-
我们用 Spring Boot 里面默认集成的 fasterxml.jackson 加以说明,这看似和 JPA 没什么关系,但是一旦我们和 @Entity 一起使用的时候,就会遇到一些问题,特别是新手同学,我们这一课时详细介绍一下用法。先来跟着我了解一下 Jackson 的基本语法。
Jackson 基本语法
我们先看一下我们项目里面的依赖。
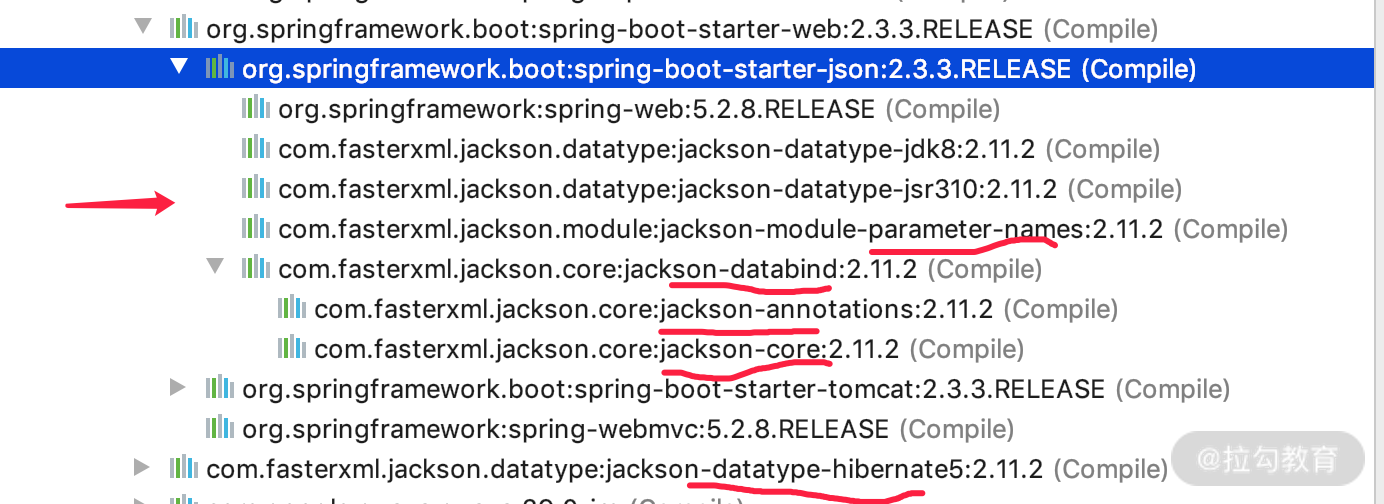
从中可以看到,当我们用 spring boot starter 的时候就会默认加载 fasterxml 相关的 jar 包模块,包括核心模块以及 jackson 提供的一些扩展 jar 包,下面详细介绍。
核心模块有三个
- jackson-core:核心包,提供基于“流模式”解析的相关 API,它包括 JsonPaser 和 JsonGenerator。Jackson 内部实现正是通过高性能的流模式 API 的 JsonGenerator 和 JsonParser 来生成和解析 json。
- jackson-annotations:注解包,提供标准注解功能,这是我们必须要掌握的基础语法。
- jackson-databind:数据绑定包,提供基于“对象绑定”解析的相关 API( ObjectMapper ) 和“树模型”解析的相关 API(JsonNode);基于“对象绑定”解析的 API 和“树模型”解析的 API 依赖基于“流模式”解析的 API。如下图中一些标准的类型转换:
jackson 提供了一些扩展 jar
- jackson-module-parameter-names:对原来的 jackson 进行了扩展,支持了构造方法和方法基本的参数支持。
- jackson-datatype:是对字段类型的支持做的一些扩展,包括下述几个部分。
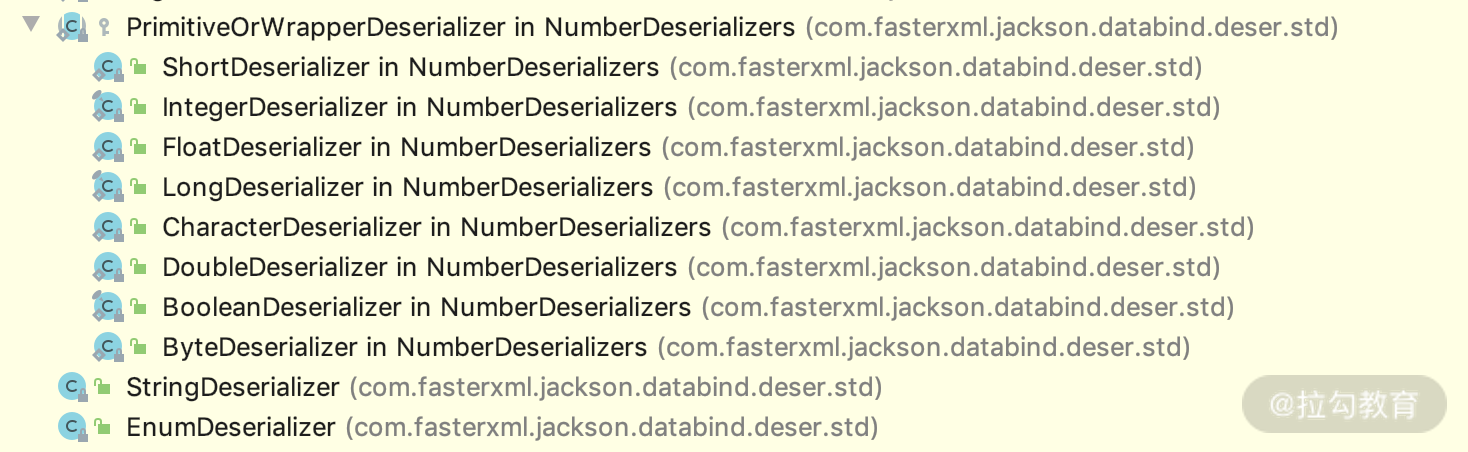
a. jackson-datatype-jdk8:是对 jdk8 语法里面的一些 Optional、Stream 等一些新的类型做的一些支持,如下图展示的一些类:

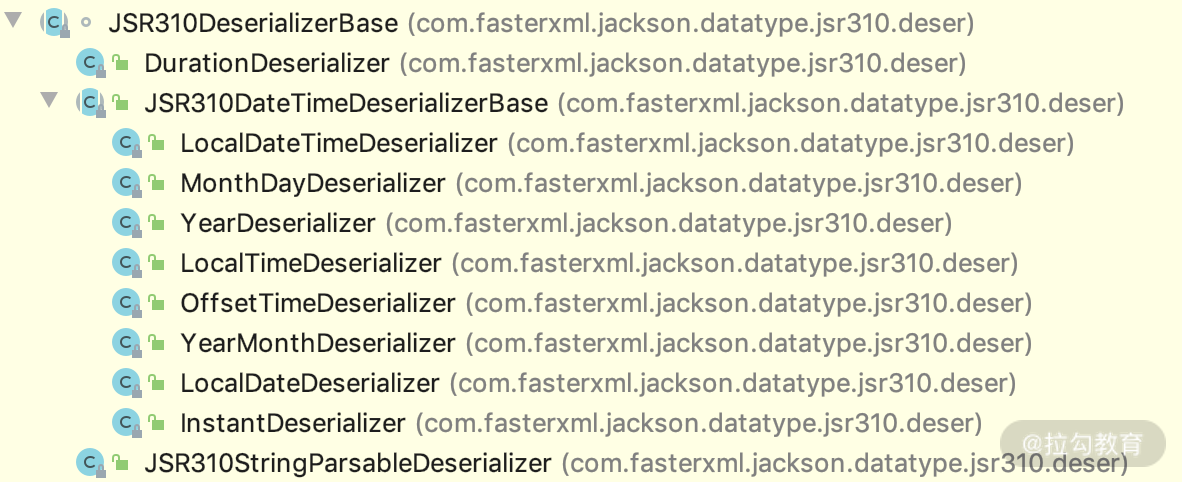
b.jackson-datatype-jsr310:是对 jdk8 中的 JSR310 时间协议做了支持,如 Duration、Instant、LocalDate、Clock 等时间类型的序列化、反序列化,如下图展示的一些类:
c.jackson-datatype-hibernate5:是对Hibernate的里面的一些数据类型的序列化、反序列化,如HibernateProxy 等。
剩下不常见的咱们就不说了,jackson-datatype 其实就是对一些常见的数据类型做序列化、反序列化,省去了我们自己写序列化、反序列化的过程。所以在我们工作中,如果需要自定义序列化的时候,可以参考这些源码。
知道了这些脉络之后,剩下的就是我们要掌握的注解有哪些了,下面我来介绍一下。
常用的一些注解
正如上面所说,我们打开 jackson-annotations,就可以看到有哪些注解了,一目了然,闲着没事的时候就可以到这里面看看,这样你会越来越熟悉。下面我们挑选一些常用的介绍一下。
Jackson 里面常用的注解如下表格所示:
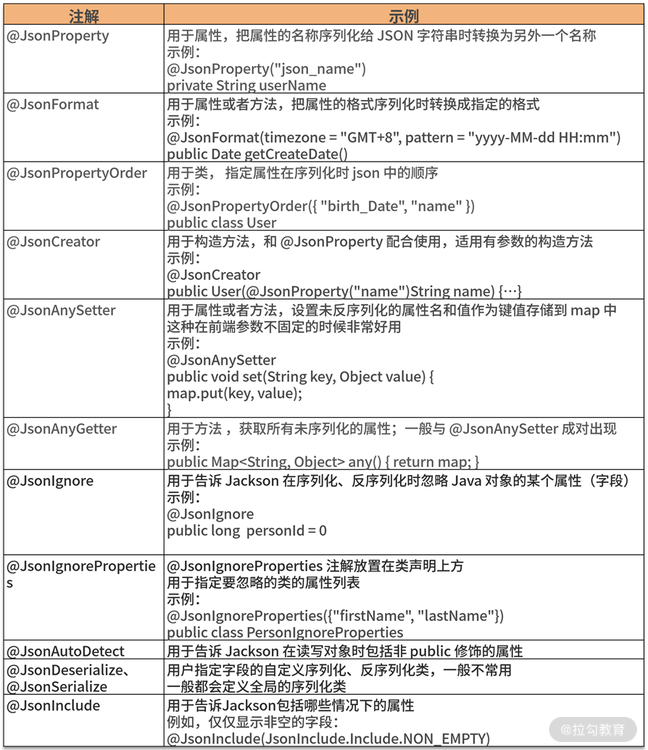
我们看个实例感受一下
接下来我们写个测试用例看一下。
首先,新建一个 UserJson 实体对象,将它转成 Json 对象,如下所示:
复制代码
package com.example.jpa.example1; import com.fasterxml.jackson.annotation.*; import lombok.*; import javax.persistence.*; import java.time.Instant; import java.util.