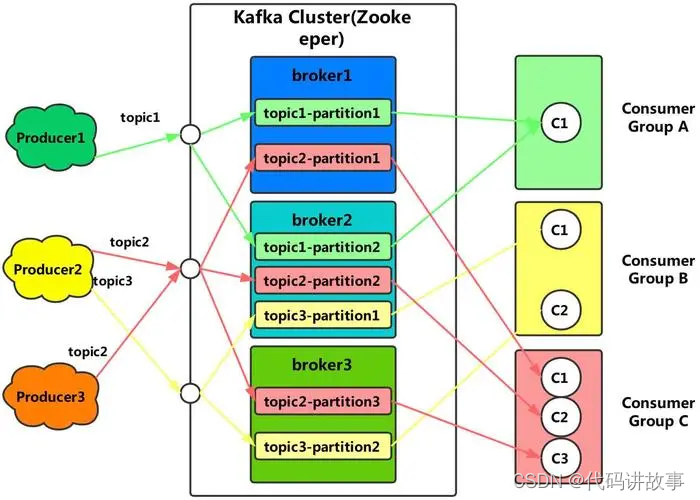
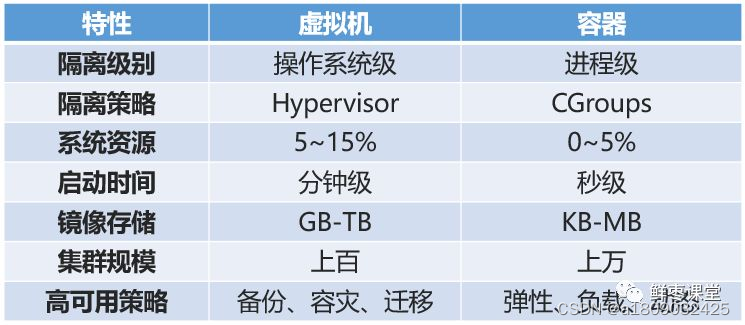
文章目录
- 一、赛事概述
- 1.1 OpenBookQA Dataset
- 1.2 比赛背景
- 1.3 评估方法和代码要求
- 1.4 比赛数据集
- 1.5 优秀notebook
- 二、 [EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS
- 2.1 Data overview
- 2.2 Data gathering
- 三、如何高效收集数据
- 3.1 概述
- 3.2 与训练数据关联的维基百科类别分析
- 四、with only 270K articles!
- 4.0 什么是RAG?
- 4.1 New 270K Wikipedia STEM articles
- 4.2 270K articles+LongFormer Large(2610s,LB=0.862)
- 4.2.1 导入依赖库,使用OpenBook方法预测结果
- 4.2.2 检索相关文档
- 4.2.3 定义预处理函数和评测指标
- 4.2.4 推理
- 4.3 270K articles+DEBERTA v3 large(2396s,LB=0.905)
- 4.4 RAPIDS TF-IDF+DEBERTA v3 large(756s,LB=0.904)
- 4.4.1 环境配置
- 4.4.2 RAG Retrieval
- 4.4.3 定义预处理函数和评测指标
- 4.4.4 双线程推理
- 4.4.5 评测结果并保存
一、赛事概述
1.1 OpenBookQA Dataset
OpenBookQA Dataset是由美国艾伦人工智能研究院(Allen Institute for AI)发布的一个问答技术评测集,其主要目的是通过选择题考试的方式来测试和评估人工智能系统的问题回答能力,以下是更详细的介绍。
-
发布背景
许多之前的阅读理解数据集都是基于抽取式的方法,只需要从给定的上下文中抽取答案,而没必要进行更深层次的推理。OpenBookQA要求模型需要利用基础知识来回答问题,进行更复杂的推理。 -
数据集构成
OpenBookQA包含5957个四选一的科学常识问题(4,957 train, 500 dev, 500 test)。这些问题需要根据包含1326个科学事实的小“书本”来回答。问题采样自维基百科页面。 -
模型表现
回答OpenBookQA的问题不仅需要给定知识库中的科学常识,还需要额外的广泛常识知识。这些问题既不能通过检索算法回答正确,也不能通过词语共现算法回答正确。Strong neural baselines在OpenBookQA上只能达到约50%的准确率,与人类92%的准确率存在明显差距。 -
附加数据
该数据集还提供了5167个群众贡献的常识知识,以及扩展的训练集、开发集、测试集,每个问题对应其所考察的核心科学事实、人类准确率、清晰度评分等信息。 -
数据集意义
OpenBookQA推动了机器阅读理解从抽取式到推理式的发展,评估了模型在开放域知识下的深层理解和推理能力。
1.2 比赛背景
赛事地址:Kaggle - LLM Science Exam
- LLM的能力:随着大型语言模型的能力不断扩展,研究领域中出现了使用LLMs来表征自身的趋势。因为许多现有的自然语言处理基准测试已经被最先进的模型轻松解决,所以有趣的工作是利用LLMs创建更具挑战性的任务,以测试更强大的模型。
- 数据生成:比赛使用了gpt3.5模型,该模型基于从维基百科中提取的各种科学主题的文本片段,要求它编写一个多项选择问题(附带已知答案),然后过滤掉简单的问题。
- 资源受限:本次比赛是一场代码比赛,GPU和时间都受到限制。
- 挑战性:虽然量化和知识蒸馏等技术可以有效地缩小语言模型以便在更少的硬件资源上运行,但这场比赛仍旧充满挑战。目前,目前在 Kaggle 上运行的最大模型有大约 100 亿个参数,而
gpt3.5有 1750 亿个参数。如果一个问答模型能够轻松通过一个比其规模大10倍以上的模型编写的问答测试,这将是一个真正有趣的结果。另一方面,如果更大的模型能够有效地难住较小的模型,这对LLMs自我评估和测试的能力具有引人注目的影响。 - 竞赛旨在探讨比gpt3.5小10倍以上的问答模型能否有效回答gpt3.5编写的问题。结果将揭示LLM的基准测试和自我测试能力。
1.3 评估方法和代码要求
提交根据平均精度 @ 3 (MAP@3) 进行评估:

其中 ,𝑈 为测试集中的问题数量,𝑃(𝑘) 为截断值为 𝑘 时的精确度,𝑛 为每个问题的预测数量,𝑟𝑒𝑙(𝑘) 为指示函数,如果排名为 𝑘 的项目是相关的(正确的)标签,则等于1,否则为0。
另外,某个问题正确预测后,后续将跳过该标签的其他预测,以防止刷准确度。举例来说,假设有一个测试集,里面有3个问题的正确答案都是A,如果有一个模型对这3个问题给出以下答案,那么以下情况都会得到平均精确度1.0的分数:
[A, B, C, D, E] # 问题1预测
[A, A, A, A, A] # 问题2预测
[A, B, A, C, A] # 问题3预测
这意味着一旦找到正确答案(A),之后的预测不再影响平均精确度分数。
本次比赛必须以notebook提交,且CPU和GPU运行时间少于9小时。禁用互联网,但是允许使用公开的外部数据,包括预先训练的模型。另外提交文件必须命名为 submission.csv。
1.4 比赛数据集
本次比赛是回答由gpt3.5模型生成的4000道多选题组成的测试集。测试集是隐藏的,当提交notebook后,才会有实际的测试数据进行评测。
- train.csv : 200个样本,问题+答案,以显示数据格式,并大致了解测试集中的问题类型。
- test.csv : 测试集,只包含题目,答案省略。
- sample_submission.csv : 提交格式示例
具体的训练集格式如下:
# Let's import the public training set and take a look
import pandas as pdtrain_df = pd.read_csv('/kaggle/input/kaggle-llm-science-exam/train.csv')
train_df.head()

对于测试集中的每个 id 标签,您最多可以预测 3 个标签 。submission.csv文件应包含header并具有以下格式:
id,prediction
0, A B C
1, B C A
2, C A B
etc.
