作者: Ultralytics
论文源码: https://github.com/ultralytics/yolov5
Ultralytics:“超视觉技术” / “超视觉系统”
0. 引言
“YOLOv5 🚀 是世界上备受喜爱的视觉人工智能,代表了 Ultralytics 对未来视觉人工智能方法的开源研究,融合了数千小时的研究和开发经验中所学到的教训和最佳实践。”
YOLOv5 仓库是在 2020-05-18 创建的,到今天已经迭代了很多个大版本了,现在已经迭代到 v7.0 了。下表是当前 (v7.0 / v6.1) 官网贴出的关于不同大小模型以及输入尺度对应的 mAP、推理速度(Speed)、参数数量(params)以及理论计算量(FLOPs)。
| Model | size(pixels) | mAPval0.5:0.95 | mAPval0.5 | SpeedCPU b1(ms) | SpeedV100 b1(ms) | SpeedV100 b32(ms) | params(M) | FLOPs@640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6+ TTA | 12801536 | 55.055.8 | 72.772.7 | 3136- | 26.2- | 19.4- | 140.7- | 209.8- |
1. 网络结构
YOLOv5 的网络结构主要由以下几部分组成:
- Backbone: New CSP-Darknet53
这是网络的主体部分。对于 YOLOv5,主干网络采用了 New CSP-Darknet53 结构,这是对先前版本中使用的 Darknet 架构的修改。 - Neck: SPPF, New CSP-PAN
这部分连接了主干网络和头部。在 YOLOv5 中,使用了 SPPF 和 New CSP-PAN 结构。 - Head: YOLOv3 Head
这部分负责生成最终的输出。YOLOv5 使用 YOLOv3 头部来实现这一目标。
关模型结构的详细信息可以在 yolov5l.yaml 中找到
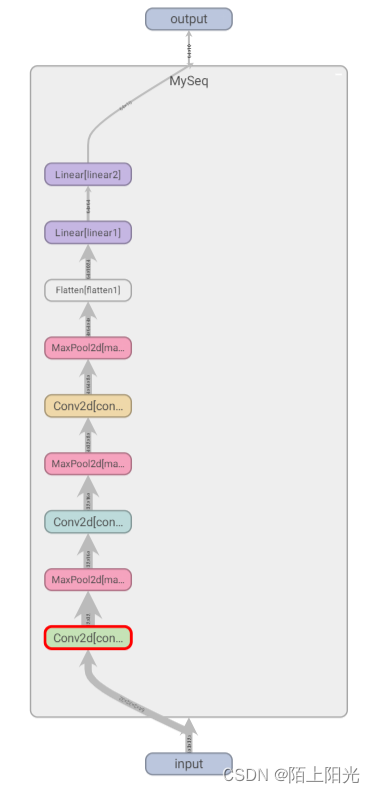
下面是官方根据 yolov5l.yaml 绘制的网络整体结构,YOLOv5 不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对 .yaml 文件中的 depth_multiple 和 width_multiple 参数。还需要注意一点,官方除了 n, s, m, l, x 版本外还有 n6, s6, m6, l6, x6,区别在于后者是针对更大分辨率的图片比如 1280 × 1280 1280\times 1280 1280×1280,当然结构上也有些差异,后者会 64 倍下采样,4 个预测特征层,而前者只会下采样到 32 倍且采用 3 个预测特征层。本文只讨论前者。

高清大图:yolov5-arch.png
注意:YOLOv5 相对于其前身引入了一些小的改变:
- 早期版本中的 Focus 结构被替换为 6x6 Conv2d 结构。这个变化提高了效率 #4825。
- SPP 结构被替换为 SPPF。这个改变使处理速度增加了一倍多。
- 要测试 SPP 和 SPPF 的速度,可以使用以下代码:
import time
import torch
import torch.nn as nnclass SPP(nn.Module):def __init__(self):super().__init__()self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)def forward(self, x):o1 = self.maxpool1(x)o2 = self.maxpool2(x)o3 = self.maxpool3(x)return torch.cat([x, o1, o2, o3], dim=1)class SPPF(nn.Module):def __init__(self):super().__init__()self.maxpool = nn.MaxPool2d(5, 1, padding=2)def forward(self, x):o1 = self.maxpool(x)o2 = self.maxpool(o1)o3 = self.maxpool(o2)return torch.cat([x, o1, o2, o3], dim=1)def main():input_tensor = torch.rand(8, 32, 16, 16)spp = SPP()sppf = SPPF()output1 = spp(input_tensor)output2 = sppf(input_tensor)print(torch.equal(output1, output2))t_start = time.time()for _ in range(100):spp(input_tensor)print(f"SPP time: {time.time() - t_start}")t_start = time.time()for _ in range(100):sppf(input_tensor)print(f"SPPF time: {time.time() - t_start}")if __name__ == '__main__':main()
