文章目录
- 前置知识
- Generalizable
- 《Enhancing NeRF akin to Enhancing LLMs: Generalizable NeRF Transformer with Mixture-of-View-Experts》
- 《WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields》
- NeO 360: Neural Fields for Sparse View Synthesis of Outdoor Scenes
- Generalizable Neural Fields as Partially Observed Neural Processes
- C2F2NeUS: Cascade Cost Frustum Fusion for High Fidelity and Generalizable Neural Surface Reconstruction Neural Surface Reconstruction
- Uncertainty
- FlipNeRF: Flipped Reflection Rays for Few-shot Novel View Synthesis
- D-IF: Uncertainty-aware Human Digitization via Implicit Distribution Field
- Conditional-flow NeRF: Accurate 3D modelling with reliable uncertainty quantification【ECCV‘22】
- Other interesting papers
- ClimateNeRF: Extreme Weather Synthesis in Neural Radiance Field
- Lighting up NeRF via Unsupervised Decomposition and Enhancement
前置知识
- TODO:对渲染有用的属性(特征)有哪些?因此处理时需要注意什么?
- Multi-View Stereo(MVS):多视角立体视觉是一种显式的三维重建方法,它试图从多个二维图像中获得精确的三维几何信息,通常通过立体匹配和三维几何计算来实现。它和NeRF都是用于三维重建的方法,区别在于显式和隐式重建。
- 离散小波变换(Discrete Wavelet Transform):TODO
- 空洞卷积(Dilated/Atrous Deconvolution):针对图像语义分割问题中下采样带来的图像分辨率降低、信息丢失问题而提出的一种新的卷积思路。使用卷积或者池化操作进行下采样会导致一个非常严重的问题:图像细节信息被丢失,小物体信息将无法被重建(假设有4个步长为2的池化层,则任何小于 24 pixel 的物体信息将理论上无法重建),高频信息也被丢失。空洞卷积通过引入扩张率(Dilation Rate)这一参数使得同样尺寸的卷积核获得更大的感受野。相应地,也可以使得在相同感受野大小的前提下,空洞卷积比普通卷积的参数量更少。
Generalizable
《Enhancing NeRF akin to Enhancing LLMs: Generalizable NeRF Transformer with Mixture-of-View-Experts》
Project page: https://github.com/VITA-Group/GNT-MOVE
Authors: University of Texas at Austin, University of Cambridge, Indian Institute of Technology Madras
摘要:
\quad Cross-scene generalizable NeRF models最近成为了NeRF领域的一个焦点,其中一些工作依赖端到端的神经架构,即将场景表征或渲染模块替换成性能不错的神经网络如TF,从而使NVS成为一个前馈推理管道。但是,这些前馈的神经架构不一定能够直接适应各种各样的场景,所以这篇文章想要通过使用来自large language models (LLMs)中的Mixture-of-Experts (MoE)思想将他们连接起来。这篇文章从一个最近的泛化性NeRF架构GNT(《Is Attention All That NeRF Needs?》【ICLR’23】)出发,证明MoE可以很好地被整合进来以增强模型。此外,他们还引入了a shared permanent expert and a geometry-aware consistency loss,这两者分别用于强化跨场景的一致性和空间平滑性,对泛化性NVS任务很重要。
动机:
\quad 之前的NeRF是backward的方式,因为需要针对每个场景单独训练,即想合成unseen scene时需要有backwar的过程。generalizable NeRF是feedforward的方式,因为在合成unseen scene时不需要训练,只有feedforward的推理过程。其中,GNT通过统一的、数据驱动的和可扩展的变压器取代了显式的场景建模和渲染功能,并通过大规模的新视图合成预训练自动诱导多视图一致的几何图形和渲染。
\quad generalizable NeRFs虽然可以实现cross-scene NVS,但是也面临着“generality”和“specialization”不能两全的根本困境。一方面,由于不同的场景属性(例如,颜色、材料),它们需要广泛地覆盖不同的场景表示和/或渲染机制,因此需要更大的整体模型尺寸来保证足够的表达性。另一方面,由于单个场景通常由专门的自相似外观模式组成,所以generalizable NeRFs必须能够per-scene specialization才能紧密地建模场景。(这里作者想要表达的是泛化需要大规模的模型来保证,所以泛化性NeRF的矛盾就是模型规模和specilizaiton的矛盾。)
\quad 为了解决上述问题,这篇文章提出将LLM中的MoE的想法引入到GNT框架中。这种思想启发于Switch Transformer【JMLR‘22】和AligNeRF【CVPR’23】,在他们中,MoE是提升泛化性的关键,通过鼓励不同的子模型(激活专家的组合)对不同的输入进行稀疏激活,从而在成为“专门化”的情况下,扩大总模型的规模而不增加执行推理成本。
\quad 这篇文章主要关注GNT中的view Transformer,即将MoE注入到view transformer中,因为作者认为MoE的模块化设计对view transformer的多视图特征聚合具有天然的帮助。MoE对ray transformer可能也有帮助,但是这里没有去做。通过实验,作者发现直接将MoE插入NeRF中不能平衡 generality(通用性) 和 specialization(特定性),这是因为NeRF模型有一些内置的先验,包括跨场景一致性和空间平滑性。MoE的引入可能会破坏这些先验,导致性能不如预期。
- 跨场景一致性:来自不同场景的相似的外观模式和材料,应该通过选择相似的专家来一致地处理。(不同场景一致性)
- 空间平滑性:同一场景相近的视图应持续平稳变化,因此做出类似或平稳过渡的专家选择。(同一场景一致性)
