资源下载:http://www.ziyuanwang.online/912.html
Kubernetes(K8s)
一、Openstack&VM
1、认识虚拟化
1.1、什么是虚拟化
在计算机中,虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间的不可切割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。这些资源的新虚拟部份是不受现有资源的架设方式,地域或物理组态所限制。一般所指的虚拟化资源包括计算能力和资料存储。
虚拟化技术是一套解决方案。完整的情况需要CPU、主板芯片组、BIOS和软件的支持,例如VMM软件或者某些操作系统本身。即使只是CPU支持虚拟化技术,在配合VMM的软件情况下,也会比完全不支持虚拟化技术的系统有更好的性能。
在实际的生产环境中,虚拟化技术主要用来解决高性能的物理硬件产能过剩和老的旧的硬件产能过低的重组重用,透明化底层物理硬件,从而最大化的利用物理硬件 对资源充分利用
虚拟化技术种类很多,例如:软件虚拟化、硬件虚拟化、内存虚拟化、网络虚拟化(vip)、桌面虚拟化、服务虚拟化、虚拟机等等。
1.2、虚拟化分类
(1)全虚拟化架构
虚拟机的监视器(hypervisor)是类似于用户的应用程序运行在主机的OS之上,如VMware的workstation,这种虚拟化产品提供了虚拟的硬件。

(2)OS层虚拟化架构

(3)硬件层虚拟化

硬件层的虚拟化具有高性能和隔离性,因为hypervisor直接在硬件上运行,有利于控制VM的OS访问硬件资源,使用这种解决方案的产品有VMware ESXi 和 Xen server
Hypervisor是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,因此也可以看作是虚拟环境中的“元”操作系统,它可以协调访问服务器上的所有物理设备和虚拟机,也叫虚拟机监视器(Virtual Machine Monitor,VMM)。
Hypervisor是所有虚拟化技术的核心。当服务器启动并执行Hypervisor时,它会给每一台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统。 宿主机
Hypervisor是所有虚拟化技术的核心,软硬件架构和管理更高效、更灵活,硬件的效能能够更好地发挥出来。常见的产品有:VMware、KVM、Xen等等
2、OpenStack与KVM、VMWare
2.1、OpenStack
OpenStack:开源管理项目 OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它不是一个软件,而是由几个主要的组件组合起来完成一些具体的工作。OpenStack由以下五个相对独立的组件构成:
· OpenStack Compute(Nova)是一套控制器,用于虚拟机计算或使用群组启动虚拟机实例;
· OpenStack镜像服务(Glance)是一套虚拟机镜像查找及检索系统,实现虚拟机镜像管理;
· OpenStack对象存储(Swift)是一套用于在大规模可扩展系统中通过内置冗余及容错机制,以对象为单位的存储系统,类似于Amazon S3;
· OpenStack Keystone,用于用户身份服务与资源管理以及
· OpenStack Horizon,基于Django的仪表板接口,是个图形化管理前端。 这个起初由美国国家航空航天局和Rackspace在2010年末合作研发的开源项目,旨在打造易于部署、功能丰富且易于扩展的云计算平台。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性,企图成为数据中心的操作系统,即云操作系统。
Openstack项目层级关系:

· 第一层是基础设施层,这一层主要包含Nova、Glance和Keystone,如果我们要想得到最基本的基础设施的服务,必须安装部署这三个项目。
· 第二层是扩展基础设施层,这一层可以让我们得到更多跟基础设施相关的高级服务,主要包含Cinder、Swift、Neutron、Designate和Ironic等,其中Cinder提供块存储,Swift提供对象存储,Neutron提供网络服务,Designate提供DNS服务,Ironic提供裸机服务。
· 第三层是可选的增强特性,帮用户提供一些更加高级的功能,主要包含Ceilometer、Horizon和Barbican,其中Ceilometer提供监控、计量服务,Horizon提供用户界面,Barbican提供秘钥管理服务。
· 第四层主要是消费型服务,所谓的消费型服务,主要是指第四层的服务都需要通过使用前三层的服务来工作。
第四层主要有Heat、Magnum、Sahara、Solum和Murano等,其中Heat主要提供orchestration服务,Magnum主要提供容器服务,Sahara主要提供大数据服务,我们可以通过Sahara很方便地部署Hadoop、Spark集群。Solum主要提供应用开发的服务,并且可以提供一些类似于CI/CD的功能。Muarno主要提供应用目录的服务,类似于App Store,就是用户可以把一些常用的应用发布出来供其他用户去使用。最右边是Kolla,Kolla的主要功能是容器化所有的OpenStack服务,便于OpenStack安装部署和升级。
2.2、KVM
KVM(Kernel-based Virtual Machine)基于内核的虚拟机 KVM是集成到Linux内核的Hypervisor,是X86架构且硬件支持虚拟化技术(Intel VT或AMD-V)的Linux的全虚拟化解决方案。它是Linux的一个很小的模块,利用Linux做大量的事,如任务调度、内存管理与硬件设备交互等。 KVM最大的好处就在于它是与Linux内核集成的,所以速度很快。

2.3、VMWare
VMWare (Virtual Machine ware) VMWare (Virtual Machine ware)是一个“虚拟PC”虚拟机管理管理软件。它的产品可以使你在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。
与“多启动”系统相比,VMWare采用了完全不同的概念。多启动系统在一个时刻只能运行一个系统,在系统切换时需要重新启动机器。VMWare是真正“同时”运行,多个操作系统在主系统的平台上,就象标准Windows应用程序那样切换。而且每个操作系统你都可以进行虚拟的分区、配置而不影响真实硬盘的数据,你甚至可以通过网卡将几台虚拟机用网卡连接为一个局域网,极其方便。安装在VMware操作系统性能上比直接安装在硬盘上的系统低不少,因此,比较适合学习和测试。
二、容器&编排技术
1、容器发展史
1.1、Chroot
容器技术的概念可以追溯到1979年的UNIX Chroot。这项功能将Root目录及其它子目录变更至文件系统内的新位置,且只接受特定进程的访问,其设计目的在于为每个进程提供一套隔离化磁盘空间。1982年其被添加至BSD。

chroot只是提供了对进程文件目录虚拟化的功能,不能够防止进程恶意访问系统。这个问题在FreeBSDGails容器技术中得以解决
1.2、FreeBSD Jails
FreeBSD Jails与Chroot的定位类似,不过其中包含有进程沙箱机制以对文件系统、用户及网络等资源进行隔离。通过这种方式,它能够为每个Jail、定制化软件安装包乃至配置方案等提供一个对应的IP地址。Jails技术为FreeBSD系统提供了一种简单的安全隔离机制。它的不足在于这种简单性的隔离也同时会影响Jails中应用访问系统资源的灵活性。

1.3、Solaris Zones
Solaris Zone技术为应用程序创建了虚拟的一层,让应用在隔离的Zone中运行,并实现有效的资源管理。每一个Zone 拥有自己的文件系统,进程空间,防火墙,网络配置等等。
Solaris Zone技术真正的引入了容器资源管理的概念。在应用部署的时候为Zone配置一定的资源,在运行中可以根据Zone的负载动态修改这个资源限制并且是实时生效的,在其他Zone不需要资源的时候,资源会自动切换给需要的资源的Zone,这种切换是即时的不需要人工干预的,最大化资源的利用率,在必要的情况下,也可以为单个Zone隔离一定的资源。

1.4、LXC
LXC指代的是Linux Containers,其功能通过Cgroups以及Linux Namespaces实现。也是第一套完整的Linux容器管理实现方案。在LXC出现之前, Linux上已经有了类似 Linux-Vserver、OpenVZ 和 FreeVPS。虽然这些技术都已经成熟,但是这些解决方案还没有将它们的容器支持集成到主流 Linux 内核。相较于其它容器技术,LXC能够在无需任何额外补丁的前提下运行在原版Linux内核之上。目前LXC项目由Canonical有限公司负责赞助及托管。

1.5、Docker
Docker项目最初是由一家名为DotCloud的平台即服务厂商所打造,其后该公司更名为Docker。Docker在起步阶段使用LXC,而后利用自己的Libcontainer库将其替换下来。与其它容器平台不同,Docker引入了一整套与容器管理相关的生态系统。其中包括一套高效的分层式容器镜像模型、一套全局及本地容器注册表、一个精简化REST API以及一套命令行界面等等。
与Docker具有同样目标功能的另外一种容器技术就是CoreOS公司开发的Rocket. Rocket基于App Container规范并使其成为一项更为开放的标准。

2、Docker容器
2.1、Docker历史
2010年,几个搞IT的年轻人,在美国旧金山成立了一家名叫“dotCloud”的公司。

这家公司主要提供基于PaaS的云计算技术服务。具体来说,是和LXC有关的容器技术。LXC,就是Linux容器虚拟技术(Linux container)、后来,dotCloud公司将自己的容器技术进行了简化和标准化,并命名为——Docker。
Docker技术诞生之后,并没有引起行业的关注。而dotCloud公司,作为一家小型创业企业,在激烈的竞争之下,也步履维艰。正当他们快要坚持不下去的时候,脑子里蹦出了“开源”的想法。
什么是“开源”?开源,就是开放源代码。也就是将原来内部保密的程序源代码开放给所有人,然后让大家一起参与进来,贡献代码和意见。
Open Source,开源
有的软件是一开始就开源的。也有的软件,是混不下去,创造者又不想放弃,所以选择开源。自己养不活,就吃“百家饭”嘛。
2013年3月,dotCloud公司的创始人之一,Docker之父,28岁的Solomon Hykes正式决定,将Docker项目开源。
不开则已,一开惊人。
越来越多的IT工程师发现了Docker的优点,然后蜂拥而至,加入Docker开源社区。
Docker的人气迅速攀升,速度之快,令人瞠目结舌。
开源当月,Docker 0.1版本发布。此后的每一个月,Docker都会发布一个版本。到2014年6月9日,Docker 1.0版本正式发布。
此时的Docker,已经成为行业里人气最火爆的开源技术,没有之一。甚至像Google、微软、Amazon、VMware这样的巨头,都对它青睐有加,表示将全力支持。
Docker火了之后,dotCloud公司干脆把公司名字也改成了Docker Inc.。
Docker和容器技术为什么会这么火爆?说白了,就是因为它“轻”。
2.2、Docker原理
容器是一种轻量级的虚拟化技术,因为它跟虚拟机比起来,它少了一层 hypervisor 层。先看一下下面这张图,这张图简单描述了一个容器的启动过程。

注: hypervisor:一种运行在物理服务器和操作系统之间的中间层软件,可以允许多个操作系统和应用共享一套基础物理硬件。可以将hypervisor看做是虚拟环境中的“元”操作系统,可以协调访问服务器上的所有物理设备和虚拟机,所以又称为虚拟机监视器(virtual machine monitor)。hypervisor是所有虚拟化技术的核心,非中断的支持多工作负载迁移是hypervisor的基本功能。当服务器启动并执行hypervisor时,会给每一台虚拟机分配适量的内存,cpu,网络和磁盘资源,并且加载所有虚拟机的客户操作系统。
最下面是一个磁盘,容器的镜像是存储在磁盘上面的。上层是一个容器引擎,容器引擎可以是 docker,也可以是其它的容器引擎。引擎向下发一个请求,比如说创建容器,这时候它就把磁盘上面的容器镜像运行成在宿主机上的一个进程。
对于容器来说,最重要的是怎么保证这个进程所用到的资源是被隔离和被限制住的,在 Linux 内核上面是由 cgroup 和 namespace 这两个技术来保证的
2.3、NameSpace
namespace 是用来做资源隔离的,在 Linux 内核上有七种 namespace,docker 中用到了前六种。第七种 cgroup namespace 在 docker 本身并没有用到,但是在 runC 实现中实现了 cgroup namespace。

1)第一个是 mout namespace。mout namespace 就是保证容器看到的文件系统的视图,是容器镜像提供的一个文件系统,也就是说它看不见宿主机上的其他文件,除了通过 -v 参数 bound 的那种模式,是可以把宿主机上面的一些目录和文件,让它在容器里面可见的; 2)第二个是 uts namespace,这个 namespace 主要是隔离了 hostname 和 domain; 3)第三个是 pid namespace,这个 namespace 是保证了容器的 init 进程是以 1 号进程来启动的; 4)第四个是网络 namespace,除了容器用 host 网络这种模式之外,其他所有的网络模式都有一个自己的 network namespace 的文件; 5)第五个是 user namespace,这个 namespace 是控制用户 UID 和 GID 在容器内部和宿主机上的一个映射,不过这个 namespace 用的比较少; 6)第六个是 IPC namespace,这个 namespace 是控制了进程兼通信的一些东西,比方说信号量; 7)第七个是 cgroup namespace,上图右边有两张示意图,分别是表示开启和关闭 cgroup namespace。用 cgroup namespace 带来的一个好处是容器中看到的 cgroup 视图是以根的形式来呈现的,这样的话就和宿主机上面进程看到的 cgroup namespace 的一个视图方式是相同的;另外一个好处是让容器内部使用 cgroup 会变得更安全。
3、D&K&O
3.1、Docker&KVM
VM 利用 Hypervisor 虚拟化技术来模拟 CPU、内存等硬件资源,这样就可以在宿主机上建立一个 Guest OS,这是常说的安装一个虚拟机。

