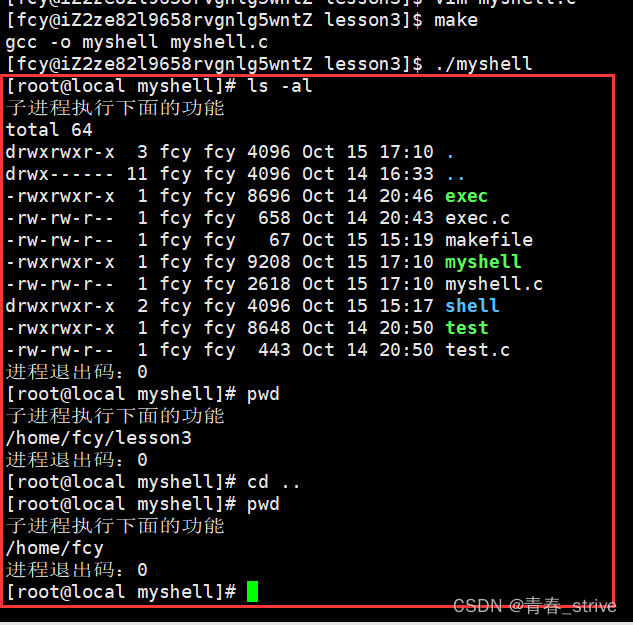
STL O(mn)
C++中提供子串查询的函数可以使用std::string类的相关方法来实现。
find函数:可以查找一个子串在原字符串中的第一个出现位置。它返回子串的起始索引,如果找不到则返回std::string::npos。substr函数:可以提取原字符串中的一个子串,根据起始位置和长度来确定子串的范围。compare函数:可以比较两个字符串是否相等或者大小关系
#include<bits/stdc++.h>
const int N=1e5+10;
signed main()
{std::string s1="hello world"; std::string s2="hello";//find函数 if(s1.find(s2)!=std::string::npos)//如果是子串 {std::cout<<"yes"<<'\n';}else{std::cout<<"no"<<'\n';}//substr提取子串std::string s3=s1.substr(0,5);std::cout<<s3<<'\n';//比较字符串大小关系if(s1.compare(s3)==0) // 字符串相等{std::cout<<"equl"<<'\n';}else if(s1.compare(s3)<0){// str1小于str2std::cout<<"s1 is less than s3"<<'\n';}else{ // str1大于str2std::cout<<"s3 is less than s1"<<'\n';} return 0;
}
find函数的时间复杂度取决于字符串的长度和待查找的子串的长度。在C++标准库中,std::string的find函数使用的是一种称为"Boyer-Moore-Horspool"算法的快速字符串搜索算法。在最坏情况下,算法的时间复杂度为O(mn),其中n是字符串的长度,m是待查找的子串的长度。这种情况发生在待查找的子串中的每个字符都与字符串进行了比较,但最终没有匹配成功。
时间复杂度是不如KMP的
KMP算法 O(m+n)
KMP算法是对暴力算法的优化
在暴力算法中我们定义两个指针i,j从0开始,
如果s[i]==x[j],则i++,j++
否则j=0(将子串移到开头,重新比较)
KMP算法则是在s[i]!=x[j]的情况下进行优化,如果不相等不将j移到0,而是根据预处理的结果来确定。
比如:
s BBC ABCDAB ABCDABCDABDE
x ABCDABD

比如到这一步时,x[j]!=s[i]
这是暴力做法:

这是KMP算法:

我们利用了ABCDAB中 后面的AB等于前面AB这一信息。
字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB"。我们需要学的就是如何利用这一信息。
n e [ i ] = j 的定义是p [ 1 , j ] = p [ i - j + 1 , i ]
对ne数组求解时,要牢抓定义
ne【1】=0,因此i从2开始计算,j从0开始,记录前后缀相等的最大长度
字符串匹配的KMP算法 - 阮一峰的网络日志 (ruanyifeng.com)
如果p【i】==p【j+1】,那么j++
否则j一直往前找,直到p【i】==p【j+1】
最后p【i】==p【j+1】,ne【i】=j
代码
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+10;
char p[N],s[N];
int m,n;
int ne[N];signed main()
{cin>>n>>p+1>>m>>s+1;for(int i=2,j=0;i<=n;i++){while(j&&p[i]!=p[j+1]) j=ne[j];if(p[i]==p[j+1]) j++;ne[i]=j; }for(int i=1,j=0;i<=m;i++){while(j&&s[i]!=p[j+1]) j=ne[j];if(s[i]==p[j+1]) j++;if(j==n){std::cout<<i-j<<" ";j=ne[j]; }}return 0;
}