文章目录
- 工具
- excel
- Tableau
- Power Query
- jupyter
- matplotlib
- numpy
- pandas
- 数据类型
- Series
- 基础的Series
- Series的字典操作
- 增加表的索引名字和表名字
- 索引操作
- DataFrame
- DataFrame 的基础使用
- DataFrame的列方法------理解
- DataFrame的行列方法------使用loc 与 iloc
- 对齐操作
- Series
- DataFrame
- 函数使用(np函数与lambda函数)
- 排序
- 索引排序
- 值排序
- NAN介绍
- 层级索引
- 简单介绍
- 如何根据索引拿到数据
- 索引操作(unstack swaplevel)
- 函数使用(计算)
- 分组聚合
- 分组-索引-自定义-类型
- 分组-字典
- 分组-函数
- 分组-索引级别
- 聚合
- 对于Series的聚合处理
- 分组后改别名-加前缀
- 索引再解
- 时间序列
- 降采样
- 连接查询
- 修改名称--column和index
- 连接查询
- 数据合并
- index不重复的时候
- index重复的情况
- 去重
- 数据替换
工具
excel
略
Tableau
略
Power Query
略
jupyter
见个人链接:30 数据分析(上)链接
matplotlib
见个人链接:30 数据分析(上)链接
numpy
见个人链接:31 数据分析(中)链接
pandas
numpy 已经能够帮助我们处理数据,能够结合 matplotlib 解决我们数据分析的问题,那么 pandas 学习的目的在什么地方呢?
- numpy 能够帮我们处理处理数值型数据,但是这还不够,很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等。
首先学习pandas,这边就默认已经学过了numpy,这边对于一些数据的相关处理,就不进行重复的介绍了。
数据类型
- float
- int
- bool
- datetime64[ns]
- datetime64[ns, tz]
- timedelta[ns]
- category
- object
默认的数据类型是 int64,float64. 判断数据类型是否为 int32,直接判断写出来的 dtype是不是等于’int32’。
Series
Pandas 有两个最主要也是最重要的数据结构: Series 和 DataFrame。
Series 是一种类似于一维数组的 对象,由一组数据(各种 NumPy 数据类型)以及一组(或者多组)与之对应的索引(数据标签)组成。
- 类似一维数组的对象
- 由数据和索引组成:索引(index)在左,数据(values)在右,不指定的话索引是自动创建的。
基础的Series
pd_array = pd.Series(range(10, 13))
print(pd_array)
print('-'*20)# 获取数据
print(pd_array.values)
print(type(pd_array.values))
# 获取索引
print(pd_array.index)
print(pd_array.index.dtype)
print('-'*20)# Series的取值操作 ------取数组操作,值得关注的是下面使用到的1实际上是那个index,而不是按照数组属性生成的
print(pd_array[1])
print('-'*20)# np_array和与常数的逻辑和算式运算 实际上就是广播运算
print(pd_array*2)
print(pd_array>11)
输出:
0 10
1 11
2 12
dtype: int64
--------------------
[10 11 12]
<class 'numpy.ndarray'>
RangeIndex(start=0, stop=3, step=1)
int64
--------------------
11
--------------------
0 20
1 22
2 24
dtype: int64
0 False
1 False
2 True
dtype: bool
Series的字典操作
# 字典变为series
pd_dict = {"小红": 20, "小明": 20.1, "小张": 16.5}
pd_array = pd.Series(pd_dict)
print(pd_array)
print(pd_array.index)
print(pd_array.values)
print(pd_array['小明']," ",pd_array[1])
输出:
小红 20.0
小明 20.1
小张 16.5
dtype: float64
Index(['小红', '小明', '小张'], dtype='object')
[20. 20.1 16.5]
20.1 20.1
增加表的索引名字和表名字
pd_array = pd.Series({"小红": 20, "小明": 20.1, "小张": 16.5})
print(pd_array)
print('-'*20)# 增加pd_array的表名字
pd_array.name = '表名字'
# 增加pd_array的索引列名字
pd_array.index.name = '索引列名字'
print(pd_array)
输出:
小红 20.0
小明 20.1
小张 16.5
dtype: float64
--------------------
索引列名字
小红 20.0
小明 20.1
小张 16.5
Name: 表名字, dtype: float64
索引操作
一般建议使用pd_array.loc[num1:num2]替代pd_array[num1:num2],效率更高,下面没有进行展示的原因就是方便理解
pd_array = pd.Series(range(5), index = list("abcde"))
print(pd_array)
print('-'*20)# 切片索引
print(pd_array['b':'d']) # 有取到d
print(pd_array[1:3]) # 没有取到d
print('-'*20)# 不连续索引
print(pd_array[[0,2]])
print(pd_array[['b','d']])
print('-'*20)# 逻辑索引
print(pd_array[pd_array>2])输出:
a 0
b 1
c 2
d 3
e 4
dtype: int64
--------------------
b 1
c 2
d 3
dtype: int64
b 1
c 2
dtype: int64
--------------------
a 0
c 2
dtype: int64
b 1
d 3
dtype: int64
--------------------
d 3
e 4
dtype: int64DataFrame
DataFrame 的基础使用
# 构建DataFrame的方法1 列表转DataFrame 列表内是一行一行的字典,也是一行一行属性
pd_dict =[{"name" : "xiaohong" ,"age" :32,"tel" :10010},{ "name": "xiaogang" ,"tel": 10000} ,{"name":"xiaowang" ,"age":22}]
pd_array=pd.DataFrame(pd_dict)
print(pd_array)
print('-'*20)# 构建DataFrame的方法2 字典转DataFrame 字典内
pd_dict = { 'A': 1,'B': pd.Timestamp('20231011'),'C': pd.Series(1, index=list(range(4)),dtype='float32'),'D': np.arange(4, dtype=np.int32),'E': ["Python","Java","C++","C"], }
pd_array = pd.DataFrame(pd_dict)
print(pd_array)
print('-'*20)# 列索引与行索引 列索引使用columns 行索引使用index
print(pd_array.index)
print(pd_array.columns)
输出:
name age tel
0 xiaohong 32.0 10010.0
1 xiaogang NaN 10000.0
2 xiaowang 22.0 NaN
--------------------A B C D E
0 1 2023-10-11 1.0 0 Python
1 1 2023-10-11 1.0 1 Java
2 1 2023-10-11 1.0 2 C++
3 1 2023-10-11 1.0 3 C
--------------------
Index([0, 1, 2, 3], dtype='int64')