1.5 优秀notebook
-
《Starter Notebook: Ranked Predictions with BERT》:Bert Baseline,使用
bert-base-cased和比赛提供的200个训练集样本进行训练,Public Score=0.545。 -
《[EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS》(制作训练数据):比赛提供的200个样本太少了,作者
LEONID KULYK先分析了比赛数据集,然后同样使用gpt3.5制作了1000个Wikipedia样本,数据集上传在Wikipedia STEM 1k。 -
《LLM-SE ~ deberta-v3-large -i | 1k Wiki》:
LEONID KULYK将自己收集的1000个Wikipedia样本和比赛训练集合并,一起训练,模型是deberta-v3-large。notebook中有最终模型权重,可直接推理,LB= 0.709。 -
《New dataset + DEBERTA v3 large training!》:
0.723→0.759-
Radek基于方法3,使用自己生成的500个额外数据训练DEBERTA v3 large,Public Score=0.723。 -
Radek后来又生成了6000条数据,跟之前的500条融合为6.5K数据集,并在此基础上进行三次训练,得到了三个模型权重,上传在Science Exam Trained Model Weights中。然后通过下面两种方法,进行推理:-
《Inference using 3 trained Deberta v3 models》:三个模型分别预测之后概率取平均,
Public Score=0.737。 -
An introduction to Voting Ensemble:作者在这个notebook中详细介绍了Voting Ensemble以及使用方法,
Public Score=0.759。
-
-
作者最后上传了15k high-quality train examples。
-
-
《Open Book LLM Science Exam》:
jjinho首次提出了Open Book方法,演示了如何在训练集中,使用faiss 执行相似性搜索,找到与问答数据最相似的context(Wikipedia数据),以增强问答效果。 -
《Open Book LLM Science Exam - Reduced RAM usage》:
quangbk改进了方法5中的内存效率。 -
《OpenBook DeBERTaV3-Large Baseline (Single Model》):
Anil将方法4和方法6结合起来。他将先测试集数据按照方法6搜索出context,然后将其与prompt合并,得到新的测试集。然后加载方法4训练的模型进行推理,Public Score=0.771。test_df["prompt"] = test_df["context"] + " #### " + test_df["prompt"] -
《Sharing my trained-with-context model》:
Mgoksu同样使用了方法7,只是使用了自己制作的数据集进行离线训练,得到一个更好的模型llm-science-run-context-2,然后进行推理,top publicLB=0.807。 -
《How To Train Open Book Model - Part 1》、《How To Train Open Book Model - Part 2》:
CHRIS DEOTTE在part1中,参照方法8在自己制作的60k数据集进行训练,得到模型model_v2;然后在part2中使用方法8中的模型llm-science-run-context-2以及model_v2分别进行推理,得到的两个概率取平均,得到最终结果(Public Score=0.819)。- 在part1中,作者使用了竞赛指标MAP@3 来评估模型,并讨论了一些训练技巧,例如使用 PEFT或冻结model embeddings&model layers来减少训练参数、增加 LR 并减少 epochs来减少计算量、 使用gradient_checkpointing(这使用磁盘来节省RAM)、使用gradient_accumlation_steps模拟更大的批次等等。
-
《LLM Science Exam Optimise Ensemble Weights》:作者首先使用了方法9训练的模型权重;另外为了增加多样性,还融合了其它几个没有使用Open Book的deberta-v3-large模型,最终
Public Score=0.837。作者还写了以下notebook:- 《Incorporate MAP@k metrics into HF Trainer》:在Trainer中加入MAP@k指标
- 《Introducing Adversarial Weight Perturbation (AWP)》、《Adversarial Weight Perturbation (AWP) Inference》:介绍对抗性权重扰动AWP,以及推理方法。
- 《Using DeepSpeed with HF🤗 Trainer》,希望可以节约内存,以便训练更大的模型。
-
《LLM-SciEx Optimise Ensemble Weights(better models)》:类似方法10,通过模型融合,
Public Score=0.846。 -
《with only 270K articles》:作者自己制作了270K Wikipedia数据,使用
LongFormer模型而不是deberta-v3-large进行训练,Public Score=0.862。 -
《Platypus2-70B with Wikipedia RAG》:
SIMJEG结合了方法8和12,一共18个版本,Public Score从0.832到0.909。ALI在 《Explained Platypus2-70B + Wikipedia RAG》中对此notebook做了详细的说明。 -
《Fork of Fork of [86.2] with only 270K articles!》在方法12的基础上改进了预处理函数,并使用方法8 的模型,
Public Score=0.905 -
《RAPIDS TF-IDF - [LB 0.904] - Single Model》:在方法12的基础上,使用RAPIDS TF-IDF加速检索过程,使用双GPU(2xT4 GPU)和双线程来加速推理过程,并微调了部分参数(prepare_answering_input2),最终
LB=0.904。作者说自己参照方法11,融合了另外6个模型,最终得分0.916,代码未公开。
二、 [EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS
参考 《[EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS》
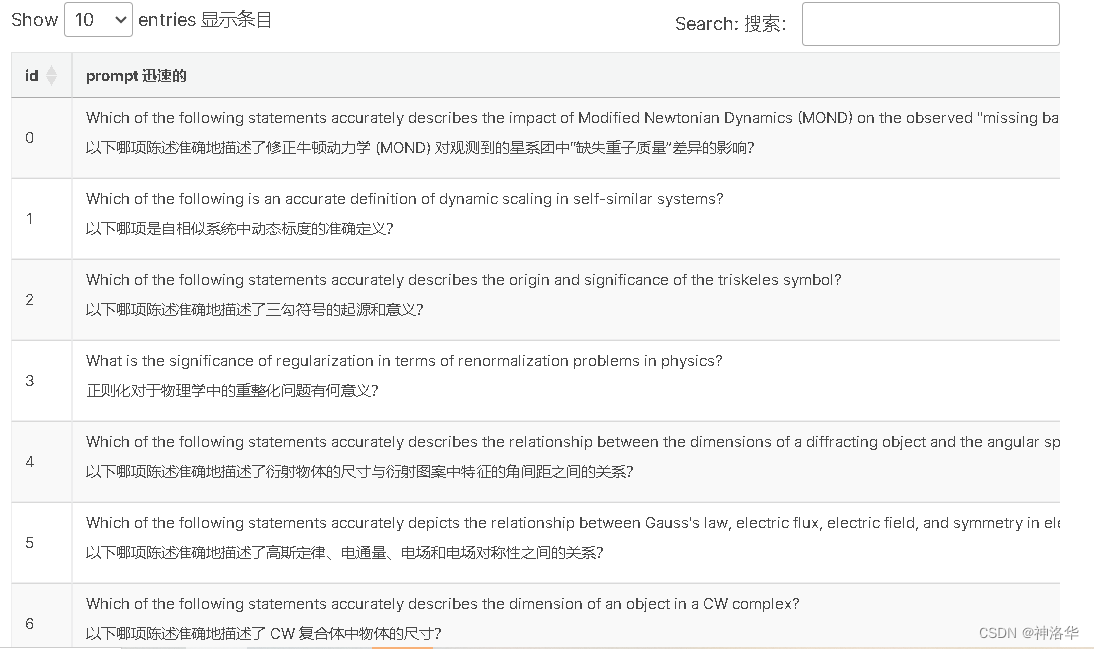
本次比赛的数据集由GPT3.5生成的多项选择题组成,数据是prompt(问题)+ A、B、C、D 、 E 五个答案选项+answer(正确答案)组成。比赛目标是根据prompt预测前三个最可能的答案选项。
2.1 Data overview
import os
import randomimport openai
import requests
import wikipediaapi
import itables
import numpy as np
import pandas as pd
import plotly.express as px
from kaggle_secrets import UserSecretsClient
# specify OpenAI API key in Kaggle's secrets add-ons.
user_secrets = UserSecretsClient()
openai.api_key = user_secrets.get_secret("openai_api")
train_df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/train.csv")
table = itables.show(train_df, table_options=dict(pageLength=10))
table
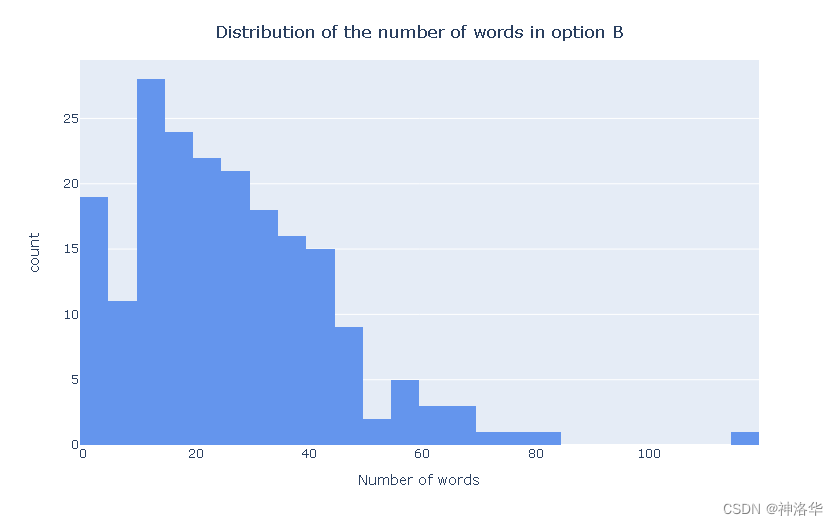
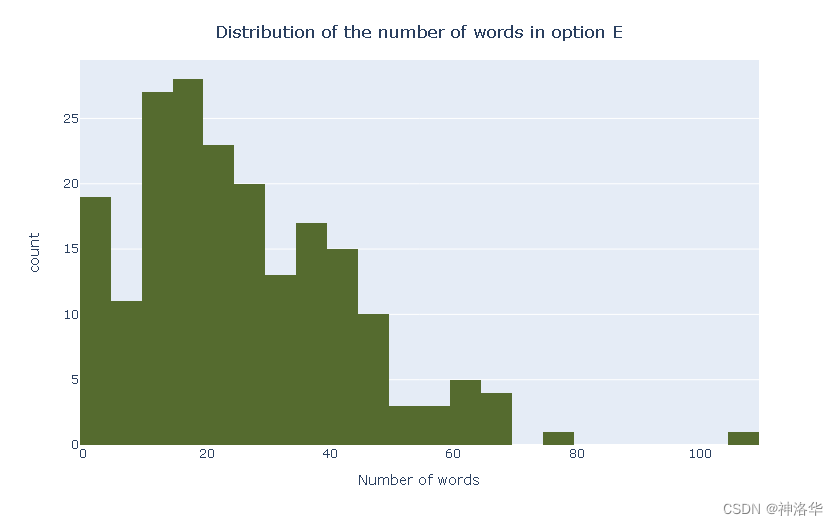
下面显示每个字段的单词数量分布:
fig = px.histogram([len(x.split(" ")) for x in train_df.prompt], nbins=40, color_discrete_sequence=['goldenrod'])
fig.update_layout(showlegend=False,xaxis_title="Number of words",title={'text': "Distribution of the number of words in prompts",'y':0.95,'x':0.5,'xanchor': 'center','yanchor': 'top'}
)
fig.show()
 |  |
 |  |
 |  |
2.2 Data gathering
本次比赛最重要的部分就是数据收集。因此,了解测试数据集是如何形成的以及如何重现其收集方法非常重要。
根据竞赛描述,测试数据集是基于维基百科的页面形成的。换句话说,选择了关于科学、技术、工程和数学主题的页面(重点是STEM中的S主题),从中摘录了一段内容,并将其传递到 GPT3.5 模型,然后生成多选问答数据。
为了复现比赛测试数据的收集,需要执行以下步骤:
-
形成一个STEM(科学、技术、工程和数学)类别列表,针对每个类别将搜索相应的页面以从中提取测试内容。
-
随机选择与相应主题或子主题相关的类别或页面。
- 随机选择一个 STEM 主题,即 S 或 T 或 E 或 M。
- 根据所选的 STEM 主题,从列表中随机选择一个类别。
- 获取所选类别的所有子类别和页面。
- 如果所选列表是子类别列表,则选择随机子类别并转到上一步,如果所选列表是页面列表,则选择随机页面。
-
在选择页面后,从中提取文本。
- 如果页面足够长(> 6 个句子),则从页面中提取前 7 个句子。
-
向LLM模型发送一条消息,明确说明需要执行的任务,并提供提取的文本。
- 包括指定要生成的多项选择题的数量、答案选项的长度或格式
- 生成过程中提供一些指南或越苏,例如提供有关问题和答案所需的风格、语气或复杂程度
options_set = set(("option_1", "option_2", "option_3", "option_4", "option_5"))
response_keys_set = set(("question", "option_1", "option_2", "option_3", "option_4", "option_5", "answer"))delimiter = "####"
system_message = f"""
You will be provided with TEXT from wikipedia. \
The TEXT will be delimited with {delimiter} characters.
