当你需要从大量数据中查找某个元素时,查找算法就变得非常重要。
无论你是初学者还是进阶者,本文将为你提供简单易懂、实用可行的知识点,帮助你更好地掌握查找在数据结构和算法中的重要性,进而提升算法解题的能力。接下来让我们开启数据结构与算法的奇妙之旅吧。
目录
查找的基本操作
二叉排序树
平衡二叉树
红黑树的基本操作
B树
哈希(散列)表基本操作
查找的基本操作
查找:在数据集合中寻找满足某种条件的数据元素的过程称为查找。
查找表:用于查找的数据集合称为查找表,它由同一类型的数据元素(或记录)组成。
关键字:数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的。
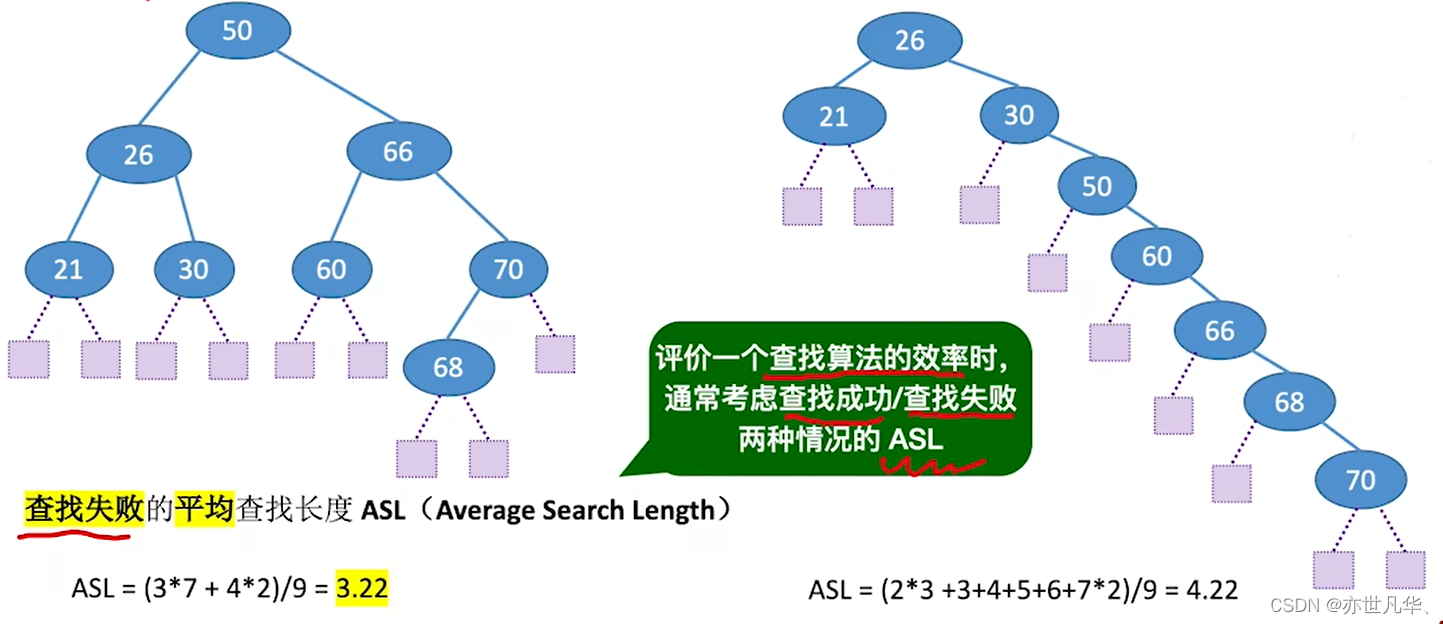
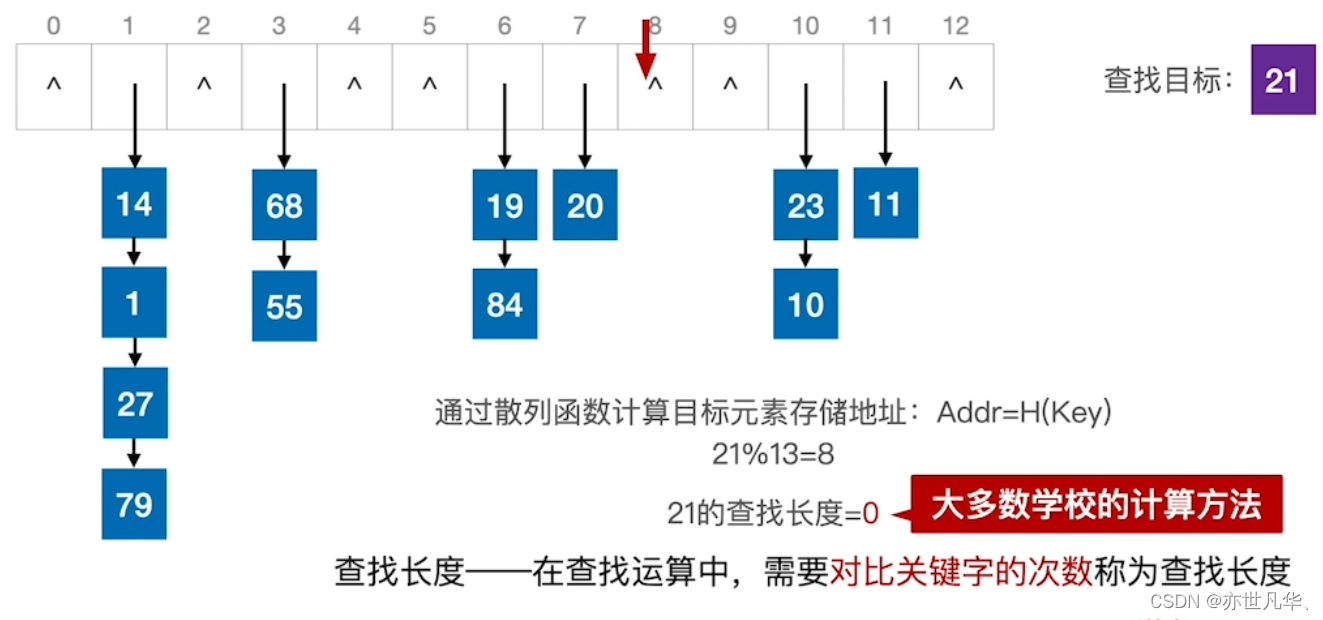
查找长度:在查找运算中,需要对比关键字的次数称为查找长度。
平均查找长度(ASL):所有查找过程中进行关键字的比较次数的平均值。
ASL的数量级反应了查找算法时间复杂度:
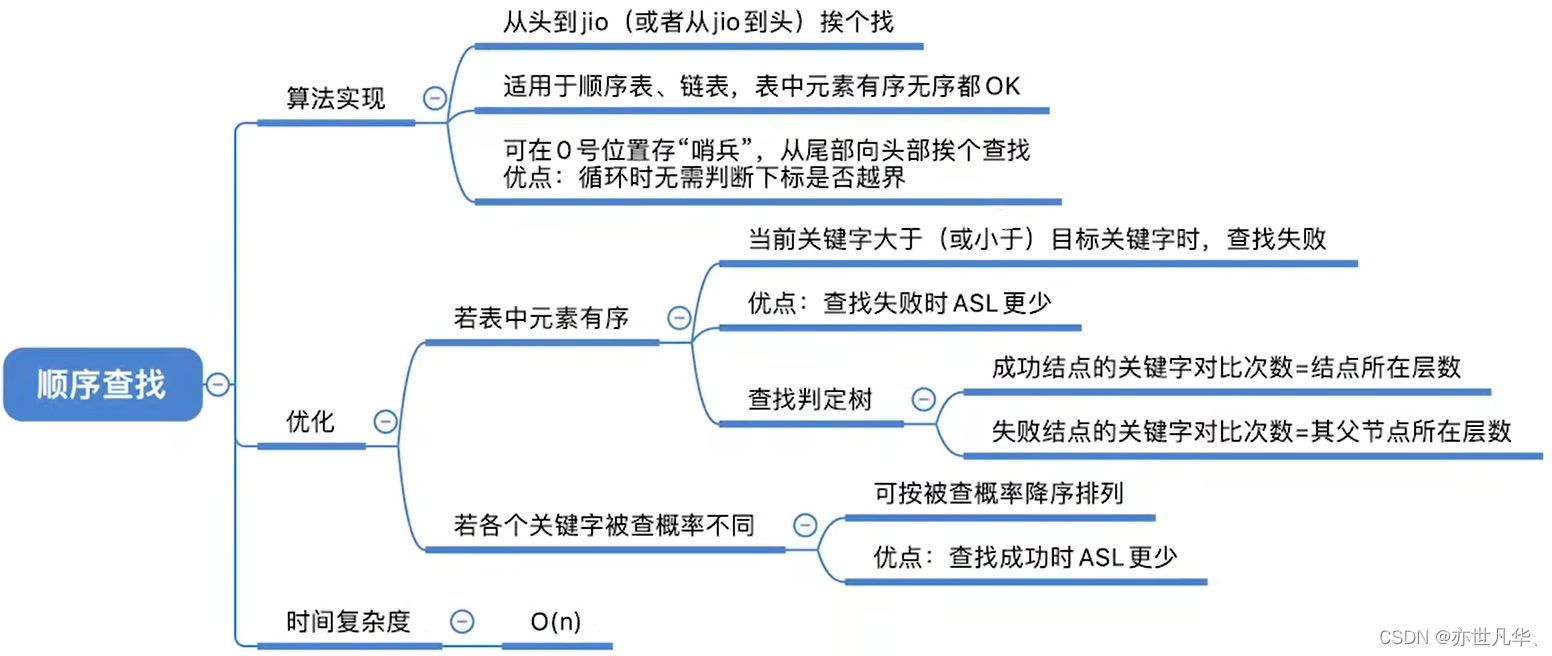
顺序查找又称 “线性查找”,通常用于线性表。其算法思想是:从头到尾挨个查找(反过来也可以)。
下面是用 C 语言实现顺序查找算法的基本代码示例:
#include <stdio.h>int sequentialSearch(int array[], int n, int target) {for (int i = 0; i < n; i++) {if (array[i] == target) {return i; // 找到匹配的元素,返回索引}}return -1; // 未找到匹配的元素,返回-1
}int main() {int array[] = {9, 5, 7, 3, 2, 8};int n = sizeof(array) / sizeof(array[0]);int target = 7;int result = sequentialSearch(array, n, target);if (result == -1) {printf("未找到目标元素\n");} else {printf("目标元素在索引 %d 处\n", result);}return 0;
}回顾重点,其主要内容整理成如下内容:
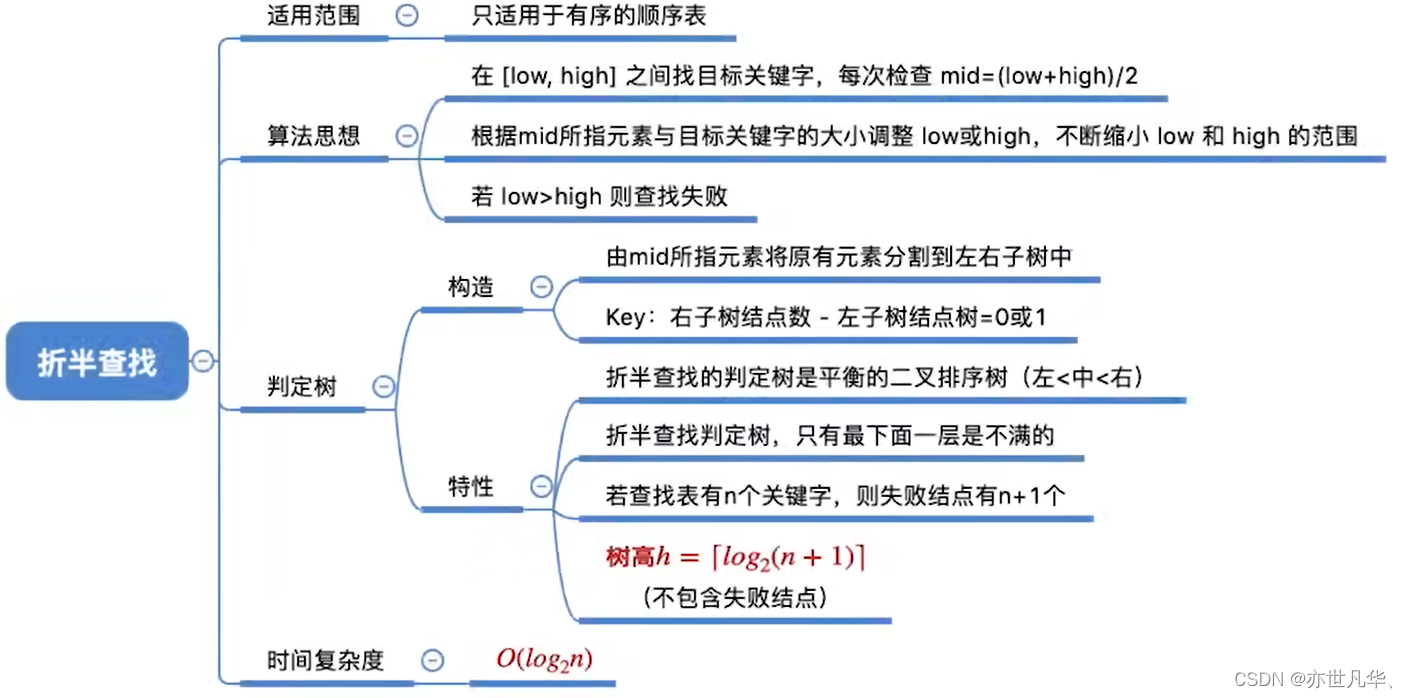
折半查找又称 “二分查找”,仅适用于有序的顺序表。二分查找通过将待查找的数据与数据集合的中间元素进行比较,从而将查找范围缩小一半,重复这个过程直到找到匹配的元素或者确定找不到为止。
下面是折半查找的相关概念及代码实现(使用C语言):
#include <stdio.h>int binarySearch(int array[], int low, int high, int target) {while (low <= high) {int mid = (low + high) / 2;if (array[mid] == target) {return mid; // 找到匹配的元素,返回索引} else if (array[mid] < target) {low = mid + 1; // 目标在当前中间元素的右侧} else {high = mid - 1; // 目标在当前中间元素的左侧}}return -1; // 未找到匹配的元素,返回-1
}int main() {int array[] = {2, 3, 5, 7, 8, 9};int n = sizeof(array) / sizeof(array[0]);int target = 7;int result = binarySearch(array, 0, n - 1, target);if (result == -1) {printf("未找到目标元素\n");} else {printf("目标元素在索引 %d 处\n", result);}return 0;
}回顾重点,其主要内容整理成如下内容:
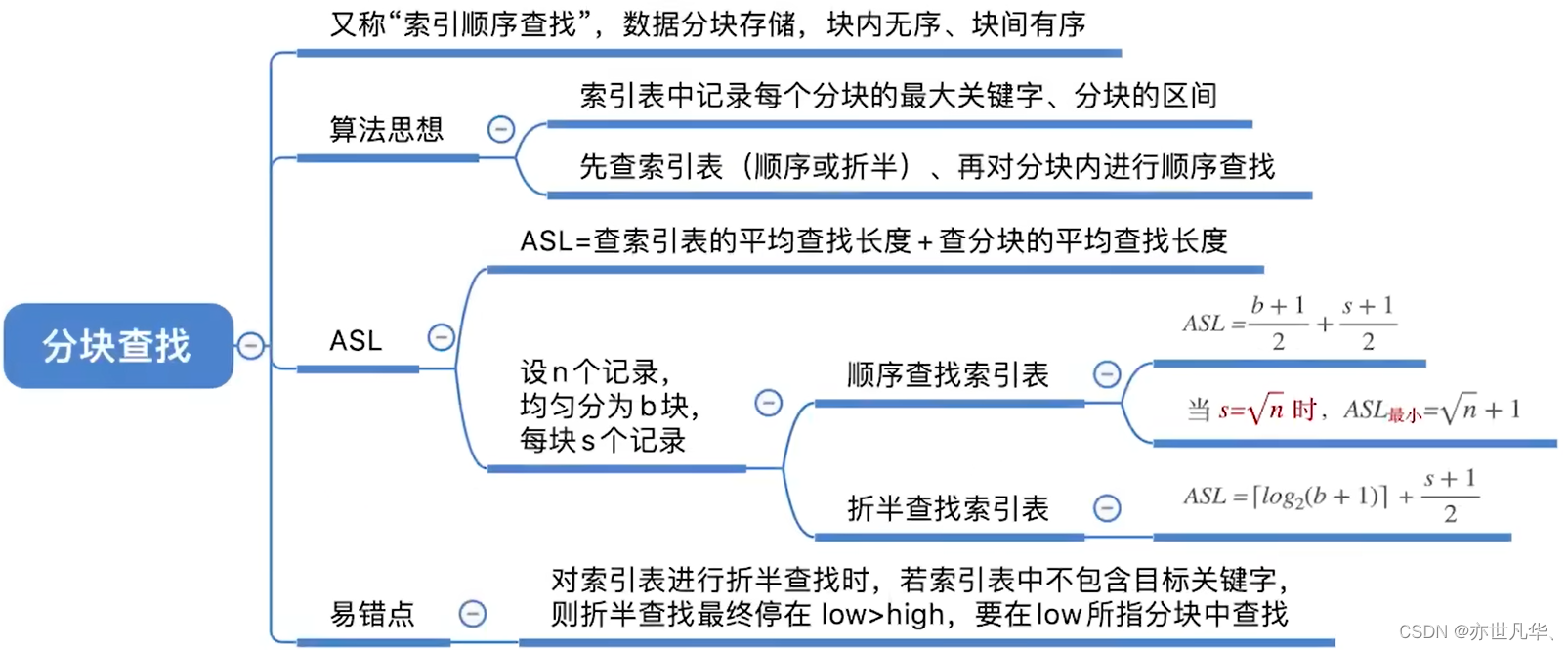
分块查找也称索引顺序查找,是一种将数据集合划分为多个块,并在每个块中建立索引来加速查找过程的一种查找算法。它适用于数据集合较大且有序的情况。
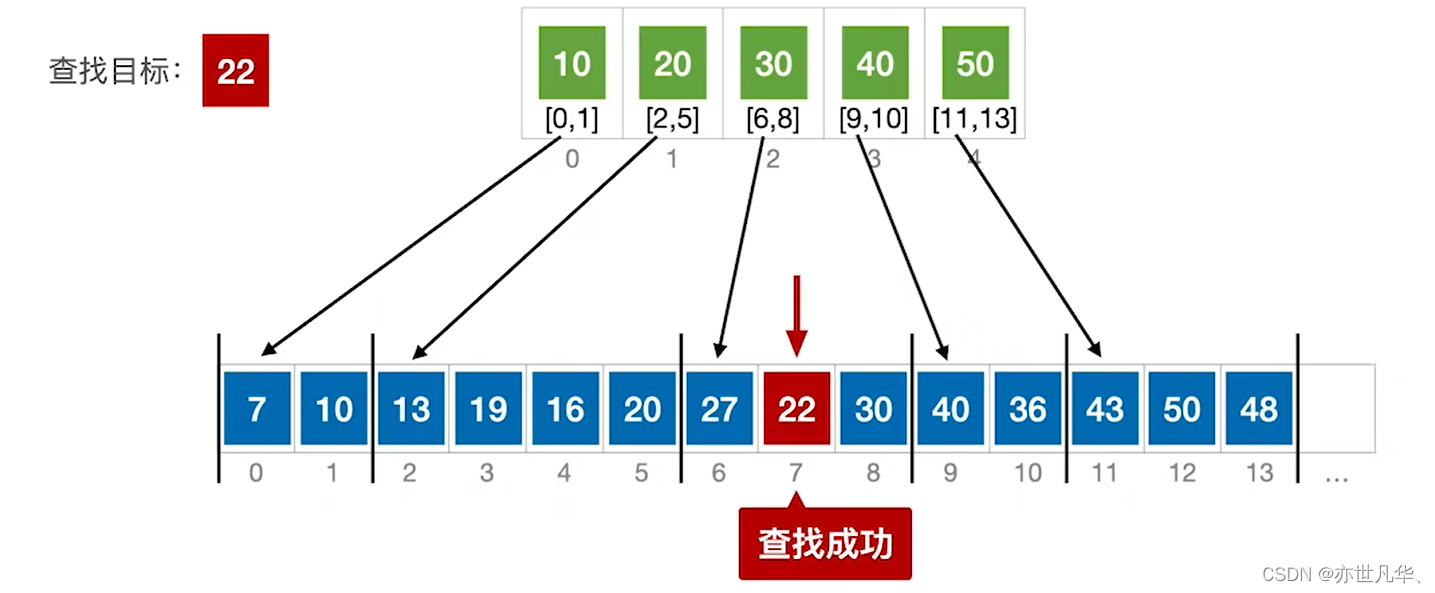
下面是分块查找的相关概念及代码实现(使用C语言):
#include <stdio.h>// 定义数据块结构
typedef struct {int index; // 索引值int max; // 当前块的最大值
} Block;int blockSearch(int blocks[], int n, int m, int target) {// 首先找到所在块的索引int blockIndex = -1;for (int i = 0; i < n; i++) {if (blocks[i].max >= target) {blockIndex = i;break;}}// 若未找到所在块,则目标元素不存在if (blockIndex == -1) {return -1;}// 在对应块内顺序查找目标元素int start = blockIndex * m; // 块的起始位置int end = (blockIndex + 1) * m - 1; // 块的结束位置for (int i = start; i <= end; i++) {if (blocks[i] == target) {return i; // 找到匹配的元素,返回索引}}return -1; // 未找到匹配的元素,返回-1
}int main() {Block blocks[] = {{0, 3}, {4, 7}, {8, 11}, {12, 14}};int n = sizeof(blocks) / sizeof(blocks[0]);int m = 4;int target = 10;int result = blockSearch(blocks, n, m, target);if (result == -1) {printf("未找到目标元素\n");} else {printf("目标元素在索引 %d 处\n", result);}return 0;