Index(['A', 'B', 'C', 'D', 'E'], dtype='object')
DataFrame的列方法------理解
# 创建DataFrame的时候指定创建columns和index
dates = pd.date_range(start='20231011',periods=2)
print(dates)
pd_array = pd.DataFrame(np.arange(6).reshape(2,3),index=dates,columns=['A','B','C'])
print(pd_array)
print('-'*20)# 根据列名取数据
print(pd_array['A']) # 取出的是Series类型
print(pd_array[['A','B']])# 取出的是DataFrame类型
print('-'*20)# 新增一列
pd_array['D'] = 0
print(pd_array)
print('-'*20)# 删除一列
del pd_array['D']
print(pd_array)
输出:
DatetimeIndex(['2023-10-11', '2023-10-12'], dtype='datetime64[ns]', freq='D')A B C
2023-10-11 0 1 2
2023-10-12 3 4 5
--------------------
2023-10-11 0
2023-10-12 3
Freq: D, Name: A, dtype: int32A B
2023-10-11 0 1
2023-10-12 3 4
--------------------A B C D
2023-10-11 0 1 2 0
2023-10-12 3 4 5 0
--------------------A B C
2023-10-11 0 1 2
2023-10-12 3 4 5DataFrame的行列方法------使用loc 与 iloc
dates = pd.date_range(start='20231011',periods=2)
print(dates)
pd_array = pd.DataFrame(np.arange(6).reshape(2,3),index=dates,columns=['A','B','C'])
print(pd_array)
print('-'*20)# 建议的行列处理 loc是元素处理 和之前的一样取出一行或者一列的话就是Series 多的话就是DataFrame
print(pd_array.loc[pd.to_datetime('20231011'):pd.to_datetime('20231012'),['A','C']])
print('-'*20)# 建议的行列处理 iloc是位置处理 和之前的一样取出一行或者一列的话就是Series 多的话就是DataFrame
# 值得关注的是,和loc不一样的是loc的字母是左闭右闭,这里的数字是左闭右开
print(pd_array.iloc[0:1,[0,2]])
输出:
DatetimeIndex(['2023-10-11', '2023-10-12'], dtype='datetime64[ns]', freq='D')A B C
2023-10-11 0 1 2
2023-10-12 3 4 5
--------------------A C
2023-10-11 0 2
2023-10-12 3 5
--------------------A C
2023-10-11 0 2对齐操作
Series
s1 = pd.Series(range(10, 20), index = range(10))
s2 = pd.Series(range(20, 25), index = range(5))
# Series 对齐运算
print('s1+s2: ')
print(s1+s2)
print('-'*20)
print(s1.add(s2, fill_value = 0)) #未对齐的数据将和填充值做运算
输出:
s1+s2:
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
dtype: float64
--------------------
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 15.0
6 16.0
7 17.0
8 18.0
9 19.0
dtype: float64
DataFrame
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])
df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])
print(df1-df2)
print(df1.sub(df2, fill_value = 2.)) #未对齐的数据将和填充值做运算
输出:
a b c
0 0.0 0.0 NaN
1 0.0 0.0 NaN
2 NaN NaN NaNa b c
0 0.0 0.0 1.0
1 0.0 0.0 1.0
2 1.0 1.0 1.0函数使用(np函数与lambda函数)
pd_array = pd.DataFrame(np.random.randn(2,3) - 1)
print(pd_array)
print('-'*20)# 直接使用np的函数,np函数和pd的相兼容
print(np.abs(pd_array))
print('-'*20)# 使用apply作用到列或者行当中 axis=0 就是作用到列上 axis=1就是作用到行上
# 对于apply来说,每一次的输入就是一个一列或者一行的数据,也可以当成一列的列表
print(pd_array.apply(lambda x : x.max(),axis=0))
print(pd_array.apply(lambda x : x.max(),axis=1))
print('-'*20)# 作用到每一个数据上
print(pd_array.applymap(lambda x : x+1))
排序
索引排序
# 实际上都是使用sort_index进行排序的,区别就是是否加上axis轴
# Series
pd_array_ser = pd.Series(np.arange(3),index=np.random.randint(1,5,3))
print(pd_array_ser)
print(pd_array_ser.sort_index(ascending=True))
print(pd_array_ser.sort_index(ascending=False))
print('-'*20)# DataFrame
pd_array_data = pd.DataFrame(np.arange(9).reshape(3,3),index=np.random.randint(1,5,3),columns=np.random.randint(1,5,3))
print(pd_array_data)
print(pd_array_data.sort_index(axis=0))# 不写asc 默认是True 即升序
print(pd_array_data.sort_index(axis=1))输出:
1 0
2 1
4 2
dtype: int32
1 0
2 1
4 2
dtype: int32
4 2
2 1
1 0
dtype: int32
--------------------2 3 2
3 0 1 2
4 3 4 5
3 6 7 82 3 2
3 0 1 2
3 6 7 8
4 3 4 52 2 3
3 0 2 1
4 3 5 4
3 6 8 7值排序
# 按值排序,by后是第几列或者说第几行的意思,就是按值排序,也需要按哪列的值进行排序
# Series 和 DataFrame 使用方式也一致,唯一的区别还是一个有axis一个没有,这边就不举series的例子了。
pd_array = pd.DataFrame(np.arange(6).reshape(2,3),columns=['a','b','c'])
print(pd_array)
print('-'*20)# 按值排序 使用sort_value 不过值得关注的是by后只能加索引名称,并不能加上相应的位置
print(pd_array.sort_values(by='a',axis=0,ascending=False))
print(pd_array.sort_values(by=1,axis=1,ascending=False))
输出:
a b c
0 0 1 2
1 3 4 5
--------------------a b c
1 3 4 5
0 0 1 2c b a
0 2 1 0
1 5 4 3NAN介绍
pd_array = pd.DataFrame([np.random.randn(3), [1., 2., np.nan],[np.nan, 4., np.nan], [1., 2., 3.]])