\quad 这两个先验对应着自然图像渲染和多视图一致性约束。但是,强制应用将会导致MoE的表示崩溃问题。表示崩溃是指当不同子模型被激活时,它们可能会学习相同或相似的函数,无法捕获不同的专业特征。这个问题在Mixture of Experts领域已经得到广泛讨论。尽管目前已经有一些解决表示崩溃的方法,但仍然不清楚这些解决方案是否会与"consistency/smoothness"(一致性和平滑性)相矛盾。这是一个新的挑战,需要引起注意。简而言之,本文面临的关键问题就是,在将MoE引入generalizable NeRF的时候,如何即保证跨场景一致性和空间平滑性,又不发生表示崩溃问题。
\quad 所以为了解决这样的问题,作者又提出了两个improvement。第一个改进是使用一个shared permanent layer 来增强 MoE 层,这个layer在所有的cases中都会被选择。这个共享专家的存在是一种架构正则化,有助于增强不同场景之间的一致性,提高跨场景的一致性。第二个改进是引入了一个空间平滑性目标,以确保几何上的连续性。这通过鼓励空间上接近的点选择相似的专家,并使用采样点之间的几何距离来重新加权它们的专家选择。作者经验性地发现,这两个一致性正则化方法与MoE中典型的专家多样性正则化方法一起工作得很好,有效地增加了模型容量,同时满足一致性和平滑性的需求。最后,作者指出,他们在复杂场景基准上进行了广泛的实验,并取得了显著的成果。当在多个场景上训练时,他们的模型(GNT-MOVE)在两个方面表现出色:(1)对于未见过的场景具有显著更好的zero-shot泛化能力;(2)对于未见过的场景具有始终更强的few-shot泛化能力。
\quad 概括一下:这篇文章指出现今的generalizable NeRF虽然有generality,但是在specialization方面的表现差(即,可以泛化,但质量不好)。为了解决这个问题,作者将MoE引入其中增强specialization(引入的时候为了避免表示崩溃问题使用了一个标准的diversity regularizer),但是直接引入效果不好(会导致跨场景一致性和空间平滑性的缺失,这对泛化性NeRF是重要的),所以作者做出了两点改进,一个是shared permanent layer来增强跨场景一致性,另一个是空间平滑性目标确保同场景连续性。
Related work:
\quad MoE: MoE是一种模型结构,它通过多个子模型(也称为专家)的组合执行输入相关的计算,根据某种学习或自定义的路由策略来处理数据。这允许模型根据输入数据的不同特征或情况,动态选择使用不同的专家来进行计算。最近在自然语言处理领域出现了一些进展,"稀疏门控MoEs"被提出,它可以扩大大型语言模型(LLM)的容量,而不会牺牲每次推断的成本。这些模型鼓励不同模块拥有不同的功能,有助于在保持精确性和效率之间取得良好的平衡。在视觉领域,MoEs也逐渐受欢迎,但是它目前只关注于分类任务。
\quad 目前一些工作已经在NeRF中隐式地探索了稀疏激活的子模型思想。Kilo-NeRF【ICCV21】引入了成千上万个小型MLP来分割和处理整个场景建模, Block-NeRF【CVPR’22】允许NeRF将大型环境划分为多个单独训练的NeRF模型,从而能够表示街景规模的场景,这是一种以块状方式处理大场景的方法,NID【ICML’22】通过组装一组基于坐标的子网络来提高INR的数据和训练效率,NeurMiPs【CVPR’22】提出了一种利用专家模型来改善场景建模的方法。
\quad MoE一般包括一个专家库 f 1 . . . f E f_1...f_E f1...fE,以及一个路由器 R \mathcal{R} R。每个专家就是一个MLP网络。路由器 R \mathcal{R} R的输出是一个E维的向量,本文选择了一个代表性的路由器:top-K gating,它将输出的E维向量中前K个大的项保留,剩下的为0,所以可以起到专家选择的作用。路由器的作用,就是将token embedding x,映射为它的专家选择分数 R \mathcal{R} R(x)。

