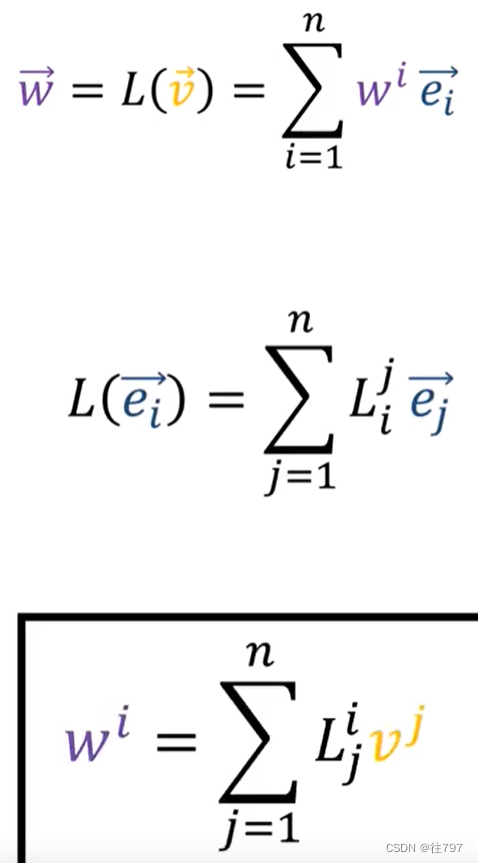之前我们已经看到了如何创建自定义损失函数
接下来,我写了关于使用 Lambda 层创建自定义激活函数的文章
一、说明
TensorFlow 2发布已经接近2年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。3大设计原则:简化概念,海纳百川,构建生态.这是本系列的第三部分,我们将创建自定义密集层并在 TensorFlow 2 中训练它们。
二、图层介绍
Lambda 层是 TensorFlow 中的简单层,可用于创建一些自定义激活函数。但是 lambda 层有很多限制,尤其是在训练这些层时。因此,我们的想法是使用TensorFlow中可继承的Keras层创建可训练的自定义层 - 特别关注密集层。
什么是图层?
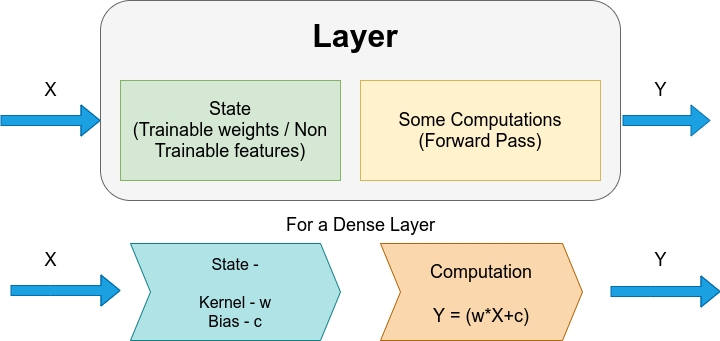
层是一个类,它接收一些参数,通过状态和计算传递它们,并根据神经网络的要求传递输出。每个模型架构都包含多个层,无论是顺序层还是函数式 API。
状态 — 主要是在“model.fit”期间训练的可训练特征。在密集层中,状态构成权重和偏差,如图 1 所示。这些值会更新,以便在模型训练时提供更好的结果。在某些图层中,状态还可以包含不可训练的特征。
计算 — 计算有助于将一批输入数据转换为一批输出数据。在图层的这一部分中,将进行计算。在密集层中,计算执行以下计算 —
Y = (w*X+c),并返回 Y。
Y 是输出,X 是输入,w = 权重,c = 偏置。
三、创建自定义密集层
现在我们知道了密集层内部发生了什么,让我们看看如何创建自己的密集层并在模型中使用它。
import tensorflow as tf
from tensorflow.keras.layers import Layerclass SimpleDense(Layer):def __init__(self, units=32):'''Initializes the instance attributes'''super(SimpleDense, self).__init__()self.units = unitsdef build(self, input_shape):'''Create the state of the layer (weights)'''# initialize the weightsw_init = tf.random_normal_initializer()self.w = tf.Variable(name="kernel", initial_value=w_init(shape=(input_shape[-1], self.units),dtype='float32'),trainable=True)# initialize the biasesb_init = tf.zeros_initializer()self.b = tf.Variable(name="bias",initial_value=b_init(shape=(self.units,), dtype='float32'),trainable=True)def call(self, inputs):'''Defines the computation from inputs to outputs'''return tf.matmul(inputs, self.w) + self.b上面代码的解释 — 该类名为 SimpleDense。当我们创建自定义层时,我们必须继承 Keras 的层类。这是在“类简单密集(层)”行中完成的。
“__init__”是类中第一个有助于初始化类的方法。 “init”接受参数并将其转换为可在类中使用的变量。这是从“Layer”类继承的,因此需要进行一些初始化。此初始化是使用“super”关键字完成的。“单位”是一个局部类变量。这类似于密度层中的单元数。默认值设置为 32,但在调用类时始终可以更改。
“build”是类中的下一个方法。这用于指定状态。在密集层中,权重和偏差所需的两种状态是“w”和“b”。当创建密集层时,我们不只是创建网络隐藏层的一个神经元,而是一次创建多个神经元(在这种情况下将创建 32 个神经元)。层中的每个神经元都需要初始化并给出一些随机权重和偏差值。TensorFlow包含许多内置函数来初始化这些值。
为了初始化权重,我们使用 TensorFlow 的 'random_normal_initializer' 函数,该函数将使用正态分布随机初始化权重。'self.w' 以张量变量的形式包含权重的状态。这些状态将使用“w_init”进行初始化。作为权重包含的值将采用“float_32”格式。它设置为“可训练”,这意味着每次运行后,这些初始权重将根据损失函数和优化器进行更新。添加了名称“内核”,以便以后可以轻松跟踪。
为了初始化偏差,使用了TensorFlow的“zeros_initializer”函数。这会将所有初始偏置值设置为零。'self.b' 是一个张量,其大小与单位大小相同(此处为 32),这 32 个偏差项中的每一个最初都设置为零。这也设置为“可训练”,因此偏差项将在训练开始时更新。添加了名称“偏差”,以便以后能够追踪它。
“调用”是执行计算的最后一种方法。在这种情况下,由于它是一个密集层,它将输入乘以权重,添加偏差,最后返回输出。“matmul”运算用作 self.w 和 self.b 是张量而不是单个数值。
# declare an instance of the class
my_dense = SimpleDense(units=1)
# define an input and feed into the layer
x = tf.ones((1, 1))
y = my_dense(x)
# parameters of the base Layer class like `variables` can be used
print(my_dense.variables)输出:
[<tf.Variable 'simple_dense/kernel:0' shape=(1, 1) dtype=float32, numpy=array([[0.00382898]], dtype=float32)>,