每一个 Guest OS 都有一个独立的内核,比如 Ubuntu、CentOS 甚至是 Windows 等,在这样的 Guest OS 之下,每个应用都是相互独立的,VM 可以提供一个更好的隔离效果。但这样的隔离效果需要付出一定的代价,因为需要把一部分的计算资源交给虚拟化,这样就很难充分利用现有的计算资源,并且每个 Guest OS 都需要占用大量的磁盘空间,比如 Windows 操作系统的安装需要 10~30G 的磁盘空间,Ubuntu 也需要 5~6G,同时这样的方式启动很慢。正是因为虚拟机技术的缺点,催生出了容器技术。
容器是针对于进程而言的,因此无需 Guest OS,只需要一个独立的文件系统提供其所需要文件集合即可。所有的文件隔离都是进程级别的,因此启动时间快于 VM,并且所需的磁盘空间也小于 VM。当然了,进程级别的隔离并没有想象中的那么好,隔离效果相比 VM 要差很多。
总体而言,容器和 VM 相比,各有优劣,因此容器技术也在向着强隔离方向发展。
Docker提供了一种程序运行的容器,同时保证这些容器相互隔离。虚拟机也有类似的功能,但是它通过Hypervisor创建了一个完整的操作系统栈。不同于虚拟机的方式,Docker依赖于Linux自带的LXC(Linux Containers)技术。LXC利用了Linux可以对进程做内存、CPU、网络隔离的特性。Docker镜像不需要新启动一个操作系统,因此提供了一种轻量级的打包和运行程序的方式。而且Docker能够直接访问硬件,从而使它的I/O操作比虚拟机要快得多。
疑问:
Docker可以直接跑在物理服务器上,这引起大家的疑问:假如已经用了Docker,还有必要使用OpenStack吗?
Docker和KVM的性能测试对比图表。和预期的一样,启动KVM和Docker容器的时间差异非常显著,而且在内存和CPU利用率上,双方差距非常大,如下表所示。

双方巨大的性能差异,导致了在相同工作负载下,KVM需要更多的CPU和内存资源,导致成本上升。
3.2、KVM&openstack

openstack是云管理平台,其本身并不提供虚拟化功能,真正的虚拟化能力是由底层的hypervisor(如KVM、Qemu、Xen等)提供。所谓管理平台,就是为了方便使用而已。如果没有openstack,一样可以通过virsh、virt-manager来实现创建虚拟机的操作,只不过敲命令行的方式需要一定的学习成本,对于普通用户不是很友好。
KVM是最底层的hypervisor,是用来模拟CPU的运行,然鹅一个用户能在KVM上完成虚拟机的操作还需要network及周边的I/O支持,所以便借鉴了qemu进行一定的修改,形成qemu-kvm。但是openstack不会直接控制qemu-kvm,会用一个libvirt的库去间接控制qemu-kvm。qemu-kvm的地位就像底层驱动来着。
OpenStack:开源管理项目
OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它不是一个软件,而是由几个主要的组件组合起来完成一些具体的工作。OpenStack由以下五个相对独立的组件构成:
-
OpenStack Compute(Nova)是一套控制器,用于虚拟机计算或使用群组启动虚拟机实例;
-
OpenStack镜像服务(Glance)是一套虚拟机镜像查找及检索系统,实现虚拟机镜像管理;
-
OpenStack对象存储(Swift)是一套用于在大规模可扩展系统中通过内置冗余及容错机制,以对象为单位的存储系统,类似于Amazon S3;
-
OpenStack Keystone,用于用户身份服务与资源管理以及
-
OpenStack Horizon,基于Django的仪表板接口,是个图形化管理前端。
这个起初由美国国家航空航天局和Rackspace在2010年末合作研发的开源项目,旨在打造易于部署、功能丰富且易于扩展的云计算平台。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性,企图成为数据中心的操作系统,即云操作系统。
KVM:开放虚拟化技术
KVM(Kernel-based Virtual Machine)是一个开源的系统虚拟化模块,它需要硬件支持,如Intel VT技术或者AMD V技术,是基于硬件的完全虚拟化,完全内置于Linux。
2008年,红帽收购Qumranet获得了KVM技术,并将其作为虚拟化战略的一部分大力推广,在2011年发布RHEL6时支持KVM作为唯一的hypervisor。KVM主打的就是高性能、扩展性、高安全,以及低成本。
与Linux的缘分
一个被某些热心支持者成为云时代的Linux,是公有云与私有云的开源操作系统。一个则是Linux内核的一部分,将Linux转换成一个Type-1 hypervisor,无需任何变更就能享受现有的Linux内核进程调度、内存管理和设备支持。
OpenStack炙手可热,它如同Linux一样,旨在构建一个内核,所有的软件厂商都围绕着它进行工作。OpenStack的许多子项目,对云计算平台中的各种资源(如计算能力、存储、网络)提供敏捷管理。此外,OpenStack也提供对虚拟化技术的支持。
KVM集成在Linux的各个主要发行版本中,使用Linux自身的调度器进行管理。KVM专注于成为最好的虚拟机监控器,是使用Linux企业的不二选择,加上它还支持Windows平台,所以也是异构环境的最佳选择。
OpenStack与KVM都发展迅猛
OpenStack是一个拥有众多支持者的大项目。时至今日,已经有超过180家企业和400多位开发人员对这一项目积极地做着贡献,而其生态系统甚至更为庞大,已经超过了5600人和850家机构。在今年9月,OpenStack基会正式成立。白金会员有红帽、IBM与惠普等,黄金会员包括思科、戴尔与英特尔等。
OpenStack基本上是一个软件项目,有近55万行代码。分解成核心项目、孵化项目,以及支持项目和相关项目。除了以上提及的五大组成,与虚拟网络有关的Quantum首次被列为核心项目。
KVM是一个脱颖而出的开放虚拟化技术。它是由一个大型的、活跃的开放社区共同开发的,红帽、IBM、SUSE等都是其成员。2011年,IBM、红帽、英特尔与惠普等建立开放虚拟化联盟(OVA),帮助构建KVM生态系统,提升KVM采用率。如今,OVA已经拥有超过250名成员公司,其中,IBM有60多位程序员专门工作于KVM开源社区。
3.3、Docker&openstack
OpenStack和Docker之间是很好的互补关系。Docker的出现能让IaaS层的资源使用得更加充分,因为Docker相对虚拟机来说更轻量,
对资源的利用率会更加充分;

云平台提供一个完整管理数据中心的解决方案,至于用哪种hypervisor或container只是云平台中的一个小部分。像OpenStack这样的云平台包含了多租户的安全、隔离、管理、监控、存储、网络等其他部分。云数据中心的管理需要很多服务支撑,但这和用Docker还是KVM其实没多大关系。
Docker不是一个全功能的VM, 它有很多严重的缺陷,比如安全、Windows支持,因此不能完全替代KVM。现在Docker社区一直在弥补这些缺陷,当然这会带来一定的性能损耗。
4、容器编排
4.1、应用部署变迁

4.2、容器管理
怎么去管理这么多的容器
• 怎么横向扩展
• 容器down 了,怎么恢复
• 更新容器后不影响业务
• 如何监控容器
• 如何调度新创建的容器
• 数据安全问题
4.3、云原生

云原生是一条最佳路径或者最佳实践。更详细的说,云原生为用户指定了一条低心智负担的、敏捷的、能够以可扩展、可复制的方式最大化地利用云的能力、发挥云的价值的最佳路径。
云原生的技术范畴包括了以下几个方面:
-
第一部分是云应用定义与开发流程。这包括应用定义与镜像制作、配置 CI/CD、消息和 Streaming 以及数据库等。
-
第二部分是云应用的编排与管理流程。这也是 Kubernetes 比较关注的一部分,包括了应用编排与调度、服务发现治理、远程调用、API 网关以及 Service Mesh。
-
第三部分是监控与可观测性。这部分所强调的是云上应用如何进行监控、日志收集、Tracing 以及在云上如何实现破坏性测试,也就是混沌工程的概念。
-
第四部分就是云原生的底层技术,比如容器运行时、云原生存储技术、云原生网络技术等。
-
第五部分是云原生工具集,在前面的这些核心技术点之上,还有很多配套的生态或者周边的工具需要使用,比如流程自动化与配置管理、容器镜像仓库、云原生安全技术以及云端密码管理等。
-
最后则是 Serverless。Serverless 是一种 PaaS 的特殊形态,它定义了一种更为“极端抽象”的应用编写方式,包含了 FaaS 和 BaaS 这样的概念。而无论是 FaaS 还是 BaaS,其最为典型的特点就是按实际使用计费(Pay as you go),因此 Serverless 计费也是重要的知识和概念。
4.4、Swarm
目前三大主流的容器平台Swarm, Mesos和Kubernetes具有不同的容器调度系统 ;
Swarm的特点是直接调度Docker容器,并且提供和标准Docker API一致的API。
每台服务器上都装有Docker并且开启了基于HTTP的DockerAPI。这个集群中有一个SwarmManager的管理者,用来管理集群中的容器资源。管理者的管理对象不是服务器层面而是集群层面的,也就是说通过Manager,我们只能笼统地向集群发出指令而不能具体到某台具体的服务器上要干什么(这也是Swarm的根本所在)。至于具体的管理实现方式,Manager向外暴露了一个HTTP接口,外部用户通过这个HTTP接口来实现对集群的管理。

4.5、Mesos
Mesos针对不同的运行框架采用相对独立的调度系统,其框架提供了Docker容器的原生支持。 Mesos并不负责调度而是负责委派授权,毕竟很多框架都已经实现了复杂的调度。
4.6、Kubernetes
Kubernetes则采用了Pod和Label这样的概念把容器组合成一个个的互相存在依赖关系的逻辑单元。相关容器被组合成Pod后被共同部署和调度,形成服务(Service)。这个是Kubernetes和Swarm,Mesos的主要区别。
Kubernetes(k8s)是自动化容器操作的开源平台,这些操作包括部署,调度和节点集群间扩展。如果你曾经用过Docker容器技术部署容器,那么可以将Docker看成Kubernetes内部使用的低级别组件。Kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术。

使用Kubernetes可以:
-
自动化容器的部署和复制
-
随时扩展或收缩容器规模
-
将容器组织成组,并且提供容器间的负载均衡
-
很容易地升级应用程序容器的新版本
-
提供容器弹性,如果容器失效就替换它,等等…
三、Kubernetes
一、k8s基本介绍
1、borg系统
Borg. Google的Borg系统运行几十万个以上的任务,来自几千个不同的应用,跨多个集群,每个集群(cell)有上万个机器。它通过管理控制、高效的任务包装、超售、和进程级别性能隔离实现了高利用率。它支持高可用性应用程序与运行时功能,最大限度地减少故障恢复时间,减少相关故障概率的调度策略。以下就是Borg的系统架构图。其中Scheduler负责任务的调度。

2、k8s基本介绍
就在Docker容器技术被炒得热火朝天之时,大家发现,如果想要将Docker应用于具体的业务实现,是存在困难的——编排、管理和调度等各个方面,都不容易。于是,人们迫切需要一套管理系统,对Docker及容器进行更高级更灵活的管理。就在这个时候,K8S出现了。
*K8S*,就是基于容器的集群管理平台,它的全称,是kubernetes**

3、k8s主要功能
Kubernetes是docker容器用来编排和管理的工具,它是基于Docker构建一个容器的调度服务,提供资源调度、均衡容灾、服务注册、动态扩缩容等功能套件。Kubernetes提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下:
-
数据卷: Pod中容器之间共享数据,可以使用数据卷。
-
应用程序健康检查: 容器内服务可能进程堵塞无法处理请求,可以设置监控检查策略保证应用健壮性。
-
复制应用程序实例: 控制器维护着Pod副本数量,保证一个Pod或一组同类的Pod数量始终可用。
-
弹性伸缩: 根据设定的指标(CPU利用率)自动缩放Pod副本数。
-
服务发现: 使用环境变量或DNS服务插件保证容器中程序发现Pod入口访问地址。
-
负载均衡: 一组Pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他Pod可通过这个ClusterIP访问应用。
-
滚动更新: 更新服务不中断,一次更新一个Pod,而不是同时删除整个服务。
-
服务编排: 通过文件描述部署服务,使得应用程序部署变得更高效。
-
资源监控: Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDB时序数据库,再由Grafana展示。
-
提供认证和授权: 支持属性访问控制(ABAC)、角色访问控制(RBAC)认证授权策略。
4、k8s集群
这个集群主要包括两个部分:
-
一个Master节点(主节点)
-
一群Node节点(计算节点)

一看就明白:Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器。
5、Master节点
Master节点包括API Server、Scheduler、Controller manager、etcd。API Server是整个系统的对外接口,供客户端和其它组件调用,相当于“营业厅”。Scheduler负责对集群内部的资源进行调度,相当于“调度室”。Controller manager负责管理控制器,相当于“大总管”。

6、node节点

Node节点包括Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选),还有就是Pod
7、k8s master
7.1、api server
Kubernetes API Server: Kubernetes API,集群的统一入口,各组件协调者,以HTTP API提供接口服务,所有对象资源的增删改查和监听操作都 交给APIServer处理后再提交给Etcd存储。
7.2、managerController