方法:
\quad 下面这个图是方法的总览图
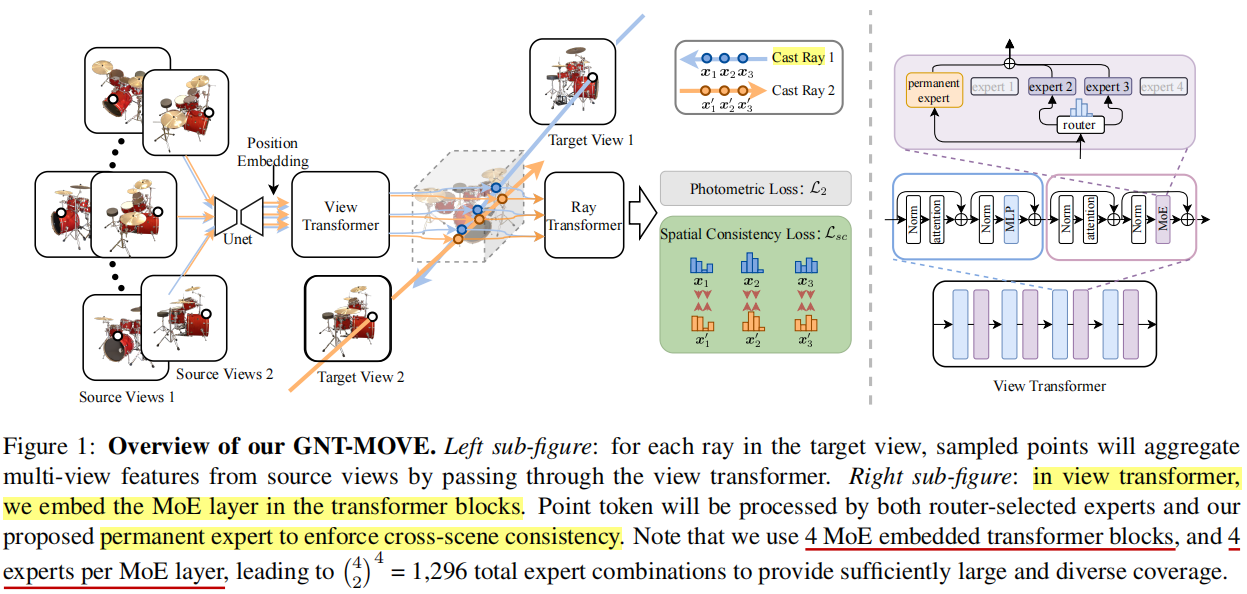
\quad 可以看出,本文就是在GNT的view transformer中潜入了一个MoE layer,对于传递的信息,MoE layer一边将它输入至一个permanent expert来保证cross-scene consistency,一边用router选出两个expert来处理它,来保证speciality。为什么要进行specialization,作者进一步解释了动机。在GNT中,UNet被用来从2D图像中提取几何、外貌、 局部光线传输信息。然后使用一个view transformer来整合这些特征估计出该采样点在隐空间中的渲染参数(例如占据情况、透明度和反射等),这些隐空间上的参数再被输入至Ray Transformer来预测光线的color(这个过程代替了渲染过程)。在这个过程中,UNet提取的特征(如自然阴影属性)中有些是互斥的(如漫反射和镜面反射),也就是说这些属性是被稀疏激活的。并且,在典型的渲染引擎中,显示一个场景通常需要调用不同的图形着色器来处理空间变化的材质和光线传输属性。对于这种现象,MoE策略非常的合适。如上面右图所示,对于传进来的特征,router来学习如何稀疏激活不同的expert组合,以模拟不同的“图形着色器”处理不同的材质和光线传输属性。
\quad 基于这些观察,作者决定将"MoE模块"引入到"View Transformer"中,以便为特定的渲染属性专门定制不同的专家组件。这意味着他们希望通过使用MoE来实现在"View Transformer"中对UNet提取出的不同渲染属性进行专门的特殊处理,以更好地控制和处理各种光线传输属性,从而提高渲染的质量和逼真度。这点动机听起来还是非常有意思且合理的。
\quad 在本文中,稀疏激活的意思是,在MoE中,每次只使用(激活)2个expert,router的作用就是学习如何实现这种稀疏激活。在GNT-MOVE中,有4个MoE模块,每个模块从4个专家中选择2个,所以专家的组合有 ( C 4 2 ) 4 = 1296 (C_4^2)^4=1296 (C42)4=1296种方案,这足以提供广泛和多样化的覆盖范围。
\quad 首先,避免MoE出现表示崩溃问题,在选择专家时需要平衡且多样化。因此,这里作者使用了MoE arts中的一种标准的 diversity regularizer来实现。公式如下,x是点 x x x的token embedding, x x x是光线 r r r上的一个点, r r r是所有视图的光线 R R R中的一个光线。CV是变异系数,即标准差和协方差的比率,绝对值越大,表示数据的变异性越大。这个损失的含义就是,在NeRF中,鼓励所有视角充分利用专家空间,并鼓励不同的专家来捕捉不同视角的细微差别。

\quad 其次,直接这样将MoE插入NeRF中,会导致跨场景一致性和空间平滑性的丢失,所以作者做了两个设计:
\quad 1)Permanent Shared Expert:直接插入MoE时,作者观察到了如下图所示的明显的跨场景不一致性。在这篇文章中,跨场景一致性如何体现呢?作者称对于不同场景中相似的外貌模式和材料,MoE应当选择一致的专家来处理。在下图中(这样的可视化举例是值得借鉴的),没有加入permanent expert f p f_p fp时,相同的外观选用了不同的专家,这是cross-scene inconsistency。加入后,相同的外观选用了相同的专家,即cross-scene consistency。这个 f p f_p fp负责提炼不同场景中的常识。


