文章目录
- 引言
- 正文
- Abstract
- Introduction
- System Overview
- 2.1 Latent Diffusion with sound-class-based conditioning以声音类别为条件的潜在扩散模型
- 2.2 Variational Autoencoder and neural vocoder变分自编码器和神经声码器
- FAD-oriented Postprocessing filter(专门针对FAD的后置过滤器)
- Experiments实验
- Models and Hyperparameters
- 总结
引言
- 这篇文章是DCASE task 7 -Track A的FAD第一名,需要参考一下他使用的技术,尝试在自己的论文上进行使用。
正文
Abstract
-
整个系统使用了LDM潜在扩散模型(latent diffusion model),变分编码器(VAE)还有HiFi-GAN声码器。
- 通过LDM,生成声音基于类别所以你的潜在表示
- 通过VAE将潜在特征表示转为mel频谱图
- 通过HiFi-GAN将频谱图转为波形图
-
数据集:使用DCASE2023提供的数据集进行训练,声音类别索引作为生成特定类别的声音潜在标识的索引。
-
提升差异度的方法:首先将LDM在AudioCaps上进行预训练,然后再进行微调
-
提升类别的度的方法:通过后处理器来提升类别嵌入度,对声音进行类别过滤
Introduction
- 这个比赛很有意义,这个技术应用很多。
- 最近提出的声音生成模型如下
AudioLDM
- 基于文本的描述的目标生成,具体构成如下:潜在特征扩散模型(LDM)、变分编码器(VAE)和神经声码器。
- LDM输入的条件信息是基于CLAP对比语音语音嵌入
- 潜在特征表示是通过VAE的自动编码器实现的
- 声码器是HiFi-GAN,将mel频谱图变为波形图
Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
-
基于AudioLDM,仅仅是使用LLM替代了CLAP
- 通过LLM(instruction-tuned large language )指令调整的大预言模型,来增强AudioLDM的文本提示功能
-
但这都是针对基本文本描述语音生成,但是不能利用现存的声音类型进行模仿,生成声音。
作者的研究介绍如下
- 模型使用Tango等人预先训练好的模型,这些模型是基于AudioCaps和Flan-T5进行训练的
- 基于条件生成的功能实现如下:
- 使用简单的线性嵌入层来取代文本理解层,借此实现基于样例生成的效果
- 后过滤层的实现原理
- 对生成的样本进行筛选,过滤,选择FAD最低的样本
- 使用贪婪向后选择策略实现声音选择的生成
System Overview
整个系统的输入是类别的索引
- 系统的概览是上面那幅图,依次是
- 基于LDM的潜在特征生成器
- VAE的将潜在特征标识映射为mel频谱图
- mel到波形图的声码器
- 后处理过滤器的流程如下
- 将生成的声音通过

2.1 Latent Diffusion with sound-class-based conditioning以声音类别为条件的潜在扩散模型
-
我们的LDM模型将采样生成的高斯噪声 Z N ( Z N ∈ R C × T r × F r ) Z_N(Z_N \in \mathbb{R}^{C \times \frac{T}{r} \times \frac{F}{r}}) ZN(ZN∈RC×rT×rF)转换为一个潜在表示 Z 0 Z_0 Z0,主要是通过 N N N步反转扩散,通过UNet模型实现的。
- T T T表示mel频谱图的帧数
- F F F表示mel滤波器的数量
- C C C表示潜在特征空间的通道数
- r r r表示VAE的压缩成都,也就是中间潜在特征空间的维度
-
类别条件信息传入:
- 神经网络接收长度为L,维度为d的嵌入向量 E ∈ R L × d E \in \mathbb {R}^{L \times d} E∈RL×d,这个 E E E是通过线性嵌入层生成的,条件信息通过交叉注意力机制传输给神经网络。
-
训练之前,我们的模型是使用Tango等项目进行初始化,原来的checkpoint是接收来自Flan-T5的文本编码器的嵌入向量,我们使用线性嵌入层进行替代。线性嵌入层将声音类别的索引 c c c投影为d维的向量。这个线性嵌入层也是和LDM一块进行训练的。并不是单独分开的。
-
交叉注意力机制原来是接收文本编码器的输出,是一个序列的嵌入向量,所以我们使用单个嵌入向量表示类别信息。
-
具体训练过程如下,基于DDPM(Denoising diffusion probablistic models),参数说明如下