True
SPP time: 0.5373051166534424
SPPF time: 0.20780706405639648
通过对比可以发现,两者的计算结果是一模一样的,但 SPPF 比 SPP 计算速度快了不止两倍,快乐翻倍 😂。
1.1 Backbone
通过与上篇博文讲的 YOLOv4 对比,其实YOLOv5 在 Backbone 部分没太大变化。但是 YOLOv5 在 v6.0 版本后相比之前版本有一个很小的改动,把网络的第一层(原来是 Focus 模块)换成了一个 6 × 6 6×6 6×6 大小的卷积层(nn.Conv2d)。两者在理论上其实等价的,但是对于现有的一些 GPU 设备(以及相应的优化算法)使用 6 × 6 6×6 6×6 大小的卷积层比使用 Focus 模块更加高效。详情可以参考这个issue #4825 -> Is the Focus layer equivalent to a simple Conv layer?。
下图是原来的 Focus 模块(和之前 Swin Transformer 中的 Patch Merging 类似),将每个 2 × 2 2×2 2×2 的相邻像素划分为一个 patch,然后将每个 patch 中相同位置(同一颜色)像素给拼在一起就得到了 4 个 feature map,然后在接上一个 3 × 3 3×3 3×3 大小的卷积层。这和直接使用一个 6 × 6 6×6 6×6 大小的卷积层等效。

1.2 Neck
YOLOv5 在 Neck 部分的变化还是相对较大的,首先是将 SPP 换成成了 SPPF(Spatial Pyramid Pooling - Fast, 是 Glenn Jocher 自己设计的),两者的作用是一样的,但后者效率更高。
1.2.1 SPP (Spatial Pyramid Pooling,空间金字塔池化)
SPP 结构如下图所示,是将输入并行通过多个不同大小的 MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。

每一个分支得到 feature map 的 shape 都一样 , 最后会实现通道数 × 4 ×4 ×4。
关于 SPP 的介绍可以看文章:[语义分割] ASPP不同版本对比(DeepLab、DeepLab v1、DeepLab v2、DeepLab v3、DeepLab v3+、LR-ASPP)
1.2.2 SPPF (Spatial Pyramid Pooling Fast,快速空间金字塔池化)
而 SPPF 结构是将输入串行通过多个 5 × 5 5×5 5×5 大小的 MaxPool 层,这里需要注意的是串行两个 5 × 5 5×5 5×5 大小的 MaxPool 层是和一个 9 × 9 9×9 9×9 大小的 MaxPool 层计算结果是一样的,串行三个 5 × 5 5×5 5×5 大小的 MaxPool 层是和一个 13 × 13 13×13 13×13 大小的 MaxPool 层计算结果是一样的。

SPPF 最后同样会实现通道数 × 4 ×4 ×4
SPPF的代码如下:
class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x) # 先通过CBL进行通道数的减半with warnings.catch_warnings():warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warningy1 = self.m(x)y2 = self.m(y1)# 上述两次最大池化# 将原来的x,一次池化后的y1,两次池化后的y2,3次池化的self.m(y2)先进行拼接,然后再CBLreturn self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
1.2.4 CSP-PAN(跨阶段部分网络-路径聚合网络)
前置小知识- CSP: Cross-Stage Partial Network,跨阶段部分网络
- PAN: Path Aggregation Network,路径聚合网络
Input Input| |Backbone Backbone| |Neck Neck/ \ / \
Part A Part B Part A Part B\ / \ /Concatenation Concatenation| |Head Head| |Output OutputFig.1 CSP Fig.2 PAN
在这个示意图中:
- CSP 结构将输入通过主干网络(Backbone)分成两部分,分别经过两个部分(Part A 和 Part B)的处理,然后再将它们连接在一起(Concatenation)。接下来,特征图进入颈部(Neck),最后到达头部(Head),产生最终的输出。这种结构有助于提高模型的性能和准确性。