<tf.Variable 'simple_dense/bias:0' shape=(1,) dtype=float32, numpy=array([0.], dtype=float32)>]上面代码的解释 — 第一行创建一个仅包含一个神经元的密集层(单位 = 1)。x(输入)是形状为 (1,1) 的张量,值为 1。Y = my_dense(x),有助于初始化密集层。“.variables”帮助我们查看在密集层中初始化的值(权重和偏差)。
“my_dense.variable”的输出显示在代码块下方。它表明“simple_dense”中有两个变量,称为“内核”和“偏差”。核 'w' 初始化值 0.0038,随机正态分布值,偏差 'b' 初始化值 0。这只是图层的初始状态。训练后,这些值将相应更改。
import numpy as np
# define the dataset
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
# use the Sequential API to build a model with our custom layer
my_layer = SimpleDense(units=1)
model = tf.keras.Sequential([my_layer])
# configure and train the model
model.compile(optimizer='sgd', loss='mean_squared_error') model.fit(xs, ys, epochs=500,verbose=0)
# perform inference
print(model.predict([10.0]))
# see the updated state of the variables
print(my_layer.variables)输出:
[[18.981567]]
[<tf.Variable 'sequential/simple_dense_1/kernel:0' shape=(1, 1) dtype=float32, numpy=array([[1.9973286]], dtype=float32)>,
<tf.Variable 'sequential/simple_dense_1/bias:0' shape=(1,) dtype=float32, numpy=array([-0.99171764], dtype=float32)>]上面代码的解释 - 上面使用的代码是检查自定义层是否工作的非常简单的方法。设置输入和输出,使用自定义层编译模型,最后训练 500 轮。重要的是要看到,训练模型后,权重和偏差的值现在已经发生了变化。最初设置为 0.0038 的权重现在为 1.9973,最初设置为零的偏差现在为 -0.9917。
四、向自定义密集层添加激活函数
之前我们创建了自定义 Dense 层,但我们没有随该层添加任何激活。当然,要添加激活,我们可以将激活编写为模型中的单独行,或者将激活添加为 Lambda 层。但是我们如何在上面创建的同一自定义层中实现激活。
答案是对自定义密集层中的“__init__”和“call”方法进行简单的调整。
class SimpleDense(Layer):# add an activation parameterdef __init__(self, units=32, activation=None):super(SimpleDense, self).__init__()self.units = units# define the activation to get from the built-in activation layers in Kerasself.activation = tf.keras.activations.get(activation)def build(self, input_shape):w_init = tf.random_normal_initializer()self.w = tf.Variable(name="kernel",initial_value=w_init(shape=(input_shape[-1], self.units),dtype='float32'),trainable=True)b_init = tf.zeros_initializer()self.b = tf.Variable(name="bias",initial_value=b_init(shape=(self.units,), dtype='float32'),trainable=True)super().build(input_shape)def call(self, inputs):# pass the computation to the activation layerreturn self.activation(tf.matmul(inputs, self.w) + self.b)上面代码的解释 — 大多数代码与我们之前使用的代码完全相同。
要添加激活,我们需要在“__init__”中指定我们需要激活。可以将激活对象的字符串或实例传递到此激活中。它设置为默认值为None,因此如果未提及激活函数,则不会引发错误。接下来,我们必须将激活函数初始化为 — 'tf.keras.activations.get(activation)'。
最后的编辑是在“调用”方法中,在计算权重和偏差之前,我们需要添加self.activation 来激活计算。所以现在的回报是计算和激活。
五、自定义密集层的完整代码,在 mnist 数据集上激活
import tensorflow as tf
from tensorflow.keras.layers import Layer
class SimpleDense(Layer):
def __init__(self, units=32, activation=None):super(SimpleDense, self).__init__()self.units = units# define the activation to get from the built-in activation layers in Keras
