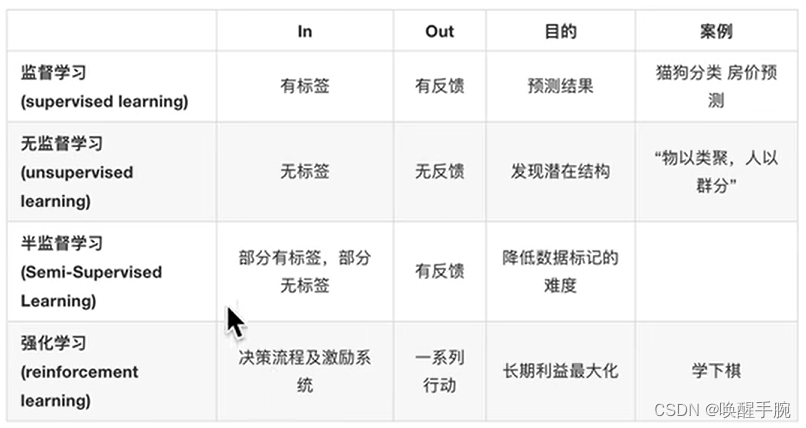
一、说明
亮点:对象检测是计算机视觉中最重要的任务之一。在这篇文章中,我们将概述最有影响力的对象检测算法家族之一:R-CNN、Fast R-CNN 和 Faster R-CNN。我们将重点介绍它们中的每一个的主要新颖性和改进。
最后,我们将专注于 Faster R-CNN,并探索代码以及如何在 PyTorch 中使用它。
教程概述:
- 物体检测简介
- R-CNN
- 快速RCNN
- 更快的RCNN
- PyTorch 实现
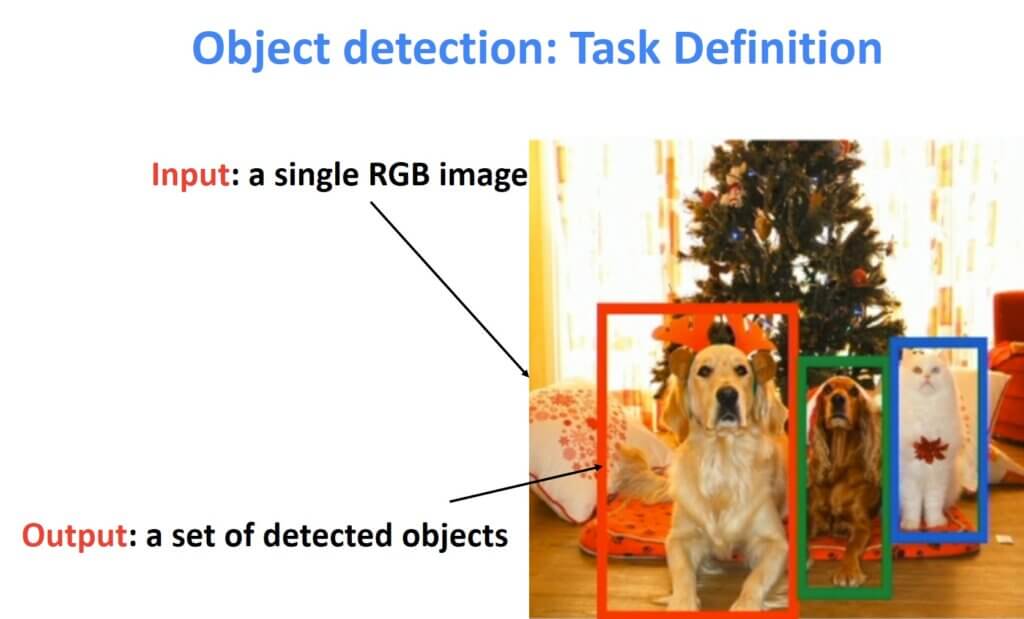
二、 物体检测简介
目标检测的目标可以看作是分类问题的扩展。在分类中,我们在图像中有一个占据中心图像区域的主要实例或对象。然后,我们的目标是检测图像中的内容。
对象检测类似,但更复杂。首先,我们不仅需要猜测它在图像中是什么,还需要检测它的位置。这通常是通过在对象边界框周围放置一个矩形框来完成的。这种定位是在地面实况标签方面完成的。也就是说,算法应该学习注释器的标记过程以及如何精确放置这个矩形框。从本质上讲,这可以转换为回归问题。另一方面,图像中确切内容的答案代表分类问题。
对于我们预测的每个对象:
- 图像中有什么?这是我们预测类别标签的分类任务
- 图像中的对象在哪里?这是定位任务,我们预测对象周围的边界框(4 个数字:x、y、宽度、高度)
为了更好地说明这一点,我们将回顾使用神经网络的分类。例如,我们可以有一个AlexNet。
2.1 检测单个对象
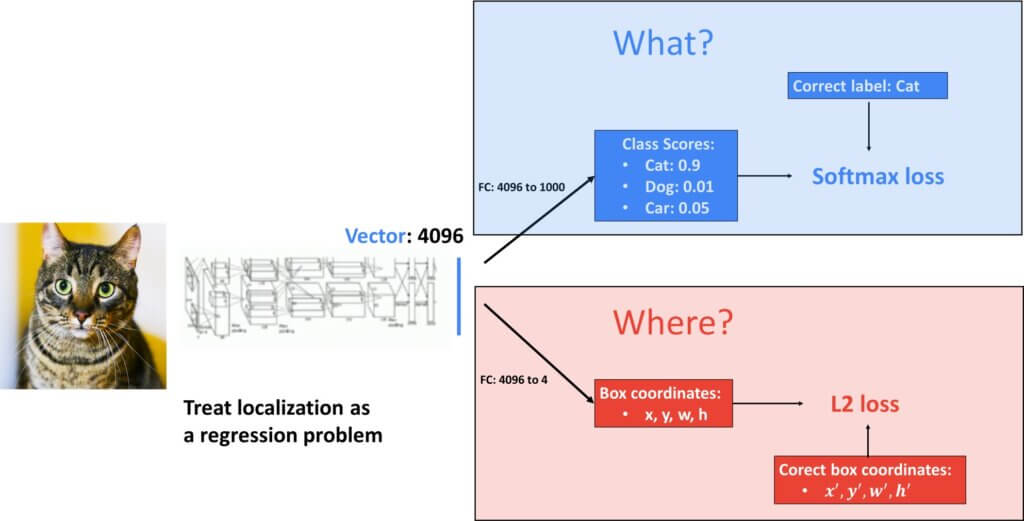
这个网络会告诉我们图像中的“什么”。为此,我们将得到一个输出分数概率向量。例如,图像中有猫的几率为 0.9。
该预测是从大小为 4096 的“最后一个”全连接层获得的,并馈送到 softmax 激活函数中。随后,该向量也可用于生成答案“哪里”猫在图像中的位置,这将被转换为回归问题。在这里,回归输出将是四个值:x、y、宽度和高度。
至于用于分类的损失函数,众所周知,我们将使用交叉熵损失。另一方面,对于回归问题,我们将使用 L2 损失函数。