*; @Entity @Data @Builder @AllArgsConstructor @NoArgsConstructor @JsonPropertyOrder({"createDate","email"}) public class UserJson {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;@JsonProperty("my_name")private String name;private Instant createDate;@JsonFormat(timezone ="GMT+8", pattern = "yyyy-MM-dd HH:mm")private Date updateDate;private String email;@JsonIgnoreprivate String sex;@JsonCreatorpublic UserJson(@JsonProperty("email") String email) {System.out.println("其他业务逻辑");this.email = email;}@Transient@JsonAnySetterprivate Map<String,Object> other = new HashMap<>();@JsonAnyGetterpublic Map<String, Object> getOther() {return other;} }然后,我们写一个测试用例,看一下运行结果。
复制代码
package com.example.jpa.example1; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import org.assertj.core.util.Maps; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import org.junit.jupiter.api.TestInstance; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest; import org.springframework.test.annotation.Rollback; import javax.transaction.Transactional; import java.time.Instant; import java.util.Date; @DataJpaTest @TestInstance(TestInstance.Lifecycle.PER_CLASS) public class UserJsonRepositoryTest {@Autowiredprivate UserJsonRepository userJsonRepository;@BeforeAll@Rollback(false)@Transactionalvoid init() {UserJson user = UserJson.builder().name("jackxx").createDate(Instant.now()).updateDate(new Date()).sex("men").email("123456@126.com").build();userJsonRepository.saveAndFlush(user);}/*** 测试用User关联关系操作**/@Test@Rollback(false)public void testUserJson() throws JsonProcessingException {UserJson userJson = userJsonRepository.findById(1L).get();userJson.setOther(Maps.newHashMap("address","shanghai"));ObjectMapper objectMapper = new ObjectMapper(); System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(userJson));} }最后,运行一下可以看到如下结果。
复制代码
{"createDate" : {"epochSecond" : 1600530086,"nano" : 588000000},"email" : "123456@126.com","id" : 1,"updateDate" : "2020-09-19 23:41","my_name" : "jackxx","address" : "shanghai" }这里可以和上面的注解列表对比一下,其中我们看到了 HashMap 被平铺开了。我们通过例子可以很容易想到使用场景是 SpringMvc 的情况下,在 get 请求的时候我们要用到序列化;在 post 请求的时候我们要用到反序列化,将 json 字符串反向转化成实体对象。
那么在 Spring 里面 Jackson 都有哪些应用场景呢?我们来看一下。