print(pd_array)
print('-'*20)# 判断是否存在缺失值 isnull
print(pd_array.isnull())
print('-'*20)# 丢弃缺失数据 dropna 可选axis,默认0 即丢失列
print(pd_array.dropna(axis=0))
print(pd_array.dropna(axis=1))
print('-'*20)# 填充缺失数据 fillna
print(pd_array.iloc[:,0].fillna(-100.))
print('-'*20)# 当这一列存在nan的时候,这一列其实就可以当作是不存在的了。
for i in pd_array.columns:print(i)
输出:
0 1 2
0 1.441817 -0.679639 -1.077804
1 1.000000 2.000000 NaN
2 NaN 4.000000 NaN
3 1.000000 2.000000 3.000000
--------------------0 1 2
0 False False False
1 False False True
2 True False True
3 False False False
--------------------0 1 2
0 1.441817 -0.679639 -1.077804
3 1.000000 2.000000 3.0000001
0 -0.679639
1 2.000000
2 4.000000
3 2.000000
--------------------
0 1.441817
1 1.000000
2 -100.000000
3 1.000000
Name: 0, dtype: float64
--------------------
0
1
2
层级索引
简单介绍
# 层级索引这边先进行简单介绍一下,如果想要构建层级索引,就需要按照下面的形式建造二维数组用于给这个索引命名
index1 = pd.MultiIndex.from_arrays([['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]], names=['cloth', 'size'])pd_array = pd.Series(np.random.randn(12),index=index1)
print(pd_array)
print(pd_array.index)
# 索引的leves这边留意一下,后面的参数会用到,对应0就是对着abcd 对应1就是012
print(pd_array.index.levels)
print('-'*20)
输出:
cloth size
a 0 -1.5570441 0.9811772 -0.104191
b 0 0.3605881 -0.7082272 -1.231045
c 0 1.0827631 0.6387772 -0.170540
d 0 0.7408661 -2.0855192 0.528614
dtype: float64
MultiIndex([('a', 0),('a', 1),('a', 2),('b', 0),('b', 1),('b', 2),('c', 0),('c', 1),('c', 2),('d', 0),('d', 1),('d', 2)],names=['cloth', 'size'])
[['a', 'b', 'c', 'd'], [0, 1, 2]]如何根据索引拿到数据
index1 = pd.MultiIndex.from_arrays([['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]], names=['cloth', 'size'])pd_array = pd.Series(np.random.randn(12),index=index1)
print(pd_array)
print('-'*20)# 层级索引如何拿取数据 其实方式一样,就是第一个,前属于level0级的,第二个逗号前属于level1级的
print(pd_array.loc['c'],end='\n\n')
print(pd_array.loc['a', 2],end='\n\n')
print(pd_array.loc[:, 2])输出:
cloth size
a 0 -0.9071931 -0.3897692 -0.424191
b 0 -0.5330611 -0.9407062 -1.350291
c 0 -0.0492831 0.1617292 -0.917866
d 0 -1.7445011 -0.4381742 0.401031
dtype: float64
--------------------
size
0 -0.049283
1 0.161729
2 -0.917866
dtype: float64-0.4241907702192611cloth
a -0.424191
b -1.350291
c -0.917866
d 0.401031
dtype: float64
索引操作(unstack swaplevel)
index1 = pd.MultiIndex.from_arrays([['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2],[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,12]],names=['cloth', 'size','pp'])pd_array = pd.Series(np.random.randn(12),index=index1)
print(pd_array)
print('-'*20)# swaplevel交换索引 填写两个参数,就是交换的level,不写默认最外面两层也即-1和-2
print(pd_array.swaplevel(0,2))
print('-'*20)# 多层索引之排序
print(pd_array.sort_index(level=1))
print('-'*20)# unstack 将具有 MultiIndex 的 Unstack(也称为数据透视图)系列生成 DataFrame。涉及的级别将自动进行排序
# 或者说将最外层的索引从下面移到上面去,我们可以理解stack就是把index堆起来,unstack就是移开,移到最上面
# 不加参数默认level最大的也就是-1,加上参数就是移开对应层级
pd_array = pd_array.unstack()
print(pd_array)
print(pd_array.stack())
输出:
cloth size pp
a 0 1 -0.4487291 2 1.5403042 3 -0.684256
b 0 4 0.3047061 5 -1.0743042 6 0.422570
c 0 7 -0.5175811 8 1.1214392 9 -0.521546
d 0 10 0.9178761 11 -2.8723232 12 0.328800
dtype: float64
--------------------
pp size cloth
1 0 a -0.448729
2 1 a 1.540304
3 2 a -0.684256
4 0 b 0.304706
5 1 b -1.074304
6 2 b 0.422570
7 0 c -0.517581
8 1 c 1.121439
9 2 c -0.521546
10 0 d 0.917876
11 1 d -2.872323
12 2 d 0.328800
dtype: float64
--------------------
cloth size pp
a 0 1 -0.448729
b 0 4 0.304706
c 0 7 -0.517581
d 0 10 0.917876
a 1 2 1.540304
b 1 5 -1.074304
c 1 8 1.121439
d 1 11 -2.872323
a 2 3 -0.684256
b 2 6 0.422570