}回顾重点,其主要内容整理成如下内容:
二叉排序树
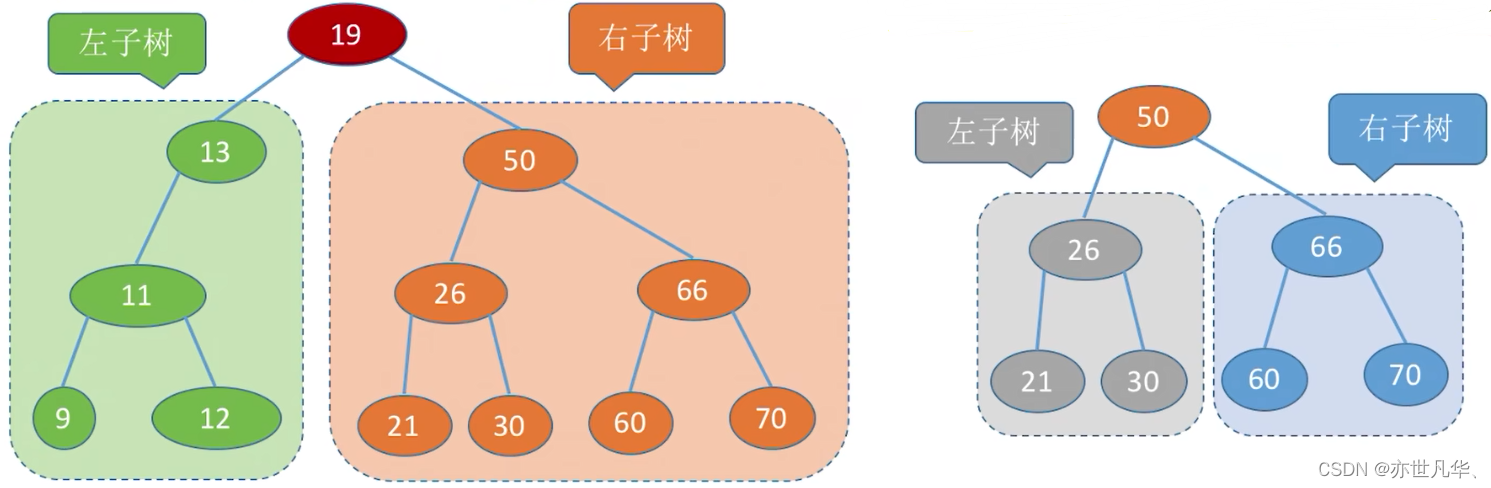
二叉排序树又称 “二叉查找树”,一颗二叉树或者是空二叉树,或者是具有如下性质的二叉树:
左子树上所有结点的关键字均小于根结点的关键字
右子树上所有结点的关键字均大于根结点的关键字
左子树和右子树又各是一颗二叉排序树:
以下是二叉排序树查找、插入、删掉等相关的操作代码:
#include <stdio.h>
#include <stdlib.h>// 二叉树节点定义
typedef struct TreeNode {int val;struct TreeNode* left;struct TreeNode* right;
} TreeNode;// 查找二叉排序树中是否存在指定值,存在返回1,不存在返回0
int searchBST(TreeNode* root, int val) {if (root == NULL) {return 0;}if (root->val == val) {return 1;} else if (root->val > val) {return searchBST(root->left, val);} else {return searchBST(root->right, val);}
}// 插入值为val的节点到二叉排序树中,返回插入后的根节点
TreeNode* insertBST(TreeNode* root, int val) {// 如果当前根节点为空,则直接将新节点插入if (root == NULL) {TreeNode* node = (TreeNode*)malloc(sizeof(TreeNode));node->val = val;node->left = NULL;node->right = NULL;return node;}// 如果val比当前根节点小,则递归插入到左子树中if (val < root->val) {root->left = insertBST(root->left, val);} else { // 否则递归插入到右子树中root->right = insertBST(root->right, val);}return root;
}// 删除值为val的节点,返回删除后的根节点
TreeNode* deleteBST(TreeNode* root, int val) {// 如果当前节点为空,则说明没有找到需要删除的节点,直接返回原根节点if (root == NULL) {return root;}// 如果需要删除的节点比当前根节点小,则递归删除左子树中的对应节点if (val < root->val) {root->left = deleteBST(root->left, val);return root;} else if (val > root->val) { // 否则递归删除右子树中的对应节点root->right = deleteBST(root->right, val);return root;}// 找到需要删除的节点if (root->left == NULL) { // 情况1:只有右子树TreeNode* right = root->right;free(root);return right;} else if (root->right == NULL) { // 情况2:只有左子树TreeNode* left = root->left;free(root);return left;} else { // 情况3:同时存在左右子树,选择用其前驱节点进行替代TreeNode* pred = root->left;while (pred->right != NULL) {pred = pred->right;}root->val = pred->val;root->left = deleteBST(root->left, pred->val);return root;}
}// 中序遍历二叉排序树,输出结果为有序序列
void inorder(TreeNode* root) {if (root == NULL) {return;}inorder(root->left);printf("%d ", root->val);inorder(root->right);
}int main() {// 构建二叉排序树TreeNode* root = NULL;root = insertBST(root, 5);insertBST(root, 3);insertBST(root, 7);insertBST(root, 2);insertBST(root, 4);insertBST(root, 6);// 查找操作printf("%d\n", searchBST(root, 4)); // 输出1printf("%d\n", searchBST(root, 8)); // 输出0// 删除操作root = deleteBST(root, 5);inorder(root); // 输出有序序列:2 3 4 6 7return 0;
}回顾重点,其主要内容整理成如下内容:
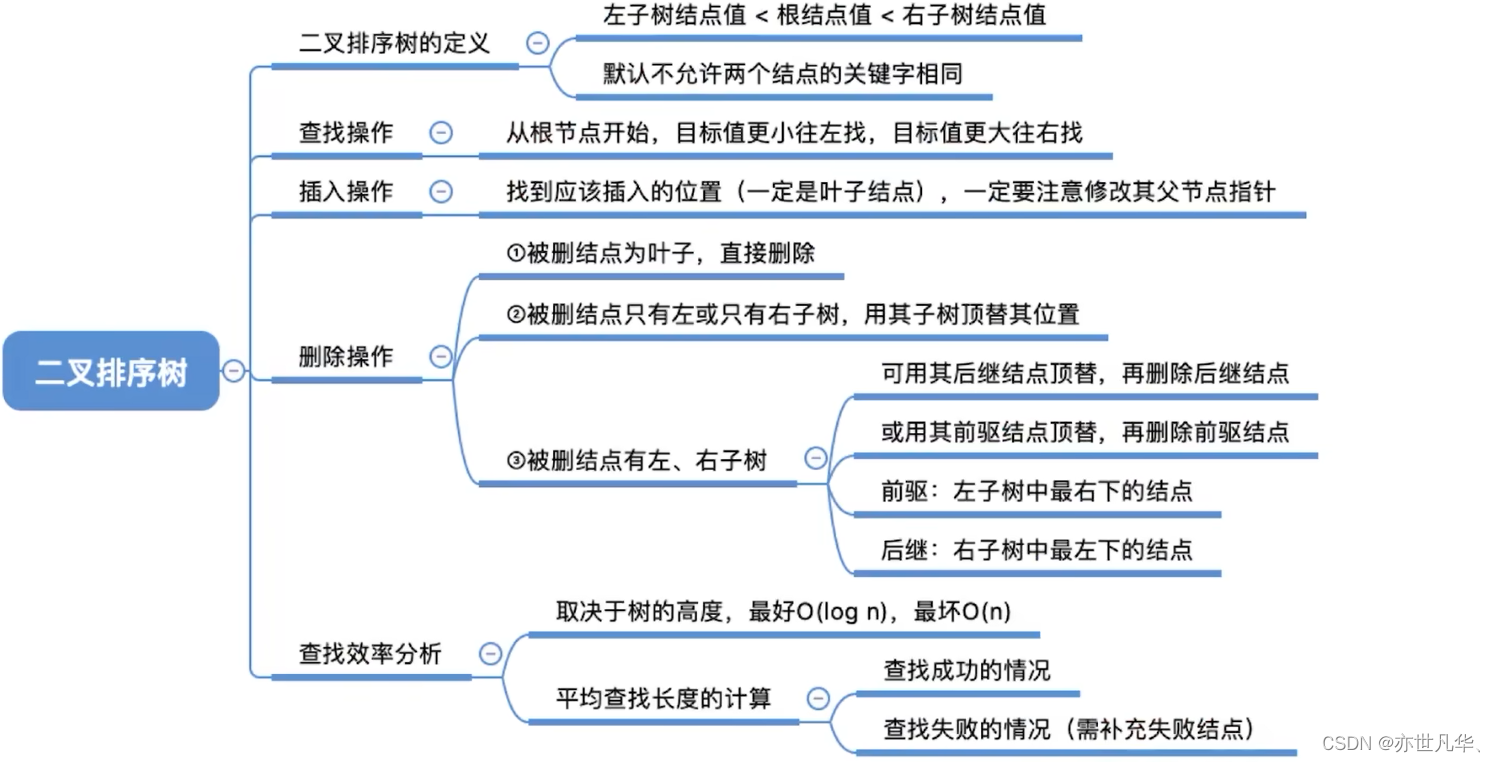
平衡二叉树
平衡二叉树也称为AVL树,是一种二叉排序树,它的左子树和右子树的高度差不超过1,即每个节点的左右子树的高度之差的绝对值都不超过1。
主要目的:在于保证二叉搜索树的查找效率。在普通的二叉搜索树中,如果出现极端情况(如数据有序插入),树高会退化为O(n),此时二叉搜索树的效率就与链表一样了。而平衡二叉树的高度始终保持在O(log n)级别,因此在大量动态插入和删除的数据操作时,平衡二叉树有着明显的优势。
结点的平衡因子 = 左子树高 - 右子树高。(结点的平衡因子的值只可能是 -1、0 或 1)
注意:只要有任一结点的平衡因子绝对值大于1,就不是平衡二叉树。