Output a python list of 5 dict objects, where each object is \
a multiple choice question whom answers should be in \
the given TEXT and that has 5 choices each and has the following format:'question': <question on the TEXT>'option_1': <question answer option>'option_2': <question answer option>'option_3': <question answer option>'option_4': <question answer option>'option_5': <question answer option>'answer': <answer option key label>You should tell me which one of your proposed options is right \
by assigning the corresponding option's key label in the 'answer' field.The question, the answer and question answer options should be broad, \
challenging, long, detailed and based on the TEXT provided.Only output the list of objects, with nothing else.
"""
def get_completion_messages(wiki_text):return [ {'role':'system', 'content': system_message}, {'role':'user', 'content': f"{delimiter}{wiki_text}{delimiter}"}, ]def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0.8, max_tokens=3000):response = openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, max_tokens=max_tokens)return response.choices[0].message["content"]
- 解析模型的输出并自动检查是否符合输出格式。
- 组合以上所有操作
最终,作者根据以上思路,基于250个维基百科Page,生成了1000个训练数据,数据集见数据集Wikipedia STEM 1k。基于此数据集进行训练和推理的代码见《LLM-SE ~ deberta-v3-large -t | 1k Wiki》、《[LB: 0.709] LLM-SE ~ deberta-v3-large -i | 1k Wiki》
三、如何高效收集数据
参考《More efficient data collection: How to choose which categories to focus on?》
3.1 概述
这次竞赛的数据集是通过gpt3.5收集的,分为两个阶段:
- 收集相关的维基百科文章。
- 从这些维基百科文章中生成问题。
第一步相对简单,在《LLM-SE ~ Wiki STEM | 1k DS》中已经解决了但第二步如果使用gpt-3.5 API来从成千上万的文章中生成新问题,会很昂贵。为了确保我们只包括与任务相关的维基百科文章,有两个主要因素:a) 降低成本,b) 减少模型中的噪声(这是微调的主要目的)。
比如,我们知道这个竞赛是基于维基百科上科学类的文章,那么训练数据不应包括历史类或地理类的文章。即使如此,维基百科上科学类文章还是有很多,如果我们可以筛选出与竞赛相关的文章,那将有助于减少模型中的噪声。
3.2 与训练数据关联的维基百科类别分析
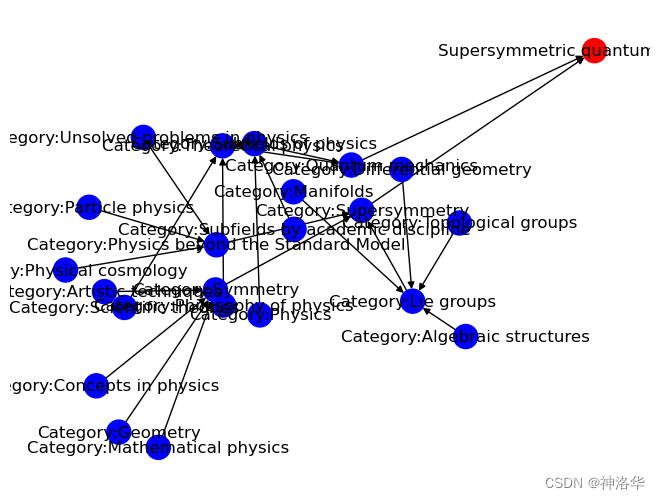
在《LLM Science Exam: Wikipedia Graph Analysis》中,作者对包含了本次比赛训练数据的wikipedia pages进行了分析,目的找出哪些wikipedia类别最合适用来生成更多的训练数据。作者采取了以下步骤:
- 手动检索,列出训练数据中包含的所有维基百科文章,一共154篇
train_pages = ['Supersymmetric quantum mechanics','Relative density','Memristor','Quantization (physics)','Symmetry in biology','Mass versus weight','Navier–Stokes equations','Thermal equilibrium','Electrical resistivity and conductivity','Superconductivity','Black hole','Born reciprocity',"Commentary on Anatomy in Avicenna's Canon",'Supernova','Angular momentum','Condensation cloud','Minkowski space','Vacuum','Standard Model','Nebula','Antiferromagnetism','Light-year','Propagation constant','Phase transition','Redshift','The Ambidextrous Universe','Interstellar medium','Improper rotation','Plant','Clockwise','Morphology (biology)','Magnetic susceptibility','Nuclear fusion','Theorem of three moments','Lorentz covariance','Causality (physics)','Total internal reflection','Surgical pathology','Environmental Science Center','Electrochemical gradient','Planetary system','Cavitation','Parity (physics)','Dimension','Heat treating','Speed of light','Mass-to-charge ratio','Landau–Lifshitz–Gilbert equation','Point groups in three dimensions','Mammary gland','Convection (heat transfer)','Modified Newtonian dynamics',"Earnshaw's theorem",'Coherent turbulent structure','Phageome','Infectious tolerance','Ferromagnetism','Coffee ring effect','Magnetic resonance imaging','Ring-imaging Cherenkov detector','Tidal force','Kutta-Joukowski theorem','Radiosity (radiometry)','Quartz crystal microbalance','Crystallinity','Magnitude (astronomy)',"Newton's law of universal gravitation",'Uniform tilings in hyperbolic plane','Refractive index','Theorem','Leidenfrost effect','API gravity','Supersymmetry','Dark Matter','Molecular symmetry','Spin (physics)','Astrochemistry','List of equations in classical mechanics','Diffraction','C1 chemistry','Reciprocal length','Amplitude','Work function','Coherence (physics)','Ultraviolet catastrophe','Symmetry of diatomic molecules','Bollard pull','Linear time-invariant system','Triskelion','Cold dark matter','Frame-dragging',"Fermat's principle",'Enthalpy','Main sequence','QCD matter','Molecular cloud','Free neutron decay','Second law of thermodynamics','Droste effect','History of geology','Gravitational wave','Regular polytope','Spatial dispersion','Probability amplitude','Stochastic differential equation','Gravity Probe B','Electronic entropy','Renormalization','Unified field theory',"Elitzur's theorem","Hesse's principle of transfer",'Ecological pyramid','Virtual particle','Ramsauer–Townsend effect','Butterfly effect','Zero-point energy','Baryogenesis','Pulsar','Decay technique','Electric flux','Water hammer','Dynamic scaling','Luminance','Crossover experiment (chemistry)','Spontaneous symmetry breaking','Self-organization in cybernetics','Stellar classification','Probability density function','Pulsar-based navigation','Supermassive black hole','Explicit symmetry breaking','Surface power density','Organography','Copernican principle','Geometric quantization','Erlangen program','Magnetic monopole','Inflation (cosmology)','Heart','Observable universe','Wigner quasiprobability distribution','Shower-curtain effect','Scale (ratio)','Hydrodynamic stability','Paramagnetism','Emissivity','Critical Raw Materials Act','James Webb Space Telescope','Signal-to-noise ratio','Photophoresis','Time standard','Time','Galaxy','Rayleigh scattering'
]
-
查找给定页面的类别:我们使用BeautifulSoup来提取每个页面所属的类别,而不依赖维基百科API,因为API会返回一些不相关的隐藏类别。
-
组合图表:使用 networkx 创建一个页面所属所有类别的图表,得到包含所有页面和它们的类别关系的整体图表。
-
分析整体图表:通过以下两个方面分析整体图表
-
查找连接数量最多的类别:对每个类别创建一个深度搜索优先树,然后计算树中的Pages数量,统计出每个类别链接了多少Pages。
-
计算类别的相关性得分:很多类别链接的Pages都很多,不足以进行分析。我们计算每个类别与其连接的所有页面之间的最短距离的倒数之和,将其做为“相关性得分”。这个得分有两个影响因素:
-
连接的页面数量:如果一个类别与更多的页面连接,那么它的得分将更高,因为它涵盖了更多的内容。
-
连接距离:如果一个类别与页面之间的连接是非常紧密的,即它们之间的最短距离很小,那么它的得分将更高。这是因为这个类别更可能与页面内容直接相关。
-
-
top_leaf_connect_distances[:10]
# 为了便于阅读,元组中加了空格
[('Category:Concepts in physics', 59.0984126984127),('Category:Concepts by field', 42.90479797979802),('Category:Physics', 42.26829004329007),('Category:Subfields of physics', 37.716269841269835),('Category:Physical sciences', 37.33095238095237),('Category:Subfields by academic discipline', 36.35238095238095),('Category:Physical phenomena', 36.318253968253956),('Category:Main topic classifications', 35.085714285714275),('Category:Concepts', 34.82943722943723),('Category:Physical quantities', 34.773409923409915)]
从上面可以看出,“Concepts in physics”得分最高,这个类别可以用于收集更多训练数据。作者测试了,仅通过“Concepts in physics”类别,并在深度为1的情况下进行查询,结果包含882个Pages,其中包括了训练集中的111个Pages,占总训练集的72%。这大大减少了我们需要生成问题以生成额外训练数据的页面数量。
考虑到其它科学领域没有覆盖到,您可以尝试探索图表中的其他类别,并将其添加进来,以查看是否可以覆盖更多的训练数据。
四、with only 270K articles!