Kubernetes Controller: 处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的各个资源控制器对于如下: 1)Replication Controller: 管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。 2)Node Controller: 管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。 3)Namespace Controller: 管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。 4)Service Controller: 管理维护Service,提供负载以及服务代理。5)EndPoints Controller: 管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints (即Pod Ip + Container Port)。 6)Service Account Controller: 管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。 7)Persistent Volume Controller: 管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。 8)Daemon Set Controller: 管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。 9)Deployment Controller: 管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和 Pod的更新。 10)Job Controller: 管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目 11)Pod Autoscaler Controller: 实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作
7.3、etcd
etcd 是一个分布式的、可靠的 key-value 存储系统,它用于存储分布式系统中的关键数据,这个定义非常重要。

etcd是一个第三方服务,分布式键值存储系统。用于保持集群状态,比如Pod、Service等对象信息
etcd是一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。Etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象的状态信息。整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置,分别是:
1)网络插件flannel、对于其它网络插件也需要用到etcd存储网络的配置信息
2)kubernetes本身,包括各种对象的状态和元信息配置
7.4、scheduler
根据调度算法为新创建的Pod选择一个Node节点。 scheduler在整个系统中承担了承上启下的重要功能,承上是指它负责接收controller manager创建新的Pod,为其安排一个落脚的目标Node,启下是指安置工作完成后,目标Node上的kubelet服务进程接管后继工作。
也就是说scheduler的作用是通过调度算法为待调度Pod列表上的每一个Pod从Node列表中选择一个最合适的Node。

8、k8s node
8.1、kubelet
kubelet是Master在Node节点上的Agent,每个节点都会启动 kubelet进程,用来处理 Master 节点下发到本节点的任务,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、 下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
1、kubelet 默认监听四个端口,分别为 10250 、10255、10248、4194

-
10250(kubelet API):kubelet server 与 apiserver 通信的端口,定期请求 apiserver 获取自己所应当处理的任务,通过该端口可以访问获取 node 资源以及状态。
-
10248(健康检查端口):通过访问该端口可以判断 kubelet 是否正常工作, 通过 kubelet 的启动参数 --healthz-port 和 --healthz-bind-address 来指定监听的地址和端口。
-
4194(cAdvisor 监听):kublet 通过该端口可以获取到该节点的环境信息以及 node 上运行的容器状态等内容,访问 http://localhost:4194 可以看到 cAdvisor 的管理界面,通过 kubelet 的启动参数
--cadvisor-port可以指定启动的端口。 -
10255 (readonly API):提供了 pod 和 node 的信息,接口以只读形式暴露出去,访问该端口不需要认证和鉴权。
8.2、kube-proxy
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作,kube-proxy 本质上,类似一个反向代理. 我们可以把每个节点上运行的 kube-proxy 看作 service 的透明代理兼LB.

kube-proxy 监听 apiserver 中service 与Endpoint 的信息, 配置iptables 规则,请求通过iptables 直接转发给 pod
8.3、docker
运行容器的引擎。
8.4、pod
Pod是最小部署单元,一个Pod有一个或多个容器组成,Pod中容器共享存储和网络,在同一台Docker主机上运行
1)pod基本结构

Pause的作用:
我们看下在node节点上都会起很多pause容器,和pod是一一对应的。
每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中。同一个Pod里的容器之间仅需通过localhost就能互相通信。
kubernetes中的pause容器主要为每个业务容器提供以下功能:
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
UTS命名空间:Pod中的多个容器共享一个主机名;Volumes(共享存储卷):
Pod中的各个容器可以访问在Pod级别定义的Volumes。
2)控制器pod
-
ReplicationController & ReplicaSet & Deployment
ReplicationController
用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代,而如果异常多出的容器也会自动回收。
在新版本的 Kubernetes 中建议使用ReplicaSet 来取代ReplicationController
ReplicaSet
ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector

虽然ReplicaSet可以独立使用,但一般还是建议使用Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet 不支持 rolling-update 但 Deployment支持)

Deployment为Pod和ReplicaSet 提供了一个 声明式定义方法,用来替代以前的 ReplicationController 来方便的管理应用。
典型的应用场景:
(1)、定义Deployment 来创建 Pod 和 ReplicaSet
(2)、滚动升级和回滚应用
(3)、扩容和索容
(4)、暂停和继续 Deployment

Deployment不仅仅可以滚动更新,而且可以进行回滚,如何发现升级到V2版本后,发现服务不可用,可以回滚到V1版本。
HPA(HorizontalPodAutoScale)
Horizontal Pod Autoscaling 仅适用于 Deployment 和 ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容

- StatefullSet
StatefullSet 是为了解决有状态服务的问题(对应Deployments 和 ReplicaSets 是为无状态服务而设计),其应用场景包括:
(1) 稳定的持久化存储,即Pod重新调度后还是能访问的相同持久化数据,基于PVC来实现
(2)稳定的网络标志,及Pod重新调度后其 PodName 和 HostName 不变,基于Headlesss Service(即没有 Cluster IP 的 Service)来实现。
(3)有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从 0 到 N-1,在下一个Pod运行之前所有之前的Pod必须都是Running 和 Ready 状态),基于 init containers 来实现。
(4)有序收缩,有序删除(即从N-1 到 0)
解析:有状态:需要实时的进行数据更新及存储,把某个服务抽离出去,再加入回来就没有办法正常工作,这样的服务就是有状态服务。
例如: mysql,Redis....无状态:docker主要面对的是无状态服务,所谓的无状态服务就是没有对应的存储数据需要实时的保留,或者是把服务摘除后经过一段时间运行后再把服务放回去依然能够正常运行,就是无状态服务。
例如: Apache、lvs
-
DaemonSet
DaemonSet确保全部(或者一些 [ node打上污点(可以想象成一个标签),pod如果不定义容忍这个污点,那么pod就不会被调度器分配到这个node ])Node上运行一个Pod的副本。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除他创建的所有Pod,使用DaemonSet 的一些典型用法:
(1) 运行集群存储daemon,例如在每个Node上运行glustered,ceph
(2)在每个Node上运行日志收集Daemon,例如:fluentd、logstash.
(3)在每个Node上运行监控Daemon,例如:Prometheus Node Exporter
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
Cron Job管理基于时间Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
9、 其他插件

COREDNS:可以为集群中的SVC创建一个域名IP的对应关系解析
DASHBOARD:给 K8S 集群提供一个 B/S 结构访问体系
INGRESS CONTROLLER:官方只能实现四层代理,INGRESS 可以实现七层代理
FEDERATION:提供一个可以跨集群中心多K8S统一管理功能
PROMETHEUS:提供K8S集群的监控能力
ELK:提供 K8S 集群日志统一分析介入平台
二、核心组件原理
1、RC[控制器]
ReplicationController
用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代,而如果异常多出的容器也会自动回收。
在新版本的 Kubernetes 中建议使用ReplicaSet 来取代ReplicationController
2、RS[控制器]
ReplicaSet
ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector
虽然ReplicaSet可以独立使用,但一般还是建议使用Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet 不支持 rolling-update 但 Deployment支持)

3、Deployment
Deployment为Pod和ReplicaSet 提供了一个 声明式定义方法,用来替代以前的 ReplicationController 来方便的管理应用。
典型的应用场景:
(1)、定义Deployment 来创建 Pod 和 ReplicaSet
(2)、滚动升级和回滚应用
(3)、扩容和索容
(4)、暂停和继续 Deployment
Deployment不仅仅可以滚动更新,而且可以进行回滚,如果发现升级到V2版本后,发现服务不可用,可以回滚到V1版本。
4、HPA
HPA(HorizontalPodAutoScale)
Horizontal Pod Autoscaling 仅适用于 Deployment 和 ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容
5、StatefullSet
StatefullSet 是为了解决有状态服务的问题(对应Deployments 和 ReplicaSets 是为无状态服务而设计),其应用场景包括:
(1) 稳定的持久化存储,即Pod重新调度后还是能访问的相同持久化数据,基于PVC来实现
(2)稳定的网络标志,及Pod重新调度后其 PodName 和 HostName 不变,基于Headlesss Service(即没有 Cluster IP 的 Service)来实现。
(3)有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从 0 到 N-1,在下一个Pod运行之前所有之前的Pod必须都是Running 和 Ready 状态),基于 init containers 来实现。
(4)有序收缩,有序删除(即从N-1 到 0)
6、DaemonSet
DaemonSet确保全部(或者一些 [ node打上污点(可以想象成一个标签),pod如果不定义容忍这个污点,那么pod就不会被调度器分配到这个node ])
Node上运行一个Pod的副本。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除他创建的所有Pod,使用DaemonSet 的一些典型用法:
(1) 运行集群存储daemon,例如在每个Node上运行glustered,ceph
(2)在每个Node上运行日志收集Daemon,例如:fluentd、logstash.
(3)在每个Node上运行监控Daemon,例如:Prometheus Node Exporter
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
Cron Job管理基于时间Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
7、Volume
数据卷,共享Pod中容器使用的数据。
8、Label
标签用于区分对象(比如Pod、Service),键/值对存在;每个对象可以有多个标签,通过标签关联对象。
Kubernetes中任意API对象都是通过Label进行标识,Label的实质是一系列的Key/Value键值对,其中key于value由用户自己指定。
Label可以附加在各种资源对象上,如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去。
Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
我们可以通过给指定的资源对象捆绑一个或者多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便的进行资源分配、调度、配置等管理工作。
一些常用的Label如下:
版本标签:“release”:“stable”,“release”:“canary”…
环境标签:“environment”:“dev”,“environment”:“qa”,“environment”:“production”
架构标签:“tier”:“frontend”,“tier”:“backend”,“tier”:“middleware”
分区标签:“partition”:“customerA”,“partition”:“customerB”
质量管控标签:“track”:“daily”,“track”:“weekly”
Label相当于我们熟悉的标签,给某个资源对象定义一个Label就相当于给它大了一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制。
Label Selector在Kubernetes中重要使用场景如下:
-> kube-Controller进程通过资源对象RC上定义Label Selector来筛选要监控的Pod副本的数量,从而实现副本数量始终符合预期设定的全自动控制流程;
-> kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service岛对应Pod的请求转发路由表,从而实现Service的智能负载均衡;
-> 通过对某些Node定义特定的Label,并且在Pod定义文件中使用Nodeselector这种标签调度策略,kuber-scheduler进程可以实现Pod”定向调度“的特性;
三、服务发现
1、service
1.1、什么是Service
Service是一个抽象的概念。它通过一个虚拟的IP的形式(VIPs),映射出来指定的端口,通过代理客户端发来的请求转发到后端一组Pods中的一台(也就是endpoint)
Service定义了Pod逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了统一的服务访问入口以及服务代理和发现机制,关联多个相同Label的Pod,用户不需要了解后台Pod是如何运行。
外部系统访问Service的问题:
-> 首先需要弄明白Kubernetes的三种IP这个问题
- Node IP:Node节点的IP地址
- Pod IP: Pod的IP地址
- Cluster IP:Service的IP地址
-> 首先,Node IP是Kubernetes集群中节点的物理网卡IP地址,所有属于这个网络的服务器之间都能通过这个网络直接通信。这也表明Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务的时候,必须通过Node IP进行通信
-> 其次,Pod IP是每个Pod的IP地址,他是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。
最后Cluster IP是一个虚拟的IP,但更像是一个伪造的IP网络,原因有以下几点:
-> Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址
-> Cluster IP无法被ping,他没有一个“实体网络对象”来响应
-> Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。
-> Kubernetes集群之内,Node IP网、Pod IP网于Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊路由规则。
1.2、service原理

2、IPTables
Iptables模式为Services的默认代理模式。在iptables 代理模式中,kube-proxy不在作为反向代理的在VIPs 和backend Pods之间进行负载均衡的分发。这个工作放给工作在四层的iptables来实现。iptables 和netfilter紧密集成,密切合作,都在kernelspace 就实现了包的转发。
在这个模式下,kube-proxy 主要有这么几步来实现实现报文转发:
- 通过watching kubernetes集群 cluster API, 获取新建、删除Services或者Endpoint Pod指令。
- kube-proxy 在node上设置iptables规则,当有请求转发到Services的 ClusterIP上后,会立即被捕获,并重定向此Services对应的一个backend的Pod。
- kube-proxy会在node上为每一个Services对应的Pod设置iptables 规则,选择Pod默认算法是随机策略。
在iptables模式中,kube-proxy把流量转发和负载均衡的策略完全委托给iptables/netfiter 来做,这些转发操作都是在kernelspace 来实现,比userspace 快很多。