c 2 9 -0.521546
d 2 12 0.328800
dtype: float64
--------------------
pp 1 2 3 4 5 6 \
cloth size
a 0 -0.448729 NaN NaN NaN NaN NaN 1 NaN 1.540304 NaN NaN NaN NaN 2 NaN NaN -0.684256 NaN NaN NaN
b 0 NaN NaN NaN 0.304706 NaN NaN 1 NaN NaN NaN NaN -1.074304 NaN 2 NaN NaN NaN NaN NaN 0.42257
c 0 NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN 2 NaN NaN NaN NaN NaN NaN
d 0 NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN 2 NaN NaN NaN NaN NaN NaN pp 7 8 9 10 11 12
cloth size
a 0 NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN 2 NaN NaN NaN NaN NaN NaN
b 0 NaN NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN NaN 2 NaN NaN NaN NaN NaN NaN
c 0 -0.517581 NaN NaN NaN NaN NaN 1 NaN 1.121439 NaN NaN NaN NaN 2 NaN NaN -0.521546 NaN NaN NaN
d 0 NaN NaN NaN 0.917876 NaN NaN 1 NaN NaN NaN NaN -2.872323 NaN 2 NaN NaN NaN NaN NaN 0.3288
cloth size pp
a 0 1 -0.4487291 2 1.5403042 3 -0.684256
b 0 4 0.3047061 5 -1.0743042 6 0.422570
c 0 7 -0.5175811 8 1.1214392 9 -0.521546
d 0 10 0.9178761 11 -2.8723232 12 0.328800
dtype: float64函数使用(计算)

# 简单介绍
pd_array = pd.DataFrame(np.arange(6).reshape(2,3),columns=['a','b','c'])
pd_array.loc[1,'b']=np.nan
print(pd_array)
print('-'*20)# 基本上的计算函数都满足下面的这两个参数
print(pd_array.sum(axis=0))
print(pd_array.sum(axis=1, skipna=False))
print('-'*20)# info 和 describe需要重点记忆 info是这个dataframe的属性,比如这一列有多少个有效数据 对应的属性是什么
# describe就是将这一列常用的数据给你算出来
print(pd_array.info(),end='\n\n\n')
print('-'*20)
print(pd_array.describe())
输出:
a b c
0 0 1.0 2
1 3 NaN 5
--------------------
a 3.0
b 1.0
c 7.0
dtype: float64
0 3.0
1 NaN
dtype: float64
--------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2 entries, 0 to 1
Data columns (total 3 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 a 2 non-null int32 1 b 1 non-null float642 c 2 non-null int32
dtypes: float64(1), int32(2)
memory usage: 160.0 bytes
None--------------------a b c
count 2.00000 1.0 2.00000
mean 1.50000 1.0 3.50000
std 2.12132 NaN 2.12132
min 0.00000 1.0 2.00000
25% 0.75000 1.0 2.75000
50% 1.50000 1.0 3.50000
75% 2.25000 1.0 4.25000
max 3.00000 1.0 5.00000
分组聚合
分组-索引-自定义-类型
pd_dict = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],'key2' : ['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],'data1': np.random.randn(8),'data2': np.random.randn(8)}
pd_array = pd.DataFrame(pd_dict)
print(pd_array)
print('-'*20)# dataframe根据key1进行分组,分组之后实际上并不能进行输出,输出的仅仅只是类的名称,需要进行使用才有说法
# 值得关注的是print(pd_array.groupby('key1').mean())这样子为什么会报错,在新版本的pandas当中会直接报错
# 这边就是对于字符串进行了不正当的运算,所以会有问题,下面的就是对于分组求平均值的例子
# 与sql的group by 进行相关理解,这样子就好理解了
print(pd_array.loc[:,['key1','data1','data2']].groupby('key1').mean())
print('-'*20)# 自定义分组 size可以理解成count groupby也是有axis参数的
self_def_key = [0, 0, 2, 3, 3, 3, 5, 7]
print(pd_array.groupby(self_def_key).size())
print(pd_array.groupby([0,1,2,2],axis=1).sum())# 通过自定义分组使得两列数组进行相加的操作
print('-'*20)# 多层分组 这个是有顺序的差别的 这个groupby也是有axis参数的,这是值得关注的
print(pd_array.groupby(['key1','key2']).size())
print(pd_array.groupby(['key2','key1']).size())
print('-'*20)# 相同的为了方便我们还可以搭配上unstack进行使用,虽然看着也一般,也不是很好看hh
print(pd_array.groupby(['key1','key2']).mean().unstack(-1))
print('-'*20)# 按照类型分组 按照行分组没有意义 用处很少
print(pd_array.groupby(pd_array.dtypes,axis=1).size())
输出:
key1 key2 data1 data2
0 a one 0.416776 -0.786980
1 b one 0.793218 -0.202770
2 a two -0.228738 0.086266
3 b three 1.686315 -0.963315
4 a two -0.216936 2.084435
5 b two 0.365339 -0.527918
6 a one -0.963694 0.503366
7 a three -0.476463 -1.732598
--------------------data1 data2
key1
a -0.293811 0.030898