self.activation = tf.keras.activations.get(activation)def build(self, input_shape):
w_init = tf.random_normal_initializer()self.w = tf.Variable(name="kernel",initial_value=w_init(shape=(input_shape[-1], self.units),dtype='float32'),trainable=True)
b_init = tf.zeros_initializer()self.b = tf.Variable(name="bias",initial_value=b_init(shape=(self.units,), dtype='float32'),trainable=True)super().build(input_shape)def call(self, inputs):# pass the computation to the activation layer
return self.activation(tf.matmul(inputs, self.w) + self.b)
mnist = tf.keras.datasets.mnist(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# build the model
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),# our custom Dense layer with activationSimpleDense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10, activation='softmax')
])
# compile the model
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
# fit the model
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)使用我们的自定义密集层和激活来训练模型,训练准确度为 97.8%,验证准确度为 97.7%。
六、结论
这是在TensorFlow中创建自定义层的方法。即使我们只看到密集层的工作,它也可以很容易地被任何其他层所取代,例如执行以下计算的二次层——
它有 3 个状态变量:a、b 和 c,
计算:
![]()
将密集层替换为二次层:
import tensorflow as tf
from tensorflow.keras.layers import Layer
class SimpleQuadratic(Layer):def __init__(self, units=32, activation=None):'''Initializes the class and sets up the internal variables'''super(SimpleQuadratic,self).__init__()self.units=unitsself.activation=tf.keras.activations.get(activation)def build(self, input_shape):'''Create the state of the layer (weights)'''a_init = tf.random_normal_initializer()a_init_val = a_init(shape=(input_shape[-1],self.units),dtype= 'float32')self.a = tf.Variable(initial_value=a_init_val, trainable='true')b_init = tf.random_normal_initializer()b_init_val = b_init(shape=(input_shape[-1],self.units),dtype= 'float32')self.b = tf.Variable(initial_value=b_init_val, trainable='true')c_init= tf.zeros_initializer()c_init_val = c_init(shape=(self.units,),dtype='float32')self.c = tf.Variable(initial_value=c_init_val,trainable='true')def call(self, inputs):'''Defines the computation from inputs to outputs'''x_squared= tf.math.square(inputs)x_squared_times_a = tf.matmul(x_squared,self.a)x_times_b= tf.matmul(inputs,self.b)x2a_plus_xb_plus_c = x_squared_times_a+x_times_b+self.creturn self.activation(x2a_plus_xb_plus_c)
mnist = tf.keras.datasets.mnist(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),SimpleQuadratic(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10, activation='softmax')
])model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)该二次层在 mnist 数据集上的验证准确率为 97.8%。
因此,我们看到我们可以在 TensorFlow 模型中实现我们自己的层以及所需的激活,以编辑甚至提高整体精度。阿琼·萨卡尔