\quad 2)Geometry-Aware Spatial Consistency:(上面是不同场景的一致性,这个对应着同一场景内的一致性。同一场景内的一致性可以说成空间平滑性。TODO:不同场景的一致性还可以用什么来体现?即可以提出什么样的方法来约束?)在同一个场景中,附近的视角在进行专家选择时应当相同或平滑,这一点可以体现多视角一致性。为此,作者这里提出了一个空间一致性目标:鼓励空间上相近的点选择相似的专家。每个点的专家选择其实就是一个分数 R \mathcal{R} R(x),或者说是一个分布。鼓励两个分布相似,自然想到的就是KL散度。但是3D采样点太多了,成对计算的计算成本太昂贵。对此,作者先找出距离小于ε的成对光线。对于每对光线,对每个点,找到距离他最近的一个点,然后计算KL散度如下。此外,由于越近的点选择专家时可能越相似,所以作者用距离作为权重来作为一致性的置信度。



实验:
训练集:合成数据有Google Scanned Object的1023个模型的对象渲染,真实数据有RealEstate10K、Spaces dataset的90个场景、handheld cellphone captures的102个场景。
测试集:常用的LLFF和 NeRF Synthetic dataset。
《WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields》
Authors: Nanyang Technological University,Max Planck Institute for Informatics
TL;DR:高频特征往往表示有价值的场景信息,现有泛化性NeRF在去除per-scene optimization后发生性能急剧下降的现象,大多是由于高频信息的丢失。
动机:
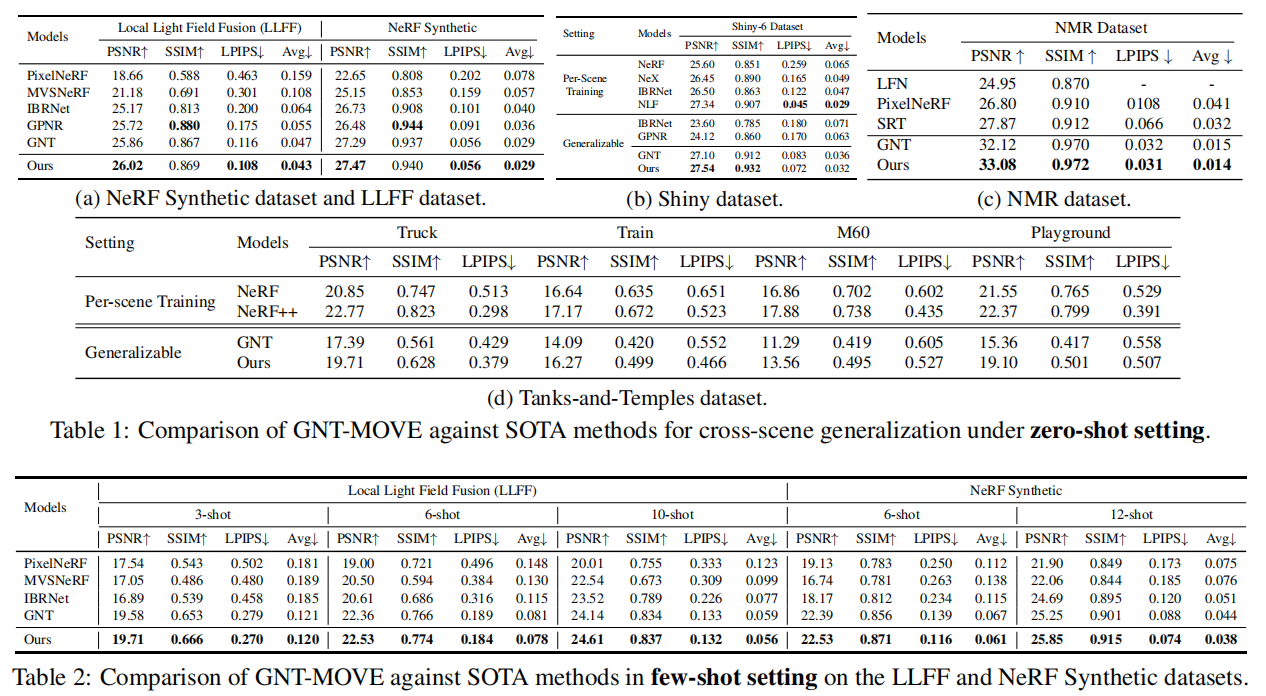
\quad 原始NeRF的可伸缩性通常很差,因为每个新场景都需要密集采样的图像。一些研究试图通过将Multi-View Stereo(MVS)技术集成到NeRF中来缓解这一问题,但它们仍然需要对新场景进行繁琐的微调过程。但是,如果去除这种微调过程,渲染质量将会严重下降,并且产生的误差主要出现在高频特性周围。如下图所示,渲染误差主要是在具有丰富的高频信息的图像区域附近。这种丢失高频细节的现象在很大程度上归因于大多数现有的generalizable NeRF在它们pipeline的特征提取阶段进行的降采样操作。

\quad 基于上述观察,这篇文章提出了一个Wavelets-based Neural Radiance Fields (WaveNeRF),它将显式的高频信息整合到训练过程中来避免这种问题。具体来说,除了利用MVS技术构建三维feature volume然后在空间域内转换为NeRF模型之外,我们进一步设计了一个小波multi view stereo(WMVS),将场景的小波系数合并到MVS中,以实现频域建模。与傅里叶变换不同,WaveNeRF利用小波变换,它是坐标不变的,并保持了像素的相对空间位置。 这种特性在MVS中特别有利,因为它允许多个输入视图在参考视图的方向上被扭曲,从而在同一坐标系内的空间域和频域内形成扫射平面(sweeping planes)。除了MVS之外,该特性还可以建立一个基于频率的辐射场,这样作者设计的一个Hybrid Neural Renderer (HNR)就可以同时利用空间域和频率域的信息来提高外貌的渲染质量,特别是在高频区域周围。此外,WaveNeRF还配备了Frequency-guided Sampling Strategy(FSS),使模型能够聚焦于具有较大高频系数的区域。通过这个FSS,在物体表面周围进行更密集的点采样,可以显著地提高渲染质量。贡献如下:
- 设计了一个WMVS模块,通过在提取几何场景特征的同时加入小波频率体积,有效地保存高频信息。
- 设计了一个HNR模块,它可以合并来自空间域和频域的特征,在神经渲染中产生忠实的高频细节。
- 开发了FSS,它可以指导体积渲染来采样物体表面周围更密集的点,以便推断出更高质量的外观和几何形状。
Related work:
\quad Multi-View Stereo:MVS是基于posed image进行显式三维重建的一种传统方法。近些年,深度学习技术才被应用到其中。MVSNet 就是基于深度学习的一种方法,它从所有输入图像中提取特征,并将它们扭曲(wrap)到参考图像上,以生成具有不同深度值的概率平面。这些平面然后被组合起来,创建一个variance-based cost volume来准确地表示特定的场景。虽然MVS方法已经表现出了良好的性能,但 3D volume grid 和 operation 的大内存需求严重限制了输入图像的分辨率和随后基于深度学习的MVS研究的发展。为了解决这个问题,RMVSNet 顺序地使用GRU规范了cost volume,使MVSNet更具有可扩展性。此外,级联MVS模型使用一种从粗到细的策略来生成不同规模的cost volume,并相应地计算深度输出,从而释放了更多的内存空间。MVS已被证明是有效的推断场景几何形状和遮挡的方法。我们遵循以往的MVS技术,并进一步引入小波变换,以实现更高的推理质量。
\quad pixelnerf和ibrnet遵循相同的理念:在每个采样点上聚合多视图特征比使用直接编码的RGB输入可以获得更好的性能。另一些方法使用MVS技术来实现泛化性NeRF。MVSNeRF、PointNeRF、GeoNeRF都是先使用MVS技术来获取一个coarse 3D 表征,只是PointNeRF使用点云增长来增强推理能力,GeoNeRF使用了Transformer模块。
\quad 在上述的这些方法中,per-scene optimization是一个可选的训练过程,但是如果没有它上述的大部分泛化性NeRF都无法达到逼真的结果,加上了它又会极大损害泛化性。
方法:
\quad 首先,为了解决泛化性NeRF中的误差主要聚集在高频区域,这篇文章提出了一个Wavelet Multi-view Stereo (WMVS) 模块,以同时在空间域和频域中获取特征体(feature volume),使高频信息可以被单独地保持和表征。其次,由于之前研究中的渲染器无法直接解耦高频特征周围的误差,这篇文章实现了一个Hybrid Neural Renderer(HNR),它可以根据从WMVS获得的高频信息来调整渲染的颜色。最后,这篇文章也注意到,之前工作的采样策略以牺牲采样质量为代价,同时对所有点进行采样。因此,为了达到更高的采样质量,即在场景中目标的周围进行更多的采样,这篇文章采用了一种Frequency-guided Sampling Strategy (FSS)。其中,采样点的坐标由特征在 frequency feature volume中的分布决定。
\quad 方法的总览如下图:

\quad WMVS模块:对于一批图像,首先用离散小波变换(DWT)生成低频成分和高频成分。低频分量直接被用来生成最低级的语义特征图(空域)。对于每个级别的高频分量,由于域间隙,天真地将不同的频率分量加在一起是不可能生成空间特征的。因此,作者这里设计了一个Inverse Wavelet Block (IWB)来模拟离散小波逆变换,方式是通过空洞卷积将上一级的频率特征和当前级别的频率特征相结合,生成隐空域特征图。然后这个特征通过CNN生成当前级别的语义特征图 f s f_s fs。