b 0.948291 -0.564667
--------------------
0 2
2 1
3 3
5 1
7 1
dtype: int640 1 2
0 a one -0.370204
1 b one 0.590449
2 a two -0.142472
3 b three 0.723001
4 a two 1.867499
5 b two -0.162579
6 a one -0.460329
7 a three -2.209061
--------------------
key1 key2
a one 2three 1two 2
b one 1three 1two 1
dtype: int64
key2 key1
one a 2b 1
three a 1b 1
two a 2b 1
dtype: int64
--------------------data1 data2
key2 one three two one three two
key1
a -0.273459 -0.476463 -0.222837 -0.141807 -1.732598 1.085351
b 0.793218 1.686315 0.365339 -0.202770 -0.963315 -0.527918
--------------------
float64 2
object 2
dtype: int64
分组-字典
# 按照类型分组 实际上也可以理解成另一类的自定义分组
pd_array = pd.DataFrame(np.random.randint(1, 10, (5,5)),columns=['a', 'b', 'c', 'd', 'e'],index=['A', 'B', 'C', 'D', 'E'])
# 给指定某个部分的数据重新赋值为 np.NaN
pd_array.loc['B','b':'d']=np.NANprint(pd_array)
# 通过字典分组
mapping_dict = {'a':'Python', 'b':'Python', 'c':'Java', 'd':'C', 'e':'Java'}
print(pd_array.groupby(mapping_dict, axis=1).size())
print(pd_array.groupby(mapping_dict, axis=1).count()) # 非NaN的个数
print(pd_array.groupby(mapping_dict, axis=1).sum())输出:
a b c d e
A 2 6.0 8.0 1.0 2
B 2 NaN NaN NaN 4
C 5 5.0 1.0 5.0 6
D 7 3.0 3.0 6.0 5
E 8 2.0 6.0 6.0 6
C 1
Java 2
Python 2
dtype: int64C Java Python
A 1 2 2
B 0 1 1
C 1 2 2
D 1 2 2
E 1 2 2C Java Python
A 1.0 10.0 8.0
B 0.0 4.0 2.0
C 5.0 7.0 10.0
D 6.0 8.0 10.0
E 6.0 12.0 10.0分组-函数
# 通过函数分组
pd_array = pd.DataFrame(np.random.randint(1, 10, (5,5)),columns=['a', 'b', 'c', 'd', 'e'],index=['AA', 'BBBB', 'CC', 'D', 'EE'])
def group_key(idx):"""idx 为列索引或行索引"""#return idxreturn len(idx)print(pd_array)
print('-'*20)
print(pd_array.groupby(group_key).size())
输出:
a b c d e
AA 8 8 8 7 3
BBBB 7 1 5 2 4
CC 1 6 1 8 5
D 1 8 8 6 6
EE 6 5 1 6 9
--------------------
1 1
2 3
4 1
dtype: int64分组-索引级别
# 通过索引级别分组
columns = pd.MultiIndex.from_arrays([['Python', 'Java', 'Python', 'Java', 'Python'],['A', 'A', 'B', 'C', 'B']], names=['language', 'index1'])
pd_array = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns)
print(pd_array)
print('-'*20)# 根据language进行分组
print(pd_array.groupby(level='language', axis=1).sum())
# 根据index进行分组
print(pd_array.groupby(level='index1', axis=1).sum())
输出:
language Python Java Python Java Python
index1 A A B C B
0 8 2 6 4 7
1 7 6 7 9 6
2 7 8 8 4 6
3 4 4 8 7 6
4 3 5 1 3 2
--------------------
language Java Python
0 6 21
1 15 20
2 12 21
3 11 18
4 8 6
index1 A B C
0 10 13 4
1 13 13 9
2 15 14 4
3 8 14 7
4 8 3 3
聚合
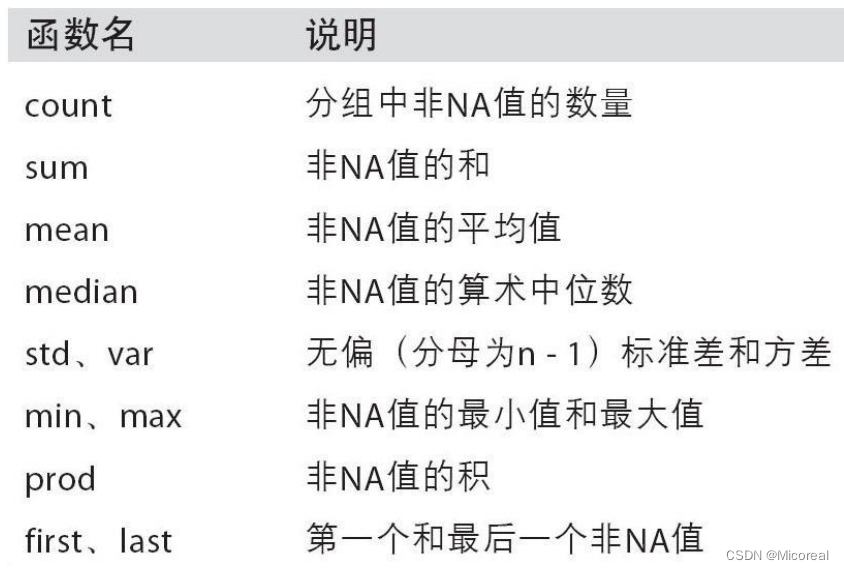
这边介绍一些别的用法:
# 聚合实际上就是上文的sum min size等函数,这边介绍一些别的用法
np_dict = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],'data1': np.random.randint(1,10, 8),'data2': np.random.randint(1,10, 8)}
np_array = pd.DataFrame(np_dict)
print(np_array)
print('-'*20)
# 自定义聚合函数
def peak_range(df):"""df:分组之后的所有数据返回数值范围"""# print(type(df)) #参数为索引所对应的记录return df.max() - df.min()print(np_array.groupby('key1').agg(peak_range))
print(np_array.groupby('key1').agg(lambda df : df.max() - df.min()))
print('-'*20)# 同时应用多个聚合函数
print(np_array.groupby('key1').agg(['mean', 'std', 'count', peak_range]))
print('-'*20)# 每列作用不同的聚合函数
dict_mapping = {'data1':'mean','data2':'count'}
print(np_array.groupby('key1').agg(dict_mapping))
输出:
key1 data1 data2
0 a 3 6
1 b 1 5
2 a 9 4
3 b 2 7
4 a 1 1
5 b 1 6
6 a 8 4
7 a 4 7
--------------------data1 data2
key1
a 8 6
b 1 2data1 data2
key1
a 8 6
b 1 2
--------------------data1 data2 mean std count peak_range mean std count peak_range
key1
a 5.000000 3.391165 5 8 4.4 2.302173 5 6
b 1.333333 0.577350 3 1 6.0 1.000000 3 2