- PAN 结构将输入通过主干网络(Backbone),然后进入颈部(Neck),颈部后分成两部分,分别通过两个部分(Part A 和 Part B)的处理,最后再次合并(Concatenation)后经过头部(Head)生成输出。
在 Neck 部分另外一个不同点就是 New CSP-PAN 了,在 YOLOv4 中,Neck 的 PAN 结构是没有引入 CSP 结构的,但在 YOLOv5 中作者在 PAN 结构中加入了 CSP。详情见上面的网络结构图,每个 C3 模块里都含有 CSP 结构。
CSP 结构是在 CSPNet(Cross Stage Partial Network)论文中提出的,CSPNet 作者说在目标检测任务中使用 CSP 结构有如下好处:
- Strengthening learning ability of a CNN:增强 CNN 的学习能力
- Removing computational bottlenecks:移除计算瓶颈
- Reducing memory costs:减少 MACs
CSP 的加入可以: 减少网络的计算量以及对显存的占用,同时保证网络的能力不变或者略微提升。CSP 结构的思想参考原论文中绘制的 CSPDenseNet,进入每个 stage(一般在下采样后)先将数据划分成俩部分,如下图左图所示的 Part1 和 Part2。

左边的图是 CSPDenseNet(来源于 CSPNet 论文)。CSP 结构会将网络分为两个部分。Part2 分支首先会经过一系列的 Block(这里是 DenseBlock),最后经过 Transition,得到输出后再与 Part1 上的输出进行 Transition 融合。
1.3 Head
在 Head 部分,YOLOv3, v4, v5 都是一样的。
2. 数据增强策略
在 YOLOv5 代码里,关于数据增强策略还是挺多的,这里简单罗列部分方法:
2.1 Mosaic,马赛克增强
核心思想:将 4 张图片拼成一张图片。

2.2 Copy Paste,复制粘贴增强
将部分目标随机的粘贴到图片中,前提是数据要有分割数据才行,即每个目标的实例分割信息。下面是 Copy paste 原论文中的示意图。

可以理解为是升级版的 Mosaic
2.3 Random affine,随机放射变换 (Rotation, Scale, Translation and Shear)
随机进行仿射变换,但根据配置文件里的超参数发现只使用了 Scale (缩放)和 Translation (平移)。

参考资料:数据增强中的仿射变换:旋转,缩放,平移以及错切(shear)
2.4 MixUp,混合数据增强
Mixup 就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,也没有消融实验。代码中只有较大的模型才使用到了 MixUp,而且每次只有 10 % 10\% 10% 的概率会使用到。

2.5 Albumentations
主要是做些滤波、直方图均衡化以及改变图片质量等等,代码里写的只有安装了 albumentations 包才会启用,但在项目的 requirements.txt 文件中 albumentations 包被注释掉了的,所以 默认不启用。
# Extras ----------------------------------------------------------------------
# ipython # interactive notebook
# mss # screenshots
# albumentations>=1.0.3
# pycocotools>=2.0.6 # COCO mAP
Albumentations 基本介绍“Albumentations” 这个名称通常不会被翻译,因为它是一个特定的计算机视觉数据增强库的名称。如果需要提到这个库,通常会直接保留原名 “Albumentations”。
Albumentations官方文档: https://albumentations.readthedocs.io/en/latest/
albumentations 是一个给予 OpenCV 的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分割、检测)的接口,易于定制且添加其他框架非常方便。
它可以对数据集进行逐像素的转换,如:
- 模糊
- 下采样
- 高斯造点
- 高斯模糊
- 动态模糊
- RGB转换
- 随机雾化
- 等
也可以进行空间转换(同时也会对目标进行转换),如:
- 裁剪
- 翻转
- 随机裁剪等。
github 及其示例地址如下:
GitHub: https://github.com/albumentations-team/albumentations
示例:https://github.com/albumentations-team/albumentations_examples
参考: https://zhuanlan.zhihu.com/p/107399127/