参考:《[86.2] with only 270K articles!》、《《Finding 270K Wikipedia STEM articles!》、《270K Wikipedia STEM articles》
4.0 什么是RAG?
参考《Kaggle大模型比赛冠军方案梳理》
常规的微调过程为:
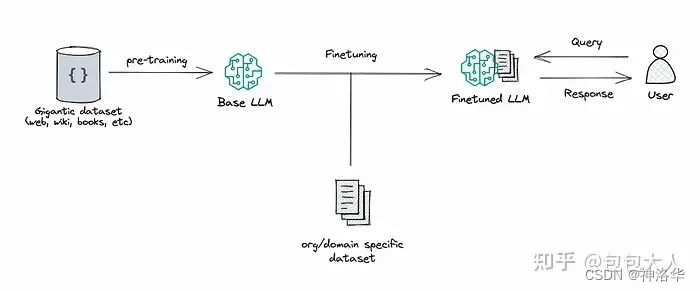
RAG(检索增强生成):R是retrievel,A是augment增强,G是generation生成,将检索(或搜索)的能力集成到LLM文本生成中。它结合了一个检索系统和一个LLM,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。具体本赛题来说,就是使用题目和选项去召回维基百科相关的文档,拼接在要回答的题目上。RAG简要过程如下:
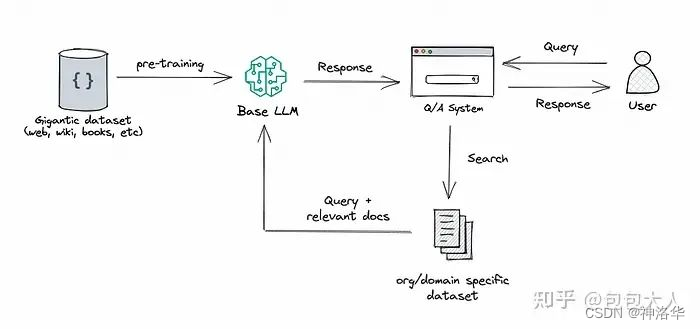
在外部知识要求高的情况下,优先RAG,需要模型适配(风格行为词汇)等,就需要微调,两者要求都高的话,需要结合使用。
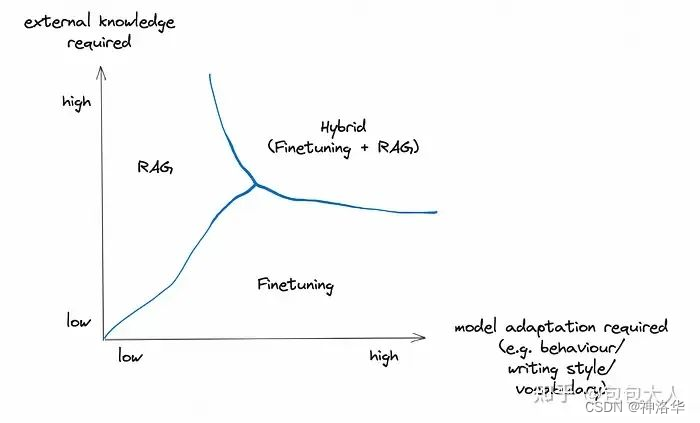
关于具体的召回技术,主要有向量+fasiss召回,tfidf相似度矩阵乘法,BM25等。第[19th Privat]给了一个非大模型方案RAG流程比较清楚的图:

4.1 New 270K Wikipedia STEM articles
很多其他人分享的检索式代码都使用相对较小的文本编码器,这些编码器在处理文章时可能性能较差。同时,考虑到所有的问题都是关于科学、技术、工程和数学(STEM)等主题的,我们是否真的需要在整个维基百科上进行检索,是否存在一些文章集合,其中包含了绝大多数所需的信息?
在《Finding 270K Wikipedia STEM articles!》中,作者基于上一章中的train_pages(用于生成训练集数据的154篇维基百科文章列表),以半监督的方式对维基百科文章进行KMeans聚类来获取 270K 维基百科 STEM 文章,发布在《STEM wikipedia subset based on Cohere embeddings》。
然而,由于 WikiExtractor 的问题,在某些情况下,最终的 Wiki 解析中会丢失一些数字甚至段落,这降低了检索增强模型的性能。因此,对于同一组文章,作者使用 Wiki API 来收集文章的上下文,然后发布了新的数据集《270K Wikipedia STEM articles》,可以使用使用 datasets.load_from_disk() 方法来加载数据。
4.2 270K articles+LongFormer Large(2610s,LB=0.862)
- 《with only 270K articles!》及其赛事区讨论
- Sentence Transformers:使用 BERT & Co 的多语言句子、段落和图像嵌入,Sentence Transformers文档
4.2.1 导入依赖库,使用OpenBook方法预测结果
# 离线安装必要的库
!pip install -U /kaggle/input/faiss-gpu-173-python310/faiss_gpu-1.7.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
!cp -rf /kaggle/input/sentence-transformers-222/sentence-transformers /kaggle/working/sentence-transformers
!pip install -U /kaggle/working/sentence-transformers
!pip install -U /kaggle/input/blingfire-018/blingfire-0.1.8-py3-none-any.whl!pip install --no-index --no-deps /kaggle/input/llm-whls/transformers-4.31.0-py3-none-any.whl
!pip install --no-index --no-deps /kaggle/input/llm-whls/peft-0.4.0-py3-none-any.whl
!pip install --no-index --no-deps /kaggle/input/llm-whls/trl-0.5.0-py3-none-any.whl
!cp /kaggle/input/datasets-wheel/datasets-2.14.4-py3-none-any.whl /kaggle/working
!pip install /kaggle/working/datasets-2.14.4-py3-none-any.whl
!cp /kaggle/input/backup-806/util_openbook.py .
import pickle,gc
from util_openbook import get_contexts, generate_openbook_outputget_contexts()
generate_openbook_output()gc.collect()
这一步是执行util_openbook.py中的两个函数:
get_contexts():使用faiss对测试集的prompt进行向量检索,检索出最相似的维基百科上下文contentgenerate_openbook_output():将content与prompt合并,再使用llm-science-run-context-2模型进行解码和推理,结果处理成比赛要求的格式,保存到submission_backup.csv文件中。
整个util_openbook.py其实就是 《Sharing my trained-with-context model》的代码,top public LB=0.807。我在《Kaggle - LLM Science Exam(二):Open Book QA&debertav3-large详解》中对代码进行了详细的解读,可供参考。
import os
import numpy as np
import pandas as pd
from datasets import load_dataset, load_from_disk
from sklearn.feature_extraction.text import TfidfVectorizer
import torch
from transformers import LongformerTokenizer, LongformerForMultipleChoice
import transformers
import matplotlib.pyplot as plt
from tqdm import tqdm
import unicodedatabackup_model_predictions = pd.read_csv("submission_backup.csv")
backup_model_predictions.head()
id prediction
0 0 D B E
1 1 A B D
2 2 A C D
3 3 C E D
4 4 D A B
!cp -r /kaggle/input/stem-wiki-cohere-no-emb /kaggle/working
!cp -r /kaggle/input/all-paraphs-parsed-expanded /kaggle/working/
4.2.2 检索相关文档
import unicodedata
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from datasets import load_from_disk
from tqdm import tqdm# 函数1:将列表分割成指定大小的块
def SplitList(mylist, chunk_size):"""将输入的列表分割成大小为chunk_size的块。参数:mylist (list): 要分割的列表。chunk_size (int): 块的大小。返回值:list of lists: 包含分割后块的列表。"""return [mylist[offs:offs+chunk_size] for offs in range(0, len(mylist), chunk_size)]# 函数2:获取相关文档的解析内容
def get_relevant_documents_parsed(df_valid):"""根据df_valid获取相关文档的解析内容。参数:df_valid (DataFrame): 包含有效数据的数据框架。返回值:list of lists: 包含相关文档的解析内容的列表。"""# 指定数据框架切块大小df_chunk_size = 600# 从磁盘加载已解析的语料库数据集paraphs_parsed_dataset = load_from_disk("/kaggle/working/all-paraphs-parsed-expanded")# 从语料库数据集中提取并修改文本modified_texts = paraphs_parsed_dataset.map(lambda example:{'temp_text':f"{example['title']} {example['section']} {example['text']}".replace('\n'," ").replace("'","")},num_proc=2)["temp_text"]# 初始化用于存储结果的空列表all_articles_indices = []all_articles_values = []# 使用 tqdm 创建一个进度条,遍历整个数据框架,按照指定的切块大小进行迭代for idx in tqdm(range(0, df_valid.shape[0], df_chunk_size)):# 从数据框架中获取当前切块的子集df_valid_ = df_valid.iloc[idx: idx+df_chunk_size]# 调用 retrieval 函数,获取相关文章的索引和分数articles_indices, merged_top_scores = retrieval(df_valid_, modified_texts)# 将当前切块的结果添加到相应的列表中all_articles_indices.append(articles_indices)all_articles_values.append(merged_top_scores)# 将各个切块的结果合并成单个数组article_indices_array = np.concatenate(all_articles_indices, axis=0)articles_values_array = np.concatenate(all_articles_values, axis=0).reshape(-1)# 计算每个查询的相关文章数目top_per_query = article_indices_array.shape[1]# 重塑结果,使其适合输出格式articles_flatten = [(articles_values_array[index],paraphs_parsed_dataset[idx.item()]["title"],paraphs_parsed_dataset[idx.item()]["text"],)for index,idx in enumerate(article_indices_array.reshape(-1))]# 使用 SplitList 函数将结果分割成适当的块并返回retrieved_articles = SplitList(articles_flatten, top_per_query)return retrieved_articles# 函数3:获取相关文档
def get_relevant_documents(df_valid):"""根据有效数据框架df_valid获取相关文档。参数:df_valid (DataFrame): 包含有效数据的数据框架。返回值:list of lists: 包含相关文档的列表。"""# 指定数据框架切块大小df_chunk_size = 800# 从磁盘加载已过滤的语料库数据集cohere_dataset_filtered = load_from_disk("/kaggle/working/stem-wiki-cohere-no-emb")# 从语料库数据集中提取并修改文本modified_texts = cohere_dataset_filtered.map(lambda example:{'temp_text':unicodedata.normalize("NFKD", f"{example['title']} {example['text']}").replace('"',"")},num_proc=2)["temp_text"]# 初始化用于存储结果的空列表all_articles_indices = []all_articles_values = []# 使用 tqdm 创建一个进度条,遍历整个数据框架,按照指定的切块大小进行迭代for idx in tqdm(range(0, df_valid.shape[0], df_chunk_size)):# 从数据框架中获取当前切块的子集df_valid_ = df_valid.iloc[idx: idx+df_chunk_size]# 调用 retrieval 函数,获取相关文章的索引和分数articles_indices, merged_top_scores = retrieval(df_valid_, modified_texts)# 将当前切块的结果添加到相应的列表中all_articles_indices.append(articles_indices)all_articles_values.append(merged_top_scores)# 将各个切块的结果合并成单个数组article_indices_array = np.concatenate(all_articles_indices, axis=0)articles_values_array = np.concatenate(all_articles_values, axis=0).reshape(-1)# 计算每个查询的相关文章数目top_per_query = article_indices_array.shape[1]# 重塑结果,使其适合输出格式articles_flatten = [(articles_values_array[index],cohere_dataset_filtered[idx.item()]["title"],unicodedata.normalize("NFKD", cohere_dataset_filtered[idx.item()]["text"]),)for index,idx in enumerate(article_indices_array.reshape(-1))]# 使用 SplitList 函数将结果分割成适当的块并返回retrieved_articles = SplitList(articles_flatten, top_per_query)return retrieved_articles# 函数4:检索相关文档
def retrieval(df_valid, modified_texts):"""根据df_valid和修改后的文本获取相关文档。参数:df_valid (DataFrame): 包含有效数据的数据框架。modified_texts (list): 修改后的文本列表。返回值:tuple: 包含相关文档的索引和分数的元组。""" corpus_df_valid = df_valid.apply(lambda row:f'{row["prompt"]}\n{row["prompt"]}\n{row["prompt"]}\n{row["A"]}\n{row["B"]}\n{row["C"]}\n{row["D"]}\n{row["E"]}',axis=1).values# 创建一个 TfidfVectorizer 对象,用于计算 TF-IDF 特征vectorizer1 = TfidfVectorizer(ngram_range=(1,2),token_pattern=r"(?u)\b[\w/.-]+\b|!|/|\?|\"|\'",stop_words=stop_words)# 用语料库内容拟合第一个 vectorizervectorizer1.fit(corpus_df_valid)vocab_df_valid = vectorizer1.get_feature_names_out()# 创建另一个 TfidfVectorizer 对象,用于计算修改后文本的 TF-IDF 特征vectorizer = TfidfVectorizer(ngram_range=(1,2),token_pattern=r"(?u)\b[\w/.-]+\b|!|/|\?|\"|\'",stop_words=stop_words,vocabulary=vocab_df_valid)# 用修改后文本的前 500,000 个条目拟合第二个 vectorizervectorizer.fit(modified_texts[:500000])# 计算语料库和修改后文本的 TF-IDF 矩阵corpus_tf_idf = vectorizer.transform(corpus_df_valid)# 打印 vectorizer 词汇表的长度print(f"vectorizer 词汇长度为 {len(vectorizer.get_feature_names_out())}")# 定义块的大小、每块的前N个最高分数以及每个查询的前N个最高分数chunk_size = 100000top_per_chunk = 10top_per_query = 10# 初始化存储每个块的顶部索引和值的列表all_chunk_top_indices = []all_chunk_top_values = []# 使用 tqdm 创建一个进度条,遍历修改后文本并按块处理for idx in tqdm(range(0, len(modified_texts), chunk_size)):# 从修改后文本中提取当前块的向量wiki_vectors = vectorizer.transform(modified_texts[idx: idx+chunk_size])# 计算每个查询的临时分数temp_scores = (corpus_tf_idf * wiki_vectors.T).toarray()# 找到每个查询的前N个最高分数的索引chunk_top_indices = temp_scores.argpartition(-top_per_chunk, axis=1)[:, -top_per_chunk:]# 提取每个查询的前N个最高分数chunk_top_values = temp_scores[np.arange(temp_scores.shape[0])[:, np.newaxis], chunk_top_indices]# 将当前块的顶部索引和值添加到相应的列表中all_chunk_top_indices.append(chunk_top_indices + idx)all_chunk_top_values.append(chunk_top_values)# 将所有块的顶部索引和值合并成单个数组top_indices_array = np.concatenate(all_chunk_top_indices, axis=1)top_values_array = np.concatenate(all_chunk_top_values, axis=1)# 对合并的顶部值进行排序,仅保留每个查询的前N个最高分数merged_top_scores = np.sort(top_values_array, axis=1)[:,-top_per_query:]# 找到每个查询的前N个最高分数的索引merged_top_indices = top_values_array.argsort(axis=1)[:,-top_per_query:]# 构建文章索引数组,以获取相关文章的索引articles_indices = top_indices_array[np.arange(top_indices_array.shape[0])[:, np.newaxis], merged_top_indices]# 返回相关文章的索引和分数return articles_indices, merged_top_scores
上述函数用来检索与测试集问答数据相关的文档,下面逐一分解这些函数及其用途:
-
SplitList(mylist, chunk_size): 将列表分割成指定大小(chunk_size)的较小块,最终返回一个包含列表块的列表。 -
get_relevant_documents_parsed(df_valid): 这个函数以一个DataFrame(df_valid)作为输入,检索一组问题的相关文章:- 加载"paraphs_parsed_dataset"数据集,包含经过预处理的文本信息。
- 它通过连接标题、章节和文本字段以及删除换行符和单引号来修改"paraphs_parsed_dataset"中的文本。
- 它初始化空列表以存储文章索引和值。
- 它按照大小为
df_chunk_size的块迭代DataFramedf_valid,其中每个块代表一组问题。对于每个问题块,它使用检索函数retrieval获得的文章索引和值,并附加到相应的列表。 - 处理完所有块后,它将文章索引和值连接成数组,并将结果格式化为一系列相关文章的列表。
- 函数返回相关文章的列表。
-
get_relevant_documents(df_valid): 这个函数类似于get_relevant_documents_parsed,但它加载不同的数据集(“cohere_dataset_filtered”)并使用不同的文本预处理方法。 -
retrieval(df_valid, modified_texts): 这个函数执行基于问题和预处理文本的实际文档检索。以下是其功能的详细说明:- 它准备了一个TF-IDF矢量化器,并根据指定的参数在预处理文本上进行拟合。
- 它计算了
df_valid中问题的TF-IDF向量。 - 它将TF-IDF计算划分为大小为
chunk_size的块,并分别处理每个块。 - 对于每个块,它计算问题的TF-IDF向量与预处理文本的TF-IDF向量之间的余弦相似性分数。
- 它选择具有最高相似性分数的每个问题的前文档。
- 它返回所选文章的索引以及相应的相似性分数。
最后,当调用get_relevant_documents_parsed(df_valid)时,它通过利用上述函数来检索 与df_valid中的问题相关的文章。针对df_valid中的每组问题,这些文章被组织成块。
stop_words = ['each', 'you', 'the', 'use', 'used','where', 'themselves', 'nor', "it's", 'how', "don't", 'just', 'your','about', 'himself', 'with', "weren't", 'hers', "wouldn't", 'more', 'its', 'were','his', 'their', 'then', 'been', 'myself', 're', 'not','ours', 'will', 'needn', 'which', 'here', 'hadn', 'it', 'our', 'there', 'than','most', "couldn't", 'both', 'some', 'for', 'up', 'couldn', "that'll","she's", 'over', 'this', 'now', 'until', 'these', 'few', 'haven','of', 'wouldn', 'into', 'too', 'to', 'very', 'shan', 'before', 'the', 'they','between', "doesn't", 'are', 'was', 'out', 'we', 'me','after', 'has', "isn't", 'have', 'such', 'should', 'yourselves', 'or', 'during', 'herself','doing', 'in', "shouldn't", "won't", 'when', 'do', 'through', 'she','having', 'him', "haven't", 'against', 'itself', 'that','did', 'theirs', 'can', 'those','own', 'so', 'and', 'who', "you've", 'yourself', 'her', 'he', 'only','what', 'ourselves', 'again', 'had', "you'd", 'is', 'other','why', 'while', 'from', 'them', 'if', 'above', 'does', 'whom','yours', 'but', 'being', "wasn't", 'be']
训练集和测试集的数据是一样的,只是测试集没有标签而已。
train_df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/train.csv")
test_df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/test.csv")
train_df.iloc[:,:7].equals(test_df)
True
retrieved_articles_parsed = get_relevant_documents_parsed(test_df)try:with open("retrieved_articles_parsed.pkl", "wb") as pickle_file:pickle.dump(retrieved_articles_parsed, pickle_file)print('保存retrieved_articles_parsed成功')
except Exception as e:# 捕获异常并打印错误信息print("保存retrieved_articles_parsed出错:", str(e))gc.collect()
retrieved_articles_parsed[0]
# 一共10篇相关文章及其标题和分数
[(0.3126188353233343,'Modified Newtonian dynamics','Several independent observations point to the fact that the visible mass in galaxies and galaxy clusters is insufficient to account for their dynamics, when analyzed using Newton\'s laws. This discrepancy – known as the "missing mass problem" – was first identified for clusters by Swiss astronomer Fritz Zwicky in 1933 (who studied the Coma cluster), and subsequently extended to include spiral galaxies by the 1939 work of Horace Babcock on Andromeda.These early studies were augmented and brought to the attention of the astronomical community in the 1960s and 1970s by the work of Vera Rubin at the Carnegie Institute in Washington, who mapped in detail the rotation velocities of stars in a large sample of spirals. While Newton\'s Laws predict that stellar rotation velocities should decrease with distance from the galactic centre, Rubin and collaborators found instead that they remain almost constant – the rotation curves are said to be "flat". This observation necessitates at least one of the following: Option (1) leads to the dark matter hypothesis; option (2) leads to MOND.'),(0.3153668078674981,'Atom','Up to 95% of the Milky Way\'s baryonic matter are concentrated inside stars, where conditions are unfavorable for atomic matter. The total baryonic mass is about 10% of the mass of the galaxy; the remainder of the mass is an unknown dark matter. High temperature inside stars makes most "atoms" fully ionized, that is, separates all electrons from the nuclei. In stellar remnants—with exception of their surface layers—an immense pressure make electron shells impossible.'),
...
...
]
retrieved_articles = get_relevant_documents(test_df)
try:with open("retrieved_articles.pkl", "wb") as pickle_file:pickle.dump(retrieved_articles, pickle_file)print('保存retrieved_articles成功')
except Exception as e:# 捕获异常并打印错误信息print("保存retrieved_articles出错:", str(e))
gc.collect()
retrieved_articles[0]
# 一共10篇相关文章及其标题和分数
[(0.2950371392568642,'Intracluster medium','Measurements of the temperature and density profiles in galaxy clusters allow for a determination of the mass distribution profile of the ICM through hydrostatic equilibrium modeling. The mass distributions determined from these methods reveal masses that far exceed the luminous mass seen and are thus a strong indication of dark matter in galaxy clusters.'),(0.29527605466122714,'Modified Newtonian dynamics',"Several other studies have noted observational difficulties with MOND. For example, it has been claimed that MOND offers a poor fit to the velocity dispersion profile of globular clusters and the temperature profile of galaxy clusters, that different values of a are required for agreement with different galaxies' rotation curves, and that MOND is naturally unsuited to forming the basis of cosmology. Furthermore, many versions of MOND predict that the speed of light is different to the speed of gravity, but in 2017 the speed of gravitational waves was measured to be equal to the speed of light to high precision. This is well understood in modern relativistic theories of MOND, with the constraint from gravitational waves actually helping by substantially restricting how a covariant theory might be constructed."),
...
...
]
# 1. 加载相似文章,用于评测
with open("/kaggle/input/retrieved-articles/retrieved_articles/retrieved_articles_parsed.pkl", "rb") as pickle_file:retrieved_articles_parsed = pickle.load(pickle_file)print('加载retrieved_articles_parsed成功')with open("/kaggle/input/retrieved-articles/retrieved_articles/retrieved_articles.pkl", "rb") as pickle_file:retrieved_articles = pickle.load(pickle_file)print('加载retrieved_articles成功')# 2. 加载训练集、测试集
train_df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/train.csv")
test_df = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/test.csv")
4.2.3 定义预处理函数和评测指标
下面的函数,是将之前检索的相似文档context和每个测试样本的question进行合并,再复制5次得到c_plus_q_5,对应五个问题选项。然后解码c_plus_q_5和options(都是长为5的列表),最后只保留input_ids和attention_mask。
def prepare_answering_input(tokenizer, question, options, context, max_seq_length=4096,):"""准备用于回答问题的输入编码,包括问题、选项、上下文等信息。参数:tokenizer (Tokenizer): 用于对文本进行分词和编码的分词器。question (str): 表示问题的文本。options (list of str): 包含问题的选项的文本列表。context (str): 包含问题和选项上下文的文本。max_seq_length (int, optional): 输入编码的最大序列长度。默认为 4096。返回值:dict: 包含编码输入的字典,包括输入的ID和注意力掩码。注意:此函数用于将问题、选项和上下文组合成一个输入编码,以供后续用于问题回答任务。"""# 组合相似文档与问题,中间用特殊字符隔开c_plus_q = context + ' ' + tokenizer.bos_token + ' ' + question# 复制组合字符串5次,以匹配答案选项的数量c_plus_q_5 = [c_plus_q] * len(options)# 使用分词器对组合字符串和选项进行编码tokenized_examples = tokenizer(c_plus_q_5, options,max_length=max_seq_length,padding="longest",truncation=False,return_tensors="pt",)# 提取编码后的输入ID和注意力掩码input_ids = tokenized_examples['input_ids'].unsqueeze(0)attention_mask = tokenized_examples['attention_mask'].unsqueeze(0)# 构建包含输入编码的字典example_encoded = {"input_ids": input_ids.to(model.device.index),"attention_mask": attention_mask.to(model.device.index),}# 返回编码后的输入return example_encoded
def map_at_3(predictions, labels):map_sum = 0pred = [np.argsort(-np.array(prob))[:3] for prob in predictions]for x,y in zip(pred,labels):z = [1/i if y==j else 0 for i,j in zip([1,2,3],x)]map_sum += np.sum(z)return map_sum / len(predictions)
4.2.4 推理
test_df.head()

def predict(df,prepare):probability = [] # 预测结果(概率)submit_ids = [] # 索引result = [] # 预测标签 for index in tqdm(range(df.shape[0])):columns = df.iloc[index].valuessubmit_ids.append(columns[0])question = columns[1]options = [columns[2], columns[3], columns[4], columns[5], columns[6]]# 测试集相似文章在articles_list列表第三个、第四个变量test_articles,test_articles_parsedcontext1 = "\n".join([retrieved_articles[index][-i][2] for i in range(4, 0, -1)])context2 = "\n".join([retrieved_articles_parsed[index][-i][2] for i in range(3, 0, -1)])inputs1 = prepare(tokenizer=tokenizer, question=question,options=options, context=context1,)inputs2 = prepare(tokenizer=tokenizer, question=question,options=options, context=context2,)with torch.no_grad():outputs1 = model(**inputs1) losses1 = -outputs1.logits[0].detach().cpu().numpy()probability1 = torch.softmax(torch.tensor(-losses1), dim=-1)with torch.no_grad():outputs2 = model(**inputs2)losses2 = -outputs2.logits[0].detach().cpu().numpy()probability2 = torch.softmax(torch.tensor(-losses2), dim=-1)probability_ = (probability1 + probability2)/2# 清除中间结果del probability1del probability2torch.cuda.empty_cache() # 释放GPU内存# 如果预测概率大于0.4就保留结果,否则采用backup_model_predictions中的预测结果,相当于集成两个模型的结果if probability_.max() > 0.4:predict = np.array(list("ABCDE"))[np.argsort(probability_)][-3:].tolist()[::-1]else:predict = backup_model_predictions.iloc[index].prediction.replace(" ","")probability.append(probability_)result.append(predict)return probability,result
from transformers import LongformerTokenizer, LongformerForMultipleChoice
model_dir="/kaggle/input/longformer-race-model/longformer_qa_model"tokenizer = LongformerTokenizer.from_pretrained(model_dir)
model = LongformerForMultipleChoice.from_pretrained(model_dir).cuda()
probability,result=predict(test_df,prepare_answering_input)result = [" ".join(i) for i in result]
pd.DataFrame({'id':train_df.id,'prediction':result}).to_csv('submission.csv', index=False)
submission_df = pd.read_csv('submission.csv')
submission_df
最终结果是0.862。
4.3 270K articles+DEBERTA v3 large(2396s,LB=0.905)
参考 《Fork of Fork of [86.2] with only 270K articles!》
与4.2相比,只改了两处:
- 预处理函数
- 模型
def prepare_answering_input(tokenizer, question, options, context, max_seq_length=1024,):c_plus_q = tokenizer.bos_token + ' ' + contextoptions = [' #### ' + question + " [SEP] " + opt for opt in options]# c_plus_q = context + ' ' + tokenizer.bos_token + ' ' + question # TODOc_plus_q_4 = [c_plus_q] * len(options)tokenized_examples = tokenizer(c_plus_q_4, options,max_length=max_seq_length,padding="longest",truncation='only_first',return_tensors="pt",add_special_tokens=False)input_ids = tokenized_examples['input_ids'].unsqueeze(0)attention_mask = tokenized_examples['attention_mask'].unsqueeze(0)example_encoded = {"input_ids": input_ids.to(model.device.index),"attention_mask": attention_mask.to(model.device.index),}return example_encoded
- 单模型
run-context-valid-loss得分0.896- 此作者在《Sharing my trained-with-context model》中发布了模型
llm-science-run-context-2,下面几个应该是作者炼的相似模型。
model_paths = [# r2, 0, 1, 2 = 81.5# 0, 1, 2 = 81.6# 0, 1, 2, 3, 4, 5 = 81.8# 0.02, 0.00, 0.08, 0.03, 0.00, 0.00, 0.31, 0.00, 0.01, 0.41, 0.13
# '/kaggle/input/llm-science-run-context-2', # 80.6
# '/kaggle/input/llm-science-run-context-3/fold_0', # 80.6'/kaggle/input/llm-science-run-context-3/fold_1', # 81.0
# # # # '/kaggle/input/llm-science-run-context-3/fold_2', # 79.9
# '/kaggle/input/llm-science-run-context-3/fold_3', # 80.1
# '/kaggle/input/llm-science-run-context-3/fold_4', # 80.0
# # # '/kaggle/input/llm-science-run-context-3/fold_5', # 79.8'/kaggle/input/llm-science-run-context-4/fold_0', # 81.8
# # # '/kaggle/input/llm-science-run-context-4/fold_1', # 79.9
# '/kaggle/input/llm-science-run-context-5/fold_0', # 81.3'/kaggle/input/run-context-valid-loss',
# '/kaggle/input/run-context2-valid-loss',# '/kaggle/input/llm-science-run-context-5/fold_1',
# '/kaggle/input/run-context-all-mpnet-base-v2-map3/0',
# '/kaggle/input/run-context-all-mpnet-base-v2-loss/0',
# '/kaggle/input/run-context-all-mpnet-base-v2-valid-loss',
]
all_probs = []
for model_path in model_paths:probs = []tokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModelForMultipleChoice.from_pretrained(model_path).cuda()for index in tqdm(range(df_valid.shape[0])):columns = df_valid.iloc[index].valuesquestion = columns[1]options = [columns[2], columns[3], columns[4], columns[5], columns[6]]context1 = '\n'.join([retrieved_articles[index][-1-i][2] for i in range(10)])context2 = '\n'.join([retrieved_articles_parsed[index][-1-i][2] for i in range(10)])inputs1 = prepare_answering_input(tokenizer=tokenizer, question=question,options=options, context=context1,)inputs2 = prepare_answering_input(tokenizer=tokenizer, question=question,options=options, context=context2,)with torch.no_grad():outputs1 = model(**inputs1) losses1 = -outputs1.logits[0].detach().cpu().numpy()probability1 = torch.softmax(torch.tensor(-losses1), dim=-1)with torch.no_grad():outputs2 = model(**inputs2)losses2 = -outputs2.logits[0].detach().cpu().numpy()probability2 = torch.softmax(torch.tensor(-losses2), dim=-1)probability_ = (probability1 + probability2*1.7)/2# probability_ = (probability1 + probability2)/2probs.append(probability_)all_probs.append(probs)
all_preds = np.stack([np.stack(prbs) for prbs in all_probs])
all_preds = softmax(all_preds, axis=2)
# best_weights = np.array([1, 1, 1.5])
# predictions = np.average(all_preds, axis=0, weights=best_weights)
predictions = all_preds.mean(0)
predictions_as_ids = np.argsort(-predictions, 1)
predictions_as_answer_letters = np.array(list('ABCDE'))[predictions_as_ids]
predictions_as_string = df_valid['prediction'] = [' '.join(row) for row in predictions_as_answer_letters[:, :3]
]submission = df_valid[['id', 'prediction']]
submission.to_csv('submission.csv', index=False)
4.4 RAPIDS TF-IDF+DEBERTA v3 large(756s,LB=0.904)
参考《RAPIDS TF-IDF - [LB 0.904] - Single Model》
作者基于4.2进行以下改动:
- 不需要运行util_openbook.py,即不需要backup_model_predictions
- 模型改为方法9: 《How To Train Open Book Model - Part 1》中训练的模型
DEBERTA v3 large,模型权重见how-to-train-open-book-model-part-1。 - 采用 RAPIDS TF-IDF,加速检索
- 使用2xT4 GPU 和双线程加速推理
4.4.1 环境配置
import os
os.system("cp /kaggle/input/datasets-wheel/datasets-2.14.4-py3-none-any.whl /kaggle/working")
os.system("pip install /kaggle/working/datasets-2.14.4-py3-none-any.whl")
os.system("pip install --no-index --no-deps /kaggle/input/llm-whls/transformers-4.31.0-py3-none-any.whl")os.system("cp -r /kaggle/input/stem-wiki-cohere-no-emb /kaggle/working")
os.system("cp -r /kaggle/input/all-paraphs-parsed-expanded /kaggle/working/")
import numpy as np, pickle
import pandas as pd, gc, os
from datasets import load_dataset, load_from_disk
import transformers, unicodedata, torch
import matplotlib.pyplot as plt
from tqdm import tqdmimport cudf
from cuml.feature_extraction.text import TfidfVectorizer_ = gc.collect()
print('Using RAPIDS version',cudf.__version__)
4.4.2 RAG Retrieval
def SplitList(mylist, chunk_size):return [mylist[offs:offs+chunk_size] for offs in range(0, len(mylist), chunk_size)]def get_relevant_documents_parsed(df_valid):df_chunk_size=600paraphs_parsed_dataset = load_from_disk("/kaggle/working/all-paraphs-parsed-expanded")modified_texts = paraphs_parsed_dataset.map(lambda example:{'temp_text':f"{example['title']} {example['section']} {example['text']}".replace('\n'," ").replace("'","")},num_proc=2)["temp_text"]all_articles_indices = []all_articles_values = []for idx in tqdm(range(0, df_valid.shape[0], df_chunk_size)):df_valid_ = df_valid.iloc[idx: idx+df_chunk_size]articles_indices, merged_top_scores = retrieval(df_valid_, modified_texts)all_articles_indices.append(articles_indices)all_articles_values.append(merged_top_scores)article_indices_array = np.concatenate(all_articles_indices, axis=0)articles_values_array = np.concatenate(all_articles_values, axis=0).reshape(-1)top_per_query = article_indices_array.shape[1]articles_flatten = [(articles_values_array[index],paraphs_parsed_dataset[idx.item()]["title"],paraphs_parsed_dataset[idx.item()]["text"],)for index,idx in enumerate(article_indices_array.reshape(-1))]retrieved_articles = SplitList(articles_flatten, top_per_query)return retrieved_articlesdef get_relevant_documents(df_valid):df_chunk_size=800cohere_dataset_filtered = load_from_disk("/kaggle/working/stem-wiki-cohere-no-emb")modified_texts = cohere_dataset_filtered.map(lambda example:{'temp_text':unicodedata.normalize("NFKD", f"{example['title']} {example['text']}").replace('"',"")},num_proc=2)["temp_text"]all_articles_indices = []all_articles_values = []for idx in tqdm(range(0, df_valid.shape[0], df_chunk_size)):df_valid_ = df_valid.iloc[idx: idx+df_chunk_size]articles_indices, merged_top_scores = retrieval(df_valid_, modified_texts)all_articles_indices.append(articles_indices)all_articles_values.append(merged_top_scores)article_indices_array = np.concatenate(all_articles_indices, axis=0)articles_values_array = np.concatenate(all_articles_values, axis=0).reshape(-1)top_per_query = article_indices_array.shape[1]articles_flatten = [(articles_values_array[index],cohere_dataset_filtered[idx.item()]["title"],unicodedata.normalize("NFKD", cohere_dataset_filtered[idx.item()]["text"]),)for index,idx in enumerate(article_indices_array.reshape(-1))]retrieved_articles = SplitList(articles_flatten, top_per_query)return retrieved_articlesdef retrieval(df_valid, modified_texts):corpus_df_valid = df_valid.apply(lambda row:f'{row["prompt"]}\n{row["prompt"]}\n{row["prompt"]}\n{row["A"]}\n{row["B"]}\n{row["C"]}\n{row["D"]}\n{row["E"]}',axis=1)#.values ###vectorizer1 = TfidfVectorizer(ngram_range=(1,2),#token_pattern=r"(?u)\b[\w/.-]+\b|!|/|\?|\"|\'", ###stop_words=stop_words,sublinear_tf=True)vectorizer1.fit(corpus_df_valid)vocab_df_valid = vectorizer1.get_feature_names() ###vectorizer = TfidfVectorizer(ngram_range=(1,2),#token_pattern=r"(?u)\b[\w/.-]+\b|!|/|\?|\"|\'", ###stop_words=stop_words,vocabulary=vocab_df_valid,sublinear_tf=True)vectorizer.fit( cudf.Series(modified_texts[:500000]) ) ###corpus_tf_idf = vectorizer.transform(corpus_df_valid)print(f"length of vectorizer vocab is {len(vectorizer.get_feature_names())}") ###chunk_size = 100000top_per_chunk = 10top_per_query = 10all_chunk_top_indices = []all_chunk_top_values = []for idx in tqdm(range(0, len(modified_texts), chunk_size)):wiki_vectors = vectorizer.transform( cudf.Series(modified_texts[idx: idx+chunk_size]) ) ###temp_scores = (corpus_tf_idf * wiki_vectors.T).toarray()chunk_top_indices = temp_scores.argpartition(-top_per_chunk, axis=1)[:, -top_per_chunk:]chunk_top_values = temp_scores[np.arange(temp_scores.shape[0])[:, np.newaxis], chunk_top_indices]all_chunk_top_indices.append(chunk_top_indices + idx)all_chunk_top_values.append(chunk_top_values)top_indices_array = np.concatenate(all_chunk_top_indices, axis=1)top_values_array = np.concatenate(all_chunk_top_values, axis=1)merged_top_scores = np.sort(top_values_array, axis=1)[:,-top_per_query:]merged_top_indices = top_values_array.argsort(axis=1)[:,-top_per_query:]articles_indices = top_indices_array[np.arange(top_indices_array.shape[0])[:, np.newaxis], merged_top_indices]return articles_indices, merged_top_scores
df_valid = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/test.csv")
retrieved_articles_parsed = get_relevant_documents_parsed(df_valid)
gc.collect()
retrieved_articles = get_relevant_documents(df_valid)
gc.collect()
# LIBRARIES TO CLEAN MEMORY
import ctypes
libc = ctypes.CDLL("libc.so.6")
_ = gc.collect()
libc.malloc_trim(0)
4.4.3 定义预处理函数和评测指标
# FUNCTION TO PREPROCESS TEXT FOR INFER
def prepare_answering_input2(tokenizer, question, options, context, max_seq_length=4096,gpu_id = 0):c_plus_q = context[:2500] + ' #### ' + questionc_plus_q_4 = [c_plus_q] * len(options)tokenized_examples = tokenizer(c_plus_q_4, options,max_length=max_seq_length,padding="longest",truncation=False,return_tensors="pt",)input_ids = tokenized_examples['input_ids'].unsqueeze(0)attention_mask = tokenized_examples['attention_mask'].unsqueeze(0)example_encoded = {"input_ids": input_ids.to(devices[gpu_id]),"attention_mask": attention_mask.to(devices[gpu_id]),}return example_encoded
# https://www.kaggle.com/code/philippsinger/h2ogpt-perplexity-ranking
import numpy as np
def precision_at_k(r, k):"""Precision at k"""assert k <= len(r)assert k != 0return sum(int(x) for x in r[:k]) / kdef MAP_at_3(predictions, true_items):"""Score is mean average precision at 3"""U = len(predictions)map_at_3 = 0.0for u in range(U):user_preds = predictions[u].split()user_true = true_items[u]user_results = [1 if item == user_true else 0 for item in user_preds]for k in range(min(len(user_preds), 3)):map_at_3 += precision_at_k(user_results, k+1) * user_results[k]return map_at_3 / U
4.4.4 双线程推理
from transformers import AutoTokenizer
from transformers import AutoModelForMultipleChoice
from torch.cuda.amp import autocast
import threading, torchdevice0 = torch.device("cuda:0")
device1 = torch.device("cuda:1")model_paths = ["/kaggle/input/model-v181"
]
loss_results = []
for model in model_paths:print('#'*25)print('=> Inferring',model)tokenizer = AutoTokenizer.from_pretrained(model)model0 = AutoModelForMultipleChoice.from_pretrained(model).to(device0)model1 = AutoModelForMultipleChoice.from_pretrained(model).to(device1)models = [model0,model1]devices = [device0,device1]all_losses = [[],[]]submit_ids = [[],[]]# Create a lock to synchronize the threadslock = threading.Lock()# Define a function for inferencedef inference_thread(gpu_id, lock):with lock:print(f"Thread {gpu_id} started on GPU {gpu_id}")# INPUT DATA SPLIT 2xSKIP = df_valid.shape[0]//2SIZE = df_valid.shape[0] - SKIPif gpu_id == 0:SIZE = SKIPSKIP = 0LOOPER = range(SIZE)if gpu_id==0: LOOPER = tqdm(range(SIZE))# INFERENCE LOOPfor index in LOOPER:columns = df_valid.iloc[index+SKIP].valuessubmit_ids[gpu_id].append(columns[0])question = columns[1]options = [columns[2], columns[3], columns[4], columns[5], columns[6]]contexts = [ retrieved_articles[index+SKIP][x][2] for x in [-1,-2,-3] ]context1 = '\n'.join(contexts)contexts = [ retrieved_articles_parsed[index+SKIP][x][2] for x in [-3,-2,-1] ]context2 = '\n'.join(contexts)inputs1 = prepare_answering_input2(tokenizer=tokenizer, question=question,options=options, context=context1,gpu_id = gpu_id)inputs2 = prepare_answering_input2(tokenizer=tokenizer, question=question,options=options, context=context2,gpu_id = gpu_id)with torch.no_grad():with autocast():outputs1 = models[gpu_id](**inputs1)losses1 = -outputs1.logits[0].detach().cpu().numpy()with torch.no_grad():with autocast():outputs2 = models[gpu_id](**inputs2)losses2 = -outputs2.logits[0].detach().cpu().numpy()all_losses[gpu_id].append( (losses1+losses2)/2. )with lock:print(f"Thread {gpu_id} finished on GPU {gpu_id}")# Create two threads for inferencethread1 = threading.Thread(target=inference_thread, args=(0, lock))thread2 = threading.Thread(target=inference_thread, args=(1, lock))# Start the threadsthread1.start()thread2.start()# Wait for both threads to finishthread1.join()thread2.join()print("Both threads have finished.")print()all_losses[0] = np.vstack( all_losses[0] )all_losses[1] = np.vstack( all_losses[1] )all_losses = np.concatenate(all_losses,axis=0)loss_results.append( all_losses )submit_ids = submit_ids[0] + submit_ids[1]# CLEAN MEMORYdel model0, model1, models_ = gc.collect()libc.malloc_trim(0)
4.4.5 评测结果并保存
all_losses = np.mean( loss_results,axis=0 )
predictions_as_ids = np.argsort(all_losses, 1)
predictions_as_answer_letters = np.array(list('ABCDE'))[predictions_as_ids]
predict = predictions_as_answer_letterspredictions = []
for row in predict:predictions.append( ' '.join(row[:3]) )pd.DataFrame({'id':submit_ids,'prediction':predictions}).to_csv('submission.csv', index=False)plt.hist( all_losses.flatten(), bins=100 )
plt.title('Logit Histogram of Test Predictions')
plt.show()

submission = pd.read_csv('submission.csv')
print( submission.shape )
submission.head()
id prediction
0 0 D E B
1 1 A B D
2 2 D A C
3 3 A C B
4 4 D A B
计算MAP@3指标
if len(submission)==200:true = pd.read_csv('/kaggle/input/kaggle-llm-science-exam/train.csv', usecols=['answer'])print('CV MAP@3 =', MAP_at_3(submission.prediction.values, true.answer.values) )
CV MAP@3 = 0.9866666666666666