--------------------data1 data2
key1
a 5.000000 5
b 1.333333 3对于Series的聚合处理
Series使用map,DataFrame使用的是agg
# 对于Series的函数处理
ser_obj = pd.Series(np.random.randint(0,10,10)) #series 用map
print(ser_obj)print(ser_obj.map(lambda x : x ** 2))# 也可以添加自定义函数,这边不详细介绍
输出:
0 9
1 1
2 5
3 0
4 9
5 0
6 2
7 4
8 7
9 0
dtype: int32
0 81
1 1
2 25
3 0
4 81
5 0
6 4
7 16
8 49
9 0
dtype: int64分组后改别名-加前缀
pd_dict = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],'data1': np.random.randint(1, 10, 8),'data2': np.random.randint(1, 10, 8)}
pd_array = pd.DataFrame(pd_dict)
print(pd_array)
print('-'*20)# 按key1分组后,计算data1,data2的统计信息并附加到原始表格中,并添加表头前缀
print(pd_array.groupby('key1').sum().add_prefix('sum_'))
print('-'*20)# 与上面进行对比,这个是原本多少行现在还是多少行,不会因为分组让数据的行数变化 一般用处也不大
print(pd_array.groupby('key1').transform(np.sum).add_suffix('_sum'))
输出:
key1 data1 data2
0 a 5 8
1 b 2 4
2 a 4 4
3 b 9 9
4 a 2 8
5 b 9 3
6 a 8 3
7 a 1 4
--------------------sum_data1 sum_data2
key1
a 20 27
b 20 16
--------------------data1_sum data2_sum
0 20 27
1 20 16
2 20 27
3 20 16
4 20 27
5 20 16
6 20 27
7 20 27
索引再解
#索引中单项不可变,但是整体可以换掉
pd_array = pd.DataFrame({'a': range(7),'b': range(7, 0, -1),'c': ['one','one','one','two','two','two', 'two'],'d': list("hjklmno")})
print(pd_array)
print('-'*20)# 本身的值进行了修改
pd_array1 = pd_array.copy()
pd_array1.index=list('abcdefg') #a的索引变了,a.index更换索引
print(pd_array1)
print('-'*20)# 本身的值没有进行修改
pd_array1=pd_array.reindex(list('abcdefg')) #返回一个新的pd_array,索引是设置了c的索引后,c索引不变,b是没有值
print(pd_array1)
print('-'*20)#让某些列变为索引,让c列,d列数据变为索引
print(pd_array.set_index(['c','d']))# 多层索引提取数据 注意()和[]的区别
print(pd_array.set_index(['c','d']).loc[('one','h'),'a'])
输出:
a b c d
0 0 7 one h
1 1 6 one j
2 2 5 one k
3 3 4 two l
4 4 3 two m
5 5 2 two n
6 6 1 two o
--------------------a b c d
a 0 7 one h
b 1 6 one j
c 2 5 one k
d 3 4 two l
e 4 3 two m
f 5 2 two n
g 6 1 two o
--------------------a b c d
a NaN NaN NaN NaN
b NaN NaN NaN NaN
c NaN NaN NaN NaN
d NaN NaN NaN NaN
e NaN NaN NaN NaN
f NaN NaN NaN NaN
g NaN NaN NaN NaN
--------------------a b
c d
one h 0 7j 1 6k 2 5
two l 3 4m 4 3n 5 2o 6 1
--------------------
0
时间序列

print(pd.date_range(start="20231015", end="20231020"))
print("-"*20)# 还有一些freq的属性,详情见使用手册即可
print(pd.date_range(start="20210712",periods=7,freq='B'))
print("-"*20)# %timeit是jupyter的一个统计时间的一条指令
s = ['2023-10-15','2023-10-16','2023-10-17']*1000
%timeit pd.to_datetime(s)
print("-"*20)# 降采样或者升采样,一般不会用到升采样,除非造假数据hh
print(pd.date_range(start="20231015", end="20231020"))# 当读取了一个表格的时候,可以通过如下的方式进行拼接成一个真实的时间
period = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"],hour=df["hour"], freq="H")输出:
DatetimeIndex(['2023-10-15', '2023-10-16', '2023-10-17', '2023-10-18','2023-10-19', '2023-10-20'],dtype='datetime64[ns]', freq='D')
--------------------
DatetimeIndex(['2021-07-12', '2021-07-13', '2021-07-14', '2021-07-15','2021-07-16', '2021-07-19', '2021-07-20'],dtype='datetime64[ns]', freq='B')
--------------------
3.05 ms ± 907 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)降采样
file_path = "./PM2.5/BeijingPM20100101_20151231.csv"df = pd.read_csv(file_path)
# print(df.head(10))# 把分开的时间字符串通过periodIndex的方法转化为pandas的时间类型
period = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"],hour=df["hour"], freq="H")
df["datetime"] = period
print(df.head(10))
输出:
No year month day hour season PM_Dongsi PM_Dongsihuan \
0 1 2010 1 1 0 4 NaN NaN
1 2 2010 1 1 1 4 NaN NaN
2 3 2010 1 1 2 4 NaN NaN
3 4 2010 1 1 3 4 NaN NaN
4 5 2010 1 1 4 4 NaN NaN
5 6 2010 1 1 5 4 NaN NaN
6 7 2010 1 1 6 4 NaN NaN
7 8 2010 1 1 7 4 NaN NaN