现在,问题是我们有两种不同的损失。但是,我们需要一个损失函数来应用梯度下降并优化参数。好吧,解决方案被证明是相当简单的。我们将两个损失相加。也就是说,更准确地说,我们将使用加权和并调整权重参数。参数的权重将意味着这两个术语中哪个对我们更有价值。另一方面,这可以简单地用于调整两种损失的规模。
因此,我们有一个网络,我们希望输出多个结果。这是计算机视觉中的标准架构,称为多任务损失。
但是,存在一个巨大的问题。我们可以在图像中有多个对象,现在事情变得越来越复杂🙁,因此,我们不能利用这种多任务丢失的想法。
2.2 检测多个对象

在上图中,我们可以看到一个检测大量“鸭子”(或图像中的其他鸟类)的示例。
三、R-CNN
解决方案是使用不同大小和纵横比的滑动窗口。
请看下图:
3.1 滑动窗口

然后,一旦我们选择了滑动窗口,我们将其视为一个简单的分类任务。换句话说,由于我们可以在同一图像中有多个不同类别的数量,因此我们删除了一个多任务学习损失函数并删除了回归部分。现在,我们将问题归结为:
- 查找滑动窗口
- 执行分类
现在存在的主要问题是我们如何用不同大小的滑动窗口覆盖整个图像,并为每个滑动窗口运行CNN检测器。嗯,这可能是相当多的窗口,我们需要制定战略以找到最佳解决方案。
幸运的是,这种“滑动窗口方法”在计算机视觉中并不是一个新问题。我们已经在 Viola 和 Jones 于 2001 年开发的人脸检测算法中看到了这一点。
区域建议:
- 找到一小组可能覆盖所有对象的框。
- 通常基于启发式方法:例如,查找“类似斑点”的图像区域
- 运行相对较慢;例如,选择性搜索在 CPU 上几秒钟内提供 2000 个区域建议

其他研究人员也广泛探讨了这个问题,主要思想是专注于为我们的图像寻找“有希望的潜在窗口”。例如,我们可以在图像中搜索类似斑点的图案,并找到一小组将覆盖整个图像的窗口,仅举几例。此外,最终开发了“区域建议”算法,该方法可以检测一张图像的2,000个子区域,它们很有可能与我们搜索要检测的对象重叠。

最后,我们得出了R-CNN算法的定义。在这里,R 代表一个区域。
该算法可查找 2,000 个感兴趣区域 (RoI)。接下来,将每个 RoI 的输入图像扭曲为大小:\(224\times224 \)。作为最后一步,使用经过训练的CNN来检查扭曲图像区域中是否存在感兴趣的对象。
此外,网络的一部分可以细化投资回报率。在这里,RoI略有调整,因此它给了我们一个4个数字的序列:\(t_{x} \),\(t_{y} \),\(t_{w} \),\(t_{h} \)。下面的公式显示了我们如何获得最终的输出边界框。

如果这是您第一个与对象检测相关的算法,您可能想知道我们如何衡量准确性。对于分类来说,这相当容易,但是我们该怎么做才能进行对象检测呢?
为此,我们使用一个名为 Intersection over Union – IoU 的概念。
3.2 联合上的交叉点
我们如何判断我们的对象检测算法是否运行良好?

假设红色边界框是一个真实值标签。接下来,我们的检测器输出图像中存在一辆用紫色边界框标记的汽车。然后,在下图中可以轻松地将 IoU 定义为两个边界框之间的交集和并集之间的比率。
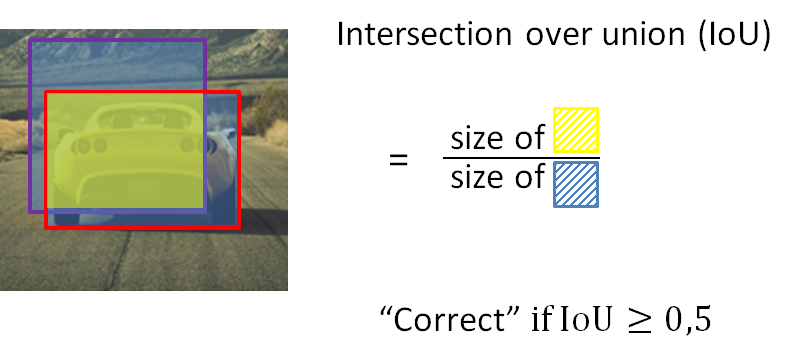
通常,大于 0.5 的值被视为良好的检测。在理想情况下,我们将完全重叠,在这种情况下,我们的 IoU 将达到最大值 1。
接下来,使用对象检测器时还有一个挑战。实质上,图像中同一对象将有大量的边界框候选项。因此,我们确实需要一种算法来解决这个问题。一种流行的算法是非最大抑制 – NMS。
3.3 非最大抑制
这个算法的想法相当简单。想象一下,我们的探测器为我们提供了下图中两辆车的以下检测。除了每个边界框之外,我们还有该检测的汽车类的概率分数。

好吧,NMS的目标是首先保留具有最高类概率的对象。例如,这些将是两个具有概率的矩形:左车为 0.8,右车为 0.9。当我们保留那些概率最大的边界框时,我们将搜索与这些边界框具有相同类和高 IoU 的边界框。在我们的例子中,我们将首先选择正确的汽车 p=0.9 并删除两个重叠的红色矩形(在右侧的汽车上)。同样,我们将对左侧的汽车重复相同的过程,从而留下白色矩形 p = 0.8 。
3.4 平均平均精度 – mAP。
最后,在使用 IoU 和 NMS 处理我们的检测后,我们需要计算目标检测器的精度。这是通过称为:平均平均精度 – mAP 的指标完成的。
计算mAP的步骤可以总结如下:我们有“狗对象”的检测。假设我们总共检测到 5 只狗。但是,我们只有 3 个地面实况检测。我们将从最高类概率 (p=0.99) 开始,并使用地面实况检测计算 IoU。如果我们的值高于 0.5,我们将将其计为真实检测。在这种情况下,我们计算精度并迭代召回。这可以在下面的召回/精度图中轻松可视化。
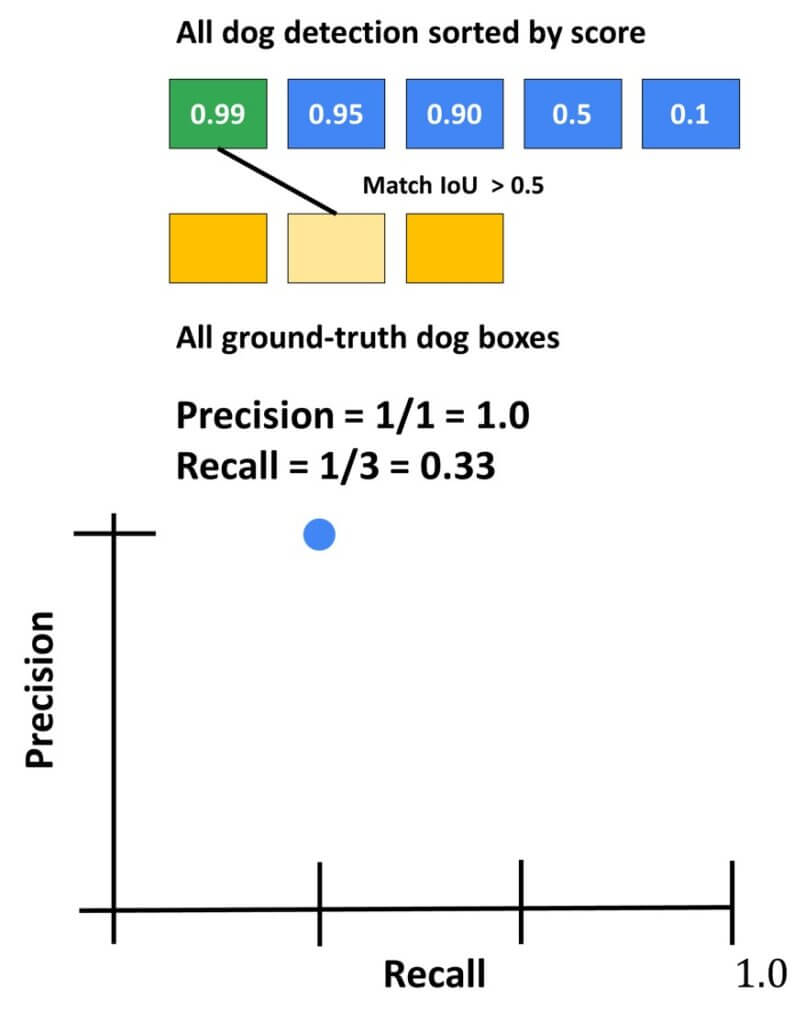
然后,我们对第二次检测进行相同的计算。例如,它将与第三个地面实况检测相匹配。现在,我们将再次更新召回率和精度并相应地绘制它们。

接下来,我们可以想象接下来的两次检测实际上是误报,而最后的第五次检测是真阳性。然后,召回率和精确度的演变如下:

最后,我们输出狗探测器的最终值。它将表示曲线下方的面积。

然后,对于一个对象检测器,假设我们正在检测三个类。我们将计算所有三个类的 AP,并取所有三个类的平均值。最后,我们将获得 meanAP 或 mAP。
四、快速 R-CNN
R-CNN算法在发明时是一个了不起的对象检测器。然而,研究人员很快意识到这种算法的主要缺点。它非常非常慢。所以,今天,有时人们甚至把它称为慢速的R-CNN。
改进来自一个相当简单的想法。交换了1)扭曲和2)在扭曲图像上运行CNN的过程。然后,主干CNN的运行只完成一次,这将大大加快速度。

我们将解释术语“骨干”。这通常是一个预先训练好的AlexNet或类似VGG的网络。它将代表处理我们的对象检测器的基础,这节省了大量工作。接下来,处理后的输出将表示特征图。请注意,主干由卷积层组成,包括最大池化和批量归一化,但不是全连接层。然后,这些特征图将被调整以适应投资回报率,为此,特征图将被裁剪/调整大小和扭曲。接下来,我们将使用较轻的“每区域网络”来处理这些扭曲特征子集中的每一个。这种较轻的网络在计算上要求要低得多。例如,该网络可能仅由来自AlexNet的最后2个完全连接的层组成。
有一个问题可能仍然让我们感到困惑。我们如何实际裁剪特征?