平衡二叉树的插入:每次调整的对象都是 “最小不平衡子树” , 在插入操作中只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡。
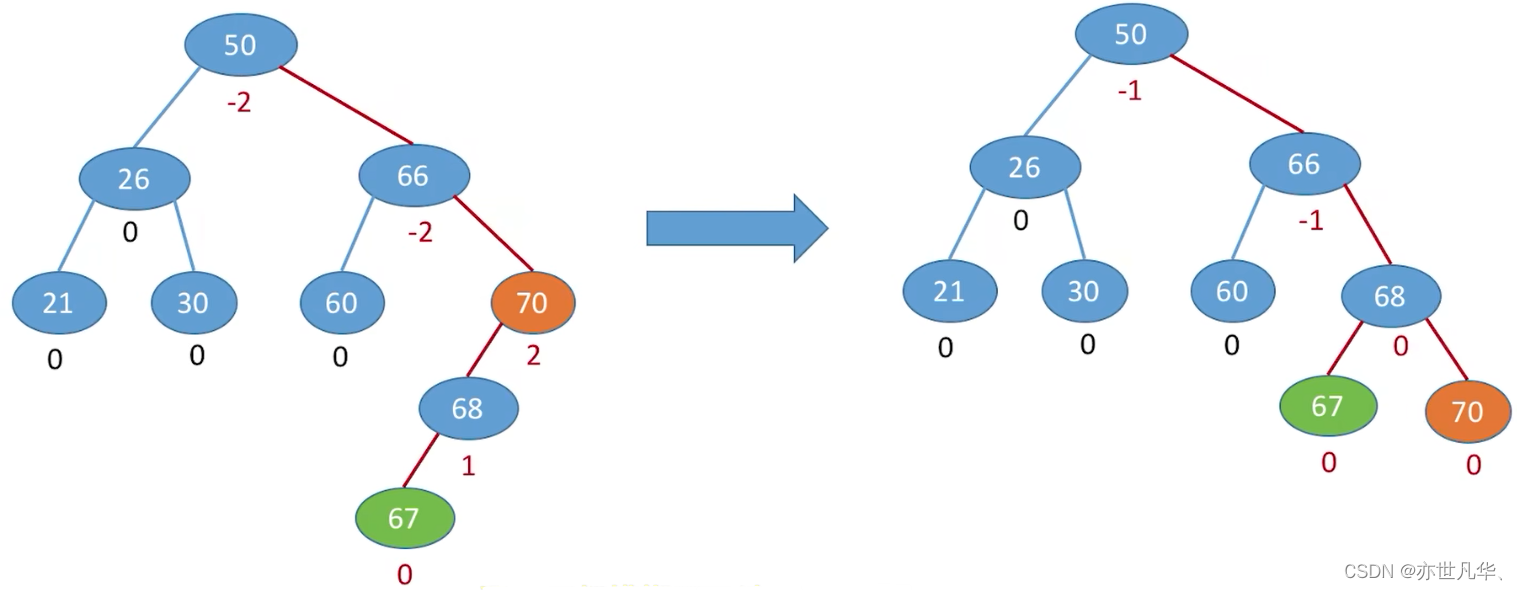
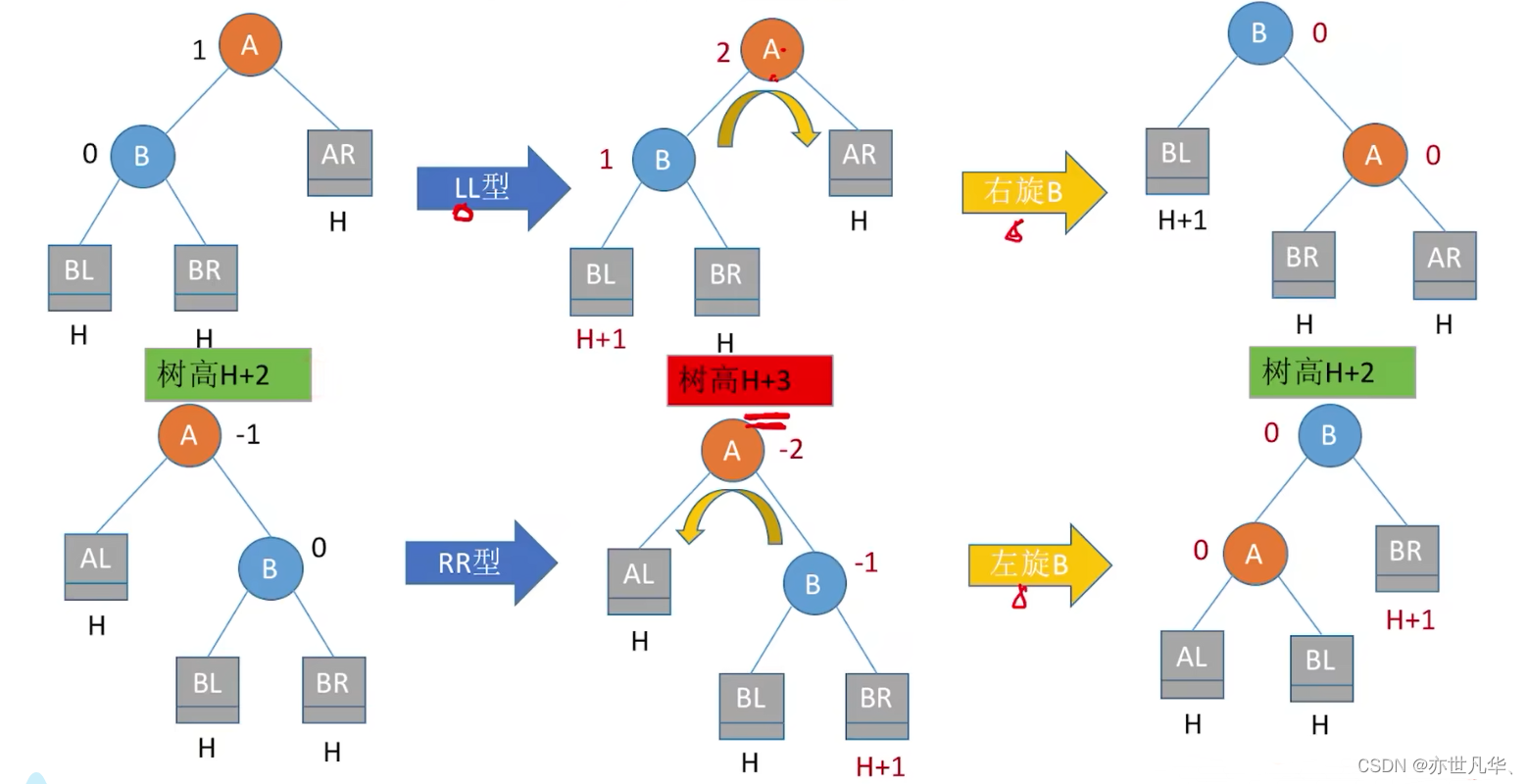
调整最小不平衡子树(LL):


