Contextual Transformer Networks for Visual Recognition
- 1. 摘要
- 2. 目的
- 3. 网络设计
代码地址
1. 摘要
Transformer with self-attention has led to the revolutionizing of natural language processing field, and recently inspires the emergence of Transformer-style architecture design with competitive results in numerous computer vision tasks. Nevertheless, most of existing designs directly employ self-attention over a 2D feature map to obtain the attention matrix based on pairs of isolated queries and keys at each spatial location, but leave the rich contexts among neighbor keys under-exploited. In this work, we design a novel Transformer-style module, i.e., Contextual Transformer (CoT) block, for visual recognition. Such design fully capitalizes on the contextual information among input keys to guide the learning of dynamic attention matrix and thus strengthens the capacity of visual representation. Technically, CoT block first contextually encodes input keys via a 3 3 convolution, leading to a static contextual representation of inputs. We further concatenate the encoded keys with input queries to learn the dynamic multi-head attention matrix through two consecutive 1 1 convolutions. The learnt attention matrix is multiplied by input values to achieve the dynamic contextual representation of inputs. The fusion of the static and dynamic contextual representations are finally taken as outputs. Our CoT block is appealing in the view that it can readily replace each 3 3 convolution in ResNet architectures, yielding a Transformer-style backbone named as Contextual Transformer Networks (CoTNet). Through extensive experiments over a wide range of applications (e.g., image recognition, object detection, instance segmentation, and semantic segmentation), we validate the superiority of CoTNet as a stronger backbone. Source code is available at https://github.com/JDAI-CV/CoTNet.
具有自注意力机制的 Transformer 已经引发了自然语言处理领域的革命,最近还激发了 Transformer 风格的架构设计的出现,在众多计算机视觉任务中取得了具有竞争力的结果。然而,现有的方式大多直接利用二维特征图上的自注意力来获取每个空间位置上的独立 q 和 k 对的注意力矩阵,而忽略了相邻 k 之间的丰富上下文信息。在本工作中,我们设计了一种新型的 Transformer-style 模块,即 Contextual Transformer (CoT) block,用于视觉识别。这种设计充分利用了输入 k 之间的上下文信息来指导 dynamic attention matrix 的学习,从而增强了视觉表达能力。从技术上讲,CoT 块首先通过一个 3 × 3 卷积具有上下文性地将输入的 k 进行编码,得到输入的 static contextual representation。我们进一步将编码的 k 与输入 q 连接起来,通过两个连续的 1 × 1 卷积来学习 dynamic multi-head attention matrix。将学习到的注意矩阵与输入的 v 相乘,实现输入的 dynamic contextual representation。最后将 static and dynamic contextual representations 的融合作为输出。我们的 CoT 块非常杰出,因为它可以很容易地替换 ResNet 体系结构中的每一个 3 × 3 卷积,产生一个 Transformer 风格的主干,称为 Contextual Transformer Networks (CoTNet)。通过各种应用(如图像识别、目标检测、实例分割和语义分割)的广泛实验,我们验证了 CoTNet 作为一个更强的骨干的优势。
2. 目的
Is there an elegant way to enhance Transformer-style architecture by exploiting the richness of context among input keys over 2D feature map?
出发点是同时捕捉输入 k 之间的两种 spatial contexts:the static context via 3 × 3 convolution and the dynamic context based on contextualized self-attention。

这种设计将 k 间的 context mining 和二维特征图上的 self-attention learning 统一结合在一个体系结构中,从而避免为了 context mining 引入额外的分支。
从技术上讲,在 CoT 块中,我们首先通过对 3 × 3 网格中所有相邻的 k 执行 3 × 3 卷积来将 k 的 representation 上下文化。上下文化的 k 特征可以被视为输入的 static representation,它反映了本地邻居之间的 static context。然后,我们将上下文化的 k 特征和输入的 q 串联在一起并连续通过两个 1 × 1 卷积,目的是生成 attention matrix。这个过程在 static context 的引导下,自然地利用了每个 q 和所有 k 之间的相互关系进行 self-attention learning。利用学习到的 attention matrix 对所有输入 v 进行聚合,从而实现输入的 dynamic contextual representation,从而描述 dynamic context。我们将 static and dynamic contextual representation 结合起来作为 CoT 块的最终输出。
3. 网络设计
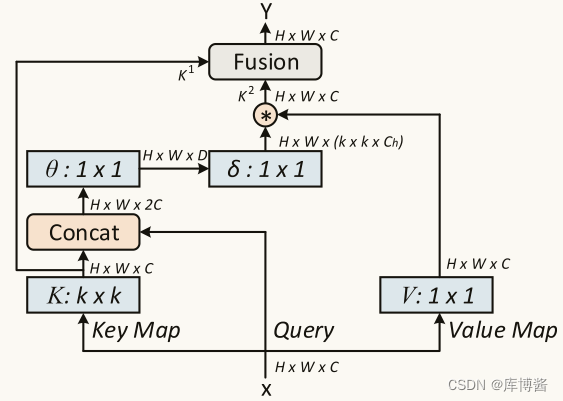
假设我们有二维的特征图 X。k,q,v 分别定义为 K = X K = X K=X, Q = X Q = X Q=X, V = X W v V = XW_v V=XWv。与典型的自注意力机制中通过 1 × 1 卷积对每个 k 进行编码不同,CoT 块首先在 k × k 网格中对所有相邻 k 在空间上进行 k × k group convolution,以便将每个 k 上下文化。学习到的具有上下文关系的 K 1 K^1 K1 自然反映了本地临近 k 之间的 static contextual information。我们将 K 1 K^1 K1 作为输入 X 的 static context representation。之后,我们将 K 1 K^1 K1 和 Q 串联在一起,然后通过两个连续的 1 × 1 卷积( W θ W_{\theta} Wθ 使用 RELU 激活函数, W ζ W_{\zeta} Wζ 不使用激活函数)获得 attention matrix A:
A = [ K 1 , Q ] W θ W ζ A=[K^1,Q]W_{\theta}W_{\zeta} A=[K1,Q]WθWζ
换句话说,对于每个 head,A 在每个空间位置的 local attention matrix 是基于 query feature 和 contextualized key feature 学习的,而不是孤立的 query-key pairs。这种方法通过增加 mined static context K 1 K^1 K1 的指导,增强了自注意力学习。接下来,根据 contextualized attention matrix A,我们将典型的自注意力机制中的所有 V 进行聚合,计算出所关注的特征图 K 2 K^2 K2:
K 2 = V ∗ A K^2=V*A K2=V∗A
考虑到 K 2 K^2 K2 捕获了输入之间的 dynamic feature interactions,我们将 K 2 K^2 K2 称为输入的 dynamic contextual representation。因此,我们的CoT 块的最终输出由 K 1 K^1 K1 和 K 2 K^2 K2 通过 attention mechanism 得到。特别是,我们首先将两个 contexts 直接融合,通过 global average pooling 获得通道维度的全局特征,进而引导跨通道 soft attention 自适应聚合两个 contexts 作为最终输出。