假设我们有以下处理管道:
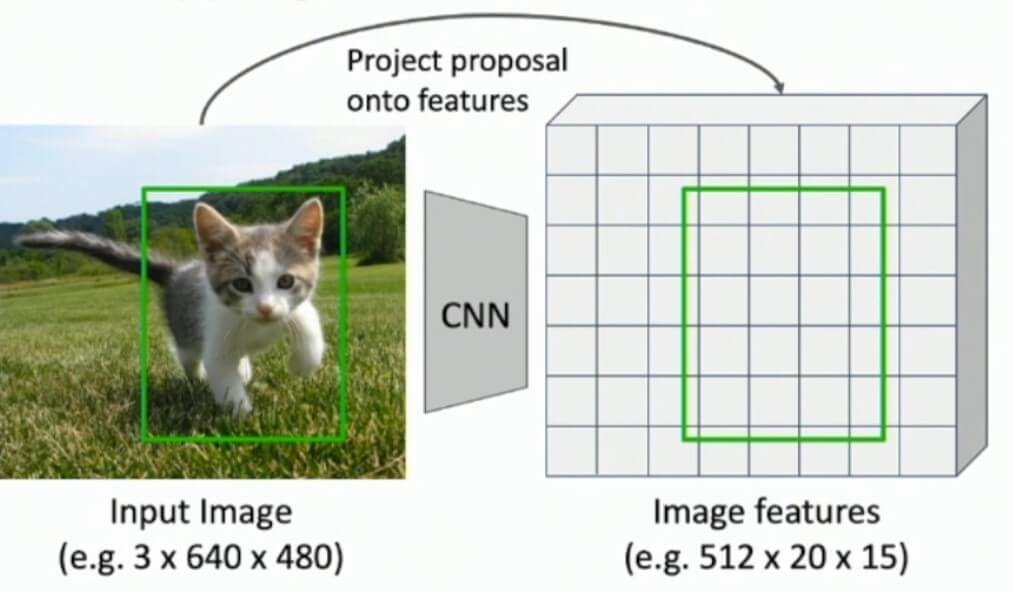
使用指定的 RoI(猫上方的绿色矩形),我们将“捕捉”到图像特征图并像往常一样继续计算。在这里,我们无需过多赘述,我们将在下图中演示此过程。简而言之,该算法将找到原始RoI和特征图元素之间的最佳匹配。必要时,将调整尺寸,以便在某些情况下,我们甚至可以具有\(3\times2\)池化区域,如下图所示。
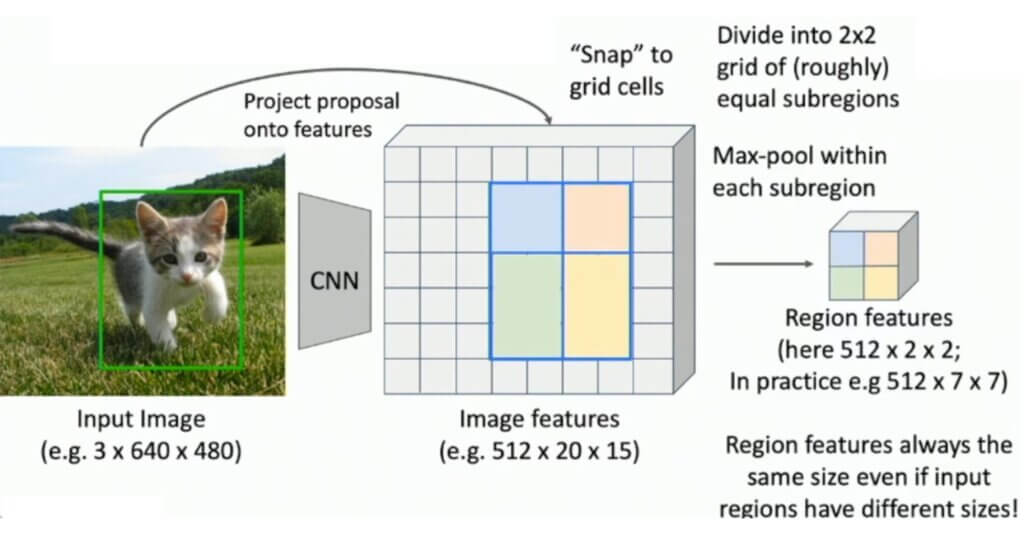
这概述了Fast R-CNN的主要思想。收益是什么?