调整最小不平衡子树(RR):


上面的两个代码思路大致如下:
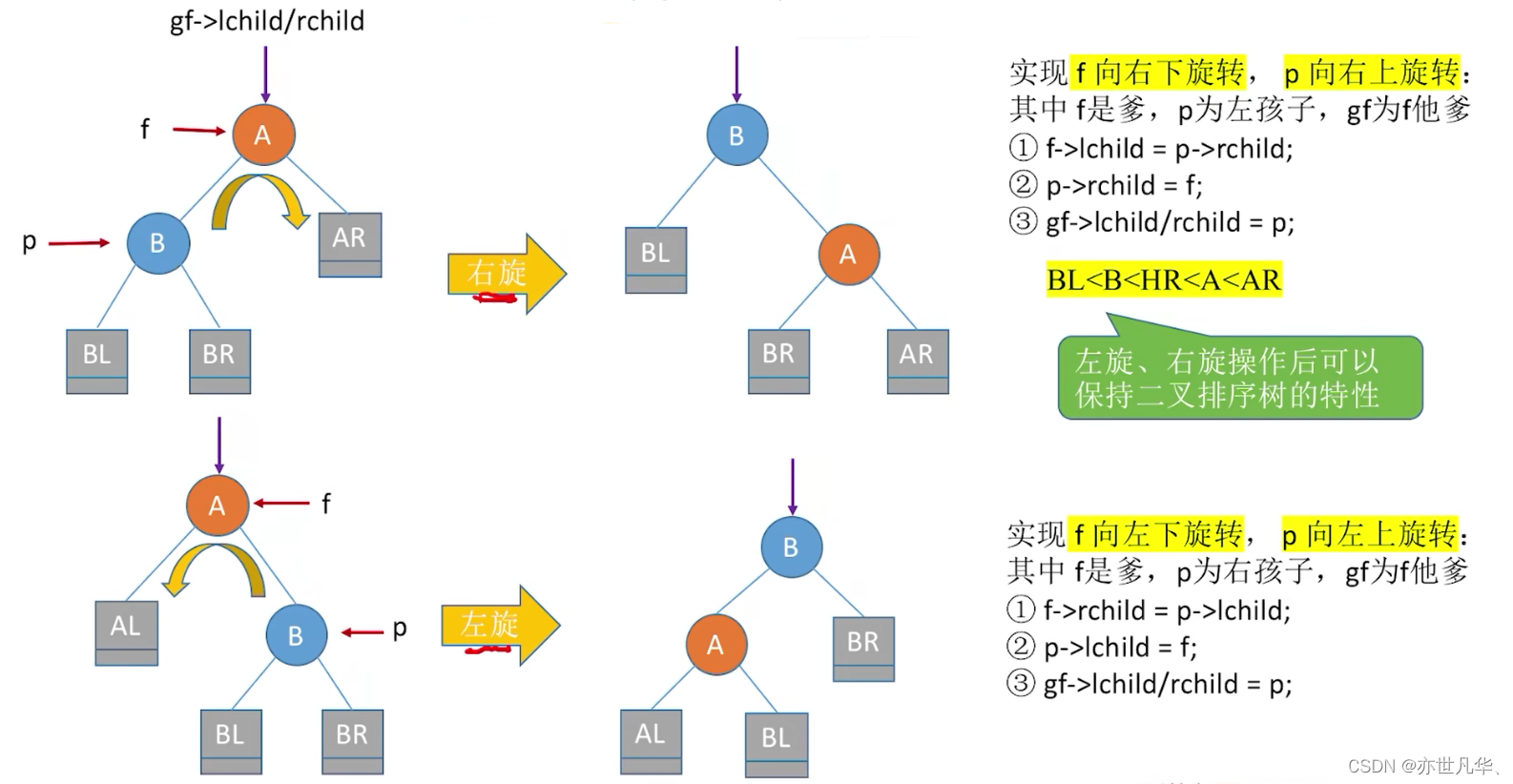
调整最小不平衡子树(LR):


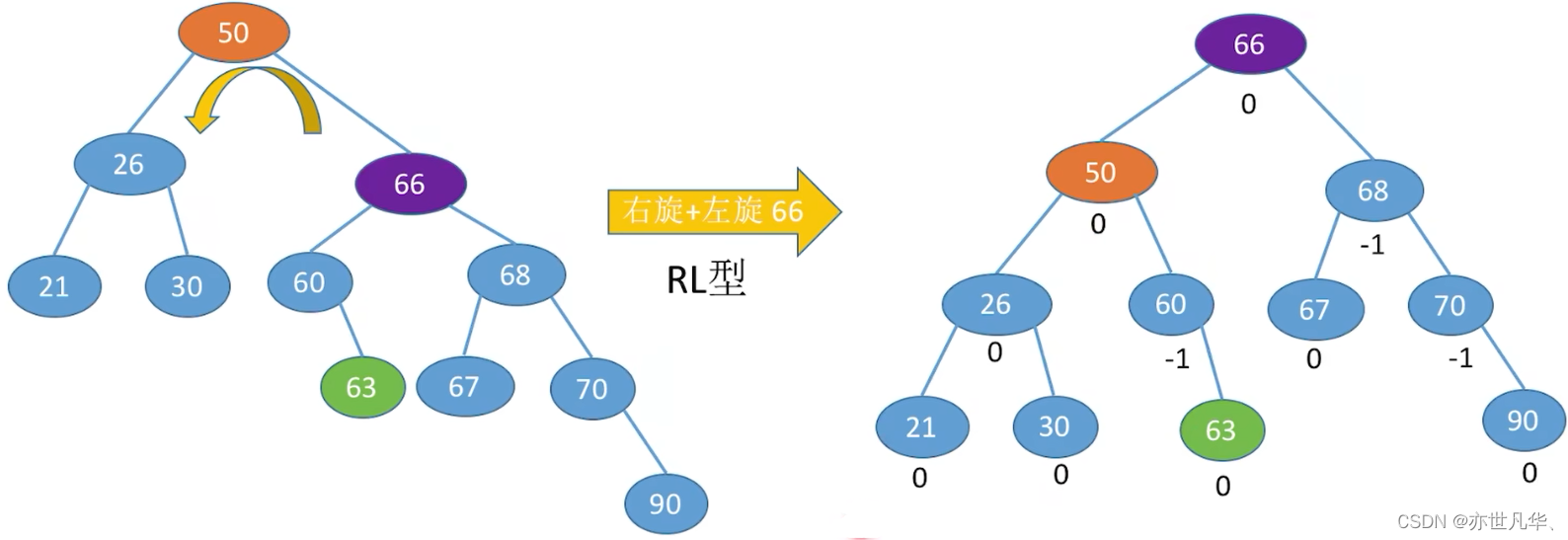
调整最小不平衡子树(RL):

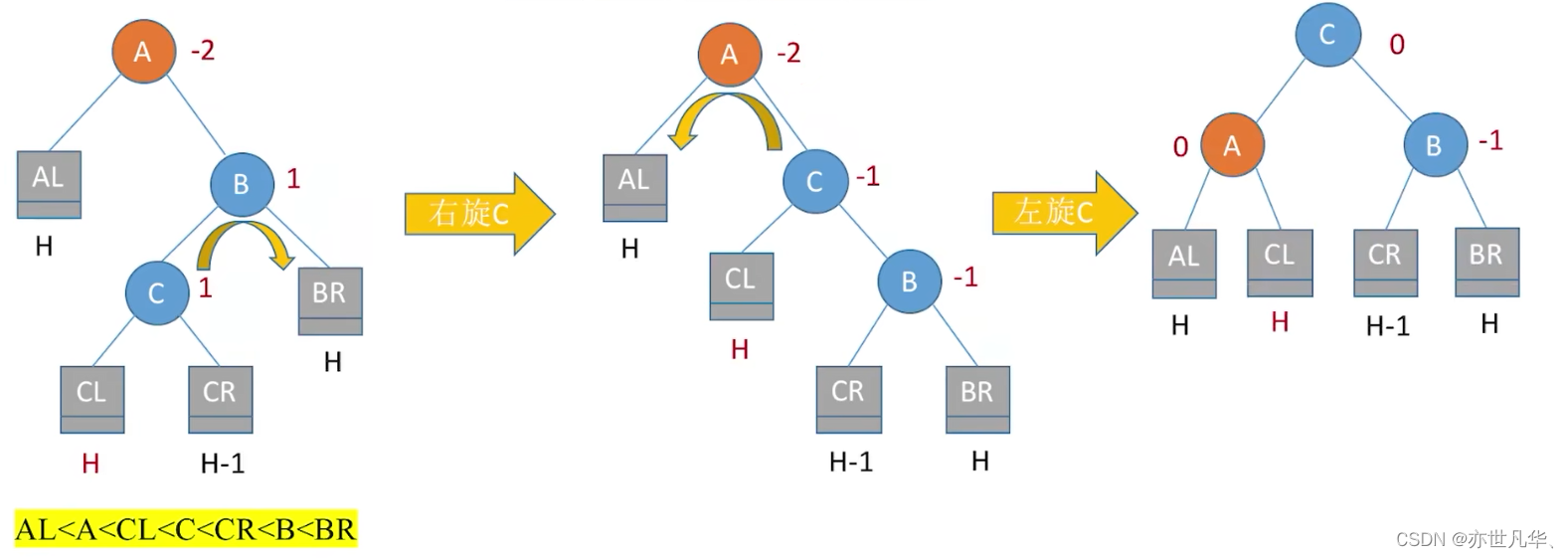
总结:

练习:



回顾重点,其主要内容整理成如下内容:

平衡二叉树的删除: 平衡二叉树的删除和插入操作有异曲同工之妙,其主要特点如下:
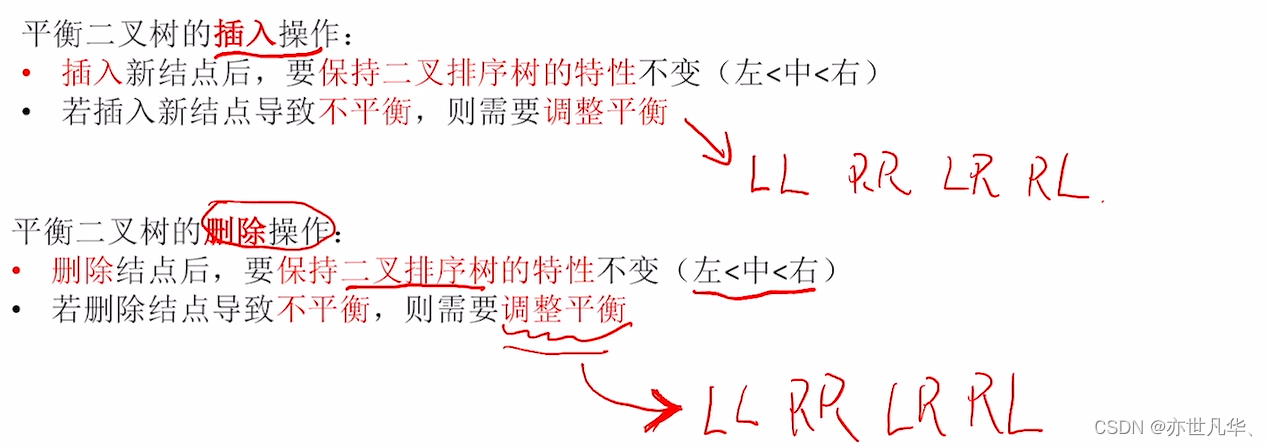
平衡二叉树的删除操作具体步骤:
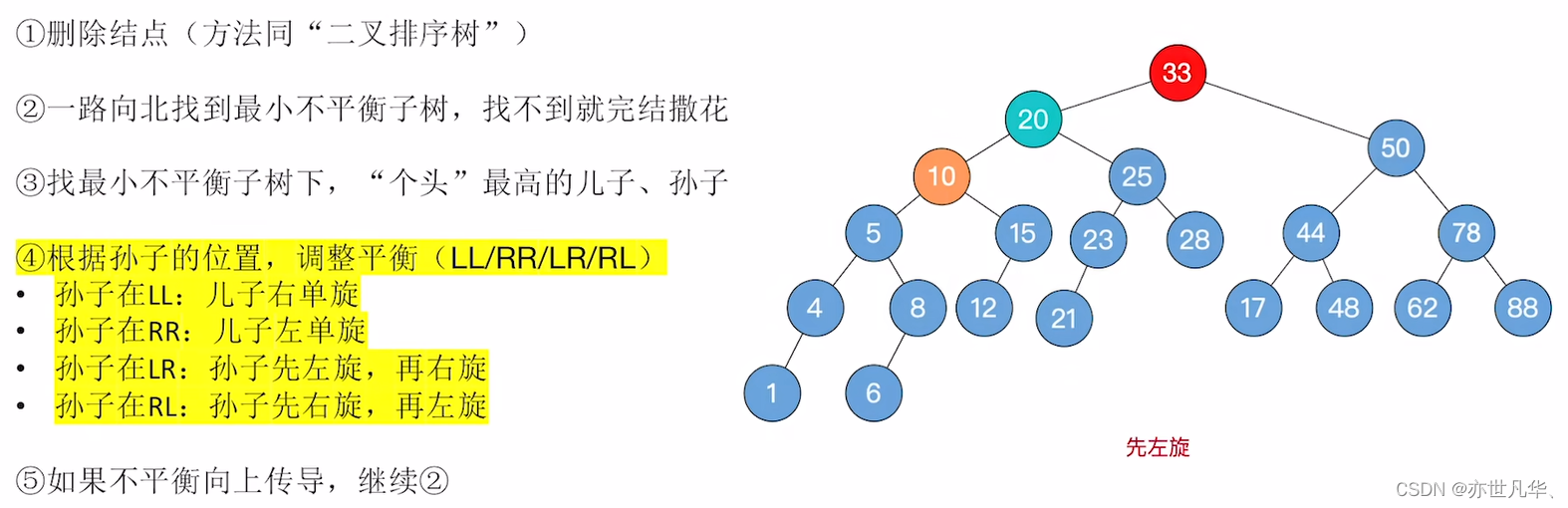
1)删除结点(方法同 “二叉排序树”)
2)一路向北(上 )找到最小不平衡子树,找不到就完结撒花
3)找最小不平衡子树下,“个头”最高的儿子、孙子
4)根据孙子的位置,调整平衡(LL/RR/LR/RL)
5)如果不平衡向上传导,继续2操作
具体的操作如下:

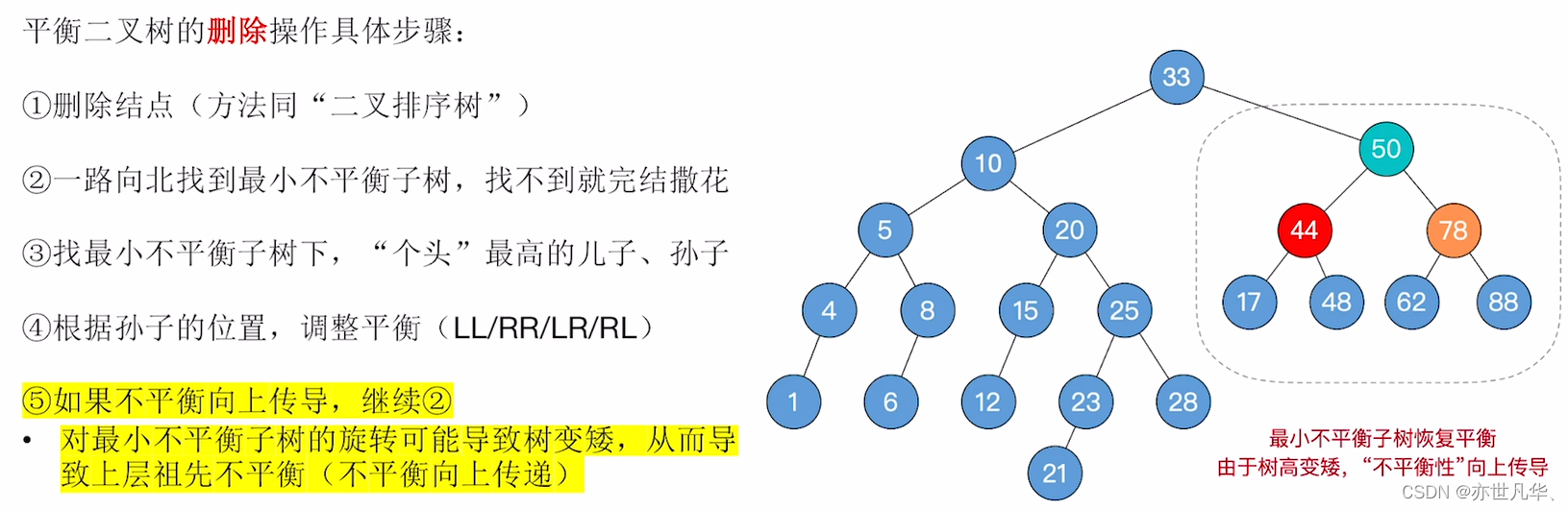
对最小不平衡子树的旋转可能导致树变矮,从而导致上层祖先不平衡(不平衡向上传递):

回顾重点,其主要内容整理成如下内容:

红黑树的基本操作
红黑树(Red-Black Tree)是一种自平衡二叉查找树,它在每个节点上增加了一个存储位表示节点的颜色,可以是红色或黑色。这个额外的颜色信息使得红黑树相较于普通的二叉查找树更加平衡,从而能够确保最坏情况下基本动态集合操作的时间复杂度为O(log n)。
平衡二叉树和红黑树的特点及其适用场景:

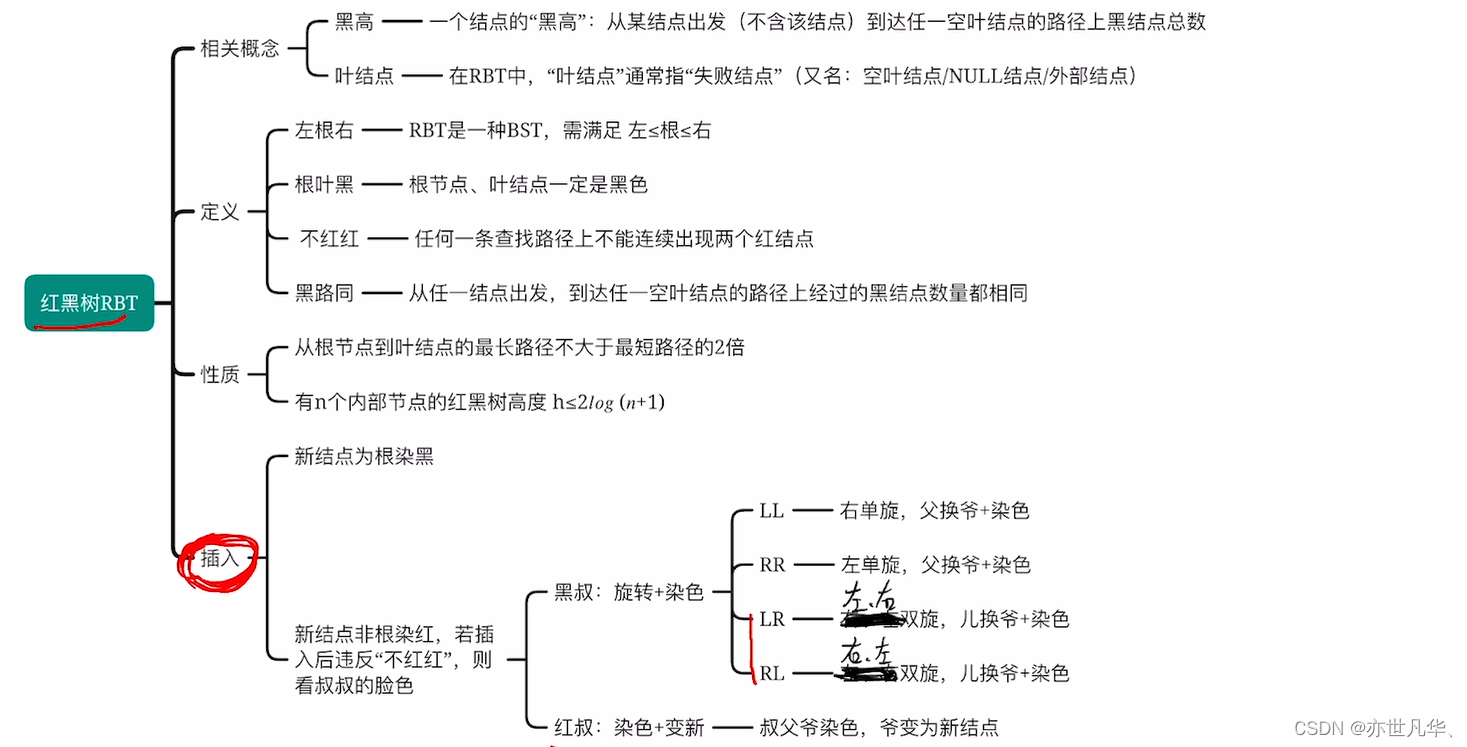
红黑树具有以下五个性质:
1)每个节点不是红色就是黑色。
2)根节点是黑色的。
3)每个叶子节点都是黑色的空节点(NIL节点)。
4)如果一个节点是红色的,则它的两个子节点都是黑色的。
5)对每个节点,从该节点到其所有后代叶子节点简单路径上,均包含相同数目的黑色节点。
将所有特性总结为的几句话:左根右、根叶黑、不红红、黑路同。
注意:1)从根结点到叶节点的最长路径不大于最短路径的2倍
2)从n个内部节点的红黑树高度
3)红黑树查找操作时间复杂度 =
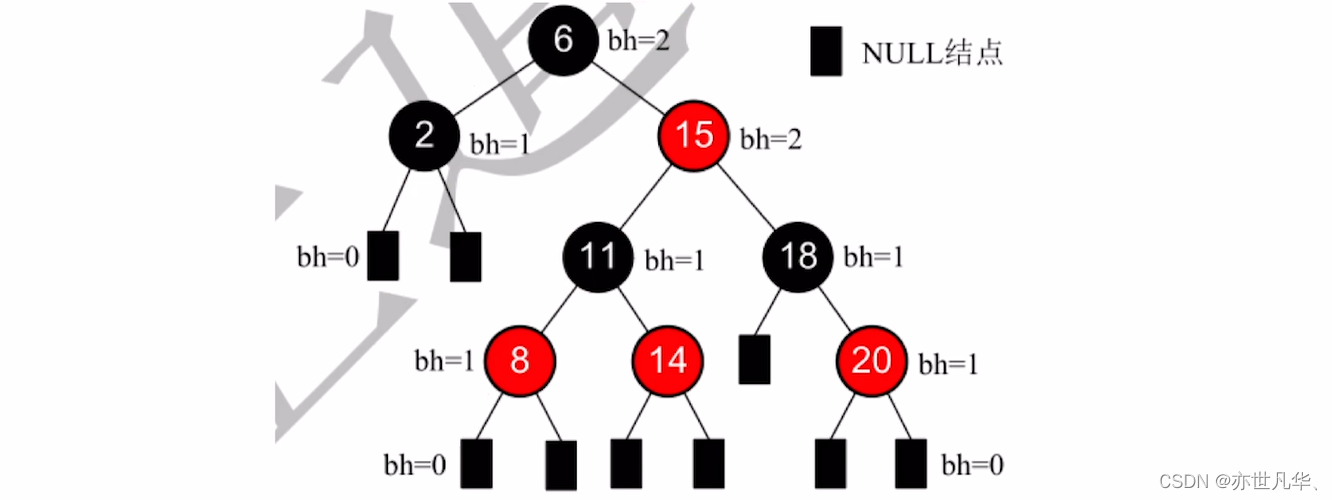
下面是一个简单的红黑树的实例:

结点的黑高bh:从某结点出发(不含该结点)到达任一空叶结点的路径上黑结点总数。
回顾重点,其主要内容整理成如下内容:
红黑树的删除操作:

B树
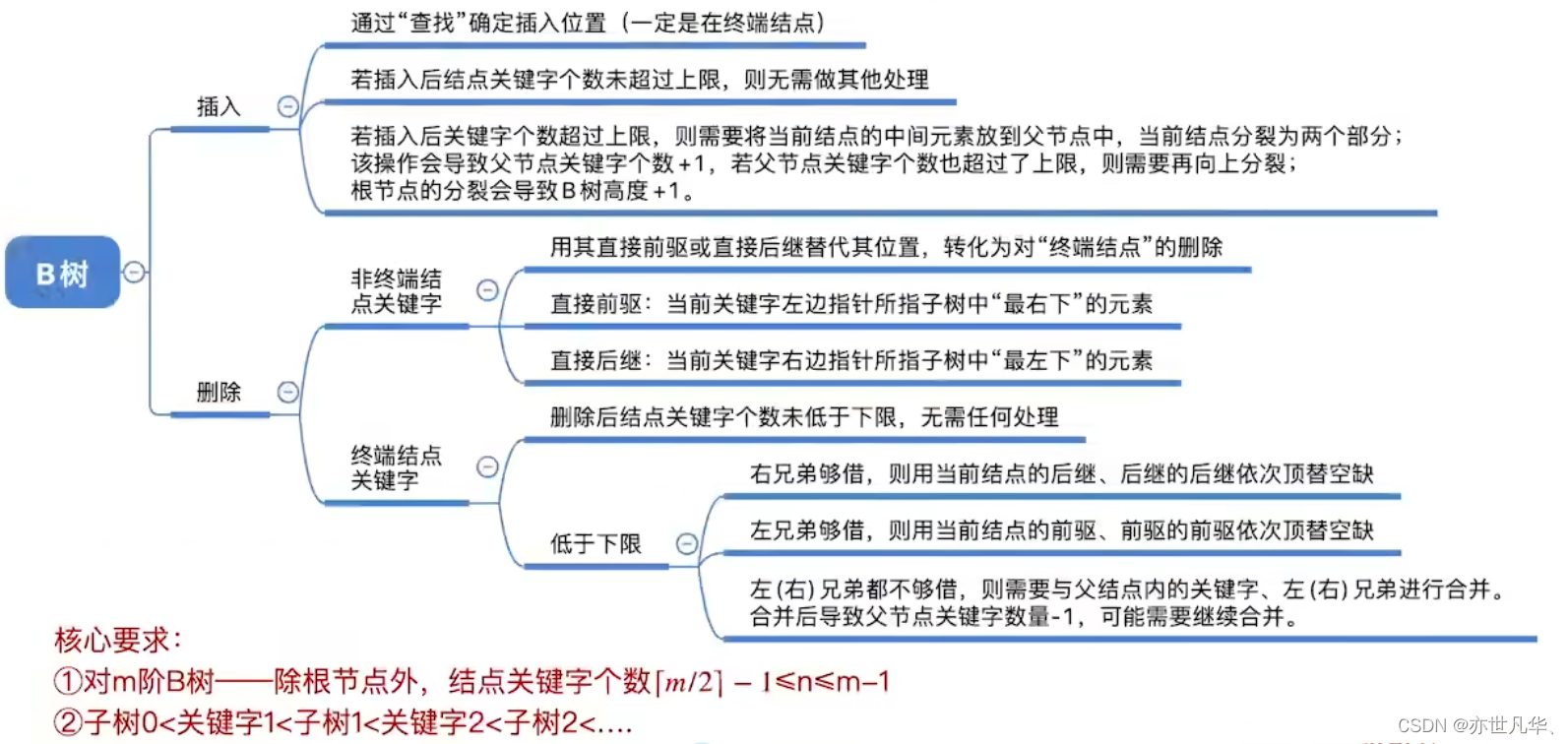
B树:又称多路平衡查找树,B树中所有结点的孩子个数的最大值称为B树的阶,通常用m表示。一颗m阶B树或为空树,或为满足如下特性的m叉树:
1)树中每个结点至多有m棵子树,即至多含有m-1个关键字。
2)若根结点不是终端结点,则至少有两棵子树。
3)除根结点外的所有非叶结点至少有[m/2]棵子树,即至少含有[m/2]-1个关键字。
4)所有的叶结点都出现在同一层次上,并且不带信息(可以视为外部结点或类似于折半查找找判定树的查找失败结点,实际上这些结点不存在,指向这些结点的指针为空)。
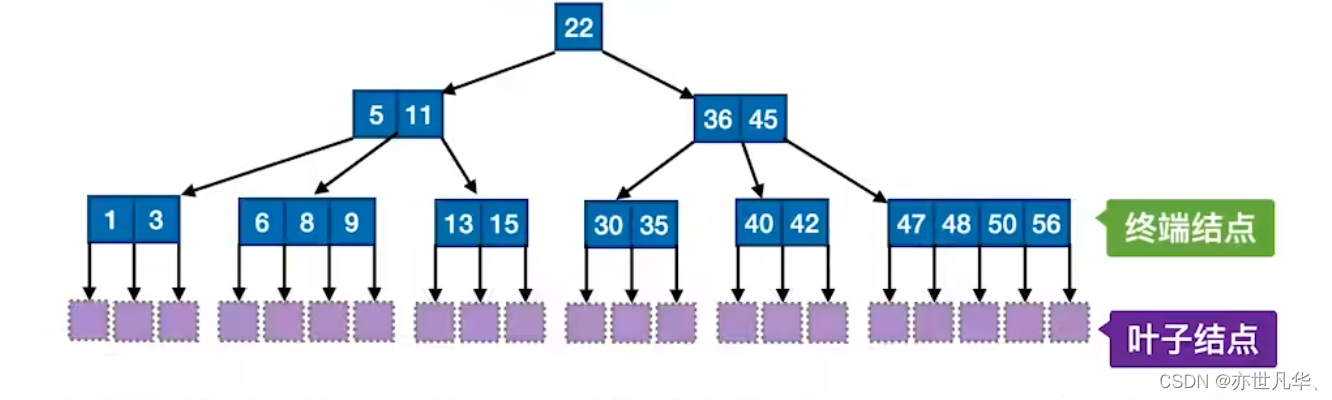

B树的高度:一般求解含n个关键字的m阶B树,最小高度和最大高度是多少?(不包含叶子结点)


B树的插入:


B树的删除: 若被删除关键字在非终端结点,则用直接前驱或直接后继来替代被删除的关键字。
直接前驱:当前关键字左侧指针所指子树下的 “最右下” 的元素。
直接后继:当前关键字右侧指针所指子树中的 “最坐下” 的元素。
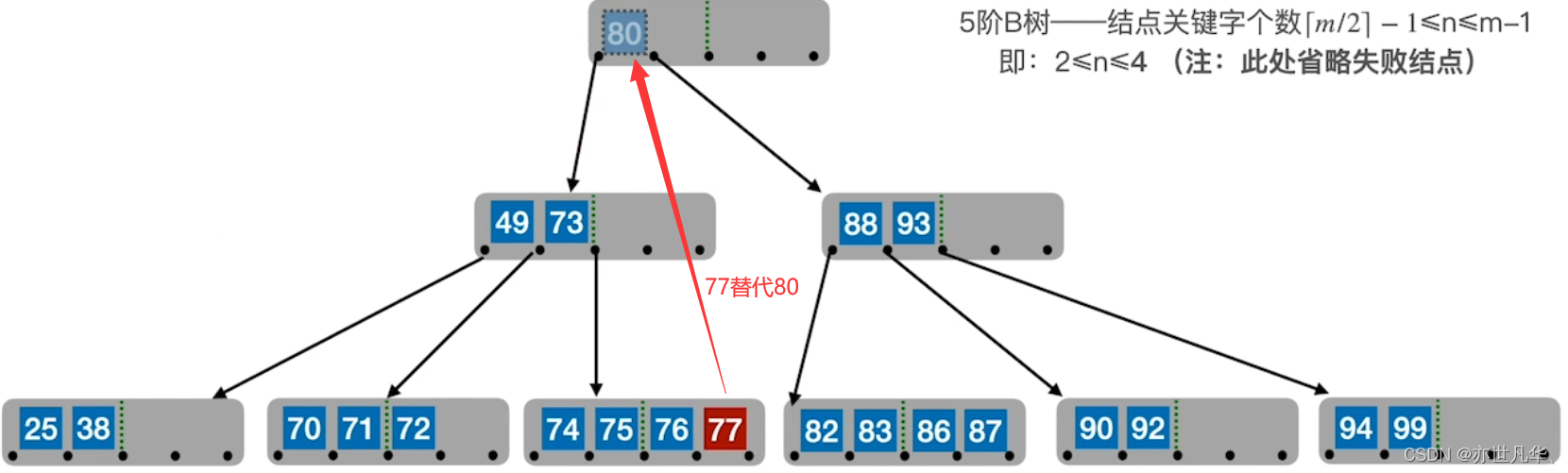
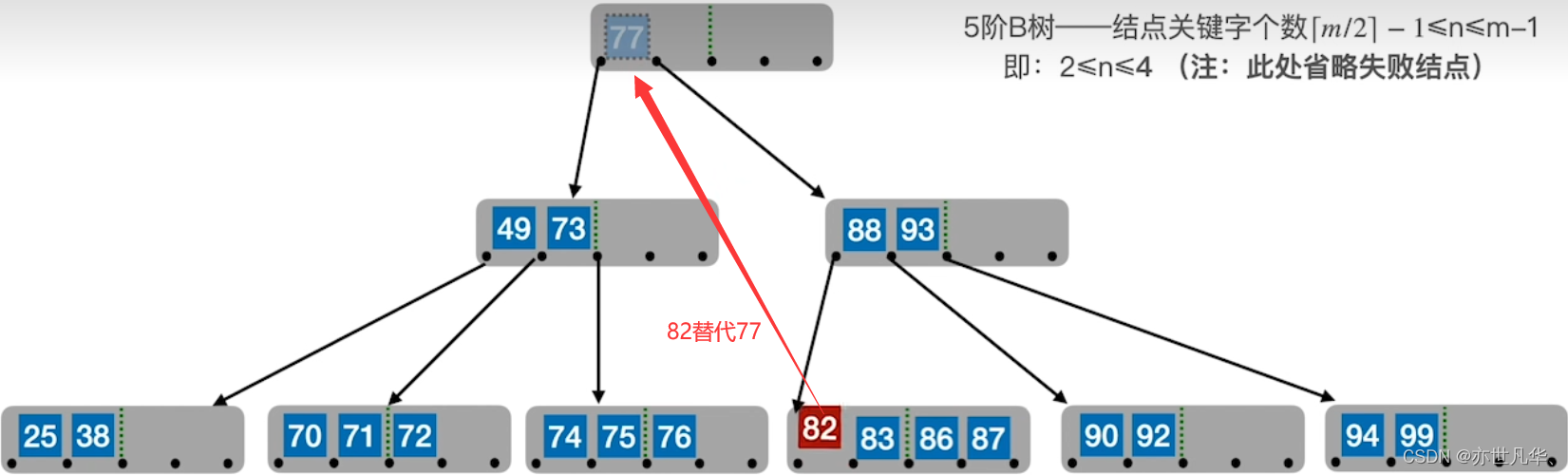