在iptables 中kube-proxy 只做好watching API 同步最新的数据信息这个角色。路由规则信息和转发都放在了kernelspace 的iptables 和netfiter 来做了。但是,这个这个模式不如userspace模式的一点是,在usersapce模式下,kube-proxy做了负载均衡,如果选择的backend 一台Pod没有想要,kube-proxy可以重试,在iptables模式下,就是一条条路由规则,要转发的backend Pod 没有响应,且没有被K8S 摘除,可能会导致转发到此Pod请求超时,需要配合K8S探针一起使用。
2.1、负载均衡的方式
在Linux中使用iptables完成tcp的负载均衡有两种模式:随机、轮询
The statistic module support two different modes:random:(随机)
the rule is skipped based on a probability
nth:(轮询)
the rule is skipped based on a round robin algorithm
2.2、随机方式
下面以一个example说明iptables两种LB方式的具体实现:
系统中提供3个servers,下面我们通过配置iptables使流量均衡访问这3台server。
# 随机:(Random balancing)
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode random --probability 0.33 -j DNAT --to-destination 10.0.0.2:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode random --probability 0.5 -j DNAT --to-destination 10.0.0.3:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -j DNAT --to-destination 10.0.0.4:1234
rules说明:
第一条规则中,指定–probability 0.33 ,则说明该规则有33%的概率会命中,
第二条规则也有33%的概率命中,因为规则中指定 --probability 0.5。 则命中的概率为:50% * (1 - 33%)=0.33
第三条规则中,没有指定 --probability 参数,因此意味着当匹配走到第三条规则时,则一定命中,此时走到第三条规则的概率为:1 - 0.33 -0.33 ≈ 0.33。
由上可见,三条规则命中的几率一样的。此外,如果我们想修改三条规则的命中率,可以通过 --probability 参数调整。
假设有n个server,则可以设定n条rule将流量均分到n个server上,其中 --probability 参数的值可通过以下公式计算得到:
其中 i 代表规则的序号(第一条规则的序号为1)n 代表规则/server的总数p 代表第 i 条规则中 --probability 的参数值p=1/(n−i+1)
注意:因为iptables中,规则是按顺序匹配的,由上至下依次匹配,因此设计iptables规则时,要严格对规则进行排序。因此上述三条规则的顺序也不可以调换,不然就无法实现LB均分了。
2.3、轮询方式
轮询算法中有两个参数:
n: 指每 n 个包p:指第 p 个包
在规则中 n 和 p 代表着: 从第 p 个包开始,每 n 个包执行该规则。
这样可能有点绕口,直接看栗子吧:
还是上面的例子,有3个server,3个server轮询处理流量包,则规则配置如下:
#every:每n个包匹配一次规则
#packet:从第p个包开始
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode nth --every 3 --packet 0 -j DNAT --to-destination 10.0.0.2:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode nth --every 2 --packet 0 -j DNAT --to-destination 10.0.0.3:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -j DNAT --to-destination 10.0.0.4:1234
3、IPVS
3.1、什么是IPVS
IPVS(IP虚拟服务器)实现传输层负载平衡,通常称为第4层LAN交换,是Linux内核的一部分。
IPVS在主机上运行,在真实服务器集群前充当负载均衡器。 IPVS可以将对基于TCP和UDP的服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。
3.2、IPVS vs. IPTABLES
IPVS模式在Kubernetes v1.8中引入,并在v1.9中进入了beta。 IPTABLES模式在v1.1中添加,并成为自v1.2以来的默认操作模式。 IPVS和IPTABLES都基于netfilter。 IPVS模式和IPTABLES模式之间的差异如下:
- IPVS为大型集群提供了更好的可扩展性和性能。
- IPVS支持比iptables更复杂的负载平衡算法(最小负载,最少连接,位置,加权等)。
- IPVS支持服务器健康检查和连接重试等。
我们都知道,在Linux 中iptables设计是用于防火墙服务的,对于比较少规则的来说,没有太多的性能影响。但是对于,一个K8S集群来说,会有上千个Services服务,当然也会转发到Pods,每个都是一条iptables规则,对集群来说,每个node上会有大量的iptables规则,简直是噩梦。
同样IPVS可以解决可能也会遇见这样大规模的网络转发需求,但是IPVS用hash tabels来存储网络转发规则,比iptables 在这上面更有优势,而且它主要工作在kernelspace,减少了上下文切换带来的开销。
3.3、IPVS负载步骤
kube-proxy和IPVS在配置网络转发中,有这么几步:
- 通过watching kubernetes集群 cluster API, 获取新建、删除Services或者Endpoint Pod指令,有新的Service建立,kube-proxy回调网络接口,构建IPVS规则。
- 同时,kube-proxy会定期同步 Services和backend Pods的转发规则,确保失效的转发能被更新修复。
- 有请求转发到后端的集群时,IPVS的负载均衡直接转发到backend Pod。
3.4、IPVS负载算法
IPVS支持的负载均衡算法有这么几种:
- rr: 轮询
- lc: 最小连接数
- dh: 目的地址hash
- sh: 源地址hash
- sed: 最短期望延迟
- nq: 无须队列等待
在node上通过 “–ipvs-scheduler”参数,指定kube-proxy的启动算法。
Kubernetes(K8s)-k8s资源清单
一、资源控制器
1、什么是控制器?
Kubernetes中内建了很多controller (控制器) ,这些相当于一个状态机,用来控制Pod的具体状态和行为
Pod 的分类
- 自主式 Pod:Pod 退出了,此类型的 Pod 不会被创建
- 控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
2、常用控制器
- ReplicationController(旧版本)
- ReplicaSet
- Deployment
- DaemonSet
- Job/Cronjob
3、自主式pod
# 自主式的pod: 单独定义一个pod,这个没有没有副本控制器管理,也没有对应deployment
#init-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: init-podlabels:app: myapp
spec:containers:- name: myappimage: hub.kaikeba.com/library/myapp:v1
#注意事项
#总结
#k8s资源对象(所有的k8s管理的资源,都叫做资源对象),都可以独立存在,但是需要根据相应原理,需求结合使用。
4、RC&RS
ReplicationController (RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收;
在新版本的Kubernetes中建议使用Replicaset来取代ReplicationController. ReplicaSet跟 ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector;
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:name: frontend
spec:replicas: 3selector:matchLabels: tier: frontend template:metadata:labels:tier: frontendspec:containers:- name: Java-nginximage: hub.kaikeba.com/library/myapp:v1env:- name: GET_HOSTS_FROM value: dnsports:- containerPort: 805、Deployment
Deployment为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,用来替代以前的 ReplicationController来方便的管理应用。典型的应用场景包括;
- 定义Deployment来创建Pod和ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续Deployment
#1)、部署一简单的Nginx应用
apiVersion: extensions/v1beta1
kind: Deployment
metadata:name: nginx-deployment
spec:replicas: 3template:metadata:labels:app: nginx spec:containers: - name: nginx image: nginx:1.7.9ports:- containerPort: 80Deployment更新策略
Deployment可以保证在升级时只有一定数量的Pod是down的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多一个不可用)
Deployment同时也可以确保只创建出超过期望数量的一定数量的Pod,默认的,它会确保最多比期望的Pod数量多一个的Pod是up的(最多1个surge )
未来的Kuberentes版本中,将从1-1变成25%-25%
kubect1 describe deployments
6、DaemonSet
#确保只运行一个副本,运行在集群中每一个节点上。(也可以部分节点上只运行一个且只有一个pod副本,如监控ssd硬盘)
# kubectl explain ds
# vim filebeat.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:name: my-deamonnamespace: defaultlabels: app: daemonset
spec:selector:matchLabels:app: my-daemonsettemplate:metadata:labels:app: my-daemonsetspec:containers:- name: daemon-appimage: hub.kaikeba.com/library/myapp:v1
7、Job
Job负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。而CronJob则就是在Job上加上了时间调度。
# 我们用Job这个资源对象来创建一个任务,我们定一个Job来执行一个倒计时的任务,定义YAML文件:
apiVersion: batch/v1
kind: Job
metadata:name: job-demo
spec:template:metadata:name: job-demospec:restartPolicy: Nevercontainers:- name: counterimage: busyboxcommand:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"# 创建
kubectl apply -f xx.yaml
# 查询日志
kubectl logs
注意Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always,我们知道Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话是不是就陷入了死循环了?
8、cronJob
CronJob其实就是在Job的基础上加上了时间调度,我们可以:在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。这个实际上和我们Linux中的crontab就非常类似了。
一个CronJob对象其实就对应中crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
crontab的格式如下:
分 时 日 月 星期 要运行的命令 第1列分钟0~59 第2列小时0~23) 第3列日1~31 第4列月1~12 第5列星期0~7(0和7表示星期天) 第6列要运行的命令
# 现在,我们用CronJob来管理我们上面的Job任务
apiVersion: batch/v1beta1
kind: CronJob
metadata:name: cronjob-demo
spec:schedule: "*/1 * * * *"jobTemplate:spec:template:spec:restartPolicy: OnFailurecontainers:- name: helloimage: busyboxargs:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"# 创建cronjob
kubctl apply -f xx.yaml
# 查询cronjob
kubectl get cronjob
# 查询jon ,cronjon会循环多个job
kubectl get job
# 实时监控查询job
kubectl get job -w我们这里的Kind是CronJob了,要注意的是.spec.schedule字段是必须填写的,用来指定任务运行的周期,格式就和crontab一样,另外一个字段是.spec.jobTemplate, 用来指定需要运行的任务,格式当然和Job是一致的。还有一些值得我们关注的字段.spec.successfulJobsHistoryLimit
二、Pod’s lifecycle
1、再次理解Pod
Pod是kubernetes中你可以创建和部署的最⼩也是最简的单位。 ⼀个Pod代表着集群中运⾏的⼀个进程。
Pod中封装着应⽤的容器(有的情况下是好⼏个容器) , 存储、 独⽴的⽹络IP, 管理容器如何运⾏的策略选项。 Pod代
表着部署的⼀个单位: kubernetes中应⽤的⼀个实例, 可能由⼀个或者多个容器组合在⼀起共享资源。
在Kubrenetes集群中Pod有如下两种使⽤⽅式:
- ⼀个Pod中运⾏⼀个容器。 “每个Pod中⼀个容器”的模式是最常⻅的⽤法; 在这种使⽤⽅式中, 你可以把Pod想象成是单个容器的封装, kuberentes管理的是Pod⽽不是直接管理容器。
- 在⼀个Pod中同时运⾏多个容器。 ⼀个Pod中也可以同时封装⼏个需要紧密耦合互相协作的容器, 它们之间共享资源。 这些在同⼀个Pod中的容器可以互相协作成为⼀个service单位——⼀个容器共享⽂件, 另⼀个“sidecar”容器来更新这些⽂件。 Pod将这些容器的存储资源作为⼀个实体来管理。
每个Pod都是应⽤的⼀个实例。 如果你想平⾏扩展应⽤的话(运⾏多个实例) , 你应该运⾏多个Pod, 每个Pod都是⼀个应⽤实例。 在Kubernetes中, 这通常被称为replication。
服务如何部署:
1、建议一个pod中部署一个容器(通常情况下都是这样的)
2、有一些业务上紧密耦合的服务,可以部署在一个容器,通信效率比较高。
2、Pod Phase
Pod 的 status 属性是一个 PodStatus 对象,拥有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。
| 阶段 | 描述 |
|---|---|
| Pending | Pod 已被 Kubernetes 接受,但尚未创建一个或多个容器镜像。这包括被调度之前的时间以及通过网络下载镜像所花费的时间,执行需要一段时间。 |
| Running | Pod 已经被绑定到了一个节点,所有容器已被创建。至少一个容器正在运行,或者正在启动或重新启动。 |
| Succeeded | 所有容器成功终止,也不会重启。 |
| Failed | 所有容器终止,至少有一个容器以失败方式终止。也就是说,这个容器要么已非 0 状态退出,要么被系统终止。 |
| Unknown | 由于一些原因,Pod 的状态无法获取,通常是与 Pod 通信时出错导致的。 |
使用命令查询pod的状态:
#查询pod的详细状态
kubectl describe pods test1 -n kube-system3、重启策略
Pod 的重启策略有 3 种,默认值为 Always。- Always : 容器失效时,kubelet 自动重启该容器;
- OnFailure : 容器终止运行且退出码不为0时重启;
- Never : 不论状态为何, kubelet 都不重启该容器。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒…)重新启动,并在成功执行十分钟后重置。
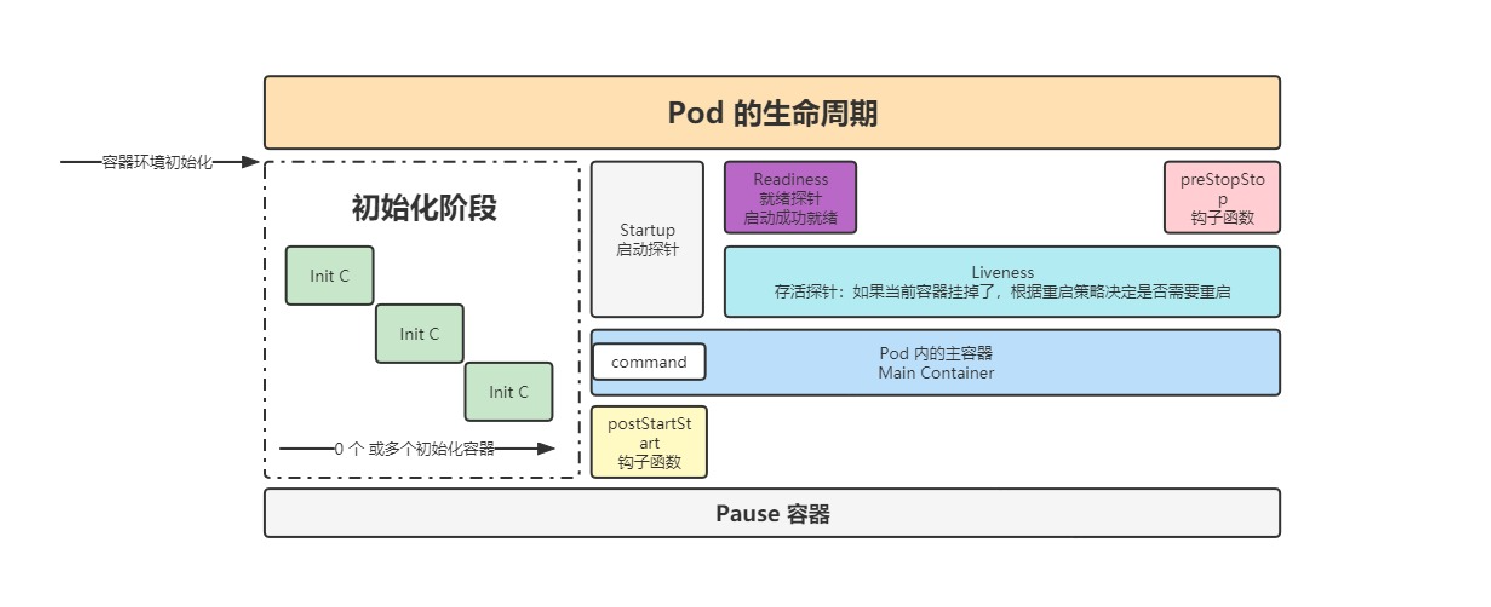
4、生命周期详解
pod生命周期示意图(初始化容器,post start,main container…,pre stop):