请看下图:
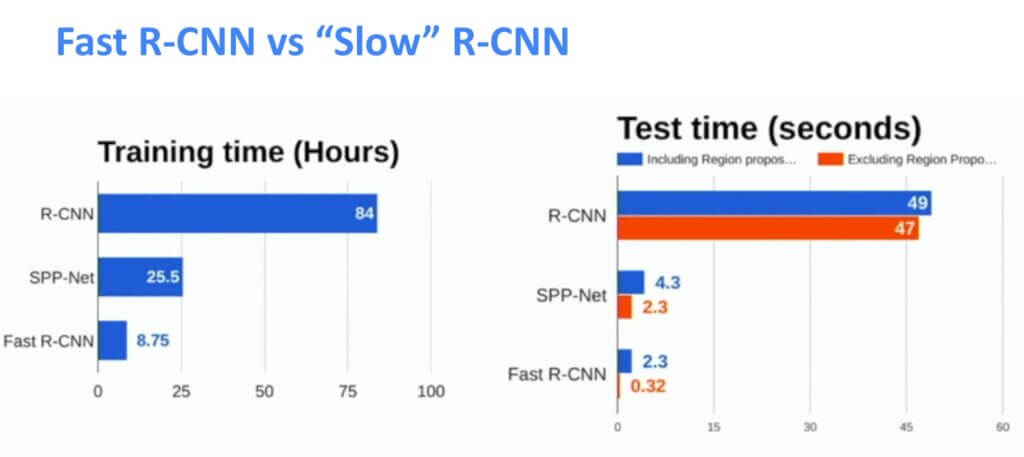
我们可以看到我们需要花在训练和测试时间上的结果。这是速度的显着提高!
五、 更快的 R-CNN
我们已经到达了该系列中的第三个算法,更快的R-CNN。同样,创建更快的 R-CNN 算法的目标可以在下面看到:
- 删除选择性 RoI 提案算法
- 创建一个层/网络,该层/网络将根据我们正在处理的图像为我们选择 RoI
该网络称为区域提案网络 (RPN)。目标是生成特征图激活。然后,我们将这些功能提供给 RPN,它将输出区域。接下来,我们在快速R-CNN中执行所有操作。
区域提案网络 (RPN)
我们将使用原始输入图像,并将其通过主干CNN传递。这将产生所需的特征图。我们将介绍所谓的锚盒。此锚框将涵盖特征图的每个元素。下图说明了锚框的一些示例。接下来,我们将有一个网络,它将使用简单的二元分类告诉我们锚点是否包含对象。在图像中,绿色锚点被分类为具有对象的区域,而红色锚点框将在进一步分析中被丢弃。

此外,这些锚框可能不完全适合我们感兴趣的对象。因此,引入了另一个步骤来优化此锚框。此细化过程可以添加到输出细化锚框的四个坐标的 PRN 网络中。最后,这个新的边界框将称为提案框。
因此,下图显示了整体算法:
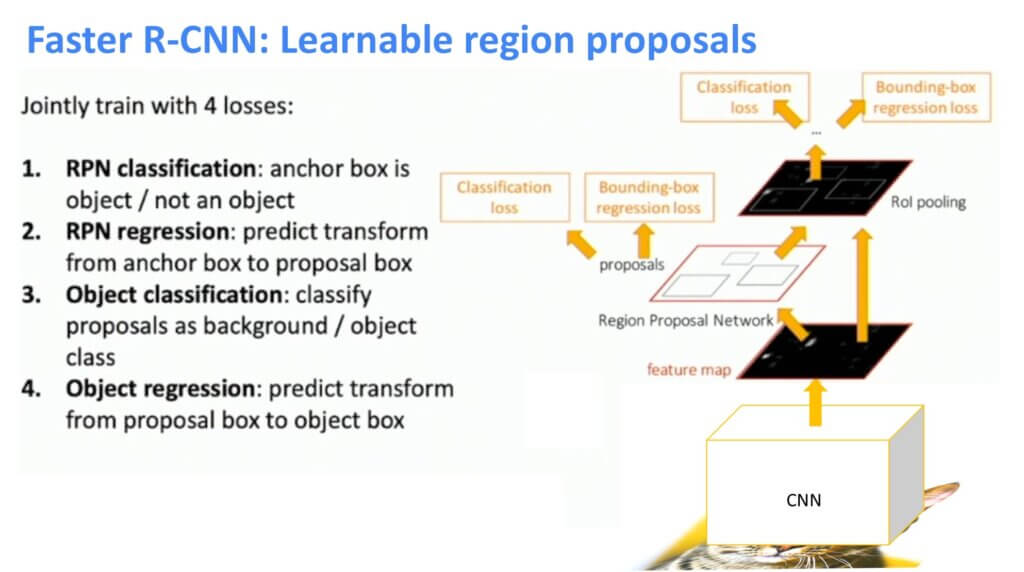
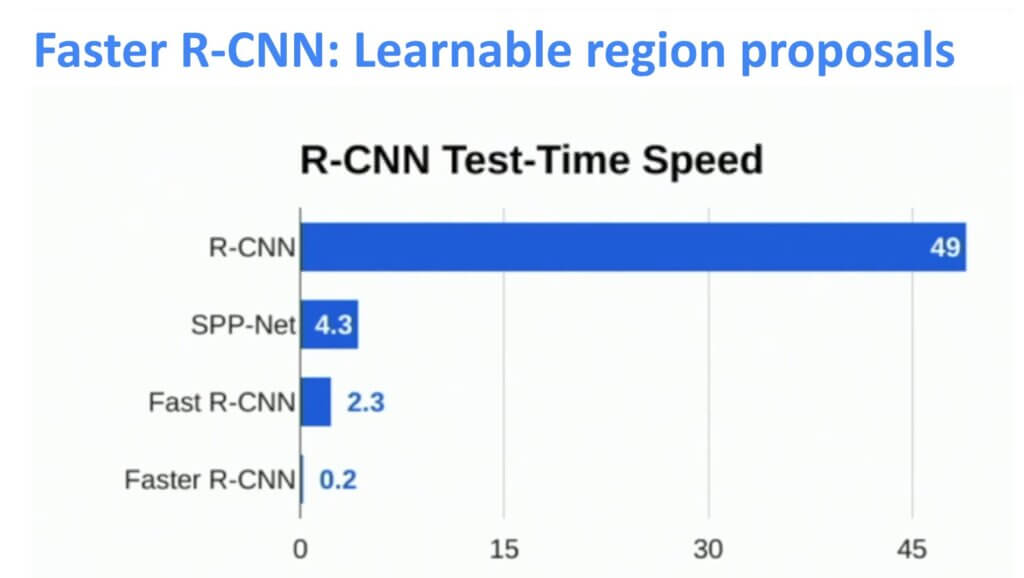
最后,我们设计了一个与原始R-CNN相比非常快的网络。因此,开发所有步骤的努力确实🙂得到了回报 下图表示处理单个图像帧所需的时间。
六、PyTorch 中更快的 R-CNN
在这一部分中,我们将演示如何在 PyTorch 中使用和应用 R-CNN 网络。从头开始实现技术性太强,而且充满了细节,所以我们只采用 PyTorch 的内置方法和模型。
import torch
import numpy as np
import matplotlib.pyplot as pltimport torchvision.transforms.functional as F在此步骤中,我们仅使用Torchvision的工具查看图像和创建边界框。
plt.rcParams["savefig.bbox"] = 'tight'def show(imgs):if not isinstance(imgs, list):imgs = [imgs]fig, axs = plt.subplots(ncols=len(imgs), squeeze=False)for i, img in enumerate(imgs):img = img.detach()img = F.to_pil_image(img)axs[0, i].imshow(np.asarray(img))axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])我们将使用!wget命令从互联网下载两个图像,并使用make_grid()方法创建照片网格。必须为此函数提供 dtype uint8 的图像。
!wget https://i.pinimg.com/736x/99/a6/fd/99a6fdcf4d023196d77eb36aa6082737--styles-php.jpg -O /content/car1.jpg
!wget https://i.pinimg.com/736x/dd/68/20/dd68208d216bb677bdab86579a856197--offroad-all-white.jpg -O /content/car2.jpgfrom torchvision.utils import make_grid