Jackson 和 Spring 的关系
我们先看一下 Jackson 在 Spring 中常见的四个应用场景,来了解一下 Spring 在这些情况下的应用,带你详细掌握 Jackson 并知道它的重要性。
应用场景一
在Spring MVC中,我们需要知道Mvc的JSON视图的加载原理。我们看一下源码,mvc 对象的转化类:HttpMessageConvertersAutoConfiguration,里面要利用JacksonHttpMessageConvertersConfiguration,如下所示:
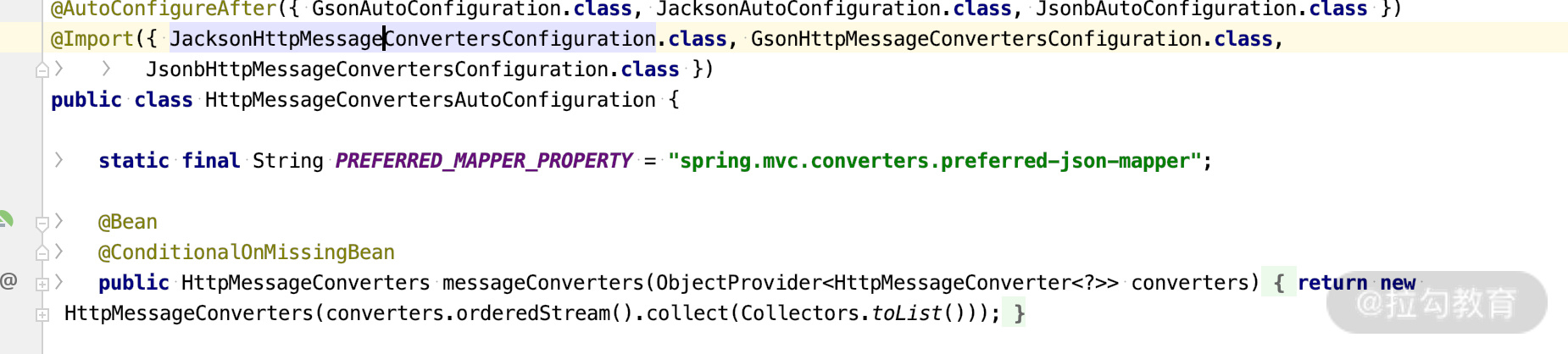
而里面的MappingJackson2HttpMessageConverter 正是采用 fasterxml.jackson 进行转化的,看下面的图片。
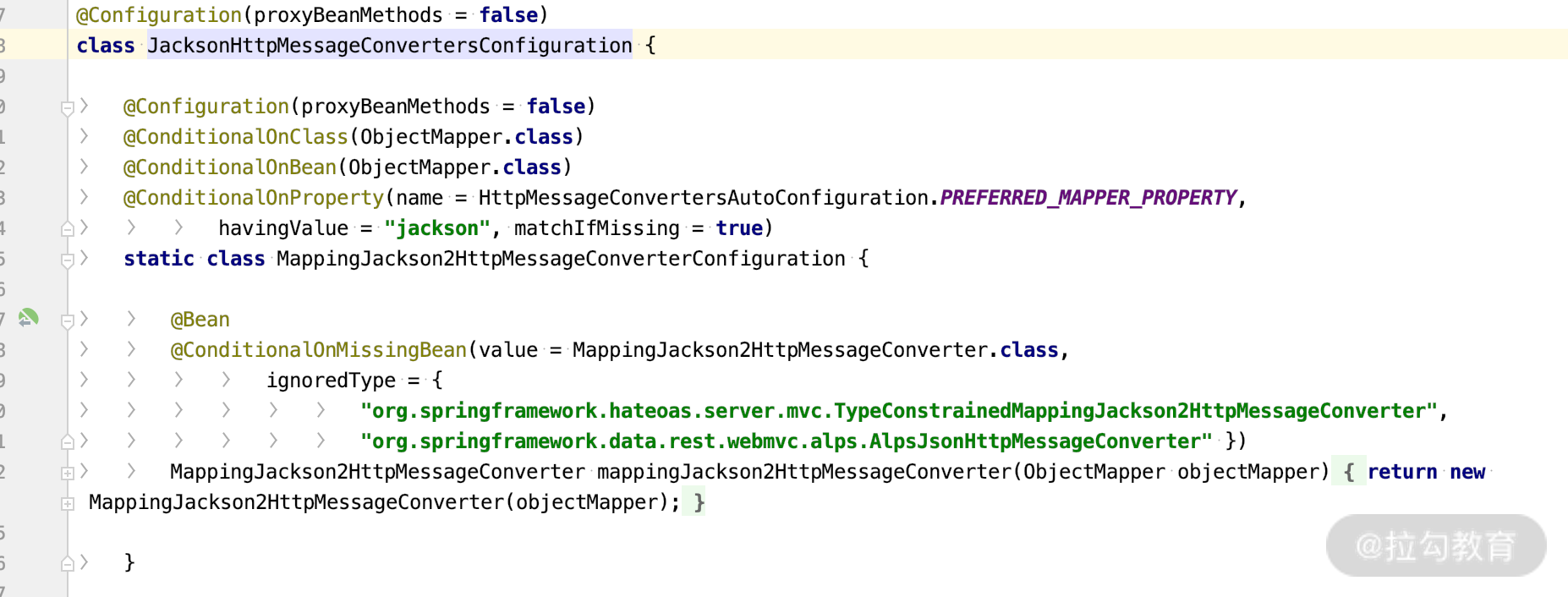
应用场景二
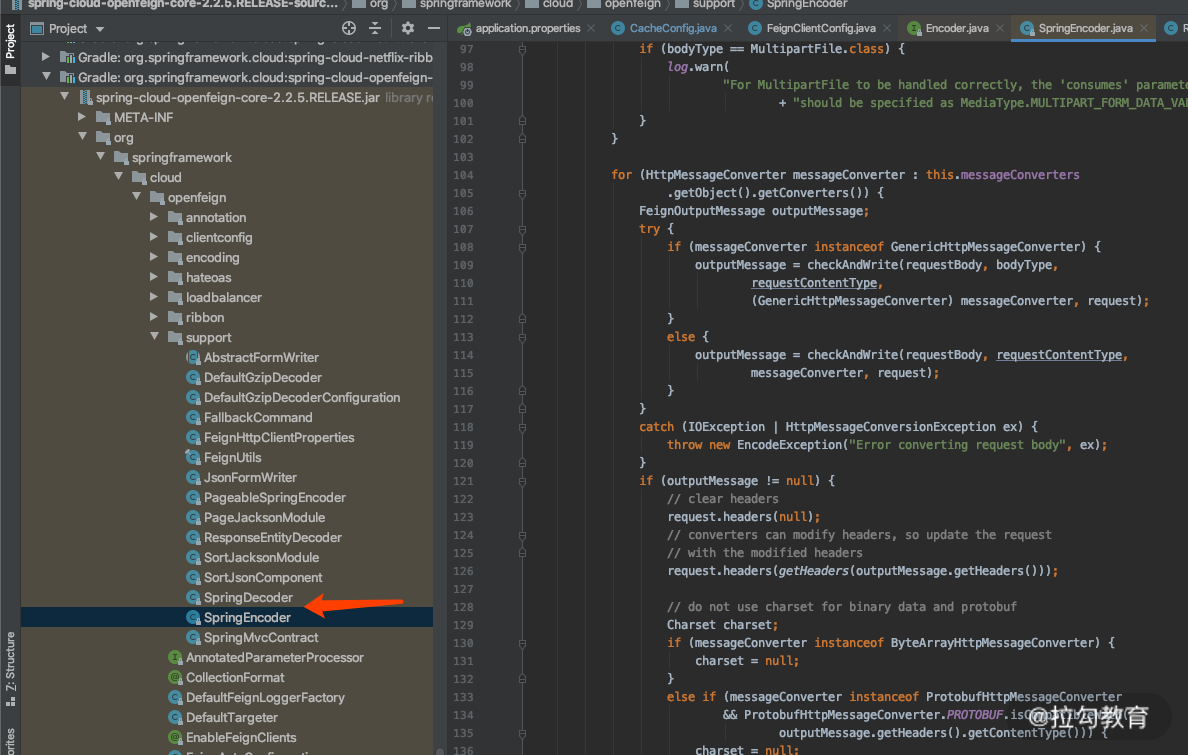
我们在微服务之间相互调用的时候,都会用到 HttpMessageConverter 里面的 JacksonHttpMessageConverter 进行转化。特别是在用 open-feign 里面的 Encode 和 Decode 的时候,我们就可以看到如下应用场景:
应用场景三
redis、cacheable 都会用到 value 的序列化,都离不开 JSON 的序列化,看下面的 redis 里面的关键配置文件。
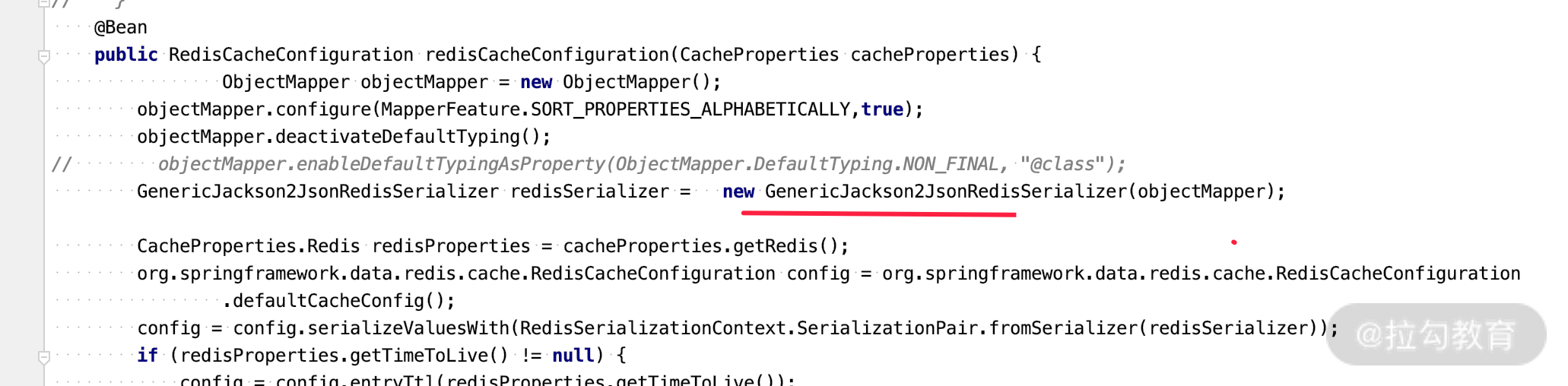
应用场景四
当我们项目之间解耦用到消息队列的时候,可能会基于 JMS消息协议发送消息,其也是基于 JSON 的序列化机制来继续converter的,它在用JmsTemplate 的时候也会遇到同样情况,我们看一下 JMS 里面相关代码。
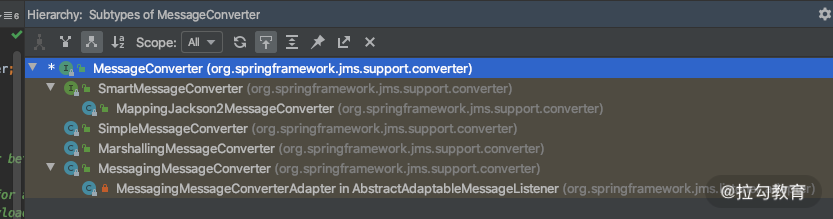
综上四个场景所述,我们是经常和 Entity 打交道的,而 @Entity 又要在各种场景转化成 JSONString,所以 Jackson 的原理我们还是要掌握一些的,下面来分析几个比较重要的。
Jackson 原理分析
Jackson 的可见性原理分析
前面我们看到了注解@JsonAutoDetect JsonAutoDetect.Visibility 类包含与 Java 中的可见性级别匹配的常量,表示 ANY、DEFAULT、NON_PRIVATE、NONE、PROTECTED_AND_PRIVATE和PUBLIC_ONLY。
那么我们打开这个类,看一下源码:
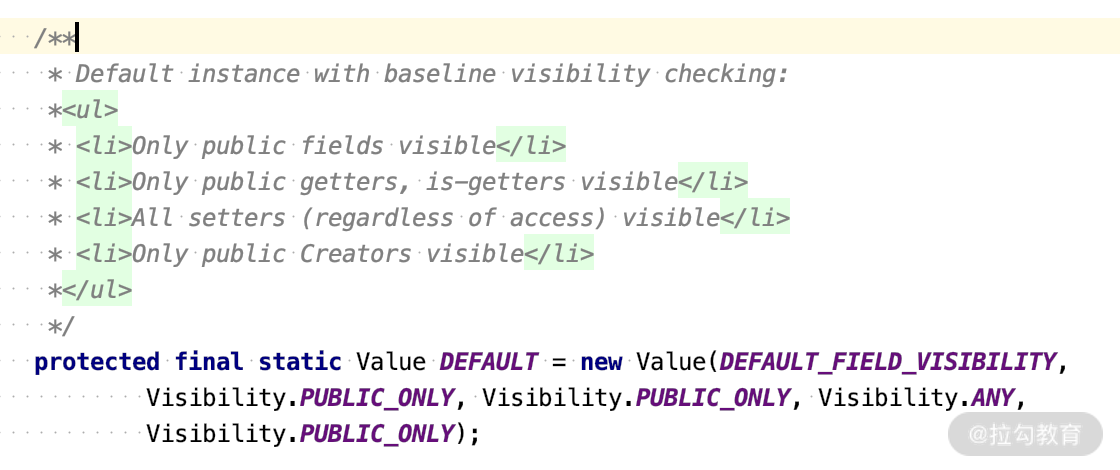
这里面的代码并不复杂,通过JsonAutoDetect 我们可以看到,Jackson 默认不是所有的属性都可以被序列化和反序列化。默认的属性可视化的规则如下:
- 若该属性修饰符是 public,该属性可序列化和反序列化。
- 若属性的修饰符不是 public,但是它的 getter 方法和 setter 方法是 public,该属性可序列化和反序列化。因为 getter 方法用于序列化,而 setter 方法用于反序列化。
- 若属性只有 public 的 setter 方法,而无 public 的 getter 方法,该属性只能用于反序列化。
所以我们可以通过私有字段的 public get 和 public set 方法控制是否可以序列化。这里可以和我们前面讲到的“JPA 实体里面的注解生效方式”做一下对比,也可以通过直接更改 ObjectMapper 设置可视化策略,如下所示:
复制代码
ObjectMapper mapper = new ObjectMapper();// PropertyAccessor 支持的类型有 ALL,CREATOR,FIELD,GETTER,IS_GETTER,NONE,SETTER// Visibility 支持的类型有 ANY,DEFAULT,NON_PRIVATE,NONE,PROTECTED_AND_PUBLIC,PUBLIC_ONLYmapper.setVisibility(PropertyAccessor.FIELD, JsonAutoDetect.Visibility.ANY);这样,就可以直接看到所有字段了,包括私有字段。接着我们说一下反序列化相关方法。
反序列化最重要的方法
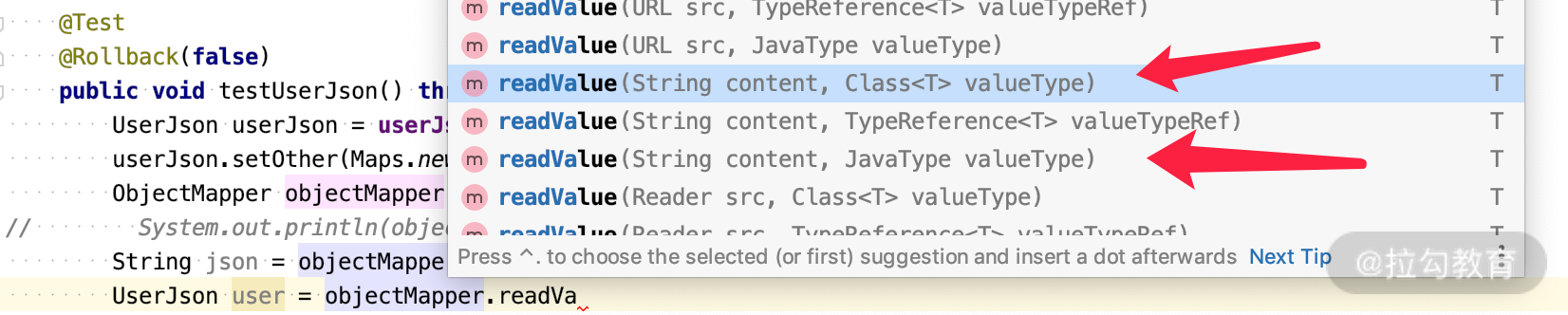
我们在做反序列化的时候要用到的三个重要方法如下所示。
复制代码
public <T> T readValue(String content, Class<T> valueType) public <T> T readValue(String content, TypeReference<T> valueTypeRef) public <T> T readValue(String content, JavaType valueType)可以看出,反序列化的时候要知道 java 的 Type 是很重要的,如下:
复制代码
String json = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(userJson); //单个对象的写法: UserJson user = objectMapper.readValue(json,UserJson.class); //返回List的返回结果的写法:List<User> personList2 = mapper.readValue(jsonListString, new TypeReference<List<User>>(){});我们也可以根据 java 的反射,即万能的 JavaType 进行反序列化和转化,如下:

你也可以看一下 Jackson2HttpMessageConverter 里面的用法。
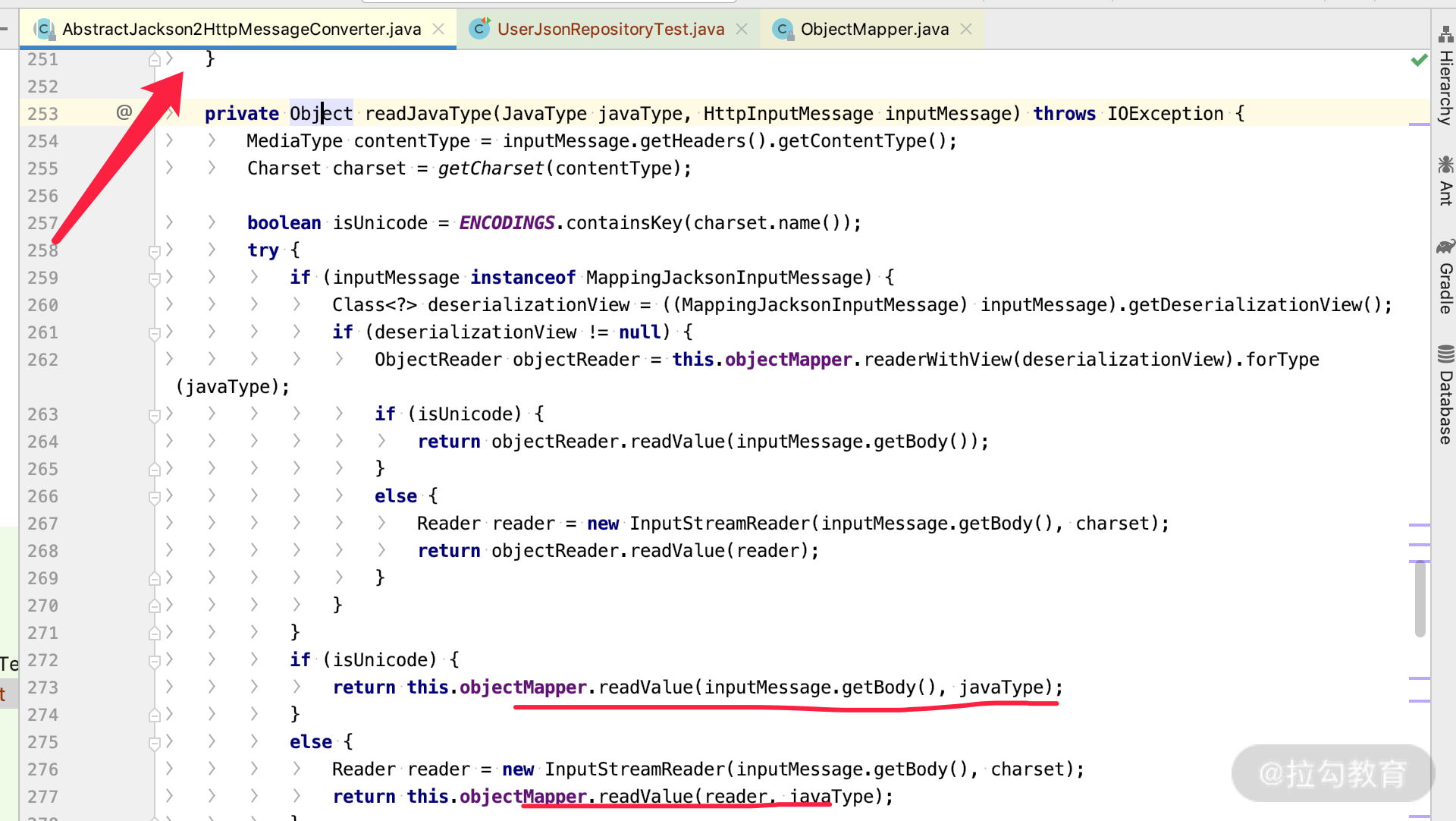
这个时候你应该很好奇,readValue 里面是如何判断 java 类型的呢?我们看下 ObjectMapper 的源码里面做了如下操作:
复制代码
public <T> T readValue(DataInput src, Class<T> valueType) throws IOException {_assertNotNull("src", src);return (T) _readMapAndClose(_jsonFactory.createParser(src),_typeFactory.constructType(valueType)); }到这里,我们看到 typeFactory 里面的 constructType 可以取到各种 type,那么点击进去看看。
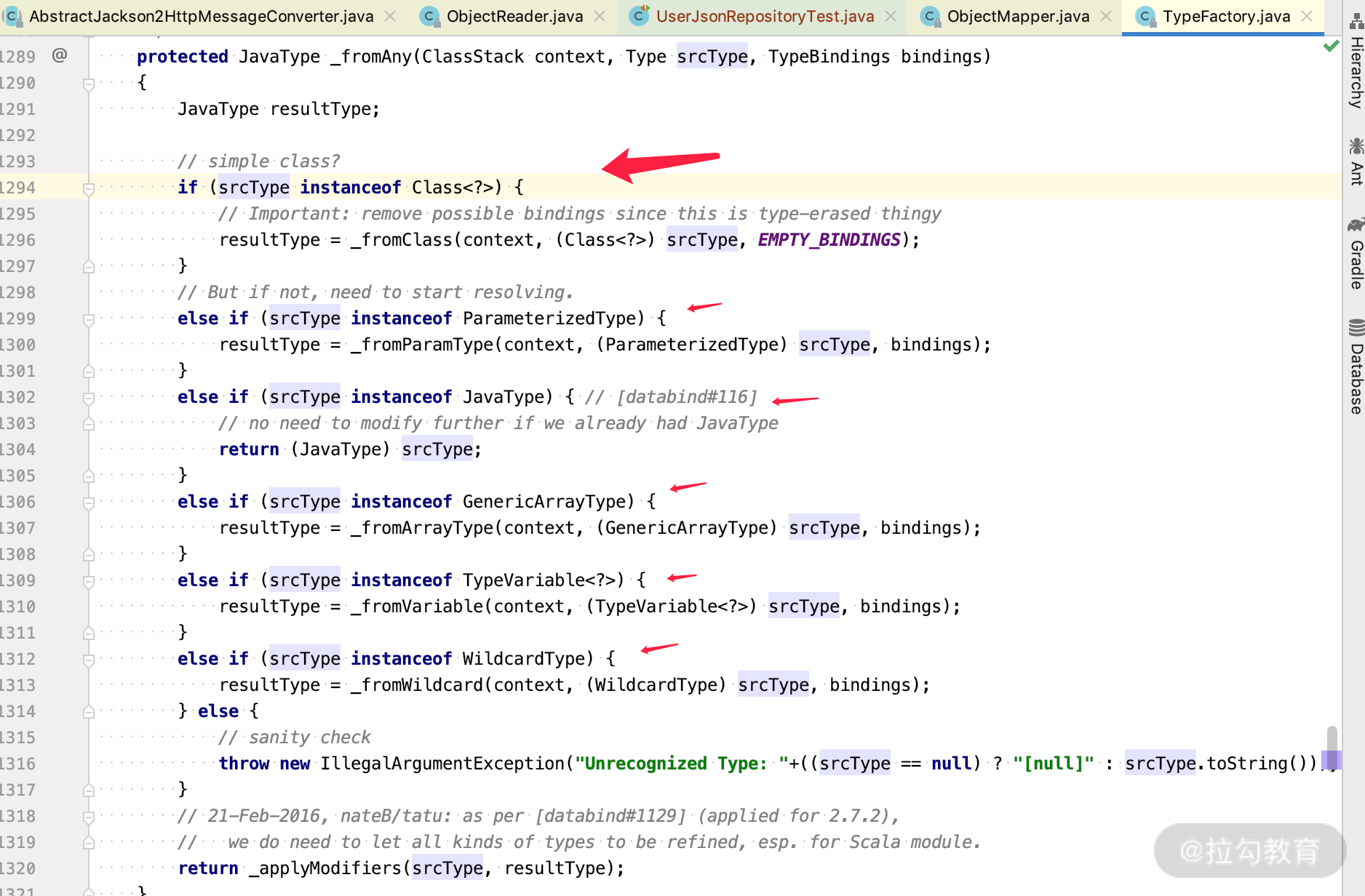
可以看到里面处理各种 java 类型和泛型的情况,当我们自己写反射代码的时候可以参考这一段,或者直接调用。此外,ObjectMapper 里面还一个重要的概念就是 Moduel,我们来看下。
Moduel 的加载机制
ObejctMapper 里面可以扩展很多 datatype,而不同的 datatype 封装到了不通的 modules 里面,我们可以 register 注册进去不同的 module,从而处理不同的数据类型。
目前 Modules 官方网站提供了很多内容,具体你可以查看这个网址:https://github.com/FasterXML/jackson#third-party-datatype-modules。这里我们重点说一下常用的加载机制。
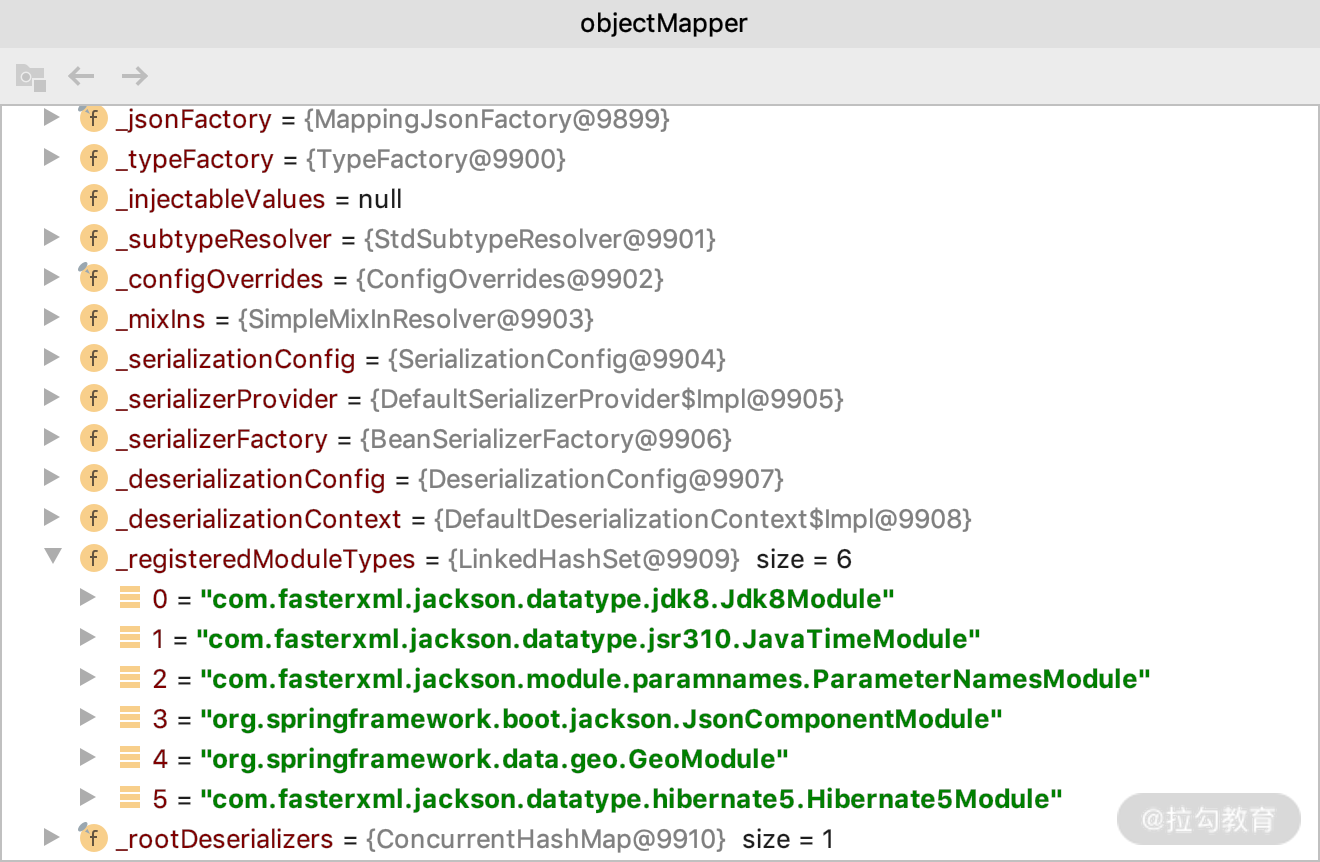
我们通过在代码里面设置一个断点,就可以很清楚地知道常用的 ModuleType 都有哪些,如 Jdk8、jsr310、Hibernate5 等。在MVC 里面默认的 Module 也是图上那些,Hibernate5 是我们自己引入的,具体解决什么问题和如何自定义的呢?我们接着往下看。
Jackson 与 JPA 常见的问题
我们用 JPA 的时候,特别是关联关系的时候,最常见的就是死循环了,你在使用时一定要注意。
死循环问题如何解决
第一种情况:我们在写 ToString 方法,特别是 JPA 的实体的时候,很容易陷入死循环,因为实体之间的关联关系配置是双向的,我们就需要 ToString 的时候把一方排除掉,如下所示:

第二种情况:在转化JSON的时候,双向关联也会死循环。按照我们上面讲的方法,这是时候我们要想到通过 @JsonIgnoreProperties(value={“address”})或者字段上面配置@JsonIgnore,如下:
复制代码
@JsonIgnore private List<UserAddress> address;此外,通过 @JsonBackReference 和 @JsonManagedReference 注解也可以解决死循环。
复制代码
public class UserAddress {@JsonManagedReferenceprivate User user; ....} public class User implements Serializable {@OneToMany(mappedBy = "user",fetch = FetchType.LAZY)@JsonBackReferenceprivate List<UserAddress> address; ...}如上述代码,也可以达到 @JsonIgnore 的效果,具体你可以自己操作一下试试,原理都是一样的,都是利用排除方法。那么接下来我们看下 HibernateModel5 是怎么使用的。
JPA 实体 JSON 序列化的常见报错
我们在实际跑之前讲过的 user 对象,或者是类似带有 lazy 对象关系的时候,经常会遇到下面的错误:
复制代码
No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS) (through reference chain: com.example.jpa.example1.User$HibernateProxy$MdjeSaTz["hibernateLazyInitializer"]) com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS) (through reference chain: com.example.jpa.example1.User$HibernateProxy$MdjeSaTz["hibernateLazyInitializer"])这个时候该怎么办呢?下面介绍几个解决办法,第一个可以引入Hibernate5Module。
常见报错解决方法
解决方法一:引入 Hibernate5Module
代码如下:
复制代码
ObjectMapper objectMapper = new ObjectMapper(); objectMapper.registerModule(new Hibernate5Module()); String json = objectMapper.writeValueAsString(user); System.out.println(json);这样子就不会报错了。
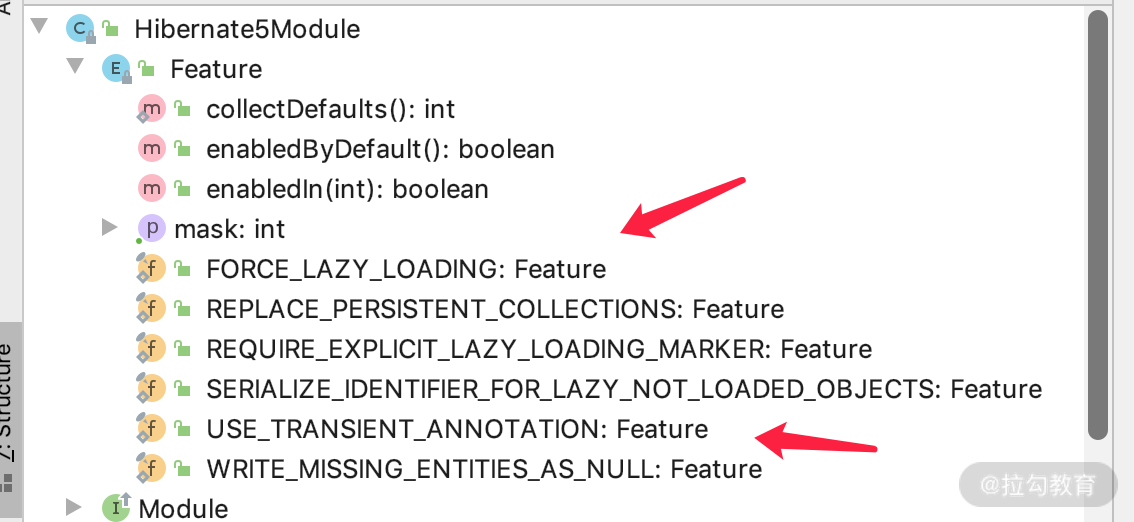
Hibernate5Module 里面还有很多 Feature 配置,例如FORCE_LAZY_LOADING,强制 lazy 里面加载就不会有上面的问题了。但是这个会有性能问题,我不建议使用。
还有 USE_TRANSIENT_ANNOTATION,利用 JPA 的 @Transient 注解配置,这个默认是开启的。所以基本上 feature 默认配置都是 ok 的,不需要我们动手,只要知道这回事就行了。
解决方法二:关闭 SerializationFeature.FAIL_ON_EMPTY_BEANS 的 feature
代码如下:
复制代码
ObjectMapper objectMapper = new ObjectMapper(); //直接关闭SerializationFeature.FAIL_ON_EMPTY_BEANS objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS,false);String json = objectMapper.writeValueAsString(user);System.out.println(json);因为是 lazy,所以 empty 的 bean 的时候不报错也可以。
解决方法三:对象上面排除“hibernateLazyInitializer”“handler”“fieldHandler”等代码如下:
复制代码
@JsonIgnoreProperties(value={"address","hibernateLazyInitializer","handler","fieldHandler"}) public class User implements Serializable {那有没有其他 ObjectMapper 的推荐配置了呢?
ObjectMapper 实战经验推荐配置项
下面是我根据自己实战经验为你推荐的配置项。