8 9 2010 1 1 8 4 NaN NaN
9 10 2010 1 1 9 4 NaN NaN PM_Nongzhanguan PM_US Post DEWP HUMI PRES TEMP cbwd Iws \
0 NaN NaN -21.0 43.0 1021.0 -11.0 NW 1.79
1 NaN NaN -21.0 47.0 1020.0 -12.0 NW 4.92
2 NaN NaN -21.0 43.0 1019.0 -11.0 NW 6.71
3 NaN NaN -21.0 55.0 1019.0 -14.0 NW 9.84
4 NaN NaN -20.0 51.0 1018.0 -12.0 NW 12.97
5 NaN NaN -19.0 47.0 1017.0 -10.0 NW 16.10
6 NaN NaN -19.0 44.0 1017.0 -9.0 NW 19.23
7 NaN NaN -19.0 44.0 1017.0 -9.0 NW 21.02
8 NaN NaN -19.0 44.0 1017.0 -9.0 NW 24.15
9 NaN NaN -20.0 37.0 1017.0 -8.0 NW 27.28 precipitation Iprec datetime
0 0.0 0.0 2010-01-01 00:00
1 0.0 0.0 2010-01-01 01:00
2 0.0 0.0 2010-01-01 02:00
3 0.0 0.0 2010-01-01 03:00
4 0.0 0.0 2010-01-01 04:00
5 0.0 0.0 2010-01-01 05:00
6 0.0 0.0 2010-01-01 06:00
7 0.0 0.0 2010-01-01 07:00
8 0.0 0.0 2010-01-01 08:00
9 0.0 0.0 2010-01-01 09:00 # 把datetime 设置为索引
df.set_index("datetime", inplace=True)# 进行降采样,进行降采样,行索引必须是pd的时间类型
df = df.resample("7D").mean()
print(df.head())
输出:
No year month day hour season PM_Dongsi \
datetime
2010-01-01 84.5 2010.0 1.000000 4.000000 11.5 4.0 NaN
2010-01-08 252.5 2010.0 1.000000 11.000000 11.5 4.0 NaN
2010-01-15 420.5 2010.0 1.000000 18.000000 11.5 4.0 NaN
2010-01-22 588.5 2010.0 1.000000 25.000000 11.5 4.0 NaN
2010-01-29 756.5 2010.0 1.571429 14.285714 11.5 4.0 NaN PM_Dongsihuan PM_Nongzhanguan PM_US Post DEWP HUMI \
datetime
2010-01-01 NaN NaN 71.627586 -18.255952 54.395833
2010-01-08 NaN NaN 69.910714 -19.035714 49.386905
2010-01-15 NaN NaN 163.654762 -12.630952 57.755952
2010-01-22 NaN NaN 68.069307 -17.404762 34.095238
2010-01-29 NaN NaN 53.583333 -17.565476 34.928571 PRES TEMP Iws precipitation Iprec
datetime
2010-01-01 1027.910714 -10.202381 43.859821 0.066667 0.786905
2010-01-08 1030.035714 -10.029762 45.392083 0.000000 0.000000
2010-01-15 1030.386905 -4.946429 17.492976 0.000000 0.000000
2010-01-22 1026.196429 -2.672619 54.854048 0.000000 0.000000
2010-01-29 1025.273810 -2.083333 26.625119 0.000000 0.000000 连接查询
建议和数据库一起学习
修改名称–column和index
pd_dict1 = {'key1' : ['a', 'b', 'a', 'b'],'key2' : np.arange(0,4),'data1': np.random.randint(1, 10, 4),'data2': np.random.randint(1, 10, 4)}
pd_dict2 = {'key1' : ['a', 'b', 'a', 'b'],'data1': np.random.randint(1, 10, 4)}
pd_array1 = pd.DataFrame(pd_dict1)
pd_array2 = pd.DataFrame(pd_dict2)
print(pd_array1)
print(pd_array2)
print('-'*20)# 为了完成下文实现的左外连接 右外连接 全外连接 以及内连接,这边可以先进行改名索引名称
# 值得关注的是这个改名是返回值的类型的
pd_array2 = pd_array2.rename(columns={'key1':'key3','data1':'data3'})
print(pd_array2)
输出:
key1 key2 data1 data2
0 a 0 5 4
1 b 1 9 4
2 a 2 1 9
3 b 3 5 5key1 data1
0 a 8
1 b 1
2 a 8
3 b 5
--------------------key3 data3
0 a 8
1 b 1
2 a 8
3 b 5
连接查询
pd_dict1 = {'key1' : ['a', 'b', 'a', 'b'],'key2' : np.arange(0,4),'data1': np.random.randint(1, 10, 4),'data2': np.random.randint(1, 10, 4)}
pd_dict2 = {'key3' : ['a', 'b', 'a', 'b'],'data3': np.random.randint(1, 10, 4)}
pd_array1 = pd.DataFrame(pd_dict1)
pd_array2 = pd.DataFrame(pd_dict2)
print(pd_array1)
print(pd_array2)
print('-'*20)# 内连接 取交集 然后on就是取具体的字段 index就是取索引,相同的也有left_index 和right_on 随意搭配使用
print(pd.merge(pd_array1,pd_array2,left_on='key2',right_index=True))
print('-'*20)# 左连接或者叫左外连接/右连接 想一下sql当中是不是叫作 left outer join
# 右连接就是how改成right 这边就不进行演示了,毕竟左右连接二者都是可以进行相互转化的
print(pd.merge(pd_array1,pd_array2,left_on='key1',right_on='key3',how='left'))
print('-'*20)# 全外连接
print(pd.merge(pd_array1,pd_array2,left_on='key1',right_on='key3',how='outer'))
输出:
key1 key2 data1 data2
0 a 0 8 7
1 b 1 2 8
2 a 2 4 1
3 b 3 6 1key3 data3
0 a 4
1 b 1
2 a 7
3 b 4
--------------------key1 key2 data1 data2 key3 data3