from torchvision.io import read_image
from pathlib import Pathcar1_int = read_image('car1.jpg')
car2_int = read_image('car2.jpg')
car_list = [car1_int, car2_int]grid = make_grid(car_list)
show(grid)
draw_bounding_boxes() 可用于在图像上绘制框。颜色、标签、宽度、字体和字体大小都可以自定义。这些框的格式为(xmin、ymin、xmax 和 ymax)。
from torchvision.utils import draw_bounding_boxesboxes = torch.tensor([[50, 50, 100, 200], [35, 120, 620, 390]], dtype=torch.float)
colors = ["blue", "yellow"]
result = draw_bounding_boxes(car1_int, boxes, colors=colors, width=5)
show(result)
当然,我们也可以描绘用于 torchvision 检测的模型生成的边界框。以下是使用加载了 Faster R-CNN 模型的 fasterrcnn_resnet50_fpn() 模型的演示。
from torchvision.models.detection import fasterrcnn_resnet50_fpn, FasterRCNN_ResNet50_FPN_Weightsweights = FasterRCNN_ResNet50_FPN_Weights.DEFAULT
transforms = weights.transforms()images = [transforms(d) for d in car_list]model = fasterrcnn_resnet50_fpn(weights=weights, progress=False)
model = model.eval()outputs = model(images)
print(outputs)[{'boxes': tensor([[ 28.9595, 134.5368, 601.7979, 349.9137],[193.5566, 140.5615, 265.0889, 167.9842],[ 39.9696, 147.1586, 385.6311, 320.0778],[ 56.1535, 57.3264, 70.2791, 74.9138],[ 18.2229, 145.6895, 372.0598, 223.5003],[306.9967, 138.4377, 609.1713, 338.3705],[401.1234, 142.1768, 597.3285, 218.0435],[194.6392, 136.0293, 311.0567, 178.4407],[177.8387, 137.6242, 564.1535, 217.5274]], grad_fn=<StackBackward0>), 'labels': tensor([ 3, 3, 3, 10, 3, 3, 3, 3, 3]), 'scores': tensor([0.9975, 0.9756, 0.1578, 0.1235, 0.1173, 0.1015, 0.1010, 0.0596, 0.0592],grad_fn=<IndexBackward0>)}, {'boxes': tensor([[ 50.2957, 92.2544, 559.3746, 