 \quad 此外,所有的高频分量被结合在一起,用一个CNN生成频率特征图。有了语义特征图和频率特征图后,作者向CasMVSNet方法那样构造 sweep plane 和 spatial feature volumes P s P_s Ps。此外,由于小波变换不影响相对坐标的良好特性,所以可以采用同样的方式来构造高频feature volume P w P_w Pw。由于高频信息通常是稀疏分布的,因此,在一个相对较小的体积内表示高频特征是非常有效的,所以 P w P_w Pw的尺寸选择为: H / 2 × W / 2 H/2 \times W/2 H/2×W/2。
\quad 此外,所有的高频分量被结合在一起,用一个CNN生成频率特征图。有了语义特征图和频率特征图后,作者向CasMVSNet方法那样构造 sweep plane 和 spatial feature volumes P s P_s Ps。此外,由于小波变换不影响相对坐标的良好特性,所以可以采用同样的方式来构造高频feature volume P w P_w Pw。由于高频信息通常是稀疏分布的,因此,在一个相对较小的体积内表示高频特征是非常有效的,所以 P w P_w Pw的尺寸选择为: H / 2 × W / 2 H/2 \times W/2 H/2×W/2。
\quad FSS策略:在获取上面的特征之后,作者使用 ray-casting(光线投射)方法来进行新视图的合成。在一个新的相机pose下,作者沿着每个相机射线均匀地采样 N c N_c Nc个点。许多先前的研究遵循经典的NeRF,先采样 N c N_c Nc个点,然后根据 N c N_c Nc个点推断的体积密度分布再采样 N f N_f Nf点以近似物体表面。然而,这种 coarse-to-fine 的采样策略需要同时训练两个NeRF网络。MVSNeRF 直接丢弃了 fine sampling,并声称添加 fine sampling 过程不能显著提高性能。 GeoNeRF首先通过检查坐标是否在有效的NDC坐标系统内来估计了 N c N_c Nc个coarse采样点,然后在这些有效的粗点周围再随机采样 N f N_f Nf点。但,虽然GeoNeRF同时采样 N c + N f N_c + N_f Nc+Nf个点,但它不能确保采样点在object附近。因此,为了采样点更多地集中在高频区域(高频特征往往表示有价值的场景信息),这里作者提出了一种Frequency-guided Sampling Strategy,如下图所示。

\quad 这个采样策略首先利用粗采样点的坐标从小波feature volume P w P_w Pw中获取相应的高频特征。然后用这些频率特征沿着所在ray构造一个概率密度函数(PDF),这个PDF决定了 fine sampling points 的分布。也就是说,在接下来的 fine sampling process中,更高小波特征值的区域有着更大的概率被采样,这可以产生高质量的采样结果。

\quad 用空域的特征输入至GeoNeRF中的MLP来预测密度和颜色,然后用频域特征预测 出frequency coefficient,进一步地对颜色进行调整。ABA是基于注意力的聚合器,用的也是GeoNeRF中提出的。
训练:
\quad 为了监督小波系数生成的过程,作者引入了两个损失。第一个如下,这个损失用来计算预测小波系数和GT 像素的小波系数的 MSE,其中R是一批训练数据的所有光线。

\quad 此外,为了提高对高频特征的学习能力,作者还设计了一个Weighted Frequency Loss。这个损失是一个改进的color loss,如下所示,这个损失基于小波系数值作为权重,将高频特征周围的误差进行放大:

\quad (要想效果好,网络的每一个环节都是经过精心设计的。并且损失的设计也很重要。)
实验:
\quad 3输入视图。



![[电源选项]没有系统散热方式,没有被动散热选项](https://img-blog.csdnimg.cn/dcd5e6e7c5b24b12a496aa18247ae64f.png)