0 a 0 8 7 a 4
1 b 1 2 8 b 1
2 a 2 4 1 a 7
3 b 3 6 1 b 4
--------------------key1 key2 data1 data2 key3 data3
0 a 0 8 7 a 4
1 a 0 8 7 a 7
2 b 1 2 8 b 1
3 b 1 2 8 b 4
4 a 2 4 1 a 4
5 a 2 4 1 a 7
6 b 3 6 1 b 1
7 b 3 6 1 b 4
--------------------key1 key2 data1 data2 key3 data3
0 a 0 8 7 a 4
1 a 0 8 7 a 7
2 a 2 4 1 a 4
3 a 2 4 1 a 7
4 b 1 2 8 b 1
5 b 1 2 8 b 4
6 b 3 6 1 b 1
7 b 3 6 1 b 4这边为了避免某些语言不存在全外连接,这边就稍微介绍一下:
外连接就是左连接 和 右连接之和,也就是包括了左表存在右表不存在 与 右表存在左表不存在的这两种情况。
数据合并
index不重复的时候
# index 没有重复的情况
pd_array1 = pd.Series(np.random.randint(0, 10, 5), index=range(0,5))
pd_array2 = pd.Series(np.random.randint(0, 10, 4), index=range(5,9))
pd_array3 = pd.Series(np.random.randint(0, 10, 3), index=range(9,12))
print(pd_array1)
print(pd_array2)
print(pd_array3)
print('-'*20)print(pd.concat([pd_array1, pd_array2, pd_array3]))
print(pd.concat([pd_array1, pd_array2, pd_array3], axis=1))
print('-'*20)
输出:
0 7
1 7
2 7
3 8
4 2
dtype: int32
5 6
6 1
7 1
8 4
dtype: int32
9 2
10 0
11 9
dtype: int32
--------------------
0 7
1 7
2 7
3 8
4 2
5 6
6 1
7 1
8 4
9 2
10 0
11 9
dtype: int320 1 2
0 7.0 NaN NaN
1 7.0 NaN NaN
2 7.0 NaN NaN
3 8.0 NaN NaN
4 2.0 NaN NaN
5 NaN 6.0 NaN
6 NaN 1.0 NaN
7 NaN 1.0 NaN
8 NaN 4.0 NaN
9 NaN NaN 2.0
10 NaN NaN 0.0
11 NaN NaN 9.0
--------------------index重复的情况
# index 有重复的情况
pd_array1 = pd.Series(np.random.randint(0, 10, 5), index=range(5))
pd_array2 = pd.Series(np.random.randint(0, 10, 4), index=range(4))
pd_array3 = pd.Series(np.random.randint(0, 10, 3), index=range(3))print(pd_array1)
print(pd_array2)
print(pd_array3)
print('-'*20)# 相同索引名直接往下排
print(pd.concat([pd_array1,pd_array2,pd_array3]))
print(pd.concat([pd_array1,pd_array2,pd_array3],axis=1))
print('-'*20)# 可以按照内连接外连接进行理解,也可以按照有无Nan进行理解
print(pd.concat([pd_array1,pd_array2,pd_array3], axis=1, join='inner'))
print(pd.concat([pd_array1,pd_array2,pd_array3], axis=1, join='outer'))
输出:
0 9
1 8
2 3
3 8
4 7
dtype: int32
0 7
1 7
2 4
3 4
dtype: int32
0 1
1 3
2 4
dtype: int32
0 9
1 8
2 3
3 8
4 7
0 7
1 7
2 4
3 4
0 1
1 3
2 4
dtype: int320 1 2
0 9 7.0 1.0
1 8 7.0 3.0
2 3 4.0 4.0
3 8 4.0 NaN
4 7 NaN NaN0 1 2
0 9 7 1
1 8 7 3
2 3 4 40 1 2
0 9 7.0 1.0
1 8 7.0 3.0
2 3 4.0 4.0
3 8 4.0 NaN
4 7 NaN NaN去重
pd_array = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4,'data2' : np.random.randint(0, 4, 8)})
print(pd_array)
print('-'*20)# duplicated内部不填值实际上就是对于data1 data2的同时相同的去重,如果加上字段,实际上就变成了只要那个字段相同,就去重,类似多重索引
print(pd_array.duplicated(),end='\n\n')
print(pd_array.duplicated('data2'))
print(pd_array[~pd_array.duplicated()])
print('-'*20)# 上面的方法是根据得到一个true or false的方式去重的,下面采用直接一个函数去重
# 一样参数还是包含着 不包含参数就是所以要相同, 包含参数字段,就是对应字段相同的来
print(pd_array.drop_duplicates('data1'))# 值得关注的是在pandas当中的nan和nan是相等的,这边懒得给出例子,读者可以自己想例子
输出:
data1 data2
0 a 2
1 a 1
2 a 3
3 a 1
4 b 2
5 b 3
6 b 1
7 b 0
--------------------
0 False
1 False
2 False
3 True
4 False
5 False
6 False
7 False
dtype: bool0 False
1 False
2 False
3 True
4 True
5 True
6 True
7 False
dtype: booldata1 data2
0 a 2
1 a 1
2 a 3
4 b 2
5 b 3
6 b 1
7 b 0
--------------------data1 data2
0 a 2
4 b 2数据替换
pd_array=pd.Series(np.arange(5))
print(pd_array)
print('-'*20)# 单个值替换单个值 值得关注的是为2的值换值 不是为2的索引换值
print(pd_array.replace(2,10))
print('-'*20)# 多个值替换一个值
print(pd_array.replace(range(2,4), 10))
print('-'*20)# 多个值替换多个值
print(pd_array.replace([1,3], [-100, -200]))
输出:
0 0
1 1
2 2
3 3
4 4
dtype: int32
--------------------
0 0
1 1
2 10
3 3
4 4
dtype: int32
--------------------
0 0
1 1
2 10
3 10
4 4
dtype: int32
--------------------
0 0
1 -100
2 2
3 -200
4 4
dtype: int32