2.6 Augment HSV(Hue, Saturation, Value)
随机调整色度,饱和度以及明度。

2.7 Random horizontal flip,随机水平翻转

3. 训练策略
在 YOLOv5 源码中使用到了很多训练的策略,这里简单总结几个:
Multi-scale training(0.5~1.5x)(多尺度训练):假设设置输入图片的大小为 640 × 640 640 \times 640 640×640,训练时采用尺寸是在 0.5 × 640 ∼ 1.5 × 640 0.5 \times 640 \sim 1.5 \times 640 0.5×640∼1.5×640 之间随机取值,注意取值时取得都是 32 的整数倍(因为网络会最大下采样 32 倍)。AutoAnchor(For training custom data)(自动聚类生产 Anchor 模板):训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成 Anchors 模板。Warmup and Cosine LR scheduler(带有 Warmup 的余弦调度器):训练前先进行 Warmup 热身,然后在采用 Cosine 学习率下降策略。EMA(Exponential Moving Average)(指数移动平均):可以理解为给训练的参数(模型参数)加了一个动量,让它更新过程更加平滑。Mixed precision(混合精度训练):能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。Evolve hyper-parameters(超参数优化):没有炼丹经验的人勿碰,保持默认就好。
“Evolve hyper-parameters” 指的是在机器学习和深度学习中,通过优化算法或搜索策略来动态地调整模型的超参数(Hyperparameters),以提高模型的性能和泛化能力。超参数是指那些不是由模型自动学习而是需要手动设置的参数,它们通常用于控制模型的结构、学习率、正则化等方面。
“Evolve” 表示超参数可以通过不断地尝试不同的值来进行迭代调整,以找到最优的超参数组合。这种过程通常涉及超参数搜索和优化技术,如网格搜索、随机搜索、贝叶斯优化等。
通过进化超参数,可以实现以下目标:
-
提高模型性能:通过找到最佳的超参数组合,模型的性能通常会得到显著的提升。这包括准确性、泛化能力和训练效率。
-
防止过拟合:适当的超参数选择可以帮助防止模型过拟合训练数据,从而提高模型的泛化能力。
-
节省时间和资源:有效的超参数优化可以节省训练时间和计算资源,因为它可以避免不必要的试验和训练周期。
-
适应不同任务:通过调整超参数,可以使同一模型适应不同类型的任务,而无需重新设计整个模型。
总之,“evolve hyper-parameters” 意味着通过智能的搜索和优化技术来改进模型的性能和适应性,而不是仅仅手动选择固定的超参数值。这是机器学习和深度学习中重要的实践,以实现更好的结果。
4. 其他
4.1 损失计算
YOLOv5 的损失主要由三个部分组成:
- Classes loss(分类损失): 采用的是 BCE loss,注意只计算正样本的分类损失。
- Objectness loss(obj 损失(置信度损失)): 采用的依然是 BCE loss,注意这里的 obj 指的是网络预测的目标边界框与 Ground True 的 CIoU。这里计算的是所有样本的 obj 损失。
- Location loss(定位损失): 采用的是 CIoU loss,注意只计算正样本的定位损失。
L a l l = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c {\mathcal L}_{all} = \lambda_1 {\mathcal L}_{\rm cls} + \lambda_2 {\mathcal L}_{\rm obj} + \lambda_3 {\mathcal L}_{\rm loc} Lall=λ1Lcls+λ2Lobj+λ3Lloc
其中, λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3 为平衡系数。
4.2 平衡不同尺度的损失
这里是指针对三个预测特征层(P3, P4, P5)上的 obj损失 采用不同的权重。在源码中,针对预测小目标的预测特征层(P3)采用的权重是 4.0,针对预测中等目标的预测特征层(P4)采用的权重是 1.0,针对预测大目标的预测特征层(P5)采用的权重是 0.4,作者说这是针对 COCO 数据集设置的超参数。
L o b j = 4.0 × L o b j s m a l l + 1.0 × L o b j m e d i u m + 0.4 × L l a r g e s m a l l {\mathcal L}_{\rm obj} = 4.0 \times {\mathcal L}^{\rm small}_{\rm obj} + 1.0 \times {\mathcal L}^{\rm medium}_{\rm obj} + 0.4 \times {\mathcal L}^{\rm small}_{\rm large} Lobj=4.0×Lobjsmall+1.0×Lobjmedium+0.4×Llargesmall