394.2029],[440.5210, 165.9631, 514.2350, 189.4745],[ 1.0823, 66.7191, 80.6373, 216.8004],[545.3552, 166.6906, 565.3425, 177.7227],[623.8428, 166.1020, 639.8632, 175.8192],[621.2831, 168.1364, 634.0815, 176.0556],[630.9683, 166.2280, 640.0000, 174.9458],[221.3280, 133.8347, 248.0095, 177.0258],[544.7429, 167.2232, 556.0880, 176.6033],[ 64.7255, 98.3926, 351.7974, 324.6750],[ 0.0000, 62.4695, 107.9940, 258.9799],[495.5164, 167.1042, 517.1301, 180.6814],[441.0862, 167.3649, 456.5072, 175.7454],[620.4214, 168.7013, 628.3602, 175.9150],[ 5.8789, 11.4534, 196.9230, 289.0226],[330.2793, 134.5042, 364.6375, 166.5594],[544.6981, 166.3828, 566.0054, 178.1335],[ 0.0000, 70.6256, 84.6627, 257.4922],[554.5934, 167.3156, 566.4719, 177.3227]], grad_fn=<StackBackward0>), 'labels': tensor([ 8, 3, 72, 3, 3, 3, 3, 1, 3, 8, 8, 3, 3, 3, 8, 1, 8, 6,3]), 'scores': tensor([0.9941, 0.9835, 0.9119, 0.9073, 0.8916, 0.5875, 0.5719, 0.2739, 0.1993,0.1637, 0.1330, 0.1272, 0.1253, 0.0706, 0.0670, 0.0657, 0.0586, 0.0559,0.0506], grad_fn=<IndexBackward0>)}] 让我们可视化模型找到的框。将仅绘制分数高于指定阈值的框。
score_threshold = 0.8
cars_with_boxes = [draw_bounding_boxes(dog_int, boxes=output['boxes'][output['scores'] > score_threshold], width=4)for dog_int, output in zip(car_list, outputs)
]
show(cars_with_boxes)
七、总结
这就是这篇文章的全部内容。我们已经看到了目标检测算法R-CNN背后的理论。我们已经看到了该算法和下一个检测算法的演变,这些算法更快,快速R-CNN和更快的R-CNN。最后,我们编写了运行我们自己的 Faster R-CNN 探测器所需的代码,并在图像上检测了汽车。
参考和引用
#027 R-CNN, Fast R-CNN, and Faster R-CNN explained with a demonstration in PyTorch - Master Data Science 16.01.2023 (datahacker.rs)
datahacker.rs 深度学习 机器学习 PyTorch 16.01.2023 | 0