-
说明:
- 初始化容器阶段初始化pod中每一个容器,他们是串行执行的,执行完成后就退出了
- 启动主容器main container
- 在main container刚刚启动之后可以执行post start命令
- 在整个main container执行的过程中可以做两类探测:liveness probe(存活探测)和readiness probe(就绪探测)
- 在main container结束前可以执行pre stop命令
-
配置启动后钩子(post start)和终止前钩子(pre stop)
- post start:容器创建之后立即执行,如果失败了就会按照重启策略重启容器
- pre stop:容器终止前立即执行,执行完成之后容器将成功终止
-
可以使用以下命令查看post start和pre stop的设置格式:
- kubectl explain pod.spec.containers.lifecycle.preStop
- kubectl explain pod.spec.containers.lifecycle.postStart
5、pod init
5.1、init容器
Pod能够持有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的Init容器
Init容器与普通的容器非常像,除了如下两点:
- Init容器总是运行到成功完成为止
- 每个Init容器都必须在下一个Init容器启动之前成功完成
如果Pod的Init容器失败,Kubernetes会不断地重启该Pod,直到Init容器成功为止。然而,如果Pod对应的restartPolicy为Never,它不会重新启动
5.2、init作用
因为Init容器具有与应用程序容器分离的单独镜像,所以它们的启动相关代码具有如下优势:
- ① 它们可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的
- ② 它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像,只需要在安装过程中使用类似sed、awk、python或dig这样的工具。
- ③ 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像。
- ④ Init容器使用LinuxNamespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问Secret的权限,而应用程序容器则不能。
- ⑤ 它们必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件。
5.3、特殊说明
- ① 在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出(网络和数据卷初始化是在pause)
- ② 如果由于运行时或失败退出,将导致容器启动失败,它会根据Pod的restartPolicy指定的策略进行重试。然而,如果Pod的restartPolicy设置为Always,Init容器失败时会使用RestartPolicy策略
- ③ 在所有的Init容器没有成功之前,Pod将不会变成Ready状态。Init容器的端口将不会在Service中进行聚集。正在初始化中的Pod处于Pending状态,但应该会将Initializing状态设置为true
- ④ 如果Pod重启,所有Init容器必须重新执行
- ⑤ 对Init容器spec的修改被限制在容器image字段,修改其他字段都不会生效。更改Init容器的image字段,等价于重启该Pod
- ⑥ Init容器具有应用容器的所有字段。除了readinessProbe(就绪检测),因为Init容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行
- ⑦ 在Pod中的每个app和Init容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误
5.4、一个例子
#init-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: init-podlabels:app: myapp
spec:containers:- name: myappimage: hub.kaikeba.com/library/busybox:v1command: ['sh', '-c', 'echo -n "running at " && date +%T && sleep 600']initContainers:- name: init-mydbimage: hub.kaikeba.com/library/busybox:v1command: ['sh', '-c', 'until nslookup init-db; do echo waiting for init-db;date +%T; sleep 2;echo; done;']#init-db.yaml
kind: Service
apiVersion: v1
metadata:name: init-db
spec:ports:- protocol: TCPport: 80targetPort: 3366#创建
kubectl create -f init-pod.yaml
#查看pod状态 init没成功
kubectl get pod
#查看log
kubectl logs init-pod -c init-mydb#创建svr
kubectl create -f init-db.yaml
#查看
kubectl get svc#svc有ip地址,等待init容器运行成功
kubectl get pod#删除
kubectl delete -f init-pod.yaml
kubectl delete -f init-db.yaml
① 在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出(网络和数据卷初始化是在pause)
② 如果由于运行时或失败退出,将导致容器启动失败,它会根据Pod的restartPolicy指定的策略进行重试。然而,如果Pod的restartPolicy设置为Always,Init容器失败时会使用RestartPolicy策略
③ 在所有的Init容器没有成功之前,Pod将不会变成Ready状态。Init容器的端口将不会在Service中进行聚集。正在初始化中的Pod处于Pending状态,但应该会将Initializing状态设置为true
④ 如果Pod重启,所有Init容器必须重新执行
⑤ 对Init容器spec的修改被限制在容器image字段,修改其他字段都不会生效。更改Init容器的image字段,等价于重启该Pod
⑥ Init容器具有应用容器的所有字段。除了readinessProbe(就绪检测),因为Init容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行
⑦ 在Pod中的每个app和Init容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误
6、容器探针

探针是由kubelet对容器执行的定期诊断。要执行诊断,kubelet调用由容器实现的Handler。有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的IP地址执行HTTPGet请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动
探测方式
- ① livenessProbe:指示容器是否正在运行。如果存活探测失败,则kubelet会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为Success(会随着容器的生命周期一直存在)
- ② readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success
检测探针 - 就绪检测
- readinessProbe-httpget
#readinessProbe-httpget
apiVersion: v1
kind: Pod
metadata:name: readiness-httpget-pod namespace: default
spec:containers:- name: readiness-httpget-container image: hub.kaikeba.com/library/myapp:v1 imagePullPolicy: IfNotPresentreadinessProbe:httpGet:port: 80path: /index1.html initialDelaySeconds: 1periodSeconds: 3
检测探针 - 存活检测
- livenessProbe-exec方式
apiVersion: v1
kind: Pod
metadata:name: liveness-exec-podnamespace: default
spec:containers: - name: liveness-exec-container image: hub.kaikeba.cn/library/busybox:v1imagePullPolicy: IfNotPresent command: ["/bin/sh","-c","touch /tmp/live;sleep 60;rm -rf /tmp/live;sleep 3600"] livenessProbe:exec:command: ["test","-e","/tmp/live"]initialDelaySeconds: 1periodSeconds: 3-
livenessProbe-Httpget方式
存活检测
apiVersion: v1
kind: Pod
metadata:name: liveness-httpget-pod namespace: default
spec:containers: - name: liveness-httpget-container image: hub.kaikeba.com/library/myapp:v1imagePu11Policy: IfNotPresent ports:- name: http containerPort: 80 livenessProbe:httpGet:port: http path: /index.html initialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10
- livenessProbe-Tcp方式
apiVersion: v1
kind: Pod
metadata:name: probe-tcp
spec:containers:- name: nginximage: hub.kaikeba.com/library/myapp:v1 livenessProbe:initialDelaySeconds: 5 timeoutSeconds: 1 tcpSocket:port: 80periodSeconds: 3
- 存活就绪
apiVersion: v1
kind: Pod
metadata:name: liveness-httpget-pod namespace: default
spec:containers: - name: liveness-httpget-container image: hub.kaikeba.com/library/myapp:v1 imagePullPolicy: IfNotPresent ports:- name: http containerPort: 80 readinessProbe:httpGet: port: 80path: /index1.html initialDelaySeconds: 1 periodSeconds: 3 livenessProbe:httpGet:port: http path: /index.html initialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10- 启动及退出动作
apiVersion: v1
kind: Pod
metadata:name: lifecycle-startstop
spec:containers:- name: lifecycle-containerimage: nginxlifecycle:poststart:exec:command: ["/bin/sh","-c","echo Hello from the postStart handler > /usr/share/message"]prestop:exec:command: ["/bin/sh","-c","echo Hello container stop"]
Kubernetes(K8s)-k8s资源清单
一、k8s资源指令