4.3 消除 Grid 敏感度 (Eliminating grid sensitivity)
在 YOLOv4 中有提到过,主要是调整预测目标中心点相对 Grid 网格的左上角偏移量。下图是 YOLOv2 和 YOLOv3 的计算公式。
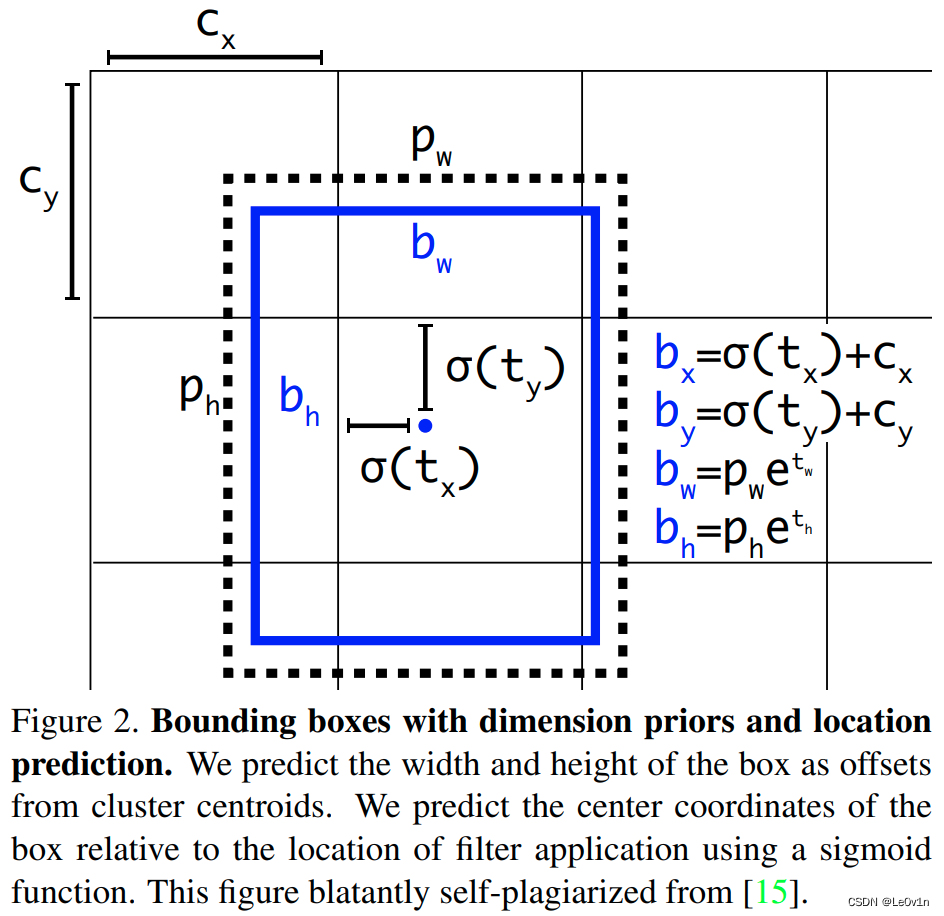
其中:
- t x t_x tx 是网络预测的目标中心 x x x 坐标偏移量(相对于网格的左上角)
- t y t_y ty 是网络预测的目标中心 y y y 坐标偏移量(相对于网格的左上角)
- c x c_x cx 是对应网格左上角的 x x x 坐标
- c y c_y cy 是对应网格左上角的 y y y 坐标
- σ \sigma σ 是 sigmoid 激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的 Grid Cell 区域
关于预测目标中心点相对 Grid 网格左上角 ( c x , c y ) (c_x, c_y) (cx,cy) 偏移量为 σ ( t x ) , σ ( t y ) \sigma(t_x), \sigma(t_y) σ(tx),σ(ty)。YOLOv4 的作者认为这样做不太合理,比如当真实目标中心点非常靠近网格的左上角点 σ ( t x ) \sigma(t_x) σ(tx) 和 σ ( t y ) \sigma(t_y) σ(ty) 应该趋近与 0 或者右下角点( σ ( t x ) \sigma(t_x) σ(tx) 和 σ ( t y ) \sigma(t_y) σ(ty) 应该趋近与 1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。
为了解决这个问题,作者对偏移量进行了缩放从原来的 ( 0 , 1 ) (0, 1) (0,1) 缩放到 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5) 这样网络预测的偏移量就能很方便达到 0 或 1,故最终预测的目标中心点 b x , b y b_x, b_y bx,by 的计算公式为:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) + c x b y = ( 2 ⋅ σ ( t y ) − 0.5 ) + c y b_x = \left( 2 \cdot \sigma(t_x) - 0.5 \right) + c_x \\ b_y = \left( 2 \cdot \sigma(t_y) - 0.5 \right) + c_y bx=(2⋅σ(tx)−0.5)+cxby=(2⋅σ(ty)−0.5)+cy
下面是霹雳吧啦Wz绘制的 y = σ ( x ) y = \sigma(x) y=σ(x) 对应sigma曲线和 y = 2 ⋅ σ ( x ) − 0.5 y = 2 \cdot \sigma(x) - 0.5 y=2⋅σ(x)−0.5 对应scale曲线。
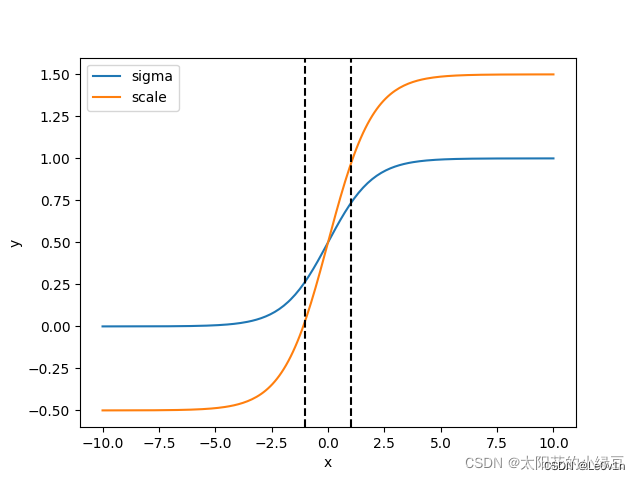
很明显通过引入缩放系数 scale 以后, x x x 在同样的区间内, y y y 的取值范围更大,或者说, y y y 对 x x x 更敏感了。并且偏移的范围由原来 ( 0 , 1 ) (0, 1) (0,1) 调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5)。
b w , b h b_w, b_h bw,bh 保持 YOLOv3 的策略不变。
在 YOLOv5 中除了调整预测 Anchor 相对 Grid 网格左上角 ( c x , c y ) (c_x, c_y) (cx,cy) 偏移量以外,还调整了预测目标高宽的计算公式,之前是:
b w = p w ⋅ e t w b h = p h ⋅ e t h b_w = p_w \cdot e^{t_w} \\ b_h = p_h \cdot e^{t_h} bw=pw⋅etwbh=ph⋅eth
在 YOLOv5 中被作者调整为:
b w = p w ⋅ ( 2 ⋅ σ ( t w ) ) 2 b h = p h ⋅ ( 2 ⋅ σ ( t h ) ) 2 b_w = p_w \cdot (2 \cdot \sigma(t_w))^2 \\ b_h = p_h \cdot (2 \cdot \sigma(t_h))^2 bw=pw⋅(2⋅σ(tw))2bh=ph⋅(2⋅σ(th))2
作者 Glenn Jocher 对此修改的原话如下,也可以参考issue #471:
The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training.