复制代码
ObjectMapper objectMapper = new ObjectMapper(); //empty beans不需要报错,没有就是没有了 objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS,false); //遇到不可识别字段的时候不要报错,因为前端传进来的字段不可信,可以不要影响正常业务逻辑 objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES,false); //遇到不可以识别的枚举的时候,为了保证服务的强壮性,建议也不要关心未知的,甚至给个默认的,特别是微服务大家的枚举值随时在变,但是老的服务是不需要跟着一起变的 objectMapper.configure(DeserializationFeature.READ_UNKNOWN_ENUM_VALUES_AS_NULL,true); objectMapper.configure(DeserializationFeature.READ_UNKNOWN_ENUM_VALUES_USING_DEFAULT_VALUE,true);时间类型的最佳实践,如何返回 ISO 格式的标准时间
有的时候我们会发现,默认的 ObjectMapper 里面的 module 提供的时间转化格式可能不能满足我们的要求,可能要进行扩展,老师提供一个自定义 module 返回 ISO 标准时间格式的一个案例,如下:
复制代码
@Test @Rollback(false) public void testUserJson() throws JsonProcessingException {UserJson userJson = userJsonRepository.findById(1L).get();userJson.setOther(Maps.newHashMap("address","shanghai"));//自定义 myInstant解析序列化和反序列化DateTimeFormatter.ISO_ZONED_DATE_TIME这种格式SimpleModule myInstant = new SimpleModule("instant", Version.unknownVersion()).addSerializer(java.time.Instant.class, new JsonSerializer<Instant>() {@Overridepublic void serialize(java.time.Instant instant,JsonGenerator jsonGenerator,SerializerProvider serializerProvider)throws IOException {if (instant == null) {jsonGenerator.writeNull();} else {jsonGenerator.writeObject(instant.toString());}}}).addDeserializer(Instant.class, new JsonDeserializer<Instant>() {@Overridepublic Instant deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException {Instant result = null;String text = jsonParser.getText();if (!StringUtils.isEmpty(text)) {result = ZonedDateTime.parse(text, DateTimeFormatter.ISO_ZONED_DATE_TIME).toInstant();}return result;}});ObjectMapper objectMapper = new ObjectMapper();//注册自定义的moduleobjectMapper.registerModule(myInstant);String json = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(userJson);System.out.println(json); }我们利用上面的UserJson案例,在测试用例里面自定义了myInstant来进行序列化和反序列化Instant这种类型,然后我们通过objectMapper.registerModule(myInstant); 注册进去。那么我们看一下运行结果:
复制代码
{"createDate" : "2020-09-20T02:36:33.308Z","email" : "123456@126.com","id" : 1,"updateDate" : "2020-09-20 10:36","my_name" : "jackxx","address" : "shanghai" }这时你会发现 createDate 的格式发生了变化,这样子的话,任何人看到我们这样的 JSON 结构就不必问我们到底是哪个时区的问题了。
08 | Jackson 注解在实体里面如何应用?常见的死循环问题如何解决?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/158174.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

计算机毕业设计选什么题目好?springboot 美食推荐系统
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…

clickhouse数据库简介,列式存储
clickhouse数据库简介
1、关于列存储
所说的行式存储和列式存储,指的是底层的存储形式,数据在磁盘上的真实存储,至于暴漏在上层的用户的使用是没有区别的,看到的都是一行一行的表格。
idnameuser_id1闪光10266032轨道物流10265…

基于秃鹰优化的BP神经网络(分类应用) - 附代码
基于秃鹰优化的BP神经网络(分类应用) - 附代码 文章目录 基于秃鹰优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.秃鹰优化BP神经网络3.1 BP神经网络参数设置3.2 秃鹰算法应用 4.测试结果:5.M…
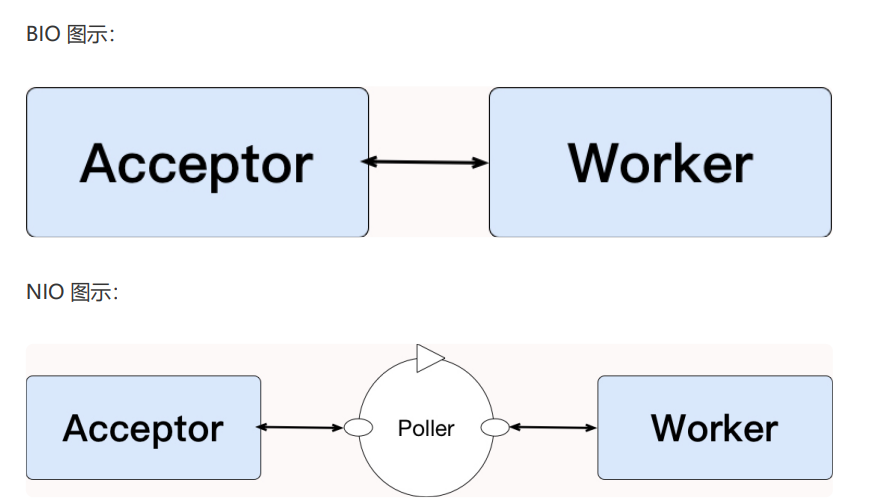
性能优化-中间件tomcat调优
Tomcat作用
主要有三个: 管理Servlet应用的生命周期。Tomcat可以管理和控制Servlet应用程序的启动、停止、暂停和恢复等生命周期过程,确保Servlet应用的稳定运行和有序管理。把客户端请求的url映射到对应的servlet。Tomcat作为一个Web服务器,可以将客户端发送的HTTP请求URL…
DL Homework 3
给定训练集,将每个样本输入给前馈神经网络,得到网络输出为,其在数据集上的结构化风险为 首先简单解释一下这堆话,结构化风险经验风险正则化项,经验风险为,对于函数我们大多数采取的为交叉熵函数,,正则化项为,首先神经网…
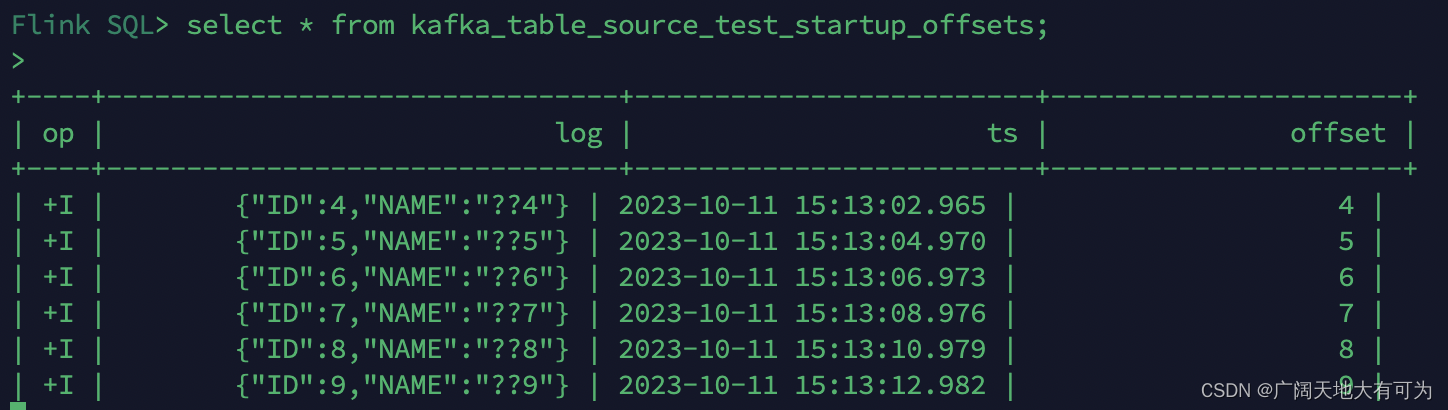
2.1、如何在FlinkSQL中读取写出到Kafka
目录
1、环境设置
方式1:在Maven工程中添加pom依赖
方式2:在 sql-client.sh 中添加 jar包依赖
2、读取Kafka
2.1 创建 kafka表
2.2 读取 kafka消息体(Value)
使用 format json 解析json格式的消息
使用 format csv 解析…
【从0开发】百度BML全功能AI开发平台【实操:以部署情感分析模型为例】
目录 一、全功能AI开发平台介绍二、AI项目落地应用流程(以文本分类为例)2-0、项目开始2-1、项目背景2-2、数据准备介绍2-3、项目数据2-4、建模调参介绍2-5、项目的建模调参2-6、开发部署2-7、项目在公有云的部署 附录:调用api代码总结 一、全…
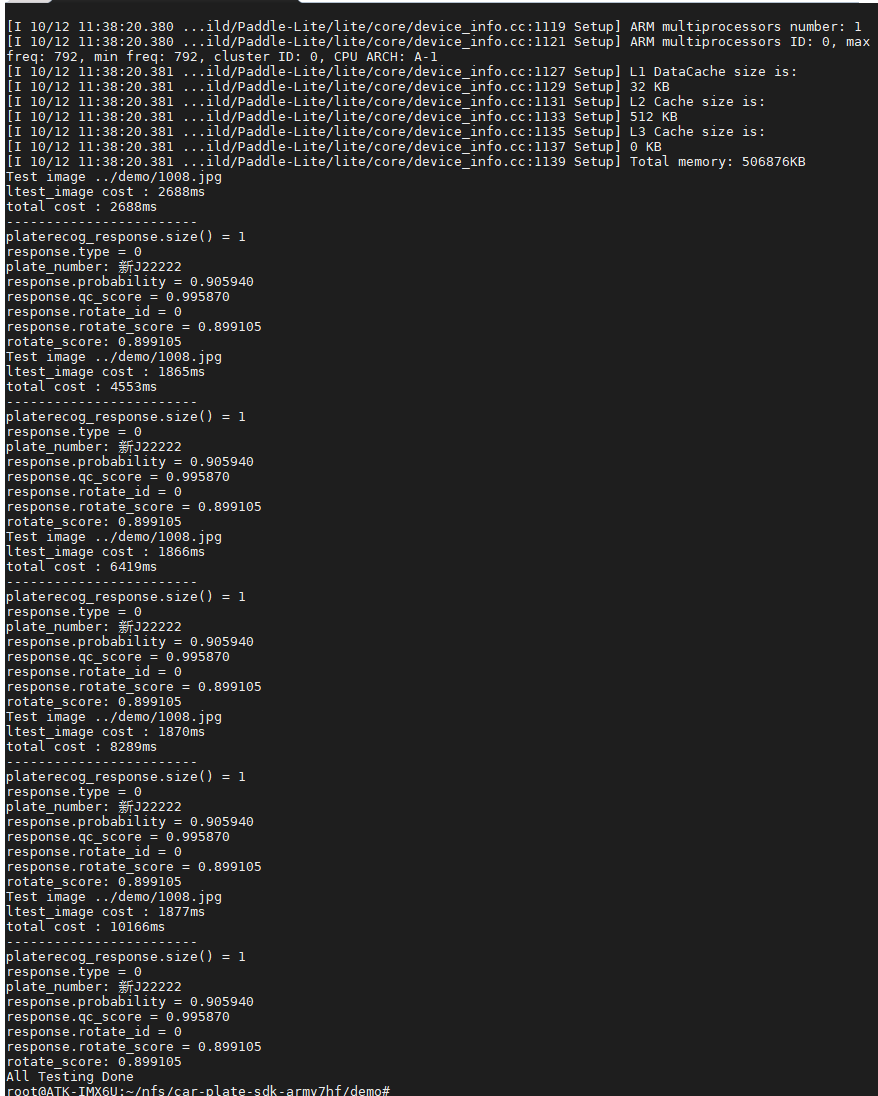
百度车牌识别AI Linux使用方法-armV7交叉编译
1、获取百度ai的sdk
百度智能云-登录 (baidu.com) 里面有两个版本的armV7和armV8架构。v7架构的性能比较低往往需要交叉编译,v8的板子性能往往比较好,可以直接在板子上编译。 解压到ubuntu里面。这里介绍v7架构的。 2、ubuntu环境配置
ubuntu下安装软件…
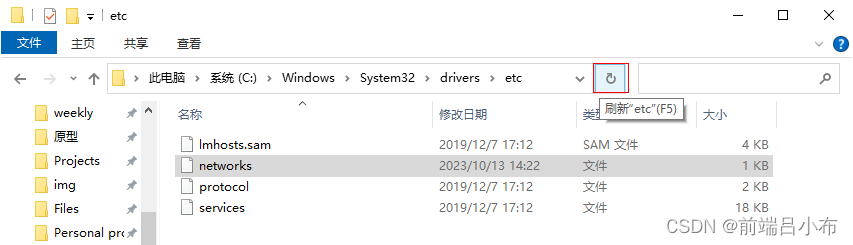
Win10找不到hosts文件的解决方案
正常情况下,Windows10系统的C:\Windows\System32\drivers\etc目录下应该有hosts文件,但偏偏有些电脑没有,哪怕你打开了查看“隐藏的项目”也没见到hosts文件,如下:
解决方案
1、先点击查看,再点击选项&…
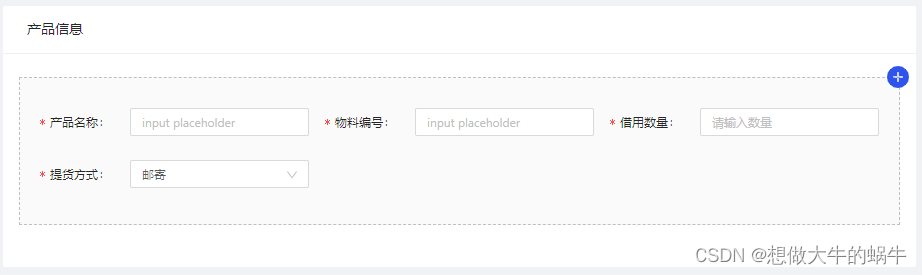
Ant Design Form.List基础用法
使用 Form.List 使用
项目中需要在新增可以多个如图 代码如下
// An highlighted block
<Card title"产品信息" bordered{false}><Form.List name"productList" >{(fields, {add, remove}) > (<>{fields.map((field) > (<Ro…
苹果放出快捷指令专题介绍页面,大大提高了 Mac 使用效率
近日,苹果发布 macOS Sonoma 更新的同时,还上线了“《快捷指令》助你效率倍增”专题页面,其目标是在 Mac 上让好用的 App 更强大。 快捷指令功能可以让设备自动完成常用或繁琐的操作,大大提升 Mac 的效率。
快捷指令能帮你在《邮…
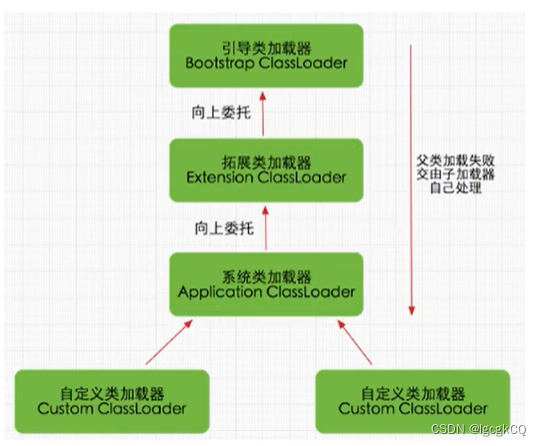
JVM上篇之类加载子系统
目录
类加载子系统
内存结构
类的生命周期
类的加载过程
加载
加载class文件方式
连接
验证
验证阶段
准备
解析
初始化
类加载器
介绍
作用
分类
引导类加载器
自定义类加载器
ClassLoader
获取ClassLoader途径
双亲委派机制
介绍
执行流程
好处
打破…

软件UI自动化测试应该怎么做?对软件产品起到什么作用?
在软件开发过程中,开发人员需要编写大量的代码来实现软件产品的功能。而这些功能往往需要在用户界面上进行展示和操作,称为UI(User Interface)。UI自动化测试是为了检测软件界面是否符合预期的设计和用户操作,通过自动化测试工具和脚本&#…
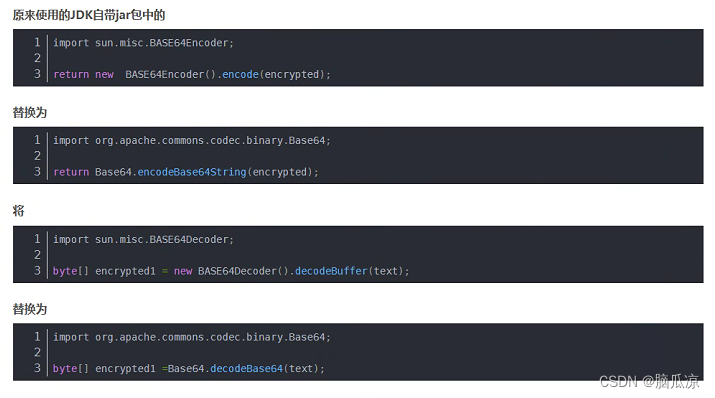
Idea执行Pom.xml导入jar包提示sun.misc.BASE64Encoder jar找不到---SpringCloud工作笔记197
奇怪之前都是好好的,这个是因为,jdk的版本不对,重新打开以后自动被选择成jdk11了...记录一下 原因是从jdk9的时候,这个jar包已经被删除了,所以会报错,如果你用的是jdk自带的这个jar包就会报错,那么还可以,修改,不让他用jdk的,让他用 用org.apache.commons.codec.binary.Base64…

NSDT编辑器实现数字孪生
数字孪生的强大功能来自于将真实世界的资产与真实世界的数据联系起来,因此您可以更好地可视化它们。数字孪生使跨职能团队能够以交互式和沉浸式方式协作设计、构建、测试、部署和操作复杂系统。
如何创建数字孪生?
数字孪生是通过导入概念模型…
PBA.客户需求分析 需求管理
一、客户需求分析 1 需求的三个层次: Requirement/Wants/Pains
大部分人认为,产品满足不了客户需要,是因为客户告知的需求是错误的,这听起来有一些道理,却没有任何意义。不同角色对于需求的理解是不一样的。在客户的需求和厂家的…
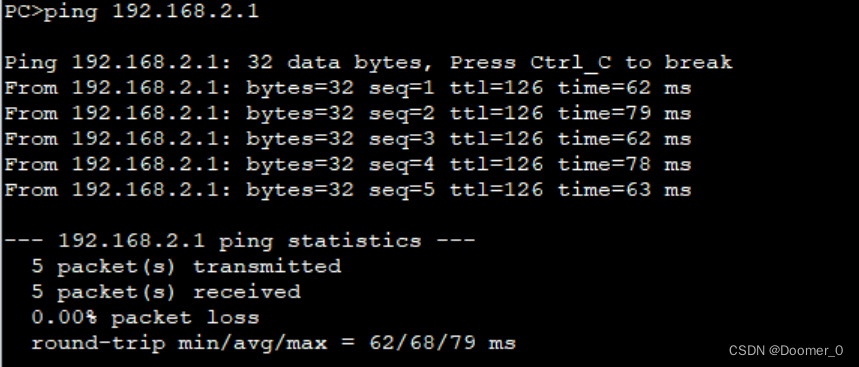
四、RIP动态路由实验
拓扑图: 基本ip的配置已经配置好了,接下来对两台路由器配置rip协议,两台PC进行跨网段通讯
RIPv1版本只能识别ABC的大类网段,不能区分子网掩码,v2版本可以识别子网掩码
首先进入R1,进入rip,宣告…
推荐文章
- Qt for Python 入门¶
- 已解决java.lang.ArrayIndexOutOfBoundsException异常的正确解决方法,亲测有效!!!
- !! A股历史平均市盈率走势图
- #LLM入门|Prompt#2.3_对查询任务进行分类|意图分析_Classification
- (001)Unit 编译 UTF8JSON
- (2.2w字)前端单元测试之Jest详解篇
- (el-switch)操作(不使用 ts):Element-plus 中 Switch 将默认值修改为 “true“ 与 “false“(字符串)来控制开关
- (JAVA)树——tree
- (kali关怀版)kali调整字体图标显示大小
- (六)正点原子STM32MP135移植——内核移植
- (免费送源码)计算机毕业设计原创定制:Java+ssm+JSP+Ajax SSM棕榈校园论坛的开发
- (三)Mysql 数据库系统全解析