1、基础操作
#创建且运行一个pod
#deployment、rs、pod被自动创建
kubectl run my-nginx --image=nginx --port=80#增加创建副本数量
kubectl scale deployment/my-nginx --replicas = 3#添加service
#kubectl expose将RC、Service、Deployment或Pod作为新的Kubernetes Service公开。kubectl expose deployment/my-nginx --port=30000 --target-port=80#编辑service配置文件kubectl edit svc/my-nginx#其他的基础指令
#查看集群中有几个Node
kubectl get nodes# 查看pod
kubectl get pods# 查看服务详情信息
kubectl describe pod my-nginx-379829228-cwlbb# 查看已部署
[root@jackhu ~]# kubectl get deployments# 删除pod
[root@jackhu ~]# kubectl delete pod my-nginx-379829228-cwlbb# 删除部署的my-nginx服务。彻底删除pod
[root@jackhu ~]# kubectl delete deployment my-nginx
deployment "my-nginx" deleted# 删除service服务
kubectl delete service my-nginx2、命令手册
kubenetes命令手册,详情请查询下表:
| 类型 | 命令 | 描述 |
|---|---|---|
| 基础命令 | create | 通过文件名或标准输入创建资源 |
| ecpose | 将一个资源公开为一个新的Service | |
| run | 在集群中运行一个特定的镜像 | |
| set | 在对象上设置特定的功能 | |
| get | 显示一个或多个资源 | |
| explain | 文档参考资料 | |
| edit | 使用默认的编辑器编辑一个资源 | |
| delete | 通过文件名,标准输入,资源名称或者标签选择器来删除资源 | |
| 部署命令 | rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 | |
| scale | 扩容会缩容Pod数量,Deployment,ReplicaSet,RC或Job | |
| autoscale | 创建一个自动选择扩容或缩容并设置Pod数量 | |
| 集群管理命令 | certificate | 修改证书资源 |
| cluster-info | 显示集群信息 | |
| top | 显示资源(CPU/Memory/Storage)使用,需要Heapster运行 | |
| cordon | 标记节点不可调 | |
| uncordon | 标记节点可调度 | |
| drain | 驱逐节点上的应用,准备下线维护 | |
| taint | 修改节点taint标记 | |
| 故障诊断和调试命令 | describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个Pod中打印一个容器日志,如果Pod只有一个容器,容器名称是可选的 | |
| attach | 附加到一个运行的容器 | |
| exec | 执行命令到容器 | |
| port-forward | 转发一个或多个本地端口到一个pod | |
| proxy | 运行一个proxy到Kubernetes API server | |
| cp | 拷贝文件或者目录到容器中 | |
| auth | 检查授权 | |
| 高级命令 | apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改,更新资源的字段 | |
| replace | 通过文件名或标准输入替换一个资源 | |
| convert | 不同的API版本之间转换配置文件 | |
| 设置命令 | label | 更新资源上的标签 |
| annotate | 更新资源上的注释 | |
| completion | 用于实现kubectl工具自动补全 | |
| 其他命令 | api-versions | 打印受支持的API 版本 |
| config | 修改kubeconfig文件(用于访问API,比如配置认证信息) | |
| help | 所有命令帮助 | |
| plugin | 运行一个命令插件 | |
| version | 打印客户端和服务版本信息 |
二、资源清单
1、required
必须存在的属性【创建资源清单的时候没有这些属性的存在它是不允许被执行的】
| 参数名称 | 字段类型 | 说明 |
|---|---|---|
| version | String | 这里是指的是K8SAPI的版本,目前基本上是v1,可以用kubectl api-version命令查询 |
| kind | String | 这里指的是yam文件定义的资源类型和角色,比如:Pod |
| metadata | Object | 元数据对象,固定值就写metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义,如果不定义的话则默认是default名称空间 |
| Spec | Object | 详细定义对象,固定值就写Spec |
| spec.containers[] | List | 这里是Spec对象的容器列表定义,是个列表 |
| spec.containers[].name | String | 这里定义容器的名字 |
| spec.containers[].image | String | 这里定义要用到的镜像名称 |
2、optional
主要属性【这些属性比较重要,如果不指定的话系统会自动补充默认值】
| 参数名称 | 字段类型 | 说明 |
|---|---|---|
| spec.containers[].name | String | 这里定义容器的名字 |
| spec.containers[].image | String | 这里定义要用到的镜像名称 |
| spec.containers[].imagePullPolicy | String | 定义镜像拉取策略,有Always、Never、IfNotPresent三个值可选(1)Always:意思是每次都尝试重新拉取镜像(2)Never:表示仅使用本地镜像(3)lfNotPresent:如果本地有镜像就使用本地镜像,没有就拉取在线镜像。上面三个值都没设置的话,默认是Always。 |
| spec.containers[].command[] | List | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令。 |
| spec.containers[].args[] | List | 指定容器启动命令参数,因为是数组可以指定多个。 |
| spec.containers[].workingDir | String | 指定容器的工作目录,进入容器时默认所在的目录 |
| spec.containers[].volumeMounts[] | List | 指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name | String | 指定可以被容器挂载的存储卷的名称 |
| spec.containers[].volumeMounts[].mountPath | String | 指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volumeMounts[].readOnly | String | 设置存储卷路经的读写模式,true或者false,默认为读写模式 |
| spec.containers[].ports[] | List | 指定容器需要用到的端口列表 |
| spec.containers[].ports[].name | String | 指定端口名称 |
| spec.containers[].ports[].containerPort | String | 指定容器需要监听的端口号 |
| spec.containers[].ports[].hostPort | String | 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认值为 TCP |
| spec.containers[].env[] | List | 指定容器运行前需设置的环境变量列表 |
| spec.containers[].env[].name | String | 指定环境变量名称 |
| spec.containers[].env[].value | String | 指定环境变量值 |
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu | String | 指定CPU的限制,单位为core数,将用于docker run --cpu-shares参数这里前面文章 Pod资源限制有讲过) |
| spec.containers[].resources.limits.memory | String | 指定MEM内存的限制,单位为MlB、GiB |
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory | String | 内存请求,单位为MIB、GiB,容器启动的初始化可用数量 |
3、other
额外的的一些属性。
| 参数名称 | 字段类型 | 说明 |
|---|---|---|
| spec.restartPolicy | String | 定义Pod的重启策略,可选值为Always、OnFailure,默认值为Always。1.Always:Pod一旦终止运行,则无论容器是如何终止的,kubelet服务都将重启它。2.OnFailure:只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它。3.Never:Pod终止后,kubelet将退出码报告给Master,不会重启该Pod。 |
| spec.nodeSelector | Object | 定义Node的Label过滤标签,以key:value格式指定,选择node节点 |
| 去运行 | ||
| spec.imagePullSecrets | Object | 定义pull镜像时使用secret名称,以name:secretkey格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker0网桥,同时设置了true将无法在同一台宿主机上启动第二个副本。 |
查看资源有那些资源清单属性,使用以下命令
# 查询所有的资源清单资源
kubectl explain pod
# 查看属性说明
kubectl explain pod.apiVersion
4、资源清单格式
#如果没有给定group名称,那么默认为core,可以使用kubectlapi-versions命令获取当前k8s版本上所有的apiversion版本信息(每个版本可能不同)
apiVersion: group/apiversion
#资源类别
kind: Pod / Service / Deployment
#资源元数据
metadata: name: namespace: lables: annotations: #主要目的是方便用户阅读查找
spec: #期望的状态(disired state)
status: #当前状态,本字段由Kubernetes自身维护,用户不能去定义
5、常用命令
#获取apiVersion版本信息
kubectl api-versions
#获取资源的apiVersion的版本信息(以pod为例),该命令同时输出属性设置帮助文档
kubectl explain pod# 字段配置格式说明
apiVersion <string> #表示字符串类型
metadata <Object> #表示需要嵌套多层字段
1abels <map[string]string> #表示由k:v组成的映射
finalizers <[]string> #表示字串列表
ownerReferences <[]Object>#表示对象列表
hostPID <boolean> #布尔类型
priority <integer> #整型
name <string> -required- #如果类型后面接-required-,表示为必填字段#通过yaml文件创建pod
kubectl create -f xxx.yaml#使用 -o 参数 加 yaml,可以将资源的配置以yaml的格式输出出来,也可以使用json,输出为json格式
kubectl get pod {podName} -o yaml
6.创建namespace
创建namespace
命令: kubectl create -f $namespace.yaml 或 kubectl create namespace $namespace
yaml文件:
[root@123 ~]# cat test-namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: test-ns
kubectl delete ns $namespace
三、部署实例
1、nginx
1)创建deployment
#tomcat服务部署
apiVersion: v1
kind: ReplicationController
metadata:name: myweb
spec:replicas: 2selector:app: mywebtemplate:metadata:labels:app: mywebspec:containers:- name: mywebimage: docker.io/kubeguide/tomcat-app:v1ports:- containerPort: 8080env:- name: MYSQL_SERVICE_HOSTvalue: 'mysql'- name: MYSQL_SERVICE_PORTvalue: '3306'#创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploynamespace: default
spec:replicas: 3selector:matchLabels:app: myapprelease: stabeltemplate:metadata:labels:app: myapprelease: stabelenv: testspec:containers:- name: myappimage: nginx:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80#创建service服务
apiVersion: v1
kind: Service
metadata:name: mywebnamespace: default
spec:type: ClusterIPselector:app: myapprelease: stabelports:- name: httpport: 80targetPort: 80#创建pod
kubectl create[apply] -f xx.yaml
#创建成功后,发现报错:因为在这个pod中创建了2个容器,但是此2个容器出现了端口冲突
#查看原因:
kubectl describe pod my-app
# 查询某个容器的日志
kubectl log my-app -c test
2)创建tomcat-svc.yaml
apiVersion: v1
kind: Service
metadata:name: myweb
spec:type: NodePortports:- port: 8080targetPort: 8080nodePort: 30088selector:app: myweb
3、eureka部署
- deployment
apiVersion: apps/v1
kind: Deployment
metadata:name: myweb-deploymentnamespace: default
spec:replicas: 3selector:matchLabels:app: mywebrelease: stabeltemplate:metadata:labels:app: mywebrelease: stabelenv: testspec:containers:- name: mywebimage: myweb:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 10086
2)svc.yaml
apiVersion: v1
kind: Service
metadata:name: webnamespace: default
spec:type: NodePortselector:app: mywebrelease: stabelports:- name: httpport: 80targetPort: 10086
4、部署lottery
apiVersion: apps/v1
kind: Deployment
metadata:name: mylotterynamespace: lottery
spec:replicas: 3selector:matchLabels:app: lotteryApprelease: stabeltemplate:metadata:labels:app: lotteryApprelease: stabelenv: testspec:containers:- name: lotteryimage: lottery:1.0imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 8081
docker build -t lottery:1.0 .docker build -t lottery-api:1.0 .
5.指定pod运行node
https://www.cnblogs.com/wukc/p/17340180.html
configmap&secret&pv&pvc
一、configMap
我们在kubernetes上部署应用的时候,经常会需要传一些配置给我们的应用,比如数据库地址啊,用户名密码啊之类的。我们要做到这个,有好多种方案,比如:
- 我们可以直接在打包镜像的时候写在应用配置文件里面,但是这种方式的坏处显而易见而且非常明显。
- 我们可以在配置文件里面通过env环境变量传入,但是这样的话我们要修改env就必须去修改yaml文件,而且需要重启所有的container才行。
- 我们可以在应用启动的时候去数据库或者某个特定的地方拿,没问题!但是第一,实现起来麻烦;第二,如果配置的地方变了怎么办?
当然还有别的方案,但是各种方案都有各自的问题。
而且,还有一个问题就是,如果说我的一个配置,是要多个应用一起使用的,以上除了第三种方案,都没办法进行配置的共享,就是说我如果要改配置的话,那得一个一个手动改。假如我们有100个应用,就得改100份配置,以此类推……
kubernetes对这个问题提供了一个很好的解决方案,就是用ConfigMap和Secret
ConfigMap功能在kubernetes1.2版本中引入,许多应用程序会从配置文件,命令行参数或环境变量中读取配置信息,ConfigAPI给我们提供了向容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
ConfigMap对像是一系列配置的集合,k8s会将这一集合注入到对应的Pod对像中,并为容器成功启动使用。注入的方式一般有两种,一种是挂载存储卷,一种是传递变量。ConfigMap被引用之前必须存在,属于名称空间级别,不能跨名称空间使用,内容明文显示。ConfigMap内容修改后,对应的pod必须重启或者重新加载配置(支持热更新的应用,不需要重启)。
Secret类似于ConfigMap,是用Base64加密,密文显示,一般存放敏感数据。一般有两种创建方式,一种是使用kubectl create创建,一种是用Secret配置文件。
1、应用场景
应用场景:镜像往往是一个应用的基础,还有很多需要自定义的参数或配置,例如资源的消耗、日志的位置级别等等,这些配置可能会有很多,因此不能放入镜像中,Kubernetes中提供了Configmap来实现向容器中提供配置文件或环境变量来实现不同配置,从而实现了镜像配置与镜像本身解耦,使容器应用做到不依赖于环境配置。
我们经常都需要为我们的应用程序配置一些特殊的数据,比如密钥、Token 、数据库连接地址或者其他私密的信息。你的应用可能会使用一些特定的配置文件进行配置,比如settings.py文件,或者我们可以在应用的业务逻辑中读取环境变量或者某些标志来处理配置信息。
我们要做到这个,有好多种方案,比如:
1.我们可以直接在打包镜像的时候写在应用配置文件里面,但是这种方式的坏处显而易见而且非常明显。
2.我们可以在配置文件里面通过 env 环境变量传入,但是这样的话我们要修改 env 就必须去修改 yaml 文件,而且需要重启所有的 container 才行。
3.我们可以在应用启动的时候去数据库或者某个特定的地方拿,没问题!但是第一,实现起来麻烦;第二,如果配置的地方变了怎么办?当然还有别的方案,但是各种方案都有各自的问题。
而且,还有一个问题就是,如果说我的一个配置,是要多个应用一起使用的,以上除了第三种方案,都没办法进行配置的共享,就是说我如果要改配置的话,那得一个一个手动改。假如我们有 100 个应用,就得改 100 份配置,以此类推……kubernetes 对这个问题提供了一个很好的解决方案,就是用 ConfigMap 和 Secret。
向容器传递参数:
| Docker | Kubernetes | 描述 |
|---|---|---|
| ENTRYPOINT | command | 容器中的可执行文件 |
| CMD | args | 需要传递给可执行文件的参数 |
如果需要向容器传递参数,可以在Yaml文件中通过command和args或者环境变量的方式实现。
apiVersion: v1
kind: Pod
metadata:name: print-greeting
spec:containers:- name: env-print-demoimage: hub.kaikeba.com/java12/bash:v1env:- name: GREETINGvalue: "Warm greetings to"- name: HONORIFICvalue: "The Most Honorable"- name: NAMEvalue: "Kubernetes"command: ["echo"]args: ["$(GREETING) $(HONORIFIC) $(NAME)"]# 创建后,命令 echo Warm greetings to The Most Honorable Kubernetes 将在容器中运行,也就是环境变量中的值被传递到了容器中。# 查看pod就可以看出kubectl logs podname
2、创建configMap
2.1、help文档
[root@k8s-master-155-221 configmap]# kubectl create configmap --help
......
Aliases:
configmap, cm #可以使用cm替代Examples:# Create a new configmap named my-config based on folder barkubectl create configmap my-config --from-file=path/to/bar #从目录创建 文件名称为键 文件内容为值?# Create a new configmap named my-config with specified keys instead of file basenames on diskkubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt #从文件创建 key1为键 文件内容为值# Create a new configmap named my-config with key1=config1 and key2=config2kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2 #直接命令行给定,键为key1 值为config1# Create a new configmap named my-config from the key=value pairs in the filekubectl create configmap my-config --from-file=path/to/bar #从文件创建 文件名为键 文件内容为值# Create a new configmap named my-config from an env filekubectl create configmap my-config --from-env-file=path/to/bar.env
2.2、使用目录创建
# 指定目录
ls /docs/user-guide/configmap
#创建game.properties,ui.properties,game.cnf ui.conf ,game.yaml
# game.properties
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30# ui.propertes
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice#创建configmap ,指令
# game-config :configmap的名称
# --from-file:指定一个目录,目录下的所有内容都会被创建出来。以键值对的形式
# --from-file指定在目录下的所有文件都会被用在 ConfigMap 里面创建一个键值对,键的名字就是文件名,值就是文件的内容
kubectl create configmap game-config --from-file=docs/user-guide/configmap# 查看configmap文件
kubectl get cm # 查看详细信息
kubectl get cm game-config -o yaml kubectl describe cm
2.3、根据文件创建
只需要指定为一个文件就可以从单个文件中创建ConfigMap
# 指定创建的文件即可
kubectl create configmap game-config-2 --from-file=/docs/user-guide/configmap/game.propertes#查看
kubectl get configmaps game-config-2 -o yaml
–from-file这个参数可以使用多次,可以分别指定game.properties,ui.propertes.效果和指定整个目录是一样的。
2.4、文字创建
# 使用--from-literal 方式直接创建configmap
# Create the ConfigMap
$ kubectl create configmap my-config --from-literal=key1=value1 --from-literal=key2=value2
configmap "my-config" created # Get the ConfigMap Details for my-config
$ kubectl get configmaps my-config -o yaml
apiVersion: v1
data:key1: value1key2: value2
kind: ConfigMap
metadata:creationTimestamp: 2017-05-31T07:21:55Zname: my-confignamespace: defaultresourceVersion: "241345"selfLink: /api/v1/namespaces/default/configmaps/my-configuid: d35f0a3d-45d1-11e7-9e62-080027a46057# 文字方式
kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm#查看
kubectlget configmaps special-config -o yaml
使用文字方式创建,利用 --from-literal 参数传递配置信息,改参数可以使用多次。
2.5、直接方法
# 直接通过配置文件的方式创建
# 耦合方式创建
apiVersion: v1
data:game.properties: |enemies=alienslives=3enemies.cheat=trueenemies.cheat.level=noGoodRottensecret.code.passphrase=UUDDLRLRBABASsecret.code.allowed=truesecret.code.lives=30ui.properties: |color.good=purplecolor.bad=yellowallow.textmode=truehow.nice.to.look=fairlyNice
kind: ConfigMap
metadata:name: game-confignamespace: default
2.6、pod中应用
# 创建configMap, special.how: very 键名:键值
apiVersion: v1
kind: ConfigMap
metadata:name: special-confignamespace: default
data:special.how: veryspecial.type: charm# 创建第二个configMap
apiVersion: v1
kind: ConfigMap
metadata:name: env-confignamespace: default
data:log_level: INFO# 第一种方式: 在pod中使用configmap配置,使用ConfigMap来替代环境变量
apiVersion: v1
kind: Pod
metadata:name: test-pod
spec:containers:- name: test-containerimage: hub.kaikeba.com/library/myapp:v1 command: ["/bin/sh", "-c", "env"]env:- name: SPECIAL_LEVEL_KEY valueFrom:configMapKeyRef: name: special-config # 第一种导入方式:在env中导入key: special.how - name: SPECIAL_TYPE_KEYvalueFrom: configMapKeyRef: name: special-config key: special.type envFrom: # 第二种导入方式,直接使用envFrom导入- configMapRef: name: env-config restartPolicy: Never# 查看日志可以发现,环境变量注入到了容器中了,打印env就结束了
kubectl logs test-pod
...
SPECIAL_TYPE_KEY=charm
SPECIAL_LEVEL_KEY=very
log_level=INFO#第二种方式:用ConfigMap设置命令行参数
#用作命令行参数,将 ConfigMap 用作命令行参数时,需要先把 ConfigMap 的数据保存在环境变量中,然后通过 $(VAR_NAME) 的方式引用环境变量.
apiVersion: v1
kind: Pod
metadata:name: test-pod
spec:containers:- name: test-containerimage: hub.kaikeba.com/library/myapp:v1command: [ "/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ] env:- name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: name: special-config key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config key: special.type restartPolicy: Never# 第三种方式:通过数据卷插件使用ConfigMap
#在数据卷里面使用这个ConfigMap,有不同的选项。最基本的就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容apiversion: v1
kind: Pod
metadata:name: test-pod3
spec:containers:- name: test-containerimage: hub.kaikeba.com/library/myapp:v1command: [ "/bin/sh", "-c", "sleep 600s" ] volumeMounts:- name: config-volumemountPath: /etc/config # 表示把conifg-volume挂载卷挂载到容器的/etc/config目录下volumes: # 开启挂载外部configmap- name: config-volumeconfigMap:name: special-configrestartPolicy: Never# 登录容器查看/etc/config目录下是否挂载成功2.7、热更新
# ConfigMap的热更新
apiVersion: v1
kind: ConfigMap
metadata:name: log-confignamespace: default
data:log_level:INFO
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata: name: my-nginx
spec:replicas: 1template:metadata:labels:run: my-nginxspec:containers:- name: my-nginximage: hub.kaikeba.com/java12/myapp:v1 ports:- containerPort: 80 volumeMounts:- name: config-volume mountPath: /etc/config volumes:- name: config-volume configMap:name: log-config# 获取值
kubectl exec my-nginx-7b55868ff4-wqh2q -it -- cat /etc/config/log_level
#输出
INFO修改ConfigMap$ kubectl edit configmap log-config
修改log-level的值为DEBUG等待大概10秒钟时间,再次查看环境变量的值
二、secret
Secret对象存储数据的方式是以键值方式存储数据,在Pod资源进行调用Secret的方式是通过环境变量或者存储卷的方式进行访问数据,解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。
另外,Secret对象的数据存储和打印格式为Base64编码的字符串,因此用户在创建Secret对象时,也需要提供该类型的编码格式的数据。在容器中以环境变量或存储卷的方式访问时,会自动解码为明文格式。需要注意的是,如果是在Master节点上,Secret对象以非加密的格式存储在etcd中,所以需要对etcd的管理和权限进行严格控制。
Secret有4种类型:
- Service Account :用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中;
- Opaque :base64编码格式的Secret,用来存储密码、密钥、信息、证书等,类型标识符为generic;
- kubernetes.io/dockerconfigjson :用来存储私有docker registry的认证信息,类型标识为docker-registry。
- kubernetes.io/tls:用于为SSL通信模式存储证书和私钥文件,命令式创建类型标识为tls。
1、Service Account
Service Account 用来访问kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中.
Service Account 不需要我们自己去管理的,此证书是由kubernetes自己来进行维护管理的。
# 创建pod
kubectl run my-nginx --image=hub.kaikeba.com/java12/nginx:v1 # 查看证书
kubctl exec -it podName -- sh
# 进入证书目录/run/secrets/kubernetes.io/serviceaccount查看即可
ca
namespace
token
2、opaque Secret
2.1、创建示例
Opaque类型的数据一个map类型,要求value是base64编码格式
# base64对用户名,密码加密效果演示
echo -n "admin" | base64
YWRtaW4=echo -n "abcdefgh" | base64
YWJjZGVmZ2g=# secret.yaml配置文件方式
apiVersion: v1
kind: Secret
metadata:name: mysecret
type: Opaque
data:password: YWJjZGVmZ2g=username: YWRtaW4=2.2、使用方式
# 将secret挂载到volume中
apiVersion: v1
kind: pod
metadata:name: secret-testlabels:name: secret-test
spec:volumes:- name: secretssecret:secretName: mysecretcontainers:- image: hub.kaikeba.com/java12/myapp:v1name: dbvolumeMounts:- name: secretsmountPath: "/etc/secrets"readOnly: true# 将secret导出到环境变量中
apiVersion: extensions/v1beta1
kind: Deployment
metadata:name: secret-deployment
spec:replicas: 2template:metadata:labels:app: pod-deploymentspec:containers:- name: pod-1image: hub.kaikeba.com/java12/myapp:v1ports:- containerPort: 80env:- name: TEST_USERvalueFrom:secretKeyRef:name: mysecretkey: username- name: TEST_PASSWORDvalueFrom:secretKeyRef:name: mysecretkey: password
三、k8s-volumes
1、什么要用volumes?
k8s中容器中的磁盘的生命周期是短暂的, 这就带来了一些列的问题
- 当一个容器损坏之后, kubelet会重启这个容器, 但是容器中的文件将丢失----容器以干净的状态重新启动
- 当很多容器运行在同一个pod中时, 很多时候需要数据文件的共享
- 在
k8s中,由于pod分布在各个不同的节点之上,并不能实现不同节点之间持久性数据的共享,并且,在节点故障时,可能会导致数据的永久性丢失。
volumes就是用来解决以上问题的
Volume 的生命周期独立于容器,Pod 中的容器可能被销毁和重建,但 Volume 会被保留。
注意:docker磁盘映射的数据将会被保留,和kubernetes有一些不一样
2、什么是volume?
volume用来对容器的数据进行挂载,存储容器运行时所需的一些数据。当容器被重新创建时,实际上我们发现volume挂载卷并没有发生变化。
kubernetes中的卷有明确的寿命————与封装它的pod相同。所以,卷的生命比pod中的所有容器都长,当这个容器重启时数据仍然得以保存。
当然,当pod不再存在时,卷也不复存在,也许更重要的是kubernetes支持多种类型的卷,pod可以同时使用任意数量的卷