原始的 YOLO/Darknet box 公式存在严重缺陷。宽度和高度完全无限制,因为它们仅为 out = exp(in),这是危险的,因为它可能导致梯度失控、不稳定、NaN 损失,最终完全失去训练的能力。
作者的大致意思是,原来的计算公式并没有对预测目标宽高做限制,这样可能出现梯度爆炸,训练不稳定等问题。下图是修改前 y = e x y = e^x y=ex 和修改后 y = ( 2 ⋅ σ ( x ) ) 2 y = (2 \cdot \sigma(x))^2 y=(2⋅σ(x))2 (相对Anchor宽高的倍率因子)的变化曲线, 很明显调整后倍率因子被限制在 ( 0 , 4 ) (0, 4) (0,4) 之间。
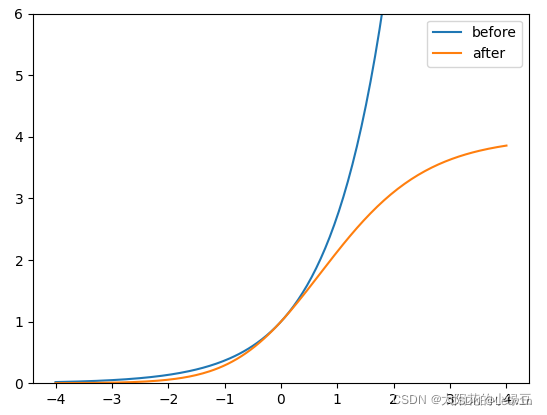
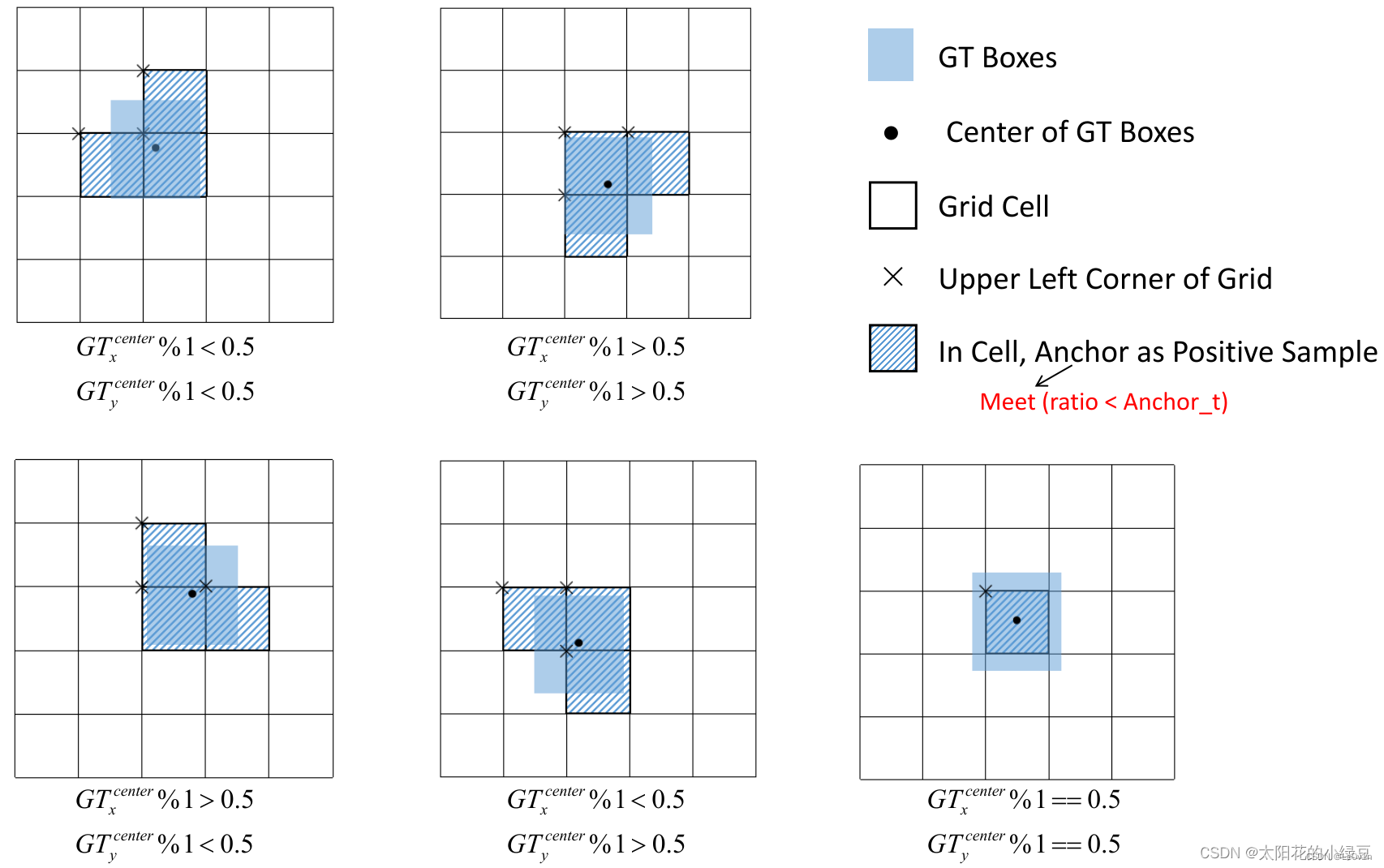
4.4 匹配样本 (Build Targets)
之前在 YOLOv4 介绍中有讲过该部分内容,其实 YOLOv5 也差不多。主要的区别在于 GT Box 与 Anchor Templates 模板的匹配方式。在 YOLOv4 中是直接将每个 GT Box 与对应的 Anchor Templates 模板计算 IoU,只要 IoU 大于设定的阈值就算匹配成功。但在 YOLOv5 中,作者先去计算每个 GT Box 与对应的 Anchor Templates 模板的高宽比例,即:
r w = w g t w a t r h = h g t h w a t r_w = \frac{w_{gt}}{w_{at}} \\ r_h = \frac{h_{gt}}{hw_{at}} rw=watwgtrh=hwathgt