- Z N ( Z N ∈ R C × T r × F r ) Z_N(Z_N \in \mathbb{R}^{C \times \frac{T}{r} \times \frac{F}{r}}) ZN(ZN∈RC×rT×rF)潜在特征表示
- 对应的类别嵌入向量 E ∈ R L × d E \in \mathbb {R}^{L \times d} E∈RL×d
- 各向同性高斯噪声
-
损失函数如下
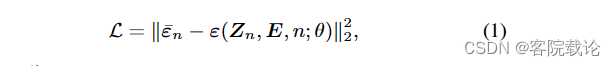
推理阶段
-
在推理阶段,我们是用DDIM去加速采样的速度,使用免费类器引导去提高声音类别的质量。
-
确定性向后传播过程如下,参数说明
- β n \beta _ n βn是前向传播的高斯分布方差
- σ n 2 \sigma_n^2 σn2是反向传播的高斯分布方差
- w w w是引导尺度的参数
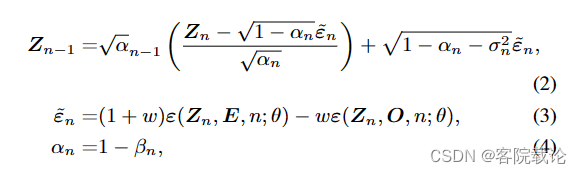
2.2 Variational Autoencoder and neural vocoder变分自编码器和神经声码器
-
我们是用VAE将mel频谱图压缩为一个潜在特征表示空间。var具体是由CNN构成的编码器堆叠而成。整个系统中,是将扩散模型的降噪之后的输出放入到VAE的解码器重,然后重建为mel频谱图。
-
然后使用HiFi-GAN将mel频谱图转为音频文件声波。HiFi的介绍具体看如下连接。HiFi-GAN具体介绍
FAD-oriented Postprocessing filter(专门针对FAD的后置过滤器)
-
虽然系统生成的样本还行,但是可以通过过度生成和过滤来实现改进。尤其是对于目前这个以FAD为评价指标的挑战。FAD计算如下
-
计算参考和生成样本的VGGish 嵌入向量,计算参考音频和生成音频的嵌入向量的平均μ和协方差矩阵Σ,其Fŕechet距离[11]为
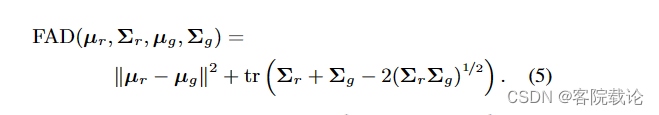
-
需要获得P样本,我们首先生成Q个样本,然后使用贪婪选择策略,将之减少到P个样本。每一次都选择一个样本k,丢弃这个样本k,FAD降低的最多。重复k次,知道Q和P数量相等。
-
如果我们有超过P个样本,我们使用Metropolis-Hastings算法来找到P元素的一个好的子集。首先,我们通过评估P样本的100个子集的FAD并选择最低的一个来初始化算法。在算法的每次迭代中,我们随机交换两个样本。首先,我们随机选择当前P个样本中的一个。然后,我们以与第一个样本的嵌入距离成反比的概率选择一个被丢弃的样本。我们交换这两个样本并评估FAD。如果它减少了,我们接受这个变化。如果它增加了,我们只有在一个随时间线性减少的小概率下才接受这个变化。否则,我们拒绝这个变化。在所有迭代中,FAD最低的子集被算法返回。
Experiments实验
Models and Hyperparameters
HiFi-GAN和VAE
-
使用HiFi-GAN和VAE的预训练模型来自AudioLDM这个项目。使用AudioSet对HiFi-GAN进行预训练。
-
所有的数据都是用增强或者填充,补充到十秒钟,然后调整采样率为16kHZ,
-
将音频转为频谱图的操作如下
- F=64,64维度的mel频谱图
- 汉明窗口是1024
- 每一跳的长度是160
- 帧数T扩展24帧,避免以后再进行padding
-
VAE是在AudioCaps、AudioSet和Freesound上进行训练过
- 压缩的水平 r r r是4
- 通道数是8
LDM
- 我们使用Tango的checkpoint作为初始化模型,模型使用的条件向量维度是 d = 1024 d = 1024 d=1024.对于微调,我们使用了 DCASE-023 Task7 开发集。由于音频数据以 22.05 kHz 采样并在四秒内分割,我们将它们重新采样到 16 kHz 并将它们填充为 10 秒。我们设置 N = 1000 个前向扩散步骤进行微调。我们的LDM使用AdamW优化器进行微调,初始学习率为3e-5,线性衰减学习率调度器。我们使用七个 A100 GPU 对模型进行了 100k 训练迭代的微调,有效批量大小为 42。在推理阶段,我们使用DDIM[8]进行100个采样步骤,使用无分类器的指导尺度w = 3。由于我们的模型以16 kHz采样率产生10秒的音频段,我们提取了前四秒的段,并将其重新采样到22.05 kHz,以适应挑战规则。
Postprocessing后处理
- 对于每个声音类,我们首先使用上述音频生成管道生成 Q = 200 个样本。然后应用FAD滤波器将样本数减少到P = 100。
总结
- 这篇文章,就是用了别人的AudioLDM的特征生成部分,只能说LDM的效果要好于pixelSNAIL。
- PixelSNAIL是使用适量量化的编码序列,特征更加简单,生成序列效果会更好,但是将复杂特征降噪为编码序列,这本来就会损失很多特征。现在使用diffusion模型,效果要好于对特征进行提取生成序列。