3、卷的类型
kubenetes卷的类型:

第一种就是本地卷
像hostPath类型与docker里面的bind mount类型,就是直接挂载到宿主机文件的类型
像emptyDir是这样本地卷,也就是类似于volume类型
这两点都是绑定node节点的
第二种就是网络数据卷
比如Nfs、ClusterFs、Ceph,这些都是外部的存储都可以挂载到k8s上
第三种就是云盘
比如AWS、微软(azuredisk)
第四种就是k8s自身的资源
比如secret、configmap、downwardAPI
4、emptyDir
先来看一下本地卷
像emptyDir类似与docker的volume,而docker删除容器,数据卷还会存在,而emptyDir删除容器,数据卷也会丢失,一般这个只做临时数据卷来使用
创建一个空卷,挂载到Pod中的容器。Pod删除该卷也会被删除。
应用场景:Pod中容器之间数据共享
当pod被分配给节点时,首先创建emptyDir卷,并且只要该pod在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的,pod中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或者不同路径上。当处于任何原因从节点删除pod时,emptyDir中的数据将被永久删除
注意:容器崩溃不会从节点中移除pod,因此emptyDir卷中的数据在容器崩溃时是安全的

emptyDir的用法
1、暂存空间,例如用于基于磁盘的合并排序
2、用作长时间计算崩溃恢复时候的检查点
3、web服务器容器提供数据时,保存内容管理器容器提取的文件
5、一个例子
apiVersion: v1
kind: Pod
metadata:name: test-pod1
spec:containers:- image: hub.kaikeba.com/library/myapp:v1name: test-containervolumeMounts:- mountPath: /cachename: cache-volumevolumes:- name: cache-volumeemptyDir: {}---
apiVersion: v1
kind: Pod
metadata:name: test-pod2
spec:containers:- image: hub.kaikeba.com/library/myapp:v1name: test-containervolumeMounts:- mountPath: /cachename: cache-volume- name: test-1image: hub.kaikeba.com/library/busybox:v1command: ["/bin/sh","-c","sleep 3600s"]imagePullPolicy: IfNotPresentvolumeMounts:- mountPath: /cachename: cache-volumevolumes:- name: cache-volumeemptyDir: {}6、HostPath
挂载Node文件系统上文件或者目录到Pod中的容器。
应用场景:Pod中容器需要访问宿主机文件 ;
7、一个例子
apiVersion: v1
kind: Pod
metadata:name: test-pod
spec:containers:- image: hub.kaikeba.com/library/myapp:v1name: test-containervolumeMounts:- mountPath: /cachename: cache-volumevolumes:- name: cache-volumehostPath:path: /datatype: Directory这里创建的数据和我们被分配的node节点的数据都是一样的,创建的数据都会更新上去,删除容器,不会删除数据卷的数据。
type类型
除了所需的path属性职位,用户还可以为hostPath卷指定type.