然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算 GT Box 和 Anchor Templates 分别在宽度以及高度方向的最大差异(当相等的时候比例为 1,差异最小):
r w max = max ( r w , 1 r w ) r h max = max ( r h , 1 r h ) r^{\max}_w = \max(r_w, \frac{1}{r_w}) \\ r^{\max}_h = \max(r_h, \frac{1}{r_h}) rwmax=max(rw,rw1)rhmax=max(rh,rh1)
接着统计 r w max r_w^{\max} rwmax 和 r h max r_h^{\max} rhmax 之间的最大值,即宽度和高度方向差异最大的值:
r max = max ( r w max , r h max ) r^{\max} = \max(r_w^{\max}, r_h^{\max}) rmax=max(rwmax,rhmax)
如果 GT Box 和对应的 Anchor Template 的 r m a x r^{max} rmax 小于阈值 anchor_t(在源码中默认设置为 4.0),即 GT Box 和对应的 Anchor Template 的高、宽比例相差不算太大,则将 GT Box 分配给该 Anchor Template 模板。为了方便大家理解,可以看下图。
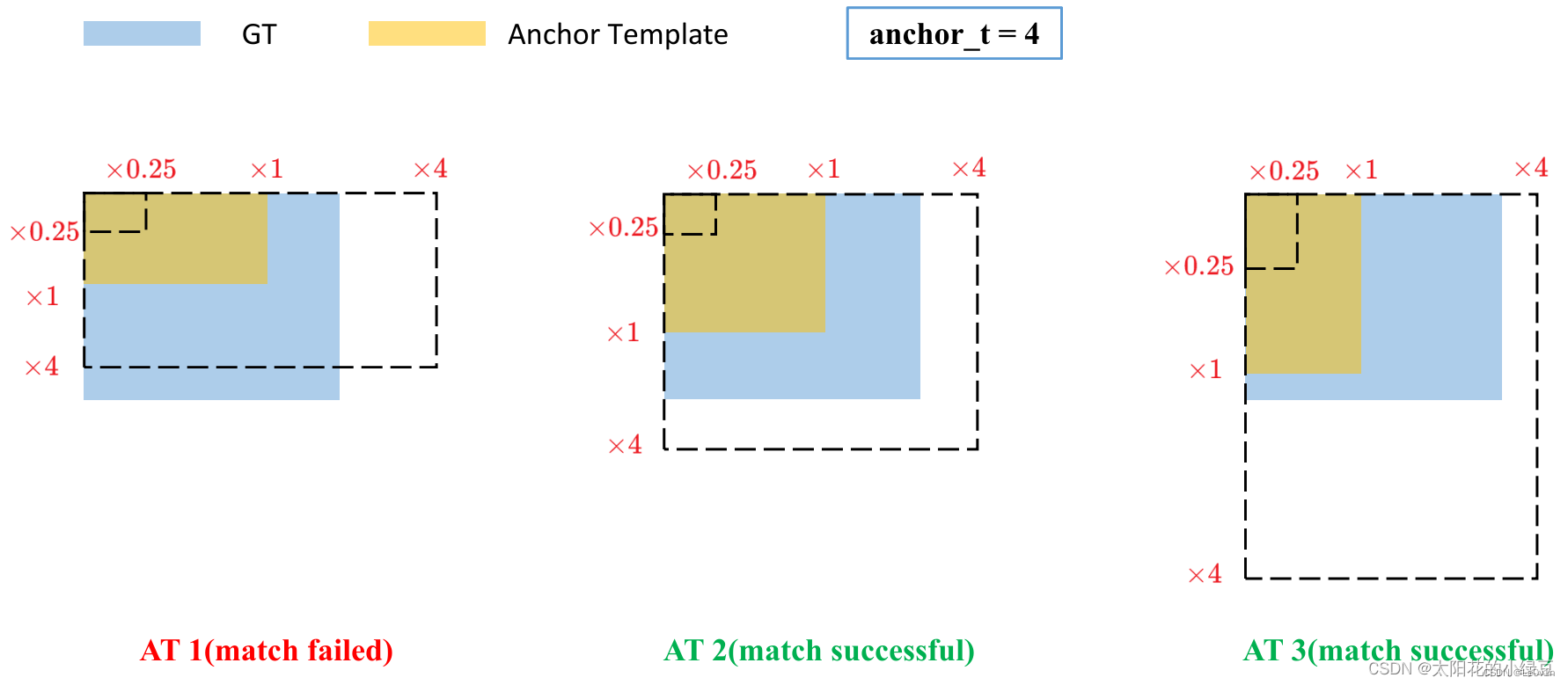
