997e-01],[1.8298e-01, 3.5044e-01, 2.1751e-01, 2.5430e-01, 1.2984e-01,1.5158e-01, 4.8908e-01, 9.8046e-01],[4.0914e-01, 9.2517e-01, 6.0098e-02, 4.6138e-01, 3.2282e-01,3.6191e-01, 3.0836e-01, 2.8638e-01],[3.8517e-01, 7.4692e-01, 8.9863e-01, 2.7790e-02, 3.9417e-01,9.2557e-01, 9.2542e-01, 7.1499e-01],[8.0929e-01, 8.2430e-01, 7.7641e-01, 4.4017e-01, 9.4351e-01,8.4430e-01, 3.9162e-01, 4.7323e-01],[4.4801e-02, 1.0588e-01, 2.5283e-01, 2.9120e-01, 8.0959e-01,6.7210e-01, 6.3844e-01, 2.8742e-01],[7.6291e-01, 7.9657e-01, 3.8156e-01, 8.2935e-01, 2.1237e-01,6.5650e-01, 7.8452e-01, 2.8097e-01],[2.0586e-01, 7.0199e-01, 5.1598e-01, 1.3107e-01, 7.8793e-01,1.1133e-01, 4.1328e-01, 1.5066e-01],[2.1346e-01, 4.1860e-01, 2.8186e-01, 6.9559e-03, 3.1852e-01,7.0937e-01, 8.8809e-01, 7.5510e-01],[9.1850e-01, 6.2456e-01, 9.4854e-01, 2.2026e-01, 8.4640e-01,4.0601e-02, 7.9473e-01, 8.2286e-01]]],[[[2.8326e-01, 9.0059e-01, 9.3148e-01, 4.2370e-01, 2.5814e-01,6.6909e-01, 1.0928e-02, 3.9296e-01],[5.1192e-01, 7.1407e-01, 8.8236e-01, 3.7678e-01, 2.2305e-01,3.1705e-01, 6.3382e-01, 7.9083e-01],[8.0426e-01, 5.3209e-01, 2.9103e-01, 1.0520e-02, 6.4828e-01,7.5650e-01, 4.3391e-01, 1.9701e-01],[6.4033e-01, 9.4359e-01, 2.6629e-01, 5.5410e-01, 8.4910e-01,7.3342e-01, 1.4064e-01, 8.7489e-01],[1.7254e-01, 9.6152e-01, 3.8131e-01, 3.8041e-01, 6.3002e-01,7.7604e-01, 2.7887e-01, 6.7200e-01],[2.0756e-01, 7.8653e-01, 4.6171e-01, 4.1734e-01, 5.7438e-01,3.6887e-01, 2.0821e-01, 9.6894e-01],[7.8206e-01, 3.9417e-01, 1.6260e-01, 7.2534e-01, 7.5993e-02,9.3412e-01, 7.7624e-02, 9.3928e-01],[9.7513e-02, 6.1370e-01, 5.7725e-01, 3.4250e-01, 1.1776e-01,5.8991e-01, 3.6010e-01, 1.5810e-01],[9.6534e-03, 3.0747e-01, 5.6363e-01, 2.5881e-01, 3.7878e-01,4.2585e-01, 4.9041e-01, 7.6013e-01],[4.1924e-01, 1.4514e-01, 6.4527e-01, 9.7834e-01, 6.0451e-01,7.6843e-01, 4.1792e-01, 8.4611e-01]],[[2.4590e-01, 3.4102e-01, 6.0761e-01, 3.9460e-01, 4.5805e-01,7.6451e-01, 2.3557e-03, 5.7520e-01],[2.5920e-01, 9.7934e-01, 3.2950e-01, 7.1681e-01, 2.3382e-01,1.1517e-01, 6.4881e-01, 9.3044e-01],[5.1903e-03, 4.7432e-01, 7.3803e-01, 8.9230e-03, 6.6601e-01,6.7898e-02, 5.2286e-01, 9.1362e-01],[5.5971e-01, 7.1264e-01, 5.3499e-01, 2.8207e-02, 6.8861e-01,5.3159e-01, 2.0791e-01, 3.0657e-01],[4.5751e-01, 7.7627e-01, 4.8192e-01, 1.3568e-01, 2.0047e-01,4.8248e-02, 4.4249e-01, 6.4919e-01],[4.0007e-01, 6.7373e-01, 8.6021e-01, 3.7193e-01, 3.9114e-01,6.1232e-01, 3.7100e-01, 8.6428e-01],[3.8925e-01, 5.3274e-01, 2.7094e-01, 4.5749e-01, 4.0679e-01,4.0885e-01, 8.1395e-01, 9.3831e-01],[8.5813e-03, 4.6552e-01, 4.2767e-01, 3.5360e-01, 2.9415e-01,9.4150e-01, 6.7335e-01, 4.2026e-02],[6.9338e-01, 5.0140e-01, 7.2334e-01, 3.3677e-01, 7.4549e-01,6.3400e-01, 8.9057e-01, 7.8879e-01],[8.0550e-01, 2.5435e-01, 9.1497e-01, 9.2267e-01, 7.1124e-01,7.9191e-01, 6.8408e-01, 6.8683e-01]],[[5.0144e-02, 7.6259e-01, 6.7326e-01, 9.8079e-01, 1.1124e-01,4.2291e-01, 1.8365e-02, 4.4412e-01],[5.4025e-01, 1.1574e-01, 6.8358e-01, 1.4154e-01, 7.2759e-01,3.1403e-01, 7.0689e-01, 1.6075e-02],[3.3388e-01, 7.9689e-01, 1.0852e-02, 9.4362e-01, 7.6169e-01,8.1700e-01, 4.6899e-01, 3.6307e-01],[1.8781e-01, 6.3930e-01, 6.3530e-02, 2.2288e-01, 5.0376e-01,5.7084e-01, 6.6219e-01, 6.0037e-01],[9.1527e-01, 8.0093e-01, 1.0186e-01, 4.6437e-01, 3.7368e-01,9.9534e-01, 5.6913e-01, 5.1303e-01],[5.9391e-01, 6.7338e-01, 9.4407e-01, 5.5762e-01, 5.8258e-01,1.8335e-02, 4.0466e-01, 1.5728e-01],[5.5420e-02, 8.7254e-01, 4.2972e-01, 7.3742e-01, 4.0287e-01,9.8190e-01, 2.8029e-01, 4.3533e-01],[3.2755e-01, 6.7667e-01, 5.8706e-01, 2.0986e-01, 9.5659e-01,7.9053e-01, 7.8864e-01, 9.1482e-02],[5.7617e-01, 7.2545e-02, 9.7183e-01, 6.0007e-01, 6.8718e-01,9.3688e-01, 7.3142e-01, 3.5678e-01],[7.1092e-01, 9.9054e-01, 6.8759e-01, 9.4545e-04, 7.7356e-01,3.8864e-01, 3.4851e-01, 7.0661e-01]],[[8.3643e-01, 5.9542e-01, 2.8547e-01, 4.0909e-01, 4.0864e-01,6.4102e-01, 6.2927e-01, 7.0807e-01],[2.2826e-01, 3.7989e-01, 4.4519e-01, 9.7904e-01, 2.2382e-01,5.0949e-01, 6.7909e-01, 4.7000e-01],[6.3309e-01, 5.1963e-01, 3.8026e-01, 6.9920e-01, 3.8465e-01,2.5132e-01, 4.9886e-01, 4.6673e-01],[9.5898e-01, 8.0877e-01, 6.4463e-01, 7.9780e-01, 7.6710e-01,1.4926e-01, 8.9849e-01, 4.8631e-01],[7.8407e-01, 1.0189e-01, 9.9365e-01, 9.5311e-01, 4.6489e-01,6.7042e-01, 1.6722e-01, 7.3440e-01],[5.4366e-01, 4.0804e-01, 2.1323e-01, 1.5707e-01, 3.4207e-01,2.5938e-01, 6.3546e-01, 7.6161e-01],[8.2502e-01, 6.5296e-01, 5.5894e-01, 6.8899e-01, 7.9576e-01,2.8821e-01, 5.0587e-01, 7.1531e-01],[7.5482e-02, 7.7817e-01, 8.5415e-01, 8.1673e-01, 7.6846e-01,6.3890e-01, 3.5124e-01, 9.1766e-01],[6.8266e-01, 8.7167e-01, 1.1057e-01, 5.7511e-01, 1.4933e-01,1.3559e-01, 1.2099e-01, 5.2032e-01],[7.0112e-01, 1.2467e-01, 3.8753e-01, 8.5428e-01, 2.8684e-01,6.2195e-01, 6.6607e-01, 1.9613e-01]]]])2.rotary_emd
past_key_value 这个参数之前分析过,这里直接置为 None 不再额外操作。rotary_emd 在代码中是通过 InternLMRotaryEmbedding 类初始化的:

这里我们也仿造源码中的初始化方式,其中 max_position_embeddings = 4069,这里再啰嗦一下,4069 就是 position 里对应的 max m 即最大位置,kv_seq_len 这里为了方便展示选取了 10。
# 补齐 past_key_valuekv_seq_len = key_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value[0].shape[-2]max_position_embeddings = 4069rotary_emb = InternLMRotaryEmbedding(head_dim, max_position_embeddings=max_position_embeddings)cos, sin = rotary_emb(value_states, seq_len=kv_seq_len)
这里传入的 value_states 经过上面的分析,rotary_emb 只使用了其 device 和 dtype,然后得到对应 m x d 的 cos、sin 矩阵,由于是将 2 个 inv_freq concat 拼接而成,所以前后是一样的:
◆ Cos

◆ Sin

3.apply_rotray_pos_emd
这里把 rotate_half 函数切换为 rotate_half_v2:
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]q_embed = (q * cos) + (rotate_half_v2(q) * sin)k_embed = (k * cos) + (rotate_half_v2(k) * sin)return q_embed, k_embed截止目前 q、k、cos、sin 都已经得到,只需要得到 position_ids 即可:
position_ids = torch.tensor(list(range(0, kv_seq_len))).unsqueeze(0).repeat(batch_size, 1)
q, k = query_states, key_states
q_embed, k_embed = apply_rotary_pos_emb(q, k, cos, sin, position_ids)其中 position_ids 需要进行 repeat 操作才能满足当前 bsz:
tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])最后得到的 q_emded、k_emded 维度为: torch.Size([2, 4, 10, 8]),对应前面的信息:
batch_size = 2query_length = 10num_heads = 4head_dim = 8即 [bsz, num_heads, query_length, head_dim]。
五.总结
国庆前前后后大概花了一周,从理论到实践,从复数、旋转,正交到最后的对位相乘,对 RoPE 旋转编码有了一定认识,还是感慨大佬的理论和实践能力,能够将数学真正应用到实践中。继续努力学习 ing ... 后续有机会把 MLP 这些也捣鼓捣鼓。
◆ 后记
源码中还多次用到了 resister_buffer 函数:
self.register_buffer("inv_freq", inv_freq, persistent=False)register_buffer 是 PyTorch 中的一个函数。在 PyTorch 中,这个函数用于将 CPU 中的内存块注册为 PyTorch 中的 Buffer,用于在 GPU 或其他设备上存储数据。persistent 参数决定了这个 Buffer 是否会在所有新的向前和向后传递中保留其值。
persistent == True
如果 persistent 参数被设置为 True,那么 Buffer 的内容将不会被梯度计算影响,也不会因为在计算新的前向传递时清除旧的 Buffer 内容。这意味着该 Buffer 会在每次新的前向或后向传递时都保持其值。
persistent == False
如果 persistent 参数 = False,那么这个 Buffer 仅在当前训练迭代中存在,在开始新的迭代或者优化器更新后会被清空。换句话说,persistent 参数 = False 意味着这个 Buffer 的内容不会持久存在,而是会在每次新的前向或后向传递时被重新计算和更新。
这里参数置为 False 我想着是不是因为每一个 batch 的样本 seq_len 不一致,所以需要每次重新计算,所以没有进行持久化。其次 register_buffer 就像是 map 构造了 kv 对的缓存,供 RoPE 在当前计算中使用。