8、NFS网络存储
Kubernetes进阶之PersistentVolume 静态供给实现NFS网络存储
NFS是一种很早的技术,单机的存储在服务器方面还是非常主流的,但nfs唯一的就是缺点比较大就是没有集群版,做集群化还是比较费劲的,文件系统做不了,这是一个很大的弊端,大规模的还是需要选择一些分布式的存储,nfs就是一个网络文件存储服务器,装完nfs之后,共享一个目录,其他的服务器就可以通过这个目录挂载到本地了,在本地写到这个目录的文件,就会同步到远程服务器上,实现一个共享存储的功能,一般都是做数据的共享存储,比如多台web服务器,肯定需要保证这些web服务器的数据一致性,那就会用到这个共享存储了,要是将nfs挂载到多台的web服务器上,网站根目录下,网站程序就放在nfs服务器上,这样的话。每个网站,每个web程序都能读取到这个目录,一致性的数据,这样的话就能保证多个节点,提供一致性的程序了。
1)、单独拿一台服务器做nfs服务器,我们这里先搭建一台NFS服务器用来存储我们的网页根目录
yum install nfs-utils -y
2)、暴露目录,让是让其他服务器能挂载这个目录
mkdir /opt/k8s
vim /etc/exports
/opt/k8s 192.168.30.0/24(rw,no_root_squash)
给这个网段加上权限,可读可写
[root@nfs ~]# systemctl start nfs
找个节点去挂载测试一下,只要去共享这个目录就要都去安装这个客户端
#其他节点也需要安装nfs
yum install nfs-utils -y
mount -t nfs 192.168.30.27:/opt/k8s /mnt
cd /mnt
df -h
192.168.30.27:/opt/k8s 36G 5.8G 30G 17% /mnt
touch a.txt
去服务器端查看已经数据共享过来了
删除nfs服务器的数据也会删除
接下来怎么将K8s进行使用
我们把网页目录都放在这个目录下
# mkdir wwwroot
# vim nfs.yaml
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nfs
spec:replicas: 3template:metadata:labels:app: nginxspec:containers:- name: nginximage: hub.kaikeba.com/library/myapp:v1volumeMounts:- name: wwwrootmountPath: /usr/share/nginx/htmlports:- containerPort: 80volumes:- name: wwwrootnfs:server: 192.168.66.13path: /opt/k8s/wwwroot
---
apiVersion: v1
kind: Service
metadata:name: nginx-servicelabels:app: nginx
spec:ports:- port: 80targetPort: 80selector:app: nginxtype: NodePort
我们在源pod的网页目录下写入数据,并查看我们的nfs服务器目录下也会共享
四、PV&PVC
1、pv&pvc说明
管理存储和管理计算有着明显的不同。PersistentVolume给用户和管理员提供了一套API,抽象出存储是如何提供和消耗的细节。在这里,我们介绍两种新的API资源:PersistentVolume(简称PV)和PersistentVolumeClaim(简称PVC)。
- PersistentVolume(持久卷,简称PV)是集群内,由管理员提供的网络存储的一部分。就像集群中的节点一样,PV也是集群中的一种资源。它也像Volume一样,是一种volume插件,但是它的生命周期却是和使用它的Pod相互独立的。PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节。
- PersistentVolumeClaim(持久卷声明,简称PVC)是用户的一种存储请求。它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源。Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式(可以被映射为一次读写或者多次只读)。
PVC允许用户消耗抽象的存储资源,用户也经常需要各种属性(如性能)的PV。集群管理员需要提供各种各样、不同大小、不同访问模式的PV,而不用向用户暴露这些volume如何实现的细节。因为这种需求,就催生出一种StorageClass资源。
StorageClass提供了一种方式,使得管理员能够描述他提供的存储的等级。集群管理员可以将不同的等级映射到不同的服务等级、不同的后端策略。
K8s为了做存储的编排
数据持久卷PersistentVolume 简称pv/pvc主要做容器存储的编排
• PersistentVolume(PV):对存储资源创建和使用的抽象,使得存储作为集群中的资源管理
pv都是运维去考虑,用来管理外部存储的
• 静态 :提前创建好pv,比如创建一个100G的pv,200G的pv,让有需要的人拿去用,就是说pvc连接pv,就是知道pv创建的是多少,空间大小是多少,创建的名字是多少,有一定的可匹配性
• 动态
• PersistentVolumeClaim(PVC):让用户不需要关心具体的Volume实现细节
使用多少个容量来定义,比如开发要部署一个服务要使用10个G,那么就可以使用pvc这个资源对象来定义使用10个G,其他的就不用考虑了
pv&pvc区别
PersistentVolume(持久卷)和PersistentVolumeClaim(持久卷申请)是k8s提供的两种API资源,用于抽象存储细节。
管理员关注如何通过pv提供存储功能而无需关注用户如何使用,同样的用户只需要挂载pvc到容器中而不需要关注存储卷采用何种技术实现。
pvc和pv的关系与pod和node关系类似,前者消耗后者的资源。pvc可以向pv申请指定大小的存储资源并设置访问模式,这就可以通过Provision -> Claim 的方式,来对存储资源进行控制。
2、生命周期
volume 和 claim 的生命周期,PV是集群中的资源,PVC是对这些资源的请求,同时也是这些资源的“提取证”。PV和PVC的交互遵循以下生命周期:
-
供给
有两种PV提供的方式:静态和动态。
-
静态
集群管理员创建多个PV,它们携带着真实存储的详细信息,这些存储对于集群用户是可用的。它们存在于Kubernetes API中,并可用于存储使用。
-
动态
当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass:PVC必须请求这样一个等级,而管理员必须已经创建和配置过这样一个等级,以备发生这种动态供给的情况。请求等级配置为“”的PVC,有效地禁用了它自身的动态供给功能。
-
绑定
用户创建一个PVC(或者之前就已经就为动态供给创建了),指定要求存储的大小和访问模式。master中有一个控制回路用于监控新的PVC,查找匹配的PV(如果有),并把PVC和PV绑定在一起。如果一个PV曾经动态供给到了一个新的PVC,那么这个回路会一直绑定这个PV和PVC。另外,用户总是至少能得到它们所要求的存储,但是volume可能超过它们的请求。一旦绑定了,PVC绑定就是专属的,无论它们的绑定模式是什么。
如果没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态,一旦PV可用了,PVC就会又变成绑定状态。比如,如果一个供给了很多50G的PV集群,不会匹配要求100G的PVC。直到100G的PV添加到该集群时,PVC才会被绑定。
-
使用
Pod使用PVC就像使用volume一样。集群检查PVC,查找绑定的PV,并映射PV给Pod。对于支持多种访问模式的PV,用户可以指定想用的模式。一旦用户拥有了一个PVC,并且PVC被绑定,那么只要用户还需要,PV就一直属于这个用户。用户调度Pod,通过在Pod的volume块中包含PVC来访问PV。
-
释放
当用户使用PV完毕后,他们可以通过API来删除PVC对象。当PVC被删除后,对应的PV就被认为是已经是“released”了,但还不能再给另外一个PVC使用。前一个PVC的属于还存在于该PV中,必须根据策略来处理掉。
-
回收
PV的回收策略告诉集群,在PV被释放之后集群应该如何处理该PV。当前,PV可以被Retained(保留)、 Recycled(再利用)或者Deleted(删除)。保留允许手动地再次声明资源。对于支持删除操作的PV卷,删除操作会从Kubernetes中移除PV对象,还有对应的外部存储(如AWS EBS,GCE PD,Azure Disk,或者Cinder volume)。动态供给的卷总是会被删除。
3、POD&PVC
先创建一个容器应用
#vim pod.yaml
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: nginximage: nginx:latestports:- containerPort: 80volumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumes:- name: wwwpersistentVolumeClaim:claimName: my-pvc
卷需求yaml,这里的名称一定要对应,一般两个文件都放在一块
# vim pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: my-pvc
spec:accessModes:- ReadWriteManyresources:requests:storage: 5Gi
接下来就是运维出场了,提前创建好pv
# vim pv1.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: my-pv1
spec:capacity:storage: 5GiaccessModes:- ReadWriteManynfs:path: /opt/k8s/demo1server: 192.168.66.13
提前创建好pv,以及挂载目录
我再创建一个pv,在nfs服务器提前把目录创建好,名称修改一下
# vim pv2.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: my-pv2
spec:capacity:storage: 10GiaccessModes:- ReadWriteManynfs:path: /opt/k8s/demo2server: 192.168.66.13
然后现在创建一下我们的pod和pvc,这里我写在一起了
# vim pod.yaml
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: nginximage: nginx:latestports:- containerPort: 80volumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumes:- name: wwwpersistentVolumeClaim:claimName: my-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: my-pvc
spec:accessModes:- ReadWriteManyresources:requests:storage: 5Gi
二、statefulset
上一个章节我们已经清楚地的认识的pv,pvc的数据绑定原理,及pv,pvc与pod的绑定方法,那么对于有状态服务部署其实已经非常简单的了,有状态服务器本身就是有实时的数据需要存储,那么现在数据存储的问题已经解决了,现在就来一个statefulset的实例部署。
1、headless services
Headless Services是一种特殊的service,其spec:clusterIP表示为None,这样在实际运行时就不会被分配ClusterIP。
前几节课中我们了解了service的作用,主要是代理一组pod容器负载均衡服务,但是有时候我们不需要这种负载均衡场景,比如下面的两个例子。
- 比如kubernetes部署某个kafka集群,这种就不需要service来代理,客户端需要的是一组pod的所有的ip。
- 还有一种场景客户端自己处理负载均衡的逻辑,比如kubernates部署两个mysql,有客户端处理负载请求,或者根本不处理这种负载,就要两套mysql。
基于上面的两个例子,kubernates增加了headless serivces功能,字面意思无service其实就是改service对外无提供IP。下面我们看看它如何配置的
apiVersion: v1
kind: Service
metadata:name: nginx-service
spec:selector:app: nginx-demoports:- port: 80name: nginxclusterIP: None
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nginx-dp
spec:selector:matchLabels:app: nginx-demoreplicas: 2template:metadata:labels:app: nginx-demospec:containers:- name: nginximage: hub.kaikeba.com/java12/myapp:v1ports:- containerPort: 80name: web
2、服务部署
apiVersion: v1
kind: PersistentVolume
metadata: name: pv001labels:name: pv001
spec:nfs:path: /opt/k8s/v1server: 192.168.66.13accessModes: ["ReadWriteMany", "ReadWriteOnce"]capacity:storage: 1Gi
---
apiVersion: v1
kind: PersistentVolume
metadata: name: pv002labels:name: pv002
spec:nfs:path: /opt/k8s/v2server: 192.168.66.13accessModes: ["ReadWriteOnce"]capacity:storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata: name: pv003labels:name: pv003
spec:nfs:path: /opt/k8s/v3server: 192.168.66.13accessModes: ["ReadWriteMany", "ReadWriteOnce"]capacity:storage: 3Gi
---
apiVersion: v1
kind: PersistentVolume
metadata: name: pv004labels:name: pv004
spec:nfs:path: /opt/k8s/v4server: 192.168.66.13accessModes: ["ReadWriteMany", "ReadWriteOnce"]capacity:storage: 1Gi
---
apiVersion: v1
kind: PersistentVolume
metadata: name: pv005labels:name: pv005
spec:nfs:path: /opt/k8s/v5server: 192.168.66.13accessModes: ["ReadWriteMany", "ReadWriteOnce"]capacity:storage: 1Gi
根据部署pv,pvc的方式,加上statefulset的部署即可。
# 部署stateful类型的有状态服务, 指定pvc
apiVersion: v1
kind: Service
metadata:name: nginxlabels:app: nginx
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:selector:matchLabels:app: nginxserviceName: "nginx"replicas: 3template:metadata:labels:app: nginxspec:terminationGracePeriodSeconds: 10containers:- name: nginximage: k8s.gcr.io/nginx-slim:0.8ports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumes:- name: wwwpersistentVolumeClaim:claimName: my-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: my-pvc
spec:accessModes:- ReadWriteManyresources:requests:storage: 5Gi # 使用volumeClaimTemplates直接指定pvc,申请pv
apiVersion: v1
kind: Service
metadata:name: nginxlabels:app: nginx
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:selector:matchLabels:app: nginxserviceName: nginxreplicas: 3template:metadata:labels:app: nginxspec:terminationGracePeriodSeconds: 10containers:- name: nginximage: hub.kaikeba.com/java12/myapp:v1ports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: wwwspec:accessModes: [ "ReadWriteOnce" ]storageClassName: "my-storage-class"resources:requests:storage: 1Gi
# 清单解析
# 等待 terminationGracePeriodSeconds 这么长的时间。(默认为30秒)、超过terminationGracePeriodSeconds等待时间后, K8S 会强制结束老POD
PVC和PV的绑定是通过StorageClassName进行的。然而如果定义PVC时没有指定StorageClassName呢?这取决与admission插件是否开启了DefaultDefaultStorageClass功能:
如果DefaultDefaultStorageClass功能开启,那么此PVC的StorageClassName就会被指定为DefaultStorageClass。DefaultStorageClass从何处而来呢?原来在定义StorageClass时,可以在Annotation中添加一个键值对:storageclass.kubernetes.io/is-default-class: true,那么此StorageClass就变成默认的StorageClass了。
如果DefaultDefaultStorageClass功能没有开启,那么没有指定StorageClassName的PVC只能被绑定到同样没有指定StorageClassName的PV。
查看了我们环境中的storageclass 定义,发现没有开启DefaultDefaultStorageClass功能。
三、storageClass
在动态资源供应模式下,通过StorageClass和PVC完成资源动态绑定(系统自动生成PV),并供Pod使用的存储管理机制。

1、什么是StorageClass
Kubernetes提供了一套可以自动创建PV的机制,即:Dynamic Provisioning.而这个机制的核心在于:StorageClass这个API对象.StorageClass对象会定义下面两部分内容:
1,PV的属性.比如,存储类型,Volume的大小等.
2,创建这种PV需要用到的存储插件
有了这两个信息之后,Kubernetes就能够根据用户提交的PVC,找到一个对应的StorageClass,之后Kubernetes就会调用该StorageClass声明的存储插件,进而创建出需要的PV.
但是其实使用起来是一件很简单的事情,你只需要根据自己的需求,编写YAML文件即可,然后使用kubectl create命令执行即可
2、为什么需要StorageClass
在一个大规模的Kubernetes集群里,可能有成千上万个PVC,这就意味着运维人员必须实现创建出这个多个PV,此外,随着项目的需要,会有新的PVC不断被提交,那么运维人员就需要不断的添加新的,满足要求的PV,否则新的Pod就会因为PVC绑定不到PV而导致创建失败.而且通过 PVC 请求到一定的存储空间也很有可能不足以满足应用对于存储设备的各种需求而且不同的应用程序对于存储性能的要求可能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,Kubernetes 又为我们引入了一个新的资源对象:StorageClass,通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据 StorageClass 的描述就可以非常直观的知道各种存储资源的具体特性了,这样就可以根据应用的特性去申请合适的存储资源了。
3、运行原理及部署流程
要使用 StorageClass,我们就得安装对应的自动配置程序,比如我们这里存储后端使用的是 nfs,那么我们就需要使用到一个 nfs-client 的自动配置程序,我们也叫它 Provisioner,这个程序使用我们已经配置好的 nfs 服务器,来自动创建持久卷,也就是自动帮我们创建 PV。1.自动创建的 PV 以${namespace}-${pvcName}-${pvName}这样的命名格式创建在 NFS 服务器上的共享数据目录中
2.而当这个 PV 被回收后会以archieved-${namespace}-${pvcName}-${pvName}这样的命名格式存在 NFS 服务器上。

搭建StorageClass+NFS,大致有以下几个步骤:
1.创建一个可用的NFS Server
2.创建Service Account.这是用来管控NFS provisioner在k8s集群中运行的权限
3.创建StorageClass.负责建立PVC并调用NFS provisioner进行预定的工作,并让PV与PVC建立管理
4.创建NFS provisioner.有两个功能,一个是在NFS共享目录下创建挂载点(volume),另一个则是建了PV并将PV与NFS的挂载点建立关联
4、statefulset实践
# rbac.yaml:#唯一需要修改的地方只有namespace,根据实际情况定义
apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-client-provisionernamespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: nfs-client-provisioner-runner
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: default
roleRef:kind: ClusterRolename: nfs-client-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: default
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: default
roleRef:kind: Rolename: leader-locking-nfs-client-provisionerapiGroup: rbac.authorization.k8s.io# 创建NFS资源的StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: managed-nfs-storage
provisioner: qgg-nfs-storage
parameters: archiveOnDelete: "false"# 创建NFS provisioner
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-client-provisionerlabels:app: nfs-client-provisionernamespace: default
spec:replicas: 1selector:matchLabels:app: nfs-client-provisionerstrategy:type: Recreateselector:matchLabels:app: nfs-client-provisionertemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisionercontainers:- name: nfs-client-provisionerimage: hub.kaikeba.com/library/nfs-client-provisioner:v1volumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: qgg-nfs-storage- name: NFS_SERVERvalue: 192.168.66.13- name: NFS_PATH value: /opt/k8svolumes:- name: nfs-client-rootnfs:server: 192.168.66.13path: /opt/k8s# 创建pod进行测试
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-claimannotations:volume.beta.kubernetes.io/storage-class: "managed-nfs-storage"
spec:accessModes:- ReadWriteManyresources:requests:storage: 1Mi# 创建测试pod,查看是否可以正常挂载
kind: Pod
apiVersion: v1
metadata:name: test-pod
spec:containers:- name: test-podimage: busybox:1.24command:- "/bin/sh"args:- "-c"- "touch /mnt/SUCCESS && exit 0 || exit 1" #创建一个SUCCESS文件后退出volumeMounts:- name: nfs-pvcmountPath: "/mnt"restartPolicy: "Never"volumes:- name: nfs-pvcpersistentVolumeClaim:claimName: test-claim #与PVC名称保持一致# StateFulDet+volumeClaimTemplates自动创建PV
---
apiVersion: v1
kind: Service
metadata:name: nginx-headlesslabels:app: nginx
spec:ports:- port: 80name: webclusterIP: None selector:app: nginx
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx"replicas: 2template:metadata:labels:app: nginxspec:containers:- name: nginximage: ikubernetes/myapp:v1ports:- containerPort: 80name: webvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: wwwannotations:volume.beta.kubernetes.io/storage-class: "managed-nfs-storage"spec:accessModes: [ "ReadWriteOnce" ]resources:requests:storage: 1Gi












![[计算机提升] 系统及用户操作](https://img-blog.csdnimg.cn/41c7cc1f36a14ee3b326d149e405752f.png)