回顾重点,其主要内容整理成如下内容:
B+树的相关概念:
B+树是一种变种的B树,也是一种自平衡的搜索树。一棵m阶的B+树满足下列条件:
1)每个分支结点最多有m棵子树(孩子结点)。
2)非叶根结点至少有两棵子树,其他每个分支结点至少有[m/2] 棵子树。
3)结点的子树个数与关键字个数相等
4)所有叶结点包含全部关键字及指向相应记录的指针,叶节点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序相互链接起来。
5)所有分支结点中仅包含它的各个子节点中关键字的最大值及指向其子节点的指针。
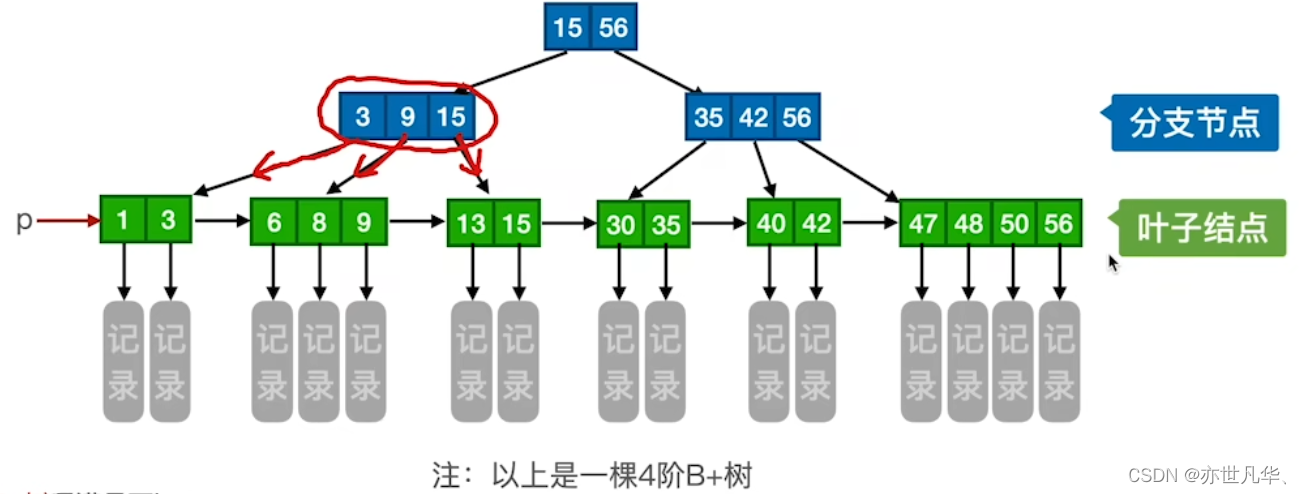
B+树的查找:无论查找成功与否,最终一定都要走到最下面一层结点。

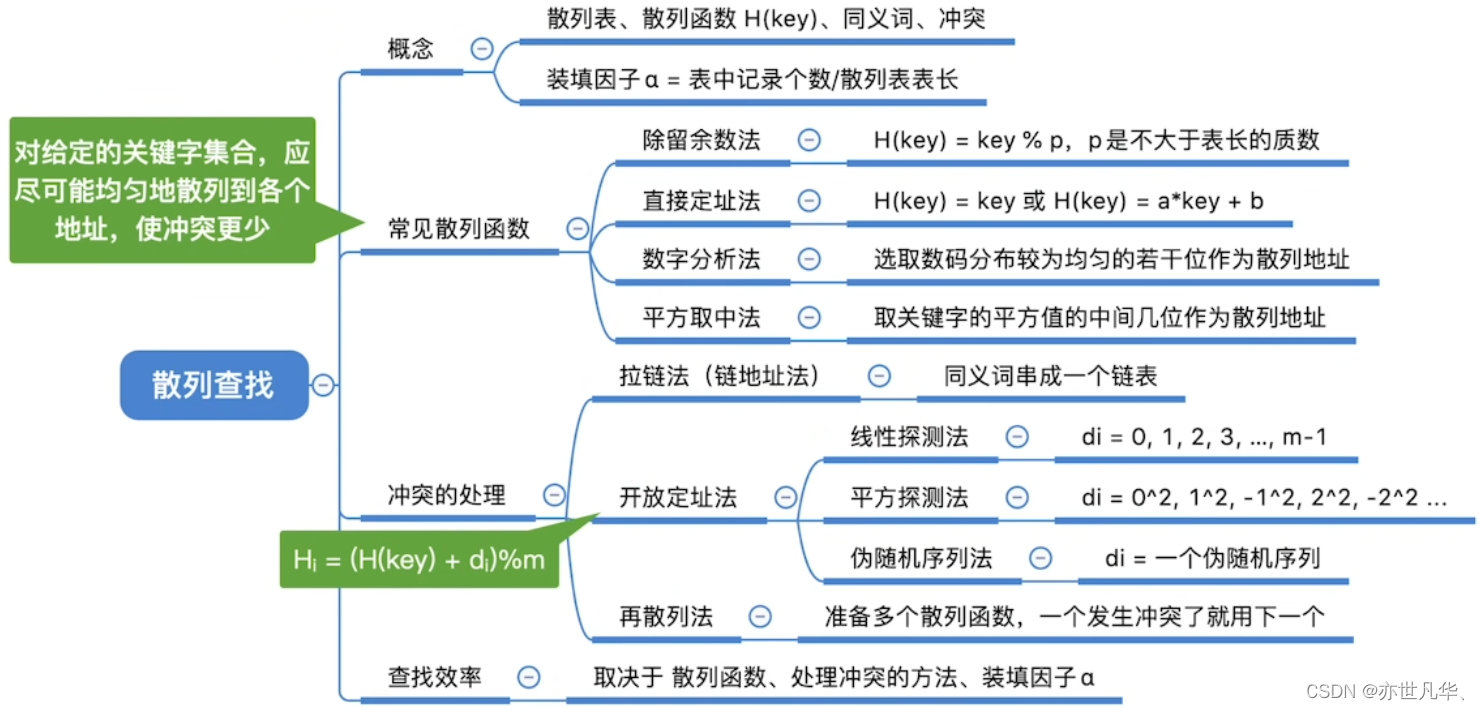
哈希(散列)表基本操作
哈希表又称散列表,是一种数据结构,特点是:数据元素的关键字与其存储地址直接相关。
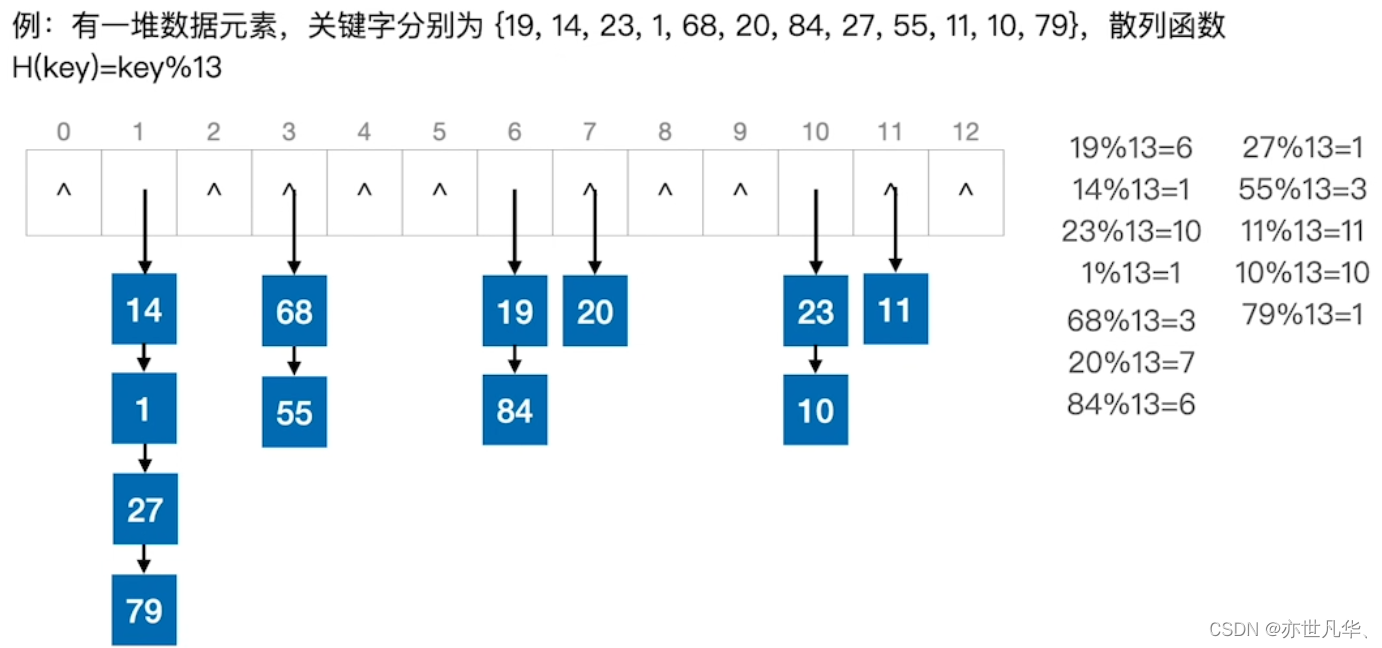
举出以下一个例子进行简单的说明:
用拉链法(又称链接法、链地址法)处理“冲突”:把所有“同义词”存储在一个链表中。
若不同的关键字通过散列函数映射到同一个值,则称它们为 “同义词”;
通过散列函数确定的位置已经存放了其他元素,则称这种情况为 “冲突”。
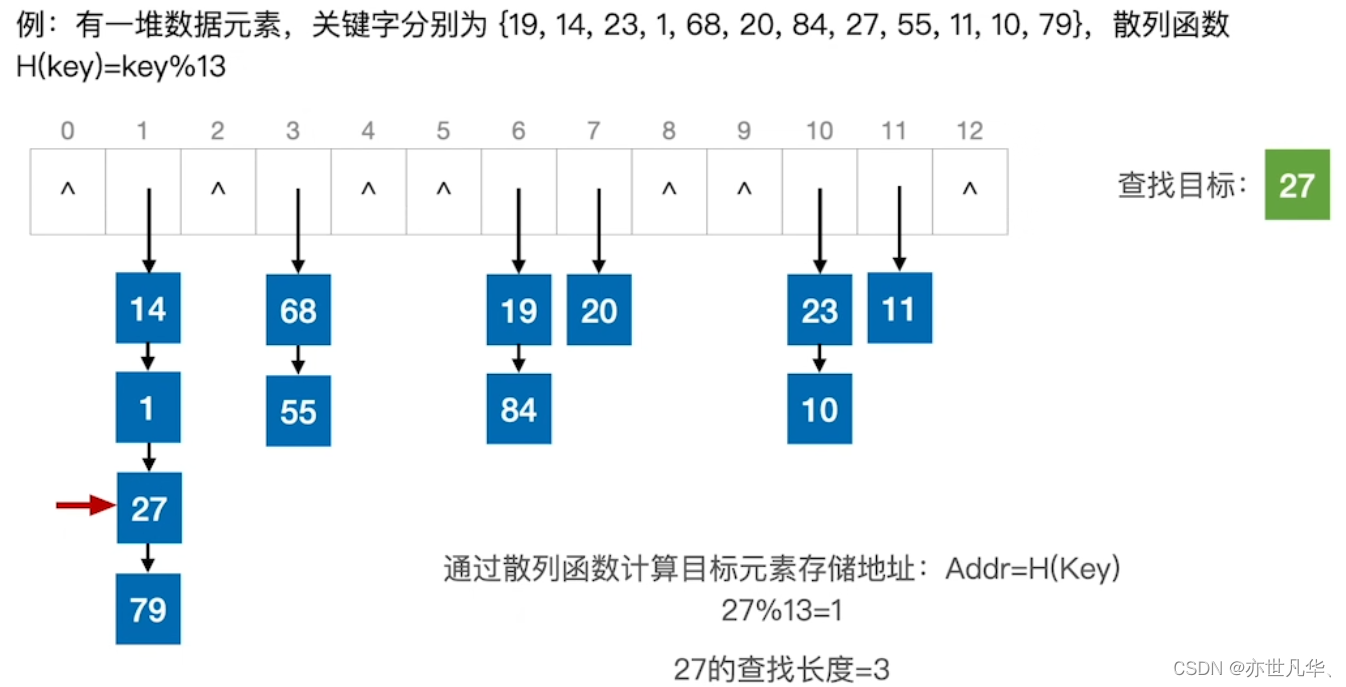
散列查找: 我们可以通过散列函数计算目标元素存储地址,然后遍历该地址来找到我们的目标
如果查找失败的情况下,比如如下的这俩种情况:
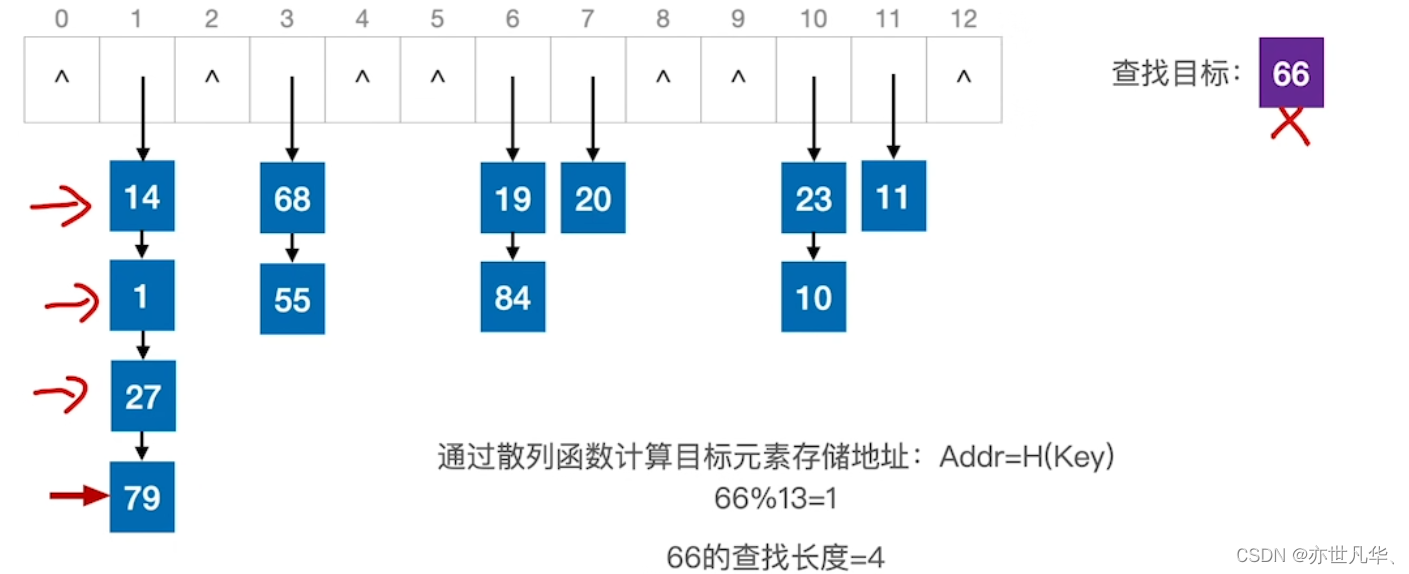
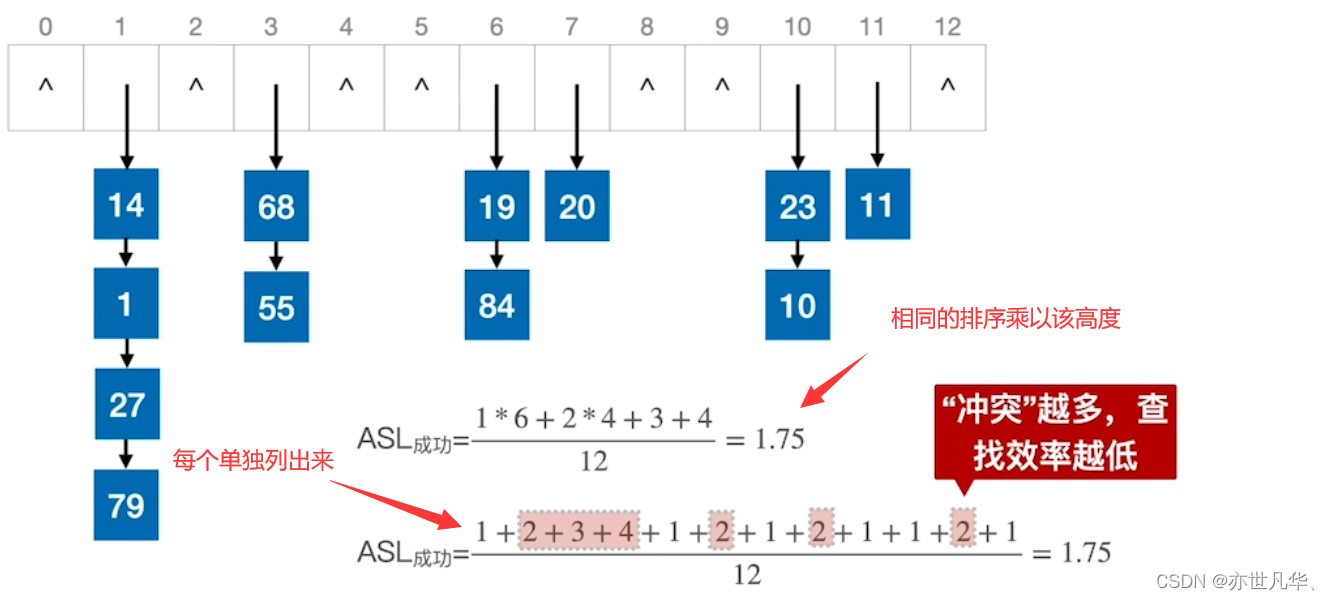
平均查找长度:如果想求解平均查找长度的话可以采用如下方式进行:

装填因子:装填因子越大表明冲突越大,查找效率越低。

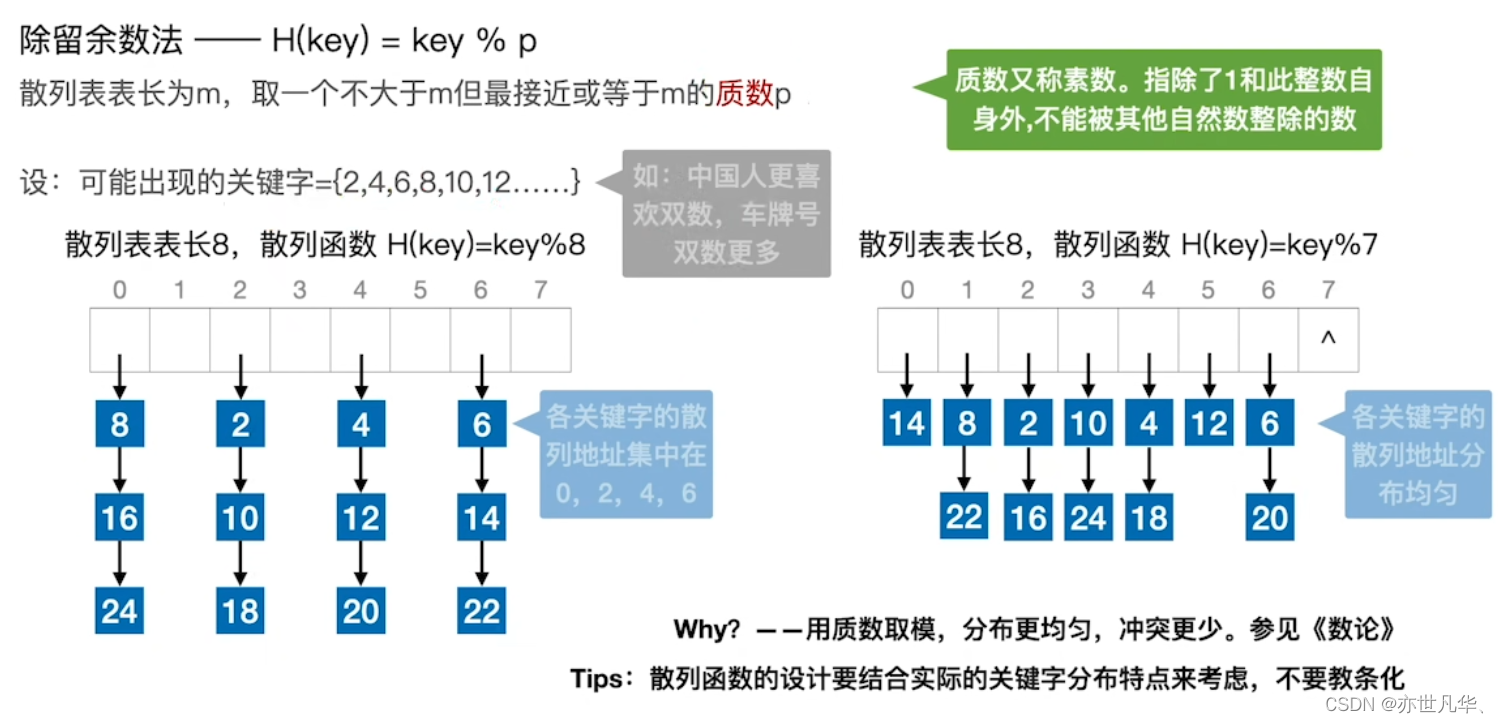
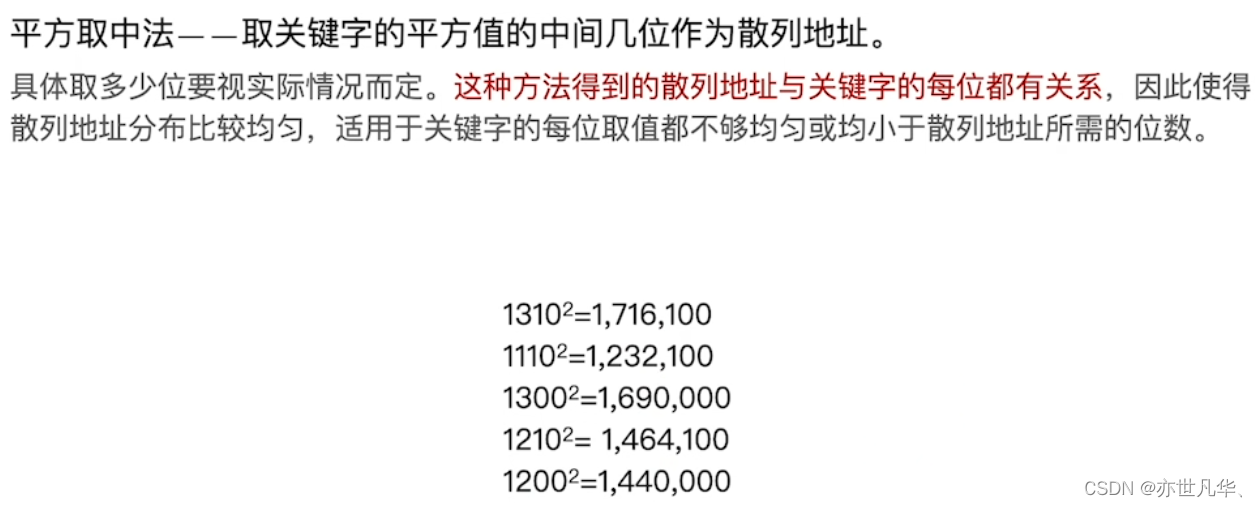
常见散列函数的设计方法:(设计目标:让不同关键字的冲突尽可能的减少)


散列表处理冲突的方法:

开放定址法有以下三种方式进行:
线性探测法:如果当前的位置冲突,往后面找有空位的地方然后进入即可。

如果想进行查找的话也可以采用如下的方式:(分别是成功和失败的情况)


查找效率分析的话如下:


平方探测法:根据d给出的公式依次带入找到对应的值

伪序列随机法:根据提供的d值进行存放:

总结:

再散列法:

回顾重点,其主要内容整理成如下内容: