目录
🌠不会点
🪐DataStream API
编辑
🌠 执行环境
创建执行环境
执行模式
触发程序执行
🌠源算子
准备基础类型
从集合中读取数据
从文件读取数据
从 Socket 读取数据
从 Kafka 读取数据 (没学过)
从数据生成器读取数据
Flink 支持的数据类型
🌠转换算子
👾基本转换算子
map
flatMap
filter
👾聚合算子
keyBy(准备工作)
sum/min-max/minBy-maxBy
reduce
👾UDF
函数类
富函数类(多个open、close)
👾物理分区算子
随机分区
轮询分配(Round-Robin)
重缩放(Rescale)
广播(Broadcast)
全局分区(并行度转1)
自定义分区
👾分流
👾合流
🌠输出算子
👾连接到外部系统
👾输出到文件
👾输出到kafka(没学过
👾MySQL
👾DIY
🌠不会点
索引:getRuntimeContext().getIndexOfThisSubtask()
子任务名: getRuntimeContext().getTaskNameWithSubtasks()
索引: 1
子任务名: Map -> Sink: Print to Std. Out (2/2)#0
🪐DataStream API

🌠 执行环境
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前 Flink 的运行环境,从而建立起与Flink 框架之间的联系
创建执行环境
我们要获取的执行环境,是 StreamExecutionEnvironment 类的对象,这是所有 Flink 程序的基础。在代码中创建执行环境的方式,就是调用这个类的静态方法,具体有以下三种
1)getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar 包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境
2)createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的CPU 核心数
3)createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包。
/*** @param host The host name or address of the master (JobManager), where the program should be* executed.* @param port The port of the master (JobManager), where the program should be executed.* @param jarFiles The JAR files with code that needs to be shipped to the cluster. If the* program uses user-defined functions, user-defined input formats, or any libraries, those* must be provided in the JAR files.* @return A remote environment that executes the program on a cluster.*/public static StreamExecutionEnvironment createRemoteEnvironment(String host, int port, String... jarFiles) {return new RemoteStreamEnvironment(host, port, jarFiles);}执行模式
DataStream API 执行模式包括:流执行模式、批执行模式和自动模式。
从 Flink 1.12 开始,官方推荐的做法是直接使用 DataStream API,在提交任务时通过将执行模式设为BATCH 来进行批处理。不建议使用DataSet API。
流批一体
触发程序执行
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
🌠源算子
Flink 可以从各种来源获取数据,然后构建DataStream 进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source 就是我们整个处理程序的输入端。
从 Flink1.12 开始,主要使用流批统一的新 Source 架构:
DataStreamSource<String> stream = env.fromSource(…)
准备基础类型
使用WaterSensor 作为数据模型。
import java.time.LocalDate;
import java.util.Objects;public class WaterSensor {public String id; // idpublic Long ts; // 时间戳public Integer vc; // 水位记录public WaterSensor(){}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}@Overridepublic int hashCode() {return super.hashCode();}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) &&Objects.equals(ts, that.ts) &&Objects.equals(vc, that.vc);}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}
}
类是公有(public)的
有一个无参的构造方法
所有属性都是公有(public)的
所有属性的类型都是可以序列化的Flink 会把这样的类作为一种特殊的 POJO(Plain Ordinary Java Object 简单的Java 对象,实际就是普通 JavaBeans)数据类型来对待,方便数据的解析和序列化。另外我们在类中还重写了 toString 方法,主要是为了测试输出显示更清晰。
我们这里自定义的 POJO 类会在后面的代码中频繁使用,所以在后面的代码中碰到,把
这里的POJO 类导入就好了。
从集合中读取数据
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();List<Integer> data = Arrays.asList(1, 22, 3);DataStreamSource<Integer> ds1 = env.fromCollection(data);ds1.print();DataStreamSource<Integer> ds2 = env.fromElements(1,23,44);ds2.print();env.execute();}从文件读取数据
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-files</artifactId> <version>${flink.version}</version>
</dependency> public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();FileSource<String> fileSource =FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("data/goodnight.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"any").print();env.execute();}从 Socket 读取数据
// TODO 准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// TODO read file
// String path = "data/goodnight.txt";DataStreamSource<String> hadoop1 = env.socketTextStream("hadoop1", 7777);
从 Kafka 读取数据 (没学过)
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version>
</dependency>
public class SourceKafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();KafkaSource<String> kafkaSource =KafkaSource.<String>builder().setBootstrapServers("hadoop102:9092").setTopics("topic_1").setGroupId("atguigu").setStartingOffsets(OffsetsInitializer.latest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> stream = env.fromSource(kafkaSource,WatermarkStrategy.noWatermarks(), "kafka-source");stream.print("Kafka");env.execute();}
}
从数据生成器读取数据
Flink 从 1.11 开始提供了一个内置的 DataGen 连接器,主要是用于生成一些随机数,用于在没有数据源的时候,进行流任务的测试以及性能测试等。1.17 提供了新的 Source 写法,需要导入依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-datagen</artifactId><version>${flink.version}</version></dependency> public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);// recordsPerCheckpoint has to be greater or equal to parallelism.// Either decrease the parallelism or increase the number of recordsPerCheckpoint./*** GeneratorFun接口重写map,输入类型Long* Long 生成的最大值,从1自增* 限速 每秒几条* 返回类型*/DataGeneratorSource<String> source = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long aLong) throws Exception {return "Number: " + aLong;}},10,RateLimiterStrategy.perSecond(2),Types.STRING// recordsPerCheckpoint has to be greater or equal to parallelism.// Either decrease the parallelism or increase the number of recordsPerCheckpoint.);env.fromSource(source, WatermarkStrategy.noWatermarks(), "DataGen").print();env.execute();}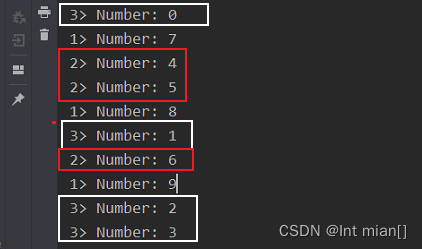 每个并行度上递增
每个并行度上递增
Flink 支持的数据类型
Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定 的序列化器、反序列化器和比较器。
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义, 就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性; 它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的。 在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比 之下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增 加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息, 从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情 况下(比如 Lambda 表达式中),自动提取的信息是不够精细的,只有显式地 告诉系统当前的返回类型,才能正确地解析出完整数据。
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
泛型擦除
Java 的泛型擦除(Generic Type Erasure)是一种编译器优化和类型安全机制,它发生在编译阶段,而不是运行时。泛型擦除的主要目的是在支持泛型的同时保持与 Java 早期版本的向后兼容性,并避免在运行时引入额外的开销。
泛型擦除的关键点包括:
类型擦除:在编译时,Java 泛型的类型信息被擦除,这意味着编译后的字节码中不再包含泛型类型信息。例如,
List<String>和List<Integer>在运行时都被视为List。类型参数擦除:泛型类型的类型参数(例如,
<T>)也会被擦除,编译后的字节码中不再包含类型参数信息。这些类型参数被擦除为它们的上边界或 Object 类型。类型强制转换:在运行时,泛型类型的实例通常会被强制转换为适当的类型,以满足编译时的类型检查。这可能导致运行时的 ClassCastException 异常,如果类型不匹配。
虽然泛型擦除是 Java 泛型的一个基本特性,但它也导致了一些泛型编程的限制和复杂性,需要开发人员注意处理泛型类型的类型安全性和边界情况
🌠转换算子
👾基本转换算子
map
public class t1_map {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_2", 2L, 2));// 方式一:传入匿名类,实现 MapFunctionstream.map(new MapFunction<WaterSensor, String>() {@Overridepublic String map(WaterSensor e) throws Exception {return e.id;}}).print();// 方式二:// stream.map((MapFunction<WaterSensor, String>) e -> e.id).print();SingleOutputStreamOperator<String> map = stream.map(s -> s.getId());// 方式三:传入 MapFunction 的实现类// stream.map(new UserMap()).print();env.execute();}public static class UserMap implements MapFunction<WaterSensor, String> {@Overridepublic String map(WaterSensor e) throws Exception {return e.id;}}
}flatMap
先按照某种规则对数据进行打散拆分,可以产生 0 到多个元素,再对拆分后的元素做转换处理
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 2L, 2),new WaterSensor("sensor_3", 3L, 3));stream.flatMap(new MyFlatMap()).print();env.execute();}public static class MyFlatMap implements FlatMapFunction<WaterSensor, String> {@Overridepublic void flatMap(WaterSensor value, Collector<String> out) throws Exception {if (value.id.equals("sensor_1")) {out.collect(String.valueOf(value.vc));} else if (value.id.equals("sensor_2")) {out.collect(String.valueOf(value.ts));out.collect(String.valueOf(value.vc));}}}filter
进行filter 转换之后的新数据流的数据类型与原数据流是相同的。filter 转换需要传入的参
数需要实现 FilterFunction 接口,而 FilterFunction 内要实现 filter()方法,就相当于一个返回布
尔类型的条件表达式。

public class t2_filter {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 2L, 2),new WaterSensor("sensor_3", 3L, 3));// 方式一:传入匿名类实现FilterFunction stream.filter(new FilterFunction<WaterSensor>() {@Overridepublic boolean filter(WaterSensor e) throws Exception {return e.id.equals("sensor_1");}}).print();stream.filter((FilterFunction<WaterSensor>) e -> e.id.equals("sensor_1")).print();stream.filter(e -> e.id.equals("sensor_1")).print();// 方式二:传入 FilterFunction 实现类 // stream.filter(new UserFilter()).print(); env.execute();}public static class UserFilter implements FilterFunction<WaterSensor> {@Overridepublic boolean filter(WaterSensor e) throws Exception {return e.id.equals("sensor_1");}}
}👾聚合算子
计算的结果不仅依赖当前数据,还跟之前的数据有关,相当于要把所有数据聚在一起进
行汇总合并——这就是所谓的“聚合”(Aggregation),类似于MapReduce 中的reduce 操作。
keyBy(准备工作)
keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
所有具有相同的key 的数据,都将被发往同一个分区。
对于Flink 而言,DataStream 是没有直接进行聚合的API 的。因为我们对海量数据做聚合
肯定要进行分区并行处理,这样才能提高效率。所以在Flink 中,要做聚合,需要先进行分区;这个操作就是通过 keyBy 来完成的。在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以
这里 key 如果是POJO 的话,必须要重写 hashCode()方法。
以id 作为key 做一个分区操作,代码实现如下
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 2L, 2),new WaterSensor("sensor_3", 3L, 3));// 方式一:使用 Lambda 表达式 KeyedStream<WaterSensor, String> keyedStream = stream.keyBy(e -> e.id);// 方式二:使用匿名类实现KeySelector KeyedStream<WaterSensor, String> keyedStream1 = stream.keyBy(new KeySelector<WaterSensor, String>() {@Overridepublic String getKey(WaterSensor e) throws Exception {return e.id;}});env.execute();}需要注意的是,keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为KeyedStream。KeyedStream 可以认为是“分区流”或者“键控流”,它是对 DataStream 按照key 的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定key 的类型。
只有基于它才可以做后续的聚合操作(比如sum,reduce)。
sum/min-max/minBy-maxBy
min(别的字段就第一个不变了)
minBy(别的字段会对应起来)
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 3L, 6),new WaterSensor("sensor_2", 2L, 9),new WaterSensor("sensor_2", 3L, 4),new WaterSensor("sensor_2", 3L, 5),new WaterSensor("sensor_3", 8L, 3),new WaterSensor("sensor_3", 7L, 7),new WaterSensor("sensor_3", 6L, 1));// 方式一:使用 Lambda 表达式KeyedStream<WaterSensor, String> KS = stream.keyBy(e -> e.id);
// // 方式二:使用匿名类实现KeySelector
// KeyedStream<WaterSensor, String> keyedStream1 = stream.keyBy(new KeySelector<WaterSensor, String>() {
// @Override
// public String getKey(WaterSensor e) throws Exception {
// return e.id;
// }
// });// KS.sum(2).print(); // Cannot reference field by position on PojoType
// KS.sum("vc").print();/* outWaterSensor{id='sensor_1', ts=1, vc=1}WaterSensor{id='sensor_1', ts=1, vc=3}WaterSensor{id='sensor_2', ts=3, vc=6}WaterSensor{id='sensor_2', ts=3, vc=11}WaterSensor{id='sensor_2', ts=3, vc=15}WaterSensor{id='sensor_2', ts=3, vc=17}WaterSensor{id='sensor_3', ts=3, vc=3}WaterSensor{id='sensor_3', ts=3, vc=6}WaterSensor{id='sensor_3', ts=3, vc=9}*/// KS.min("vc").print();/* 一条一条读进来,判断目前哪个最小,另外的值居然都是第一条的!!!!WaterSensor{id='sensor_1', ts=1, vc=1}WaterSensor{id='sensor_1', ts=1, vc=1}WaterSensor{id='sensor_2', ts=3, vc=6}WaterSensor{id='sensor_2', ts=3, vc=6}WaterSensor{id='sensor_2', ts=3, vc=4}WaterSensor{id='sensor_2', ts=3, vc=4}WaterSensor{id='sensor_3', ts=8, vc=3}WaterSensor{id='sensor_3', ts=8, vc=3}WaterSensor{id='sensor_3', ts=8, vc=1}*/KS.minBy("vc").print();/* 合理的,别的值都是对应的WaterSensor{id='sensor_1', ts=1, vc=1}WaterSensor{id='sensor_1', ts=1, vc=1}WaterSensor{id='sensor_2', ts=3, vc=6}WaterSensor{id='sensor_2', ts=3, vc=6}WaterSensor{id='sensor_2', ts=3, vc=4}WaterSensor{id='sensor_2', ts=3, vc=4}WaterSensor{id='sensor_3', ts=8, vc=3}WaterSensor{id='sensor_3', ts=8, vc=3}WaterSensor{id='sensor_3', ts=6, vc=1}*/env.execute();}reduce
reduce 可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
调用 KeyedStream 的 reduce 方法时,需要传入一个参数,实现 ReduceFunction 接口。接
口在源码中的定义如下:public interface ReduceFunction<T> extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
}
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 3L, 6),new WaterSensor("sensor_2", 2L, 9),new WaterSensor("sensor_2", 3L, 4),new WaterSensor("sensor_2", 3L, 5),new WaterSensor("sensor_3", 8L, 3),new WaterSensor("sensor_3", 7L, 7),new WaterSensor("sensor_3", 6L, 1));KeyedStream<WaterSensor, String> KS = stream.keyBy(e -> e.id);KS.reduce(new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {System.out.println("value1: "+value1);System.out.println("value2: "+value2);return new WaterSensor(value1.id, value2.ts, value1.vc+value2.vc);}}).print();/*** WaterSensor{id='sensor_1', ts=1, vc=1} 第一条不进入reduce* value1: WaterSensor{id='sensor_1', ts=1, vc=1}* value2: WaterSensor{id='sensor_1', ts=2, vc=2}* WaterSensor{id='sensor_1', ts=2, vc=3}* * WaterSensor{id='sensor_2', ts=3, vc=6} 第一条不进入reduce* value1: WaterSensor{id='sensor_2', ts=3, vc=6}* value2: WaterSensor{id='sensor_2', ts=2, vc=9}* WaterSensor{id='sensor_2', ts=2, vc=15}* value1: WaterSensor{id='sensor_2', ts=2, vc=15}* value2: WaterSensor{id='sensor_2', ts=3, vc=4}* WaterSensor{id='sensor_2', ts=3, vc=19}* value1: WaterSensor{id='sensor_2', ts=3, vc=19}* value2: WaterSensor{id='sensor_2', ts=3, vc=5}* WaterSensor{id='sensor_2', ts=3, vc=24}** WaterSensor{id='sensor_3', ts=8, vc=3} 第一条不进入reduce* value1: WaterSensor{id='sensor_3', ts=8, vc=3}* value2: WaterSensor{id='sensor_3', ts=7, vc=7}* WaterSensor{id='sensor_3', ts=7, vc=10}* value1: WaterSensor{id='sensor_3', ts=7, vc=10}* value2: WaterSensor{id='sensor_3', ts=6, vc=1}* WaterSensor{id='sensor_3', ts=6, vc=11}*/env.execute();}👾UDF
函数类
public class t6_UDF {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 3L, 6),new WaterSensor("sensor_2", 2L, 9),new WaterSensor("sensor_2", 3L, 4),new WaterSensor("sensor_2", 3L, 5),new WaterSensor("sensor_3", 8L, 3),new WaterSensor("sensor_3", 7L, 7),new WaterSensor("sensor_3", 6L, 1));// 方式一 自定义函数实现
// SingleOutputStreamOperator<WaterSensor> filter = stream.filter(new UserFilter()).print();// 通过匿名类来实现 FilterFunction 接口:stream.filter(new FilterFunction<WaterSensor>() {@Overridepublic boolean filter(WaterSensor value) throws Exception {return value.id.equals("sensor_1");}}).print();// lambdastream.filter(value -> value.id.equals("sensor_1")).print();env.execute();}public static class UserFilter implements FilterFunction<WaterSensor> {@Overridepublic boolean filter(WaterSensor e) throws Exception {return e.id.equals("sensor_1");}}}富函数类(多个open、close)
所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
Rich Function 有生命周期的概念。典型的生命周期方法有:
⚫ open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期,当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。
⚫ close()方法,是生命周期中的最后一个调用的方法,类似于结束方法。一般用来做一些清理工作。
这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
来看一个例子说明:
public class t6_UDF_rich {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);env.fromElements(1,2,3,4).map(new RichMapFunction<Integer, Integer>() {@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);System.out.println(" 索引: " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期开始, " +"子任务名: "+ getRuntimeContext().getTaskNameWithSubtasks()+"调用open");}@Overridepublic Integer map(Integer integer) throws Exception {return integer * 10;}@Overridepublic void close() throws Exception {super.close();System.out.println(" 索引: " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期结束, " +"子任务名: "+ getRuntimeContext().getTaskNameWithSubtasks()+"调用close");}}).print();env.execute();}
}// 索引: 0 的任务的生命周期开始, 子任务名: Map -> Sink: Print to Std. Out (1/2)#0调用open
// 索引: 1 的任务的生命周期开始, 子任务名: Map -> Sink: Print to Std. Out (2/2)#0调用open
// 1> 10
// 2> 20
// 2> 40
// 1> 30
// 索引: 0 的任务的生命周期结束, 子任务名: Map -> Sink: Print to Std. Out调用close
// 索引: 1 的任务的生命周期结束, 子任务名: Map -> Sink: Print to Std. Out调用close
👾物理分区算子
常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
随机分区
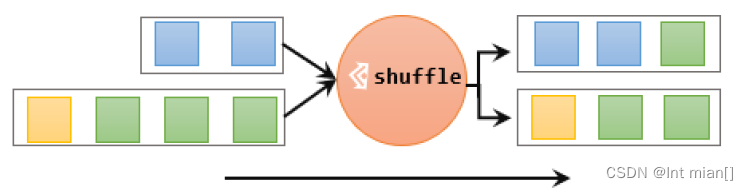
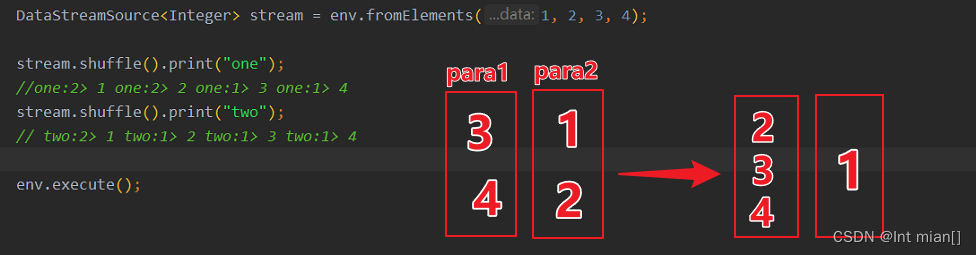
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随
机地分配到下游算子的并行任务中去。
轮询分配(Round-Robin)
轮询,简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用 DataStream.rebalance()方法,就可以实现轮询重分区。rebalance 使用的是Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
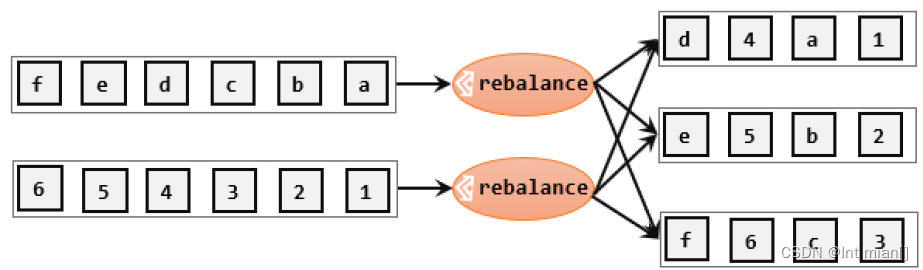
重缩放(Rescale)
重缩放分区和轮询分区非常相似。
🌌重分区是将数据流重新分区为新的分区数,通常涉及改变分区策略或将数据重新组织以匹配不同的并行度需求。
- 重分区通常用于将数据重新分发到更多或更少的并行任务,以实现负载均衡或更好的并行性。
- 重分区可能会引入数据洗牌和网络传输的开销。
广播(Broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
全局分区(并行度转1)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
自定义分区
当 Flink 提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
public class t7_DIYpartition {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<Integer> stream = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8);stream.partitionCustom(new MyPartitioner(), value -> value).print();env.execute();}public static class MyPartitioner implements Partitioner<Integer> {@Overridepublic int partition(Integer key, int numPartitions) {if (key < 5) {return 0;} else{return 1;}// 这里如果分三个区就报错了,可能因为并行度?}}
}👾分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
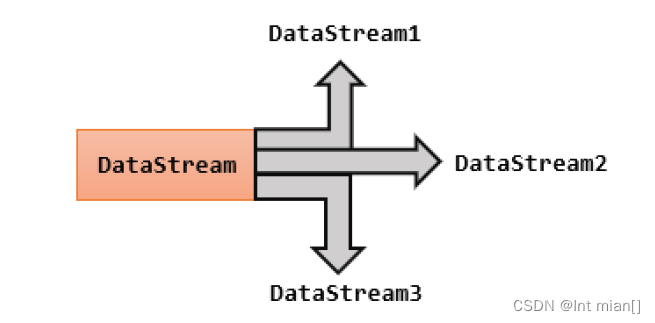
就这么个理
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<Integer> stream = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8);SingleOutputStreamOperator<Integer> ds1 = stream.filter(x -> x % 2 == 0);SingleOutputStreamOperator<Integer> ds2 = stream.filter(x -> x % 2 != 0);ds1.print("ds1");ds2.print("ds2");env.execute();} public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> stream = env.fromElements(new WaterSensor("sensor_1", 1L, 1),new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 3L, 6),new WaterSensor("sensor_2", 2L, 9),new WaterSensor("sensor_2", 3L, 4),new WaterSensor("sensor_2", 3L, 5),new WaterSensor("sensor_3", 8L, 3),new WaterSensor("sensor_3", 7L, 7),new WaterSensor("sensor_3", 6L, 1));SingleOutputStreamOperator<WaterSensor> process = stream.process(new ProcessFunction<WaterSensor, WaterSensor>() {@Overridepublic void processElement(WaterSensor value, ProcessFunction<WaterSensor, WaterSensor>.Context ctx, Collector<WaterSensor> out) throws Exception {if (value.getId().equals("sensor_1")) {ctx.output(new OutputTag<WaterSensor>("s1", Types.POJO(WaterSensor.class)), value);} else if (value.getId().equals("sensor_2")) {ctx.output(new OutputTag<WaterSensor>("s2", Types.POJO(WaterSensor.class)), value);} else {out.collect(value);}}});process.print();process.getSideOutput(new OutputTag<WaterSensor>("s1", Types.POJO(WaterSensor.class))).print("s1");process.getSideOutput(new OutputTag<WaterSensor>("s2", Types.POJO(WaterSensor.class))).print("s2");env.execute();/*s1> WaterSensor{id='sensor_1', ts=1, vc=1}s1> WaterSensor{id='sensor_1', ts=2, vc=2}s2> WaterSensor{id='sensor_2', ts=3, vc=6}s2> WaterSensor{id='sensor_2', ts=2, vc=9}s2> WaterSensor{id='sensor_2', ts=3, vc=4}s2> WaterSensor{id='sensor_2', ts=3, vc=5}WaterSensor{id='sensor_3', ts=8, vc=3}WaterSensor{id='sensor_3', ts=7, vc=7}WaterSensor{id='sensor_3', ts=6, vc=1}*/}👾合流
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。 所以 Flink 中合流的操作会更加普遍,对应的 API 也更加丰富。
联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作 要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。

stream1.union(stream2, stream3, ...) SideOutputDataStream<WaterSensor> s1 = process.getSideOutput(new OutputTag<WaterSensor>("s1", Types.POJO(WaterSensor.class)));SideOutputDataStream<WaterSensor> s2 = process.getSideOutput(new OutputTag<WaterSensor>("s2", Types.POJO(WaterSensor.class)));DataStream<WaterSensor> union = process.union(s1, s2);union.print();连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink 还提供了另外一种方便的合流操作——连接(connect)。
为了处理更加灵活,连接操作允许流的数据类型不同。 但我们知道一个DataStream中的数据只能有唯一的类型, 所以连接得到的并不是DataStream,而是一个“连接流”。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Integer> stream1 = env.fromElements(11, 22, 33);DataStreamSource<String> stream2 = env.fromElements("aaa", "bbb", "ccc");// 好像只能connect两个ConnectedStreams<Integer, String> connect = stream1.connect(stream2);// 流1类型 流2类型 输出类型, map完又变成了dataStreamconnect.map(new CoMapFunction<Integer, String, String>() {@Overridepublic String map1(Integer value) throws Exception {return value.toString()+"str";}@Overridepublic String map2(String value) throws Exception {return value;}}).print();/*** aaa* 11* bbb* 22* ccc* 33*/env.execute();}由于需要“一国两制”,因此调用.map()方法时传入的不再是一个简单的 MapFunction,而是一个 CoMapFunction,表示分别对两条流中的数据执行 map 操作。这个接 口有三个类型参数,依次表示第一条流、第二条流,以及合并后的流中的数据类型。需要实 现的方法也非常直白:.map1()就是对第一条流中数据的 map 操作,.map2()则是针对第二条流。
与 CoMapFunction 类似,如果是调用.map()就需要传入一个 CoMapFunction,需要实现map1()、map2()两个方法;而调用.process()时,传入的则是一个 CoProcessFunction。它也是 “处理函数”家族中的一员,用法非常相似。它需要实现的就是 processElement1()、 processElement2()两个方法,在每个数据到来时,会根据来源的流调用其中的一个方法进行处 理。
🌠输出算子
👾连接到外部系统
Flink 的 DataStream API 专门提供了向外部写入数据的方法:addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一般都是利用 Sink 算子完成的。
Flink1.12 开始,同样重构了 Sink 架构,stream.sinkTo(…) ,当然,Sink 多数情况下同样并不需要我们自己实现。之前我们一直在使用的 print 方法其实就是一种 Sink,它表示将数据流写入标准控制台打印输出。Flink 官方为我们提供了一部分的框架的Sink 连接器。如下图所示,列出了 Flink 官方目前支持的第三方系统连接器:

👾输出到文件
Flink 专门提供了一个流式文件系统的连接器:FileSink,为批处理和流处理提供了一个统一的Sink,它可以将分区文件写入 Flink 支持的文件系统。
FileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded)格式。这两种不同的方式都有各自的构建器(builder),可以直接调用 FileSink 的静态方法:
⚫ 行编码: FileSink.forRowFormat(basePath,rowEncoder)。
⚫ 批量编码: FileSink.forBulkFormat(basePath,bulkWriterFactory)。
👾输出到kafka(没学过

👾MySQL
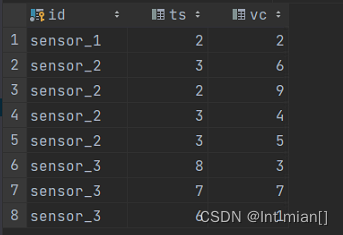
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency>CREATE TABLE `ws` (`id` varchar(100) NOT NULL,`ts` bigint(20) DEFAULT NULL,`vc` int(11) DEFAULT NULL,) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);SingleOutputStreamOperator<WaterSensor> sensorDS = env.fromElements(new WaterSensor("sensor_1", 2L, 2),new WaterSensor("sensor_2", 3L, 6),new WaterSensor("sensor_2", 2L, 9),new WaterSensor("sensor_2", 3L, 4),new WaterSensor("sensor_2", 3L, 5),new WaterSensor("sensor_3", 8L, 3),new WaterSensor("sensor_3", 7L, 7),new WaterSensor("sensor_3", 6L, 1));/*** TODO 写入mysql* 1、只能用老的sink 写法: addsink* 2、JDBCSink 的 4 个参数:* 第一个参数: 执行的 sql,一般就是 insert into* 第二个参数: 预编译 sql, 对占位符填充值* * 第三个参数: 执行选项 ---》 攒批、重试* * 第四个参数: 连接选项 ---》 url、用户名、密码**/SinkFunction<WaterSensor> jdbcSink = JdbcSink.sink("insert into ws values(?,?,?)",new JdbcStatementBuilder<WaterSensor>() {@Overridepublic void accept(PreparedStatement preparedStatement, WaterSensor waterSensor) throws SQLException {//每收到一条 WaterSensor,如何去填充占位符preparedStatement.setString(1,waterSensor.getId());preparedStatement.setLong(2,waterSensor.getTs());preparedStatement.setInt(3,waterSensor.getVc());}},JdbcExecutionOptions.builder().withMaxRetries(3) // 重试次数.withBatchSize(100) // 批次的大小:条数.withBatchIntervalMs(3000) // 批次的时间.build(),new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/firstscheam?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8").withUsername("root").withPassword("123456").withConnectionCheckTimeoutSeconds(60) // 重试的超时时间.build());sensorDS.addSink(jdbcSink);env.execute();
}
👾DIY
最好用提供好的
如果我们想将数据存储到我们自己的存储设备中,而Flink 并没有提供可以直接使用的连接器,就只能自定义 Sink 进行输出了。
stream.addSink(new MySinkFunction<String>());
在实现 SinkFunction 的时候,需要重写的一个关键方法 invoke(),在这个方法中我们就可以实现将流里的数据发送出去的逻辑。
这种方式比较通用,对于任何外部存储系统都有效;不过自定义 Sink 想要实现状态一致性并不容易,所以一般只在没有其它选择时使用。实际项目中用到的外部连接器Flink 官方基本都已实现,而且在不断地扩充,因此自定义的场景并不常见。


![[机缘参悟-110] :一个IT人对面具的理解:职业面具戴久了,就会忘记原本真实的自己,一个人是忠于职位,还是忠于内心?](https://img-blog.csdnimg.cn/2464ef572c7c4e5c8eecf82a9cc13b89.png)