假设对某个 GT Box 而言,其实只要 GT Box 满足在某个 Anchor Template 宽和高的 × 0.25 \times 0.25 ×0.25 倍和 × 4.0 \times 4.0 ×4.0 倍之间就算匹配成功。
剩下的步骤和 YOLOv4 中一致:
将 GT 投影到对应预测特征层上,根据 GT 的中心点定位到对应 Cell,注意图中有三个对应的 Cell。因为网络预测中心点的偏移范围已经调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5),所以按理说只要 Grid Cell 左上角点距离 GT 中心点在 ( − 0.5 , 1.5 ) (−0.5, 1.5) (−0.5,1.5) 范围内它们对应的 Anchor 都能回归到 GT 的位置处。这样会让正样本的数量得到大量的扩充。
则这三个 Cell 对应的 AT2 和 AT3 都为正样本。
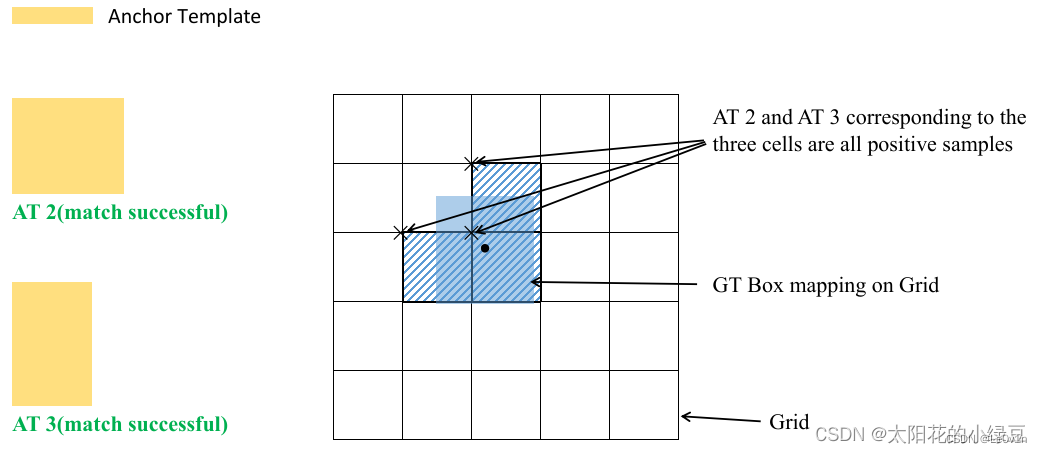
还需要注意的是,YOLOv5 源码中扩展 Cell 时只会往上、下、左、右 四个方向 扩展,不会往左上、右上、左下、右下方向扩展。
下面又给出了一些根据 G T x c e n t e r GT_x^{center} GTxcenter, G T y c e n t e r GT_y^{center} GTycenter 的位置扩展的一些 Cell 案例,其中 %1 表示取余并保留小数部分。
到此,YOLOv5 相关理论的内容基本上都分析完了。
知识来源
- YOLOv5网络详解
- YOLOv5网络详解